模块 1:通义向量模型核心认知
1.1 一句话讲透:通义向量模型到底是什么?
通义向量模型是阿里云通义千问团队推出的、专门针对中文语义优化的文本向量模型,是国内企业级 RAG 项目的主流选型之一,你可以把它理解成「中文语义理解能力拉满的国产向量生成工具」。
通义向量模型的核心作用也是:把中文文本转换成代表语义的固定长度数字向量,实现「语义越像、向量越近」的精准匹配,是 RAG 系统精准检索的核心底层技术。
模块 2:环境准备与账号配置
方案:零基础首选【通义千问云端向量 API】(90% 的零基础用户都选这个)
步骤1:开通通义千问服务,创建 API-KEY
通义千问管理控制台:通义千问
步骤 2:安装核心依赖包
打开终端 / 命令提示符,执行下面的命令,安装通义向量调用的核心依赖,用国内清华镜像,速度快,无包冲突:
bash
pip install dashscope scikit-learn numpy -i https://pypi.tuna.tsinghua.edu.cn/simple- dashscope:阿里云通义千问的官方 Python SDK,专门用来调用通义向量模型
- scikit-learn/numpy:用来计算向量相似度
安装完成后,执行下面的命令,验证安装是否成功:
bash
python -c "import dashscope; print(' dashscope安装成功,通义向量调用环境准备完成!')"
实操代码
python
# -*- coding: utf-8 -*-
"""
@Created on : 2026/6/10 11:20
@creator : er_nao
@File :day_90.py
@Description :通义向量模型调用
"""
# 导入通义千问官方SDK
import dashscope
from dashscope import TextEmbedding
import numpy as np
from config import TONGYI_API_KEY
import json
# ====================== 核心配置:替换成你自己的API-KEY ======================
# 把你之前在阿里云控制台复制的API-KEY粘贴到这里
dashscope.api_key = TONGYI_API_KEY
# 向量结果保存路径
output_save_path = "C:\\Users\\hp\\Desktop\\NLP学习数据\\通义向量批量生成结果.json"
# ==================================================================================
"""
# 实操 1:云端 API 单文本向量生成
核心目标:掌握通义向量 API 的核心调用方法,给单条文本生成向量,直观看到向量的样子。
"""
# 核心函数:调用通义向量模型,给单条文本生成向量
def generate_tongyi_embedding(text: str) -> np.ndarray:
"""
调用通义千问向量模型,给单条中文文本生成embedding向量
:param text: 输入的中文文本
:return: 生成的向量(numpy数组,固定长度1536维)
"""
# 调用通义向量API
response = TextEmbedding.call(
model=TextEmbedding.Models.text_embedding_v2, # 通义向量V2模型,中文效果最好
input=text
)
print(f"打印response返回结果:{response}")
# 解析API返回结果,提取向量
if response.status_code == 200:
# 提取向量,转成numpy数组,自动做归一化处理
embedding = np.array(response.output["embeddings"][0]["embedding"])
return embedding
else:
# 调用失败,打印错误信息
print(f"通义向量调用失败,错误码:{response.status_code},错误信息:{response.message}")
return None
"""
实操 2:云端 API 批量文本向量生成(衔接 RAG 项目核心实操)
核心目标:批量生成通义向量,输出「文本内容 + 向量 + 元数据」的结构化结果,可直接用于后续的向量库搭建。
"""
