注:本文为 "搜索引擎" 相关译文。
英文引文,机翻未校。
如有内容异常,请看原文。
The Anatomy of a Large-Scale Hypertextual Web Search Engine
大型超文本网络搜索引擎的剖析
Sergey Brin and Lawrence Page
谢尔盖·布林、劳伦斯·佩奇
Computer Science Department, Stanford University, Stanford, CA 94305, USA
美国加利福尼亚州斯坦福市,斯坦福大学计算机科学系,邮编 94305
sergey@cs.stanford.edu and page@cs.stanford.edu
邮箱:sergey@cs.stanford.edu、page@cs.stanford.edu
Abstract
摘要
In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/ To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date. Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
本文介绍谷歌这款大型搜索引擎原型系统,该系统充分利用超文本自身结构。谷歌旨在高效抓取并索引网络页面,输出比现有系统体验更佳的搜索结果。该原型系统存储了至少 2400 万页面的全文与超链接数据库,可在 http://google.stanford.edu/ 访问。研发搜索引擎是一项极具挑战的工作。搜索引擎需要对数千万乃至数亿网页建立索引,其中包含数量庞大的独立词汇,每日还要处理数千万条检索请求。尽管大型网络搜索引擎具备重要价值,但相关学术研究却十分有限。此外,随着技术飞速发展与网络规模持续扩张,如今搭建网络搜索引擎与三年前相比已截然不同。本文对我们研发的大型网络搜索引擎进行详尽阐述,这也是目前已知首份对外公开的完整技术说明。除了需要将传统检索技术适配海量数据规模外,如何利用超文本中的附加信息优化搜索结果,也带来了全新技术难题。本文围绕如何搭建实用的大型系统、挖掘超文本附加信息展开研究,同时探讨了如何有效应对内容不受管控、任何人可自由发布信息的超文本数据集。
Keywords
关键词
World Wide Web, Search Engines, Information Retrieval, PageRank, Google
万维网、搜索引擎、信息检索、网页排名算法、谷歌
1. Introduction
1. 引言
(Note: There are two versions of this paper -- a longer full version and a shorter printed version. The full version is available on the web and the conference CD-ROM.)
(注:本文分为完整版与精简印刷版两个版本,完整版可在网络及会议光盘中查阅。)
The web creates new challenges for information retrieval. The amount of information on the web is growing rapidly, as well as the number of new users inexperienced in the art of web research. People are likely to surf the web using its link graph, often starting with high quality human maintained indices such as Yahoo! or with search engines. Human maintained lists cover popular topics effectively but are subjective, expensive to build and maintain, slow to improve, and cannot cover all esoteric topics. Automated search engines that rely on keyword matching usually return too many low quality matches. To make matters worse, some advertisers attempt to gain people's attention by taking measures meant to mislead automated search engines. We have built a large-scale search engine which addresses many of the problems of existing systems. It makes especially heavy use of the additional structure present in hypertext to provide much higher quality search results. We chose our system name, Google, because it is a common spelling of googol, or 10 100 10^{100} 10100 and fits well with our goal of building very large-scale search engines.
万维网为信息检索领域带来了全新挑战。网络信息体量飞速增长,同时也涌现出大量不熟悉网络检索方式的新用户。用户通常依托网络链接图谱浏览网页,一般先使用雅虎等人工维护的优质目录站点或搜索引擎。人工目录能够有效收录热门内容,但存在主观性强、搭建与维护成本高、更新滞后的问题,也无法覆盖各类小众冷门主题。依靠关键词匹配的自动化搜索引擎,往往会返回大量低质量结果。更有部分广告商刻意采取手段误导自动化搜索引擎,以此博取流量。为此,我们研发了一款大型搜索引擎,解决了现有系统存在的诸多问题。该系统深度挖掘超文本的附加结构,大幅提升搜索结果质量。系统命名为 Google,取自英文单词 googol(代表 10 100 10^{100} 10100),也契合我们打造超大型搜索引擎的目标。
1.1 Web Search Engines -- Scaling Up: 1994 - 2000
1.1 网络搜索引擎的规模演进:1994 - 2000 年
Search engine technology has had to scale dramatically to keep up with the growth of the web. In 1994, one of the first web search engines, the World Wide Web Worm (WWWW) McBryan 94 had an index of 110,000 web pages and web accessible documents. As of November, 1997, the top search engines claim to index from 2 million (WebCrawler) to 100 million web documents (from Search Engine Watch). It is foreseeable that by the year 2000, a comprehensive index of the Web will contain over a billion documents. At the same time, the number of queries search engines handle has grown incredibly too. In March and April 1994, the World Wide Web Worm received an average of about 1500 queries per day. In November 1997, Altavista claimed it handled roughly 20 million queries per day. With the increasing number of users on the web, and automated systems which query search engines, it is likely that top search engines will handle hundreds of millions of queries per day by the year 2000. The goal of our system is to address many of the problems, both in quality and scalability, introduced by scaling search engine technology to such extraordinary numbers.
为跟上网络发展步伐,搜索引擎技术必须实现大规模扩容。1994 年,最早的网络搜索引擎之一万维网蠕虫(WWWW)仅索引了 11 万份网页及可在线访问文档。截至 1997 年 11 月,主流搜索引擎的网页索引数量区间为 200 万(WebCrawler)至 1 亿份(数据来源:搜索引擎观察网)。可以预见,到 2000 年,全网综合索引的文档数量将突破 10 亿份。与此同时,搜索引擎的检索请求量也呈爆发式增长。1994 年 3 至 4 月,万维网蠕虫日均处理约 1500 条检索请求;1997 年 11 月,阿尔塔维斯塔搜索引擎宣称日均处理约 2000 万条检索请求。随着网络用户持续增加,加之各类自动化程序不断发起检索,到 2000 年,主流搜索引擎日均检索量或将达到数亿次。面对如此庞大的数据体量,搜索引擎技术在检索质量与扩容能力上暴露出诸多问题,本系统的研发目标便是解决这些难题。
1.2. Google: Scaling with the Web
1.2 谷歌:适配网络规模持续扩容
Creating a search engine which scales even to today's web presents many challenges. Fast crawling technology is needed to gather the web documents and keep them up to date. Storage space must be used efficiently to store indices and, optionally, the documents themselves. The indexing system must process hundreds of gigabytes of data efficiently. Queries must be handled quickly, at a rate of hundreds to thousands per second.
即便针对当下的网络环境,搭建可平稳扩容的搜索引擎也困难重重。系统需要高速抓取技术来收集网页文档并保证内容及时更新,同时高效利用存储空间存放索引及原始文档。索引系统需具备处理数百 GB 数据的能力,检索请求也需实现每秒数百至数千条的快速响应。
These tasks are becoming increasingly difficult as the Web grows. However, hardware performance and cost have improved dramatically to partially offset the difficulty. There are, however, several notable exceptions to this progress such as disk seek time and operating system robustness. In designing Google, we have considered both the rate of growth of the Web and technological changes. Google is designed to scale well to extremely large data sets. It makes efficient use of storage space to store the index. Its data structures are optimized for fast and efficient access (see section 4.2). Further, we expect that the cost to index and store text or HTML will eventually decline relative to the amount that will be available (see Appendix B). This will result in favorable scaling properties for centralized systems like Google.
随着网络规模不断扩大,上述工作的难度持续上升。不过硬件性能提升与成本下降,在一定程度上缓解了这些问题。但磁盘寻道时间、操作系统稳定性等方面的短板依旧突出。在谷歌的设计过程中,我们充分考量了网络增长速度与技术迭代趋势。谷歌可平稳适配超大规模数据集,对索引的存储空间进行了优化,同时针对数据快速访问需求完成数据结构优化(详见 4.2 节)。此外我们预判,随着文本与超文本标记语言文档体量不断增加,索引与存储的单位成本将会持续下降(详见附录 B),这会让谷歌这类集中式系统具备优异的扩容特性。
1.3 Design Goals
1.3 设计目标
1.3.1 Improved Search Quality
1.3.1 提升搜索质量
Our main goal is to improve the quality of web search engines. In 1994, some people believed that a complete search index would make it possible to find anything easily. According to Best of the Web 1994 -- Navigators, "The best navigation service should make it easy to find almost anything on the Web (once all the data is entered)." However, the Web of 1997 is quite different. Anyone who has used a search engine recently, can readily testify that the completeness of the index is not the only factor in the quality of search results. "Junk results" often wash out any results that a user is interested in. In fact, as of November 1997, only one of the top four commercial search engines finds itself (returns its own search page in response to its name in the top ten results). One of the main causes of this problem is that the number of documents in the indices has been increasing by many orders of magnitude, but the user's ability to look at documents has not. People are still only willing to look at the first few tens of results.
本系统的核心目标是提升网络搜索引擎的检索质量。1994 年,部分观点认为,只要搭建完整的检索索引,用户就能轻松找到所需内容。《1994 年度优秀网络导航服务》中提到:"完善的导航服务,应能让用户轻松找到网络上的几乎所有内容(前提是全部数据已录入索引)。"但 1997 年的网络环境早已截然不同。当下使用过搜索引擎的用户都能发现,索引的完整性并非决定搜索结果质量的唯一因素,大量无效信息往往会淹没用户真正需要的内容。截至 1997 年 11 月,四大主流商用搜索引擎中,仅有一家在检索自身名称时,能将官方页面排在结果前十位。该问题的主要成因是:索引内的文档数量呈数量级增长,但用户浏览结果的能力并未同步提升,用户通常只会查看前几十条结果。
Because of this, as the collection size grows, we need tools that have very high precision (number of relevant documents returned, say in the top tens of results). Indeed, we want our notion of "relevant" to only include the very best documents since there may be tens of thousands of slightly relevant documents. This very high precision is important even at the expense of recall (the total number of relevant documents the system is able to return). There is quite a bit of recent optimism that the use of more hypertextual information can help improve search and other applications Marchiori 97 Spertus 97 Weiss 96 Kleinberg 98. In particular, link structure Page 98 and link text provide a lot of information for making relevance judgments and quality filtering. Google makes use of both link structure and anchor text (see Sections 2.1 and 2.2).
因此,随着数据集规模扩大,搜索引擎必须具备极高的检索精准度(保证前几十条结果均为有效内容)。网络中可能存在数万条弱相关文档,因此我们定义的"相关内容"仅指向最优文档。即便牺牲召回率(系统可返回的全部相关文档总数),也要保证高精准度。多项近期研究表明,深挖超文本信息能够有效优化搜索及各类应用(参考文献 Marchiori 97 Spertus 97 Weiss 96 Kleinberg 98)。其中,链接结构(参考文献 Page 98)与链接文本可用于判断内容相关性、筛选优质页面。谷歌同时运用了链接结构与锚文本技术(详见 2.1、2.2 节)。
1.3.2 Academic Search Engine Research
1.3.2 推动搜索引擎领域学术研究
Aside from tremendous growth, the Web has also become increasingly commercial over time. In 1993, 1.5% of web servers were on .com domains. This number grew to over 60% in 1997. At the same time, search engines have migrated from the academic domain to the commercial. Up until now most search engine development has gone on at companies with little publication of technical details. This causes search engine technology to remain largely a black art and to be advertising oriented (see Appendix A). With Google, we have a strong goal to push more development and understanding into the academic realm.
除规模飞速扩张外,网络的商业化程度也不断加深。1993 年,仅有 1.5% 的网络服务器使用商业域名 .com,到 1997 年这一比例已突破 60%。与此同时,搜索引擎也从学术领域逐步转向商用领域。目前,搜索引擎的研发工作大多由企业主导,核心技术细节极少对外公开,这使得搜索引擎技术近乎成为"黑箱技术",且整体偏向广告导向(详见附录 A)。我们研发谷歌的另一重要目标,是推动搜索引擎技术在学术领域的发展与普及。
Another important design goal was to build systems that reasonable numbers of people can actually use. Usage was important to us because we think some of the most interesting research will involve leveraging the vast amount of usage data that is available from modern web systems. For example, there are many tens of millions of searches performed every day. However, it is very difficult to get this data, mainly because it is considered commercially valuable.
