
🎯 博主简介
CSDN 「新星创作者」 ,人工智能技术领域博主,码龄 5 年 ,累计发布
190+ 篇原创文章,博客总访问量30万+浏览。
🚀 持续更新 AI 前沿实战知识,专注于 AI 技术实战、RAG 系统、Agent 应用开发与大模型工程化落地。目前主要更新方向包括:
- 🦞 最新 OpenClaw 教程 ---从入门到精通|AI 智能助手/自动化/Skills 实战(原 Clawdbot/Moltbot)
- 🔌 MCP 协议专题 --- 从协议规范到工具接入,深入理解 Agent 工具生态
- ✨ Agent 记忆系统 --- 长期记忆、上下文管理与个性化智能体设计
- 📘 图解机器学习合集 --- 用图解方式系统梳理机器学习核心概念,持续更新中
同时也会持续分享 AI 编程、Java 后端、Spring 生态、Transformer、大模型基础、计算机视觉 等方向内容,内容会尽量结合自己的学习记录、项目实践和踩坑经验来整理。
📱GZH:安逸Ai(科技前沿新闻,Github热门项,最新免费资料...)- 网页观看完整系列合集:🌐 Anyi AI 学习资源站
机器学习到底是什么?
你有没有这种感觉------刷抖音的时候,它好像比你自己还懂你?点开一条短视频,下一条居然刚好也是你想看的。
这背后藏着一门让计算机学会"思考"的技术。今天就来聊聊它。
你可能每天都在和机器学习打交道
说个有意思的事。
早上出门,打开地图导航。它告诉你"前方拥堵,建议绕行"------这不是人工客服告诉你的,是算法实时分析路况数据后算出来的。
打开邮箱,垃圾邮件被自动归到垃圾箱。跟Siri说"帮我定个闹钟",它听懂了。这些都是机器学习在起作用。
抖音的推荐、淘宝的"猜你喜欢"、美团的外卖排序------说白了,你以为的"懂你",其实是"数据在懂你"。机器学习早就从实验室走出来,塞进了你手机里的每一个App。
机器学习到底是什么?
1959年,有个叫Arthur Samuel的人给了一个定义:让计算机具有无需明确编程即可学习的能力。
听起来有点绕,我举个例子你就懂了。
想让计算机识别猫,传统做法是写规则:"有胡须"、"会喵喵叫"、"体型较小"------然后让它按这些规则判断。问题是,猫的品种太多了,姿态也太多了,你永远写不全。
机器学习的思路完全不同。它不需要你写规则,你只需要给它看足够多的猫。看多了,它自己就懂了。
这就像教小孩认字。你不会说"马这个字,笔画是横折钩加什么什么"。你会指着图画说"这是马,那是牛",多看几次,小孩自己就分清了。
