大模型 API 接入到生产系统之后,最容易遇到的问题不是"能不能调用成功",而是"应该把这次请求发给哪个模型、哪个供应商、哪个 endpoint,以及失败后怎么切换"。这就是大模型 API 智能路由要解决的问题。
文章目录
-
- [一、为什么大模型 API 需要智能路由](#一、为什么大模型 API 需要智能路由)
- 二、先把路由对象拆清楚
- 三、智能路由的核心输入是什么
-
- [1. 任务类型](#1. 任务类型)
- [2. 请求规模](#2. 请求规模)
- [3. 质量要求](#3. 质量要求)
- [4. 实时状态](#4. 实时状态)
- [5. 业务约束](#5. 业务约束)
- 四、推荐的路由架构
-
- [1. 任务识别层](#1. 任务识别层)
- [2. 策略决策层](#2. 策略决策层)
- [3. 通道选择层](#3. 通道选择层)
- [4. 执行与重试层](#4. 执行与重试层)
- [5. 观测与反馈层](#5. 观测与反馈层)
- 五、一个可落地的路由决策流程
- 六、降级策略怎么设计
-
- [1. 同模型换 endpoint](#1. 同模型换 endpoint)
- [2. 同供应商换模型](#2. 同供应商换模型)
- [3. 跨供应商切换](#3. 跨供应商切换)
- [4. 能力降级](#4. 能力降级)
- [5. 失败停止](#5. 失败停止)
- 七、成本控制:不要只看单价
- [八、灰度、A/B 与效果评估](#八、灰度、A/B 与效果评估)
- 九、常见坑
-
- [1. 只做模型路由,不做参数适配](#1. 只做模型路由,不做参数适配)
- [2. 失败后无限重试](#2. 失败后无限重试)
- [3. 没有请求级 trace_id](#3. 没有请求级 trace_id)
- [4. 没有隔离租户额度](#4. 没有隔离租户额度)
- [5. 路由策略不可解释](#5. 路由策略不可解释)
- 十、落地建议
- 总结
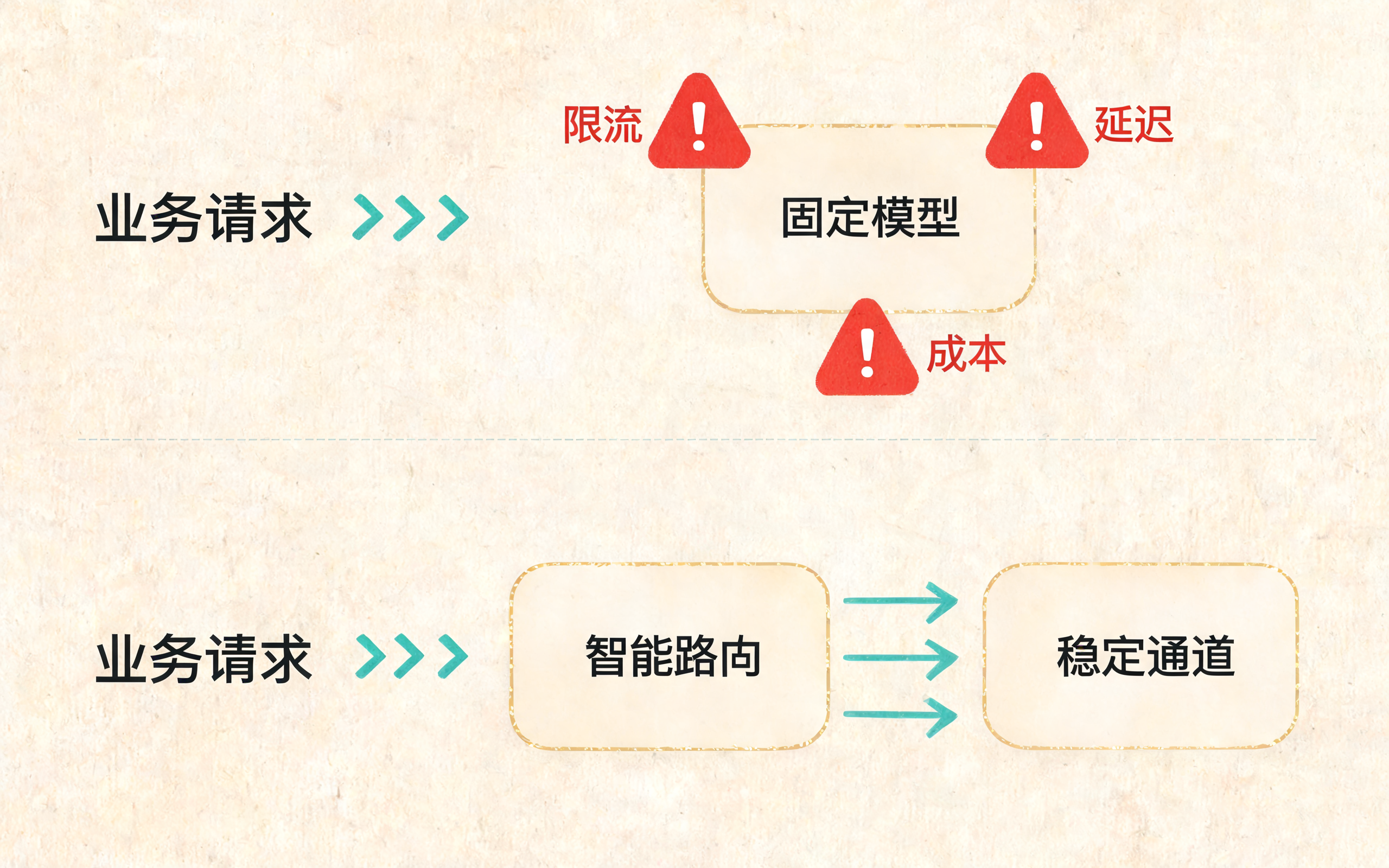
生产环境下固定模型调用与智能路由分流对比
一、为什么大模型 API 需要智能路由
