大家好,我是上好佳佳佳呀。今天学习的是 LangChain 里那条神奇的
|管道。在学习的过程中,刚上手 LangChain 的时候,照着示例能跑通,稍微改一下链条就报错。我发现核心是没摸清管道里每个环节"吃的是什么、吐的是什么"。可以通过此篇博客,边读边思考:如果让你设计一个链式调用框架,你会怎么保证每一步的输入输出衔接?心里是否会有一张完整的数据流转地图?带着这个问题,我相信学习之后对于Chain的搭链和排错会从容许多,那么我们开始吧~🔗 前置知识
📅 更新日期:2026-06-12
文章目录
- [1. Chain能跑起来的两个前提条件](#1. Chain能跑起来的两个前提条件)
-
- [1.1 前提一:必须是Runnable的子类](#1.1 前提一:必须是Runnable的子类)
- [1.2 前提二:输入输出类型必须匹配](#1.2 前提二:输入输出类型必须匹配)
- [2. 提示词模板(Prompt)的输入与输出](#2. 提示词模板(Prompt)的输入与输出)
-
- [2.1 PromptTemplate(字符串模板)](#2.1 PromptTemplate(字符串模板))
- [2.2 ChatPromptTemplate(消息列表模板)](#2.2 ChatPromptTemplate(消息列表模板))
- [2.3 两种模板的输入输出总结](#2.3 两种模板的输入输出总结)
- [3. 模型(Model)的输入与输出](#3. 模型(Model)的输入与输出)
- [4. 输出解析器(Output Parser)](#4. 输出解析器(Output Parser))
-
- [4.1 为什么需要解析器?](#4.1 为什么需要解析器?)
- [4.2 StrOutputParser(字符串输出解析器)](#4.2 StrOutputParser(字符串输出解析器))
- [4.3 JsonOutputParser(JSON 输出解析器)](#4.3 JsonOutputParser(JSON 输出解析器))
- [5. RunnableLambda:将任意函数注入链中](#5. RunnableLambda:将任意函数注入链中)
-
- [5.1 RunnableLambda 是什么?](#5.1 RunnableLambda 是什么?)
- [5.2. 直接使用函数/lambda入链](#5.2. 直接使用函数/lambda入链)
- [5.3 Lambda 匿名函数的书写格式](#5.3 Lambda 匿名函数的书写格式)
- [6. 总结复盘](#6. 总结复盘)
1. Chain能跑起来的两个前提条件
任何一个Chain(链)能顺畅执行,都必须满足两个底层条件。
1.1 前提一:必须是Runnable的子类
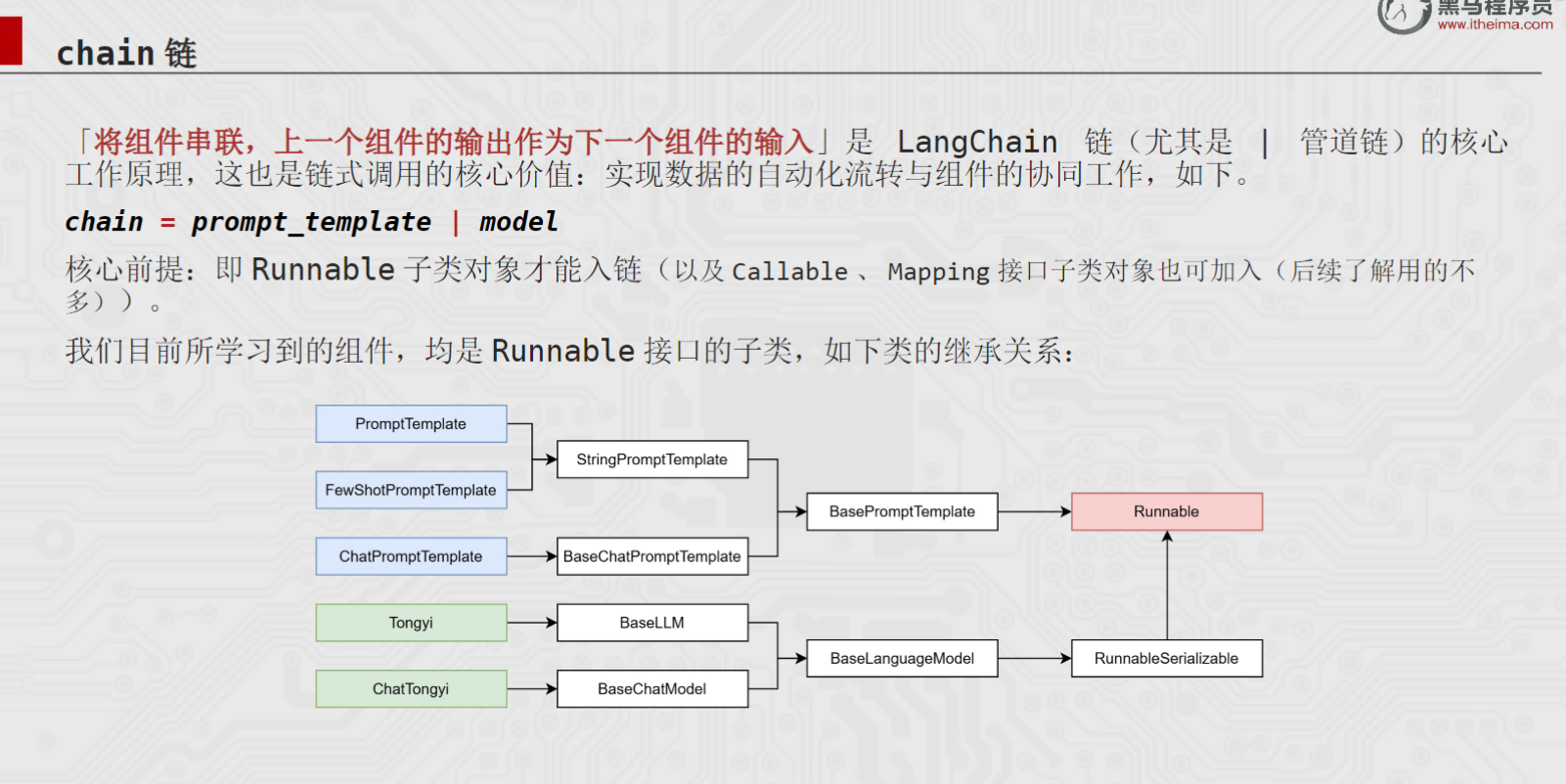
在LangChain中,并不是什么对象都能用 | 串起来。只有Runnable的子类对象才能入链 。为什么呢?因为Runnable这个抽象基类内部重写了 or 魔术方法。
python
# 伪代码示意
class Runnable:
def __or__(self, other):
