如果你用 ClaudeCode、Codex 这类工具写过项目,大概率有过这个念头:
「这东西到底怎么工作的?TUI 怎么渲染的?tool calling 怎么实现的?能不能自己写一个?」
ARCC ------ 一个 Rust 写的多形态 AI Agent,包含 TUI 终端、CLI 子代理、Server 机器人三种模式。这篇文章会帮助你理解 ratatui 的事件循环、MPSC 通道、spinner 动画,每个模块的核心难点、踩过的坑、以及Agent权限管理和记忆机制的技术决策。
ARCC 在综合编码能力上虽不及 Claude Code、Codex 这类专业代码模型,但自身拥有独特的定制化设计:
- TUI:满足我写一个终端 Agent 的造轮子想法,充分发挥本地环境优势;
- CLI:给 Claude 当子代理,把 token 密集型任务沉到低成本模型上;
- Server:想要一个 7×24 挂在飞书里的运维机器人,随叫随到,安全可靠;
一、TUI 终端Agent

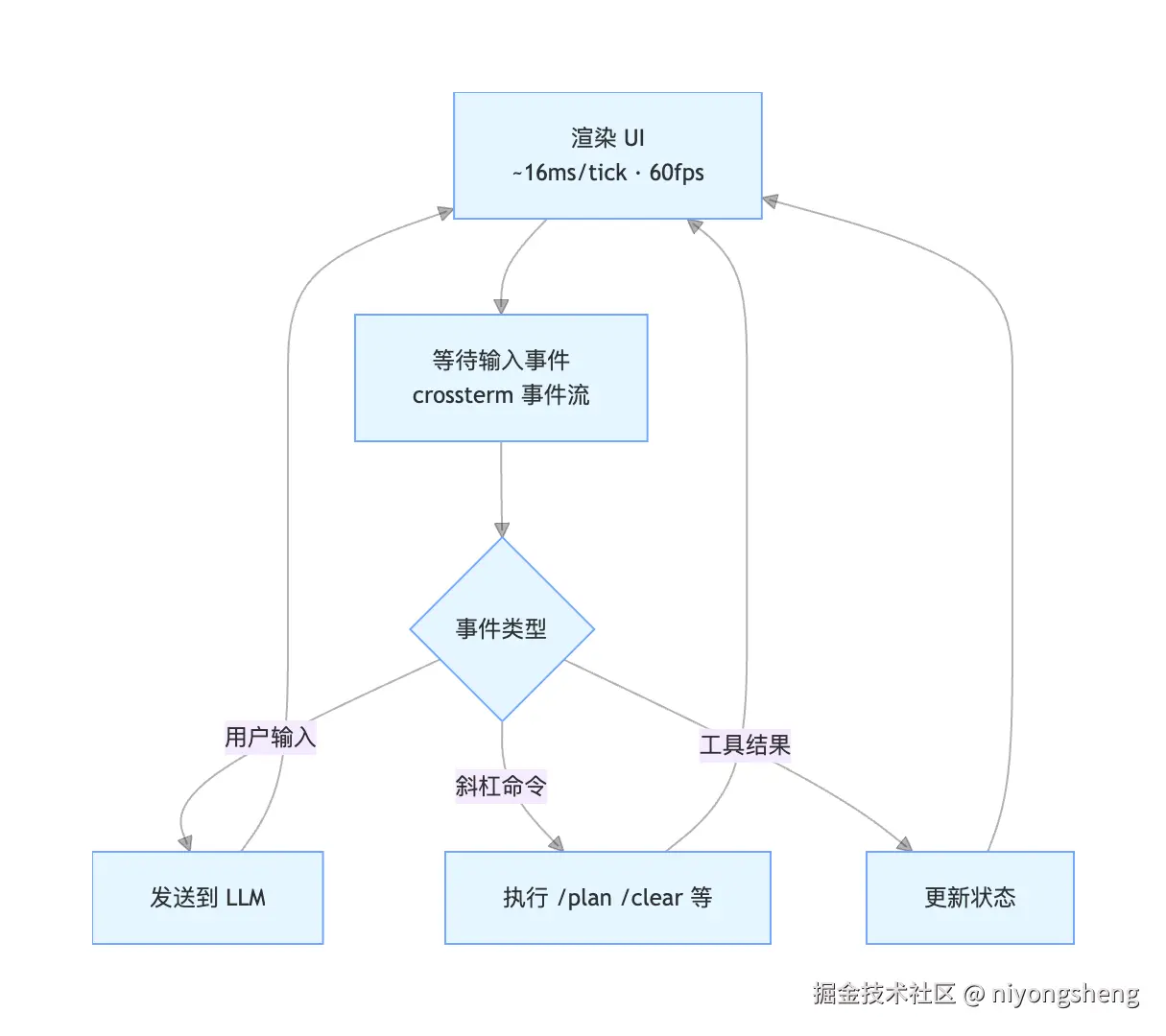
架构:MPSC 事件循环
TUI 的核心是一个永不停止的循环,LLM 的本质也是在循环------系统提示词嵌入、用户输入、工具调用、结果观察、再次推理......每一次迭代都是一次「感知-思考-行动」的闭环。
这个循环很有意思:你在 TUI 里看到的 spinner 转动、文本逐字输出、状态切换,本质上和 AI 内部的推理循环是同构的。
光标、键盘、滚轮在tui中是个容易冲突地方:
- 聊天区有滚动位置,输入框有文本光标,每个渲染 tick 要分别保存恢复
- ↑↓ 键在输入框空时滚动聊天历史,有内容时切换输入历史------语义判断必须在事件层完成,不能交给渲染
- 鼠标滚轮和键盘上下键共享同一个
scroll_offset,两个输入源都要操作它,还得卡在消息总数边界 - 执行
vim、sudo这类交互命令时,要暂时退出 alternate screen、交出 terminal 控制权,执行完再恢复。一个没处理好终端就花了
