前言
不知道有没有小伙伴遇到过这样的场景:老板让你用AI分析一份50页的PDF年报,你把文件直接扔给大模型,结果模型要么报错文件太大,要么只提取出零散的几段文字,关键数据全丢了。
更让人头疼的是,当你的知识库里有PDF合同、Word文档、PPT课件、Excel报表、图片截图、会议录音......各种格式五花八门,想把它们喂给AI做RAG检索,光是格式转换就得折腾半天。
这就是当下大模型应用开发中最常见的一个痛点:数据格式的多样性已经成为AI应用扩展的最大瓶颈。
而就在前几天,微软开源的一款工具MarkItDown再次引爆了技术圈。
GitHub数据显示,MarkItDown在2026年6月1日单日增长243颗星,6月4日单日增长更是高达2000+颗星,Star总数已突破15万,连续多日霸榜GitHub Trending。
许多小伙伴在工作中可能已经听说了这个工具,但未必真正了解它有多强大。
今天这篇文章,就专门跟大家一起聊聊这个话题,希望对你会有所帮助。
更多项目实战在我的技术网站:susan.net.cn/project
一、为什么我们需要MarkItDown?
在深入讲解之前,先来聊聊核心问题:大模型和各类文档之间,到底隔着什么?
我们看一个典型的场景。
假设你是一名RAG系统的开发者,需要做一个内部知识库检索系统。
公司的知识资产分布如下:
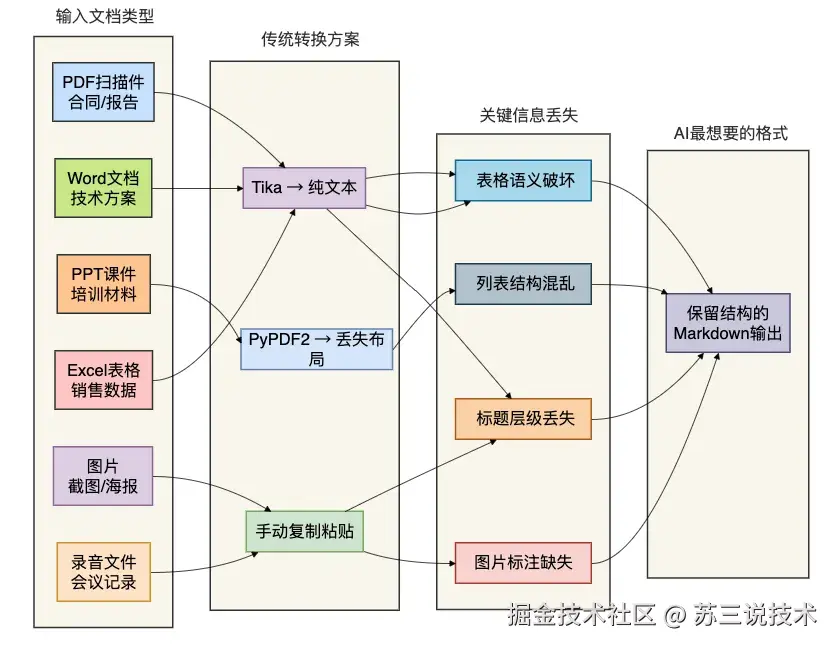
传统方案的痛点:
第一,格式兼容性差。
超过78%的企业文档仍以PDF、PPTX、DOCX等封闭格式存储,这些格式虽然保证了视觉呈现的一致性,却给后续的文本分析、知识库构建和AI训练带来了巨大的障碍。不同厂商的文档格式存在细微差异,转换后经常出现乱码、排版错乱。
第二,语义丢失严重。
复杂文档中的表格、图表、公式等元素在转换过程中往往丢失关键信息。某行业头部企业曾尝试使用某商业工具处理50万份技术文档,结果有32%的文档出现了格式异常,表格数据的转换准确率不足65%。
第三,处理效率低下。
传统方案往往依赖商业软件或定制化开发,成本高、扩展性差。批量处理千页级文档时,内存占用和CPU消耗呈指数级增长。
而MarkItDown正是为解决这一系列痛点而生的"瑞士军刀"。
它是一款轻量级的Python工具,专门将各种文件格式(PDF、Word、Excel、PPT、图片、音频等)统一转换为大模型最"爱吃"的Markdown格式,同时保留关键的文档结构信息(包括:标题、列表、表格、链接等)。
大模型为什么对Markdown有天然的亲和力?Markdown格式保留了文档结构(标题层级、列表、表格、链接),又足够轻量,没有多余的格式标记。对于需要理解文档语义的AI来说,这是最理想的输入格式。相比之下,纯文本丢失了结构信息,HTML又太臃肿,Markdown刚好在中间找到了完美的平衡点。
二、MarkItDown是什么?
