#下载的时候不用着急,可能网络速度比较慢所以要等待的时间比较长(我体验下来基本上挺快的,不像自己电脑用校园网下载很不稳定,还会出现因网络波动导致下载失败的情况)
云环境注册与启动

注册登录AMD AI 开发者计划后,在Radeon Cloud启动Hello ROCm Bate的云环境:
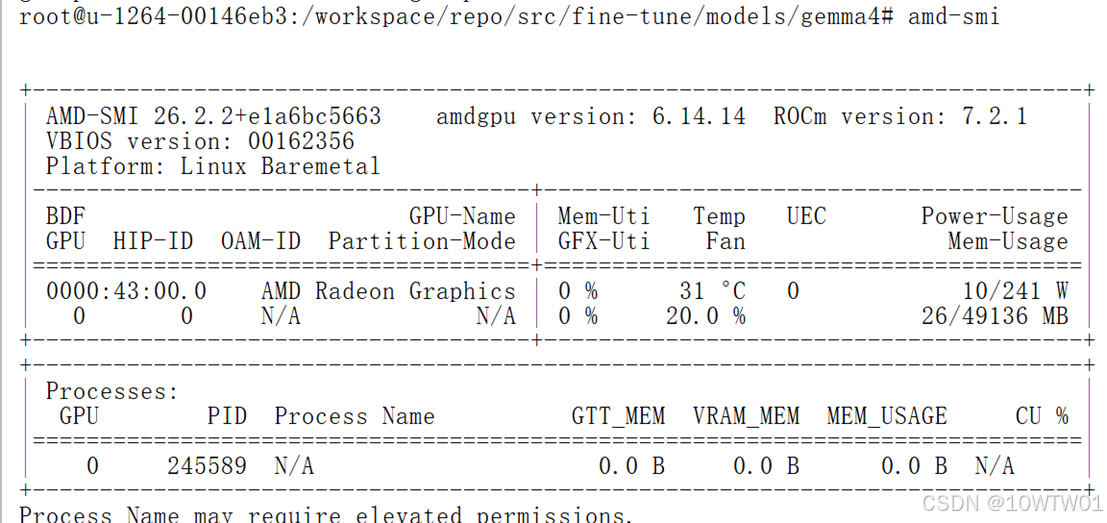
打开云环境,选择Terminal方式,输入amd-smi查看GPU:
输入一段Python程序查看GPU能否使用:
python -c "import torch; print('PyTorch:', torch.version); print('ROCm available:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')"

正常输出:
ROCm available: True
Device: AMD Radeon Graphics
下载 Gemma4 模型
切换国内镜像源:
pip config set global.index-url Simple Index
安装魔搭 ModelScope用于下载 Gemma4 模型
pip install modelscope
modelscope download --model google/gemma-4-E4B-it --cache_dir "./models"
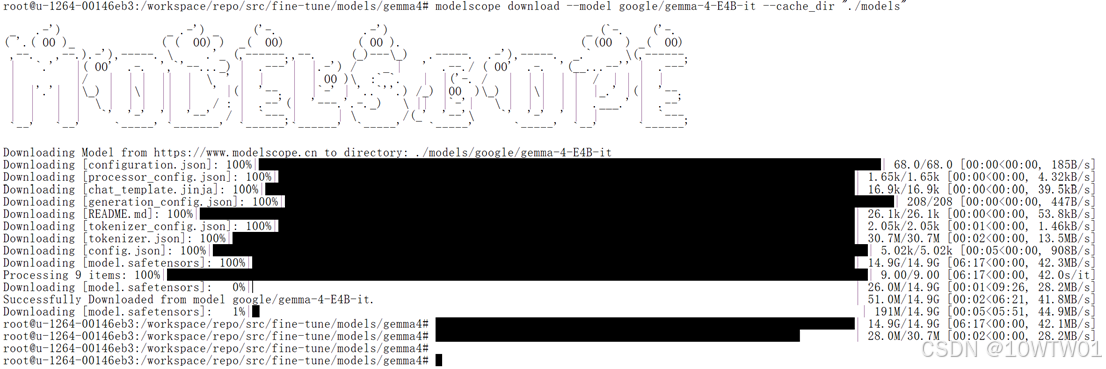
ls -lh ./models/google/gemma-4-E4B-it/
 此时gemma-4-E4B-it下载成功
此时gemma-4-E4B-it下载成功
启动 vLLM 服务
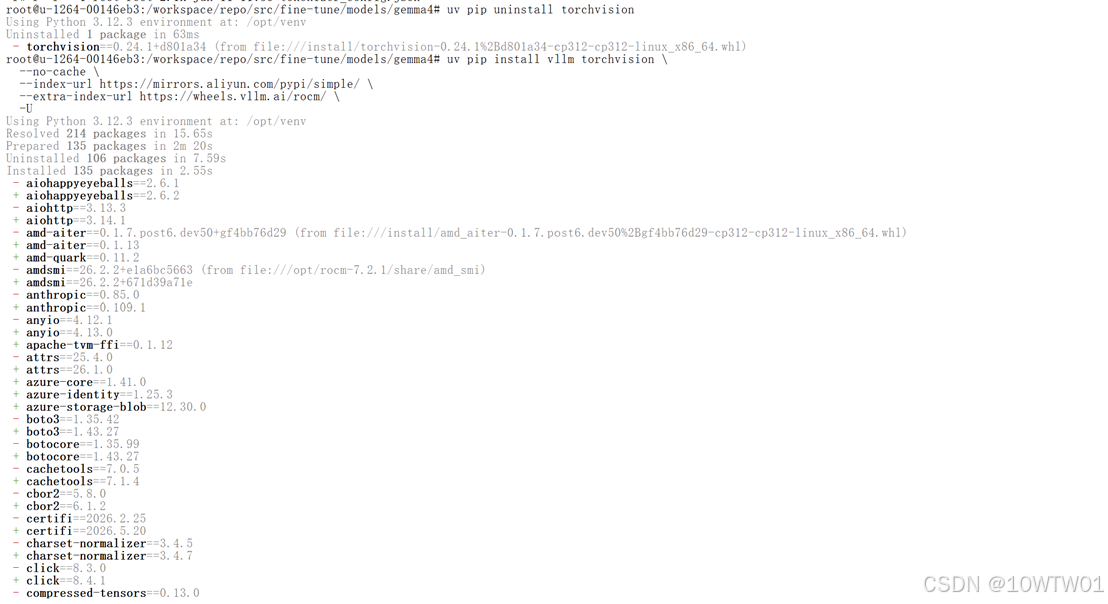
先卸载torchvision再连同vllm一起安装:
uv pip uninstall torchvision
uv pip install vllm torchvision \
--no-cache \
--index-url https://mirrors.aliyun.com/pypi/simple/ \
--extra-index-url https://wheels.vllm.ai/rocm/ \
-U
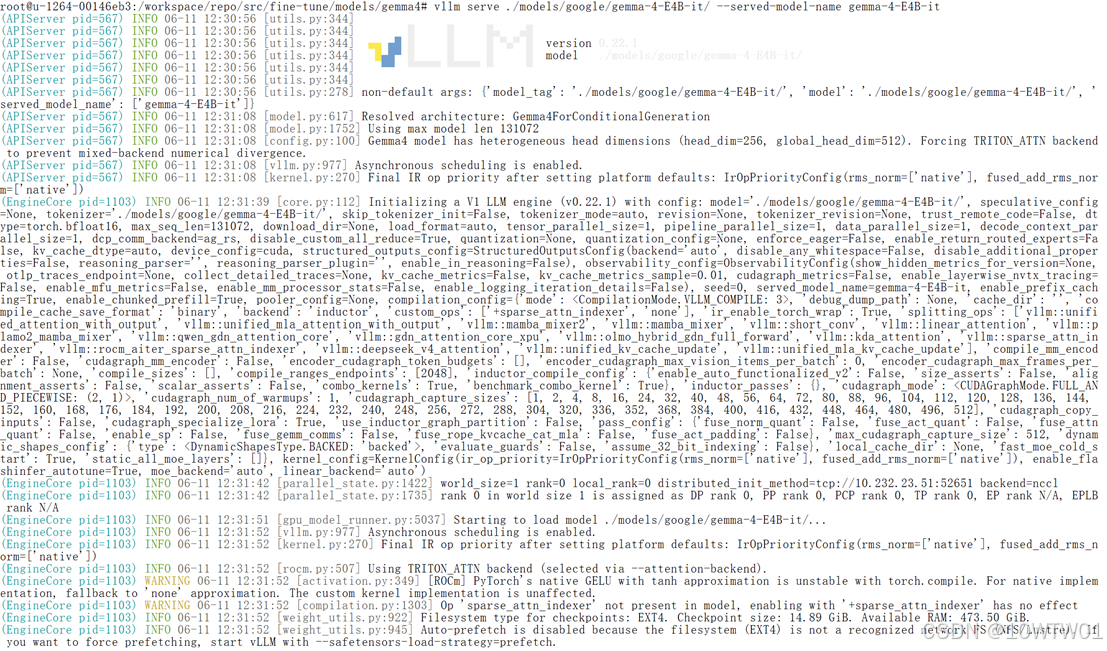
下载完就可以启动
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it
| 字段 / 术语 | 含义 | 示例值(来自日志) |
|---|---|---|
| model / model_tag | 模型文件或 Hugging Face 模型路径 | ./models/google/gemma-4-E4B-it/ |
| dtype | 模型推理使用的浮点数据类型 | torch.bfloat16 |