另一项重要设计目标是打造可供大量用户正常使用的系统。我们十分重视系统的实际使用场景,因为现代网络系统会产生海量用户行为数据,基于这些数据能够开展极具价值的研究。例如,全网每日会产生数千万条检索记录,但这类数据因具备商业价值,极难获取。
Our final design goal was to build an architecture that can support novel research activities on large-scale web data. To support novel research uses, Google stores all of the actual documents it crawls in compressed form. One of our main goals in designing Google was to set up an environment where other researchers can come in quickly, process large chunks of the web, and produce interesting results that would have been very difficult to produce otherwise. In the short time the system has been up, there have already been several papers using databases generated by Google, and many others are underway. Another goal we have is to set up a Spacelab-like environment where researchers or even students can propose and do interesting experiments on our large-scale web data.
最后一项设计目标是搭建架构,支持基于大规模网络数据的前沿研究。为满足科研需求,谷歌将抓取到的全部原始文档以压缩格式存储。谷歌的核心设计初衷之一,是搭建开放环境,让其他研究人员能够快速处理海量网络数据,完成以往难以实现的研究。系统上线短期内,已有多篇论文基于谷歌的数据库完成,更多相关研究也在推进中。我们还希望打造类似太空实验室的科研平台,供研究人员乃至学生基于大规模网络数据开展各类创新实验。
2. System Features
2. 系统特性
The Google search engine has two important features that help it produce high precision results. First, it makes use of the link structure of the Web to calculate a quality ranking for each web page. This ranking is called PageRank and is described in detail in Page 98. Second, Google utilizes link to improve search results.
谷歌拥有两大核心特性,用以保障高精准度的搜索结果。第一,系统利用网络链接结构计算每个网页的质量排名,该算法即为网页排名算法(PageRank),详细介绍见参考文献 Page 98。第二,谷歌借助链接信息优化搜索结果。
2.1 PageRank: Bringing Order to the Web
2.1 网页排名算法:梳理网络内容权重
The citation (link) graph of the web is an important resource that has largely gone unused in existing web search engines. We have created maps containing as many as 518 million of these hyperlinks, a significant sample of the total. These maps allow rapid calculation of a web page's "PageRank", an objective measure of its citation importance that corresponds well with people's subjective idea of importance. Because of this correspondence, PageRank is an excellent way to prioritize the results of web keyword searches. For most popular subjects, a simple text matching search that is restricted to web page titles performs admirably when PageRank prioritizes the results (demo available at google.stanford.edu). For the type of full text searches in the main Google system, PageRank also helps a great deal.
网络的引用(链接)图谱是一项重要资源,却基本未被现有搜索引擎利用。我们构建了包含 5.18 亿条超链接的图谱,这也是全网链接的大规模样本。依托该图谱可快速计算网页的网页排名值,该数值能够客观衡量网页的引用权重,且与大众对网页重要性的主观认知高度契合。因此,网页排名算法是关键词检索结果排序的优质方案。针对多数热门检索内容,仅基于网页标题做简单文本匹配,再结合网页排名算法排序,就能得到理想效果(演示地址:google.stanford.edu)。在谷歌全文检索场景中,网页排名算法同样发挥着重要作用。
2.1.1 Description of PageRank Calculation
2.1.1 网页排名算法计算原理
Academic citation literature has been applied to the web, largely by counting citations or backlinks to a given page. This gives some approximation of a page's importance or quality. PageRank extends this idea by not counting links from all pages equally, and by normalizing by the number of links on a page. PageRank is defined as follows:
学术界的文献引用逻辑被借鉴到网络领域,主流方式是统计网页的引用量与反向链接数量,以此粗略判定网页的重要性与质量。网页排名算法在此基础上做出优化:不再对所有链接一视同仁,同时结合网页的出链数量做归一化处理。网页排名的定义如下:
We assume page A has pages T1...Tn which point to it (i.e., are citations). The parameter d is a damping factor which can be set between 0 and 1 . We usually set d to 0.85. There are more details about d in the next section. Also C ( A ) C(A) C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows:
假设网页 A 被网页 T 1 T_1 T1 至 T n T_n Tn 链接指向(即被引用)。参数 d d d 为阻尼系数,取值范围在 0 0 0 到 1 1 1 之间,本系统默认取值为 0.85 0.85 0.85,下一节将详细说明该参数。(C(A)$ 代表网页 A 的出链数量。网页 A 的网页排名计算公式如下:
P R ( A ) = ( 1 − d ) + d ( P R ( T 1 ) C ( T 1 ) + ⋯ + P R ( T n ) C ( T n ) ) P R(A)=(1-d)+d\left(\frac{P R(T_1)}{C(T_1)}+\dots+\frac{P R(T_n)}{C(T_n)}\right) PR(A)=(1−d)+d(C(T1)PR(T1)+⋯+C(Tn)PR(Tn))
Note that the PageRanks form a probability distribution over web pages, so the sum of all web pages' PageRanks will be one.
所有网页的网页排名值构成概率分布,因此全网所有网页的网页排名值总和为 1 1 1。
PageRank or P R ( A ) P R(A) PR(A) can be calculated using a simple iterative algorithm, and corresponds to the principal eigenvector of the normalized link matrix of the web. Also, a PageRank for 26 million web pages can be computed in a few hours on a medium size workstation. There are many other details which are beyond the scope of this paper.
网页排名值 P R ( A ) PR(A) PR(A) 可通过简易迭代算法计算,其结果等价于全网归一化链接矩阵的主特征向量。一台中等配置的工作站,仅需数小时即可完成 2600 万网页的网页排名计算。更多技术细节不在本文讨论范围内。
2.1.2 Intuitive Justification
2.1.2 算法逻辑通俗解读
PageRank can be thought of as a model of user behavior. We assume there is a "random surfer" who is given a web page at random and keeps clicking on links, never hitting "back" but eventually gets bored and starts on another random page. The probability that the random surfer visits a page is its PageRank. And, the damping factor is the probability at each page the "random surfer" will get bored and request another random page. One important variation is to only add the damping factor d to a single page, or a group of pages. This allows for personalization and can make it nearly impossible to deliberately mislead the system in order to get a higher ranking. We have several other extensions to PageRank, again see Page 98.
网页排名算法可以理解为一种用户行为模型。我们假设存在一名"随机浏览者":该用户随机打开一个网页,持续点击页面内链接且不使用返回功能,最终因失去兴趣,转而打开另一个随机网页。网页被这名随机浏览者访问的概率,即为该网页的网页排名值。阻尼系数代表浏览者在当前页面失去兴趣、跳转至随机新页面的概率。该算法可做拓展优化:仅对单个或部分网页启用阻尼系数,以此实现个性化排序,同时大幅降低人为刷取高排名、误导系统的可能性。网页排名算法还有其他拓展方案,详见参考文献 Page 98。
Another intuitive justification is that a page can have a high PageRank if there are many pages that point to it, or if there are some pages that point to it and have a high PageRank. Intuitively, pages that are well cited from many places around the web are worth looking at. Also, pages that have perhaps only one citation from something like the Yahoo! homepage are also generally worth looking at. If a page was not high quality, or was a broken link, it is quite likely that Yahoo's homepage would not link to it. PageRank handles both these cases and everything in between by recursively propagating weights through the link structure of the web.
从另一角度解读:若一个网页被大量页面链接指向,或是被多个高权重页面链接指向,其网页排名值就会较高。直观来看,被全网多处引用的网页通常具备较高价值。同理,即便一个网页仅被雅虎首页这类高权重页面单次引用,其质量也普遍有所保障,低质页面或失效链接基本不会被这类主流首页引用。网页排名算法依托网络链接结构递归传递权重,能够适配上述各类场景。
2.2 Anchor Text
2.2 锚文本
The text of links is treated in a special way in our search engine. Most search engines associate the text of a link with the page that the link is on. In addition, we associate it with the page the link points to. This has several advantages. First, anchors often provide more accurate descriptions of web pages than the pages themselves. Second, anchors may exist for documents which cannot be indexed by a text-based search engine, such as images, programs, and databases. This makes it possible to return web pages which have not actually been crawled. Note that pages that have not been crawled can cause problems, since they are never checked for validity before being returned to the user. In this case, the search engine can even return a page that never actually existed, but had hyperlinks pointing to it. However, it is possible to sort the results, so that this particular problem rarely happens.
本系统对链接文本采用特殊处理方式。多数搜索引擎仅将链接文本归属到链接所在页面,而我们同时将其关联至链接指向的页面。该方式具备多项优势:第一,锚文本往往比网页自身内容更能精准描述页面主题;第二,图片、程序、数据库等无法被文本检索引擎索引的资源,通常会配有锚文本,借助锚文本可检索到这类未被抓取的资源。需要注意的是,未被抓取的页面未经有效性校验就展示给用户,会产生问题,系统甚至可能返回仅有链接指向、实际并不存在的页面。但通过合理的结果排序,可大幅减少这类问题的出现。
This idea of propagating anchor text to the page it refers to was implemented in the World Wide Web Worm McBryan 94 especially because it helps search non-text information, and expands the search coverage with fewer downloaded documents. We use anchor propagation mostly because anchor text can help provide better quality results. Using anchor text efficiently is technically difficult because of the large amounts of data which must be processed. In our current crawl of 24 million pages, we had over 259 million anchors which we indexed.
将锚文本关联至目标页面的思路,最早应用于万维网蠕虫(参考文献 McBryan 94),该思路可实现非文本资源检索,还能在少下载页面的前提下扩大检索范围。我们应用锚文本关联技术,核心目的是提升搜索结果质量。但锚文本数据体量庞大,高效处理存在技术难点。在本次 2400 万页面的抓取任务中,我们共索引了超过 2.59 亿条锚文本。
2.3 Other Features
2.3 其他特性
Aside from PageRank and the use of anchor text, Google has several other features. First, it has location information for all hits and so it makes extensive use of proximity in search. Second, Google keeps track of some visual presentation details such as font size of words. Words in a larger or bolder font are weighted higher than other words. Third, full raw HTML of pages is available in a repository.
除网页排名算法与锚文本技术外,谷歌还具备多项附加特性。第一,系统记录所有检索词的位置信息,广泛运用词邻近度规则优化检索;第二,系统识别网页视觉样式细节,例如字体大小,字号更大、字体加粗的词汇会被赋予更高权重;第三,系统仓库中存储了网页完整的原始超文本标记语言代码。
3 Related Work
3. 相关研究现状
Search research on the web has a short and concise history. The World Wide Web Worm (WWWW) McBryan 94 was one of the first web search engines. It was subsequently followed by several other academic search engines, many of which are now public companies. Compared to the growth of the Web and the importance of search engines there are precious few documents about recent search engines Pinkerton 94. According to Michael Mauldin (chief scientist, Lycos Inc) Mauldin, "the various services (including Lycos) closely guard the details of these databases". However, there has been a fair amount of work on specific features of search engines. Especially well represented is work which can get results by post-processing the results of existing commercial search engines, or produce small scale "individualized" search engines. Finally, there has been a lot of research on information retrieval systems, especially on well controlled collections. In the next two sections, we discuss some areas where this research needs to be extended to work better on the web.
