文章目录
- 前言
- [1 decoder-only LLM 的自回归生成流程](#1 decoder-only LLM 的自回归生成流程)
- [1.1 llm为什么 是 decoder only 一同天下](#1.1 llm为什么 是 decoder only 一同天下)
- [1.2 一般性的基础模块](#1.2 一般性的基础模块)
-
-
- [1.2.1 tokenizer](#1.2.1 tokenizer)
- [1.2.1 token embeding](#1.2.1 token embeding)
- [1.2.3 VLM token embeding](#1.2.3 VLM token embeding)
- [1.2.4 position embedding 和 RoPE](#1.2.4 position embedding 和 RoPE)
- [1.2.5 decoder-only V.S. encoder-only](#1.2.5 decoder-only V.S. encoder-only)
- [1.2.6 temperature 和 top-p](#1.2.6 temperature 和 top-p)
- [1.2.7 illusion 和 hallucination](#1.2.7 illusion 和 hallucination)
- [1.2.8 多模态的诅咒(模态对齐税)](#1.2.8 多模态的诅咒(模态对齐税))
-
- [1.3 VLM 的主要问题点](#1.3 VLM 的主要问题点)
- 总结
前言
我们可以看到有如下关系
LLM:
text tokens → text tokens
VLM:
image tokens + text tokens → text tokens
VLA:
image tokens + text tokens + robot state/history → action tokens / continuous actions
笔者 在 看 很多vla 的 论文时, 看到 VLM 是 很多 机器人和自驾的核心.
所以 接下来会深入vlm 进行学习
1 decoder-only LLM 的自回归生成流程
在当前的 LLM(如 GPT 系列、Llama、Qwen 等)中,Decoder-only 架构占据了绝对的主导地位。这类模型的特征是自回归生成(Autoregressive Generation),简单来说,就是"根据当前看到的所有历史内容,预测下一个 Token;然后把新生成的 Token 塞进历史里,像滚雪球一样循环往复。
1.1 llm为什么 是 decoder only 一同天下
主要原因是 decoder only 有很好的 scaling 可预测, 其他的是次要原因
(1) decoder 注重因果 (casual mask)
gpt: decoder-only
bert: encoder-only (random mask)
decoder中的训练数据因为从左向右(即单向的右边不能看到左边) 训练效率较高 会挨个将训练数据训练 , 而 bert 是对 15% 的 遮住的算loss
最重要的是 ,这样可以迫使模型去看上下文, 学会真正的推理 ,而不是因为知道 答案而倒推.
(2) decoder 训推一致
gpt 训练和 推理 都是 从左向右 但方向
bert里面 是带有 mask 的, 模型 会 看到 mask 预测, 而模型在推理时是没有 mask, 这样就会有分布偏移
bert也意识到这个问题, 将 15% 里面 10% 保留原词, 10% 是随机替换, 但是只是缓解, 没有根本解除.
(3) decoder 使用范式变化
在 bert 时代, 每个任务需要手机标注数据, 分类头, 问答头, 标注头 等等
例如:
情感分类(垃圾邮件识别):
你必须在 BERT 顶端焊上一个 分类头(Classification Head)(本质是一个普通的线性层 Linear Layer),输出概率是 0 还是 1。你需要收集 1 万条标注好的邮件去微调(Fine-tune)它。
抽取式问答(从文章中找答案):把分类头拆下来,换上一个 问答头(QA Head),去预测答案在文章中的"起始位置"和"结束位置"的索引。又需要收集几千条问答数据去训练。
命名实体识别(找人名、地名):再换上一个 序列标注头(Sequence Labeling Head)(比如 CRF 层),去预测每个词是不是名字。
在 gpt(具体是 gpt3) 时代,设计 prompt 即可: Language Modeling Head(预测下一个词的头) , 一个模型处理所有任务, 上下文学习 = 序列生成(天然的 预测序列)
例如:
做分类任务:输入 Prompt: "判断以下邮件是否为垃圾邮件:'恭喜你中奖一亿元!'。选项:是,否。"
GPT 的工作: 预测下一个 Token。它顺理成章地预测出:"是"。
做问答任务:输入 Prompt: "文章:'张三出生于北京。'。请问张三出生在哪里?"GPT 的工作: 预测下一个 Token。它接着输出:"北" → \rightarrow → "京"。
做翻译任务:输入 Prompt: "将'苹果'翻译成英文:"GPT 的工作: 预测下一个 Token。输出:"Apple"。
(4) scaling 表现好
openai在研究 scaling law 的时候 发现 同时增加 模型参数/数据量/计算量时, decoder only 做 language model 的 cross-entropy loss 下降曲线是最平滑最可预测的(https://arxiv.org/pdf/2001.08361).
