目录
Gemma4介绍
Gemma 4 是 Google DeepMind 于 2026 年 4 月推出的一系列最新、最强的开源大模型。它的定位非常明确:以极高的"参数效率"为核心,将强大的 AI 能力从云端带到你的手机、电脑等本地设备上。
相比上一代 Gemma 3 27B 模型,Gemma 4 的性能实现了飞跃式提升 :
速度与功耗:速度比前代快4倍,耗电量最多可减少60% 。数学能力:在 AIME 2026 数学竞赛测试中,准确率从 20.8% 暴涨至 89.2% 。编程能力:在 LiveCodeBench 代码测试中,得分从 29.1% 提升至 80.0% 。
Gemma 4 是 Google 在开源大模型领域的一次重磅反击。它以 Apache 2.0 许可证开放,提供了一系列从手机到服务器的模型,主打高效、多模态和原生智能体能力,旨在让开发者能在任何地方(尤其是本地设备)构建强大、低成本且保护隐私的 AI 应用。
一、Gemma 4 各版本参数对比
| 模型版本 | 总参数量 | 有效/激活参数量 | 核心定位与特点 |
|---|---|---|---|
| Gemma 4-E2B | 51亿 | 23亿 | 极致轻量:专为手机等移动端设备设计,内存占用可低至1.5GB以下,普通安卓手机就能完全离线运行,速度最快。 |
| Gemma 4-E4B | 80亿 | 45亿 | 性能与功耗平衡:适合需要更强推理能力的复杂任务,是端侧设备的主力版本。 (本次使用的模型) |
| Gemma 4-26B A4B (MoE) | 252亿 | 38亿 | 速度与性能的完美平衡:采用混合专家(MoE)架构,推理速度接近40亿参数的模型,但性能却能媲美310亿参数的模型,性价比极高。 |
| Gemma 4-31B (Dense) | 310亿 | 310亿 (全激活) | 性能旗舰:用310亿参数达到了开源模型性能的顶峰,在权威榜单上排名全球第三,性能可超越比自己大20倍的模型。 |
本文主要使用AMD显卡进行大模型Gemma4的推理部署测试。
介绍ROCm:ROCm(Radeon Open Compute)是AMD推出的开源GPU计算平台,专为高性能计算(HPC)、机器学习、深度学习等场景设计。它支持AMD的Radeon Instinct和部分消费级显卡,提供与CUDA类似的编程环境,但基于开放标准。