# 返回一个 RunnableSequence 对象,把 self 和 other 串联起来
return RunnableSequence(self, other)当你写下 prompt | model 时,实际上执行了 prompt.or (model),并且它返回一个 RunnableSequence 对象。而这个 RunnableSequence 本身也是 Runnable 的子类,所以你可以继续 | parser,形成更长的链,换句话说也就是无限套娃。这就是链式调用的语法根基。
那么问题又来了,哪些才是 Runnable 的子类呢?LangChain中绝大多数核心组件都继承自Runnable,比如我们天天打交道的:
- prompt:ChatPromptTemplate、PromptTemplate
- model:BaseChatModel(各种聊天模型)
- StrOutputParser、JsonOutputParser 等解析器(之后学习)
- 甚至你自己用 RunnableLambda 包装的函数(之后学习)
1.2 前提二:输入输出类型必须匹配
链的本质是"上一个组件的输出,作为下一个组件的输入"。这就像水管接头,前一根管子的出水口必须和后一根的入水口型号一致,否则就漏水(报错)
管道里数据是怎么流动的?画出来很简单:
用户输入
│
▼
组件 A ← 进某种类型,出某种类型
│
▼
组件 B ← 进的类型,必须和 A 出的类型兼容
│
▼
组件 C ← 同理,B 出啥,C 就得进啥
│
▼
最终输出核心:上游组件的输出类型 ≈ 下游组件的输入类型
所以,想要顺畅地设计Chain,我们首先必须搞清楚管道中每一个组件到底接受什么类型的数据,又输出什么类型的数据。
2. 提示词模板(Prompt)的输入与输出
提示词模板是管道的起点,它把用户传入的变量替换成格式化的提示词。
2.1 PromptTemplate(字符串模板)
这是最基础、最常见的 Prompt 模板,它用于生成一段纯文本提示词:
python
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template("请将以下内容翻译成{language}:{text}")
# 📥 输入:一个字典,key 对应模板里的 {变量名}
# 📤 输出:一个 StringPromptValue 对象
result = prompt.invoke({"language": "英文", "text": "你好"})
print(type(result))
# <class 'langchain_core.prompt_values.StringPromptValue'>StringPromptValue 是一个包装对象 ,它内部保存了格式化好的字符串。你可以用两种方式拿到文本:
- result.text :属性,直接返回字符串
- result.to_string() :方法,同样返回字符串
🧐 细节点拨:
.text和.to_string()有啥区别?答案是:对 StringPromptValue 来说,返回的内容完全一样,都是格式化后的纯文本。区别可能就是前者是属性访问,后者是方法调用。从设计上说,保留方法是为了接口的兼容性和语义清晰。
2.2 ChatPromptTemplate(消息列表模板)
这是更常见的用法,生成一个包含SystemMessage、HumanMessage等角色的消息列表,供ChatModel消化。
python
