目录
一、论文基础信息
1.1 基本概况
- 标题 :Efficient Memory Management for Large Language Model Serving with PagedAttention(基于分页注意力的大语言模型服务高效内存管理)
https://arxiv.org/pdf/2309.06180
- 作者与单位:UC 伯克利、斯坦福大学、加州大学圣地亚哥分校等联合团队,包含 Woosuk Kwon、Zhuohan Li 等研究者。
- 发表会议:SOSP 2023(操作系统领域顶会),发表时间 2023 年 10 月;预印本发布于 2023 年 9 月。
- 核心产出 :提出PagedAttention(分页注意力) 新型注意力算法,并基于该算法构建开源 LLM 推理服务系统 vLLM,核心解决 LLM 在线服务中 KV Cache 内存低效问题。
- 开源地址 :GitHub - vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs · GitHub,目前已成为工业界主流 LLM 推理框架。
1.2 研究核心目标
针对大语言模型(LLM)自回归推理场景,解决KV Cache 内存碎片化、无法跨序列共享、内存利用率极低的行业痛点,在不修改模型结构、不损失推理精度的前提下,大幅提升 LLM 服务的批处理能力与整体吞吐量,缓解 GPU 内存墙瓶颈。
二、研究背景与行业核心痛点
2.1 LLM 推理基础特性
主流 LLM 基于自回归 Transformer 架构,推理分为两个阶段,且全程依赖KV Cache(键值缓存):
- Prompt 阶段(预填充):输入完整提示词,可通过矩阵运算并行计算所有 token 的 Key/Value 向量,并缓存至 KV Cache,GPU 算力利用率高。
- 自回归生成阶段 :逐一生成新 token,每一步复用历史 token 的 KV 向量,仅计算当前新 token 的 KV 向量并追加到缓存。该阶段为内存受限型负载,GPU 算力严重闲置,是延迟与吞吐瓶颈的核心来源。
KV Cache 的核心作用是避免重复计算历史 token 的注意力 K/V 向量,但其具备三大天然特性:动态扩容(生成 token 越多,缓存越大)、长度不可预知(输出长度由模型动态决定)、多解码场景存在大量可共享缓存。
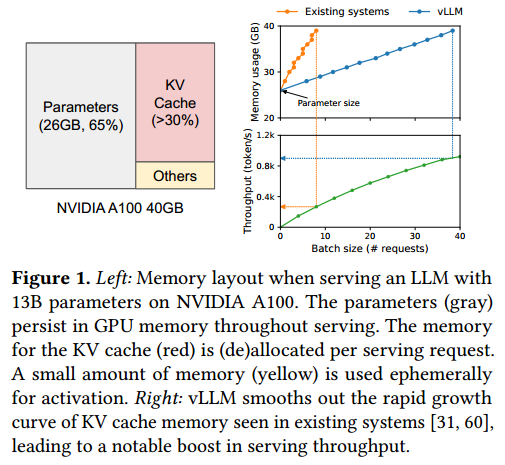
以 OPT-13B 模型为例:单个 token 的 KV Cache 占用 800KB,单条最大长度 2048 的请求需占用1.6GB显存;对于 40GB A100 GPU,仅 KV Cache 理论上只能承载数十条请求,内存资源极度紧张。
2.2 现有系统的致命缺陷
当前主流 LLM 推理系统(FasterTransformer、Orca 等)均遵循深度学习框架的通用规则:KV Cache 必须存储在连续 GPU 内存中 。为适配未知的输出长度,系统会为每条请求预分配最大序列长度的连续内存块,由此引发两大核心问题:
(1)严重的内存碎片化,内存利用率极低
论文实测数据显示,现有系统 KV Cache 的有效利用率仅为 20.4%~38.2%,剩余内存全部被浪费,浪费分为三类:
- 预留浪费:为未来未生成的 token 预占用内存,整个请求生命周期内无法被其他请求复用;
- 内部碎片:请求实际输出长度远小于预分配的最大长度,大块连续内存空置;
- 外部碎片:不同请求预分配的内存尺寸不一,请求释放后产生大量零散内存空洞,无法分配给新请求。
(2)无法实现 KV Cache 跨序列共享
LLM 常用解码算法(并行采样、束搜索、共享前缀提示词)会产生多条同源序列,这些序列的前缀 KV Cache 完全一致。但现有系统中每条序列独占独立连续内存块,无法复用缓存,进一步放大内存开销。例如束搜索场景下,传统系统会反复拷贝 KV Cache,带来双重的内存与算力损耗。
2.3 行业趋势加剧瓶颈
GPU 算力迭代速度远快于内存扩容:以 NVIDIA A100 到 H100 为例,算力翻倍但单卡最大显存仍维持 80GB。随着模型参数量增大(66B、175B)、序列长度变长、解码逻辑复杂化,内存逐渐成为 LLM 服务的第一大瓶颈,限制批处理大小与服务吞吐量。