MarkItDown由微软AutoGen团队开发并开源,已在GitHub上累计超过14.2万颗星,Fork超过9000次,贡献者达到78人。
项目采用MIT许可证,对商业使用非常友好。
一句话定位:微软AutoGen团队出品的"文件→Markdown"转换器,专为LLM数据预处理设计。
MarkItDown解决的痛点非常具体:在LLM时代,喂给模型的数据素材常常是PDF、Word、PPT、Excel、图片、音频、YouTube链接,而模型更擅长读"接近纯文本又保留结构"的Markdown。
它的目标用户是RAG / Agent / 文档问答的开发者,不是传统的文档排版工具,而是一个轻量级的文档预处理工具。
支持的格式涵盖了日常工作中的几乎所有文档类型:
| 类别 | 具体格式 |
|---|---|
| 办公文档 | PDF、Word(DOCX)、PowerPoint(PPTX)、Excel(XLSX/XLS) |
| 图片 | JPG、PNG(支持OCR和EXIF提取) |
| 音频 | MP3、WAV(支持语音转文字) |
| 网页内容 | HTML、直接URL |
| 数据格式 | CSV、JSON、XML |
| 其他 | ZIP压缩包、Outlook邮件(MSG)、YouTube视频链接、EPUB电子书 |
三、快速上手:一行命令搞定安装
安装前需要Python 3.10或更高版本。
建议先创建虚拟环境避免依赖冲突:
bash
体验AI代码助手
代码解读
复制代码
# 创建并激活虚拟环境 python -m venv .venv source .venv/bin/activate # Linux/Mac .venv\Scripts\activate # Windows
最便捷的安装方式是一行命令安装全部依赖:
bash
体验AI代码助手
代码解读
复制代码
pip install 'markitdown[all]'
如果只需要特定格式的支持,也可以按需安装,这样可以减少不必要的依赖包:
bash
体验AI代码助手
代码解读
复制代码
# 只安装PDF、Word、PPT的支持 pip install 'markitdown[pdf,docx,pptx]'
目前可选的依赖项包括[all]、[pptx]、[docx]、[xlsx]、[pdf]、[audio-transcription]、[youtube-transcription]等,支持灵活选择。
命令行使用非常简洁:
bash
体验AI代码助手
代码解读
复制代码
# 基本用法:转换文件并输出到指定位置 markitdown 报告.pdf -o 报告.md # 或使用重定向 cat 报告.pdf | markitdown > 报告.md
在Python代码中调用也同样简单:
python
体验AI代码助手
代码解读
复制代码
from markitdown import MarkItDown md = MarkItDown() result = md.convert("report.pdf") print(result.text_content)
批量处理时,几行代码就能搞定几十份文件:
python
体验AI代码助手
代码解读
复制代码
from markitdown import MarkItDown from pathlib import Path md = MarkItDown() for file in Path("docs").glob("*.pdf"): result = md.convert(str(file)) Path(f"output/{file.stem}.md").write_text(result.text_content)
四、底层原理深度剖析
很多小伙伴可能好奇:MarkItDown是如何做到智能识别文件格式,并自动调用对应的解析器的?