很多团队一开始接大模型 API,会把调用逻辑写成这样:
text
业务请求 → 固定模型 → 固定 API Key → 固定 endpoint → 返回结果这在 Demo 阶段没问题,但进入生产后很快会遇到一堆现实问题:
- 某个模型响应慢,影响整体接口 RT;
- 某个供应商限流,业务请求开始大量失败;
- 不同任务对模型能力要求不同,简单分类任务没必要用最贵模型;
- 长上下文任务、代码生成任务、摘要任务、结构化抽取任务的最优模型不一样;
- 境内外网络、合规、成本和稳定性要求不一样;
- 某个模型升级后效果波动,需要灰度切换;
- Agent 工具调用场景里,一次任务可能包含多轮模型调用,不能每轮都盲目走同一个模型。
所以,大模型 API 路由不是简单的"负载均衡",而是一个同时考虑能力、成本、延迟、稳定性、上下文长度、地域、合规和降级策略的决策系统。
一个比较稳的目标是:
text
在满足质量和安全要求的前提下,把每次请求路由到最合适、最稳定、成本最可控的模型通道。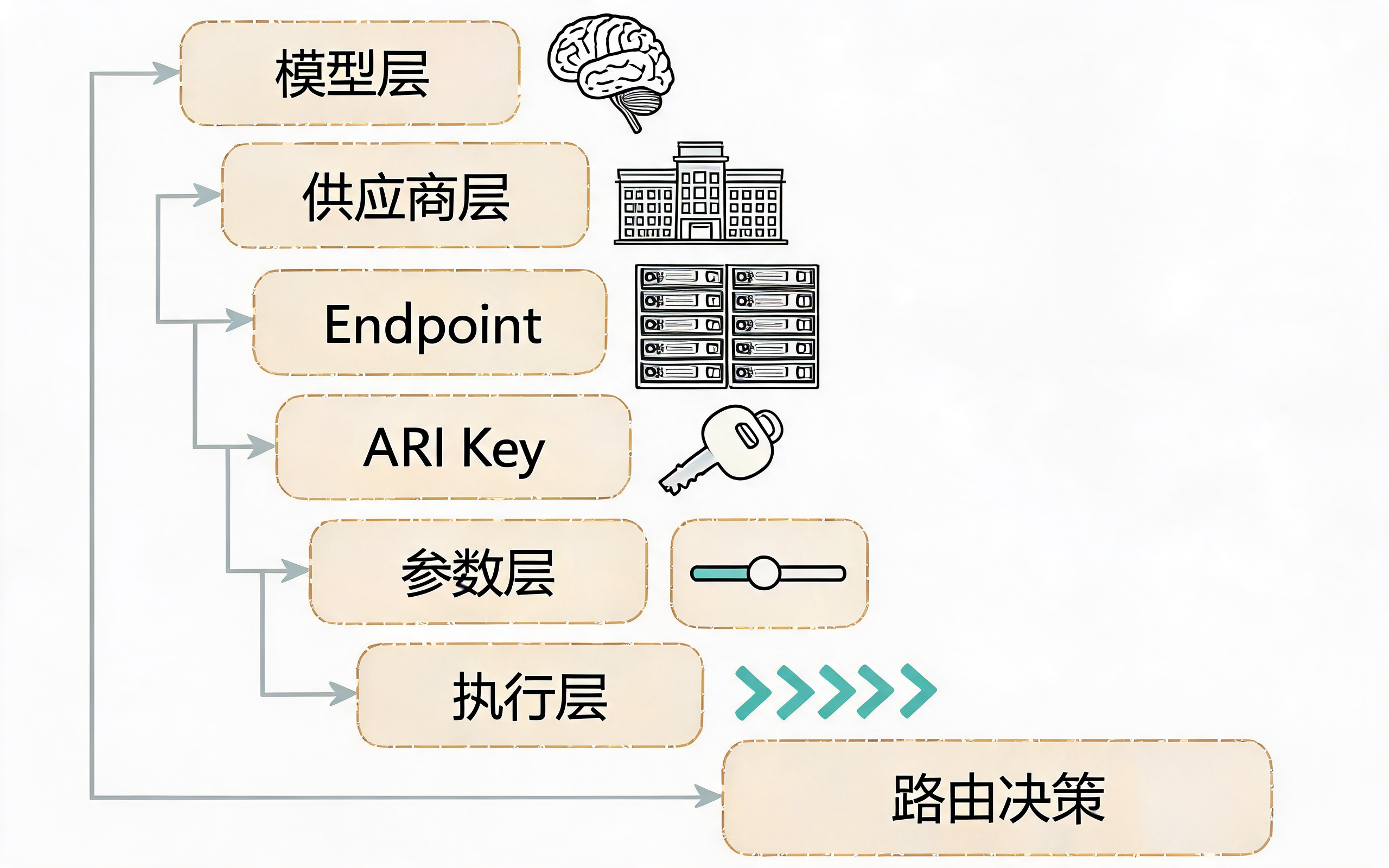
大模型 API 路由对象分层:模型、供应商、Endpoint、Key、参数和执行方式
二、先把路由对象拆清楚
做智能路由前,先不要急着写策略。第一步是把"可以被路由的对象"拆清楚。
常见路由对象包括:
| 路由层级 | 示例 | 说明 |
|---|---|---|
| 模型层 | GPT、Claude、Doubao、Qwen、DeepSeek | 根据任务能力和效果选择模型 |
| 供应商层 | OpenAI、火山方舟、阿里云、私有化模型 | 根据可用性、成本、地域和合规选择供应商 |
| endpoint 层 | 不同地域、不同网关、不同 API 版本 | 根据网络质量和版本稳定性选择入口 |
| API Key 层 | 多个账号、多组额度 | 根据限流、余额和隔离要求选择凭证 |
| 参数层 | temperature、max_tokens、stream、tools | 根据任务类型和预算动态调整参数 |
| 执行层 | 同步、流式、异步任务 | 根据响应时长和用户体验选择执行方式 |
