♻️ 资源
大小: 11.6MB
➡️ 资源下载: https://download.csdn.net/download/s1t16/87450295
使用 SVM 方法对数字进行分类训练和预测
一、总体方案
1.1 题目分析
设计一个 GUI 界面,可以用鼠标在界面上写数字,然后对所写的数字进行识别。使用 SVM 方法对数字进行分类训练和预测。
1.2 总体方案设计
进行一次手写数字的识别流程如下:

二、算法基本原理
支持向量机(SVM)是 90 年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。
支持向量是距离分类超平面近的那些点,SVM 的思想就是使得支持向量到分类超平面的间隔最大化。距离分类超平面近的那些点到该超平面的间隔最大化代表了该超平面对两类数据的区分度强,不容易出现错分的情况。如图 1 所示,支持向量到超平面 1 的间隔大于支持向量到超平面 2 的间隔,因此超平面 1 优于超平面 2。
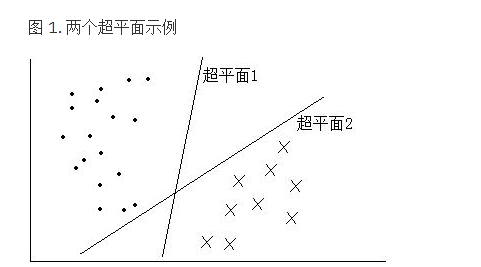
SVM 可以很好得解决二分类问题,对于多分类情况,就需要对模型进行改动。如 one-versus-rest 法,这种方法每次选择一个类别作为正样本,剩下其他类别作为负样本,假设一共有 3 个类别,这样相当于训练出了 3 个不同的 SVM。然后将测试数据分别带入 3 个 SVM 模型中,得到的 3 个结果中的最大值则为最终的分类结果。
三、系统实现
图像预处理------提取特征部分
function feature = FeatureBlock(img)
% 输入:
黑底白字的二值图像。输出:35维的网格特征
% ======提取特征,转成5*7的特征矢量,把图像中每10*10的点进行划分相加,进行相加成一个点=====%
%======即统计每个小区域中图像象素所占百分比作为特征数据====%
feature = blkproc(img,[4 4],'SumColor');
feature=reshape(feature,[1,49]);SVM 训练分类
主要包括提取预测和响应,训练分类器,设置保持验证,计算准确性。
具体实现如下:
提取预测和响应部分:
% Extract predictors and response
predictorNames = {'trainFeatures1', 'trainFeatures2', 'trainFeatures3', 'trainFeatures4', 'trainFeatures5', 'trainFeatures6', 'trainFeatures7', 'trainFeatures8', 'trainFeatures9', 'trainFeatures10', 'trainFeatures11', 'trainFeatures12', 'trainFeatures13', 'trainFeatures14', 'trainFeatures15', 'trainFeatures16', 'trainFeatures17', 'trainFeatures18', 'trainFeatures19', 'trainFeatures20', 'trainFeatures21', 'trainFeatures22', 'trainFeatures23', 'trainFeatures24', 'trainFeatures25', 'trainFeatures26', 'trainFeatures27', 'trainFeatures28', 'trainFeatures29', 'trainFeatures30', 'trainFeatures31', 'trainFeatures32', 'trainFeatures33', 'trainFeatures34', 'trainFeatures35', 'trainFeatures36', 'trainFeatures37', 'trainFeatures38', 'trainFeatures39', 'trainFeatures40', 'trainFeatures41', 'trainFeatures42', 'trainFeatures43', 'trainFeatures44', 'trainFeatures45', 'trainFeatures46', 'trainFeatures47', 'trainFeatures48', 'trainFeatures49'};
predictors = datasetTable(:,predictorNames);
predictors = table2array(varfun(@double, predictors));