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是一名专业的{role}。"),
("human", "{question}"),
])
# 📥 输入:同样是 dict
# 📤 输出:ChatPromptValue 对象(内部包装的是消息列表)
result = prompt.invoke({"role": "翻译官", "question": "请翻译:你好"})
print(type(result))
# <class 'langchain_core.prompt_values.ChatPromptValue'>注意,ChatPromptValue 和 StringPromptValue 不同 ,它装的不是纯文本,是消息对象列表。
python
# 方式一:.messages 属性 ------ 返回消息对象列表
print(result.messages)
# [SystemMessage(content="你是一名专业的翻译官。", ...),
# HumanMessage(content="请翻译:你好", ...)]
# 方式二:.to_messages() 方法 ------ 同样返回消息对象列表
print(result.to_messages())
# [SystemMessage(content="你是一名专业的翻译官。", ...),
# HumanMessage(content="请翻译:你好", ...)]
# 方式三:.to_string() 方法 ------ 把所有消息拼成一个可读字符串
print(result.to_string())
# System: 你是一名专业的翻译官。
# Human: 请翻译:你好🧐 细节点拨:
.messagesvs.to_messages()vs.to_string()(1)
.messages和.to_messages()的区别两者返回的内容完全一致 :都是
List[BaseMessage],即消息对象列表。区别在哪?还是前者是属性访问,后者是方法调用。从设计上说,保留方法是为了接口的兼容性和语义清晰。
(2)
.to_string()的定位
.to_string()把消息列表拼成一个人类可读的字符串 :这个方法的定位是展示和调试 ,不要把它当成传给模型的东西,模型需要的是消息对象列表,不是这个拼接字符串。
对比一览:
对比维度 .messages.to_messages().to_string()类型 属性 方法 方法 返回值类型 List[BaseMessage]List[BaseMessage]str返回内容 消息对象列表 消息对象列表(和 .messages一样)拼接后的可读字符串 主要用途 获取消息对象 统一接口,兼容多态 调试、日志、肉眼查看 能传给 Model 吗? ✅ 可以 ✅ 可以 ❌ 不建议,传给 Model 的应该是消息列表
StringPromptValue 调用 .to_messages() 会怎样?它会机智地把纯文本包一层 HumanMessage 返回给你。这就是统一接口的优雅之处,外面不用管里面是什么,调 .to_messages() 一定拿到消息列表。StringPromptValue → Model 调用 .to_messages() → HumanMessage(...)
