目录
背景:
通过前面的学习,我们知道一个线程是通过一堆的坐标进行定位的,本期就详细的介绍每一个线程是怎么确定唯一的索引,然后建立并行计算,并且不同的线程组织形式是怎样影响性能的
块+线程建立索引
一个核函数绑定一个网格,网格当中我们去设置块,块里面有线程
索引是啥?
本质来说就是偏移量
大家都能访问全局数据,那针对全局数据,我们想要不同的线程访问不同的部分,那就要让每个线程根据偏移量去算属于自己的那部分即可
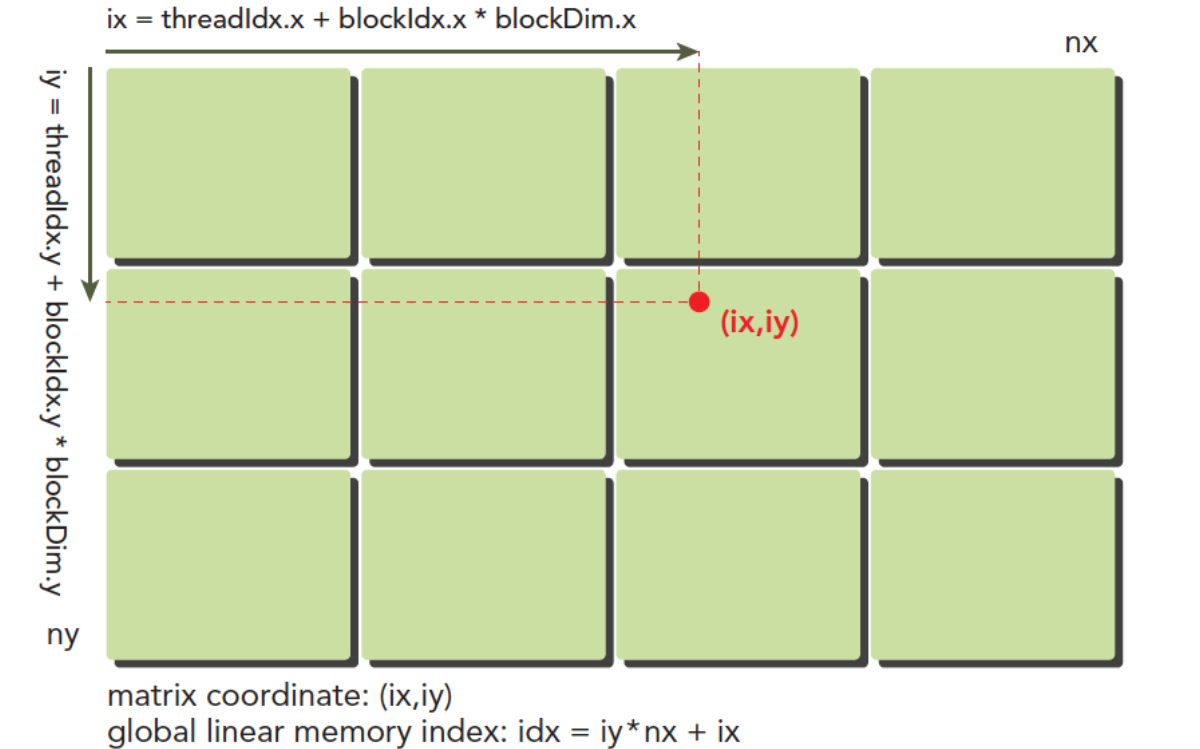
全局地址:(ix, iy),在整个全局网格当中,你属于哪里
局部地址:(threadIdx.x, threadIdx.y),在这个块中,你属于哪里
那计算一个全局地址,肯定要知道某个块有多少个线程,那就是blockDim.x
cppix = blockIdx.x * blockDim.x + threadIdx.x; iy = blockIdx.y * blockDim.y + threadIdx.y;在学习Linux系统编程的时候就曾经学过数组是如何在内存当中分布的
在Host和Device中的内存都是线性的
我们要做管理的就是:
- 线程和块索引(来计算线程的全局索引)
- 矩阵中给定点的坐标(ix,iy)
- (ix,iy)对应的线性内存的位置
你要学会把二维的地址映射成线性的一维地址,你一开始是计算得到ix,iy,但是你要通过这个地址计算偏移量,然后某个线程通过起始地址+偏移量就能在线性内存当中访问特定的地址
cppidx=ix+iy∗nx这个就是偏移量idx的计算,iy*nx就是要把前面的跳过
我们上面已经计算出了线程的全局坐标,用线程的全局坐标对应矩阵的坐标,也就是说,线程的坐标(ix,iy)对应矩阵中(ix,iy)的元素,这样就形成了一一对应,不同的线程处理矩阵中不同的数据,举个具体的例子,ix=10,iy=10的线程去处理矩阵中(10,10)的数据,当然你也可以设计别的对应模式,但是这种方法是最简单出错可能最低的。
二维矩阵加法不同模式的对比
threadIdx.x:水平方向(列方向)的偏移
threadIdx.y:垂直方向(行方向)的偏移
cppint nx = 512; // 矩阵的列数 int ny = 32768; // 矩阵的行数我们设置了二维矩阵加法,一共相加1<<24个数据
数据是一个 32768 行、512 列 的矩阵,总元素数 = 512 × 32768 = 16777216(即
1<<24)。