| max_seq_len | 模型支持的最大上下文长度(token 数) | 131072 |
| tensor_parallel_size | 张量并行使用的 GPU 数量 | 1 |
| pipeline_parallel_size | 流水线并行级数 | 1 |
| data_parallel_size | 数据并行副本数 | 1 |
| enable_prefix_caching | 是否开启前缀缓存,复用相同前缀的 KV 缓存 | True |
| enable_chunked_prefill | 是否将长 prompt 拆分为多个块进行预填充 | True |
| trust_remote_code | 是否信任 Hugging Face 仓库中的自定义模型代码 | False |
| quantization | 模型量化方法(None 表示未量化) | None |
| seed | 随机种子 | 0 |
| kv_cache_dtype | KV 缓存的数据类型,auto 为自动选择 | auto |
| compilation_config.mode | 编译模式,3 表示使用 vLLM 的 torch.compile 优化 | 3(VLLM_COMPILE) |
| Attention backend | 注意力计算后端,此处因模型异构头维度强制使用 Triton | TRITON_ATTN |
| Resolved architecture | 自动识别的模型架构类 | Gemma4ForConditionalGeneration |
| Asynchronous scheduling | 是否启用异步调度 | enabled |
| Available KV cache memory | GPU 显存中可分配给 KV 缓存的容量 | 27.25 GiB |
| GPU KV cache size | KV 缓存最多能容纳的 token 总数 | 1,701,816 tokens |
| Maximum concurrency | 在最大上下文长度下的理论最大并发请求数 | 12.98x |
| Model loading memory | 加载模型权重占用的 GPU 显存 | 15.16 GiB |
| Model loading time | 加载权重耗时 | 7.96 seconds |
| torch.compile time | torch.compile 总耗时(含图捕获前的编译) | 54.60 s |
| Compiling a graph for compile range | 为指定 token 范围编译计算图,并缓存该图 | (1, 2048) 耗时 44.75 s |
| Graph capturing time | 捕获 CUDA 图所花费的时间 | 19 secs |