2.3 两种模板的输入输出总结
| 模板类型 | 输入类型 | 输出对象 | 获取格式化内容的关键方式 |
|---|---|---|---|
PromptTemplate |
dict |
StringPromptValue |
.text / .to_string() 得到纯文本 |
ChatPromptTemplate |
dict |
ChatPromptValue |
.messages / .to_messages() 得到消息列表 |
补充:FewShotChatMessagePromptTemplate
这是一个特殊的存在,它并不是管道中独立的一环,而是嵌在ChatPromptTemplate内部 使用,作为"示例选择器"工作。它没有独立的 invoke() 入口,输入输出完全由包裹它的父模板决定。因此我们暂时不必单独考虑它的格式。
3. 模型(Model)的输入与输出
模型是整个链的发动机。LangChain中的聊天模型(BaseChatModel)有一个非常智能的设计:输入多态。它能接受多种格式,极大地方便了链条的串联。
模型到底能接收什么?
python
from langchain.chat_models import init_chat_model
model = init_chat_model("deepseek-chat") # 用你自己的模型即可
# 方式1:纯字符串(内部自动包装成 HumanMessage)
response = model.invoke("你好,请解释一下量子力学")
print(type(response)) # <class 'langchain_core.messages.AIMessage'>
# 方式2:消息列表(最标准的方式)
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="你是一个物理学家。"),
HumanMessage(content="解释量子力学"),
]
response = model.invoke(messages)
print(type(response)) # AIMessage
# 方式3:PromptValue 对象(这正是 prompt.invoke() 的返回值)
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是{role}。"),
("human", "{question}"),
])
prompt_value = prompt.invoke({"role": "物理学家", "question": "解释量子力学"})
response = model.invoke(prompt_value)
print(type(response)) # AIMessage从源码的注释也能看到模型接受输入的类型非常灵活:
python
# 输入类型提示(Union类型)
# str | List[BaseMessage] | PromptValue正是这种设计,让 prompt | model 直接打通了:prompt输出 ChatPromptValue 或 StringPromptValue,模型都能愉快接收。
🧐 深入思考
Model 内部的处理逻辑大致是这样的:
python# Model 内部伪代码 def _prepare_input(self, x): if isinstance(x, str): return [HumanMessage(content=x)] # 字符串 → 包一层 HumanMessage elif isinstance(x, PromptValue): return x.to_messages() # PromptValue → 调 to_messages() elif isinstance(x, list): return x # 消息列表 → 直接用StringPromptValue 的
.to_messages()返回[HumanMessage(...)],ChatPromptValue 的.to_messages()返回[SystemMessage(...), HumanMessage(...)]。不管上游传的是哪种 PromptValue,Model 统一调.to_messages()就能拿到消息列表。这就是为什么
prompt | model不管用哪种 prompt 都能正常工作的原因。 这样的设计也意味着你在链里可以灵活混搭不同的 Prompt 类型。
模型输出:AIMessage 里有什么?