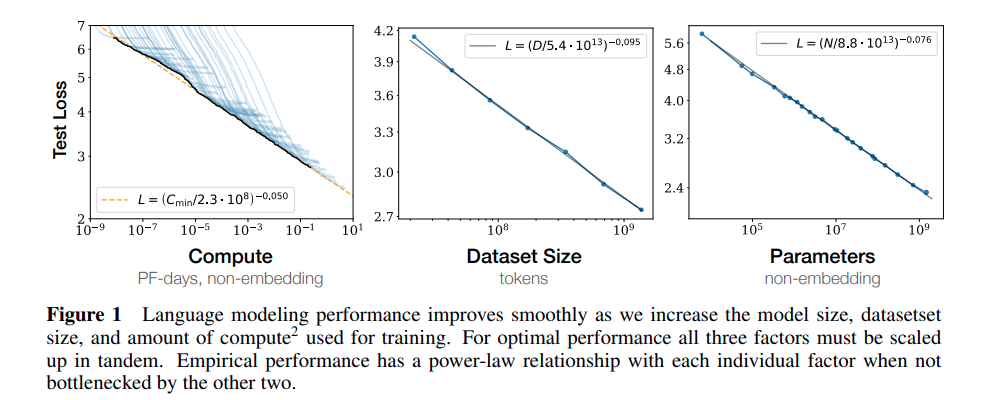
这对一个公司进行大规模训练时 有了较好的可控预测(几千万训练费用不会打水漂)
(5) kv cache
kv cache 可以将计算复杂度 从 O 2 → O ( n ) O^2 → O(n) O2→O(n)
(6) encoder+decoder 不如 decoder only
google 的 T5 就是用 encoder + decoder,感觉应该更牛逼(但是市场上你看不到这样的结构)
但是 encoder 和 decoder 的 参数 比例 多少合适? T5 做了 消融实验, 结论是相等效果更好,
但是所有的任务上都是 相等更好么? 不清楚, 所以这种不确定性在动辄几千万元的训练面前就变得不合适.
还有一个问题就是 encoder 的输出要给decoder 计算交叉注意力, 训练时, encoder 和 decoder 的流水线如何切分 需要考虑, 交叉注意力计算也更复杂
最有一个是致命弱点,就是 假设上述两点都解决了, 但是encoder+ decoder 在上下文学习过程中没有 胜过 decoder only 结构, 甚至 因为 encoder(理解) + decoder(生成) 因为将 理解 和 生成 分成了两个部分, 这样 使得模型在学习新任务的能力 学习上下问的能力减弱
1.2 一般性的基础模块
再来复习下 基础模块,基础怎么打都不为过
1.2.1 tokenizer
LLM 不认识字符串: "pick up the red cube"
模型需要经过 tokenizer : "pick up the red cube" -> 1234, 567,891, 4321, 7788 (部分token 压缩 可能 pick up 会被合并)
所以可以看出:
原始文本 = 人能读懂的符号
token_ids = 模型处理的token 的编号
代码里经常是:
python
encoded = tokenizer("pick up the red cube", return_tensors = "pt")
input_ids = encoded["input_ids"]此时, input_ids.shape = batch_size, seq_len, 我们给seq_len 取名T方便后面描述
1.2.1 token embeding
token mbeding 就是把ids 变成向量, LLM 有一个 embedding table : vocab_size, hidden_size
假设 vocab_size = 32000, hidden_size(H) = 4096
那么, embeding table 的形状就是: 32000, 4096
假设token_ids = 1234 , 那么 就有
token_id = 1234
↓
embedding_table1234
↓
一个 4096 维向量
得到
input_ids: B, T
↓
embeds: B, T, H
1.2.3 VLM token embeding
普通的 LLM 输入的是:
text token ids → text token embedings
VLM 输入的是:
image→vision encoder→ image features→ projector → image embeddings
将两者拼起来:
image_embeds: B, N, H
text_embeds: B, T, H
inputs_embeds: B, N + T, H
1.2.4 position embedding 和 RoPE
如果没有 position embedding 或者 RoPE(https://spaces.ac.cn/archives/8265/comment-page-1)
下面这几个词在llm 看来都是一样的
I love robot
robot love I
love I robot
但是这两者有点区分:
普通 position embedding:直接加到 token embedding 上。
RoPE:不是直接加到 embedding 上,而是在 attention 里作用到 Q 和 K 上。 在做attention 的时候 让模型知道: 这个 token 是第几个位置 以及 两个 token 之间相隔多远
1.2.5 decoder-only V.S. encoder-only
我们之前看过的ViT 就是encoder only (full attention)
而llm 是 decoder only (masked attention)
他们的区别在于
ViT / encoder-only:
所有 token 可以互相看。
LLM / decoder-only:
每个 token 只能看自己和前面的 token。
1.2.6 temperature 和 top-p
这两个都是打模型来控制随机性的,
temperature 和 top-p 越高, 富有创造力, temperature 和 top-p 越低 回答保守越稳定
1.2.7 illusion 和 hallucination
illusion 是错觉,
hallucination 是幻觉: 凭空捏造, 用户给的是对, 但是无中生有出来很多没有的.
