主题方向:Agent 落地
从"读故事"到"经历故事"
最近两年,AI在内容生成领域的进化速度令人目眩。不仅能生成电影级视频,GPT-5级别的模型能写出长篇小说,各种AI写作工具把创作门槛打到了地板。但一个问题始终让我不满足:这些"创作"都是单向输出。
你让AI写一个故事,它噼里啪啦吐出几千字,你读完就完了。没有参与感,没有沉浸感,更没有"命运掌握在自己手里"的紧张感。
这让我想到一个方向:如果AI不只是写 故事,而是讲故事呢?如果它坐在你面前,用声音和表情带你进入一个世界,在每个关键节点让你做出选择,你的每一个决定都改变剧情走向------这会不会是一种全新的娱乐形态?
更重要的是:如果这个"讲故事的人"不是一个文字框,而是一个3D数字人------它会笑、会紧张、会压低声音说"小心,前面有危险"------这种体验和读文字能一样吗?
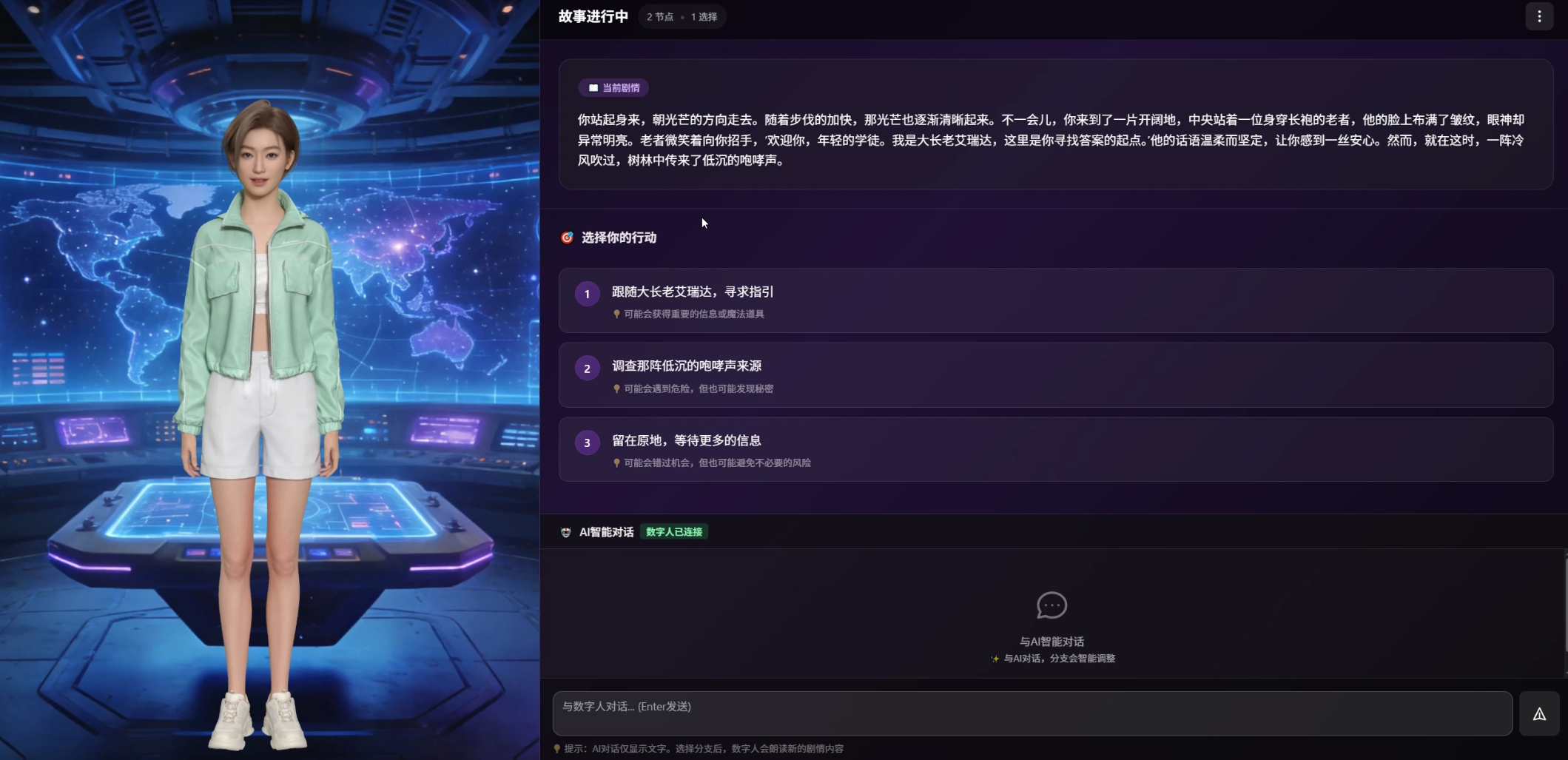
带着这个想法,我开始了一个实验:用魔珐星云的具身智能数字人平台,搭一个AI互动叙事Agent。**它不只是单方面"讲故事"------你可以在关键节点选择剧情走向,也可以随时自由对话影响数字人的讲述内容和表演方式。你的每一次输入,都会改变接下来的故事走向和数字人的情绪表现,一切围绕交互------让用户从"听故事的人"变成"创造故事的人"。**这篇文章记录了整个过程中的技术思考和实践心得。
魔珐星云::魔珐星云官网
一、文字Agent的交互天花板
做这个项目之前,我认真梳理了一下当前AI Agent在交互层面的瓶颈。不讨论模型能力,只讨论交互形态。
1.1 文字交互的"信息密度陷阱"