调用 model.invoke() 后返回的是 AIMessage 对象。
python
response = model.invoke("你好")
# ① .content ------ 最常用,模型回复的文本
print(response.content)
# "你好!有什么我可以帮助你的吗?"
# ② .usage_metadata ------ Token 用量明细(注意是字典)
print(response.usage_metadata)
# {'input_tokens': 8, 'output_tokens': 12, 'total_tokens': 20}
# ③ .response_metadata ------ 模型的响应元信息
print(response.response_metadata)
# {'model_name': 'deepseek-chat', 'finish_reason': 'stop', ...}
# finish_reason 的几个常见值:
# 'stop' → 正常完成
# 'length' → 达到 max_tokens 上限被截断
# 'content_filter' → 内容被安全策略过滤此外,流式输出(model.stream())会返回一个迭代器,每次产出 AIMessageChunk,其中 .content 是增量文字片段,需要自己拼接。
模型的输入输出总结
| 模型调用方式 | 可接受的输入 | 输出类型 | 关键属性 |
|---|---|---|---|
model.invoke() |
str / List[BaseMessage] / PromptValue |
AIMessage |
.content(文本)、.usage_metadata(Token 统计)、.response_metadata(模型元信息) |
model.stream() |
同上 | Iterator[AIMessageChunk] |
.content(增量文本片段,需自行拼接) |
4. 输出解析器(Output Parser)
解析器的本质是格式转换器,同时它本身就是 Runnable,可以完美入链。它的使命就是把上游(通常是模型)输出的 AIMessage 转换成下游需要的数据格式。
4.1 为什么需要解析器?
python
chain = prompt | model | model # 能跑吗?现在咱们能分析了:
prompt输出StringPromptValue或ChatPromptValue- → 第一个
model能接收 ✅(Model 支持 PromptValue 输入) - → 第一个
model输出AIMessage - → 第二个
model能接收吗?❓
第二个 Model 的 invoke() 能接收 str、List[BaseMessage]、PromptValue,但不直接接收 AIMessage。所以直连两个 Model 是有问题的。
🎯 正确的多模型链设计思路 :上一个模型输出的
AIMessage,不应该裸着丢给下一个模型。正确的做法是:提取它的内容 → 作为新提示词的变量值 → 构建新的提示词 → 喂给下一个模型。
用户输入 → prompt1 → model1 → [转换] → prompt2 → model2 → [转换] → 最终结果 ↑ 关键一步:把 AIMessage 转成 prompt2 能吃的格式
输出解析器(Output Parser) 就是干这个"格式转换"活儿的。
4.2 StrOutputParser(字符串输出解析器)
StrOutputParser 是 LangChain 里最朴素的解析器,就做一件事:把 AIMessage 里的 .content 提取出来,返回纯字符串 str。
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import AIMessage
parser = StrOutputParser()
# 📥 输入:AIMessage 对象
# 📤 输出:纯字符串
response = AIMessage(content="你好!有什么可以帮你的吗?")
result = parser.invoke(response)
print(type(result)) # <class 'str'>
print(result) # "你好!有什么可以帮你的吗?"Chain的两个必要条件:
- ✅ 是 Runnable 子类?是的。
- ✅ 输出
str能被 Model 接收?没问题。
实际应用中,我们想让模型翻译后,直接将纯文本返回给用户,链就是:
python
chain = prompt | model | StrOutputParser()
chain.invoke({"language": "英文", "text": "你好"})
# 最终直接得到一个字符串 "Hello",不用再手动 .content整个数据流过程:
text
第1步:用户输入 dict → prompt 输出 ChatPromptValue
第2步:model 接收 ChatPromptValue → 输出 AIMessage
第3步:StrOutputParser 接收 AIMessage → 输出 str简单直接,所以它在很多不需要后续处理、只要最终文本的场景下(比如纯问答、翻译后直接展示)是非常方便的。
思考 :如果我想把模型A的回复作为新提示词的某个变量(比如{previous_answer}),直接用 StrOutputParser 够吗?