网络检索领域的研究历史较短。万维网蠕虫(WWWW)(参考文献 McBryan 94)是最早的一批网络搜索引擎之一,此后又涌现出多款学术类搜索引擎,其中不少现已转型为商业公司。相较于网络的发展速度与搜索引擎的重要性,针对新一代搜索引擎的公开研究文献十分稀缺(参考文献 Pinkerton 94)。莱科斯公司首席科学家迈克尔·莫尔丁曾表示:"包括莱科斯在内的各大检索服务商,均严格保密数据库核心细节。"不过,针对搜索引擎单项功能的研究成果较为丰富,其中两大研究方向尤为突出:一是基于现有商用搜索引擎的结果做二次处理,二是搭建小型个性化搜索引擎。此外,信息检索系统的相关研究成果众多,且大多基于管控规范的数据集开展。接下来两节将探讨现有研究需要拓展的方向,以适配网络检索场景。
3.1 Information Retrieval
3.1 信息检索技术
Work in information retrieval systems goes back many years and is well developed Witten 94. However, most of the research on information retrieval systems is on small well controlled homogeneous collections such as collections of scientific papers or news stories on a related topic. Indeed, the primary benchmark for information retrieval, the Text Retrieval Conference TREC 96, uses a fairly small, well controlled collection for their benchmarks. The "Very Large Corpus" benchmark is only 20GB compared to the 147GB from our crawl of 24 million web pages. Things that work well on TREC often do not produce good results on the web. For example, the standard vector space model tries to return the document that most closely approximates the query, given that both query and document are vectors defined by their word occurrence. On the web, this strategy often returns very short documents that are the query plus a few words. For example, we have seen a major search engine return a page containing only "Bill Clinton Sucks" and picture from a "Bill Clinton" query. Some argue that on the web, users should specify more accurately what they want and add more words to their query. We disagree vehemently with this position. If a user issues a query like "Bill Clinton" they should get reasonable results since there is a enormous amount of high quality information available on this topic. Given examples like these, we believe that the standard information retrieval work needs to be extended to deal effectively with the web.
信息检索系统的研究历史悠久,技术体系已较为成熟(参考文献 Witten 94)。但现有研究大多基于小规模、管控严格、内容单一的数据集,例如专题学术论文、同类新闻稿件。信息检索领域的权威评测平台文本检索会议(TREC 96),所使用的基准数据集同样规模有限、管控规范。其"超大型语料库"基准数据集仅 20 GB,而我们抓取 2400 万网页得到的数据总量就达到 147 GB。在文本检索会议数据集上表现优异的技术,往往无法适配网络场景。例如经典向量空间模型:将检索词与文档基于词频构建向量,返回与检索向量相似度最高的文档。该策略应用在网络中时,常会匹配到仅包含检索词加少量文字的极短页面。举例而言,某主流搜索引擎在检索"比尔·克林顿"时,返回了仅含不当言论与一张图片的页面。部分观点认为,网络用户应当细化检索需求、增加检索词,但我们对此并不认同。检索"比尔·克林顿"这类关键词时,网络上存在大量优质相关内容,搜索引擎理应返回合理结果。由此可见,传统信息检索技术需要拓展优化,才能有效适配网络环境。
3.2 Differences Between the Web and Well Controlled Collections
3.2 网络数据集与标准受控数据集的差异
The web is a vast collection of completely uncontrolled heterogeneous documents. Documents on the web have extreme variation internal to the documents, and also in the external meta information that might be available. For example, documents differ internally in their language (both human and programming), vocabulary (email addresses, links, zip codes, phone numbers, product numbers), type or format (text, HTML, PDF, images, sounds), and may even be machine generated (log files or output from a database). On the other hand, we define external meta information as information that can be inferred about a document, but is not contained within it. Examples of external meta information include things like reputation of the source, update frequency, quality, popularity or usage, and citations. Not only are the possible sources of external meta information varied, but the things that are being measured vary many orders of magnitude as well. For example, compare the usage information from a major homepage, like Yahoo's which currently receives millions of page views every day with an obscure historical article which might receive one view every ten years. Clearly, these two items must be treated very differently by a search engine.
网络是海量、无管控、内容异构的文档集合。网页的内部内容与外部元数据都存在极大差异。从内容层面来看,网页使用的自然语言、编程语言各不相同,包含邮箱、链接、邮编、电话、产品编号等各类词汇,格式涵盖文本、超文本标记语言、便携文档格式、图片、音频等,部分内容甚至是机器自动生成的日志文件、数据库输出内容。外部元数据指文档本身不包含、但可间接推导的信息,例如来源可信度、更新频率、内容质量、访问量、引用量等。外部元数据的来源多样,且对应指标的数值跨度可达多个数量级。以雅虎首页与一篇冷门历史文献对比:前者日均访问量达数百万次,后者可能十年仅有一次访问,搜索引擎必须对二者做差异化处理。
Another big difference between the web and traditional well controlled collections is that there is virtually no control over what people can put on the web. Couple this flexibility to publish anything with the enormous influence of search engines to route traffic and companies which deliberately manipulating search engines for profit become a serious problem. This problem that has not been addressed in traditional closed information retrieval systems. Also, it is interesting to note that metadata efforts have largely failed with web search engines, because any text on the page which is not directly represented to the user is abused to manipulate search engines. There are even numerous companies which specialize in manipulating search engines for profit.
网络与传统标准数据集的另一核心差异,是网络内容发布完全不受管控。网络发布自由,叠加搜索引擎巨大的流量导向作用,催生了大量企业为牟利刻意作弊、操纵搜索结果的行为,这一问题从未在传统封闭式信息检索系统中出现。此外,网页元数据技术在搜索引擎场景中基本失效:网页内对用户不可见的文本,常被恶意利用来操纵检索排名,市面上甚至出现了专门以此牟利的公司。
4 System Anatomy
4. 系统架构
First, we will provide a high level discussion of the architecture. Then, there is some in-depth descriptions of important data structures. Finally, the major applications: crawling, indexing, and searching will be examined in depth.
本节首先介绍系统整体架构,随后详解核心数据结构,最后深入分析三大核心模块:网页抓取、索引构建与检索服务。
4.1 Google Architecture Overview
4.1 谷歌整体架构概述
In this section, we will give a high level overview of how the whole system works as pictured in Figure 1. Further sections will discuss the applications and data structures not mentioned in this section. Most of Google is implemented in C or C++ for efficiency and can run in either Solaris or Linux.
本节结合图 1 介绍系统整体运行逻辑,未提及的功能模块与数据结构将在后续章节详述。为保障运行效率,谷歌主体代码采用 C / C++ 编写,可运行在 Solaris 与 Linux 操作系统上。
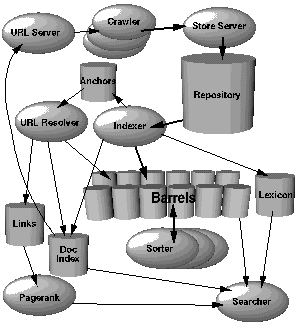
Figure 1. High Level Google Architecture
图 1. 谷歌整体架构
| URL Server | URL 服务端 |
|---|---|
| Crawler | 抓取服务端 |
| Store Server | 存储服务端 |
| Anchors | 锚文本 |
| Repository | 资源仓库 |
| URL Resolver | URL 解析器 |
| Indexer | 索引器 |
| Barrels | 索引分桶 |
| Lexicon | 词库 |
| Links | 链接库 |
| Sorter | 排序器 |
| PageRank | 网页排名模块 |
| Searcher | 检索模块 |
In Google, the web crawling (downloading of web pages) is done by several distributed crawlers. There is a URLserver that sends lists of URLs to be fetched to the crawlers. The web pages that are fetched are then sent to the storeserver. The storeserver then compresses and stores the web pages into a repository. Every web page has an associated ID number called a docID which is assigned whenever a new URL is parsed out of a web page. The indexing function is performed by the indexer and the sorter. The indexer performs a number of functions. It reads the repository, uncompresses the documents, and parses them. Each document is converted into a set of word occurrences called hits. The hits record the word, position in document, an approximation of font size, and capitalization. The indexer distributes these hits into a set of "barrels", creating a partially sorted forward index. The indexer performs another important function. It parses out all the links in every web page and stores important information about them in an anchors file. This file contains enough information to determine where each link points from and to, and the text of the link.
谷歌采用多分布式抓取器完成网页抓取(下载)工作。网址服务端向抓取器下发待抓取网址列表,抓取到的网页统一传输至存储服务端,由存储服务端压缩后存入文档仓库。系统解析出新网址时,会为对应网页分配唯一文档编号。索引工作由索引器与排序器协同完成。索引器的功能包括:读取仓库内文档、解压并解析内容,将每份文档转换为词项记录集合;词项记录会标注词汇、词汇在文档中的位置、字号信息与大小写状态。索引器将词项记录分配至多个"索引分桶",生成初步排序的正向索引。同时,索引器会提取网页内所有链接,将链接来源、目标地址、链接文本等关键信息存入锚文本文件。
The URLresolver reads the anchors file and converts relative URLs into absolute URLs and in turn into docIDs. It puts the anchor text into the forward index, associated with the docID that the anchor points to. It also generates a database of links which are pairs of docIDs. The links database is used to compute PageRanks for all the documents.
网址解析器读取锚文本文件,将相对网址转换为绝对网址,并映射为对应的文档编号;同时将锚文本关联至目标文档编号,存入正向索引。此外,网址解析器会生成由文档编号对组成的链接数据库,该数据库用于计算所有网页的网页排名值。
The sorter takes the barrels, which are sorted by docID (this is a simplification, see Section 4.2.5), and resorts them by wordID to generate the inverted index. This is done in place so that little temporary space is needed for this operation. The sorter also produces a list of wordIDs and offsets into the inverted index. A program called DumpLexicon takes this list together with the lexicon produced by the indexer and generates a new lexicon to be used by the searcher. The searcher is run by a web server and uses the lexicon built by DumpLexicon together with the inverted index and the PageRanks to answer queries.
排序器读取按文档编号排序的索引分桶(简化描述,详见 4.2.5 节),按照词汇编号重新排序,生成倒排索引。该过程为原地排序,几乎无需额外临时存储空间。排序器同时输出词汇编号与倒排索引偏移量列表。词汇库生成程序结合该列表与索引器产出的原始词库,生成检索服务专用词库。检索服务由网页服务器承载,依托专用词库、倒排索引与网页排名数据处理用户检索请求。
4.2 Major Data Structures
4.2 核心数据结构
Google's data structures are optimized so that a large document collection can be crawled, indexed, and searched with little cost. Although, CPUs and bulk input output rates have improved dramatically over the years, a disk seek still requires about 10 ms to complete. Google is designed to avoid disk seeks whenever possible, and this has had a considerable influence on the design of the data structures.
谷歌对数据结构做了深度优化,实现海量文档的低成本抓取、索引与检索。多年来,中央处理器与批量读写性能大幅提升,但单次磁盘寻道仍需约 10 毫秒。因此谷歌在设计时尽可能减少磁盘寻道操作,这一原则也主导了整体数据结构的设计思路。
4.2.1 BigFiles
4.2.1 大文件结构
BigFiles are virtual files spanning multiple file systems and are addressable by 64 bit integers. The allocation among multiple file systems is handled automatically. The BigFiles package also handles allocation and deallocation of file descriptors, since the operating systems do not provide enough for our needs. BigFiles also support rudimentary compression options.
大文件是跨多个文件系统的虚拟文件,采用 64 位整数寻址,可自动完成多文件系统间的空间分配。由于操作系统原生文件描述符数量无法满足需求,大文件组件还负责文件描述符的分配与释放,同时支持基础压缩功能。
4.2.2 Repository
4.2.2 文档仓库
The repository contains the full HTML of every web page. Each page is compressed using zlib (see RFC1950). The choice of compression technique is a tradeoff between speed and compression ratio. We chose zlib's speed over a significant improvement in compression offered by bzip. The compression rate of bzip was approximately 4 to 1 on the repository as compared to zlib's 3 to 1 compression. In the repository, the documents are stored one after the other and are prefixed by docID, length, and URL as can be seen in Figure 2. The repository requires no other data structures to be used in order to access it. This helps with data consistency and makes development much easier; we can rebuild all the other data structures from only the repository and a file which lists crawler errors.