-
核心组件
1、编程模型与工具:最核心的是 HIP (异构计算接口可移植性)。HIP是一个C++运行时API,它的一大亮点是代码移植性------你可以用它编写能在AMD和NVIDIA GPU上都能运行的代码。AMD还提供了HIPIFY工具,能帮助将现有的CUDA代码自动转换为HIP代码,降低迁移成本。
2、优化的库:ROCm提供了针对AI和高性能计算优化的各类计算库,例如:AI/ML库:如 MIOpen(深度学习库);数学库:如 rocBLAS(线性代数)、rocFFT(傅里叶变换);通信库:如 RCCL,用于多GPU通信。
3、开发者工具:包含用于性能分析的ROCprofiler、调试的ROCgdb、系统监控的AMD SMI等一系列完整的开发和调试工具。
-
ROCm 与 CUDA 对比
| 特性 | ROCm | CUDA |
|---|---|---|
| 厂商 | AMD | NVIDIA |
| 开源 | 是 | 否 |
| 跨平台支持 | 部分支持 | 全平台 |
| 生态系统 | MIOpen、rocBLAS | cuDNN、cuBLAS |
二、环境准备
运行环境可以为以下两种方式:
- 1、本地有带特定AMD Radeon显卡或AMD Instinct™ 系列专业计算卡的主机(显存需要16G+,或者内存有32G以上,Python3.12),并且安装ROCm驱动
- 2、云端服务(带AMD显卡,ROCm=7.2.1,Python3.12,入手快)
本文档采用AMD提供的开发者算力进行云端Gemm4的免费部署测试。
- 1、打开AMD开发者网站https://developer.amd.com.cn/,登录账号(没有账号提前注册就可以),点击"我的权益",领取"积分免费兑换云额度",下拉跳转的网页到底部,点击"立即兑换",确认用100积分兑换100个小时的云端服务使用时间。

- 2、打开AMD开发者云https://radeon.anruicloud.com/服务平台
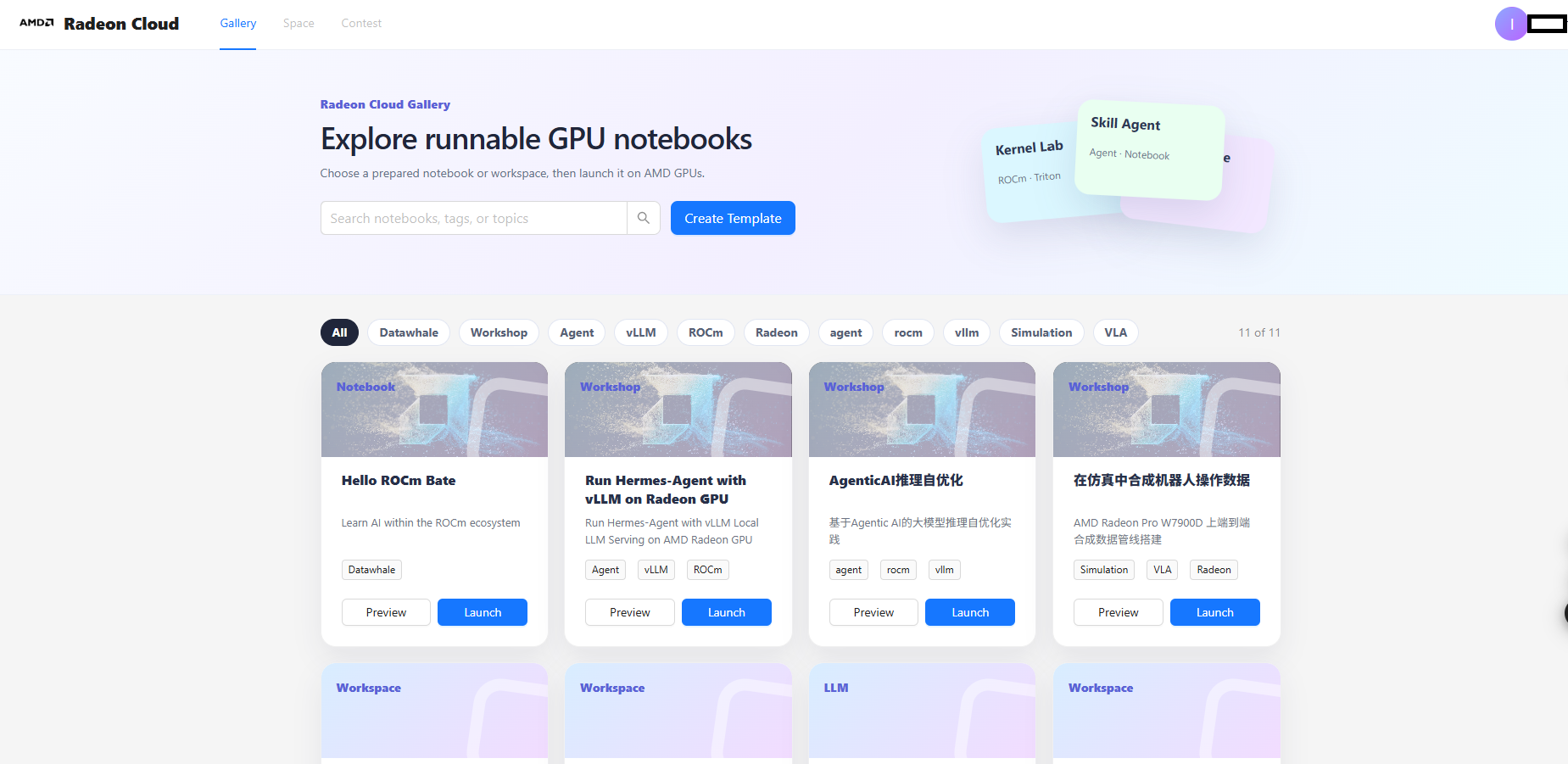