| Graph capturing memory | 捕获 CUDA 图额外占用的 GPU 显存 | 3.28 GiB |
| Avg prompt throughput | 平均 prompt 处理吞吐量 | 7.3 tokens/s |
| Avg generation throughput | 平均 token 生成吞吐量 | 24.3 tokens/s |
| Prefix cache hit rate | 前缀缓存命中率 | 79.8% |
| Triton kernel JIT compilation | 推理时发生 Triton 内核即时编译,导致延迟抖动(警告) | _compute_slot_mapping_kernel, kernel_unified_attention |
| Generation config override | 模型自带的 generation_config.json 覆盖了默认采样参数 | temperature=1.0, top_k=64, top_p=0.95 |
| Multi-modal warmup failed | 多模态预热失败(通常因缺少多模态输入数据) | 警告信息 |
| Auto-prefetch disabled | 由于文件系统为 EXT4,非网络文件系统,自动预取被禁用 | 提示信息 |
| APIServer / EngineCore | 组件名:API 服务器进程 / 引擎核心进程 | APIServer pid=567, EngineCore pid=1103 |
| world_size=1 rank=0 local_rank=0 | 分布式训练/推理的总进程数、当前进程编号及本地 GPU 编号。这里是单卡,所以都是 0。 | world_size=1 rank=0 local_rank=0 |
| distributed_init_method=tcp://... | 分布式初始化方式,通过 TCP 地址同步进程。 | tcp://10.232.23.51:52651 |
| backend=nccl | 分布式通信后端,NCCL 用于 GPU 间通信。 | nccl |
| DP rank, PP rank, PCP rank, TP rank, EP rank, EPLB rank | 多维并行策略中各个维度的编号:数据并行 (DP)、流水线并行 (PP)、流水线块并行 (PCP)、张量并行 (TP)、专家并行 (EP)、专家负载均衡并行 (EPLB)。均为 0 表示未启用对应并行。 | DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A |
| Starting to load model | 开始从磁盘加载模型权重到 GPU。 | ./models/google/gemma-4-E4B-it/ |