这个问题的答案藏在它的三层架构设计中。
下面是MarkItDown的核心架构图,帮助大家理解整个转换流程:

下面来逐个层次拆解。
4.1 第一层:格式识别层
它让AI知道"这是什么文件"。
这一层的核心任务是准确判断输入文件的类型。传统方案可能只看文件名后缀,但后缀是可以伪造的,比如把PDF文件.jpg重命名为photo.jpg后上传。
MarkItDown采用三级递进式识别策略:
第一级:扩展名识别。 系统首先检查文件名的扩展名,这是最快的方式。
第二级:MIME类型检测。 如果扩展名识别失败或存在疑点,系统会读取文件的二进制头部(文件签名),根据标准格式的特征字节来判断MIME类型。
第三级:Magika深度学习分类器。 当扩展名和MIME类型都无法确定时------这是最复杂的场景,MarkItDown会调用Google的Magika工具。Magika是一种基于深度学习的字节级内容分类器,能够通过分析文件实际内容的统计特征来判断格式,准确率极高。拿到识别的mimetype后,系统会与前两步的猜测结果进行兼容性比对,如果存在不一致,就把Magika的猜测也作为候选加入,多个猜测依次喂给转换器链处理。
这种设计把"格式猜测+格式分发"解耦成两个独立层,使得第三方开发者添加新的转换器时,完全不需要碰Magika的底层代码。
4.2 第二层:转换器调度层
它是优先级路由系统。
MarkItDown的核心竞争力在于其基于优先级的智能转换器调度系统。MarkItDown类内部维护着一张按优先级排序的转换器注册表,每次转换调用时会动态计算并重新排序。
调度机制的设计基于一个核心原则:越精准的转换器优先级越高。
- 优先级0.0:专门为PDF、DOCX等专有格式设计的特定格式转换器,如_pdf_converter.py和_docx_converter.py
- 优先级10.0:处理纯文本、HTML等通用格式的通用格式转换器,如_plain_text_converter.py和_html_converter.py
当系统遇到未知格式的文件时,会自动触发"格式探测-转换器匹配-降级处理"的三级验证流程。
如果任何一种内置转换器都无法处理,系统会进入降级模式,尽最大努力返回基础文本内容,而不是直接失败。
4.3 第三层:转换执行层
18个内置转换器齐上阵。
MarkItDown在__init__阶段默认一次性注册了18个内置转换器:
css
体验AI代码助手
代码解读
复制代码
PlainText → Zip → Html → Rss → Wikipedia → YouTube → BingSerp → Docx → Xlsx → Xls → Pptx → Audio → Image → Ipynb → Pdf → OutlookMsg → Epub → Csv
一个非常巧妙的设计是:convert()方法会自动根据入参类型分流:
| 入参类型 | 处理策略 |
|---|---|
str |
URL和本地路径二选一自动判断 |
Path |
直接走本地文件 |
requests.Response |
从响应体读取 |
有.read()方法的对象 |
走流式处理 |
这意味着同一套逻辑同时服务于CLI、Python API、HTTP URL、内存二进制流,用户完全不需要操心应该调用哪个API。
五、进阶功能
MarkItDown的强大之处不仅在于格式转换,还在于它对AI能力的深度融合。
5.1 图像AI描述
配合视觉大模型(如GPT-4o),MarkItDown可以自动为文档中的图片生成语义描述,让原本AI"看不懂"的图片内容也能被理解和索引。
5.2 OCR文字识别
通过集成Azure Document Intelligence,MarkItDown可以从扫描件PDF或图片中精确提取文字。如果你配置了Azure的DocIntel服务,还能实现更高质量的企业级文档分析。
5.3 MCP协议原生支持
MarkItDown原生支持Model Context Protocol,可以直接挂载到Claude Desktop或其他支持MCP的AI工具上使用。项目中自带markitdown-mcp插件,可以将convert_to_markdown(uri)功能暴露为标准MCP工具,支持STDIO、Streamable HTTP、SSE三种传输协议。
此外,基于entry_points的官方插件机制,允许开发者通过标准Python入口点扩展自定义转换逻辑。
插件加载时如果出现异常只会输出警告而不会中断主流程,保证了整体的鲁棒性。
六、优缺点与使用建议
6.1 优点
1. 开发效率极高。 一行命令完成20+种格式的统一转换,相比传统方案的适配成本------针对不同格式分别写代码,用不同的库、不同的逻辑------工作量减少80%以上。
2. LLM天然友好。 直接输出Markdown格式,标题层级、列表、表格语义清晰,Token效率极高,相比直接喂原文件可节省高达80%的Token消耗。
3. 格式覆盖广。 覆盖PDF、DOCX、PPTX、XLSX、图片、音频、YouTube等主流办公和多媒体格式,基本覆盖日常工作中的所有文档类型。