文字是一种低信息密度媒介。一句话"他推开门,看到了一个令人震惊的场景",读者需要自己脑补画面、情绪、氛围。这在读小说的时候没问题,因为小说的价值恰恰在于激发想象。但在互动场景中,这就成了障碍------用户的注意力在"阅读文字"和"做出选择"之间反复切换,很难保持沉浸感。
更致命的是,纯文字无法传递语气和情绪。同样一句"你确定要打开那扇门吗?",用平静的语气说和在诡异的低语中说,传递的信息完全不同。文字Agent做不到这种区分。
1.2 语音交互的"单一通道局限"
加个TTS变成语音Agent呢?好一些,但还不够。语音只有听觉通道,没有视觉反馈。用户在听故事的时候,眼睛无处安放------盯着一个空白聊天框?看滚动字幕?这和听有声书没什么本质区别,依然缺少"在场感"。
1.3 传统数字人的"视频流陷阱"
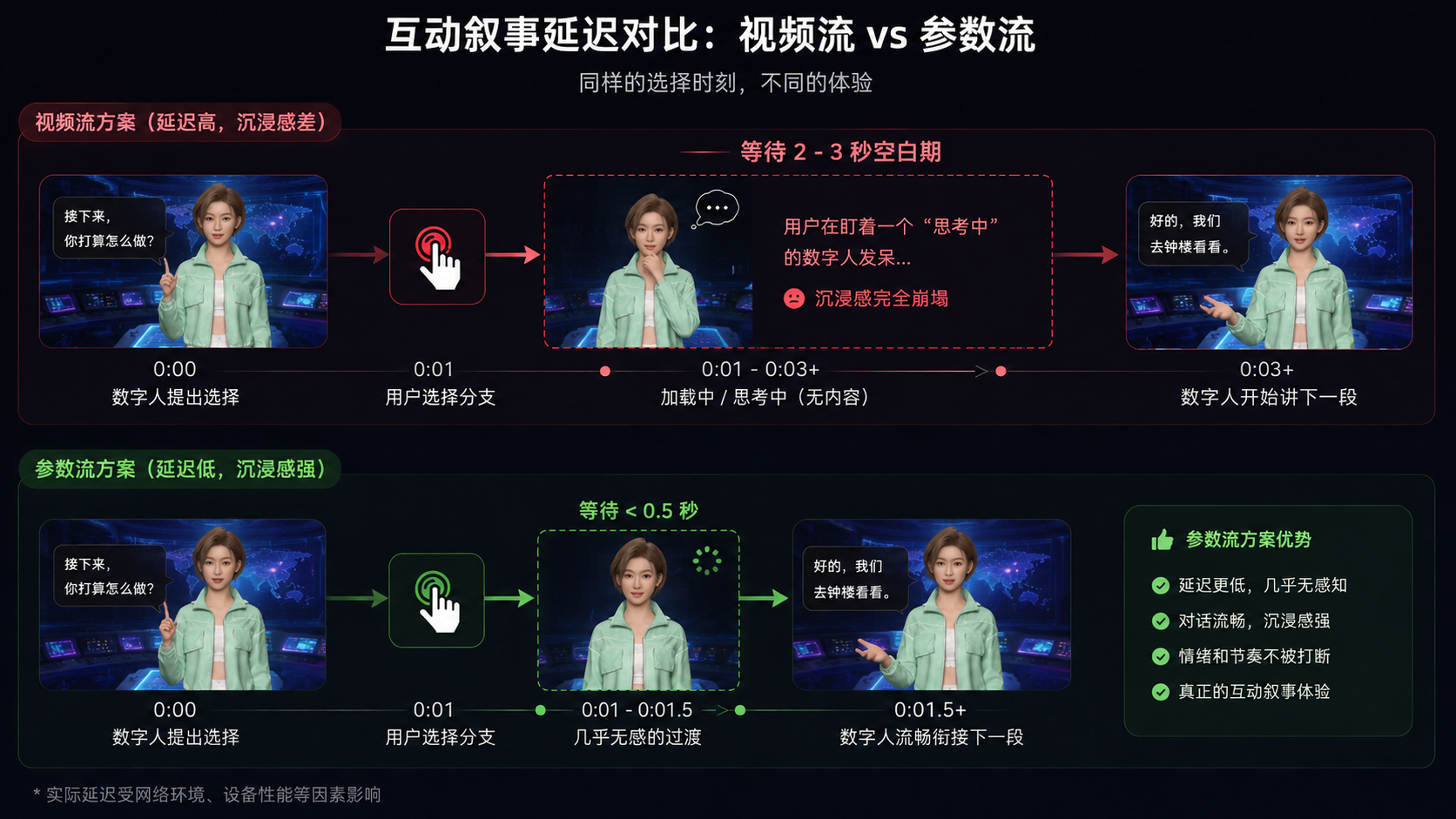
那加个3D数字人不就好了?问题没那么简单。市面上大部分数字人产品采用云端渲染+视频流推送的方案。数字人确实"看得见"了,但交互体验反而更差了------
- 用户选了一个分支,要等2-3秒数字人才开始讲故事(视频编码+传输+解码的延迟)
- 带宽成本随用户数线性增长,一个互动叙事场景动辄十几分钟的会话时长,费用让人头皮发麻
- 表情动作僵硬,每次都是同样的"微笑+挥手"预设,讲恐怖故事也在微笑
这不是某个产品的实现问题,而是视频流架构的根本缺陷。视频流的本质是把一个动态画面压缩成一串图像帧,这个编码-传输-解码的过程不可避免地引入延迟,而且带宽消耗跟画质直接挂钩------你要高清就得加带宽,要低延迟就得降画质。
二、单点拼接为什么不work
看到这里,很多人可能会想:那我分别把LLM、TTS、3D渲染做到最好,再用API串起来不就行了?