| Asynchronous scheduling is enabled | 启用异步调度,允许 CPU 调度与 GPU 计算重叠执行。 | Asynchronous scheduling is enabled. |
| Final IR op priority | 中间表示层的算子优先级配置,指定哪些算子优先使用原生实现。这里 rms_norm 和 fused_add_rms_norm 使用 native 内核。 | IrOpPriorityConfig(rms_norm='native', fused_add_rms_norm='native') |
| Using TRITON_ATTN backend | 注意力计算后端选用 Triton,因为模型存在异构头维度,强制使用该后端以避免混合后端的数值差异。 | Using TRITON_ATTN backend (selected via --attention-backend). |
| sparse_attn_indexer | 自定义稀疏注意力索引算子。模型中没有该算子,强制启用它没有效果。 | Op 'sparse_attn_indexer' not present in model, enabling with '+sparse_attn_indexer' has no effect |
| Filesystem type for checkpoints: EXT4 | 存放模型检查点的文件系统类型为 EXT4(本地磁盘)。 | EXT4 |
| Checkpoint size: 14.89 GiB | 模型权重文件的总大小。 | 14.89 GiB |
| Available RAM: 473.50 GiB | 系统可用内存大小。 | 473.50 GiB |
| Loading safetensors checkpoint shards | 加载 safetensors 格式的权重分片,这里只有 1 个分片。 | 1/1 00:06\<00:00, 6.21s/it |
| Loading weights took 7.17 seconds | 加载模型权重到内存/显存实际耗时。 | 7.17 seconds |
| Model loading took 15.16 GiB memory and 7.959798 seconds | 模型加载完成后占用的 GPU 显存以及总加载时间。 | 15.16 GiB memory and 7.959798 seconds |
| Encoder cache will be initialized with a budget of 2496 tokens | 为多模态编码器缓存预分配 2496 个 token 的空间,并计划以 1 个最大特征尺寸的视频进行性能分析。 | budget of 2496 tokens, and profiled with 1 video items of the maximum feature size. |