不够!因为它输出的是一个孤零零的字符串,而prompt.invoke()需要的是字典 {"previous_answer": "..."}。
pythonprompt2 = ChatPromptTemplate.from_messages([ ("system", "你是一个报告撰写专家。"), ("human", "根据以下内容写报告:\n" "主题:{topic}\n" "分析:{content}\n" "结论:{conclusion}"), ])这里有三个变量
{topic}、{content}、{conclusion}。StrOutputParser 只输出一个str,根本没法拆成三个变量分别注入。解决思路 :让第一个 Model 输出 JSON 格式的内容,然后解析成
dict。dict的 key 刚好对上 prompt2 的变量名。这时我们需要更强大的 JsonOutputParser 或自定义函数(RunnableLambda)来构建字典。
4.3 JsonOutputParser(JSON 输出解析器)
JsonOutputParser 的工作流程是:提取从上游传过来的 AIMessage 对象中取出 .content 属性(一个字符串);对该字符串调用 json.loads(),将其转换为 Python 字典(或列表等合法 JSON 结构);如果解析成功,返回字典,如果字符串不是合法的 JSON,会直接抛出异常。
所以,JsonOutputParser 并不是简单地"把 content 提取出来返回 dict",而是要求 content 本身必须是一个严格的 JSON 字符串,然后才转成 dict。
使用它的三个步骤:
- 写提示词时明确告诉模型只输出纯 JSON,并给出键名和示例格式;
- 用 JsonOutputParser() 解析模型的 AIMessage,得到 Python 字典;
- 将字典传给下一个 Prompt,键名与模板变量一一对应即可
代码实现案例:
第一步:构造提示词,强制要求 JSON 输出
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from langchain.chat_models import init_chat_model
model = init_chat_model("deepseek-chat") # 请替换成你自己的模型
# 提示词1:翻译并给出置信度,必须输出严格的 JSON
translate_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个翻译专家。请将用户输入翻译成{target_lang},并对翻译质量给出置信度(0-1之间)。"
"你必须**只输出**一个合法的 JSON 对象,不要包含任何其他文字。JSON 的格式必须是:"
'{{"translation": "...", "confidence": 0.xx}}'),
("human", "{text}")
])注意提示词中我们反复强调"只输出 JSON 对象,不要有任何多余文字",这是让解析器能正常工作的前提。
第二步:定义下游的第二个提示词
第二个提示词需要两个变量:translation 和 confidence,这两个变量名必须和 JSON 中的键名完全一致。
python
# 提示词2:利用翻译结果和置信度生成评估
evaluate_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个语言质量评估员。请根据以下信息给出简短评价。"),
("human", "翻译结果:{translation}\n置信度:{confidence}")
])第三步:构建链
python
from langchain_core.output_parsers import StrOutputParser
parser = JsonOutputParser() # 负责把 AIMessage → dict
chain = (
translate_prompt # 输出 ChatPromptValue
| model # 输出 AIMessage (内容期望是 JSON 字符串)
| parser # 输出 dict,例如 {'translation': 'Hello', 'confidence': 0.98}
| evaluate_prompt # 接收 dict,自动解包为变量
| model # 第二次调用模型
| StrOutputParser() # 最终输出纯文本
)
result = chain.invoke({"target_lang": "英文", "text": "你好世界"})
print(result)数据流动解析:
输入 dict {"target_lang":"英文", "text":"你好世界"}
→ translate_prompt 格式化为 ChatPromptValue
→ 模型A 输出 AIMessage(content='{"translation": "Hello World", "confidence": 0.98}')
→ JsonOutputParser 解析成字典 {"translation": "Hello World", "confidence": 0.98}
→ evaluate_prompt.invoke(该字典) 自动填入变量,生成新的 ChatPromptValue
→ 模型B 输出 AIMessage(content="翻译准确,置信度高。")
→ StrOutputParser 提取出最终的字符串关键点 :
JsonOutputParser返回的字典,它的键必须和下一个 Prompt 模板中的{变量名}完全一致,LangChain 会自动将字典的键值对注入模板。这种"约定优于配置"的设计,让多个模型的串联变得极其顺滑。
Q: 如果模型不听话,输出里掺杂了别的东西,JsonOutputParser会报错吗?