-
2、点击
"Launch",稍等3秒,会有"Open Notebook"的提示,点击即可使用云端的AMD显卡环境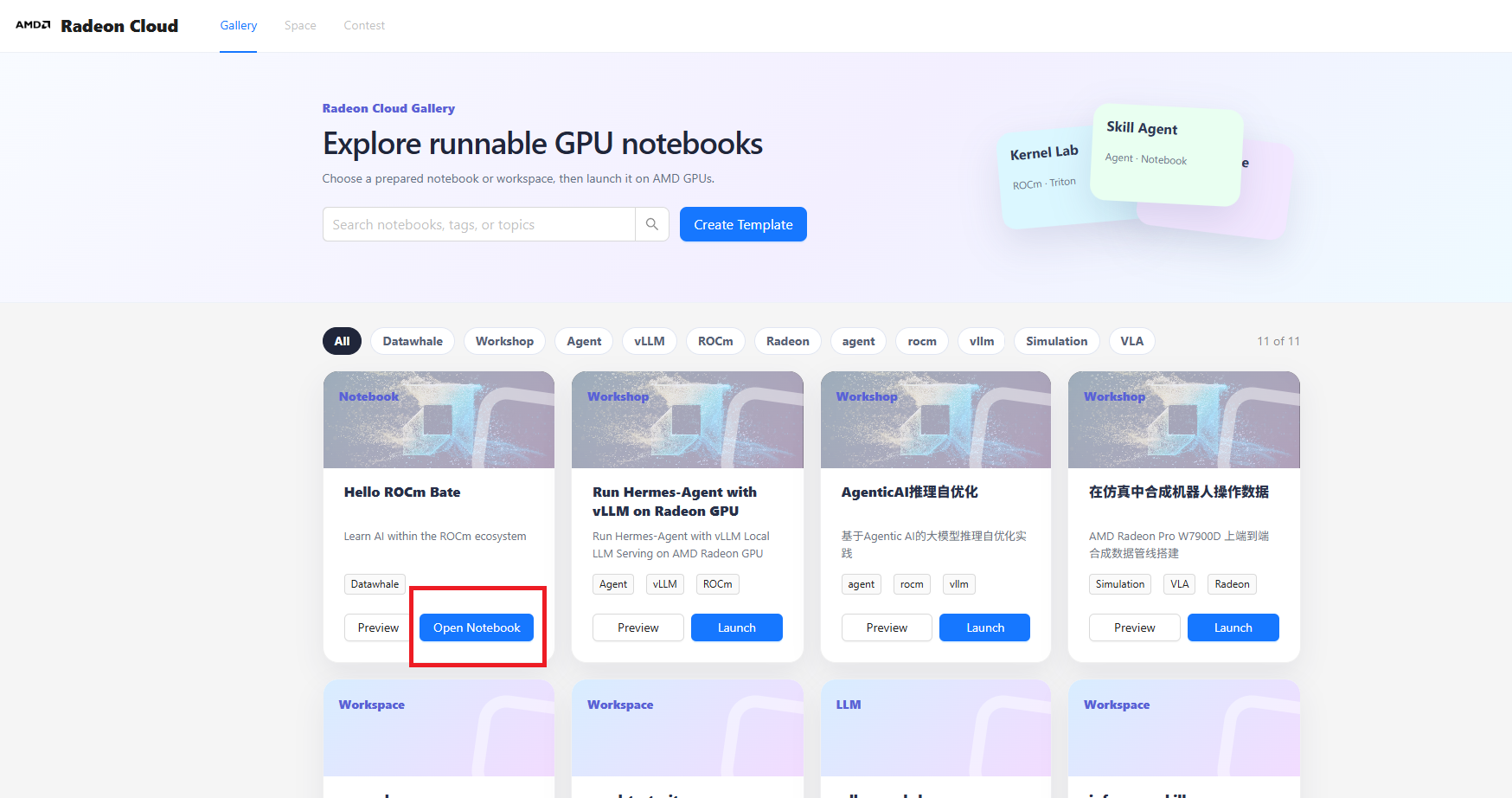
-
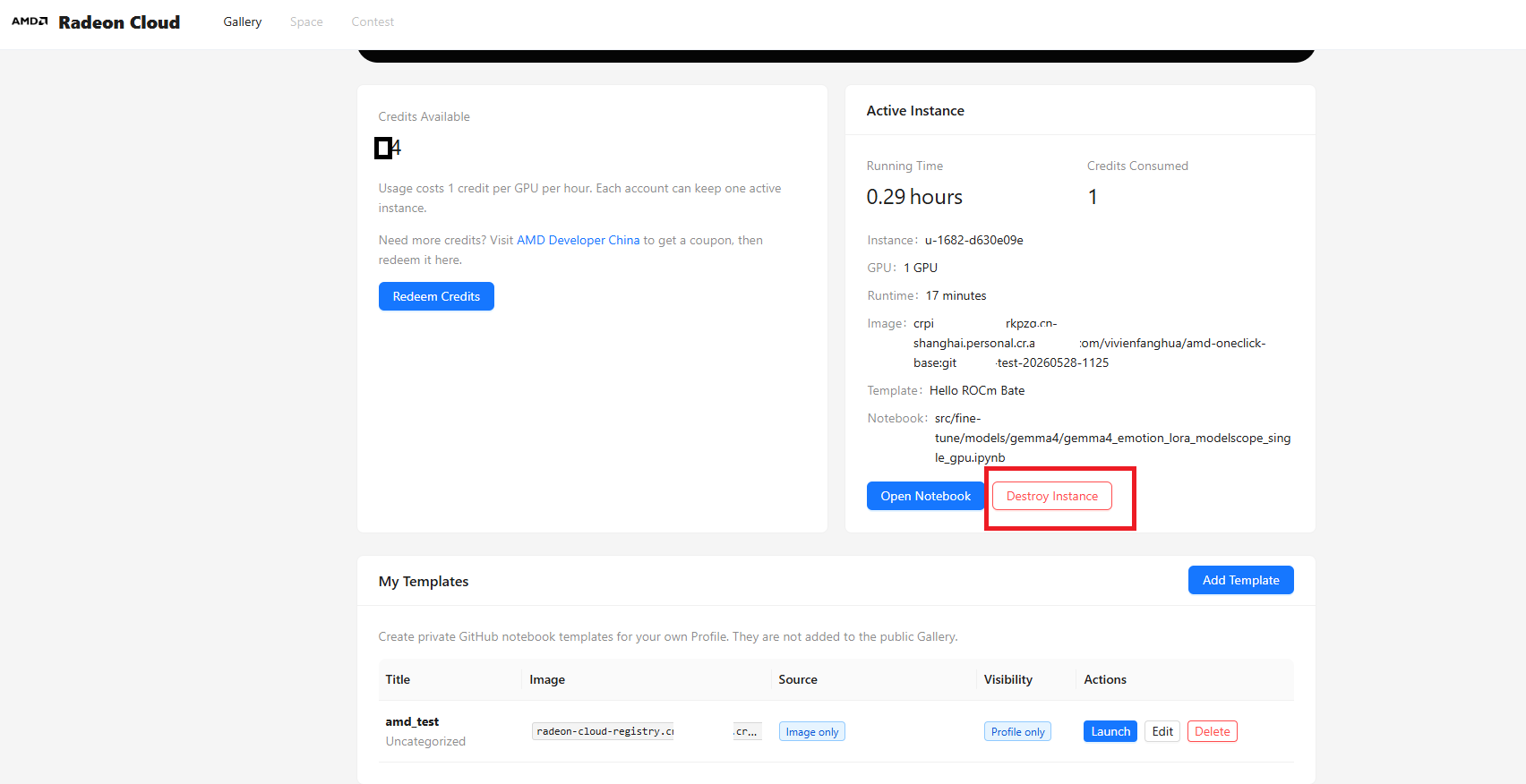
3、正确释放云端资源,避免不必要的积分浪费
如下图,点击右上角"Profile",进入资源设置。
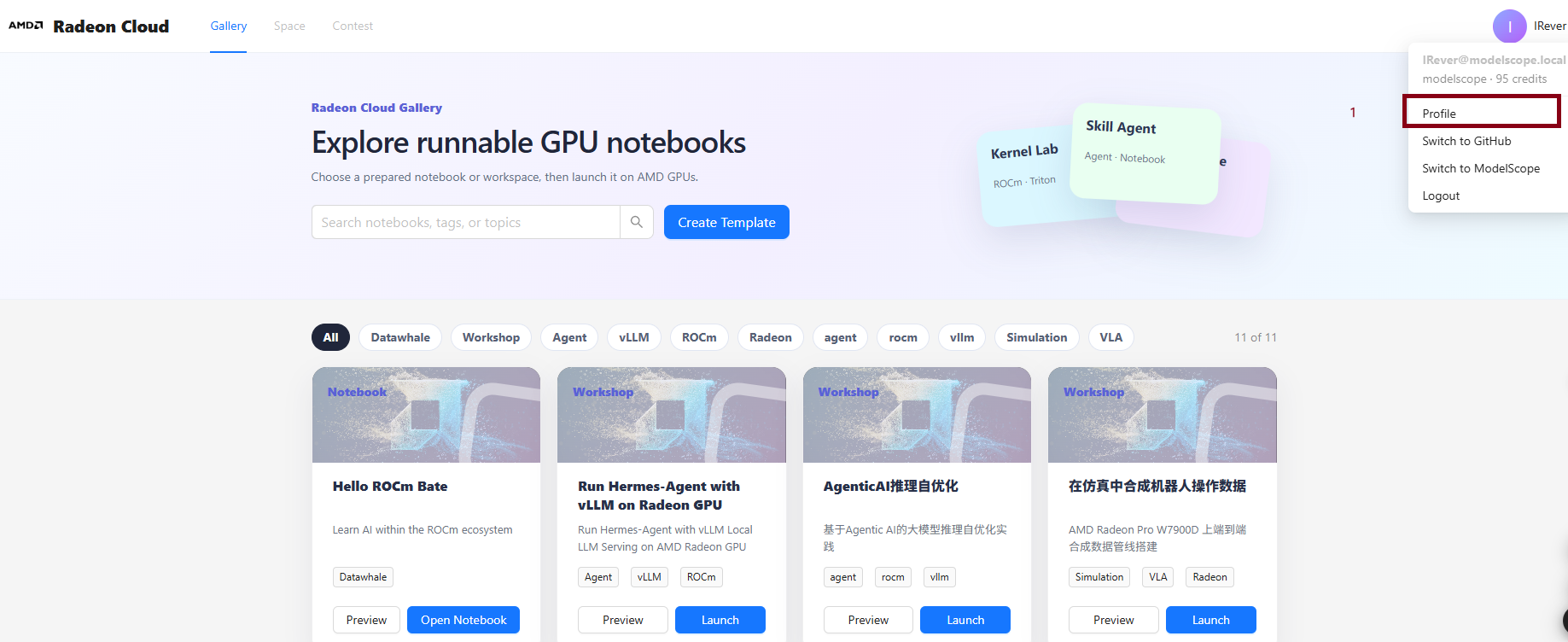
点击"Destory Instance"删除刚刚创建的实例,这样才能真正避免资源浪费。
三、部署测试
- 在jupyter中创建一个终端,输入以下命令以确认显存资源:
shell
amd-smi 输出结果中的Mem-Usage对应的显存数量即为当前显存占用,如26/49136MB即表示49GB显存有26MB当前被占用。
- 确认 PyTorch 能识别 AMD GPU,在终端输入:
shell