response = datasetTable.number;
% Train a classifier
template = templateSVM('KernelFunction', 'polynomial', 'PolynomialOrder', 2, 'KernelScale', 'auto', 'BoxConstraint', 1, 'Standardize', 1);
trainedClassifier = fitcecoc(predictors, response, 'Learners', template, 'Coding', 'onevsone', 'PredictorNames', {'trainFeatures1' 'trainFeatures2' 'trainFeatures3' 'trainFeatures4' 'trainFeatures5' 'trainFeatures6' 'trainFeatures7' 'trainFeatures8' 'trainFeatures9' 'trainFeatures10' 'trainFeatures11' 'trainFeatures12' 'trainFeatures13' 'trainFeatures14' 'trainFeatures15' 'trainFeatures16' 'trainFeatures17' 'trainFeatures18' 'trainFeatures19' 'trainFeatures20' 'trainFeatures21' 'trainFeatures22' 'trainFeatures23' 'trainFeatures24' 'trainFeatures25' 'trainFeatures26' 'trainFeatures27' 'trainFeatures28' 'trainFeatures29' 'trainFeatures30' 'trainFeatures31' 'trainFeatures32' 'trainFeatures33' 'trainFeatures34' 'trainFeatures35' 'trainFeatures36' 'trainFeatures37' 'trainFeatures38' 'trainFeatures39' 'trainFeatures40' 'trainFeatures41' 'trainFeatures42' 'trainFeatures43' 'trainFeatures44' 'trainFeatures45' 'trainFeatures46' 'trainFeatures47' 'trainFeatures48' 'trainFeatures49'}, 'ResponseName', 'number', 'ClassNames', {'0' '1' '2' '3' '4' '5' '6' '7' '8' '9'});设置保持验证部分:
% Set up holdout validation
cvp = cvpartition(response, 'Holdout', 0.25);
trainingPredictors = predictors(cvp.training,:);
trainingResponse = response(cvp.training,:);训练分类器部分:
% Train a classifier
template = templateSVM('KernelFunction', 'polynomial', 'PolynomialOrder', 2, 'KernelScale', 'auto', 'BoxConstraint', 1, 'Standardize', 1);
validationModel = fitcecoc(trainingPredictors, trainingResponse, 'Learners', template, 'Coding', 'onevsone', 'PredictorNames', {'trainFeatures1' 'trainFeatures2' 'trainFeatures3' 'trainFeatures4' 'trainFeatures5' 'trainFeatures6' 'trainFeatures7' 'trainFeatures8' 'trainFeatures9' 'trainFeatures10' 'trainFeatures11' 'trainFeatures12' 'trainFeatures13' 'trainFeatures14' 'trainFeatures15' 'trainFeatures16' 'trainFeatures17' 'trainFeatures18' 