文档仓库存储所有网页的完整超文本标记语言代码,所有页面均采用 zlib 算法压缩(参考 RFC1950 标准)。压缩算法的选择需要在压缩速度与压缩率之间权衡:bzip 算法压缩率更高(压缩比约 4:1),但我们优先选择速度更快的 zlib 算法(压缩比约 3:1)。文档在仓库中连续存储,每条文档头部标注文档编号、文档长度与网址,结构如图 2 所示。访问文档仓库无需依赖其他附属数据结构,既保障了数据一致性,也降低了开发难度。仅依靠文档仓库与抓取错误日志文件,即可重建整套附属数据结构。
Repository. 53.5 GB = 147.8 GB uncompressed
文档仓库:压缩后 53.5 GB,原始数据 147.8 GB

Figure 2. Repository Data Structure
图 2. 文档仓库数据结构
| synclength | 同步长度 |
|---|---|
| compressed packet | 压缩数据包 |
| Packet (stored compressed in repository) | 数据包(在仓库中压缩存储) |
| docid | 文档 ID |
| ecode | 编码标识 |
| urlen | 链接长度 |
| pagelen | 页面长度 |
| uri | 统一资源标识符(链接) |
| page | 页面数据 |
4.2.3 Document Index
4.2.3 文档索引
The document index keeps information about each document. It is a fixed width ISAM (Index sequential access mode) index, ordered by docID. The information stored in each entry includes the current document status, a pointer into the repository, a document checksum, and various statistics. If the document has been crawled, it also contains a pointer into a variable width file called docinfo which contains its URL and title. Otherwise the pointer points into the URLlist which contains just the URL. This design decision was driven by the desire to have a reasonably compact data structure, and the ability to fetch a record in one disk seek during a search
文档索引记录每份文档的相关信息,是按文档编号排序的定长索引顺序访问模式索引。单条索引记录包含文档状态、仓库内存储指针、文档校验和及各类统计信息。若该网页已完成抓取,索引会指向变长文档信息文件(存储网址与页面标题);若未抓取,则指向仅存放网址的网址列表文件。该设计兼顾了数据结构的精简性,同时保证检索时单次磁盘寻道即可读取单条索引记录。
Additionally, there is a file which is used to convert URLs into docIDs. It is a list of URL checksums with their corresponding docIDs and is sorted by checksum. In order to find the docID of a particular URL, the URL's checksum is computed and a binary search is performed on the checksums file to find its docID. URLs may be converted into docIDs in batch by doing a merge with this file. This is the technique the URLresolver uses to turn URLs into docIDs. This batch mode of update is crucial because otherwise we must perform one seek for every link which assuming one disk would take more than a month for our 322 million link dataset.
系统还配有网址与文档编号映射文件:该文件按网址校验和排序,逐条记录网址校验和与对应文档编号。查询指定网址的文档编号时,先计算网址校验和,再通过二分查找在映射文件中匹配结果。网址解析器依托该文件,批量完成网址到文档编号的转换。批量更新模式至关重要:若对 3.22 亿条链接逐条做磁盘寻道匹配,单块磁盘完成该任务需要一个月以上。
4.2.4 Lexicon
4.2.4 词库
The lexicon has several different forms. One important change from earlier systems is that the lexicon can fit in memory for a reasonable price. In the current implementation we can keep the lexicon in memory on a machine with 256 MB of main memory. The current lexicon contains 14 million words (though some rare words were not added to the lexicon). It is implemented in two parts -- a list of the words (concatenated together but separated by nulls) and a hash table of pointers. For various functions, the list of words has some auxiliary information which is beyond the scope of this paper to explain fully.
词库分为多种形态。相较于早期系统,本系统的一大改进是:在硬件成本可控的前提下,词库可完整加载至内存。当前配置下,一台 256 MB 内存的设备即可容纳全量词库。词库共收录 1400 万个词汇(部分生僻词汇未录入),整体分为两部分:一是词汇列表(词汇连续存储,以空字符分隔),二是指针哈希表。词汇列表还附带各类辅助信息,相关细节本文不再赘述。
4.2.5 Hit Lists
4.2.5 词项记录表
A hit list corresponds to a list of occurrences of a particular word in a particular document including position, font, and capitalization information. Hit lists account for most of the space used in both the forward and the inverted indices. Because of this, it is important to represent them as efficiently as possible. We considered several alternatives for encoding position, font, and capitalization -- simple encoding (a triple of integers), a compact encoding (a hand optimized allocation of bits), and Huffman coding. In the end we chose a hand optimized compact encoding since it required far less space than the simple encoding and far less bit manipulation than Huffman coding. The details of the hits are shown in Figure 3.
词项记录表用于记录单个词汇在文档中的所有出现信息,包括位置、字体、大小写。正向索引与倒排索引的存储空间,绝大部分被词项记录表占用,因此其编码方式必须极致精简。我们对比了三种编码方案:基础整数三元组编码、人工优化位压缩编码、哈夫曼编码。最终选用人工优化位压缩编码,该方案的空间占用远低于基础编码,同时相比哈夫曼编码大幅减少位运算开销。词项记录的编码细节如图 3 所示。
Our compact encoding uses two bytes for every hit. There are two types of hits: fancy hits and plain hits. Fancy hits include hits occurring in a URL, title, anchor text, or meta tag. Plain hits include everything else. A plain hit consists of a capitalization bit, font size, and 12 bits of word position in a document (all positions higher than 4095 are labeled 4096). Font size is represented relative to the rest of the document using three bits (only 7 values are actually used because 111 is the flag that signals a fancy hit). A fancy hit consists of a capitalization bit, the font size set to 7 to indicate it is a fancy hit, 4 bits to encode the type of fancy hit, and 8 bits of position. For anchor hits, the 8 bits of position are split into 4 bits for position in anchor and 4 bits for a hash of the docID the anchor occurs in. This gives us some limited phrase searching as long as there are not that many anchors for a particular word. We expect to update the way that anchor hits are stored to allow for greater resolution in the position and docIDhash fields. We use font size relative to the rest of the document because when searching, you do not want to rank otherwise identical documents differently just because one of the documents is in a larger font.
本系统每条词项记录固定占用 2 字节,分为特殊词项与普通词项两类。特殊词项包含出现在网址、标题、锚文本、元标签中的词汇;其余场景的词汇均为普通词项。普通词项编码结构:1 位大小写标识、3 位字号标识、12 位词汇位置标识(位置编号超过 4095 时统一记为 4096)。字号采用相对值编码,3 位二进制共支持 7 种取值,二进制 111 作为特殊词项的标记位。特殊词项编码结构:1 位大小写标识、字号位固定设为 7(标记类型)、4 位类型标识、8 位位置标识。锚文本类特殊词项的 8 位位置标识拆分使用:4 位记录词汇在锚文本内的位置,4 位记录锚文本所属文档编号的哈希值。依托该结构,在单个词汇锚文本数量不多的情况下,可实现简单短语检索。后续我们计划优化锚文本词项的存储格式,提升位置与文档编号哈希字段的精度。字号采用相对值编码,是为了避免内容一致的文档,仅因字体大小不同而出现排名差异。
The length of a hit list is stored before the hits themselves. To save space, the length of the hit list is combined with the wordID in the forward index and the docID in the inverted index. This limits it to 8 and 5 bits respectively (there are some tricks which allow 8 bits to be borrowed from the wordID). If the length is longer than would fit in that many bits, an escape code is used in those bits, and the next two bytes contain the actual length.
词项记录表的长度字段存储在记录内容之前。为节省空间,正向索引中将记录表长度与词汇编号合并存储(占用 8 位),倒排索引中将记录表长度与文档编号合并存储(占用 5 位),同时采用位复用技术从词汇编号中借用 8 位扩容。当长度超出对应比特位的表示范围时,对应比特位写入转义符,后续 2 字节存储真实长度。
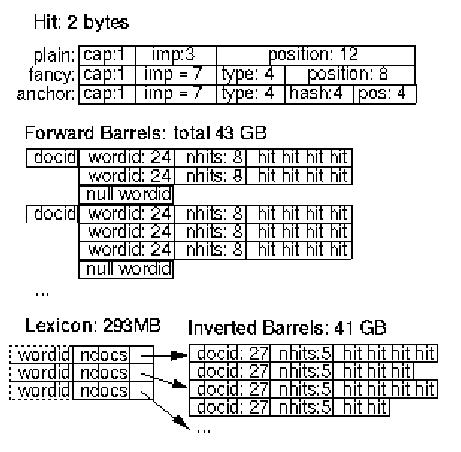
Figure 3. Forward and Reverse Indexes and the Lexicon
图 3. 正向索引、倒排索引与词库结构
数据结构&存储说明
| Hit | 词项记录 |
|---|---|
| plain / fancy | 普通 / 特殊类型 |
| cap | 大小写(位) |
| font | 字号 |
| position | 位置(位) |
| fancy | 特殊类型 |
| flag | 标记位 |
| type | 类型(位) |
| anchor | 锚文本类型 |
| pos | 锚文本位置(位) |
| hash | 文档哈希(位) |
| Forward Barrels | 正向索引分桶 |
| Lexicon | 词库 |
| Inverted Barrels | 倒排索引分桶 |
| docid | 文档编号 |
| wordid | 词汇编号 |
| nhits | 词项数(number of hits,hit 在此处指词项命中记录) |
4.2.6 Forward Index
4.2.6 正向索引
The forward index is actually already partially sorted. It is stored in a number of barrels (we used 64). Each barrel holds a range of wordID's. If a document contains words that fall into a particular barrel, the docID is recorded into the barrel, followed by a list of wordID's with hitlists which correspond to those words. This scheme requires slightly more storage because of duplicated docIDs but the difference is very small for a reasonable number of buckets and saves considerable time and coding complexity in the final indexing phase done by the sorter. Furthermore, instead of storing actual wordID's, we store each wordID as a relative difference from the minimum wordID that falls into the barrel the wordID is in. This way, we can use just 24 bits for the wordID's in the unsorted barrels, leaving 8 bits for the hit list length.
正向索引为预部分序结构,分为多个索引分桶(本系统使用 64 个分桶),每个分桶对应一段连续的词汇编号区间。若文档内的词汇归属某个分桶,则该分桶中记录此文档编号,以及对应词汇编号与词项记录表。该方案会因文档编号重复占用少量额外空间,但分桶数量合理时,空间损耗极小,同时大幅降低排序器在最终索引阶段的耗时与开发复杂度。此外,分桶内不存储原始词汇编号,而是存储词汇编号与当前分桶最小词汇编号的差值。基于该方式,分桶内词汇编号仅需 24 位表示,剩余 8 位用于存储词项记录表长度。
4.2.7 Inverted Index
4.2.7 倒排索引
The inverted index consists of the same barrels as the forward index, except that they have been processed by the sorter. For every valid wordID, the lexicon contains a pointer into the barrel that wordID falls into. It points to a doclist of docID's together with their corresponding hit lists. This doclist represents all the occurrences of that word in all documents.
倒排索引沿用正向索引的分桶结构,由排序器处理生成。词库中为每个有效词汇编号配置指针,指向其所属分桶,指针最终定位到文档列表。文档列表记录所有包含该词汇的文档编号,以及对应的词项记录表,完整呈现该词汇在全网文档中的所有出现位置。
An important issue is in what order the docID's should appear in the doclist. One simple solution is to store them sorted by docID. This allows for quick merging of different doclists for multiple word queries. Another option is to store them sorted by a ranking of the occurrence of the word in each document. This makes answering one word queries trivial and makes it likely that the answers to multiple word queries are near the start. However, merging is much more difficult. Also, this makes development much more difficult in that a change to the ranking function requires a rebuild of the index. We chose a compromise between these options, keeping two sets of inverted barrels -- one set for hit lists which include title or anchor hits and another set for all hit lists. This way, we check the first set of barrels first and if there are not enough matches within those barrels we check the larger ones.
文档列表中文档编号的排序规则是核心设计点。方案一:按文档编号排序,多词汇检索时可快速合并多条文档列表;方案二:按词汇在文档中的权重排序,单词汇检索效率极高,多词汇检索的优质结果也会集中在列表前端,但多列表合并难度大,且排序规则修改后需要全量重建索引,开发维护成本高。本系统采用折中方案,维护两套倒排索引分桶:第一套仅收录标题、锚文本类词项记录,第二套收录全量词项记录。检索时优先查询第一套分桶,若匹配结果数量不足,再查询全量分桶。
4.3 Crawling the Web
4.3 网页抓取模块
Running a web crawler is a challenging task. There are tricky performance and reliability issues and even more importantly, there are social issues. Crawling is the most fragile application since it involves interacting with hundreds of thousands of web servers and various name servers which are all beyond the control of the system.