python -c "import torch; print('PyTorch:', torch.__version__); print('ROCm available:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')"- 下载Gemma4模型
shell
# 为了提升国内环境下的依赖下载速度,先把 pip 源切换到腾讯云镜像
pip config set global.index-url https://mirrors.cloud.tencent.com/pypi/simple/
# 安装 魔搭 ModelScope
pip install modelscope
# 下载 Gemma4 模型到当前的models目录
modelscope download --model google/gemma-4-E4B-it --cache_dir "./models"
# 确认 Gemma4 模型模型文件完整下载成功
ls -lh ./models/google/gemma-4-E4B-it/实测结果如下图所示:
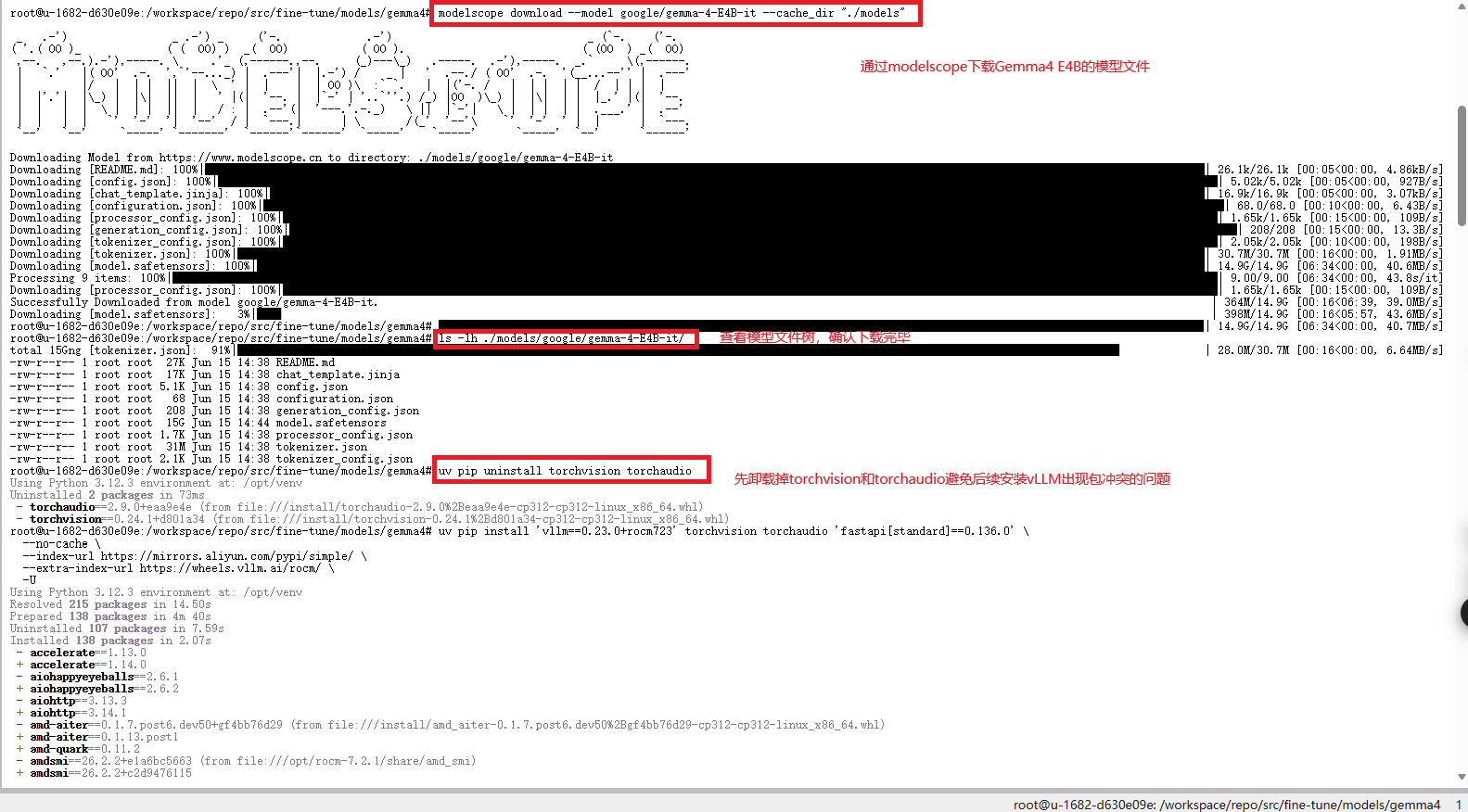
