对应教材:陈封能《数据挖掘导论》第3章
核心问题:如何根据已有数据特征,预测一个新样本的类别标签?
一、分类问题是什么?
1.1 定义
-
分类 = 有监督学习任务。给定一个样本的特征(x),预测它的类别(y)。
-
类别是离散的,例如:垃圾邮件/正常邮件、拖欠贷款/不拖欠、癌症/健康。
1.2 分类 vs 回归 vs 聚类
| 任务 | 输出类型 | 是否有标签 | 例子 |
|---|---|---|---|
| 分类 | 离散类别 | 有(监督学习) | 判断邮件是不是垃圾 |
| 回归 | 连续数值 | 有(监督学习) | 预测房价 |
| 聚类 | 离散簇(无预设类别) | 无(无监督学习) | 自动将新闻分成几组 |
1.3 分类的基本步骤(三步走)
-
训练(Induction):用带标签的训练集,通过学习算法训练出一个模型(分类器)。
-
测试(Deduction):用未参与训练的测试集评估模型效果(例如准确率)。
-
部署:将模型用于新数据,进行预测。
💡 形象理解:就像老师用有答案的例题教你解题方法(训练),然后用新题目考你(测试),最后你能独立解任何同类题目(部署)。
二、决策树(Decision Tree)------ 最直观的分类算法
决策树是一种树形结构的分类器,内部节点表示"属性测试",分支表示测试结果,叶节点表示类别预测。
2.1 决策树长什么样?(贷款违约例子)
训练数据(10条记录,预测是否会拖欠贷款):
| 编号 | 有房者? | 婚姻状况 | 年收入(万) | 拖欠? |
|---|---|---|---|---|
| 1 | 是 | 单身 | 125 | 否 |
| 2 | 否 | 已婚 | 100 | 否 |
| 3 | 否 | 单身 | 70 | 否 |
| 4 | 是 | 已婚 | 120 | 否 |
| 5 | 否 | 离异 | 95 | 是 |
| 6 | 否 | 已婚 | 60 | 否 |
| 7 | 是 | 离异 | 220 | 否 |
| 8 | 否 | 单身 | 85 | 是 |
| 9 | 否 | 已婚 | 75 | 否 |
| 10 | 否 | 单身 | 90 | 是 |
生成的一棵决策树(可能的一种):
拥有房产? / \ 是 否 / \ No 婚姻状况? / | \ 已婚 单身 离异 / | \ No 年收入? No / \ <80K ≥80K / \ No Yes
解读:
-
如果"有房产" → 直接预测"不拖欠"(No)
-
如果"无房且已婚" → 预测"不拖欠"
-
如果"无房且离异" → 预测"不拖欠"
-
如果"无房且单身且年收入<80K" → 预测"不拖欠"
-
如果"无房且单身且年收入≥80K" → 预测"拖欠"(Yes)
2.2 决策树怎么生成的?------ Hunt 算法(递归划分)
Hunt 算法是许多决策树算法的基础,步骤如下:
-
如果当前节点所有样本属于同一类别 → 标记为叶节点,停止。
-
否则,选择一个属性,将样本划分成若干子集。
-
对每个子集递归执行步骤1-2。
关键问题 :每次选哪个属性来划分?
→ 需要用不纯性度量来量化划分的"好坏"。
2.3 三种不纯性度量(纯度越高,值越小)
假设一个节点中有若干样本,分属不同类别。我们想用一个数字表示它有多"混"。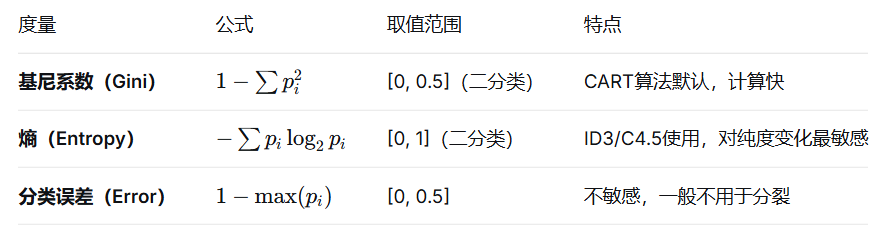
🧠 手算例子(二分类,C0和C1):
节点(0,6):纯 → Gini=0, Entropy=0, Error=0
节点(1,5):较纯 → Gini≈0.278, Entropy≈0.65, Error≈0.167
节点(3,3):最不纯 → Gini=0.5, Entropy=1.0, Error=0.5
为什么推荐用熵或基尼?