cppint dimx = 32; // 每个线程块在 x 方向(列方向)的线程数 int dimy = 4; // 每个线程块在 y 方向(行方向)的线程数 dim3 block(dimx, dimy); // 二维线程块:32列 × 4行 = 128 个线程
cppdim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
(nx + block.x - 1) / block.x是向上取整公式,保证列方向有足够的线程块。代入数字:
(512 + 32 - 1) / 32 = (543) / 32 = 16,列方向需要 16 个块。
(ny + block.y - 1) / block.y=(32768 + 4 - 1) / 4 = 8192,行方向需要 8192 个块。网格总大小:16 × 8192 = 131072 个线程块。
每个块 128 线程,总线程数 = 131072 × 128 = 16777216,恰好等于数据元素总数,完美覆盖。
cpp__global__ void vectorSumDevice(float* a,float*b,float*res,int nx,int ny){ //先算出下标 int ix=threadIdx.x+blockIdx.x*blockDim.x; int iy=threadIdx.y+blockIdx.y*blockDim.y; if (ix < nx && iy < ny) { int idx = iy * nx + ix; res[idx] = a[idx] + b[idx]; } }if是因为我们向上取整,所以可能开多了线程数,所以可能越界,这里是为了防止越界的
相差25倍啊,这就是并行计算的优势
二维网格一维块
一维网格一维块
- 改变执行配置(线程组织)能得到不同的性能
- 传统的核函数可能不能得到最好的效果(默认配置)
- 一个给定的核函数,通过调整网格和线程块大小可以得到更好的效果
没有万能配置,最佳 Block 大小取决于核函数的寄存器用量、共享内存大小、数据规模,以及你的 GPU 架构(计算能力)。工具就是反复试验,用
ncu或计时器对比不同配置的耗时。接下来我们将深度刨析底层硬件结构,了解完之后再来看为什么不同的配置效果竟然不一样



如何查询硬件信息
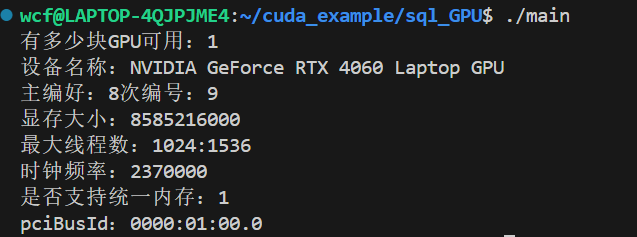
获取设备数量:
cppcudaError_t cudaGetDeviceCount(int* deviceCount);
deviceCount:输出参数,指向一个int变量的指针,函数执行成功后会把可用 CUDA 设备的数量写入这个变量。- 返回值 :
cudaError_t类型的错误码
- 成功:返回
cudaSuccess(数值为 0)- 失败:返回非 0 错误码,需要通过
cudaGetErrorString()解析获取设备信息
cppcudaError_t cudaGetDeviceProperties( cudaDeviceProp* prop, // 输出参数:CPU 内存中的结构体指针 int device // 输入参数:设备索引(从 0 开始) );返回值 :
cudaError_t错误码
- 成功:
cudaSuccess- 失败:常见错误如
cudaErrorInvalidDevice(设备索引越界)、cudaErrorInitializationError(CUDA 运行时初始化失败)
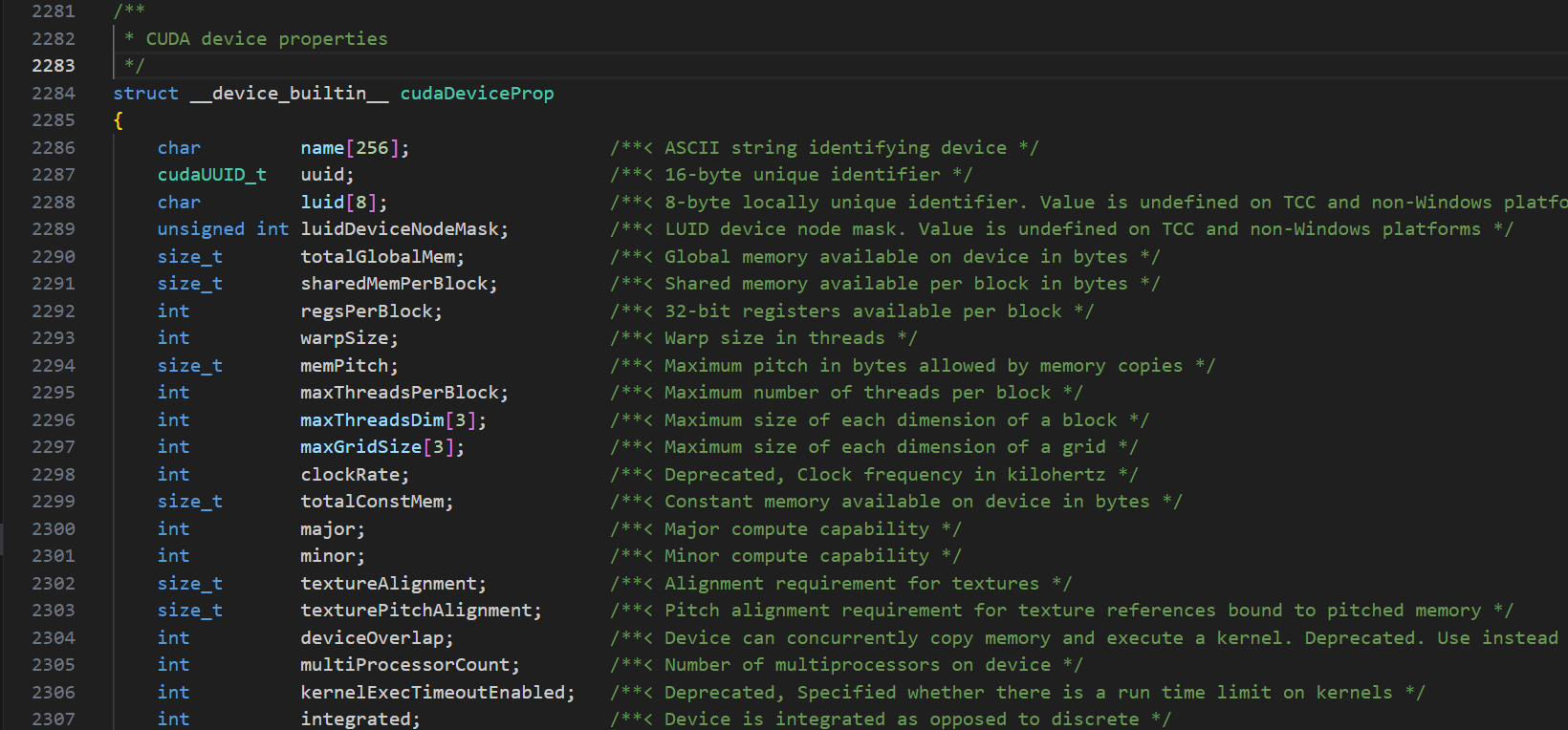
cudaDeviceProp包含超过 100 个字段,只需要记住一些常见的,或者你用的时候在查一下
名称 :
prop.name计算能力 :
prop.major,prop.minor(主次版本号)显存大小 :
prop.totalGlobalMem多处理器(SM)数量 :
prop.multiProcessorCount最大线程数 :
prop.maxThreadsPerBlock(单个线程块允许的最大线程数)、prop.maxThreadsPerMultiProcessor(单个 SM(流式多处理器)硬件上最多能同时驻留的线程总数 。)时钟频率 :
prop.clockRate(KHz)是否支持统一内存 :
prop.unifiedAddressing设置/获取当前设备:
cpp// 设置当前活跃设备 cudaError_t cudaSetDevice(int device); // 获取当前活跃设备 cudaError_t cudaGetDevice(int* device);
cudaSetDevice只影响调用它的那个 CPU 线程- 不同的 CPU 线程可以同时使用不同的 GPU 设备
- 一个 CPU 线程同一时间只能有一个活跃设备
根据条件选择设备:
cudaChooseDevice