- 启动vLLM服务:vLLM 是一个本地高效推理大模型的项目,这里我们使用vLLM来测试刚才下载的模型能否正常使用。
shell
# 需更新云环境中的 vLLM 版本
uv pip uninstall torchvision torchaudio # 经测试,在该云环境中,需卸载重新安装两个库才能正常使用
uv pip install 'vllm==0.23.0+rocm723' torchvision torchaudio 'fastapi[standard]==0.136.0' \
--no-cache \
--index-url https://mirrors.aliyun.com/pypi/simple/ \
--extra-index-url https://wheels.vllm.ai/rocm/ \
-U
# 启动vLLM服务
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it实测结果如下图所示:
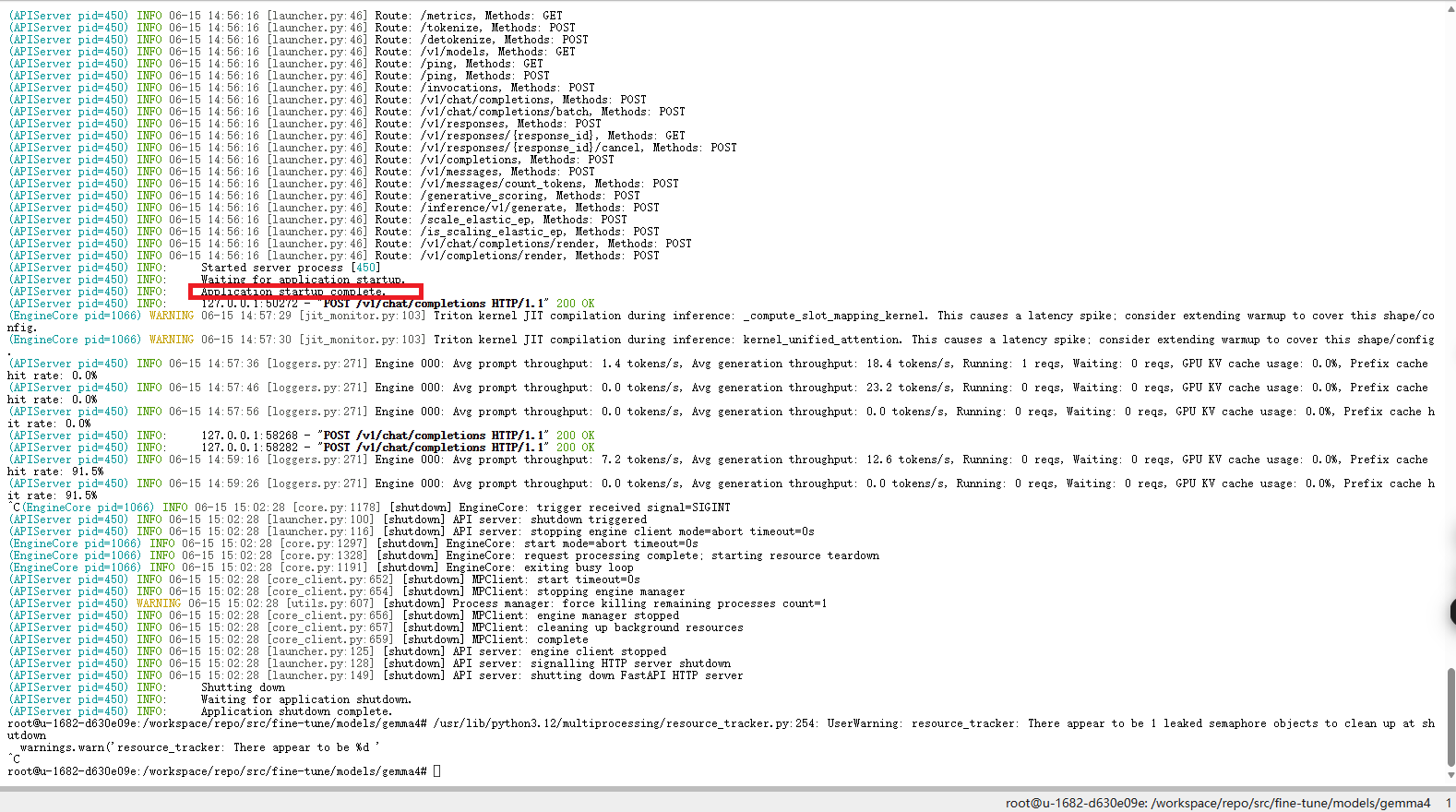
如果终端出现红色框中的文字则可认为Gemma4对话服务已启动。
如果需要关闭服务,按Ctrl+C退出。
- 另开一个终端,输入以下命令即可进行与Gemma4模型对话:
shell
vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-it实测结果如下图所示:
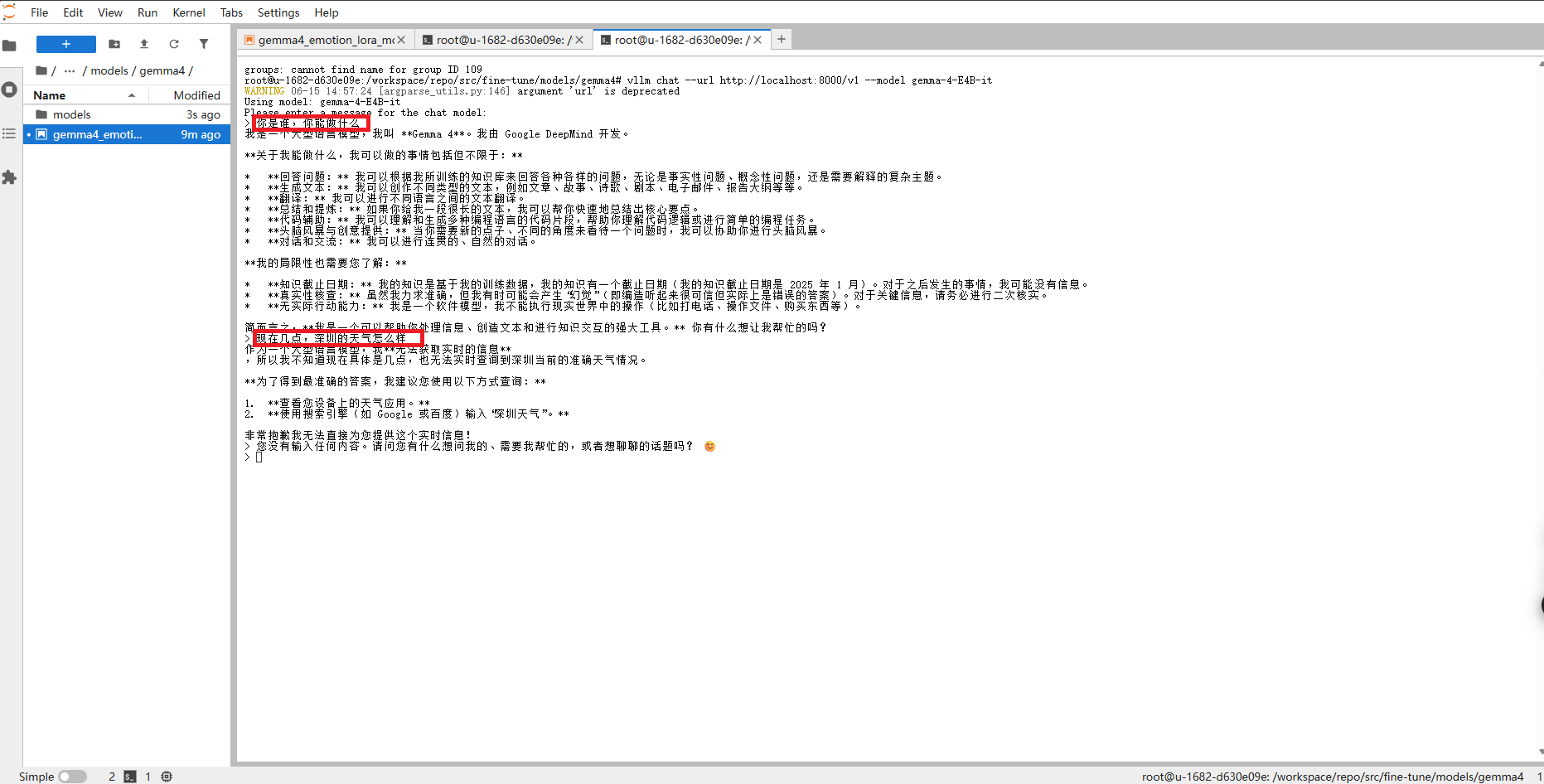
输入问题,Gemma4能有回复,但无法获知自身未知的客观现象,如天气和时间,后续可结合工具函数进行prompt,构造一个智能体。
如果需要关闭服务,按Ctrl+C退出。
四、后续微调
读者可参考https://radeon.anruicloud.com/templates/257/preview的单卡微调Gemma4 E4B-it对模型进行LORA微调,加深并且掌握使用AMD对大模型进行微调的方法。
✨🎉**最后,感谢Datawhale平台提供机会,让笔者能接触到AMD在大模型部署/微调这块的一些工作。**✨🎉