因为分类误差对纯度变化不敏感(只要多数类比例不变,误差就不变),而熵和基尼能区分更细微的分布差异。
2.4 信息增益(Information Gain)------ 选择最佳属性
信息增益 = 父节点不纯度 - 子节点加权平均不纯度
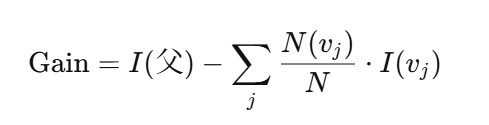
其中 I 可以是熵或基尼。
手算例子(贷款数据,用熵):
-
父节点:7个No,3个Yes → 熵 = 0.881
-
按"有房者"划分:
-
"是":3个样本,全No → 熵=0
-
"否":7个样本,4No+3Yes → 熵=0.985
-
加权平均 = (3/10)*0 + (7/10)*0.985 = 0.690
-
信息增益 = 0.881 - 0.690 = 0.191
-
-
按"婚姻状况"划分:
-
已婚(4个全No): 熵=0
-
单身(1No+3Yes): 熵=0.811
-
离异(1No+1Yes): 熵=1.0
-
加权平均 = (4/10)*0 + (4/10)*0.811 + (2/10)*1.0 = 0.324+0.2=0.524
-
信息增益 = 0.881 - 0.524 = 0.357
-
结论:婚姻状况的增益更大 → 应该先按婚姻状况划分。
2.5 信息增益的问题与改进:增益率
-
问题 :信息增益偏向取值多的属性。比如用"ID号"划分,每个子节点只有一个样本,增益最大,但毫无意义(过拟合)。
-
解决方案(C4.5算法) :用增益率 = 信息增益 / 划分信息熵(SplitInfo)
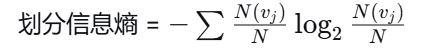
分支越多,划分信息熵越大 → 增益率被"惩罚",从而抑制多值属性偏好。
2.6 常见决策树算法对比
| 算法 | 分裂准则 | 分支数 | 处理连续属性 | 优缺点 |
|---|---|---|---|---|
| ID3 | 信息增益 | 多路 | 否 | 偏向多值属性 |
| C4.5 | 增益率 | 多路 | 是 | 修正了偏向,但计算稍复杂 |
| CART | 基尼系数 | 二叉树 | 是 | 通用,sklearn默认 |
三、模型评估 ------ 如何判断分类器好不好?
3.1 混淆矩阵(Confusion Matrix)
对于二分类,预测结果与真实标签有四种组合:
| 预测为正(Positive) | 预测为负(Negative) | |
|---|---|---|
| 真实为正 | TP(真正例) | FN(假负例,漏报) |
| 真实为负 | FP(假正例,误报) | TN(真负例) |
3.2 核心评估指标
| 指标 | 公式 | 含义 | 关注点 |
|---|---|---|---|
| 准确率(Accuracy) | (TP+TN) / 总样本 | 整体预测正确的比例 | 不适合不平衡数据 |
| 精确率(Precision) | TP / (TP+FP) | 预测为正的样本中实际为正的比例 | 避免误报(FP) |
| 召回率(Recall) | TP / (TP+FN) | 实际为正的样本中被预测出来的比例 | 避免漏报(FN) |
| F1分数 | 2×P×R / (P+R) | 精确率和召回率的调和平均 | 综合两者 |
📌 业务取舍:
垃圾邮件过滤 → 高精确率(别把正常邮件误判为垃圾)
癌症筛查 → 高召回率(宁可误报,不可漏诊)
3.3 为什么需要ROC与AUC?(不平衡数据的救星)
例子:欺诈检测,99%交易正常,1%欺诈。若模型把所有交易都预测为"正常",准确率=99%,但一个欺诈都抓不到 ------ 这个模型毫无用处。
问题 :准确率在不平衡数据下失效。
解决 :使用ROC曲线和AUC值,它们不受类别不平衡影响。
3.4 ROC曲线(Receiver Operating Characteristic)
-