| Using cache directory: ... for vLLM's torch.compile | torch.compile 编译缓存存放目录。 | /root/.cache/vllm/torch_compile_cache/... |
| Dynamo bytecode transform time: 7.93 s | TorchDynamo 将模型字节码转换为 FX 图所花费的时间。 | 7.93 s |
| Cache the graph of compile range (1, 2048) for later use | 对 token 范围 (1, 2048) 编译好的计算图进行缓存,后续复用。 | (1, 2048) |
| Compiling a graph for compile range (1, 2048) takes 44.75 s | 具体编译该范围计算图耗时。 | 44.75 s |
| saved AOT compiled function to ... | Ahead-Of-Time 编译生成的函数被保存到磁盘缓存路径。 | /root/.cache/vllm/torch_compile_cache/torch_aot_compile/.../model |
| torch.compile took 54.60 s in total | 从开始编译到结束总共花费 54.60 秒。 | 54.60 s |
| Initial profiling/warmup run took 0.83 s | 预热运行(profiling 阶段)耗时。 | 0.83 s |
| Available KV cache memory: 27.25 GiB | 可用于存储 KV 缓存的 GPU 显存大小。 | 27.25 GiB |
| GPU KV cache size: 1,701,816 tokens | KV 缓存最多可容纳的 token 总数。 | 1,701,816 tokens |
| Maximum concurrency for 131,072 tokens per request: 12.98x | 当每个请求占用最大上下文长度(131072 tokens)时,理论上最多可同时处理约 12.98 个请求。 | 12.98x |
| Kernel JIT monitor activated | 内核即时编译监控已启动,推理过程中发生的 Triton JIT 编译将以警告形式记录。 | Kernel JIT monitor activated --- Triton JIT compilations during inference will be logged as warnings. |
| Supported tasks: 'generate' | 该模型 API 支持的任务类型为文本生成。 | 'generate' |