三、核心设计思想:操作系统虚拟内存的跨领域迁移
本论文最具创新性的思路是将操作系统(OS)经典的虚拟内存、分页机制系统性迁移至 LLM KV Cache 管理与注意力计算,建立一套完整类比关系:
| 操作系统概念 | vLLM/PagedAttention 对应概念 | 核心作用 |
|---|---|---|
| 物理内存页(Page) | KV Block(KV 块) | 统一大小的最小内存分配单元,消除碎片 |
| 进程 | LLM 推理请求 / 序列 | 独立的逻辑执行单元 |
| 虚拟内存 / 逻辑地址 | 逻辑 KV 块 | 请求视角下 "连续" 的 KV 缓存空间 |
| 页表(Page Table) | 块表(Block Table) | 维护逻辑块→物理块的映射,实现间接寻址 |
| 写时复制(Copy-on-Write, CoW) | 块级写时复制 | 实现多序列共享物理块,避免数据拷贝 |
| 页面交换(Swap) | GPU-CPU 块交换 | 内存过载时将冷缓存迁移至 CPU 内存 |
基于该思想,PagedAttention 打破了 "注意力 K/V 向量必须存于连续内存" 的固有范式:将 KV Cache 切分为固定尺寸的 KV 块,逻辑上连续的 KV 缓存可映射到物理上离散的 GPU 内存块,从根源解决碎片与共享问题。
四、核心技术体系详解
4.1 底层算法:PagedAttention(分页注意力)
4.1.1 KV 块划分规则
将单条序列的 KV Cache 分割为若干固定大小的 KV Block(块大小记为B,vLLM 默认值为 16,即每个块存储 16 个 token 的 K/V 向量)。块是内存分配、注意力计算、缓存共享的最小单元。
4.1.2 分块注意力计算逻辑
传统注意力基于完整连续 K/V 张量计算,PagedAttention 将计算拆解为块级运算,改写核心公式:
- 设第j个 KV 块的 Key 张量为Kj、Value 张量为Vj;
- 注意力得分按块计算:
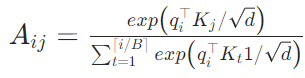
- 最终输出为所有块的加权求和:
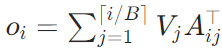
GPU 内核会逐个读取离散的物理 KV 块完成计算,无需整体内存连续。该设计是所有内存优化的算法基础。
4.1.3 核心优势(算法层面)
- 消除外部碎片:所有物理块尺寸统一,无大小不一的内存空洞;
- 大幅降低内部碎片:仅最后一个未满的块存在少量碎片,整体近乎零浪费;
- 动态按需分配:仅在生成新 token 时分配新物理块,不预占用最大长度内存;
- 支持细粒度共享:以块为单位实现多序列 KV 缓存复用。
4.2 端到端系统:vLLM 整体架构
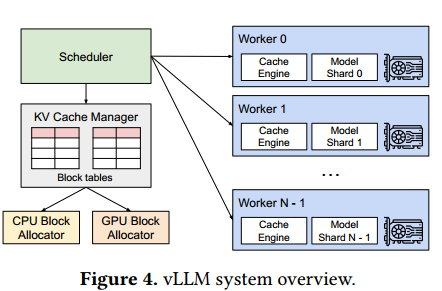
vLLM 是基于 PagedAttention 构建的分布式 LLM 推理服务引擎 ,整体架构分为集中式调度器 与多 GPU 工作节点两大模块,适配单机与多卡分布式场景。
- 集中式调度器(Scheduler):全局统筹请求调度、块表管理、请求抢占、负载分配,维护全局逻辑块与物理块的映射关系。
- GPU 工作节点(Worker) :每个节点包含三部分:
- 模型分片(Model Shard):支持张量模型并行,拆分大模型至多 GPU;
- 缓存引擎(Cache Engine):执行 PagedAttention 内核、KV 块读写;
- 块分配器:分为 GPU 块分配器(管理显存物理块)、CPU 块分配器(管理交换内存)。
- 核心组件:块表(Block Table) :类比 OS 页表,记录每条请求的逻辑 KV 块 到物理 KV 块的映射关系,是实现非连续内存访问的核心。
4.3 KV Cache 精细化管理(内存优化核心)
4.3.1 动态块分配策略
- Prompt 阶段:仅分配提示词所需的 KV 块,不预分配额外空间;
- 自回归生成阶段:当前块写满后,才动态从空闲物理块池中分配新块;
- 内存回收:请求生成结束后,立即释放所有关联物理块至空闲池,供新请求复用。