这条路我也走过。结论是:单点最优不等于全局最优。
2.1 LLM的"语义盲区"
大模型生成文本的能力毋庸置疑,但它不知道自己的文字将要由一个数字人"说出来"。这意味着它不会在需要停顿的地方加标点,不会在需要强调的地方加重语气,更不会在需要配合手势的地方留出空间。
举个例子,LLM可能生成这样的文本:
"突然,一个黑影从角落里窜了出来!你往后退了一步,却发现身后也是一堵墙。"
如果只是阅读,这段文字很有画面感。但如果要由数字人说出来,你需要额外的信息:在"窜了出来"的时候数字人应该做出惊讶的表情,在"一堵墙"的时候语气应该变得紧张。LLM不提供这些信息------它只管生成文本。
2.2 TTS的"情感真空"
现代TTS在自然度上已经做得很好了,但大部分TTS是"情感扁平"的------它用同一种语气念完一整段话,不管是惊喜、恐惧还是平静。有的TTS支持SSML标记来调整语速和音调,但手动标注既低效又不精确。
2.3 渲染的"预设陷阱"
3D渲染引擎能做出逼真的数字人,但谁来驱动它的表情和动作?如果你用预设动画("说话时循环播放挥手"),用户三分钟就能识破。如果你用AI实时生成动作,又回到了延迟问题------生成动作参数本身就需要时间。
2.4 串行拼接的"延迟雪崩"
最致命的还是延迟。当LLM(500ms)→ TTS(300ms)→ 动作生成(200ms)→ 渲染(100ms)→ 网络传输(300ms)串行执行时,总延迟轻松超过1.4秒。在互动叙事场景中,这意味着用户选了一个分支后,要对着一个"正在思考"的数字人发呆两秒------沉浸感瞬间碎了一地。

三、换一条路:参数流+AI端渲和端侧解算技术
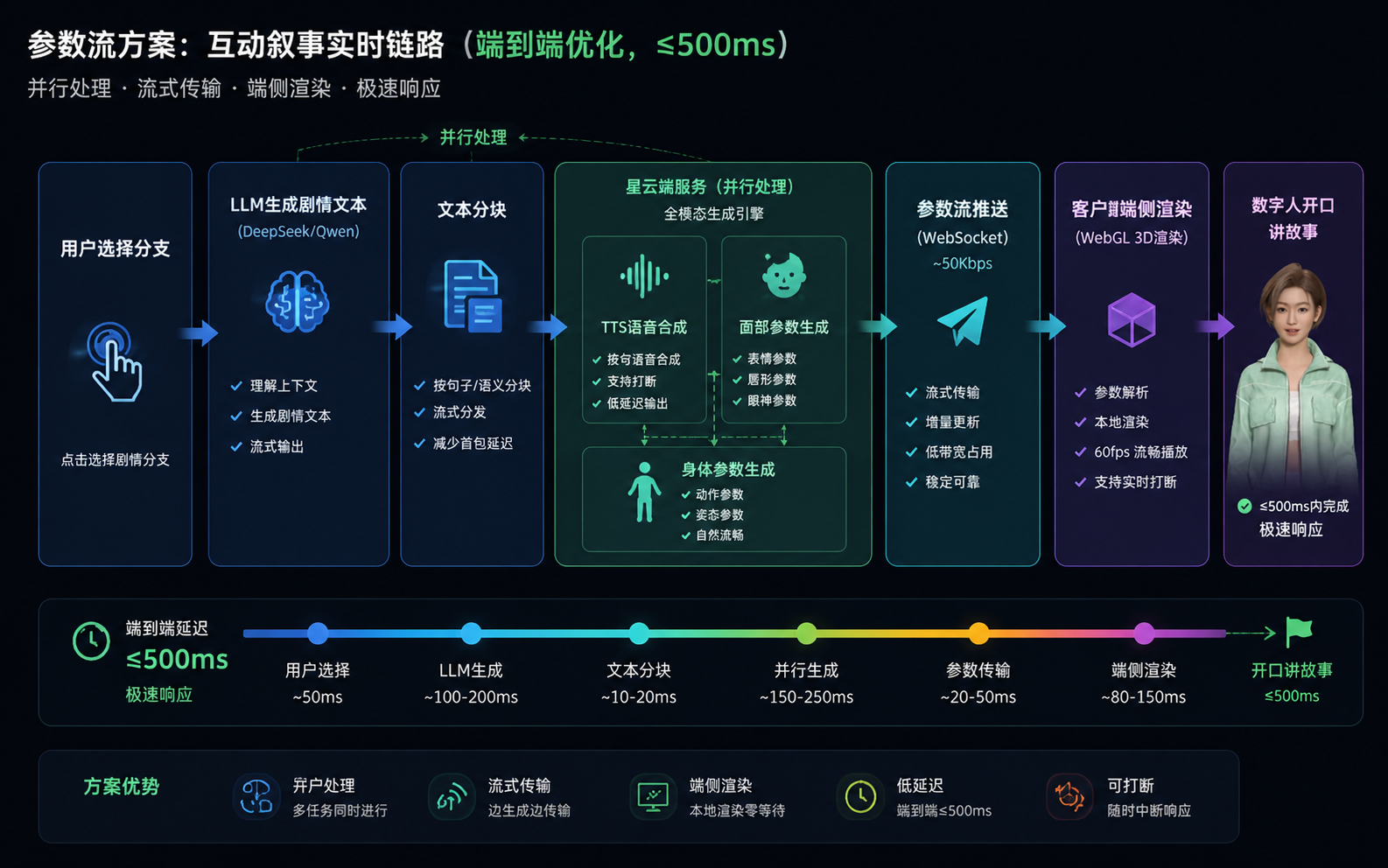
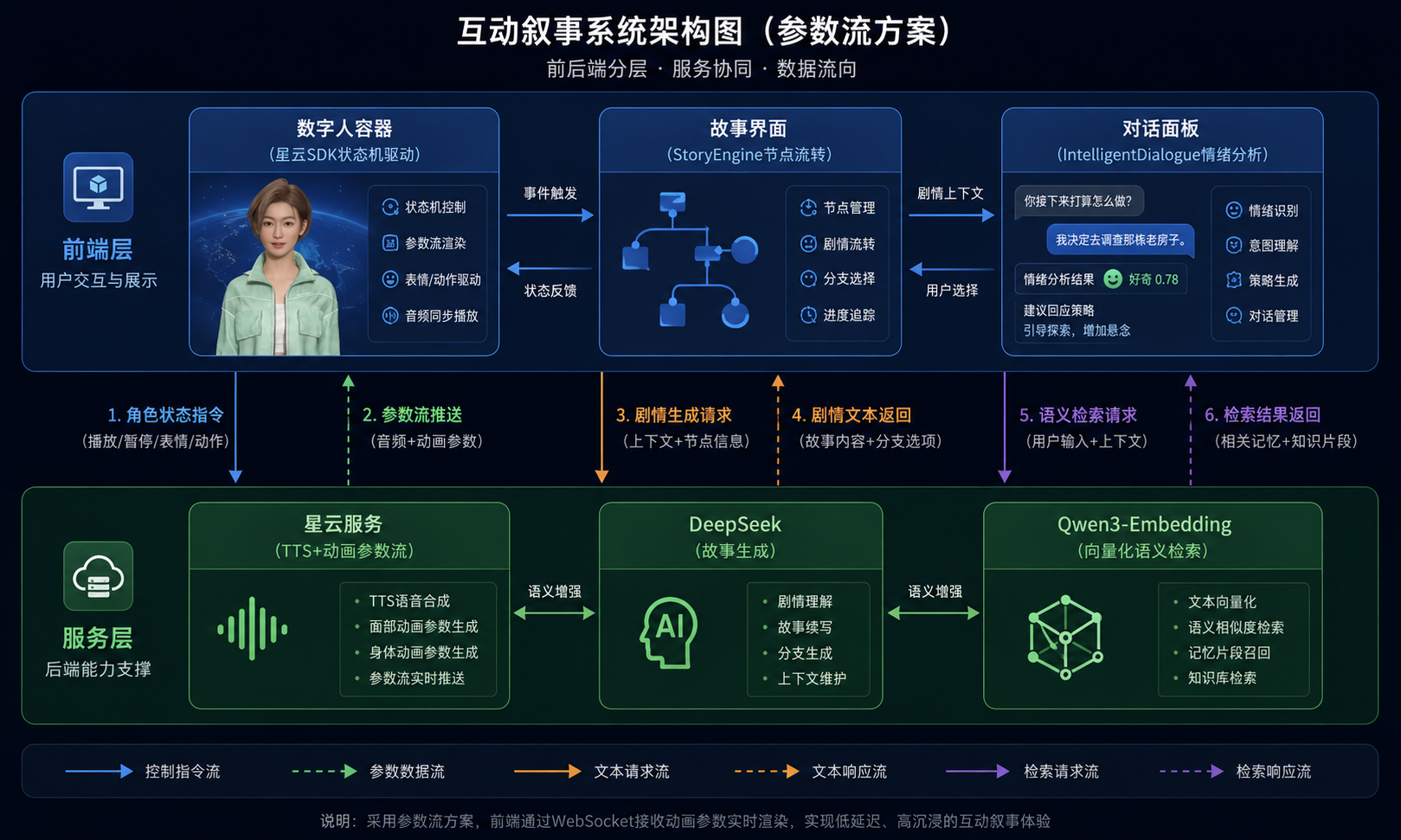
魔珐星云的技术路线完全绕开了视频流的思路,用的是参数流架构。理解这个概念对后续的开发实践很关键。
3.1 核心思路:只传参数,不传画面
传统视频流方案会在服务端完成全帧画面绘制、编码,再将内容分发至终端;自研参数流架构仅在云端生成语音、面部与肢体动画等轻量化参数并下发,终端依托AI 端渲和解算能力,调用本地 GPU 实时生成 3D 数字人画面。
打个比方:视频流像是看直播,参数流像是玩3D游戏。直播的画质和流畅度取决于网络带宽和主播的编码能力;游戏的画质取决于你本地显卡的性能,网络只影响"延迟"。
这个思路转换带来几个直接好处:
- 带宽从Mbps级降到Kbps级(参数数据量远小于视频数据量),一百个并发用户和一万个并发用户对服务端的带宽压力差异不大
- 客户端渲染意味着画质不降级,本机GPU能跑多好就多好
- AI端渲和端侧解算技术让延迟结构更扁平,不需要视频编解码环节
- 百元级芯片就能部署,RK3588跑1080p,RK3566跑720p,不挑硬件
3.2 三层打通:从感知到表达
魔珐星云的三层架构把感知-认知-表达端到端打通:
多模态感知层(理解用户输入)
↓
大模型+智能体认知层(LLM推理决策)
↓
多模态具身表达层(语音+表情+身体动画+端侧渲染)关键在于这三层不是独立拼接,而是联合优化 的。从用户输入到数字人开口回应,整条链路的延迟控制在端到端 ≈ 500ms。这个数字在我的实际测试中是可信的------在网络正常的情况下,用户做出选择后,数字人几乎"秒开口",不需要等一个尴尬的空白期。
3.3 对互动叙事意味着什么
在互动叙事场景中,≈500ms的端到端响应意味着:
- 用户选完分支后,数字人立刻开始讲下一段,没有出戏的等待
- 长对话不心疼,参数流的带宽消耗极低,十几分钟的叙事会话成本几乎可以忽略
- 表情动作跟内容同步,SDK的SSML机制允许在文本中嵌入动作指令,数字人在讲"小心!"的时候会配合紧张的表情和手势
四、实战:搭建一个AI互动叙事Agent
4.1 项目核心点:以实时交互为核心,打造沉浸式互动叙事体验
传统叙事类数字人方案,交互功能与故事内容相互割裂,仅作为附加模块存在;本项目依托魔珐星云自研参数流架构 + AI 端渲和解算带来的低延迟 实时交互能力,实现交互与叙事深度融合,用户行为、情绪可全链路实时作用于整体叙事流程。
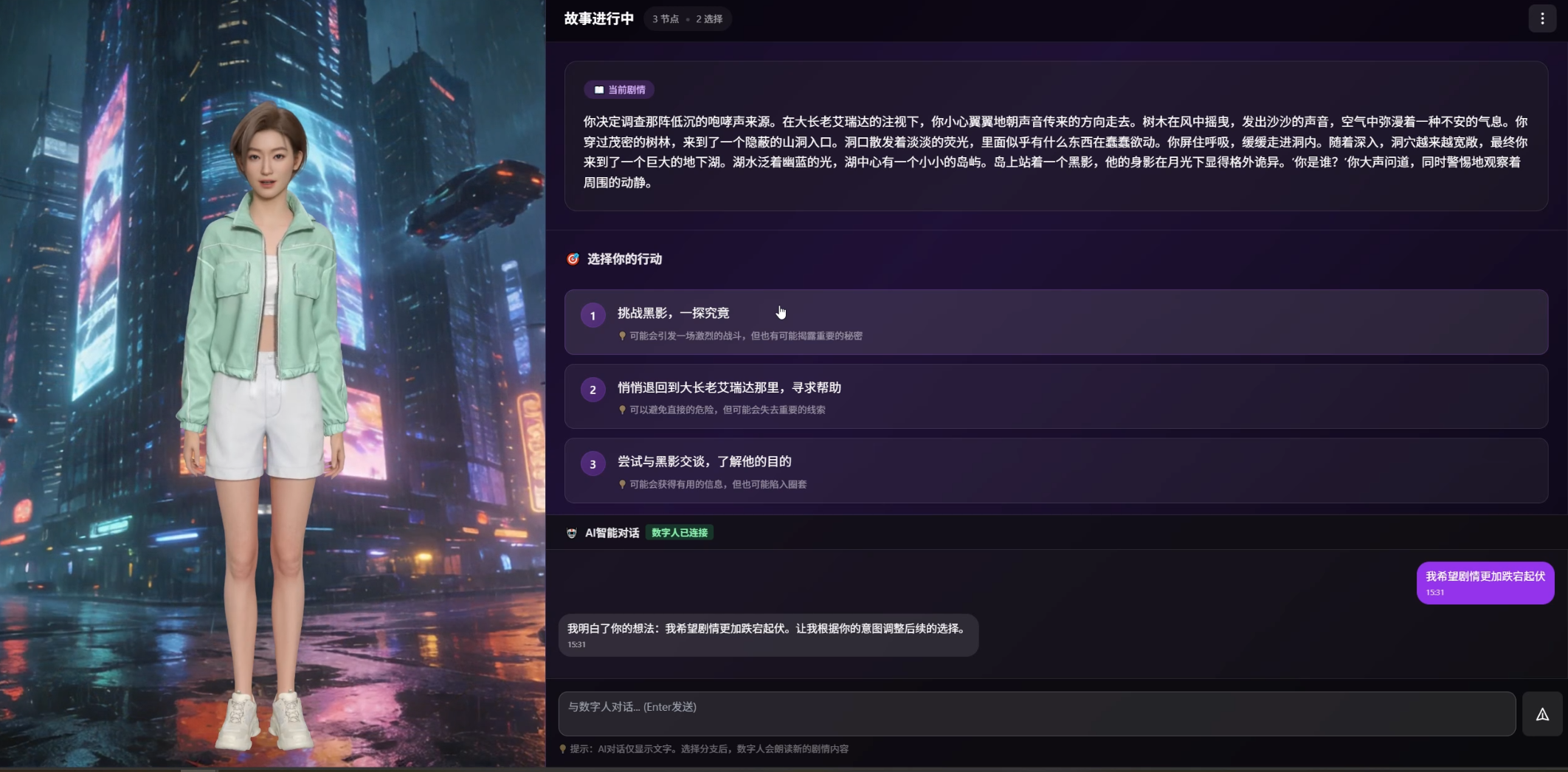
- 分支选择 即时 驱动剧情 :每到关键节点,用户从3个分支中做出选择,每一次选择都会实时生效,直接带来实质性的剧情分化。不是"选A还是B"的表面选择,而是每个选择都会让后续剧情产生实质性的分歧。
- 自由对话 支持随时打断:用户不必被动等待分支选项,随时可以开口说话,跟数字人对话。你的想法、情绪、意图都会被AI感知,并反映到接下来的剧情生成中------比如你对某个角色表达了好奇,后续剧情就会围绕这个角色展开更多内容。
- 情绪感知联动形象表达:系统可实时捕捉用户情绪,驱动数字人同步调整语音、神态与肢体状态。当用户流露紧张情绪,数字语气、神态随之变得沉稳;当用户情绪高涨,则搭配对应的肢体动作与表情。全程动态联动,告别固定化内容输出模式。
三类实时交互模式层层叠加、有机结合,打破单向内容输出的局限,让用户彻底告别单调的单向收听,沉浸式玩转整个故事。

4.2 场景设计
用户进入页面后,选择一个故事世界(比如赛博朋克城市),数字人开始讲述开场剧情。讲完后,屏幕上出现3个分支选项,用户选择一个,数字人继续讲对应的剧情,然后再次出现新的分支------如此循环。
这个场景的技术核心是三件事:
- LLM流式生成故事内容(用Qwen或DeepSeek)
- 数字人实时朗读(用星云SDK的流式speak接口)
- 向量检索上下文(确保AI"记住"之前的剧情)
4.3 极简Demo代码
下面是完整可运行的HTML代码。LLM部分使用DeepSeek作为故事生成的"大脑"。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>灵魂讲述者 - AI互动叙事Demo</title>
<style>
* { margin: 0; padding: 0; box-sizing: border-box; }
body {
font-family: -apple-system, sans-serif;
background: #0d1117;
color: #c9d1d9;
display: flex;
height: 100vh;
overflow: hidden;
}
/* 数字人区域 */
#avatar-container {
width: 45%;
height: 100%;
position: relative;
background: #161b22;
}
/* 故事面板 */
.story-panel {
width: 55%;
display: flex;
flex-direction: column;
padding: 24px;
overflow-y: auto;
}
h1 {
font-size: 20px;
color: #58a6ff;
margin-bottom: 16px;
}
.story-text {
flex: 1;
line-height: 1.8;
font-size: 15px;
padding: 16px;
background: #161b22;
border-radius: 10px;
border: 1px solid #30363d;
margin-bottom: 16px;
white-space: pre-wrap;
}
/* 分支选项 */
.choices {
display: flex;
flex-direction: column;
gap: 10px;
margin-bottom: 16px;
}
.choice-btn {
padding: 14px 18px;
background: #21262d;
border: 1px solid #30363d;
border-radius: 8px;
color: #c9d1d9;
cursor: pointer;
text-align: left;
font-size: 14px;
transition: all 0.2s;
}
.choice-btn:hover {
border-color: #58a6ff;
background: #1c2333;
}
.choice-btn:disabled {
opacity: 0.4;
cursor: not-allowed;
}
/* 配置区 */
.config {
display: flex;
gap: 8px;
margin-bottom: 12px;
flex-wrap: wrap;
}
.config input {
flex: 1;
min-width: 140px;
padding: 8px 12px;
border: 1px solid #30363d;
border-radius: 6px;
background: #161b22;
color: #c9d1d9;
font-size: 12px;
}
.btn {
padding: 8px 16px;
border: 1px solid #30363d;
border-radius: 6px;
background: #21262d;
color: #c9d1d9;
cursor: pointer;
font-size: 13px;
}
.btn:hover { border-color: #58a6ff; }
.btn-primary {
background: #238636;
border-color: #238636;
color: white;
}
.status {
font-size: 12px;
color: #8b949e;
text-align: center;
margin-bottom: 8px;
}
</style>
</head>
<body>
<div id="avatar-container"></div>
<div class="story-panel">
<h1>灵魂讲述者 - AI互动叙事</h1>
<div class="config">
<input id="app-id" placeholder="星云 App ID" />
<input id="app-secret" type="password" placeholder="星云 App Secret" />
<input id="llm-key" type="password" placeholder="DeepSeek API Key" />
<button class="btn btn-primary" onclick="startStory()">开始冒险</button>
</div>
<div class="status" id="status">填写密钥后点击"开始冒险"</div>