cppcudaError_t cudaChooseDevice( int* device, // 输出:选中的设备索引 const cudaDeviceProp* prop // 输入:要求的设备属性 ); // 要求:计算能力至少 8.0,显存至少 8GB cudaDeviceProp requirement; memset(&requirement, 0, sizeof(requirement)); requirement.major = 8; // 主版本号至少 8 requirement.totalGlobalMem = 8 * 1024 * 1024 * 1024ULL; // 显存至少 8GB int bestDevice; cudaChooseDevice(&bestDevice, &requirement); printf("自动选择的最优设备: %d\n", bestDevice); cudaSetDevice(bestDevice);查看 PCIe 总线等信息:
cudaDeviceGetPCIBusId
cppcudaError_t cudaDeviceGetPCIBusId( char* pciBusId, // 输出:PCIe ID 字符串,长度至少 16 字节 int len, // 缓冲区长度 int device // 输入:CUDA 设备索引 );
pciBusId:你提供的一个字符数组(缓冲区),用于接收总线 ID 字符串。
len:这个缓冲区的长度。官方文档规定最小为 13,但建议给 128 足以万无一失。
device:要查询的 GPU 编号(0, 1, 2...)。返回值 :
cudaError_t,成功时返回cudaSuccess。返回的字符串格式是固定的:
"domain:bus:device.function",例如"0000:01:00.0"。这和在nvidia-smi里Bus-Id一栏看到的完全一致。查询CUDA版本
cpp// 获取驱动支持的最高 CUDA 版本 cudaError_t cudaDriverGetVersion(int* driverVersion); // 获取当前运行时库的版本 cudaError_t cudaRuntimeGetVersion(int* runtimeVersion); 版本号 = 主版本号 × 1000 + 次版本号 × 10
- 驱动版本告诉你:你的显卡最多能跑多新的 CUDA 程序
- 运行时版本告诉你:你的程序是用哪个版本的 CUDA 编译的