横轴:假正率(FPR)= FP / (FP+TN) ------ 误报率
-
纵轴:真正率(TPR)= TP / (TP+FN) ------ 召回率/灵敏度
如何绘制 :
分类器通常输出一个"概率"(或得分)。我们遍历所有可能的阈值(从高到低),每个阈值对应一个(FPR, TPR)点,连成曲线。
-
理想模型:曲线紧贴左上角 (0,1) → AUC=1
-
随机模型:对角线 (0,0) 到 (1,1) → AUC=0.5
-
好的模型:曲线在对角线上方,AUC>0.5
3.5 AUC(Area Under Curve)------ 排序能力的量化
-
AUC值 = ROC曲线下的面积,范围0,1。
-
物理意义:随机选一个正样本和一个负样本,模型给正样本打分高于负样本的概率。
-
AUC=0.85 意味着:85%的概率正样本得分高于负样本。
核心优势:AUC只关注排序,不依赖于具体阈值,且对类别不平衡非常稳健。
3.6 ROC vs PR曲线(如何选择?)
-
ROC曲线:适合评估整体区分能力,对不平衡数据鲁棒。
-
PR曲线 (精确率-召回率曲线):当数据极度不平衡 且关注正类时更敏感。如果正类很少,ROC可能过于乐观,PR曲线更能反映真实性能。
一般先看ROC/AUC,如果正类非常稀少(如1%),补充PR曲线。
四、过拟合与剪枝
4.1 过拟合 vs 欠拟合
| 状态 | 训练集表现 | 测试集表现 | 原因 | 解决 |
|---|---|---|---|---|
| 欠拟合 | 差 | 差 | 模型太简单 | 增加模型复杂度 |
| 恰当拟合 | 好 | 好 | 平衡 | ------ |
| 过拟合 | 极好 | 差 | 模型太复杂,记住了噪声 | 剪枝、正则化、增加数据 |
决策树特别容易过拟合,因为它可以把树长得非常深,直到每个叶节点只有一个样本。
4.2 剪枝策略
-
预剪枝 :在树生长过程中提前停止。
常用参数:
max_depth(最大深度)、min_samples_split(节点最少样本数)、min_samples_leaf(叶节点最少样本数)。 -
后剪枝 :先让树充分生长,然后自底向上修剪掉不重要的子树。
常用方法:代价复杂度剪枝(
ccp_alpha),alpha越大剪枝越强。
4.3 交叉验证(Cross Validation)
-
将训练集分成K份(常用K=5或10),轮流用K-1份训练,1份验证,最后取平均性能。
-
GridSearchCV :自动搜索最佳超参数组合(如
max_depth、criterion)。
五、Python实战(sklearn 决策树)
5.1 简单代码示例(鸢尾花数据集)
python
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(X_train, y_train)
print(dt.score(X_test, y_test)) # 准确率约 0.9785.2 特征重要性
决策树可以输出每个特征的重要性(该特征在所有分裂中减少的不纯度之和,归一化)。
python
print(dt.feature_importances_)在鸢尾花中,花瓣长度和宽度通常比花萼特征重要得多。
5.3 决策树优缺点
| 优点 | 缺点 |
|---|---|
| 模型直观,易于解释 | 容易过拟合(需剪枝) |
| 可处理数值和分类型特征 | 对数据微小变化敏感 |
| 预测速度快 | 偏向高基数分类型特征 |
| 不需要特征缩放 | 类别不平衡时表现可能差 |
六、本章核心公式汇总(考试必备)

七、总结
-
分类是预测离散标签的有监督学习任务。
-
决策树通过递归划分构建树形模型,核心是选择最佳分裂属性。
-
不纯性度量(基尼、熵)帮助评估划分质量。
-
评估指标:混淆矩阵、精确率、召回率、F1、准确率。
-
ROC/AUC是不平衡数据下评估模型排序能力的黄金标准。
-
过拟合 是决策树的主要问题,通过剪枝 和交叉验证解决。