<div class="story-text" id="story-text">
欢迎来到互动叙事世界。连接数字人后,AI将为你讲述一个专属故事,在每个关键时刻,你的选择将改变剧情走向......
</div>
<div class="choices" id="choices"></div>
</div>
<!-- 加载星云SDK -->
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
<script>
let sdk = null;
let storyHistory = []; // 剧情历史(用于LLM上下文)
let currentChoices = [];
// ============ 世界观设定 ============
const WORLD = {
name: '赛博暗巷',
setting: `故事发生在2147年的新上海。城市被巨型企业"天穹集团"控制,
居民生活在霓虹灯与废墟交织的底层街区。你是一个信息贩子,
靠在暗网中买卖秘密为生。今晚,你收到了一条加密信息------
来自一个已经"消失"三年的老朋友。`,
style: '赛博朋克,黑暗,悬疑,以第二人称叙事'
};
// ============ 星云SDK连接 ============
async function initAvatar() {
const appId = document.getElementById('app-id').value;
const appSecret = document.getElementById('app-secret').value;
if (!appId || !appSecret) {
setStatus('请填写星云密钥(xingyun3d.com 免费获取)');
return false;
}
setStatus('正在连接数字人...');
sdk = new XmovAvatar({
containerId: '#avatar-container',
appId,
appSecret,
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',
onStateChange: (state) => setStatus('数字人: ' + state),
onVoiceStateChange: (status) => {
if (status === 'end') {
// 数字人讲完当前段落,显示选项让用户选择
showChoices();
}
},
onMessage: (msg) => {
if (msg.code >= 40000) console.error('SDK:', msg);
},
enableLogger: true
});
try {
await sdk.init({
onDownloadProgress: (p) => setStatus('资源加载: ' + p + '%')
});
await sdk.idle();
setStatus('数字人就绪');
return true;
} catch (e) {
setStatus('连接失败: ' + e.message);
return false;
}
}
// ============ 故事生成(LLM流式+数字人驱动)============
async function startStory() {
const llmKey = document.getElementById('llm-key').value;
if (!llmKey) {
setStatus('请填写 DeepSeek API Key');
return;
}
// 连接数字人
const ok = await initAvatar();
if (!ok) return;
// 生成开场
await generateNarrative('这是故事的开始,请生成开场剧情。');
}
async function generateNarrative(userAction) {
const llmKey = document.getElementById('llm-key').value;
// 构建上下文(保留最近5段剧情)
const context = storyHistory.slice(-5).map(
(h, i) => `第${i + 1}段: ${h.narrative}`
).join('\n');
setStatus('AI正在构思...');
// 切换数字人状态为"思考"
if (sdk) await sdk.think();
try {
// 调用DeepSeek生成剧情+分支(一次API调用)
const response = await fetch('https://api.deepseek.com/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + llmKey
},
body: JSON.stringify({
model: 'deepseek-chat',
messages: [
{
role: 'system',
content: `你是一个互动小说引擎。
世界观:${WORLD.setting}
风格:${WORLD.style}
规则:
1. 每次续写150-250字的剧情段落