网页抓取模块的研发难度较高,不仅存在性能与稳定性难题,还会涉及各类网络沟通问题。该模块需要与数十万台网页服务器、域名服务器交互,而这些设备均不受本系统管控,因此也是整套系统中最易出现故障的模块。
In order to scale to hundreds of millions of web pages, Google has a fast distributed crawling system. A single URLserver serves lists of URLs to a number of crawlers (we typically ran about 3). Both the URLserver and the crawlers are implemented in Python. Each crawler keeps roughly 300 connections open at once. This is necessary to retrieve web pages at a fast enough pace. At peak speeds, the system can crawl over 100 web pages per second using four crawlers. This amounts to roughly 600K per second of data. A major performance stress is DNS lookup. Each crawler maintains a its own DNS cache so it does not need to do a DNS lookup before crawling each document. Each of the hundreds of connections can be in a number of different states: looking up DNS, connecting to host, sending request, and receiving response. These factors make the crawler a complex component of the system. It uses asynchronous IO to manage events, and a number of queues to move page fetches from state to state.
为实现数亿网页的抓取能力,谷歌采用高速分布式抓取架构。单台网址服务端向多台抓取器分发网址列表(常规部署 3 台抓取器),网址服务端与抓取器均使用 Python 开发。单台抓取器同时维持约 300 条网络连接,保障抓取速度。四台抓取器并行工作时,系统峰值抓取速度可达每秒 100 个网页,数据下载速率约每秒 600 KB。域名解析是主要性能瓶颈,因此每台抓取器都配备独立域名解析缓存,避免每个网页都重复发起域名查询。数百条连接会分别处于域名解析、建立连接、发送请求、接收响应等不同状态,这也让抓取器的逻辑变得复杂。模块采用异步输入输出机制处理各类事件,并通过多级队列完成抓取任务的状态流转。
It turns out that running a crawler which connects to more than half a million servers, and generates tens of millions of log entries generates a fair amount of email and phone calls. Because of the vast number of people coming on line, there are always those who do not know what a crawler is, because this is the first one they have seen. Almost daily, we receive an email something like, "Wow, you looked at a lot of pages from my web site. How did you like it?" There are also some people who do not know about the robots exclusion protocol, and think their page should be protected from indexing by a statement like, "This page is copyrighted and should not be indexed", which needless to say is difficult for web crawlers to understand. Also, because of the huge amount of data involved, unexpected things will happen. For example, our system tried to crawl an online game. This resulted in lots of garbage messages in the middle of their game! It turns out this was an easy problem to fix. But this problem had not come up until we had downloaded tens of millions of pages. Because of the immense variation in web pages and servers, it is virtually impossible to test a crawler without running it on large part of the Internet. Invariably, there are hundreds of obscure problems which may only occur on one page out of the whole web and cause the crawler to crash, or worse, cause unpredictable or incorrect behavior. Systems which access large parts of the Internet need to be designed to be very robust and carefully tested. Since large complex systems such as crawlers will invariably cause problems, there needs to be significant resources devoted to reading the email and solving these problems as they come up.
抓取器需对接超 50 万台服务器,每日产生数千万条日志,也因此收到大量邮件与电话咨询。大量网络用户初次接触爬虫程序,并不了解其原理,我们几乎每天都会收到类似"你们访问了我网站大量页面,体验如何?"的邮件。还有部分用户不了解爬虫排除协议,仅在页面标注"本页面受版权保护,禁止索引",希望阻止爬虫抓取,而这类文本无法被爬虫识别。海量数据抓取过程中还会出现各类突发问题,例如抓取在线游戏页面时,会获取到大量游戏交互垃圾信息,该问题虽易修复,但在抓取数千万页面后才被发现。网页与服务器的环境千差万别,仅靠小规模测试无法验证爬虫稳定性,必须接入大规模网络环境实测。全网中存在数百类小众异常场景,仅在个别页面触发,轻则导致爬虫崩溃,重则引发不可预知的错误行为。面向全网的系统必须具备极强的健壮性,并经过严格测试。爬虫这类大型复杂系统难免出现各类问题,因此需要专门人力对接用户反馈、及时排障。
4.4 Indexing the Web
4.4 索引构建模块
Parsing -- Any parser which is designed to run on the entire Web must handle a huge array of possible errors. These range from typos in HTML tags to kilobytes of zeros in the middle of a tag, non-ASCII characters, HTML tags nested hundreds deep, and a great variety of other errors that challenge anyone's imagination to come up with equally creative ones. For maximum speed, instead of using YACC to generate a CFG parser, we use flex to generate a lexical analyzer which we outfit with its own stack. Developing this parser which runs at a reasonable speed and is very robust involved a fair amount of work.
内容解析:面向全网的解析器,必须兼容各类异常格式。包括超文本标记语言标签拼写错误、标签内存在大量零字节、非 ASCII 字符、标签数百层深度嵌套,以及各类非常规错误。为追求极致解析速度,我们未使用 YACC 生成上下文无关文法解析器,而是基于 flex 生成词法分析器,并为其定制独立栈结构。开发这款兼顾速度与健壮性的解析器,投入了大量工作量。
Indexing Documents into Barrels -- After each document is parsed, it is encoded into a number of barrels. Every word is converted into a wordID by using an in-memory hash table -- the lexicon. New additions to the lexicon hash table are logged to a file. Once the words are converted into wordID's, their occurrences in the current document are translated into hit lists and are written into the forward barrels. The main difficulty with parallelization of the indexing phase is that the lexicon needs to be shared. Instead of sharing the lexicon, we took the approach of writing a log of all extra words that were not in a base lexicon, which we fixed at 14 million words. That way multiple indexers can run in parallel and then the small log file of extra words can be processed by one final indexer.
文档分桶索引:文档解析完成后,内容会编码并写入对应索引分桶。系统通过内存哈希表(词库)将词汇转换为唯一词汇编号,词库新增词汇会单独记录至日志文件。词汇转为编号后,其在文档中的出现信息生成词项记录表,写入正向索引分桶。索引模块并行化的最大难点是词库共享。本系统设置 1400 万个基础词汇,索引器不共享全量词库,仅将基础词库外的新增词汇写入日志。多台索引器可并行工作,最终由一台索引器统一处理新增词汇日志。
Sorting -- In order to generate the inverted index, the sorter takes each of the forward barrels and sorts it by wordID to produce an inverted barrel for title and anchor hits and a full text inverted barrel. This process happens one barrel at a time, thus requiring little temporary storage. Also, we parallelize the sorting phase to use as many machines as we have simply by running multiple sorters, which can process different buckets at the same time. Since the barrels don't fit into main memory, the sorter further subdivides them into baskets which do fit into memory based on wordID and docID. Then the sorter, loads each basket into memory, sorts it and writes its contents into the short inverted barrel and the full text inverted barrel.
排序处理:排序器逐个读取正向索引分桶,按词汇编号排序,分别生成标题与锚文本专用倒排分桶、全文倒排分桶。该流程逐桶执行,几乎不占用临时存储空间。排序阶段支持多机并行,部署多台排序器即可同时处理不同分桶。由于单个体索引分桶无法完整载入内存,排序器会依据词汇编号与文档编号,将其拆分为多个可载入内存的子数据集。排序器依次将子数据集载入内存、完成排序,再分别写入两类倒排分桶。
4.5 Searching
4.5 检索服务模块
The goal of searching is to provide quality search results efficiently. Many of the large commercial search engines seemed to have made great progress in terms of efficiency. Therefore, we have focused more on quality of search in our research, although we believe our solutions are scalable to commercial volumes with a bit more effort. The google query evaluation process is show in Figure 4.
检索服务的核心目标是高效输出高质量结果。主流商用搜索引擎在检索效率上已较为成熟,因此本研究重点优化检索质量,同时我们认为稍加改造后,本方案可适配商用级检索并发量。谷歌的检索处理流程如图 4 所示。
To put a limit on response time, once a certain number (currently 40,000) of matching documents are found, the searcher automatically goes to step 8 in Figure 4. This means that it is possible that sub-optimal results would be returned. We are currently investigating other ways to solve this problem. In the past, we sorted the hits according to PageRank, which seemed to improve the situation.
为控制响应时长,系统检索到指定数量(当前为 40000 条)匹配文档后,会直接跳转至图 4 中第 8 步,这可能导致部分优质结果被遗漏。我们目前正在研究优化方案,此前曾通过网页排名值对结果预排序,一定程度上缓解了该问题。
4.5.1 The Ranking System
4.5.1 结果排序体系
Google maintains much more information about web documents than typical search engines. Every hitlist includes position, font, and capitalization information. Additionally, we factor in hits from anchor text and the PageRank of the document. Combining all of this information into a rank is difficult. We designed our ranking function so that no particular factor can have too much influence. First, consider the simplest case -- a single word query. In order to rank a document with a single word query, Google looks at that document's hit list for that word.
谷歌存储的网页维度信息远多于传统搜索引擎,每条词项记录都包含位置、字体、大小写信息,同时系统还会结合锚文本词项与网页排名值综合打分。多维度指标融合排序存在较大难度,因此我们设计的排序函数会均衡各维度权重,避免单一指标主导结果。以最简单的单词汇检索为例:系统读取该词汇在所有文档中的词项记录表,以此作为排序依据。
Google considers each hit to be one of several different types (title, anchor, URL, plain text large font, plain text small font, ...), each of which has its own type-weight. The type-weights make up a vector indexed by type. Google counts the number of hits of each type in the hit list. Then every count is converted into a count-weight. Count-weights increase linearly with counts at first but quickly taper off so that more than a certain count will not help. We take the dot product of the vector of count-weights with the vector of type-weights to compute an IR score for the document. Finally, the IR score is combined with PageRank to give a final rank to the document.
系统将词项记录划分为多个类型(标题、锚文本、网址、正文大号字体、正文小号字体等),并为每种类型设置独立类型权重,构成类型权重向量。系统统计各类词项的出现次数,将次数转换为次数权重:次数权重随出现次数线性增长,达到阈值后不再提升,避免词项堆砌影响排序。将次数权重向量与类型权重向量做点积运算,得到文档的信息检索得分,最终结合网页排名值,生成文档综合排名。
For a multi-word search, the situation is more complicated. Now multiple hit lists must be scanned through at once so that hits occurring close together in a document are weighted higher than hits occurring far apart. The hits from the multiple hit lists are matched up so that nearby hits are matched together. For every matched set of hits, a proximity is computed. The proximity is based on how far apart the hits are in the document (or anchor) but is classified into 10 different value "bins" ranging from a phrase match to "not even close". Counts are computed not only for every type of hit but for every type and proximity. Every type and proximity pair has a type-prox-weight. The counts are converted into count-weights and we take the dot product of the count-weights and the type-prox-weights to compute an IR score. All of these numbers and matrices can all be displayed with the search results using a special debug mode. These displays have been very helpful in developing the ranking system.
多词汇检索的逻辑更为复杂。系统需要同时遍历多条词项记录表,词汇位置相邻的文档会被赋予更高权重。系统匹配不同词汇的词项记录,优先组合位置邻近的词汇,并计算词汇邻近度。邻近度根据词汇在文档或锚文本中的间距划分 10 个等级,从完全短语匹配到间距极远依次区分。统计维度拓展为"词项类型 + 邻近度"组合,每种组合对应专属权重。统计结果转换为次数权重后,与组合权重向量做点积运算,得到信息检索得分。系统提供专用调试模式,可随检索结果展示所有权重、向量与矩阵数据,为排序体系的迭代优化提供支撑。
4.5.2 Feedback
4.5.2 人工反馈机制
The ranking function has many parameters like the type-weights and the type-prox-weights. Figuring out the right values for these parameters is something of a black art. In order to do this, we have a user feedback mechanism in the search engine. A trusted user may optionally evaluate all of the results that are returned. This feedback is saved. Then when we modify the ranking function, we can see the impact of this change on all previous searches which were ranked. Although far from perfect, this gives us some idea of how a change in the ranking function affects the search results.
排序函数包含类型权重、邻近度组合权重等大量参数,参数调优难度较高。为此系统搭建了人工反馈机制:授权用户可对检索结果进行评价,评价数据统一存储。当修改排序函数参数后,可回溯历史检索记录,验证参数调整对结果的影响。该机制虽并非完美,但能有效辅助参数调优。
-
Parse the query.