| Default vLLM sampling parameters have been overridden... | 模型自带的 generation_config.json 覆盖了 vLLM 默认采样参数(温度 1.0, top_k 64, top_p 0.95)。 | {'temperature': 1.0, 'top_k': 64, 'top_p': 0.95} |
| Detected the chat template content format to be 'openai' | 检测到对话模板内容格式为 OpenAI 格式。 | 'openai' |
| Starting vLLM server on http://0.0.0.0:8000 | vLLM API 服务启动,监听所有网络接口的 8000 端口。 | http://0.0.0.0:8000 |
| Route: /v1/chat/completions, Methods: POST | 可用的 API 路由及其 HTTP 方法,例如 OpenAI 兼容的聊天补全接口。 | 列表中的多个路由,如 /v1/chat/completions |
启动所需时间比较长,我是06-11 12:30:56 启动到06-11 12:33:32才加载成功
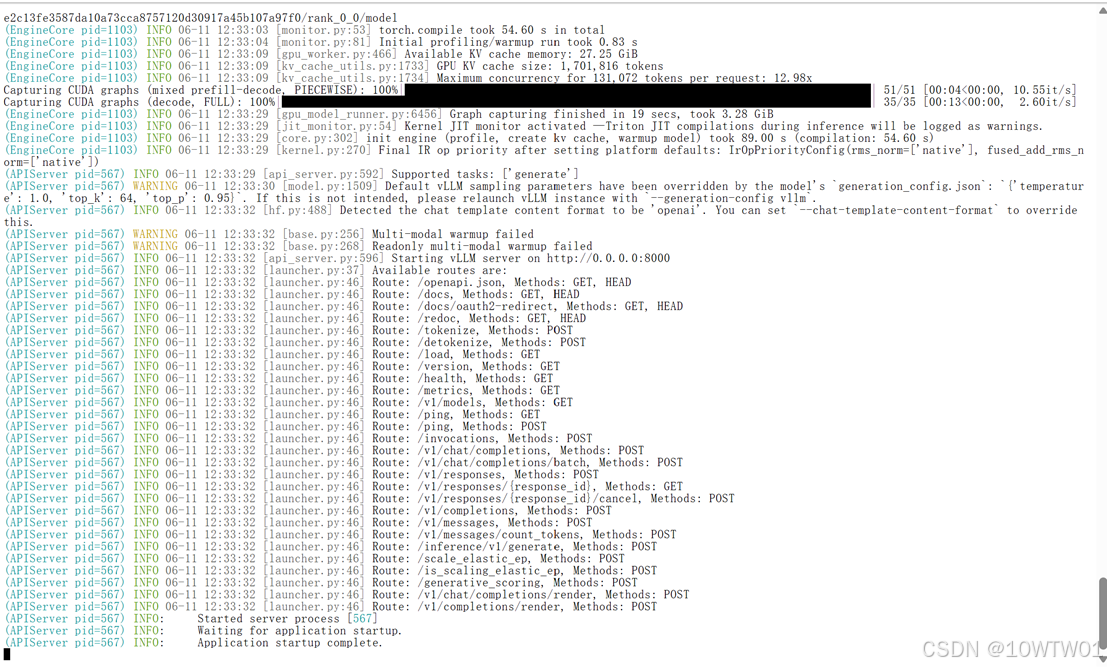
这时候不要关闭terminal窗口,因为此时vllm程序相当于一个后端程序在跑了,为我们提供模型服务。
启动成功后,我们不妨用amd-smi看一下用vllm运行16GB的gemma4要占用多少资源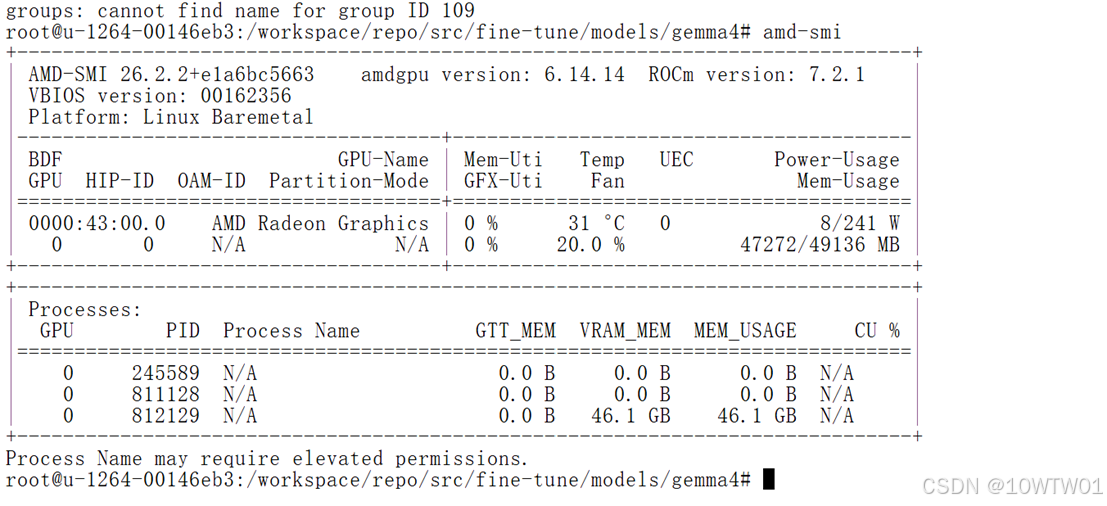
可以看到GPU 目前计算负载很低(GFX-Uti即图形/计算核心利用率 0%、功耗仅 8W),而已用显存 / 总显存达到了47272/49136 MB,都被PID=812129进程就是我们运行的AI推理任务所占用(换算下就知道了47272 MB**=**46.1640625 GB约等于46.1GB)。也就是为什么后面要结束推理进程释放显存空间用于微调。
#Mem-Uti 是显存带宽 利用率,而 Mem-Usage 是容量占用,两者不同
打开新终端进行对话测试
vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-it
然后看到Please enter a message for the chat model:就说明已经连接上就可以对话了,
这里我输入了回车,教程里给的示例是经典的"你是谁,你能做什么"。
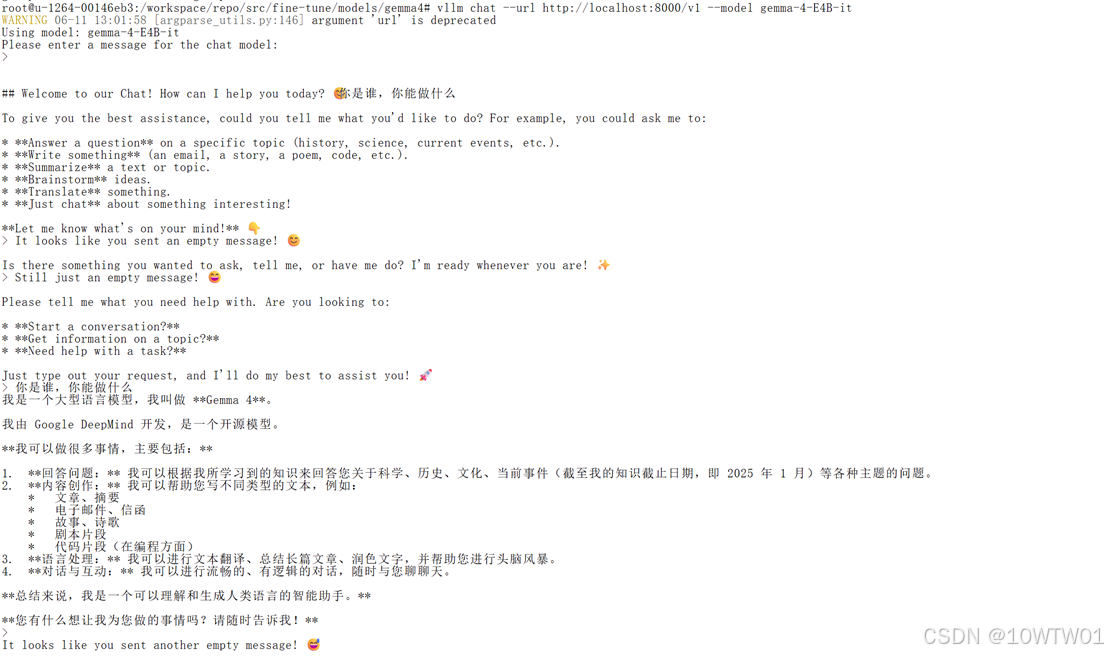
然后在用vllm运行gemma-4模型的terminal下可以看到:


因为上面我在客户端输入了3次请求(一次回车+一次"你是谁,你能做什么"+一次回车),所以服务器端生成了3次回复:
| 日志行片段 / 字段 | 含义 | 示例(来自日志) |