2. 在剧情末尾提供3个不同的分支选项
3. 选项应该有明确的后果提示
4. 严格按以下JSON格式输出,不要加任何其他文字:
{"narrative":"剧情内容","choices":[{"text":"选项1","hint":"可能的后果"},{"text":"选项2","hint":"可能的后果"},{"text":"选项3","hint":"可能的后果"}]}`
},
{ role: 'user', content: `已有剧情:\n${context || '(无,这是开头)'}\n\n用户行动:${userAction}\n\n请续写剧情。` }
],
temperature: 0.9,
response_format: { type: 'json_object' }
})
});
const data = await response.json();
const result = JSON.parse(data.choices[0].message.content);
// 记录到历史
storyHistory.push(result);
// 让数字人讲故事
await speakNarrative(result.narrative);
currentChoices = result.choices;
} catch (e) {
setStatus('生成失败: ' + e.message);
if (sdk) await sdk.idle();
}
}
// ============ 数字人流式朗读 ============
async function speakNarrative(text) {
if (!sdk) return;
// 按标点分块,模拟自然的说话节奏
const chunks = text.match(/[^。!?;...]+[。!?;...]?/g) || [text];
let isFirst = true;
for (let i = 0; i < chunks.length; i++) {
const chunk = chunks[i].trim();
if (!chunk) continue;
const isEnd = (i === chunks.length - 1);
await sdk.speak(chunk, isFirst, isEnd);
isFirst = false;
}
// 在页面文字区域同步显示
const storyEl = document.getElementById('story-text');
storyEl.textContent += '\n\n' + text;
storyEl.scrollTop = storyEl.scrollHeight;
}
// ============ 分支选择 ============
function showChoices() {
const container = document.getElementById('choices');
container.innerHTML = '';
currentChoices.forEach((choice, index) => {
const btn = document.createElement('button');
btn.className = 'choice-btn';
btn.textContent = `${index + 1}. ${choice.text}${choice.hint ? ' ------ ' + choice.hint : ''}`;
btn.onclick = () => makeChoice(choice);
container.appendChild(btn);
});
}
async function makeChoice(choice) {
// 清空选项
document.getElementById('choices').innerHTML = '';
setStatus(`你选择了:${choice.text}`);
// 切换到倾听状态
if (sdk) await sdk.listen();
// 生成新剧情
await generateNarrative(`玩家选择了:"${choice.text}"(${choice.hint})`);
}
// ============ 工具函数 ============
function setStatus(text) {
document.getElementById('status').textContent = text;
}
// 页面关闭时释放资源
window.addEventListener('beforeunload', () => {
if (sdk) sdk.destroy();
});
</script>
</body>
</html>使用方式 :保存为 .html 文件,通过本地服务器打开(npx serve . 或 python -m http.server),填入星云密钥和DeepSeek API Key,点击"开始冒险"即可体验。
4.4 代码中的几个关键设计
(1)一次API调用同时生成剧情+分支
注意我在system prompt中要求LLM同时输出 narrative(剧情内容)和 choices(3个分支选项),用JSON格式约束输出。这比"先让LLM写剧情,再调一次API生成分支"要高效得多------一次调用解决两个问题,且内容与选项之间的语义一致性更好。