很多系统的路由失败,原因不是策略不够复杂,而是只路由了"模型名",没有路由供应商、endpoint、Key 和参数。结果模型看似切换了,但限流、延迟或权限问题仍然存在。
三、智能路由的核心输入是什么
一个可落地的大模型 API 路由器,至少应该读取五类输入。
1. 任务类型
任务类型决定模型能力需求。比如:
- 问答:重视事实性、知识覆盖和上下文理解;
- 摘要:重视长文本处理、压缩能力和稳定输出;
- 代码:重视代码理解、补全、调试能力;
- 工具调用:重视 JSON 稳定性、函数调用可靠性;
- 分类/打标:重视成本、速度和格式稳定;
- 多模态:需要图片、音频或视频能力;
- Agent 规划:重视推理、状态跟踪和工具选择。
如果所有任务都走同一个模型,就会出现两种浪费:简单任务成本过高,复杂任务质量不够。
2. 请求规模
请求规模主要看:
- 输入 token 数;
- 预期输出 token 数;
- 是否需要长上下文;
- 是否需要流式返回;
- 是否包含图片、文件或工具 schema。
例如,一个 20 万 token 的长文档总结请求,不能路由到上下文窗口不足的模型;一个实时聊天请求,也不适合路由到首 token 延迟特别高的通道。
3. 质量要求
不是所有请求都需要最高质量。可以按业务风险分级:
| 质量等级 | 场景 | 路由倾向 |
|---|---|---|
| L1 低风险 | 标签分类、简单改写、草稿生成 | 低成本、低延迟模型 |
| L2 中风险 | 客服回答、摘要、结构化抽取 | 稳定模型 + 格式校验 |
| L3 高风险 | 法务、金融、医疗、生产变更建议 | 高质量模型 + 人工确认 + 审计 |
质量等级越高,越不能只按成本路由。
4. 实时状态
智能路由必须读取实时状态,否则只能算静态配置。
常见状态包括:
- 当前通道的成功率;
- P50/P95/P99 延迟;
- 限流次数;
- 超时次数;
- 5xx 错误率;
- 余额或配额;
- 熔断状态;
- 最近一次健康检查结果。
这部分数据通常来自网关日志、监控系统、调用埋点和健康探测。
5. 业务约束
业务约束决定哪些路由即使技术上可行,也不能选。
例如:
- 某些数据不能出境;
- 某些用户只能走私有化模型;
- 某些租户有独立 Key 和额度;
- 某些请求不能用于训练;
- 某些模型不允许处理敏感数据;
- 某些场景必须保留审计日志。
智能路由的第一条原则应该是:先过滤不允许的通道,再在允许集合里做最优选择。
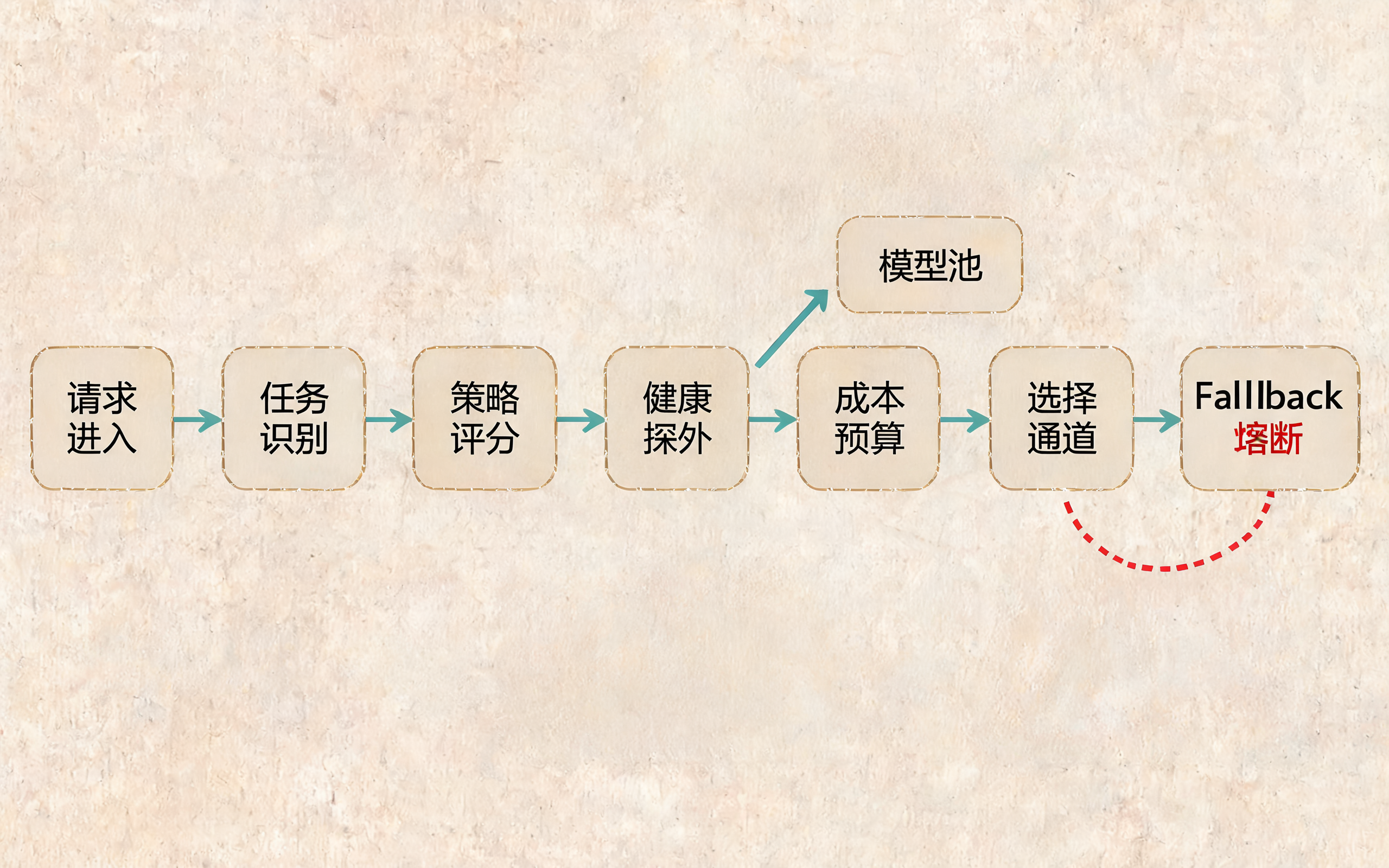
一次请求经过任务识别、策略评分、健康探针、成本预算和 Fallback 的路由流程
四、推荐的路由架构
一个相对清晰的大模型 API 智能路由架构,可以分成六层:
text
业务请求
↓
任务识别层
↓
策略决策层
↓
通道选择层
↓
执行与重试层
↓
观测与反馈层1. 任务识别层
任务识别层负责把业务请求转成结构化路由上下文。
示例:
json
{
"task_type": "tool_calling",
"risk_level": "medium",
"input_tokens": 4200,
"need_stream": true,
"need_json": true,
"tenant": "team_a",
"region": "cn",
"max_cost": 0.08,
"timeout_ms": 30000
}这一步可以由业务显式传入,也可以由网关根据路径、标签、prompt 模板或模型调用参数推断。
2. 策略决策层
策略决策层负责根据规则和实时状态生成候选通道。
常见策略:
- 任务类型 → 候选模型集合;
- 风险等级 → 是否允许低成本模型;
- 输入长度 → 过滤上下文不足的模型;
- 地域约束 → 过滤不合规通道;
- 成本预算 → 过滤价格过高通道;
- 健康状态 → 过滤熔断通道。
3. 通道选择层
通道选择层在候选集合里打分排序。
一个简单评分公式可以是:
text
score = 质量分 * 0.4 + 稳定性分 * 0.25 + 延迟分 * 0.2 + 成本分 * 0.15不同业务可以调整权重:
- 在线聊天更重视延迟;
- 自动报告更重视质量;
- 批处理任务更重视成本;
- 高风险任务更重视稳定和安全。
4. 执行与重试层
执行层要处理真实调用过程中的失败。