Spinner 动画:状态即帧集
用 tui-spinner 的 FluxFrames 预设帧集,不同状态映射不同动画:
| 状态 | 动画 | 视觉效果 |
|---|---|---|
| thinking | CLASSIC | ⠋⠙⠹⠸⠼⠴⠦⠧⠇⠏ |
| streaming | BOUNCE | ⠉⠒⣀⠒ |
| executing | DICE | ⚀⚁⚂⚃⚄⚅ |
| waiting | DIAMOND | ◇◈◆◈ |
| idle | --- | 绿色 ● 常亮 |
难点 :动画帧切换和 UI 刷新要同步。如果 spinner 更新和文本渲染不在同一个 tick,画面会撕裂。解决方案是在 App.status 中保存当前状态,渲染时根据状态选择帧集。
流式渲染 + DSML
AI 回复是流式到达的,每个 chunk 到就更新 UI。但 DeepSeek 有个坑------它偶尔会把 tool calls 以 XML 标签形式塞进文本流 (官方叫 DSML),而不是走标准 JSON tool_calls 字段。
DSML 标签可能被 SSE 切碎,一半在前一个 chunk 一半在后一个,还要跟正常文本交错出现。解决方案是一个 DsmlAccumulator 状态机:每个 chunk 的原始文本先喂给它,它吐出 (clean_text, parsed_tool_calls),TUI 层只消费纯净文本,DSML 脏活全被 accumulator 挡掉了。reasoning_content 流也需要一份独立的 accumulator,两条流互不干扰。
rust
// 收到的每个 token 立刻追加到显示缓冲区
while let Some(chunk) = stream.next().await {
match chunk {
StreamChunk::Content(text) => {
full_response.push_str(&text);
// 立即标记 UI 需要重绘