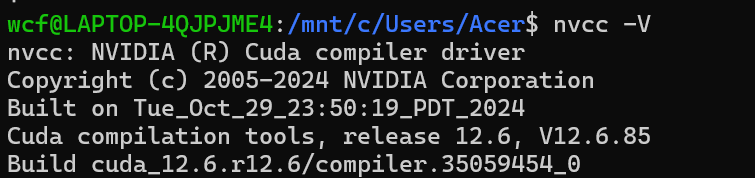
581.42 版本驱动,最多能跑用 CUDA 13.0 及以下版本编译的程序
我安装了12.6的版本,所以可以兼容,向下是可以兼容的,向上就不行
所以有时候安装的cuda过高,但是驱动不行,要么就升级驱动,要么就静态链接而不是采用动态
没问题,通过函数查询也是这个结果
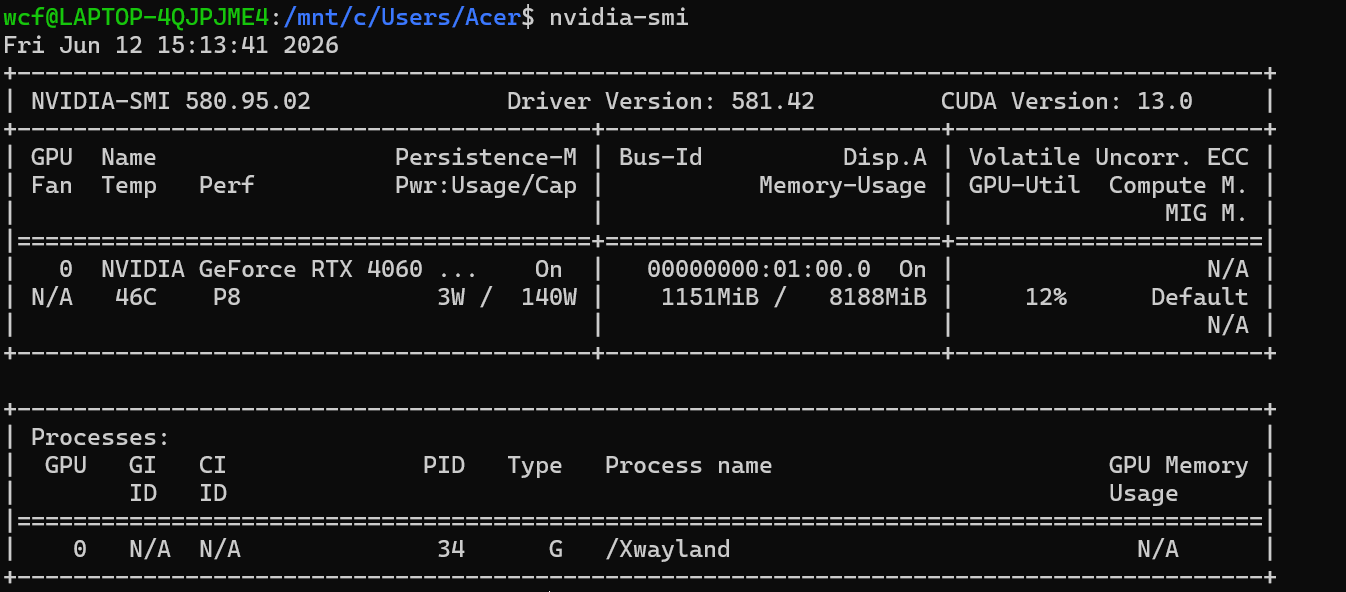
nvidia-smi
nvidia-smi全称 NVIDIA System Management Interface ,是 NVIDIA 驱动自带的命令行 GPU 监控管理工具,不需要额外安装,只要装了 NVIDIA 显卡驱动就有。它是 CUDA 开发者、AI 从业者和运维人员最常用的工具,没有之一。
bashnvidia-smi --help可以通过这个命令去参看其参数
分为三个标准部分:
- 顶部系统信息栏:驱动版本、CUDA 支持版本(只要小于13.0版本的兼容)
- 中间 GPU 设备信息表:核心硬件状态(温度、功耗、显存、利用率)
- 底部进程占用表:哪些进程正在使用 GPU 和显存
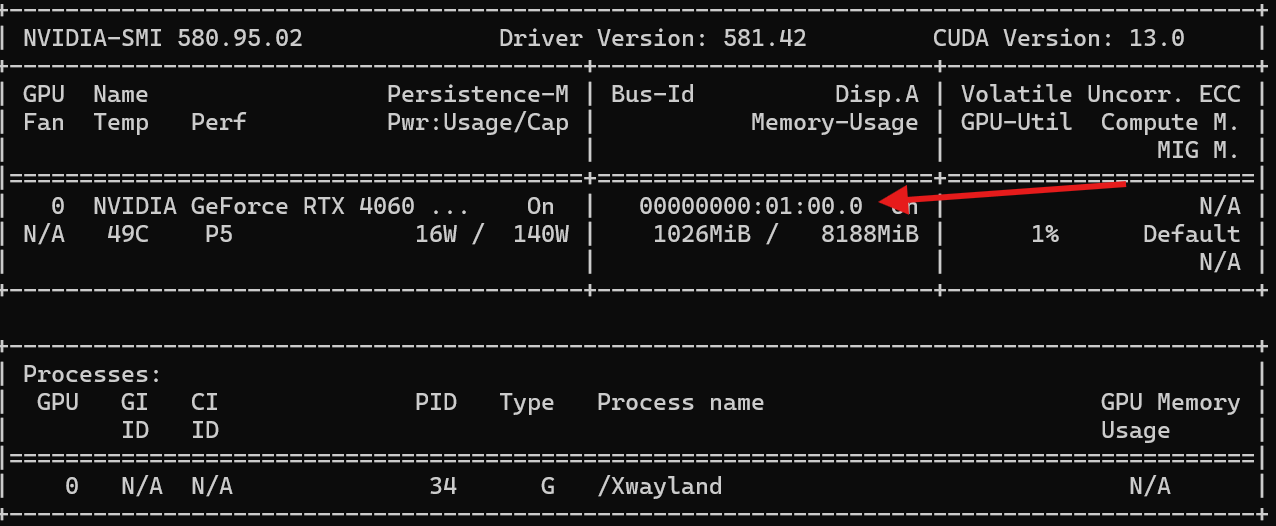
字段 含义 说明 GPU 0GPU 设备索引,从 0 开始 对应 cudaSetDevice(0)的参数,我只有 1 块显卡所以只有 0 号Name显卡完整型号 NVIDIA GeForce RTX 4060(笔记本版) Fan显卡风扇转速(0-100%) 显示 N/A是正常的:笔记本显卡的风扇由主板 EC 直接控制,nvidia-smi 读不到转速TempGPU 核心温度(摄氏度) 46℃,非常健康的待机温度(正常范围 30-85℃) PerfGPU 性能状态 从 P0(最高性能)到 P12(最低功耗)。你这里是 P8,说明 GPU 处于低功耗待机状态,运行程序时会自动升到 P0-P2 Persistence-M持久模式 On 表示驱动常驻内存,加快 CUDA 程序启动速度。服务器建议开启,笔记本不用管 Pwr:Usage/Cap当前功耗 / 设计功耗上限 3W / 140W,待机功耗极低。运行大型程序时会接近 140W 的上限