|---|---|---|
| 127.0.0.1:35910 - "POST /v1/chat/completions HTTP/1.1" 200 OK | API 服务器收到来自本地的聊天补全请求,并成功返回 200 状态码。 | 来源 IP 127.0.0.1,端口 35910,接口 /v1/chat/completions |
| Triton kernel JIT compilation during inference: _compute_slot_mapping_kernel | 推理过程中触发 Triton 内核的即时编译(JIT),引起单次请求的延迟增加(延迟尖峰)。建议扩展预热范围以覆盖此形状/配置。 | 内核名:_compute_slot_mapping_kernel |
| Avg prompt throughput | 过去一段时间内平均 prompt 处理吞吐量(token/秒)。 | 7.3 tokens/s、6.4 tokens/s、0.0 tokens/s |
| Avg generation throughput | 过去一段时间内平均 token 生成吞吐量(token/秒)。 | 24.3 tokens/s、25.8 tokens/s、3.4 tokens/s、0.0 tokens/s |
| Running: 0 reqs / Running: 1 reqs | 当前正在引擎中执行(生成 token)的请求数量。 | 0 reqs、1 reqs |
| Waiting: 0 reqs | 当前排队等待调度的请求数量。 | 0 reqs(始终为 0,说明没有排队) |
| GPU KV cache usage | GPU 上 KV 缓存的使用率(百分比)。 | 0.0%、0.1% |
| Prefix cache hit rate | 前缀缓存命中率,即新请求的前缀 token 中有多大比例复用了已缓存的 KV 计算。 | 79.8%、88.5% |
| Engine 000 | 日志来源引擎编号,000 表示第一个(也是唯一)推理引擎。 | Engine 000 |
| loggers.py:271 | 打印统计信息的代码位置,方便定位源码。 | 文件 loggers.py,行号 271 |
这里面就可以很直观的看到一些生成的参数比如POST /v1/chat/completions出现了三次,即请求了三次服务。然后我对使用LLM API服务时也经常会看到的字段GPU KV cache和Prefix Cache展开了调研:
什么是 GPU KV cache?(内存)
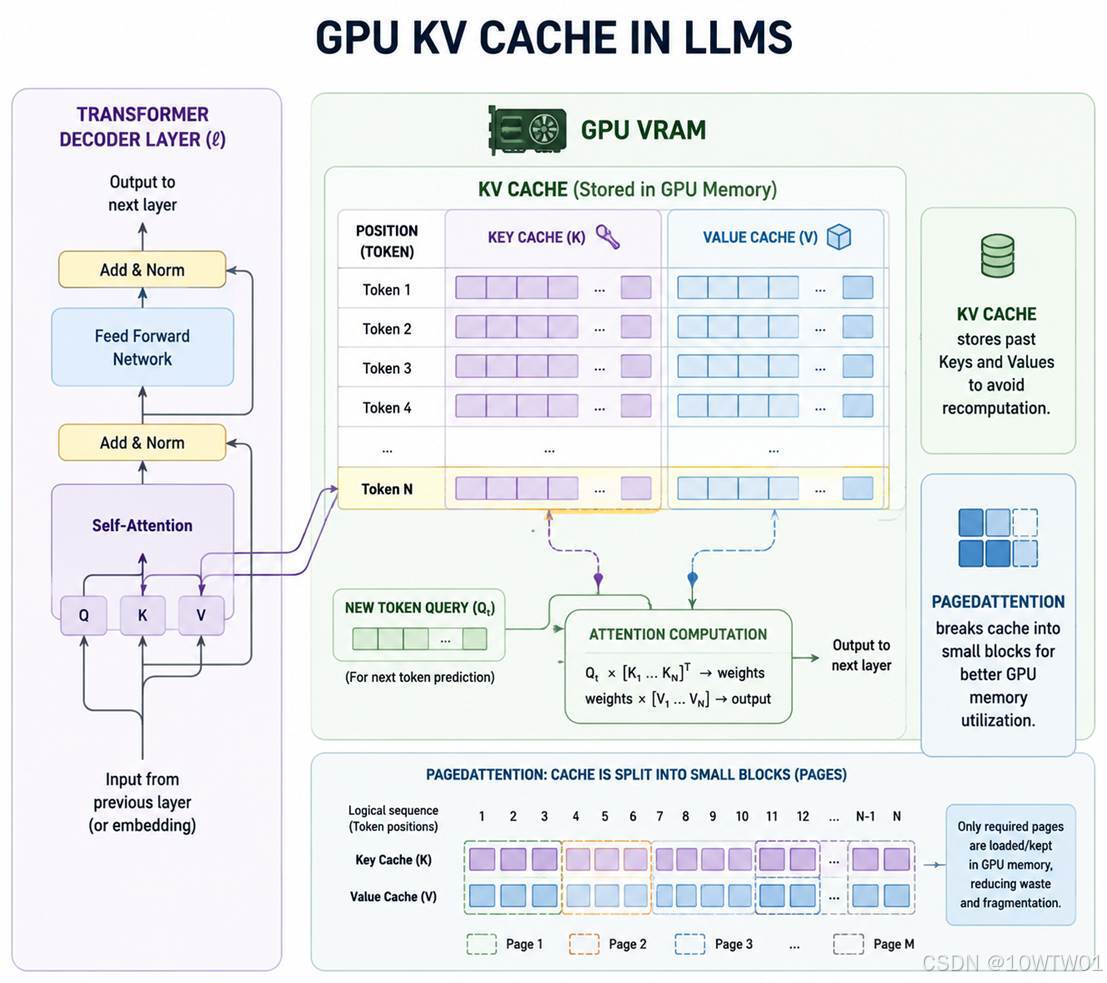
在 Transformer 自回归生成中,模型每预测一个新 token,都需要对所有历史 token 计算注意力。为避免每次都重新计算,会把每个位置的 Key(K)和 Value(V)矩阵 缓存下来,这就是 KV cache。GPU KV cache 特指这些缓存存储在 GPU 显存(VRAM)中,是推理吞吐和显存占用的核心瓶颈。