'trainFeatures19' 'trainFeatures20' 'trainFeatures21' 'trainFeatures22' 'trainFeatures23' 'trainFeatures24' 'trainFeatures25' 'trainFeatures26' 'trainFeatures27' 'trainFeatures28' 'trainFeatures29' 'trainFeatures30' 'trainFeatures31' 'trainFeatures32' 'trainFeatures33' 'trainFeatures34' 'trainFeatures35' 'trainFeatures36' 'trainFeatures37' 'trainFeatures38' 'trainFeatures39' 'trainFeatures40' 'trainFeatures41' 'trainFeatures42' 'trainFeatures43' 'trainFeatures44' 'trainFeatures45' 'trainFeatures46' 'trainFeatures47' 'trainFeatures48' 'trainFeatures49'}, 'ResponseName', 'number', 'ClassNames', {'0' '1' '2' '3' '4' '5' '6' '7' '8' '9'});计算准确性部分:
% Compute validation accuracy
validationPredictors = predictors(cvp.test,:);
validationResponse = response(cvp.test,:);
validationAccuracy = 1 - loss(validationModel, validationPredictors, validationResponse, 'LossFun', 'ClassifError');识别按钮响应部分
function pushbutton9_Callback(hObject, eventdata, handles)
% hObject handle to pushbutton9 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% M=evalin('base','QuadraticSVMSim');
% model=load('QuadraticSVM.mat');
% model=model.QuadraticSVMSim;
value=1;
str=[num2str(value),'.bmp'];
model=load('QuadraticSVM');
model=model.d;
h=getframe(handles.axes1);
img=rgb2gray(h.cdata);
img=imresize(img,[28,28]);
img=im2bw(img,0.95);
img=~img;
img=uint8(img*255);
feature2=FeatureBlock(img);
feature4=Quadruple(img);
feature=[feature2];
output=predict(model,feature);
set(handles.edit1,'string',output);
imwrite(img',str);四、结果记录及分析
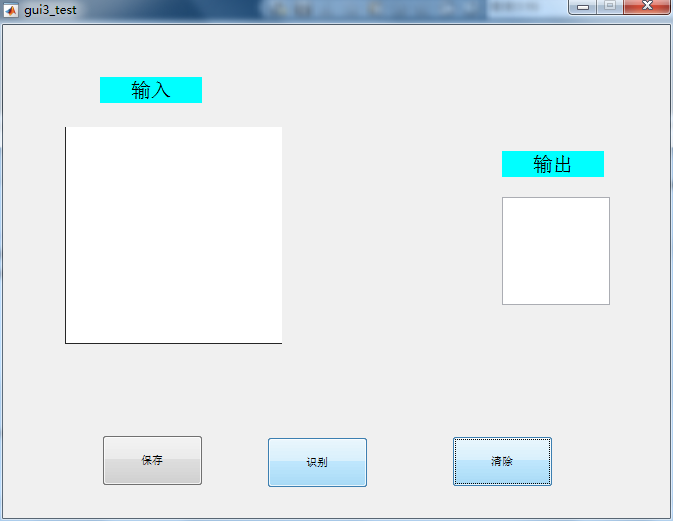
初始界面:
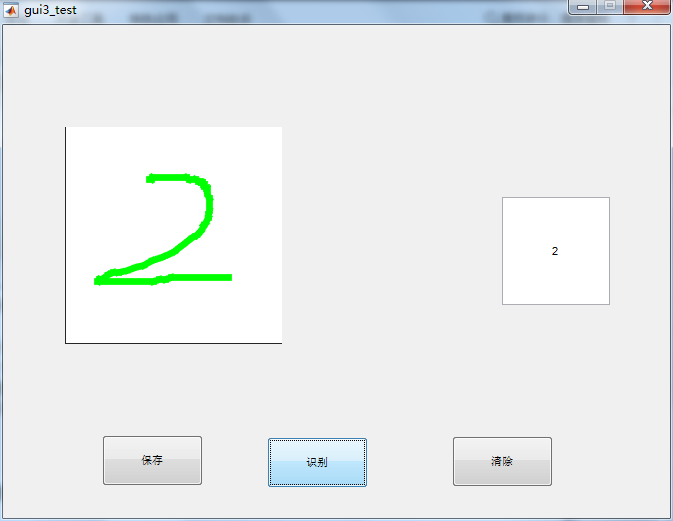
手写数字后识别界面:
支持向量到分类超平面的间隔最大化的思路得到的模型理论上是准确度最高的一种模型。但是调用 SVM 算法的测试准确度并不一定都很高。这其中有很多原因,比如数据预处理的效果、训练集的大小、特征值的选择、参数设置以及核函数的选择等因素。
五、课程设计收获及心得
在这次课程设计中,我用到了 MATLAB 的 GUI 编程,学习了 SVM 支持向量机这个机器学习算法,深入学习了划分超平面,目标函数学习的对偶算法,核函数软间隔与正则化这些概念,对机器学习有了更深入的了解和学习。
六、参考文献
蒙 庚 祥 , 方 景 龙 . 基 于 支 持 向 量 机 的 手 写 体 数 字 识 别 系 统 设 计 . 计 算 机 工 程 与 设计 , 2005 ( 26 ) . 6
Ne l l o Cr i s t i a ni ni ,John Sha we - Ta y l or . 支 持 向 量 机 导 论 . 北 京 工 业 出 版 社 ,200 4(3 ).1