4. 架构灵活,可扩展。 插件式架构让开发者可以按需安装依赖,也可以自己写插件扩展新的格式支持。基于优先级的转换器调度系统确保最佳格式适配。
5. 微软官方维护。 微软AutoGen团队出品,更新活跃,有完善的社区支持和持续迭代。
6.2 缺点
没有完美的工具,MarkItDown也有一些需要注意的地方。
局限一:内嵌图片处理方式。 对于图片,MarkItDown只能生成这种内嵌方式,所有图片都以Base64编码嵌入Markdown中,导致文件体积膨胀2-4倍。图片没有与文档分离的做法对于版本管理很不友好。
局限二:结构化还原精度有限。 MarkItDown的核心定位是"为LLM优化的文档结构化提取工具",而非追求视觉还原的排版转换器。它会优先保留对AI理解至关重要的信息(标题层级、列表结构、表格语义),但不会保留字体、颜色、页眉页脚等视觉元素。
局限三:复杂格式处理效果不稳定。 根据实测数据,普通文档转换效果较好,但PPT、Excel复杂表格、双栏论文、扫描版PDF的效果会明显受结构复杂度影响。
局限四:AI增强功能需要额外成本。 扫描件和音频的处理需要OCR/ASR服务,这些往往需要调用云端API或配置本地模型,会产生额外的成本。
局限五:处理速度一般。 根据性能测试数据,基于Python的MarkItDown处理速度约为Rust实现的undocx的约1/5.5,在处理大规模文档批量化任务时,性能可能是瓶颈。
6.3 竞品横向对比
为了帮大家更好地做选型,这里做一个横向对比分析:
| 对比维度 | MarkItDown | Pandoc | Marker | textract |
|---|---|---|---|---|
| 主要定位 | AI数据预处理 | 通用文档转换 | PDF高保真提取 | 纯文本抽取 |
| 输入格式广度 | 20+种 | 40+种 | 仅PDF为主 | 较广 |
| 输出格式 | 仅Markdown | 40+种 | Markdown/HTML | 纯文本 |
| 结构保留能力 | 较强(标题/列表/表格) | 强(排版/引用/数学公式) | 极强(保真布局) | 弱 |
| LLM友好度 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ | ⭐ |
| 实现语言 | Python | Haskell | Python | Python |
| 学习成本 | 低 | 中等 | 中高 | 低 |
选型建议:
- MarkItDown适合RAG/Agent/文档问答的LLM预处理场景
- Pandoc适合有双向转换需求(Markdown→PDF/Word),需要保留完整排版的场景
- Marker适合需要对复杂PDF(双栏、扫描件)进行高保真转换的场景
- textract适合只需要快速抽取纯文本、不关心结构信息的场景
6.4 适用场景总结
| 场景 | 是否推荐 | 核心价值 |
|---|---|---|
| RAG知识库构建 | ✅ 强烈推荐 | 批量文档转Markdown后导入向量数据库,检索准确率显著提升 |
| LLM训练数据预处理 | ✅ 强烈推荐 | 将PDF论文、PPT课件等自动构建训练数据集,Token效率高 |
| 企业内部文档智能处理 | ✅ 推荐 | 批量提取合同、研究报告等非结构化文档的内容 |
| 个人知识管理与笔记 | ✅ 推荐 | 快速将阅读材料转为纯文本,便于笔记整理 |
| AI Agent工作流集成 | ✅ 推荐 | 作为Agent的前置处理步骤,让Agent能"阅读"任何格式的文件 |
| 高保真PDF排版还原 | ❌ 不推荐 | 视觉还原非其设计目标,建议选择Marker或Pandoc |
| 双向文档格式互转 | ❌ 不推荐 | 只能单向转Markdown,建议选择Pandoc |
七、实战案例
许多小伙伴在工作中可能正在开发RAG系统,下面用一个完整示例展示如何用MarkItDown构建知识库预处理Pipeline:
python
体验AI代码助手
代码解读
复制代码
import os from pathlib import Path from typing import List, Dict from markitdown import MarkItDown import chromadb # 向量数据库 class MarkItDownRAGPipeline: """基于MarkItDown的RAG预处理流水线""" def __init__(self, collection_name: str = "knowledge_base"): self.md = MarkItDown() self.client = chromadb.Client() self.collection = self.client.get_or_create_collection(collection_name) self.processed = set() def process_document(self, file_path: str) -> Dict: """处理单个文档并生成向量存储项""" try: result = self.md.convert(file_path) doc_id = Path(file_path).stem return { "id": doc_id, "text": result.text_content, "metadata": { "source": file_path, "char_count": len(result.text_content), "headings": self._extract_headings(result.text_content) } } except Exception as e: print(f"处理失败 {file_path}: {e}") return None def _extract_headings(self, markdown_text: str) -> List[str]: """提取Markdown中的所有标题,用于增强检索""" import re return re.findall(r'^#{1,6}\s+(.+)$', markdown_text, re.MULTILINE) def batch_process(self, directory: str, extensions: List[str] = None): """批量处理整个目录""" extensions = extensions or ['pdf', 'docx', 'pptx', 'xlsx', 'md'] docs = [] for ext in extensions: for file_path in Path(directory).glob(f"*.{ext}"): if str(file_path) not in self.processed: doc = self.process_document(str(file_path)) if doc: docs.append(doc) self.processed.add(str(file_path)) # 批量添加到向量库 if docs: self.collection.add( ids=[d["id"] for d in docs], documents=[d["text"] for d in docs], metadatas=[d["metadata"] for d in docs] ) print(f"✅ 成功处理 {len(docs)} 个文档") def search(self, query: str, top_k: int = 5) -> List[Dict]: """检索相关知识""" results = self.collection.query( query_texts=[query], n_results=top_k ) return results # 使用示例 pipeline = MarkItDownRAGPipeline() pipeline.batch_process("./company_docs") # 批量处理所有文档 # 检索示例 results = pipeline.search("2025年销售数据分析") for idx, result in enumerate(results['documents'][0]): print(f"{idx+1}. {result[:200]}...")
这个示例展示了MarkItDown在RAG管道中的完整应用:批量转换多格式文档为Markdown → 提取结构化内容 → 存入向量数据库 → 支持语义检索。
整个过程仅需几十行代码,就完成了原本需要多个工具配合才能实现的功能。
总结
MarkItDown的火爆绝非偶然。
截至2026年6月,MarkItDown的GitHub Star数已突破15万,6月第一周日均增长超过1000颗星。
这个数据背后反映的是一个深刻的行业趋势:当大模型的能力边界不断扩展时,"如何喂数据"已经成为AI应用落地的核心瓶颈,而MarkItDown正是微软对这个问题的优秀答卷。
总结一下MarkItDown的核心价值:
-
它是"格式鸿沟"的架桥者。 在企业数字化转型浪潮中,78%以上的文档仍以PDF、PPTX、DOCX等封闭格式存储,MarkItDown通过统一转换为Markdown,让所有文档资产都能被AI顺畅"阅读"。
-
它重新定义了"AI友好的文档转换"。 与Pandoc追求排版保真的理念不同,MarkItDown选择了一条截然不同的道路:为AI优化而非为人类排版。它保留标题层级、列表结构、表格语义,丢弃对AI无意义的视觉装饰。
-
它的大生态正在形成。 基于插件机制,已经出现了OCR增强插件、MarkItDown MCP Server(作为MCP Tool挂载到Claude桌面端)等生态组件。社区还提供了TypeScript版本的
markitdown-ts,适用于Serverless和边缘计算环境。
如果你正在做RAG系统、AI Agent或任何需要处理多格式文档的AI应用,MarkItDown绝对值得加入你的技术栈。
毕竟,能用一行代码解决的问题,为什么要写一百行呢?
如果觉得今天的分享对你有帮助,点个在看,转发给更多正在被文档格式问题困扰的小伙伴!也欢迎留言分享你用MarkItDown解决过的实际问题~