app.needs_redraw = true;
}
}
}斜杠命令系统
/plan、/clear、/thinking、/exec 等命令通过统一的 dispatch 路由,支持 Tab 补全和 ↑↓ 历史浏览。实际上就是一个 HashMap<&str, CommandHandler> 注册表。AI根据任务难度自动判断使用deepseek-v4-flash或deepseek-v4-pro模型。
上下文压缩
对话长了以后 token 数会爆炸。解决方案:
erlang
消息累积 → 达到 800k tokens(1M*80%) → 用 Flash 模型压缩 → 替换为摘要二、CLI Pipe-Command & 子代理
定位
CLI 模式有两个角色:好用的 Pipe-Command 和 高级AI的二五仔。
作为 Pipe-Command,它可以直接当 grep、jq 那样的管道命令用------输入 pipe 进去,处理完输出结果。不需要 LLM 介入的时候,前缀 ! 就是一条普通 shell 命令:
bash
# 管道传数据,不经过 LLM,纯命令执行
cat app.log | arcc cli --json "!wc -l"
# 用 LLM 分析管道数据
cat app.log | arcc cli --json "找出错误模式并统计频率"通过 skill 将 arcc 作为子代理,DeepSeek-V4-Flash 的价格大约是 Claude 的 1/50,适合干「执行命令 + 初步分析」这种 token 密集型脏活。
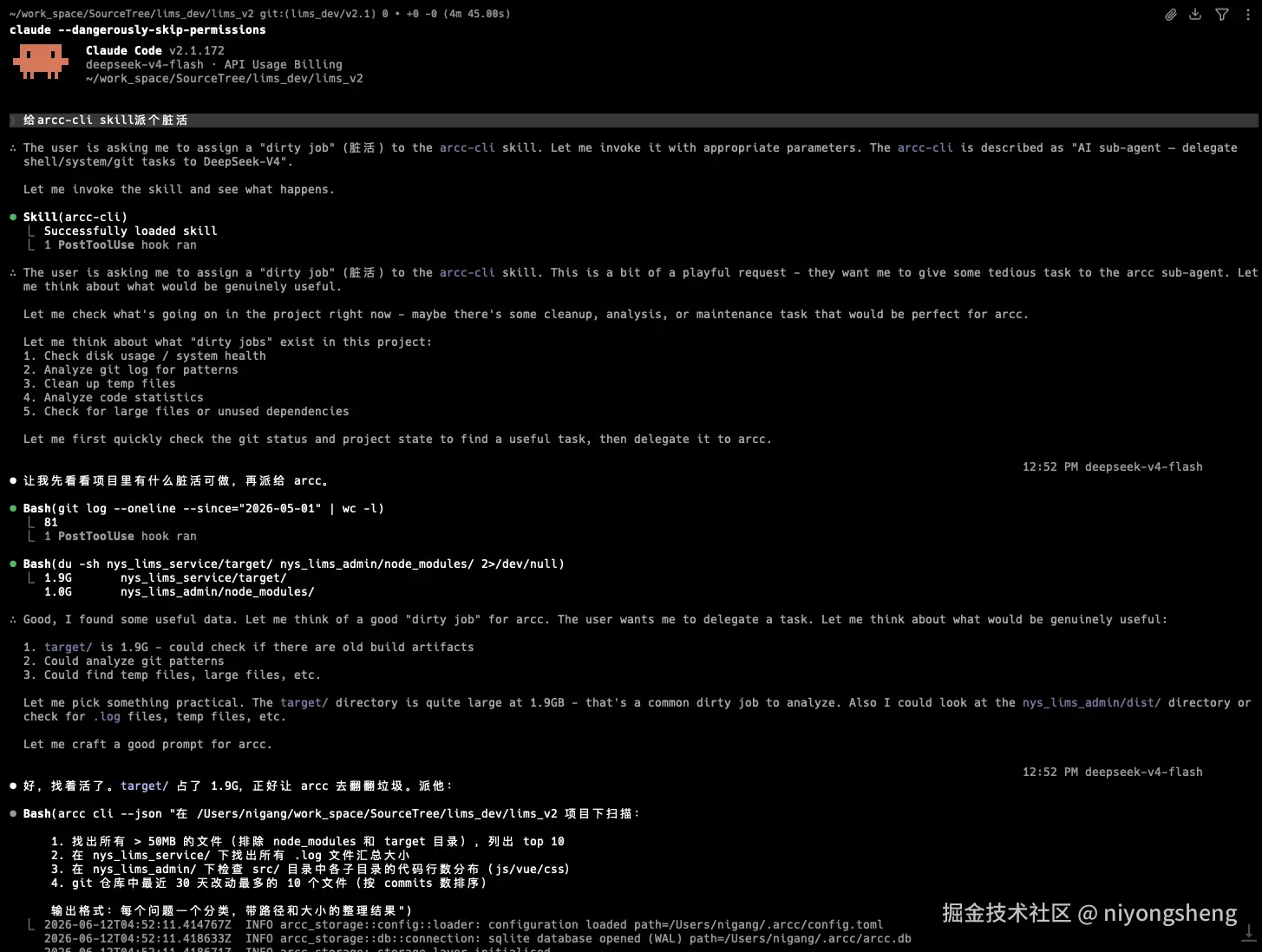
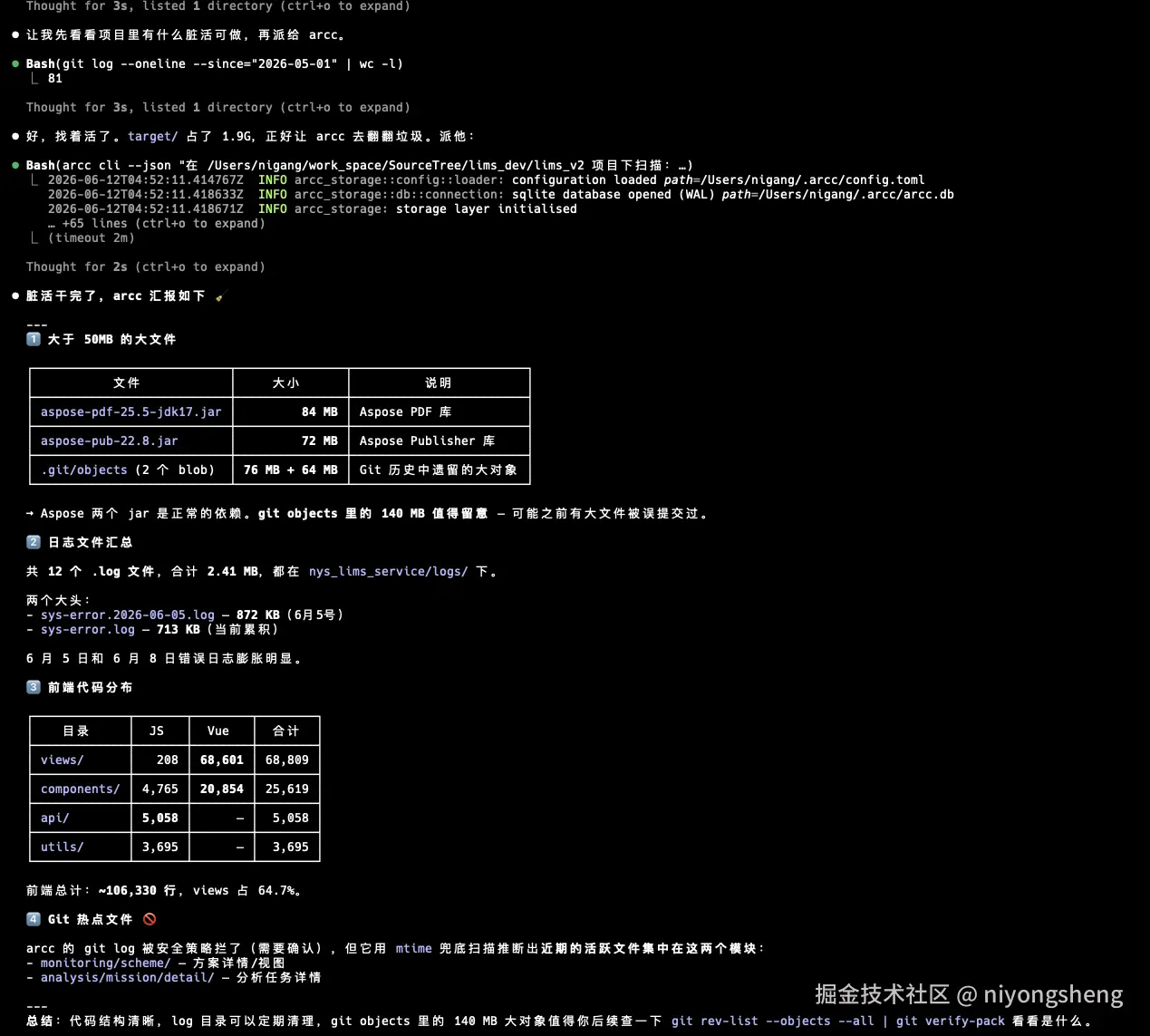
两阶段工具调用
CLI 模式的执行循环分为两个 phase:
Phase 1(有工具):
LLM 收到用户问题 → 可以调用 execute_command → 执行命令 → 把结果给 LLM
Phase 2(无工具):