解析检索语句
-
Convert words into wordIDs.
将检索词汇转换为词汇编号
-
Seek to the start of the doclist in the short barrel for every word.
定位每个词汇在精简倒排分桶内文档列表的起始位置
-
Scan through the doclists until there is a document that matches all the search terms.
遍历文档列表,筛选出包含所有检索词的文档
-
Compute the rank of that document for the query.
计算该文档针对本次检索的排名分值
-
If we are in the short barrels and at the end of any doclist, seek to the start of the doclist in the full barrel for every word and go to step 4.
若当前使用精简倒排分桶,且任意一个文档列表已遍历完毕,则切换至全量倒排分桶,重新定位所有词汇的文档列表起始位置,并回到第 4 步。
-
If we are not at the end of any doclist go to step 4.
若所有文档列表均未遍历完毕,则回到第 4 步。
Sort the documents that have matched by rank and return the top k.
将所有匹配文档按排名排序,返回排名靠前的 k 条结果。
图 4. Google Query Evaluation
图 4. 谷歌检索执行流程
5 Results and Performance
5. 实验结果与系统性能
The most important measure of a search engine is the quality of its search results. While a complete user evaluation is beyond the scope of this paper, our own experience with Google has shown it to produce better results than the major commercial search engines for most searches. As an example which illustrates the use of PageRank, anchor text, and proximity, Figure 4 shows Google's results for a search on "bill clinton". These results demonstrates some of Google's features. The results are clustered by server. This helps considerably when sifting through result sets. A number of results are from the whitehouse.gov domain which is what one may reasonably expect from such a search. Currently, most major commercial search engines do not return any results from whitehouse.gov, much less the right ones. Notice that there is no title for the first result. This is because it was not crawled. Instead, Google relied on anchor text to determine this was a good answer to the query. Similarly, the fifth result is an email address which, of course, is not crawlable. It is also a result of anchor text.
衡量搜索引擎优劣最核心的指标是搜索结果质量。本文未开展完整的用户测评,但实际使用体验表明,在绝大多数检索场景下,谷歌的搜索结果优于主流商用搜索引擎。为展示网页排名算法、锚文本与词邻近度的实际效果,图 4 展示了检索 "bill clinton" 时谷歌返回的结果,这些结果体现了谷歌的多项特性。检索结果按照服务器域名聚合归类,极大方便用户筛选内容。多条结果来自 whitehouse.gov 域名,这也是该检索词对应的理想内容来源。而当时多数主流商用搜索引擎甚至无法返回该域名下的内容,更不用说精准结果。可以看到第一条结果没有页面标题,原因是该页面未被系统抓取,谷歌依靠锚文本判定其与检索内容高度相关。同理,第五条结果是一个邮箱地址,这类资源无法被爬虫抓取,同样是依托锚文本实现检索命中。
All of the results are reasonably high quality pages and, at last check, none were broken links. This is largely because they all have high PageRank. The PageRanks are the percentages in red along with bar graphs. Finally, there are no results about a Bill other than Clinton or about a Clinton other than Bill. This is because we place heavy importance on the proximity of word occurrences. Of course a true test of the quality of a search engine would involve an extensive user study or results analysis which we do not have room for here. Instead, we invite the reader to try Google for themselves at http://google.stanford.edu.
本次返回的所有结果均为高质量页面,经核查不存在失效链接,这主要得益于这些页面都拥有较高的网页排名值。图中以红色百分比与柱状图展示各页面的网页排名值。此外,检索结果中没有出现其他名为比尔的人物、或是其他姓克林顿的人物,这是因为系统高度重视词汇在页面中的邻近关系。当然,完整的搜索引擎质量评测需要大规模用户调研与结果分析,受篇幅限制本文不再展开,读者可自行访问体验谷歌原型系统。

Figure 4. Sample Results from Google
来自谷歌的示例结果
5.1 Storage Requirements
5.1 存储资源占用
Aside from search quality, Google is designed to scale cost effectively to the size of the Web as it grows. One aspect of this is to use storage efficiently. Table 1 has a breakdown of some statistics and storage requirements of Google. Due to compression the total size of the repository is about 53 GB, just over one third of the total data it stores. At current disk prices this makes the repository a relatively cheap source of useful data. More importantly, the total of all the data used by the search engine requires a comparable amount of storage, about 55 GB. Furthermore, most queries can be answered using just the short inverted index. With better encoding and compression of the Document Index, a high quality web search engine may fit onto a 7GB drive of a new PC.
除了保障搜索质量外,谷歌在设计上兼顾了扩容成本,能够低成本适配持续增长的网络规模,高效利用存储空间是关键一环。表 1 统计了谷歌各项数据的规模与存储占用情况。得益于压缩技术,文档仓库总容量约为 53 GB,仅为原始数据体积的三分之一多。结合当时的磁盘价格来看,文档仓库的存储成本较低。更重要的是,搜索引擎运行所需的其余全部数据总占用空间约 55 GB,与文档仓库体量相近。绝大多数检索请求仅依靠精简倒排索引即可完成响应。如果对文档索引进一步优化编码与压缩算法,一套高品质的网络搜索引擎甚至可以部署在一台个人电脑的 7 GB 硬盘分区中。
Storage Statistics 存储统计
| 指标项 | 数值 |
|---|---|
| Total Size of Fetched Pages 抓取页面原始总大小 | 147.8 GB |
| Compressed Repository 压缩后文档仓库 | 53.5 GB |
| Short Inverted Index 精简倒排索引 | 4.1 GB |
| Full Inverted Index 全量倒排索引 | 37.2 GB |
| Lexicon 词库 | 293 MB |
| Temporary Anchor Data (not in total) 锚文本临时数据(不计入总计) | 6.6 GB |
| Document Index Incl. Variable Width Data 文档索引(含变长数据) | 9.7 GB |
| Links Database 链接数据库 | 3.9 GB |
| Total Without Repository 不含文档仓库总占用 | 55.2 GB |
| Total With Repository 含文档仓库总占用 | 108.7 GB |
Web Page Statistics 网页数据统计
| 指标项 | 数值 |
|---|---|
| Number of Web Pages Fetched 已抓取网页数量 | 24 million 2400 万 |
| Number of Urls Seen 累计发现网址数量 | 76.5 million 7650 万 |
| Number of Email Addresses 提取邮箱地址数量 | 1.7 million 170 万 |
| Number of 404's 404 失效页面数量 | 1.6 million 160 万 |
5.2 System Performance
5.2 系统整体性能
It is important for a search engine to crawl and index efficiently. This way information can be kept up to date and major changes to the system can be tested relatively quickly. For Google, the major operations are Crawling, Indexing, and Sorting. It is difficult to measure how long crawling took overall because disks filled up, name servers crashed, or any number of other problems which stopped the system. In total it took roughly 9 days to download the 26 million pages (including errors). However, once the system was running smoothly, it ran much faster, downloading the last 11 million pages in just 63 hours, averaging just over 4 million pages per day or 48.5 pages per second. We ran the indexer and the crawler simultaneously. The indexer ran just faster than the crawlers. This is largely because we spent just enough time optimizing the indexer so that it would not be a bottleneck. These optimizations included bulk updates to the document index and placement of critical data structures on the local disk. The indexer runs at roughly 54 pages per second. The sorters can be run completely in parallel; using four machines, the whole process of sorting takes about 24 hours.
高效的抓取与索引能力对搜索引擎至关重要,既能保证内容及时更新,也能快速完成系统版本迭代与功能测试。谷歌的核心作业模块分为网页抓取、索引构建与排序处理。受磁盘占满、域名服务器宕机等各类故障影响,难以统计完整抓取周期。系统累计耗时约 9 天完成 2600 万页面的抓取(含异常页面)。系统稳定运行后效率大幅提升,仅用 63 小时就完成了最后 1100 万页面的抓取,日均抓取量超 400 万页面,平均每秒抓取 48.5 个页面。索引器与抓取器同步运行,且索引器处理速度略高于抓取器。我们针对性优化了索引器,避免其成为性能瓶颈,优化内容包括文档索引批量更新、将核心数据结构部署在本地磁盘等。索引器的处理速度约为每秒 54 个页面。排序模块支持全并行运行,使用四台服务器时,完整排序流程耗时约 24 小时。
5.3 Search Performance
5.3 检索性能
Improving the performance of search was not the major focus of our research up to this point. The current version of Google answers most queries in between 1 and 10 seconds. This time is mostly dominated by disk IO over NFS (since disks are spread over a number of machines). Furthermore, Google does not have any optimizations such as query caching, subindices on common terms, and other common optimizations. We intend to speed up Google considerably through distribution and hardware, software, and algorithmic improvements. Our target is to handle several hundred queries per second. Table 2 has some sample query times from the current version of Google. They are repeated to show the speedups resulting from cached IO.
本阶段研究并未将检索性能作为核心优化方向。当前版本的谷歌处理绝大多数检索请求的耗时在 1 至 10 秒之间,延迟主要来自网络文件系统的磁盘读写(数据磁盘分布式部署在多台设备上)。同时该版本未启用检索缓存、高频词子索引等常规优化手段。后续我们计划通过分布式架构、硬件升级、软件调优与算法迭代大幅提升检索速度,目标是实现每秒处理数百条检索请求。表 2 列出了当前版本谷歌的检索耗时样本,通过重复执行相同检索,展示磁盘读写缓存带来的性能提升。
| Query 检索词 | Initial Query 首次检索 | Same Query Repeated (IO mostly cached) 重复检索(读写已缓存) | ||
|---|---|---|---|---|
| CPU Time(s) 处理器耗时(秒) | Total Time(s) 总耗时(秒) | CPU Time(s) 处理器耗时(秒) | Total Time(s) 总耗时(秒) | |
| al gore 艾尔·戈尔 | 0.09 | 2.13 | 0.06 | 0.06 |
| vice president 副总统 | 1.77 | 3.84 | 1.66 | 1.80 |
| hard disks 硬盘 | 0.25 | 4.86 | 0.20 | 0.24 |
| search engines 搜索引擎 | 1.31 | 9.63 | 1.16 | 1.16 |
Table 2. Search Times
表2 检索耗时
6 Conclusions
6. 总结
Google is designed to be a scalable search engine. The primary goal is to provide high quality search results over a rapidly growing World Wide Web. Google employs a number of techniques to improve search quality including page rank, anchor text, and proximity information. Furthermore, Google is a complete architecture for gathering web pages, indexing them, and performing search queries over them.
谷歌是一套具备良好扩容能力的搜索引擎,核心目标是在规模飞速扩张的万维网环境中提供高质量搜索结果。系统综合运用网页排名算法、锚文本、词汇邻近度等多项技术提升检索质量,同时谷歌也是一套集网页抓取、索引构建、检索服务于一体的完整架构。
6.1 Future Work
6.1 未来研究方向
A large-scale web search engine is a complex system and much remains to be done. Our immediate goals are to improve search efficiency and to scale to approximately 100 million web pages. Some simple improvements to efficiency include query caching, smart disk allocation, and subindices. Another area which requires much research is updates. We must have smart algorithms to decide what old web pages should be recrawled and what new ones should be crawled. Work toward this goal has been done in Cho 98. One promising area of research is using proxy caches to build search databases, since they are demand driven. We are planning to add simple features supported by commercial search engines like boolean operators, negation, and stemming. However, other features are just starting to be explored such as relevance feedback and clustering (Google currently supports a simple hostname based clustering). We also plan to support user context (like the user's location), and result summarization. We are also working to extend the use of link structure and link text. Simple experiments indicate PageRank can be personalized by increasing the weight of a user's home page or bookmarks. As for link text, we are experimenting with using text surrounding links in addition to the link text itself. A Web search engine is a very rich environment for research ideas. We have far too many to list here so we do not expect this Future Work section to become much shorter in the near future.