(2)按标点分块的流式朗读
speakNarrative() 函数用正则按标点(。!?;...)把文本分块,然后逐块送入 sdk.speak()。这样做的好处是数字人的说话节奏更自然------在每个句号处自然停顿,而不是一口气念完一整段。首块 isStart=true 立即开始驱动,后续块顺序追加,末块 isEnd=true 收尾。
(3)语音状态回调驱动的UI同步
核心的交互节奏是由 onVoiceStateChange 回调驱动的。数字人讲完 一段话(status === 'end')后,才显示分支选项让用户选择。这保证了用户是在"听完全部内容"后才做决定,而不是边听边被选项分散注意力。
4.5 从Demo到完整产品:我的项目经验
上面的Demo是最小实现。我的完整项目------"灵魂讲述者"------还加入了几个让体验质变的特性:
向量检索上下文:故事越讲越长,LLM的上下文窗口放不下所有历史剧情。我用Qwen3-Embedding把每段剧情向量化存入IndexedDB,生成新剧情时先语义检索最相关的历史段落作为上下文。这确保了AI能"记住"几十个节点前的关键伏笔。
SSML动作系统 :星云SDK支持在文本中嵌入 <ue4event> 标签触发特定手势。比如开场时用"Welcome"动作,悬疑场景用"Think"动作,遇到转折时用"Surprise"动作。这些动作和文本内容同步执行,让数字人的"表演"与故事氛围匹配。
情绪感知对话 :除了选分支,用户还可以自由对话影响剧情。后台用Qwen3-VL分析用户发言的情绪,数字人的回应风格和SSML动作会根据情绪自动调整------用户说"我害怕"时数字人语气变温柔配合安慰手势,用户说"冲!"时数字人语气变激昂。
背景动态切换:10张不同氛围的背景图随故事节点循环切换,悬疑场景用暗色背景,温馨场景用暖色背景,增强视觉沉浸感。
五、开发者视角:SDK、API与架构
5.1 SDK接入:比想象中简单
魔珐星云的JS SDK接入门槛不高。CDN加载一个脚本文件,核心API只有七八个方法。我整理了一个快速上手清单:
1. 加载SDK: <script src="...xmovAvatar@latest.js">
2. 创建实例: new XmovAvatar({ containerId, appId, appSecret, gatewayServer, callbacks })
3. 初始化: await sdk.init({ onDownloadProgress })
4. 控制状态: sdk.idle() / .listen() / .think() / .interactiveidle()
5. 驱动说话: sdk.speak(text, isStart, isEnd)
6. 销毁实例: sdk.destroy()需要注意的几个坑:
- 必须通过
localhost或HTTPS访问,file://协议不支持WebSocket - 容器元素必须有明确的宽高 ,不能用
flex: 1之类的弹性布局撑出来 - 页面离开时必须调用 destroy(),否则服务端会话不释放,很快触发并发限制
5.2 SSML动作:让数字人"会表演"
星云SDK的SSML机制是让数字人"活起来"的关键。三种动作类型:
语义动作(ka_intent):按意图触发手势。比如在"欢迎各位"前嵌入Welcome意图,数字人会做出欢迎手势。
<speak>热烈<ue4event><type>ka_intent</type>
<data><ka_intent>Welcome</ka_intent></data>
</ue4event>欢迎你来到这个世界...</speak>技能动作(ka):触发预定义的特定动画,如dance、wave等。
说话动作(ka + action_semantic):在说话的同时执行动作,实现"边说边比划"。
在我的叙事项目中,我建立了一个情绪到动作的映射表:
|------|-----------|-----------|
| 场景 | SSML动作 | 效果 |
| 故事开场 | Welcome | 数字人做出欢迎手势 |
| 悬疑紧张 | Think | 数字人皱眉、抱臂 |
| 剧情转折 | Surprise | 数字人做出惊讶表情 |
| 悲伤片段 | Comfort | 数字人做出安慰手势 |
| 战斗场景 | Celebrate | 数字人做出胜利姿势 |
这种"语义驱动的动作系统"比纯预设动画高明得多------动作不是机械循环的,而是跟正在说的内容语义相关的。
5.3 AI Coding工具的实际价值
我在这个项目中实际使用了三种AI编程工具,各有分工:
Claude Code:负责架构设计和复杂逻辑实现。比如向量检索服务、流式文本分块策略、状态机的异常处理------这些需要理解全局上下文的任务交给Claude Code更合适。它能在项目级别理解代码之间的关系,避免局部修改引入全局问题。
Cursor + 星云AI Coding Skill:负责SDK集成和前端组件开发。星云官方的Skill文件本质上是一个结构化的Prompt,教会AI编辑器如何正确使用SDK------包括初始化流程、状态机管理、中断协议、生命周期保护。部署后,在Cursor中输入"初始化星云数字人项目",AI就能生成完整的可运行代码。