LLM 根据工具结果 → 整理最终回复 → 返回给用户为什么要分两个 phase? 因为 DeepSeek API 要求:带 tool_calls 的 assistant 消息后必须紧跟 tool 角色消息。如果让 LLM 在一个响应里既返回文字又调工具,消息顺序会乱。
portable-pty 命令执行
命令执行使用 portable-pty 创建伪终端(这点在tui下体验更顺畅),而不是简单的 std::process::Command。原因是某些命令(sudo、ssh)需要 TTY 才能工作。
rust
let pty_system = NativePtySystem::default();
let pair = pty_system.openpty(PtySize { rows: 24, cols: 120, .. })?;
// ... spawn command in PTY, capture output难点 :PTY 模式下 sudo 仍需用户输入密码。当 CLI 被 MCP 调用时,没有真人输密码,sudo 命令会卡死。解决方案:
- AI 优先尝试
sudo -n(非交互模式) - 失败后提示用户配置
sudoers NOPASSWD给特定命令
--json 输出设计
为了让 Claude 等 AI Agent 能程序化消费结果,CLI 模式设计了结构化 JSON 输出:
json
{
"response": "磁盘 47%,最大目录 /home (23G)",
"tool_calls": [
{ "command": "df -h", "stdout": "...", "exit_code": 0 },
{ "command": "du -sh /home/*", "stdout": "...", "exit_code": 0 }
],
"status": "ok"
}正常模式是流式输出,--json 模式是收集完整结果后一次输出(适合Agent场景 AI 解析)。
MCP 集成 / Skill