建议把失败分成几类:
| 错误类型 | 是否重试 | 是否换通道 | 说明 |
|---|---|---|---|
| 网络抖动 | 可重试 | 不一定 | 短暂连接失败 |
| 429 限流 | 谨慎重试 | 建议换通道或降级 | 避免重试风暴 |
| 5xx 服务异常 | 可重试 | 建议换通道 | 供应商侧异常 |
| 401/403 | 不应盲重试 | 换 Key 或停止 | 鉴权/权限问题 |
| 参数错误 | 不重试 | 修参数 | 请求体不符合 API |
| 内容安全拦截 | 不重试 | 走安全流程 | 需要业务处理 |
不要把所有失败都交给统一 retry。大模型 API 的失败语义差异很大,盲重试只会放大故障。
5. 观测与反馈层
路由器必须持续记录每个通道的表现。
建议至少记录:
- route_id;
- request_id / trace_id;
- task_type;
- selected_model;
- selected_provider;
- fallback_chain;
- status_code;
- provider_error_code;
- first_token_latency;
- total_latency;
- input_tokens / output_tokens;
- estimated_cost;
- retry_count;
- final_status。
这些数据会反过来更新通道评分,形成闭环。
五、一个可落地的路由决策流程
可以把路由流程写成下面这个顺序:
text
1. 解析任务上下文
2. 根据业务约束过滤通道
3. 根据任务类型筛选模型
4. 根据上下文长度筛选模型
5. 根据实时健康状态剔除异常通道
6. 根据质量、延迟、成本、稳定性打分
7. 选择主通道和备用通道
8. 执行调用
9. 根据错误类型决定重试、降级、切换或失败
10. 记录路由结果,更新统计指标伪代码如下:
python
def route_llm_request(ctx, channels):
candidates = []
for ch in channels:
if not ch.enabled:
continue
if ctx.region not in ch.allowed_regions:
continue
if ctx.input_tokens > ch.max_context_tokens:
continue
if ctx.task_type not in ch.supported_tasks:
continue
if ctx.risk_level == "high" and not ch.allow_high_risk:
continue
if ch.health.status == "open_circuit":
continue
candidates.append(ch)
if not candidates:
raise RuntimeError("no available llm channel")
def score(ch):
quality = ch.quality_score(ctx.task_type)
stability = 1 - ch.recent_error_rate
latency = 1 / max(ch.p95_latency_ms, 1)
cost = 1 / max(ch.price_per_1k_tokens, 0.0001)
return quality * 0.4 + stability * 0.25 + latency * 0.2 + cost * 0.15
ranked = sorted(candidates, key=score, reverse=True)
return ranked[0], ranked[1:3]这个版本不复杂,但已经比"写死一个模型名"稳定很多。
六、降级策略怎么设计
智能路由的价值,很大一部分体现在失败后的降级。
1. 同模型换 endpoint
适合网络抖动、局部地域异常。
text
model_a / endpoint_cn_1 → model_a / endpoint_cn_2优点是输出风格变化小,适合对一致性要求高的场景。
2. 同供应商换模型
适合某个模型限流或临时不可用。
text
高质量模型 → 中等质量模型要注意:模型能力下降后,最好同步降低任务复杂度,例如减少输出长度、关闭非必要工具、增加格式校验。