该策略将内存浪费严格限制在单个未满块内,实测 KV Cache 有效利用率接近 100%。
4.3.2 引用计数 + 写时复制(CoW):块共享机制
为实现多序列共享物理块,vLLM 为每个物理块增加引用计数:
- 共享阶段:多条序列的逻辑块映射到同一个物理块,引用计数 + 1,无需复制数据;
- 写触发阶段:当某条序列需要向共享物理块写入新 token 时,若引用计数 > 1,则触发 CoW:分配新物理块、拷贝原块数据,当前序列指向新块,原块引用计数 - 1;
- 独占阶段:引用计数 = 1 的物理块可直接写入,无拷贝开销。
该机制完美适配各类多序列解码算法,在保证数据隔离的同时最大化内存复用。
4.4 多解码场景适配(通用性验证)
PagedAttention 与块管理机制原生支持 LLM 主流解码方式,不同场景的内存收益差异显著:
- 基础采样(贪心 / 随机采样) :单序列生成,核心收益来自消除内存碎片,批处理请求数提升 2~4 倍。
- 并行采样(单 Prompt 多输出) :多条输出序列共享 Prompt 前缀块,内存节省 6.1%~30.5%,序列数量越多收益越高。
- 束搜索(Beam Search) :多候选序列不仅共享前缀,中间块也可动态共享,是收益最高的场景。实测内存节省最高达55.2%(Alpaca)、66.3%(ShareGPT),吞吐量相比基线提升 2.3 倍。
- 共享前缀(通用指令 / 系统提示词) :多请求共用长前缀时,预缓存公共块,长前缀场景下吞吐量提升3.58 倍。
- 聊天机器人(长对话):长 Prompt + 动态上下文的场景下,碎片问题最严重,vLLM 吞吐量为传统基线的 2 倍。
4.5 内存过载处理:调度、抢占与降级策略
当 GPU 物理块耗尽时,vLLM 采用FCFS(先来先服务) 调度,优先抢占最晚到达的请求,并提供两种降级恢复方案,适配不同硬件场景:
- 全有或全无驱逐策略:序列的所有 KV 块必须整体驱逐 / 保留(LLM 生成依赖完整历史缓存,无法局部驱逐);同源多序列(如束搜索候选)统一调度、统一抢占。
- Swap(内存交换) :将被抢占序列的 KV 块拷贝至 CPU 内存,恢复时再拷回 GPU。大尺寸块场景更优,小尺寸块因频繁拷贝受 PCIe 带宽限制,性能较差。
- Recomputation(重计算) :不缓存被抢占序列的 KV 块,恢复时重新计算 Prompt 阶段的缓存。开销稳定,小尺寸块场景优于 Swap,整体开销始终不超过 Swap 的 20%。
4.6 分布式部署能力
原生支持Megatron-LM 风格张量模型并行,适配 66B、175B 等超大规模模型:
- 大模型按注意力头维度拆分至多 GPU,每个 Worker 仅负责部分注意力头的计算;
- 全局统一块表与 KV Cache 管理器,所有 GPU 共享逻辑 - 物理块映射,无需额外内存同步;
- 各 Worker 独立存储对应分片的 KV 数据,分布式开销极低。
4.7 内核级优化(抵消 PagedAttention 固有开销)
PagedAttention 因块表查询、分支判断,单注意力内核延迟比传统 FasterTransformer 高 20%~26%。团队通过CUDA 内核融合抵消该开销:
- 融合 Reshape + 块写入:将 KV 数据重塑、分块写入合并为单个内核,减少内核启动开销;
- 融合块读取 + 注意力计算:按 GPU Warp 对齐读取块数据,优化内存访问带宽;
- 融合批量块拷贝:批量处理 CoW 触发的块拷贝,避免多次调用异步拷贝接口。
最终,内存利用率提升带来的批处理增益,完全覆盖单算子的轻微开销,端到端性能大幅领先基线。
五、实验评估体系与核心结果
5.1 实验环境配置
- 硬件:NVIDIA A100 GPU(40GB/80GB),Google Cloud A2 实例;
- 测试模型:OPT-13B/66B/175B、LLaMA-13B(覆盖主流中小、超大参数量模型);
- 数据集 :
- ShareGPT:真实聊天数据,长输入、长输出、序列长度方差大;
- Alpaca:指令数据集,短序列;
- WMT16:机器翻译数据集,用于共享前缀场景测试;
- 基线系统 :