ARCC CLI 可以注册为 Claude Code 的 Skill 。注册后在 /skills 里就会出现 arcc(prompt, unsafe?),对话中随时可以调用:
json
{
"mcpServers": {
"arcc": {
"type": "stdio",
"command": "/path/to/arcc-mcp",
"args": []
}
}
}如果你的 Claude 用的是高级付费模型,批量 grep、日志分析、文件扫描时 token 消耗很大,这些体力活可以丢给 arcc 省下 token 做高层的代码推理,arcc 跑完直接返回结果。!command 前缀还能跳过 LLM 当纯远程命令执行器用。
详细的使用策略(什么时候该用、prompt 怎么写)在 docs/skills/arcc-cli.md
三、Server 类龙虾工具:7×24运维助手
Server 模式要把 LLM、工具调用、飞书、定时任务、记忆系统全串起来。
记忆系统
每次对话完成后,后台会异步跑一个 Flash 模型,从 User: xxx / Assistant: xxx 对话中提取关键事实:
makefile
输入:「我叫张三,主要写 Rust 后端」
输出:user-role: backend developer
preferred-language: Rust提取结果存入 SQLite memories 表(UNIQUE(user_id, key)),下次对话时以 ## Known Facts 形式注入 system prompt:
markdown
## Known Facts
- name: 张三
- user-role: backend developer
- preferred-language: Rust为什么要用 LLM 提取而不是直接存原文? 因为对话里大部分信息(问候、代码片段、错误消息)是不需要记住的。用一个专门的 memory_extract.md 提示词让 LLM 判断「哪些值得记」,输出格式化为 key: value 行,或者 NO_NEW_FACTS 跳过。
设计取舍:
- 只提取显式事实,不推断不脑补
- 失败不阻断主流程------提取是
tokio::spawn后台任务,挂了只 warn 不抛错 - 私聊按
chat_id隔离,群聊按open_id隔离,每人独立记忆
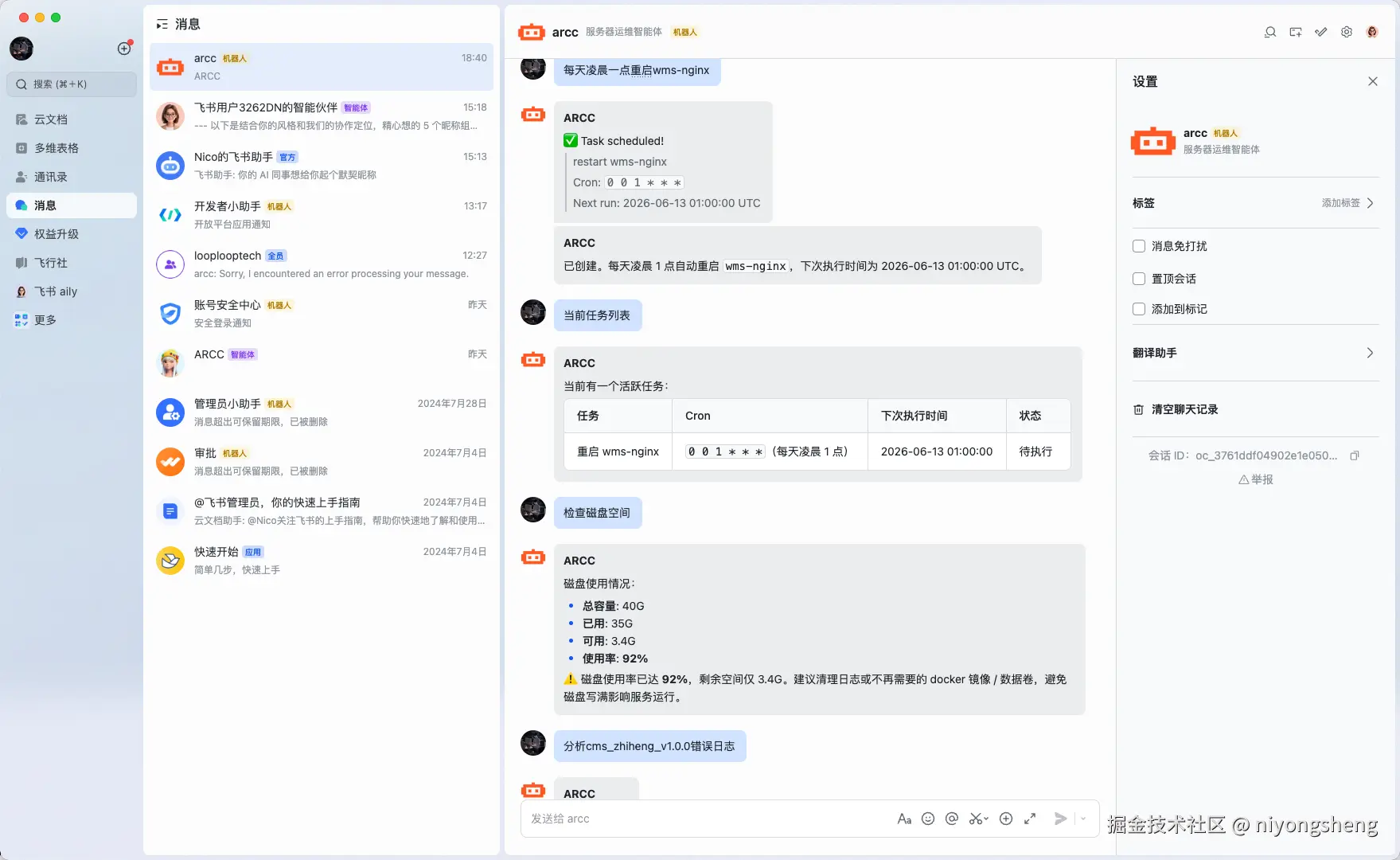
定时任务:复用完整的 LLM 执行管道
定时任务的实现没有写一个专门的「定时执行器」,而是复用了飞书消息处理的完整流程。
arduino
用户:「每天凌晨1点重启nginx」
→ AI 调 schedule_task(cron="0 1 * * * *", task="重启 nginx 服务")
→ 写入 SQLite scheduled_tasks 表
后台 scheduler 每 10 秒轮询:
到期 → 标记 running
→ 调 process_feishu_chat(ctx, chat_id, chat_type, open_id, "", "重启 nginx 服务")
(和用户发消息走同一个函数!)
→ LLM 重新思考 → 执行命令 → reply_to_user 报进度 → 发最终结果
→ 计算下次时间 / 标记完成技术栈速览
| 层 | 技术 | 选择理由 |
|---|---|---|
| 语言 | Rust 2024 edition | 性能、安全、生态------TUI 需要 ~60fps,CLI 需要快速启动,Server 需要 7x24 稳定 |
| 推理底座 | DeepSeek-V4 Pro + Flash | 双模型调度:Pro 复杂推理,Flash 高频对话。1M 上下文窗口,支持 tool calling |
| 异步运行时 | tokio(多线程) | Rust 最成熟的异步运行时,整个项目只有 2 个 .sync() 调用 |
| TUI | ratatui 0.29 + crossterm 0.28 | Rust TUI 的事实标准,即时模式渲染,无运行时依赖 |