- 没有 KV cache:生成第 N 个 token 要算 N 次注意力,复杂度 O(n²)
- 有 KV cache:只需要用新 token 的 Q 去查之前缓存的 K、V,复杂度降到 O(n)
代价:随着序列变长,KV cache 线性增长,塞满显存。
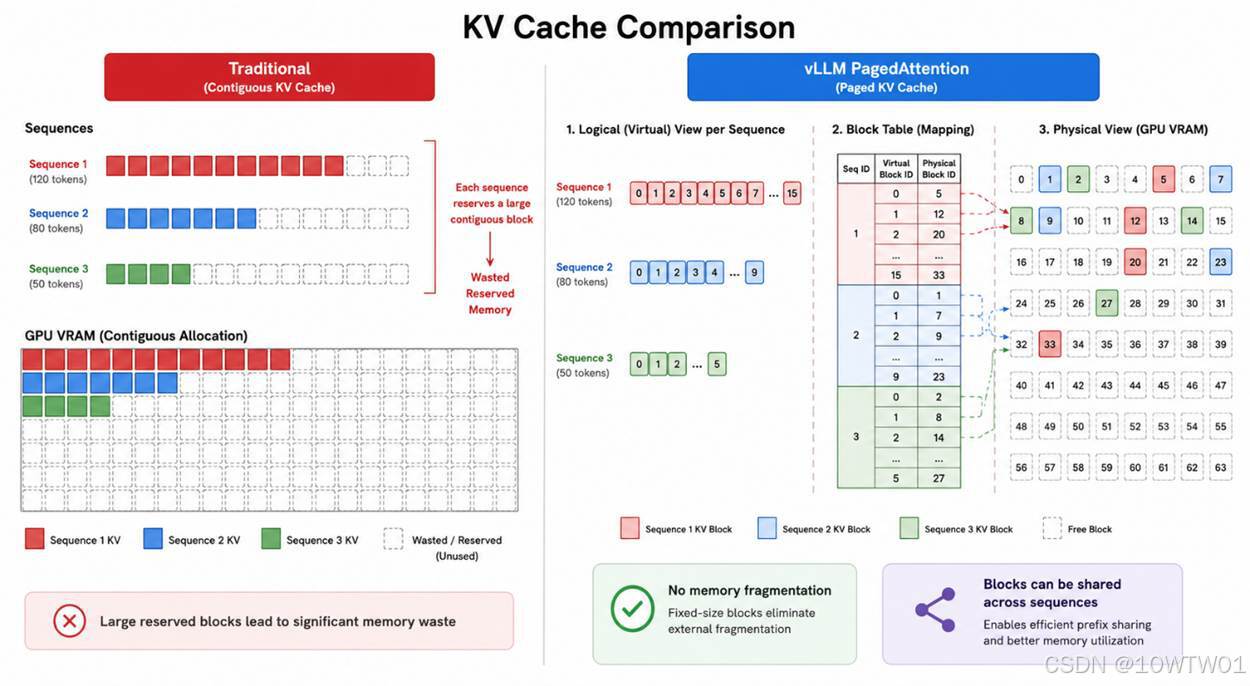
PagedAttention
传统做法是给每个序列预留一整块连续显存,导致显存碎片化、利用率低(比如预留了 2048 但只用 100,跟操作系统中的内存分配类似)。vLLM 把 KV cache 切成无数个小的物理块(Block),就像操作系统的虚拟内存分页一样:
逻辑上连续的 KV cache 可以分散在显存的不同地方,几乎零浪费,同一个 Block 还能在不同请求间共享(例如相同的系统提示)
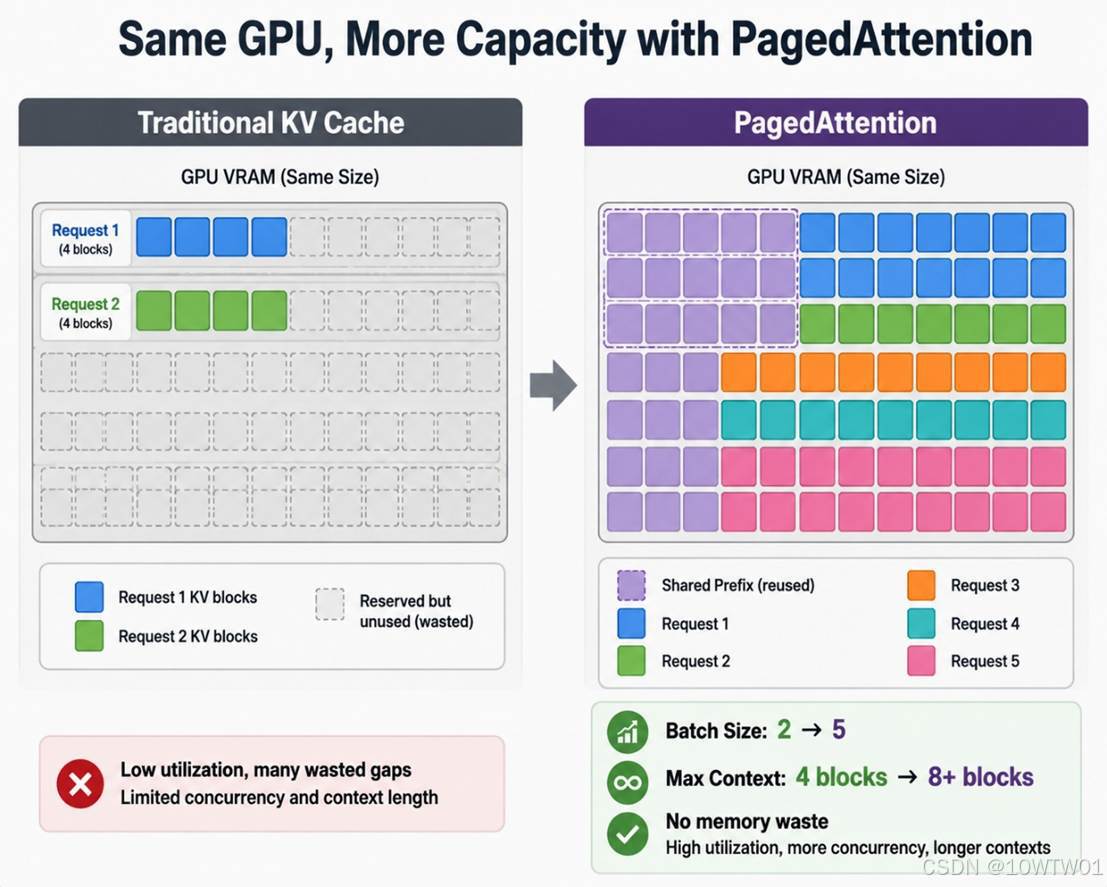
PagedAttention 通过上述方式相比传统方式,能在相同的GPU 上支持更大 batch(服务的请求数)、更长context(上下文)。
什么是 Prefix Cache?(内存复用)
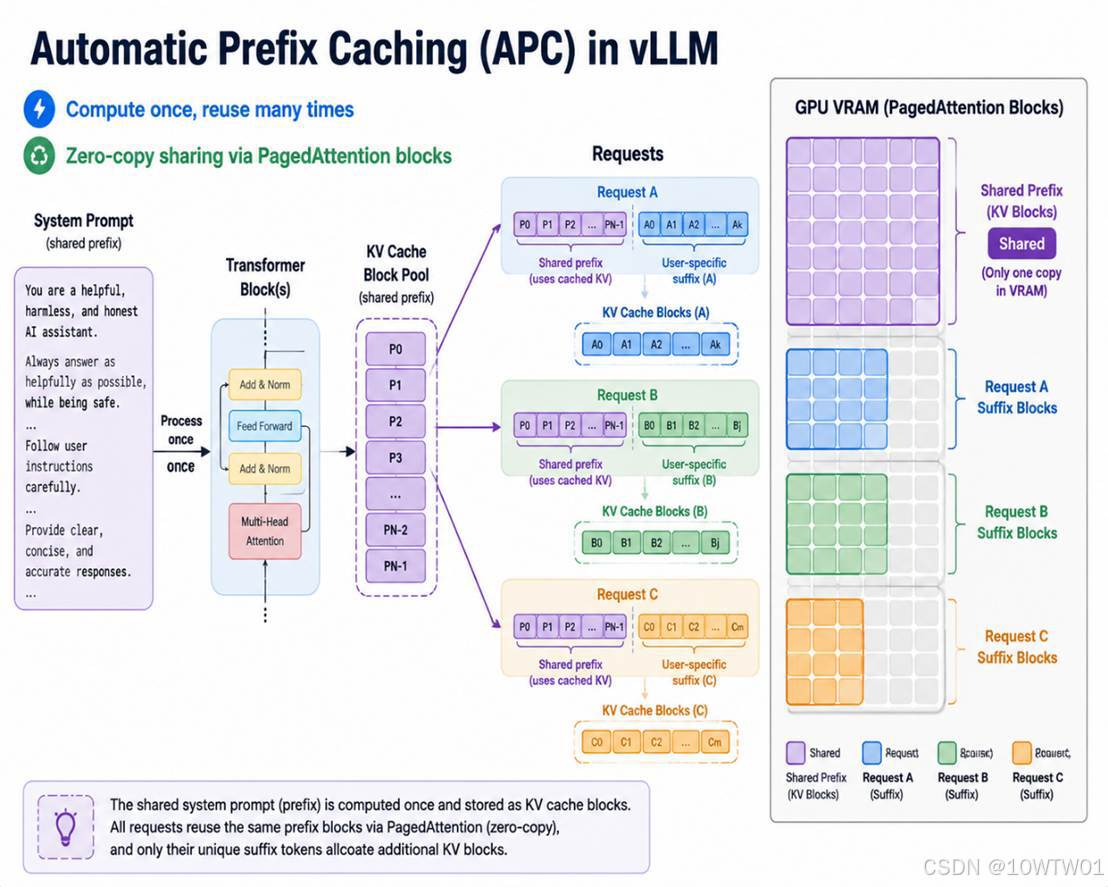
在 LLM 服务中,很多请求的开头完全一样,比如:
- 相同的系统提示(system prompt)
- 相同的 few-shot 示例
- 相同的对话历史前缀
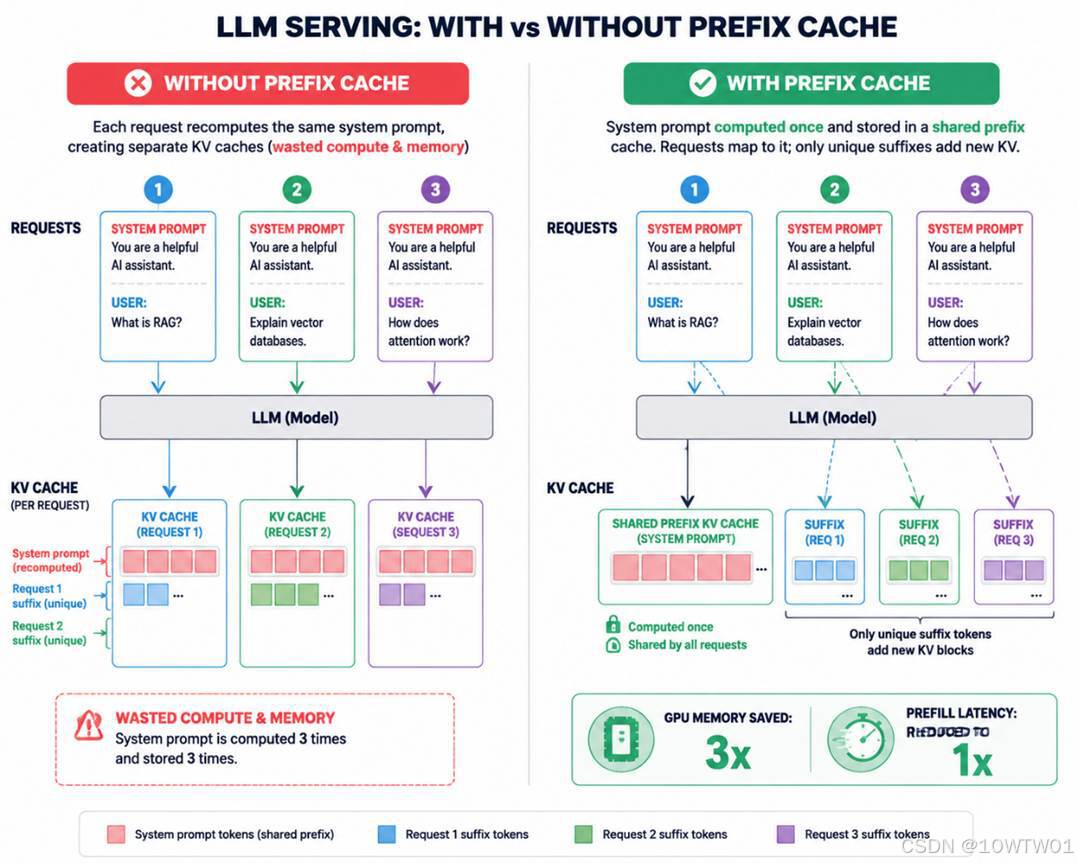
传统做法下,每个请求都要独立地对这段前缀计算一次自注意力、生成完整 KV cache,哪怕内容一模一样。
Prefix Cache 的思路:既然前缀相同,算出来的 K、V 也就相同,那就算一次,缓存起来,让后续所有请求直接复用这段 KV cache 块。
- vLLM 中的自动前缀缓存(Automatic Prefix Caching, APC)
- vLLM 基于 PagedAttention 的块(Block)级管理实现自动前缀缓存:
当新请求到来,vLLM 会检查其 prompt token 序列中,是否有某个物理块里的内容跟之前已缓存的块完全匹配。匹配上的块,直接映射到该请求的逻辑 KV cache 中,物理上零拷贝共享。只有前缀后面不同的部分才需要新算和分配新块。
这样带来的好处:
-
- 节省预填充(prefill)时间:前缀计算只需做一次,后续请求秒级跳过。
- 节省 GPU 显存:N 个请求共享同一套系统提示的 KV cache,显存只占 1 份,而不是 N 份。
特别适合聊天机器人:系统提示可能几千个 token,在每轮对话中都出现,有了前缀缓存,显存压力骤降。
关闭 vLLM 服务
经典Ctrl +C即可快速撤离.