3. 跨供应商切换
适合供应商级别故障或限流。
text
provider_a / model_x → provider_b / model_y这种切换要提前处理好参数差异、错误码差异、流式协议差异和工具调用格式差异。
4. 能力降级
有些任务不一定要完整失败,可以降级处理:
- 从长答案降级为摘要;
- 从实时流式降级为异步任务;
- 从复杂 Agent 多轮规划降级为单轮建议;
- 从自动执行降级为人工确认;
- 从高温创意生成降级为低温稳定输出。
5. 失败停止
不是所有情况都应该降级。
例如:
- 401/403 表示鉴权或权限问题;
- 请求体参数不合法;
- 命中内容安全策略;
- 业务要求必须使用指定模型;
- 高风险任务缺少人工确认。
这些场景应该停止并返回明确错误,而不是偷偷换模型。
七、成本控制:不要只看单价
很多团队做路由时只看模型单价,这是不够的。
真实成本至少包括:
text
总成本 = 输入 token 成本 + 输出 token 成本 + 重试成本 + 失败成本 + 延迟成本 + 人工兜底成本举个例子:
- 模型 A 单价低,但 JSON 经常不稳定,导致重试两次;
- 模型 B 单价高一点,但一次成功,格式稳定;
- 最终模型 B 可能反而更便宜。
所以成本路由要结合成功率和重试率,不能只看价格表。
建议记录每个任务类型下的:
- 单次平均成本;
- 首次成功率;
- 平均重试次数;
- 平均输出长度;
- 人工介入率;
- 用户满意度或质量评分。
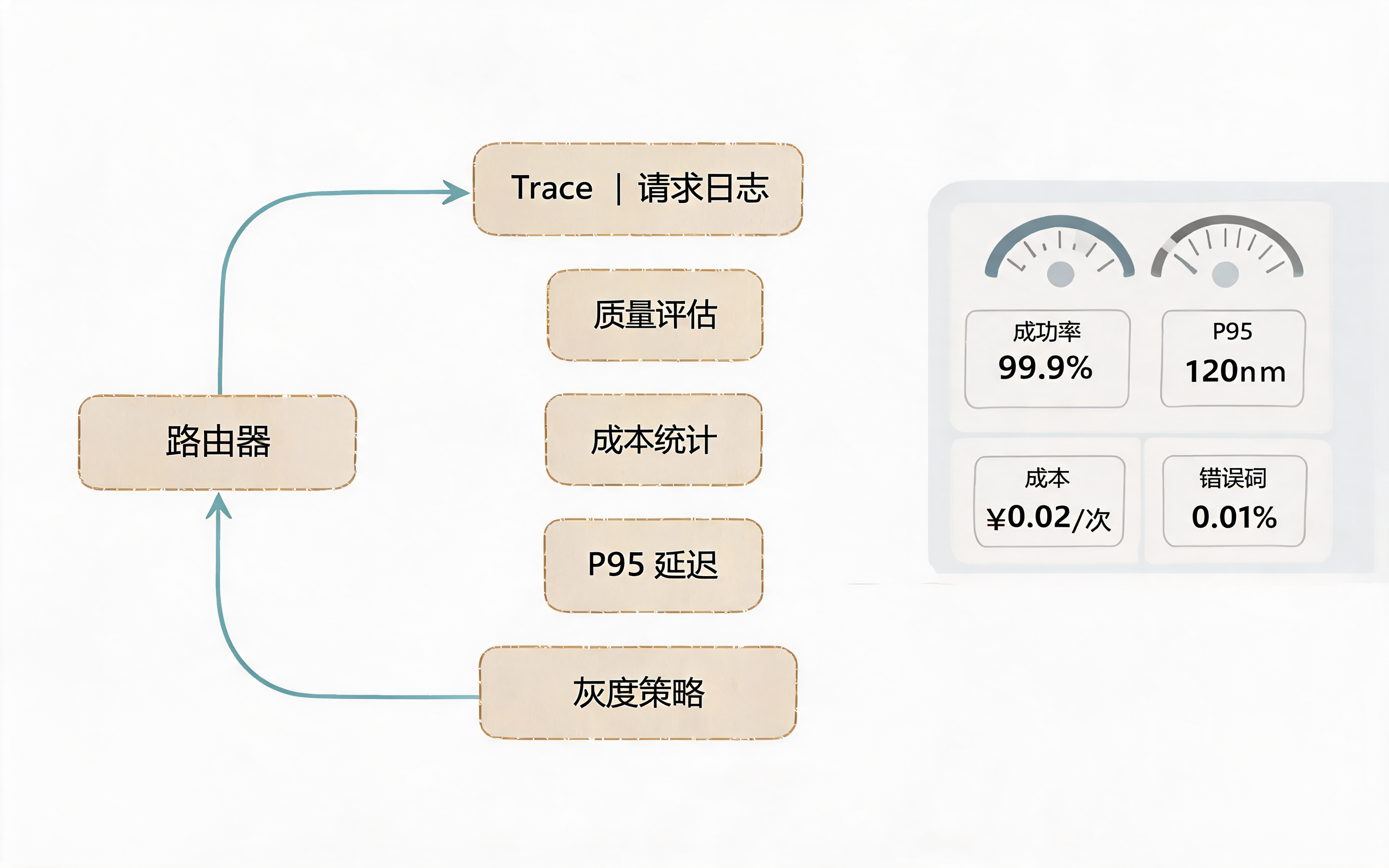
通过 Trace、日志、质量评估和灰度策略形成路由迭代闭环
八、灰度、A/B 与效果评估
智能路由上线后,不能一次性全量切换。
推荐流程:
- 离线评测:用黄金集比较不同模型在任务类型上的质量;
- 小流量灰度:让 1% 或 5% 请求走新策略;
- 指标对比:观察成功率、延迟、成本、投诉率;
- 自动回滚:指标恶化时恢复旧策略;
- 分租户放量:先低风险租户,再核心租户;
- 长期监控:模型升级、价格变化、限流变化都要重新评估。