- FasterTransformer:英伟达低延迟推理引擎,无精细调度;
- Orca(SOSP 2022,当时 SOTA 吞吐系统):分为三个变体:
- Orca (Max):预分配模型最大序列长度(工业界主流用法);
- Orca (Pow2):按 2 的幂次预分配,适度缩减预留空间;
- Orca (Oracle):理想上限,预知真实输出长度(实际无法落地);
- 核心指标:归一化延迟(单 token 耗时)、批处理请求数、吞吐量(req/s)、KV Cache 内存节省率。
5.2 核心实验结论
5.2.1 基础单序列生成
- ShareGPT(长序列) :vLLM 吞吐量比 Orca (Oracle) 高 1.7~2.7 倍,比 Orca (Max) 高 2.7~8 倍,比 FasterTransformer 高22 倍;同延迟下批处理请求数是 Orca (Oracle) 的 2.2 倍。
- Alpaca(短序列) :提升幅度收窄,短序列下传统系统碎片问题减弱,部分场景进入计算瓶颈而非内存瓶颈。
- 175B 超大模型:GPU 内存总量充足,基线内存压力小,vLLM 优势进一步缩小。
5.2.2 复杂解码场景(增益最显著)
解码逻辑越复杂,vLLM 优势越大:OPT-13B+Alpaca 场景下,束搜索(beam=6)相比 Orca (Oracle) 吞吐量提升2.3 倍(基础采样仅 1.3 倍);并行采样、束搜索的内存共享能力成为核心增益来源。
5.2.3 共享前缀与聊天场景
- 机器翻译(1-shot 短前缀):吞吐量提升 1.67 倍;5-shot 长前缀提升3.58 倍;
- 聊天机器人(长对话):吞吐量为三类 Orca 基线的 2 倍,完美解决长上下文的碎片问题。
5.3 消融实验(设计选择验证)
- KV 块大小调优 :默认 16 为全局最优。
- 块过小(<16):GPU 并行计算能力无法充分利用,延迟上升;
- 块过大(>128):内部碎片激增,内存利用率下降;
- 场景适配:ShareGPT 长序列适合 16~128,Alpaca 短序列优先 16/32。
- Swap vs 重计算 :
- 小块(8/16):重计算性能更优;
- 大块(128+):内存交换更优;
- 中等块(16~64):两者性能持平。
- 内核开销验证:PagedAttention 单算子延迟高 20%~26%,但端到端吞吐量碾压基线,证明内存优化的收益远大于算子开销。
六、核心创新点总结
6.1 技术创新
- 跨领域思想融合 :首次将操作系统虚拟内存、分页、页表、CoW、页面交换整套成熟技术系统性应用于 LLM KV Cache 管理,开辟 LLM 推理优化新方向。
- 算法范式突破 :提出 PagedAttention,打破 "注意力 K/V 必须存储在连续内存" 的行业固有认知,实现非连续内存下的分块注意力计算。
- 细粒度内存共享:基于引用计数 + CoW 实现块级 KV 缓存共享,原生兼容所有主流解码算法,最大化内存复用率。
6.2 工程创新
- 端到端工业级系统:构建 vLLM 开源推理引擎,结合分页内存、迭代级调度、请求抢占、分布式并行,可直接落地生产环境。
- 混合内存降级方案:同时支持 Swap 与重计算两种过载恢复策略,适配不同硬件、不同业务场景,提升系统鲁棒性。
- 内核融合优化:通过 CUDA 内核融合抵消 PagedAttention 的间接寻址开销,兼顾内存效率与计算性能。
七、同类方案横向对比
| 推理系统 / 技术 | 核心优化方向 | 优势场景 | 与 vLLM 的差异 |
|---|---|---|---|
| FasterTransformer | 注意力内核极致优化、低延迟 | 低并发、低延迟在线服务 | 无内存优化与精细调度,吞吐量差距可达 22 倍,定位不同 |
| Orca(OSDI 2022) | 迭代级请求调度、请求交错 | 高吞吐服务 | 仅优化调度,无法解决碎片与缓存共享;与 vLLM 可互补使用 |
| FlexGen | 权重 + KV 多级 Swap(GPU/CPU/ 磁盘) | 单 GPU 离线超大模型推理 | 侧重离线推理,无在线共享优化,在线服务性能弱于 vLLM |