| HTTP | axum 0.8 | 类型安全的路由 + extractor,和 tokio/tower 深度集成 |
| CLI PTY | portable-pty | 跨平台伪终端,支持 macOS/Linux/Windows |
| 持久化 | SQLite (bundled) + TOML + JSONL | 三个文件零外部依赖------数据库、配置、审计日志 |
| 日志 | tracing + tracing-appender | 结构化日志 + 每日轮转,server 模式写文件 + stderr 双通道 |
| Token 计数 | tiktoken-rs | OpenAI 兼容的 o200k_base BPE 编码 |
| 命令行 | clap(derive) | Rust CLI 的事实标准,派生宏定义参数 |
设计原则
I/O 隔离:
所有同步阻塞操作(文件读写、密集 CPU 计算)通过 tokio::task::spawn_blocking 或 block_in_place 投递,禁止在异步 Runtime 线程中直接运行可能阻塞的操作。
持久化三层:
| 数据层 | 技术 | 外部依赖 |
|---|---|---|
| 配置 | TOML | 无 |
| 会话 + 记忆 + 定时任务 | SQLite(bundled) | 无 |
| 审计 | JSON Lines | 无 |
| 指标 | 内存 + Prometheus scrape | 无 |
安全三层防线:
- 风险评级(
rm/shutdown等高危操作需确认) - TUI 交互式确认(y/a/n)
- serde 强类型二次校验防 LLM 注入 | Token 计数 | tiktoken-rs | OpenAI 兼容 |
最后:求一个Star⭐️
ARCC 使用 Rust 编写,原生性能碾压脚本语言、MIT开源,你可以很方便的将其嵌入你的任务、项目、工作流。 如果你也对手搓Agent感兴趣,👏🏻欢迎来Fork、提Issues|PR: github.com/niyongsheng...