A: 会!因为它直接对内容字符串做 json.loads,一旦不是合法JSON就抛异常。补救方法有两个:一是在提示词里三令五申;二是使用 OutputFixingParser 尝试修复,或者自定义 RunnableLambda
5. RunnableLambda:将任意函数注入链中
StrOutputParser 和 JsonOutputParser 都是"固定功能"选手,各司其职。但实际开发中,你总会遇到一些自定义的转换需求:
- 把模型输出的内容截取前 200 个字做摘要
- 把 AIMessage 的
content和usage_metadata拼在一起返回 - 做 key 值重命名 (第二个模型输出
theme,但 prompt3 要的是topic) - 根据 content 的长度做条件分流
这些,固定解析器都搞不定。你需要自己定义转换逻辑 ,RunnableLambda 登场了。
5.1 RunnableLambda 是什么?
顾名思义:Runnable (可运行的)+ Lambda (函数)= 一个能被加入管道的函数包装器。可以把一个普通的Python函数(或lambda匿名函数)转换成Runnable对象,从而可以用 | 加入链中。
python
from langchain_core.runnables import RunnableLambda
# 自定义转换函数
def extract_and_summarize(ai_msg):
"""提取 AIMessage 的内容和 token 用量,返回一个自定义字典"""
return {
"text": ai_msg.content,
"word_count": len(ai_msg.content),
"tokens_used": ai_msg.usage_metadata.get("total_tokens", 0)
if ai_msg.usage_metadata else 0,
}
# 包装成 Runnable 实例
runnable_func = RunnableLambda(extract_and_summarize)
# 现在它可以被 invoke 调用了
result = runnable_func.invoke(ai_msg)
print(result)
# {'text': '...', 'word_count': 150, 'tokens_used': 200}然后就可以入链:
python
chain = prompt | model | RunnableLambda(extract_and_summarize) | prompt2 | model🧐 RunnableLambda 是 Runnable 的子类吗?
是的。 你看它名字开头就是
Runnable。它继承自Runnable基类,所以天然拥有全套标准接口:invoke()、stream()、batch()等,当然也能通过|加入管道。
5.2. 直接使用函数/lambda入链
在 | 管道中,我们可以直接传入一个普通函数或lambda,LangChain会自动将其转换为 RunnableLambda! 这背后是因为 Runnable.__or__ 方法在检测到 other 是一个可调用对象时,内部会调用 RunnableLambda(other) 来包装。
因此,你完全可以写出极其简洁的链:
python
chain = (
prompt
| model
| (lambda ai_msg: {"previous_answer": ai_msg.content}) # 把AIMessage包装成字典
| second_prompt
| model
| StrOutputParser()
)所以下面两种写法完全等价:
python
# 写法 1:显式包装(推荐------一看就知道是 Runnable)
chain = prompt | model | RunnableLambda(lambda x: x.content) | prompt2 | model
# 写法 2:直接传函数(简洁------LangChain 帮你自动包装)
chain = prompt | model | (lambda x: x.content) | prompt2 | model📝 建议 :简单的一两句
lambda,直接入链问题不大。复杂的逻辑还是老老实实用def+ 显式RunnableLambda(),一来代码可读性强,二来方便单独测试这个函数。
注意函数写法:
- 参数:就是上游传过来的数据(这里是
AIMessage对象) - 函数体:一个表达式,返回下游需要的数据(这里是字典)
5.3 Lambda 匿名函数的书写格式
Python 中 lambda 的基本语法:
python
lambda 参数: 返回值表达式注意:
lambda只能写一个表达式 ,不能有if-elif-else多行语句块(但可以用三元表达式)- 表达式的结果自动作为返回值,不需要写 return
python
# ===== 简单场景用 lambda =====
# 例 1:提取 content
lambda ai_msg: ai_msg.content
# 例 2:截取前 100 个字符
lambda ai_msg: ai_msg.content[:100]
# 例 3:构造字典(注意区分两个冒号的作用)
lambda ai_msg: {"summary": ai_msg.content, "tokens": ai_msg.usage_metadata.get("total_tokens", 0)}
# ↑ lambda语法 ↑ 字典的key-value分隔符
# 例 4:字段重命名
lambda d: {"topic": d["theme"], "content": d["body"]}
# 例 5:三元表达式(条件判断)
lambda ai_msg: ai_msg.content if len(ai_msg.content) < 500 else ai_msg.content[:500] + "..."