关键是不要只看平均值。P95/P99 延迟、失败尾部、格式错误率,往往比平均质量更能反映线上体验。
九、常见坑
1. 只做模型路由,不做参数适配
不同模型的参数名、默认值、工具调用格式、JSON 输出稳定性可能不同。如果只替换 model 字段,很容易出现隐性错误。
2. 失败后无限重试
429、5xx、超时都需要退避和熔断。否则路由器会从"保护系统"变成"放大故障"的组件。
3. 没有请求级 trace_id
没有 trace_id,就很难知道一次请求到底经过了哪个模型、几次重试、哪些 fallback,以及最终为什么失败。
4. 没有隔离租户额度
多个租户共用一个 Key,一旦某个租户请求暴涨,其他租户也会被限流。生产系统最好做到租户级额度和限流隔离。
5. 路由策略不可解释
如果线上结果变差,却不知道为什么选了某个模型,排查会非常痛苦。每次路由都应该记录"选择原因"。
十、落地建议
如果从 0 开始做,我建议按三个阶段推进。
第一阶段:配置化路由
先把模型、供应商、endpoint、Key、价格、上下文长度、支持任务类型配置化。让业务不用改代码就能切换通道。
第二阶段:规则化路由
加入任务类型、上下文长度、地域、风险等级、成本预算等规则。这个阶段先不要过度智能,规则可解释更重要。
第三阶段:数据驱动路由
接入实时健康状态、质量评估、成本统计和 A/B 实验结果,让路由策略可以根据线上表现动态调整。
最终,一个成熟的大模型 API 智能路由系统应该具备这些能力:
- 任务识别;
- 合规过滤;
- 多模型候选;
- 多供应商 fallback;
- 成本和延迟权衡;
- 限流、熔断和退避;
- 请求级 trace;
- 灰度和回滚;
- 策略可解释;
- 持续评估。
总结
大模型 API 智能路由,本质上是在模型能力、稳定性、成本、延迟和业务约束之间做动态权衡。
不要把它理解成简单的"哪个便宜用哪个",也不要一开始就做成复杂的黑盒决策系统。更稳的路线是:先配置化,再规则化,最后数据驱动。
对于生产级 AI 应用来说,智能路由不是锦上添花,而是可靠性工程的一部分。它决定了系统在模型限流、供应商波动、成本压力和质量要求之间,能不能持续稳定地服务用户。