大型网络搜索引擎是复杂的系统工程,仍有大量研究工作待完成。我们现阶段的目标是提升检索效率,并将索引规模扩容至约 1 亿个网页。可落地的基础优化方案包括新增检索缓存、智能磁盘分配、子索引等。网页更新策略也是重点研究方向,需要设计智能算法判定哪些历史页面需要重新抓取、哪些新页面需要新增抓取,相关研究已有成果发表。利用代理缓存构建检索数据库是一个具备潜力的方向,该架构基于用户访问需求驱动。我们计划增添商用搜索引擎已普及的基础功能,例如布尔运算、否定检索、词干提取。同时,相关性反馈、结果聚类等功能尚处于探索阶段(当前谷歌仅支持基于域名的简单聚类)。后续还将支持用户场景信息(例如地理位置)、检索结果摘要生成功能。我们也会进一步拓展链接结构与链接文本的应用场景。初步实验表明,通过提升用户主页、收藏页面的权重,可以实现网页排名算法的个性化定制。在链接文本方面,我们尝试结合链接周边文本一同分析,而非仅使用链接本身文字。网络搜索引擎可衍生出大量研究方向,受篇幅限制无法一一列举,因此短期内本章节的研究方向列表不会缩减。
6.2 High Quality Search
6.2 高质量检索
The biggest problem facing users of web search engines today is the quality of the results they get back. While the results are often amusing and expand users' horizons, they are often frustrating and consume precious time. For example, the top result for a search for "Bill Clinton" on one of the most popular commercial search engines was the Bill Clinton Joke of the Day: April 14, 1997. Google is designed to provide higher quality search so as the Web continues to grow rapidly, information can be found easily. In order to accomplish this Google makes heavy use of hypertextual information consisting of link structure and link (anchor) text. Google also uses proximity and font information. While evaluation of a search engine is difficult, our subjectively found that Google returns higher quality search results than current commercial search engines. The analysis of link structure via PageRank allows Google to evaluate the quality of web pages. The use of link text as a description of what the link points to helps the search engine return relevant (and to some degree high quality) results. Finally, the use of proximity information helps increase relevance a great deal for many queries.
当时搜索引擎用户面临的最大问题就是检索结果质量参差不齐。部分结果虽内容新奇、拓宽视野,但更多低质内容会浪费用户大量时间。举例来说,某主流商用搜索引擎检索 "Bill Clinton" 时,首条结果是 1997 年 4 月 14 日的相关趣味段子。谷歌以打造高质量检索服务为目标,力求在网络规模持续扩张的背景下,让用户快速获取有效信息。为实现该目标,系统深度挖掘超文本信息,包括链接结构与锚文本,同时结合词汇邻近度、字体样式等维度优化结果。搜索引擎的量化评测难度较高,但从实际使用体验来看,谷歌的结果质量优于同期商用搜索引擎。依托网页排名算法分析链接结构,系统能够评判网页本身质量;将锚文本作为目标页面的描述信息,有助于返回相关度高且质量可靠的内容;而词汇邻近度规则则大幅提升了多数检索场景的内容匹配度。
6.3 Scalable Architecture
6.3 可扩展架构
Aside from the quality of search, Google is designed to scale. It must be efficient in both space and time, and constant factors are very important when dealing with the entire Web. In implementing Google, we have seen bottlenecks in CPU, memory access, memory capacity, disk seeks, disk throughput, disk capacity, and network IO. Google has evolved to overcome a number of these bottlenecks during various operations. Google's major data structures make efficient use of available storage space. Furthermore, the crawling, indexing, and sorting operations are efficient enough to be able to build an index of a substantial portion of the web -- 24 million pages, in less than one week. We expect to be able to build an index of 100 million pages in less than a month.
除检索质量外,谷歌的架构天生支持横向扩容。面向全网数据时,系统的空间利用率与运行效率至关重要,底层常数级性能优化也会产生显著影响。在谷歌的落地过程中,我们先后遇到处理器、内存访问、内存容量、磁盘寻道、磁盘吞吐、磁盘容量、网络读写等多类性能瓶颈,并针对性完成优化。谷歌的核心数据结构实现了存储空间的高效利用,同时网页抓取、索引构建、排序等核心流程效率出众,可在一周内完成 2400 万网页的索引搭建。我们预估,系统可在一个月内完成 1 亿网页的全量索引构建。
6.4 A Research Tool
6.4 科研应用价值
In addition to being a high quality search engine, Google is a research tool. The data Google has collected has already resulted in many other papers submitted to conferences and many more on the way. Recent research such as Abiteboul 97 has shown a number of limitations to queries about the Web that may be answered without having the Web available locally. This means that Google (or a similar system) is not only a valuable research tool but a necessary one for a wide range of applications. We hope Google will be a resource for searchers and researchers all around the world and will spark the next generation of search engine technology.
谷歌不仅是一款高性能搜索引擎,同时也是重要的科研工具。依托谷歌采集的数据集,已有多篇论文发表于各类学术会议,更多相关研究也在推进中。参考文献Abiteboul 97等近期研究表明,脱离本地全网数据集,大量网络相关检索与分析工作将存在明显局限。这意味着谷歌及同类系统不仅具备科研价值,更是诸多研究方向不可或缺的基础平台。我们希望谷歌能够为全球普通用户与科研人员提供数据与服务支持,并推动下一代搜索引擎技术的创新发展。
7 Acknowledgments
7. 致谢
Scott Hassan and Alan Steremberg have been critical to the development of Google. Their talented contributions are irreplaceable, and the authors owe them much gratitude. We would also like to thank Hector Garcia-Molina, Rajeev Motwani, Jeff Ullman, and Terry Winograd and the whole WebBase group for their support and insightful discussions. Finally we would like to recognize the generous support of our equipment donors IBM, Intel, and Sun and our funders. The research described here was conducted as part of the Stanford Integrated Digital Library Project, supported by the National Science Foundation under Cooperative Agreement IRI-9411306. Funding for this cooperative agreement is also provided by DARPA and NASA, and by Interval Research, and the industrial partners of the Stanford Digital Libraries Project.
斯科特·哈桑与艾伦·斯特恩伯格为谷歌的研发做出了至关重要的贡献,他们的工作无可替代,在此我们致以诚挚的谢意。同时感谢赫克托·加西亚-莫利纳、拉吉夫·莫特瓦尼、杰夫·乌尔曼、特里·维诺格拉德以及整个 WebBase 团队提供的支持与富有价值的探讨。感谢 IBM、英特尔、昇阳等设备捐赠方,以及所有资助机构的鼎力支持。本文相关研究隶属于斯坦福综合数字图书馆项目,该项目由美国国家科学基金会依据合作协议 IRI-9411306 资助,美国国防高级研究计划局、美国国家航空航天局、英特沃研究公司以及斯坦福数字图书馆项目的合作企业也为本项目提供了资金支持。
References
参考文献
-
Best of the Web 1994 -- Navigators http://botw.org/1994/awards/navigators.html
1994年度优秀网络导航服务
-
Bill Clinton Joke of the Day: April 14, 1997. http://www.io.com/~cjburke/clinton/970414.html
1997年4月14日比尔·克林顿趣味段子
-
Bzip2 Homepage http://www.muraroa.demon.co.uk/
Bzip2压缩算法官网
-
Google Search Engine http://google.stanford.edu/
谷歌搜索引擎原型站点(内容可正常读取)
-
Harvest http://harvest.transarc.com/
Harvest检索系统
-
Mauldin, Michael L. Lycos Design Choices in an Internet Search Service, IEEE Expert Interview http://www.computer.org/pubs/expert/1997/trends/x1008/mauldin.htm
迈克尔·莫尔丁:莱科斯互联网检索服务的设计思路(IEEE专家访谈)(页面404,资源不存在)
-
The Effect of Cellular Phone Use Upon Driver Attention http://www.webfirst.com/aaa/text/cell/cell0toc.htm
手机使用对驾驶员注意力的影响
-
Search Engine Watch http://www.searchenginewatch.com/
搜索引擎观察资讯站
-
RFC 1950 (zlib) ftp://ftp.uu.net/graphics/png/documents/zlib/zdoc-index.html
RFC 1950(zlib压缩协议)
-
Robots Exclusion Protocol: http://info.webcrawler.com/mak/projects/robots/exclusion.htm
爬虫排除协议规范
-
Web Growth Summary: http://www.mit.edu/people/mkgray/net/web-growth-summary.html
网络规模增长统计
-
Yahoo! http://www.yahoo.com/
雅虎官网
-
Abiteboul 97 Serge Abiteboul and Victor Vianu, Queries and Computation on the Web. Proceedings of the International Conference on Database Theory. Delphi, Greece 1997.
Abiteboul 97 塞尔日·阿比特布尔、维克多·维亚努:《网络查询与计算》,数据库理论国际会议论文集,1997年,希腊德尔斐
-
Bagdikian 97 Ben H. Bagdikian. The Media Monopoly. 5th Edition. Publisher: Beacon, ISBN: 0807061557
Bagdikian 97 本·巴格迪基安:《媒体垄断》(第5版),灯塔出版社,书号:0807061557
-
Cho 98 Junghoo Cho, Hector Garcia-Molina, Lawrence Page. Efficient Crawling Through URL Ordering. Seventh International Web Conference (WWW 98). Brisbane, Australia, April 14-18, 1998.
Cho 98 赵俊浩、赫克托·加西亚-莫利纳、劳伦斯·佩奇:《基于网址排序的高效网页抓取》,第七届国际万维网大会,1998年4月14日-18日,澳大利亚布里斯班
-
Gravano 94 Luis Gravano, Hector Garcia-Molina, and A. Tomasic. The Effectiveness of GlOSS for the Text-Database Discovery Problem. Proc. of the 1994 ACM SIGMOD International Conference On Management Of Data, 1994.
Gravano 94 路易斯·格拉瓦诺等人:《GlOSS系统在文本数据库检索中的有效性》,1994年ACM数据管理国际会议论文集
-
Kleinberg 98 Jon Kleinberg, Authoritative Sources in a Hyperlinked Environment, Proc. ACM-SIAM Symposium on Discrete Algorithms, 1998.
Kleinberg 98 乔恩·克莱因伯格:《超链接环境下的权威信息源识别》,ACM-SIAM离散算法研讨会论文集,1998年
-
Marchiori 97 Massimo Marchiori. The Quest for Correct Information on the Web: Hyper Search Engines. The Sixth International WWW Conference (WWW 97). Santa Clara, USA, April 7-11, 1997.
Marchiori 97 马西莫·马尔基奥里:《网络精准信息探索:超链接搜索引擎》,第六届国际万维网大会,1997年4月7日-11日,美国圣克拉拉
-
McBryan 94 Oliver A. McBryan. GENVL and WWWW: Tools for Taming the Web. First International Conference on the World Wide Web. CERN, Geneva (Switzerland), May 25-26-27 1994. http://www.cs.colorado.edu/home/mcbryan/mypapers/www94.ps
McBryan 94 奥利弗·麦克布莱恩:《GENVL与WWWW:网络管理工具》,首届国际万维网大会,1994年5月25日-27日,瑞士日内瓦欧洲核子研究中心
-
Page 98 Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd. The PageRank Citation Ranking: Bringing Order to the Web. Manuscript in progress. http://google.stanford.edu/~backrub/pageranksub.ps
Page 98 劳伦斯·佩奇、谢尔盖·布林等人:《网页排名引用算法:梳理网络权重》
-
Pinkerton 94 Brian Pinkerton, Finding What People Want: Experiences with the WebCrawler. The Second International WWW Conference Chicago, USA, October 17-20, 1994. http://info.webcrawler.com/bp/WWW94.html
Pinkerton 94 布莱恩·平克顿:《挖掘用户检索需求:WebCrawler实践经验》,第二届国际万维网大会,1994年10月17日-20日,美国芝加哥
-
Spertus 97 Ellen Spertus. ParaSite: Mining Structural Information on the Web. The Sixth International WWW Conference (WWW 97). Santa Clara, USA, April 7-11, 1997.