# ===== 复杂场景用 def =====
def complex_transform(ai_msg):
content = ai_msg.content.strip()
tokens = ai_msg.usage_metadata.get("total_tokens", 0) if ai_msg.usage_metadata else 0
if len(content) > 800:
content = content[:800] + "\n...(已截断)"
status = "truncated"
else:
status = "complete"
return {
"text": content,
"status": status,
"tokens": tokens,
}
runnable = RunnableLambda(complex_transform)6. 总结复盘
学到这里,咱们把整个知识点串成一张全景图。搭任何链,心里有类似这个数据图,就知道每一步数据变成了什么类型、能不能传给下一环:
┌─────────────────────────────────────────┐
│ LangChain 管道数据流转
└─────────────────────────────────────────┘
用户输入 (dict)
│
▼
┌──────────────┐ ┌──────────────┐
│ PromptTemplate│ │ChatPromptTemp│ 📥 两种 Prompt 都吃 dict
│ .invoke() │ │ .invoke() │
└──────┬───────┘ └──────┬───────┘
│ │
▼ ▼
┌──────────────┐ ┌──────────────┐
│StringPrompt │ │ChatPrompt │ 📤 输出不同,但都有 .to_messages()
│ Value │ │ Value │
└──────┬───────┘ └──────┬───────┘
│ │
└─────────┬──────────┘
│
▼
┌────────────────┐
│ Chat Model │ 📥 能吃:str / List[Message] / PromptValue
│ .invoke() │ 📤 吐出:AIMessage
└───────┬────────┘
│
▼
┌────────────────┐
│ AIMessage │
│ .content │
│ .usage_meta │
│ .response_meta│
└───────┬────────┘
│
┌──────────┼──────────┬──────────────┐
│ │ │ │
▼ ▼ ▼ ▼
┌────────┐ ┌────────┐ ┌──────────┐ ┌──────────────┐
│ Str │ │ Json │ │ Runnable │ │ 自定义函数 │
│ Output │ │ Output │ │ Lambda │ │ (自动包装) │
│ Parser │ │ Parser │ │ │ │ │
└───┬────┘ └───┬────┘ └────┬─────┘ └──────┬───────┘
│ │ │ │
▼ ▼ ▼ ▼
str dict 自定义类型 自定义类型
│ │ │ │
└──────────┼───────────┼───────────────┘
│
▼
可以喂给下一个 可以喂给下一个
model(吃str) prompt(吃dict)原则一:入链资格
只有
Runnable子类才能入链。不过 LangChain 的核心组件全都是 Runnable,而且普通函数会被自动包装------所以实际开发中你几乎不用操心"能不能入链"这件事。
原则二:类型匹配上游吐出的东西,下游得能接住。这是最容易踩坑的地方。 尤其当你自己写
RunnableLambda做自定义转换时,一定先看清楚下游组件需要什么类型的输入,再决定你的函数返回什么。
原则三:显式优于隐式LangChain 做了很多自动适配,自动包装函数、自动处理类型转换,这很方便,但出问题时也增加了排查难度。关键节点用显式的解析器或 RunnableLambda,不仅自己看起来清楚,日后读代码也一目了然。
以上为个人学习总结,旨在梳理个人理解。如有疏漏或不当之处,欢迎指正与交流。如果文章对你有帮助,别忘了点个赞、留个言,让更多的小伙伴看到~ 我们下篇再见!