大模型为什么会有幻觉?
原因1: 大模型的目标就不是说真话, 而是预测下一个token. 一个模型在训练中从来没有接受过这样的监督(比如一个事情是事实还是编的.) ,大模型学的是当前文本的下一个词可能是什么, 他学的是语言的统计规律而不是 世界的真实知识, 因此模型就没有追求真实的动力. 大模型追求的是流畅和连惯性像人说的话, 刚好巧合大多数时候流畅的文本也恰好是真实的. 所以大部分情况看起来时说真话, 一旦说得通畅和说得正确发生冲突, 模型会毫不犹豫选择说得通
原因2: 模型不知道自己不知道什么, 人类会知道我对有些事情不了解, 但是模型没有这种机制, 大模型永远是一个token 接着一个token 往下说.
原因3: 训练和推理之间存在差异(暴露偏差). 训练的时候模型用的是 teacher forcing 每一步的输入都是真实的上下文, 而推理的时候模型看的是自己推理得到的上下文, 如果前面生成一个有偏差那么就会基于上的这个错误继续往下写错误会越滚越大,最后结果也许偏离事实,但是流畅度是可以的, 这也是模型经常在较长上下文时出现幻觉.
原因4: 压缩导致的信息损失
因为训练的本质就是用较少的参数(几十B)去记住数万亿token(数十TB), 这个压缩比例在100:1 ~ 300:1, 当你问道一些低频度细节性的事实, 模型很可能没有详细记忆只能靠模式补全然后来猜出来一个合理的答案.
原因5: attention检索失败, 有些知识是存在模型参数里的(也就是没有压缩信息丢失),但是推理的时候没有被正确的取出来, q 和 k 去匹配时是模糊的, 当上下文很长或者模型的推理和训练时见到的表述差异较大时, 注意力可能会指向错误的信息
原因6: 大模型经过 RLHF 后, 模型"学会兜底", 也就是宁可回答是不好的也不要空着不回答.
1.2.8 多模态的诅咒(模态对齐税)
4个原因:
(1)信息密度不对等, (2)零和博弈, (3)跨模态对llm的扭曲, (4)冗余token 稀释了注意力
详见 https://blog.csdn.net/mikhailbran/article/details/161872314
1.3 VLM 的主要问题点
text
VLM 结构
├── 双塔对齐结构
│ ├── CLIP
│ └── SigLIP
│
├── Projector 拼接结构
│ ├── LLaVA
│ ├── CLIP vision encoder
│ ├── linear / MLP projector
│ ├── image tokens 映射到 LLM hidden space
│ └── image tokens + text tokens concat
│
├── Query 压缩结构
│ ├── BLIP-2
│ ├── frozen image encoder
│ ├── Q-Former
│ ├── learnable query tokens
│ └── compressed visual tokens → LLM
│
├── Cross-Attention 注入结构
│ ├── Flamingo
│ ├── Perceiver Resampler
│ ├── fixed visual tokens
│ ├── gated cross-attention
│ └── interleaved image-text input
│
├── SigLIP + LLM 结构
│ ├── PaliGemma
│ ├── SigLIP vision encoder
│ ├── Gemma language model
│ └── transfer-friendly VLM
│
├── Fused Vision Encoder 结构
│ ├── Prismatic VLM
│ ├── DINOv2
│ ├── SigLIP
│ ├── fused visual features
│ └── OpenVLA backbone
│
└── Dynamic Resolution 结构
├── Qwen2-VL
├── Qwen2.5-VL
├── dynamic visual tokens
├── M-RoPE
├── image / video unified input
└── grounding / OCR / long-video capability总结
1 为什么decode only 盛行
2 一般性的 知识点
3 梳理了vlm 重点结构都有哪些