| FlashAttention | 注意力分块计算、降低峰值显存 | 通用推理、训练 | 优化注意力计算与峰值内存,不优化 KV Cache 长期存储与共享;可与 PagedAttention 叠加使用 |
总结:Orca 优化 "调度并发",vLLM 优化 "内存利用率",二者是当前高吞吐 LLM 服务的黄金组合;FlashAttention 与 PagedAttention 优化维度不同,可叠加部署进一步提升性能。
八、方案局限性与工程调优要点
8.1 固有局限性
- 单注意力算子存在轻微开销:块表查询、分支逻辑导致单算子延迟提升 20%~26%,依赖批量增益弥补;
- 块大小需场景化调优:无通用最优块尺寸,长 / 短序列业务需单独配置;
- Swap 策略受硬件带宽限制:小尺寸块下,CPU-GPU 拷贝的 PCIe 带宽成为瓶颈;
- 极短序列场景增益有限:当内存充足、系统进入计算瓶颈时,内存优化的价值无法体现。
8.2 生产环境调优建议
- 块大小:通用场景默认 16;长对话 / 长 Prompt 业务选用 32~64;纯短指令场景选用 16;
- 内存过载策略 :小显存 GPU 优先开启重计算,大显存 GPU 可启用 Swap;
- 解码场景:束搜索、并行采样等高共享场景优先启用块共享,最大化内存收益;
- 分布式部署:超大模型优先采用张量并行,复用全局块表,减少分布式开销。
九、行业影响、落地现状与未来方向
9.1 行业影响与落地
- 学术层面 :作为 SOSP 顶会论文,证明系统底层技术与大模型结合的巨大价值,启发了后续分页 KV、前缀缓存、多级内存管理等大量研究工作。
- 工业落地:vLLM 目前是全球最主流的开源 LLM 推理框架之一,广泛用于开源模型(LLaMA、Qwen、Mistral 等)部署、云厂商 LLM 服务、私有化部署,成为行业标配。
- 生态扩展:兼容 Hugging Face Transformers、主流 API 协议(OpenAI API),逐步适配 AMD、昇腾等非 NVIDIA 硬件。
9.2 未来研究方向
- 自适应块尺寸:运行时动态调整 KV 块大小,免去人工调参;
- 多级前缀缓存:构建全局热点前缀 + 用户私有前缀的分层缓存,进一步提升共享率;
- 跨节点 KV 共享:分布式集群内多 GPU 节点共享 KV 块,突破单卡内存上限;
- 与新型解码结合:融合推测解码、多轮对话上下文缓存,强化长会话场景性能;
- 异构硬件适配:针对 AI 芯片架构优化 PagedAttention 内核,脱离 NVIDIA GPU 依赖。
十、全文总结
本文针对 LLM 在线服务中KV Cache 内存碎片化、缓存无法共享 的核心瓶颈,创新性地将操作系统虚拟内存分页、写时复制、页面交换等经典技术迁移至大模型推理领域,提出PagedAttention 分页注意力算法,并构建开源系统 vLLM。
核心价值体现在三点:
- 内存效率革命:将传统系统 20%~38% 的 KV Cache 利用率提升至接近 100%,从根源释放 GPU 内存;
- 吞吐大幅提升 :在保持延迟不变的前提下,整体吞吐量相比当时 SOTA 系统提升2~4 倍,复杂解码、长序列场景增益更突出;
- 通用性与工程价值:原生兼容所有主流 LLM、解码算法与分布式架构,开源后快速成为工业界标准推理框架。
该工作不仅解决了 LLM 服务的现实痛点,更打通了传统系统技术与大模型基础设施的融合路径,为后续大模型推理、内存优化领域提供了全新的设计思路。
KV Cache其他优化方向
|---------------------------------------|----------------------------|
| 技术 | 思路 |
| **MQA** (Multi-Query Attention) | 所有头共享一组 K/V,减少缓存 |
| **GQA** (Grouped-Query Attention) | 几组头共享 K/V,平衡效果和效率 |
| **PageAttention (vLLM)** | 把 KV Cache 分页管理,减少内存碎片 |
| **量化压缩** | 把 K/V 存成 INT8/INT4,降低显存 |
| **滑动窗口** | 只缓存最近 N 个 token(如 Mistral) |