# 核心函数:批量文本向量生成
def batch_generator_tongyi_embedding(chunk_list: list) -> list:
"""
给批量文本块生成通义向量,输出结构化结果
:param chunk_list: 文本块列表,每个元素是一个文本字符串
:return: 结构化结果列表,每个元素包含chunk_id、chunk_content、embedding_vector
"""
batch_result = []
total_count = len(chunk_list)
print(f"开始批量生成通义向量,共 {total_count} 个文本块")
for idx, chunk in enumerate(chunk_list):
if not chunk.strip():
print(f"第{idx + 1}个文本块为空,跳过")
continue
# 生成向量
embedding = generate_tongyi_embedding(chunk)
if embedding is not None:
# 结构化保存结果
batch_result.append({
"chunk_id": idx + 1,
"chunk_content": chunk,
"embedding_vector": embedding.tolist(), # 转成列表,方便保存到JSON
"embedding_dim": len(embedding)
})
# 打印进度
if (idx + 1) % 5 == 0:
print(f"已完成 {idx + 1}/{total_count} 个文本块的向量生成")
print(f" 批量向量生成完成!共成功生成 {len(batch_result)} 个文本块的向量")
return batch_result
# 核心函数:保存向量结果到JSON文件
def save_embedding_result(result_list:list, save_path: str) -> bool:
try:
with open(save_path, mode="w", encoding="utf-8")as f:
json.dump(result_list,f,ensure_ascii=False,indent=2)
print(f" 向量结果已保存至:{save_path}")
return True
except Exception as e:
print(f"结果保存失败,错误信息:{str(e)}")
return False
"""
实操 3:向量相似度计算
核心目标:计算不同文本之间的通义向量相似度,验证「语义越像、相似度越高」的核心规律,彻底理解通义向量的语义匹配能力。
"""
from sklearn.metrics.pairwise import cosine_similarity
# 核心函数:计算两个文本的语义相似度
def calculate_tongyi_similarity(text1: str, text2: str) -> float:
"""
计算两个中文文本的语义相似度,返回0-1之间的数值
数值越接近1,语义越相似;越接近0,语义越无关
"""
# 生成两个文本的向量
embedding1 = generate_tongyi_embedding(text1).reshape(1, -1)
embedding2 = generate_tongyi_embedding(text2).reshape(1, -1)
# 计算余弦相似度
similarity = cosine_similarity(embedding1, embedding2)[0][0]
return round(similarity, 4)
# ====================== 测试运行 ======================
if __name__ == "__main__":