DeepSeek / Qwen:作为项目的"AI大脑"。DeepSeek擅长创意写作和JSON结构化输出,适合故事生成。Qwen3-VL支持多模态,在需要分析用户上传图片的场景中表现更好。两个模型都通过OpenAI兼容API调用,切换成本低。
5.4 架构全景
完整项目的技术架构:
┌──────────────────── 前端(React + TypeScript)────────────────────┐
│ │
│ ┌────────────┐ ┌──────────────┐ ┌───────────────────────────┐ │
│ │ 数字人容器 │ │ 故事界面 │ │ 对话面板 │ │
│ │ (星云SDK) │ │ (分支选择) │ │ (自由对话影响剧情) │ │
│ └─────┬──────┘ └──────┬───────┘ └──────────┬────────────────┘ │
│ │ │ │ │
│ ┌─────▼──────┐ ┌──────▼───────┐ ┌──────────▼────────────────┐ │
│ │ 星云SDK │ │ StoryEngine │ │ IntelligentDialogue │ │
│ │ 状态机驱动 │ │ 节点流转管理 │ │ 情绪分析+SSML动作选择 │ │
│ └─────┬──────┘ └──────┬───────┘ └──────────┬────────────────┘ │
│ │ │ │ │
│ ┌─────▼──────┐ ┌──────▼───────┐ ┌──────────▼────────────────┐ │
│ │ WebSocket │ │ VectorStore │ │ EmotionAnalysis │ │
│ │ 参数流接收 │ │ IndexedDB │ │ Qwen3-VL情绪检测 │ │
│ └────────────┘ └──────────────┘ └───────────────────────────┘ │
└──────────────────────────┬────────────────────────────────────────┘
│
┌────────────┼────────────┐
│ │ │
┌────────▼──┐ ┌──────▼──────┐ ┌─▼──────────────┐
│ 星云服务 │ │ DeepSeek │ │ Qwen3-Embedding │
│ TTS+动画 │ │ 故事生成 │ │ 向量化 │
│ 参数流 │ │ 分支生成 │ │ 语义检索 │
└───────────┘ └─────────────┘ └─────────────────┘
六、总结:具身Agent------下一代交互入口的雏形
做完这个项目后,我对"AI Agent"这个概念有了新的理解。
传统的Agent定义是"能自主感知、决策、执行的AI系统"。但在我看来,如果Agent的"执行"只是生成一段文字或调用一个API,那它的能力边界其实很窄。真正的"执行"应该包括表达------不只是输出信息,而是用语音、表情、手势等方式,像一个真实的存在一样与用户交互。
魔珐星云给我的体验是:它补上了Agent的"表达层"。LLM提供认知能力,星云提供具身表达能力,两者结合就形成了一个AI具身智能体------能思考、能表达、能感知用户状态、能自然交互。
几个具体的体验感受:
关于延迟。 端到端≈500ms的响应速度在互动叙事场景中体感非常明显。用户选完分支后数字人几乎"秒接话",不会出现那种"选完了盯着屏幕等半天"的尴尬。这不是锦上添花,而是决定了用户是否愿意继续"聊下去"的关键。
关于成本。 参数流架构的带宽消耗极低。我做过一个粗略对比:同样10分钟的互动会话,视频流方案大约需要1.5GB数据传输量,参数流方案只需要约30MB。这意味着在高并发场景下,参数流的运营成本可能是视频流的几十分之一。
关于开发者体验。 星云SDK的设计哲学是"少即是多"------核心API只有几个方法,但足够灵活。配合AI Coding工具和官方Skill文件,一个前端开发者从零到跑通一个数字人应用,一个下午就能搞定。这种开发效率对于快速验证创意想法非常重要。
关于场景想象。 互动叙事只是冰山一角。我尝试过在教育场景(AI数学老师)、情绪陪伴场景(心灵伴侣)、企业展厅场景(智能讲解)中使用星云SDK------每次都有新的发现。具身Agent的可能性远比我们想象的要大。
最后说一句:2025年的AI行业在疯狂卷"模型能力",但交互形态的创新同样重要。当所有Agent都还在用文字对话的时候,谁能率先给Agent一副"身体",让交互从"读写"变成"听看说"------谁就可能在下一代人机交互的竞争中占据先机,魔珐星云至少给出了一个可行的技术路径。
相关资源:
- 魔珐星云开发者文档:https://xingyun3d.com/developers/52-183
- 魔珐星云AI Coding Skill文档:https://rsjqcmnt5p.feishu.cn/wiki/ULNQwoiKwid2tVkTpAlcMb49nKg
- DeepSeek API(故事生成):https://platform.deepseek.com/
- ModelScope API(国产LLM/Embedding):https://modelscope.cn/
魔珐星云::魔珐星云官网