字段 含义 说明 Bus-IdPCIe 总线 ID 00000000:01:00.0,是物理 GPU 的唯一永久标识,对应cudaDeviceGetPCIBusId的返回值Disp.A显示输出状态 On 表示这个 GPU 正在连接显示器输出画面。我的笔记本屏幕就是由这块 4060 驱动的 Memory-Usage显存使用量 / 总显存 1151MiB / 8188MiB,也就是 8GB 显存,当前用了约 1.1GB(主要是桌面系统占用) Volatile Uncorr. ECCECC 内存错误计数 消费级显卡没有 ECC 纠错内存,所以永远显示 N/A GPU-UtilGPU 核心利用率(0-100%) 12%,说明有轻微的图形负载(桌面动画、窗口拖动),没有运行计算程序 Compute M.计算模式 Default 是默认模式,允许多个进程同时使用 GPU。还有 Exclusive Process(独占模式,只允许一个进程使用) MIG M.多实例 GPU 模式 消费级显卡不支持 MIG,所以永远显示 N/A
字段 含义 你的情况说明 GPU进程所在的 GPU 索引 0 号 GPU GI ID / CI IDGPU 实例 ID 和计算实例 ID 只有开启 MIG 的服务器卡才会显示,消费级永远 N/A PID系统进程 ID 34,可以用 `ps -ef grep 34` 查看这个进程的详细信息 Type进程类型 G= 图形进程(桌面、游戏、视频播放);C= 计算进程(CUDA、AI 训练、推理)Process name进程名称 /Xwayland是 Linux 桌面的显示服务器,负责渲染桌面和窗口GPU Memory Usage该进程占用的显存 显示 N/A 是正常的:Wayland/X11 的显存占用会合并到总显存中,不单独统计 支持非常强大的命令
bash1. 实时监控 GPU 状态(每秒刷新) nvidia-smi -l 1 2. 查看更详细的硬件信息 # 显示所有GPU的完整信息 nvidia-smi -q # 只显示特定GPU的信息 nvidia-smi -q -i 0 3. 自定义输出字段(适合脚本使用) # 只输出显卡型号、温度、核心利用率、显存利用率 nvidia-smi --query-gpu=name,temperature.gpu,utilization.gpu,utilization.memory --format=csv 4. 实时监控进程 GPU 占用 # 每秒刷新一次,显示所有GPU进程的利用率 nvidia-smi pmon -s u -d 1 5. 释放被占用的 GPU 显存 nvidia-smi --gpu-reset -i 0接下来我们将重点讲解硬件知识,然后根据硬件来配置最好的参数