Spertus 97 埃伦·斯珀特斯:《ParaSite:网络结构信息挖掘》,第六届国际万维网大会,1997年4月7日-11日,美国圣克拉拉
-
TREC 96 Proceedings of the fifth Text REtrieval Conference (TREC-5). Gaithersburg, Maryland, November 1996. Publisher: Department of Commerce, National Institute of Standards and Technology. Editors: D. K. Harman and E. M. Voorhees. Full text at: http://www.nist.gov/
TREC 96 第五届文本检索会议论文集,1996年11月,美国马里兰州盖瑟斯堡,由美国国家标准与技术研究院出版,编者:D. K. 哈曼、E. M. 沃希斯(链接可正常访问)
-
Witten 94 Ian H Witten, Alistair Moffat, and Timothy C. Bell. Managing Gigabytes: Compressing and Indexing Documents and Images. New York: Van Nostrand Reinhold, 1994.
Witten 94 伊恩·威滕等人:《海量数据管理:文档与图片的压缩与索引》,范诺斯特兰德出版社,1994年,纽约
-
Weiss 96 Ron Weiss, Bienvenido Velez, Mark A. Sheldon, Chanathip Manprempre, Peter Szilagyi, Andrzej Duda, and David K. Gifford. HyPursuit: A Hierarchical Network Search Engine that Exploits Content-Link Hypertext Clustering. Proceedings of the 7th ACM Conference on Hypertext. New York, 1996.
Weiss 96 罗恩·韦斯等人:《HyPursuit:基于内容与超链接聚类的分层网络搜索引擎》,第七届ACM超文本会议论文集,1996年,纽约
Vitae
作者简介
Sergey Brin received his B.S. degree in mathematics and computer science from the University of Maryland at College Park in 1993. Currently, he is a Ph.D. candidate in computer science at Stanford University where he received his M.S. in 1995. He is a recipient of a National Science Foundation Graduate Fellowship. His research interests include search engines, information extraction from unstructured sources, and data mining of large text collections and scientific data.
谢尔盖·布林于 1993 年获得马里兰大学帕克分校数学与计算机科学学士学位,1995 年于斯坦福大学取得计算机科学硕士学位,现为该校计算机科学专业博士在读。他曾获得美国国家科学基金会研究生奖学金。研究方向包括搜索引擎、非结构化信息抽取、海量文本与科研数据挖掘。
Lawrence Page was born in East Lansing, Michigan, and received a B.S.E. in Computer Engineering at the University of Michigan Ann Arbor in 1995. He is currently a Ph.D. candidate in Computer Science at Stanford University. Some of his research interests include the link structure of the web, human computer interaction, search engines, scalability of information access interfaces, and personal data mining.
劳伦斯·佩奇出生于美国密歇根州东兰辛市,1995 年获得密歇根大学安娜堡分校计算机工程学士学位,现为斯坦福大学计算机科学专业博士在读。主要研究方向包括网络链接结构、人机交互、搜索引擎、信息访问接口的可扩展性、个人数据挖掘。
8 Appendix A: Advertising and Mixed Motives
8 附录 A:广告模式与利益冲突
Currently, the predominant business model for commercial search engines is advertising. The goals of the advertising business model do not always correspond to providing quality search to users. For example, in our prototype search engine one of the top results for cellular phone is "The Effect of Cellular Phone Use Upon Driver Attention", a study which explains in great detail the distractions and risk associated with conversing on a cell phone while driving. This search result came up first because of its high importance as judged by the PageRank algorithm, an approximation of citation importance on the web Page, 98. It is clear that a search engine which was taking money for showing cellular phone ads would have difficulty justifying the page that our system returned to its paying advertisers. For this type of reason and historical experience with other media Bagdikian 83, we expect that advertising funded search engines will be inherently biased towards the advertisers and away from the needs of the consumers.
当时商用搜索引擎的主流商业模式为广告变现,该模式的运营目标与为用户提供优质检索服务的初衷时常相悖。举例而言,在我们的原型系统中,检索 "cellular phone" 时首条结果是一篇研究论文《手机使用对驾驶员注意力的影响》,该文章详细分析了驾车通话带来的注意力分散与安全隐患。该页面凭借网页排名算法判定的高权重成为首位结果。显然,依靠手机广告盈利的搜索引擎,不会向广告合作方推送这类内容。结合其他媒体行业的发展经验来看,依靠广告营收的搜索引擎,天生会偏向广告商利益,而忽视普通用户的真实需求。
Since it is very difficult even for experts to evaluate search engines, search engine bias is particularly insidious. A good example was OpenText, which was reported to be selling companies the right to be listed at the top of the search results for particular queries Marchiori 97. This type of bias is much more insidious than advertising, because it is not clear who "deserves" to be there, and who is willing to pay money to be listed. This business model resulted in an uproar, and OpenText has ceased to be a viable search engine. But less blatant bias are likely to be tolerated by the market. For example, a search engine could add a small factor to search results from "friendly" companies, and subtract a factor from results from competitors. This type of bias is very difficult to detect but could still have a significant effect on the market. Furthermore, advertising income often provides an incentive to provide poor quality search results. For example, we noticed a major search engine would not return a large airline's homepage when the airline's name was given as a query. It so happened that the airline had placed an expensive ad, linked to the query that was its name. A better search engine would not have required this ad, and possibly resulted in the loss of the revenue from the airline to the search engine. In general, it could be argued from the consumer point of view that the better the search engine is, the fewer advertisements will be needed for the consumer to find what they want. This of course erodes the advertising supported business model of the existing search engines. However, there will always be money from advertisers who want customers to switch products, or have something that is genuinely new. But we believe the issue of advertising causes enough mixed incentives that it is crucial to have a competitive search engine that is transparent and in the academic realm.
即便是行业专家,也难以客观评测搜索引擎的优劣,这就让平台偏向性问题变得更加隐蔽。典型案例是 OpenText 搜索引擎,该平台被曝光向企业售卖关键词置顶排名。这类人为干预排名的行为比普通广告模式危害更大,因为外界无法区分排名靠前的结果是凭借内容质量还是付费推广。该商业模式引发大量争议,最终 OpenText 彻底退出搜索引擎市场。而一些更为隐蔽的偏向性行为,却容易被市场默许:例如对合作企业的页面小幅加权,对竞品页面刻意降权。这类行为难以被察觉,却会深刻影响行业格局。此外,广告营收会反向驱使搜索引擎降低结果质量。我们曾发现某主流搜索引擎,在检索大型航空公司名称时,不展示其官方首页,原因是该航空公司投放了高价关键词广告。如果搜索引擎检索能力足够优秀,用户可直接找到官网,平台便会失去这笔广告收入。站在用户角度不难发现:搜索引擎检索效果越好,用户越不需要借助广告寻找内容,这会动摇现有搜索引擎的广告盈利模式。当然,推广新品、引导用户更换产品的广告需求会一直存在。但广告带来的利益冲突问题不容忽视,因此业界亟需一款具备竞争力、运作透明、依托学术理念打造的搜索引擎。
9 Appendix B: Scalability
9 附录 B:系统可扩展性
9. 1 Scalability of Google
9.1 谷歌自身的可扩展性
We have designed Google to be scalable in the near term to a goal of 100 million web pages. We have just received disk and machines to handle roughly that amount. All of the time consuming parts of the system are parallelize and roughly linear time. These include things like the crawlers, indexers, and sorters. We also think that most of the data structures will deal gracefully with the expansion. However, at 100 million web pages we will be very close up against all sorts of operating system limits in the common operating systems (currently we run on both Solaris and Linux). These include things like addressable memory, number of open file descriptors, network sockets and bandwidth, and many others. We believe expanding to a lot more than 100 million pages would greatly increase the complexity of our system.
谷歌的短期扩容目标是支持 1 亿网页索引,我们已配齐可承载该规模数据的磁盘与服务器设备。系统中所有耗时较长的模块(抓取器、索引器、排序器)均已实现并行化,时间复杂度近似线性。核心数据结构也能够平稳适配规模扩容。但当索引规模达到 1 亿网页时,系统会逼近主流操作系统(当前使用 Solaris 与 Linux)的各类资源上限,包括寻址内存、文件描述符数量、网络套接字与带宽等。如果继续将索引规模大幅突破 1 亿网页,系统整体复杂度会急剧上升。
9.2 Scalability of Centralized Indexing Architectures
9.2 集中式索引架构的可扩展性
As the capabilities of computers increase, it becomes possible to index a very large amount of text for a reasonable cost. Of course, other more bandwidth intensive media such as video is likely to become more pervasive. But, because the cost of production of text is low compared to media like video, text is likely to remain very pervasive. Also, it is likely that soon we will have speech recognition that does a reasonable job converting speech into text, expanding the amount of text available. All of this provides amazing possibilities for centralized indexing. Here is an illustrative example. We assume we want to index everything everyone in the US has written for a year. We assume that there are 250 million people in the US and they write an average of 10k per day. That works out to be about 850 terabytes. Also assume that indexing a terabyte can be done now for a reasonable cost. We also assume that the indexing methods used over the text are linear, or nearly linear in their complexity. Given all these assumptions we can compute how long it would take before we could index our 850 terabytes for a price that a small company could afford. Moore's Law was defined in 1965 as a doubling every 18 months in processor power. It has held remarkably true, not just for processor power, but for other system parameters such as disk as well. If we assume that Moore's law holds for the future, we need only 10 more doublings, or 15 years to reach our goal of indexing everything everyone in the US has written for a year for a price that a small company could afford. Of course, hardware experts are somewhat concerned Moore's Law may not continue to hold for the next 15 years, but there are certainly a lot of interesting centralized applications even if we only get part of the way to our hypothetical example.
随着计算机性能提升,以合理成本对海量文本建立索引已成为现实。视频等高带宽多媒体内容会愈发普及,但文本内容的创作成本远低于视频,因此仍会长期占据主流。同时,语音转文字技术会进一步扩充文本数据体量,这为集中式索引架构带来广阔的应用空间。举一个示例:假设要对美国全体民众一年内创作的所有文本建立索引,按照美国 2.5 亿人口、人均每日创作 10KB 文本计算,数据总量约为 850 TB。假设当前每 TB 数据的索引成本处于合理区间,且文本索引算法的时间复杂度为线性或近似线性,结合硬件发展趋势,即可推算出中小型企业能够承担该项目成本的时间。摩尔定律提出于 1965 年,定义为处理器性能每 18 个月提升一倍,该规律不仅适用于处理器,磁盘等硬件设备也基本符合这一趋势。若摩尔定律持续生效,硬件性能再提升 10 倍(历时 15 年)后,中小型企业即可负担这套 850 TB 文本的索引工程。硬件领域专家认为,未来 15 年摩尔定律可能不再完全适用,但即便无法达成上述理想化场景,集中式架构依然能支撑大量极具价值的应用场景。
Of course a distributed systems like Gloss Gravano 94 or Harvest will often be the most efficient and elegant technical solution for indexing, but it seems difficult to convince the world to use these systems because of the high administration costs of setting up large numbers of installations. Of course, it is quite likely that reducing the administration cost drastically is possible. If that happens, and everyone starts running a distributed indexing system, searching would certainly improve drastically.
诸如 GlOSS、Harvest 这类分布式系统,在索引场景中往往具备更高的效率与更简洁的架构,但大规模部署分布式节点的运维成本居高不下,导致这类系统难以普及。如果未来分布式架构的运维成本能够大幅降低,全网普及分布式索引系统后,检索服务的整体能力将会迎来质的飞跃。
Because humans can only type or speak a finite amount, and as computers continue improving, text indexing will scale even better than it does now. Of course there could be an infinite amount of machine generated content, but just indexing huge amounts of human generated content seems tremendously useful. So we are optimistic that our centralized web search engine architecture will improve in its ability to cover pertinent text information over time and that there is a bright future for search.
人类的文字、语音产出量存在上限,而计算机性能持续提升,文本索引技术的扩容能力会不断增强。机器自动生成的内容或许会无限增长,但仅针对人类创作的海量文本建立索引,就具备极高的实用价值。因此我们相信,本文提出的集中式网络搜索引擎架构,未来能够不断优化文本信息检索能力,搜索引擎领域也将拥有广阔的发展前景。

导图图源:- The Anatomy of a Large-Scale Hypertextual Web Search Engine 大型超文本Web搜索引擎的剖析-CSDN博客
https://blog.csdn.net/qq_36926570/article/details/105056350
reference
- The Anatomy of a Search Engine - google.pdf
http://infolab.stanford.edu/pub/papers/google.pdf