# 1:云端API单文本向量生成
# text = "通义向量模型调用,核心目标是掌握通义向量的调用方法,完成RAG项目的文本向量化"
# # 调用函数生成向量
# test_embedding = generate_tongyi_embedding(text)
#
# if test_embedding is not None:
# print("通义向量生成成功!")
# print(f"测试文本:{text}")
# print(f"生成的向量维度:{len(test_embedding)} 维")
# print(f"向量前10个数字:{test_embedding[:10]}")
# print(f"向量后10个数字:{test_embedding[-10:]}")
# 2:云端 API 批量文本向量生成
# your_chunk_list = [
# "Day85的学习内容是pdfplumber安装与PDF文字提取,核心目标是掌握PDF读取,能独立提取PDF中的文字内容",
# "Day86的学习内容是RAG核心文本分块逻辑与全流程实操,核心目标是掌握文本分块技术,能对长文档进行合理分块",
# "Day87的学习内容是文档分段、切块策略,核心目标是了解文档分块,能对长文档进行合理的分块处理",
# "Day88的学习内容是文本切分函数封装,核心目标是将文档分段、切块逻辑封装成可复用的工程化函数",
# "Day89的学习内容是embedding向量概念通俗理解,核心目标是彻底搞懂embedding向量的本质、核心作用与RAG关联逻辑",
# "Day90的学习内容是通义向量模型调用,核心目标是掌握通义向量的调用方法,完成RAG项目的文本向量化",
# ]
# # 批量生成向量
# embedding_result = batch_generator_tongyi_embedding(your_chunk_list)
# # 保存结果到JSON文件
# if embedding_result:
# save_embedding_result(embedding_result, output_save_path)
# 3.向量相似度计算
# 测试文本组,验证语义相似度
test_group = [
("Day90的学习内容是通义向量模型调用", "今天要学的是通义向量的调用方法", "语义高度相似"),
("Day90的学习内容是通义向量模型调用", "RAG项目的核心是文本向量化和向量检索", "语义有一定关联"),
("Day90的学习内容是通义向量模型调用", "我今天吃了苹果和香蕉", "语义完全无关"),
("通义向量模型是中文RAG的主流选型", "BGE模型是通用中文向量模型", "同类型不同模型,语义有一定关联"),
]
# 循环计算每组文本的相似度
for text1, text2, desc in test_group:
sim = calculate_tongyi_similarity(text1, text2)
print(f"\n【{desc}】")
print(f"文本1:{text1}")
print(f"文本2:{text2}")
print(f"通义向量语义相似度:{sim}")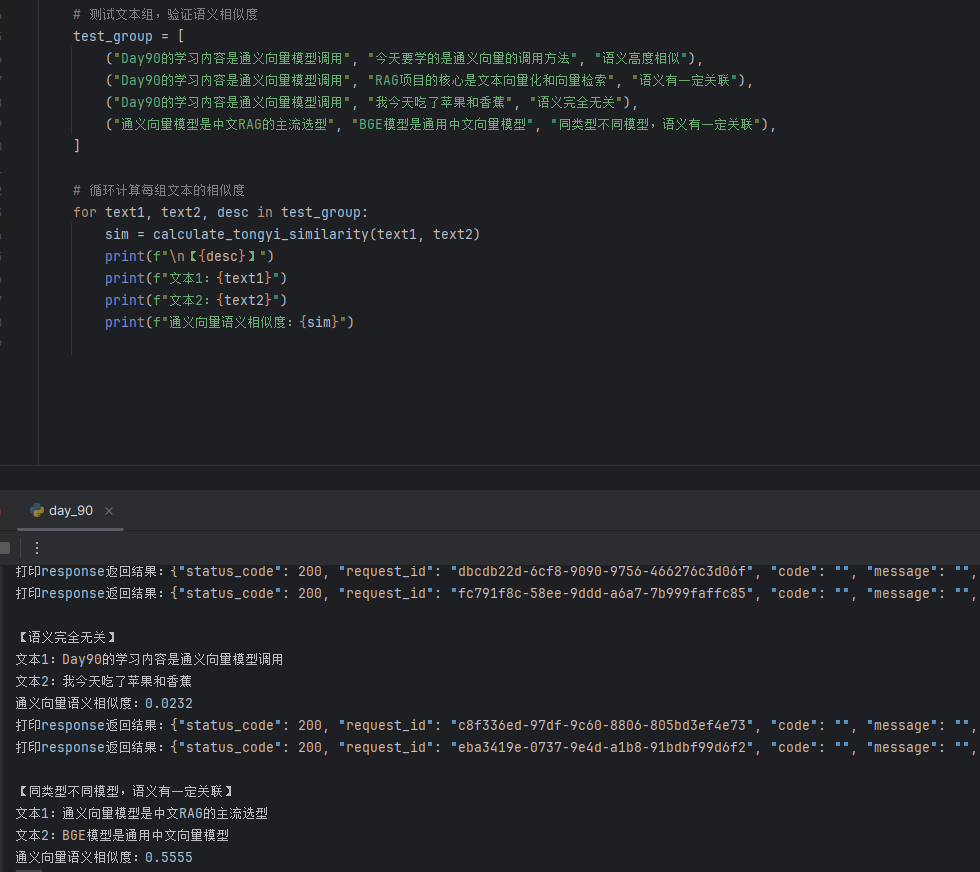
补充知识点说明:
python
为什么
generate_tongyi_embedding(text1).reshape(1, -1)
代码后面要写个 .reshape(1, -1)1. 整体作用
reshape(1, -1) 是 改变数组形状,把原本一维向量,转成 二维矩阵(一行多列)。
原因:你后面用的 cosine_similarity 相似度计算函数,只接收二维数组,不接收一维数组,不加这行代码会直接报错。
2. 先看原始向量长什么样
调用 generate_tongyi_embedding(text) 得到的结果是 一维数组:
python
# 形状:(1536,) 只有1个维度,一整行数字
emb = generate_tongyi_embedding("测试文本")
print(emb.shape) # 输出:(1536,)你可以理解成:一条直线上的 1536 个数字。
而 sklearn 的 cosine_similarity 要求输入格式必须是:
(样本数, 特征数) → 二维结构(有行、有列)
一维数组直接丢进去,程序识别不了,就会报错。
3. 拆解 reshape (1, -1)
3.1. 语法规则
数组.reshape(行数, 列数)
- 第一个参数 1:指定变成 1 行
- 第二个参数 -1:自动计算列数(不用你手动写 1536)
3.2. 举个极简小例子
python
import numpy as np
arr = np.array([0.1, 0.2, 0.3])
print("原数组形状:", arr.shape) # (3,) 一维
arr2 = arr.reshape(1, -1)
print("变形后形状:", arr2.shape) # (1, 3) 二维
print("原数组:", arr) # [0.1 0.2 0.3]
print("变形后:", arr2) # [[0.1 0.2 0.3]] 外层多了一对方括号