你给它数据,它自己找出规律。这个规律就是"模型"------模型不是程序,是一堆数学公式,但这堆公式能预测、会判断、甚至能做决定。
所以,机器学习的本质就是:从数据中学习,然后做预测。
不过有个前提------现实问题必须能转换成数学问题。天气预测可以,因为温度、湿度、气压都能用数字表示。但"这幅画美不美"?审美很难量化,这个问题机器学习暂时搞不定。
AI、机器学习、深度学习,到底啥关系?
聊机器学习,必须把这三个概念捋清楚。很多人把它们混着用,其实它们不是一回事。
来看一张图:
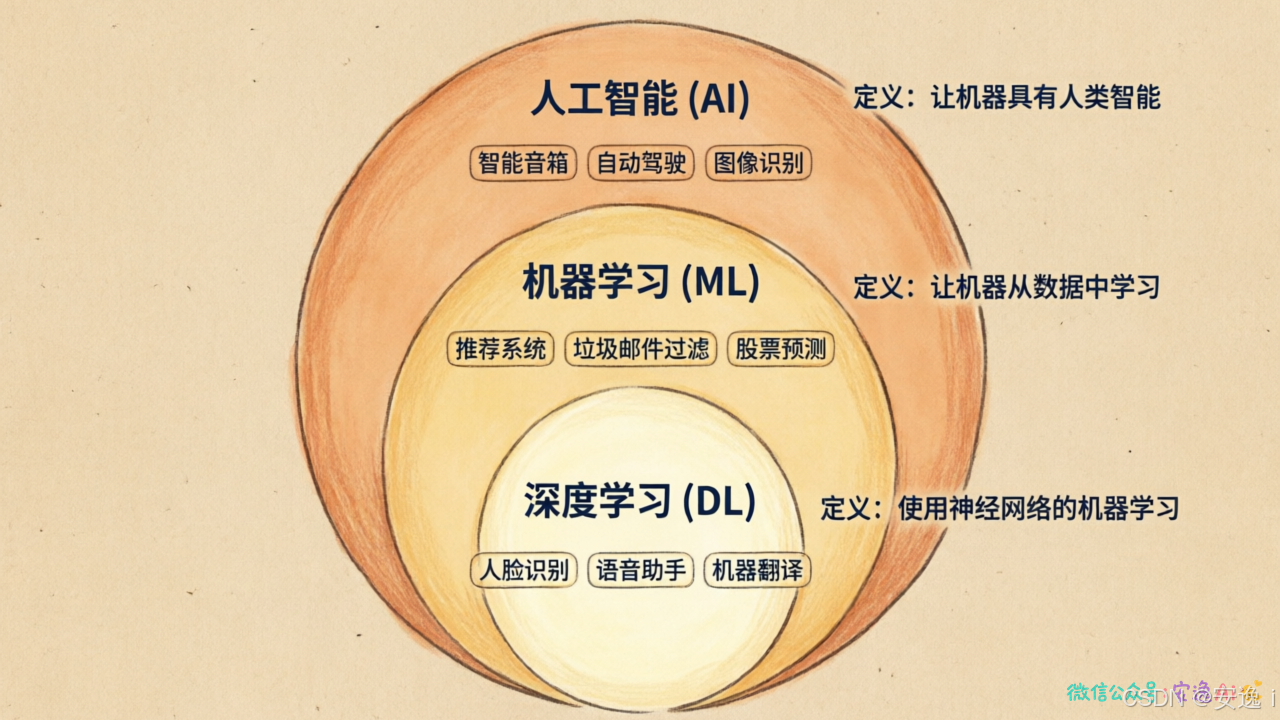
是包含关系。人工智能是个大类,目标是用计算机实现"智能行为"------推理、规划、学习、感知,全在内。机器学习是实现人工智能的一种方法。深度学习又是机器学习的一个分支,灵感来自大脑神经元的结构。
人脑有亿万个神经元,彼此连接,形成网络。深度学习模拟这个结构,用"人工神经网络"来处理数据。所以三者的关系就像俄罗斯套娃:最外层是人工智能,中间是机器学习,最里层是深度学习。
深度学习不是万能的,但在图像识别、语音处理、自然语言这些领域特别强。Siri能听懂你说的话,ChatGPT能写文章,靠的都是深度学习。没有机器学习打基础,深度学习就是空中楼阁。
三种学习方式,机器的三条成长路径
机器学习不是一种方法,是三种。它们学习的"姿势"完全不同。
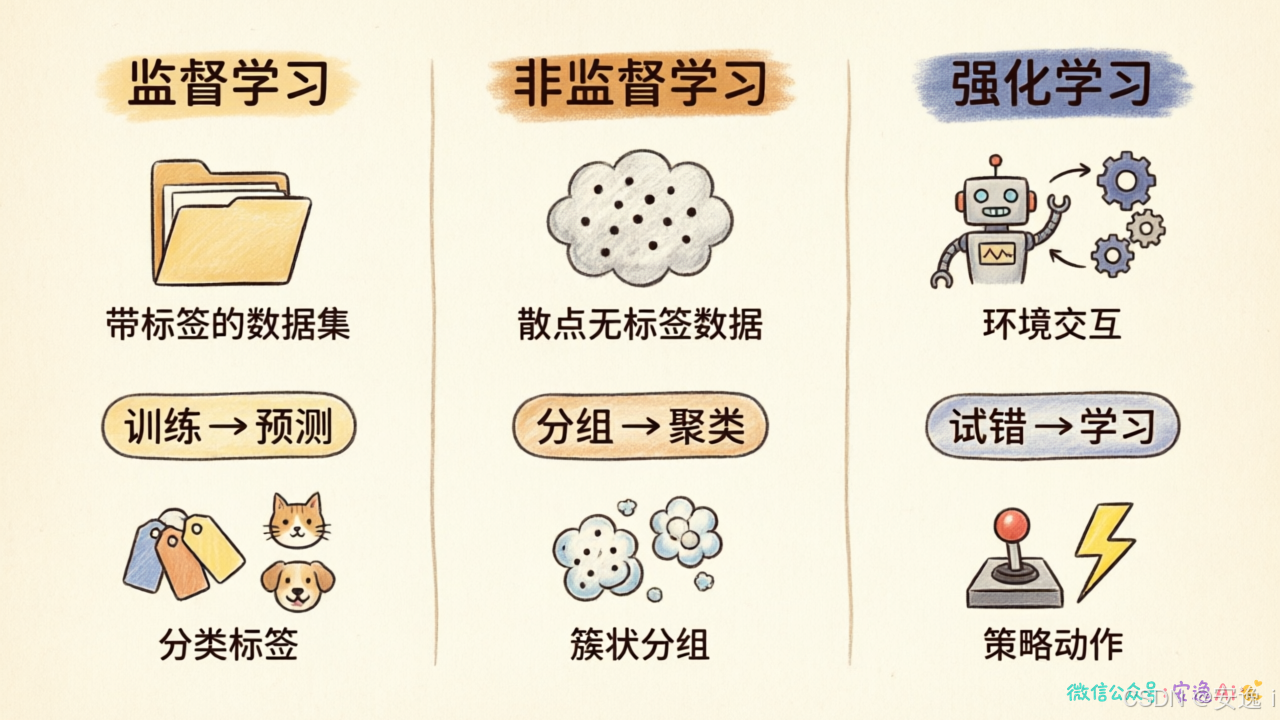
监督学习:有老师批改的考试
给你题目,同时给你答案。"这张图是猫,那张图是狗。"学完之后,再拿新图给它看,它就能自己判断。
这是监督学习。需要大量标注数据------图片要人工标记"这是猫"、"那是狗"。数据越准,效果越好。缺点是标注成本高。
非监督学习:自己发现规律
不给答案,只给数据。它可能会发现:哦,这堆数据聚在一起,那堆数据聚在另一边。但它不知道左边这堆叫什么。
代表应用是用户分群。把用户分成"高活跃"、"低活跃"、"潜在流失"------分类是它自己发现的。
强化学习:玩游戏的逻辑
没有固定答案,只有"奖励"和"惩罚"。做对了给正向反馈,做错了给负向反馈。通过不断试错,机器学会最优策略。
AlphaGo Zero就是这么学下棋的。没人教它棋谱,它自己跟自己对弈几百万局,然后成了世界冠军。这个逻辑最接近人类的学习方式------从经验中成长。
打个比方的话:
监督学习 = 有老师批改的考试
非监督学习 = 没人告诉你对错,自己琢磨规律
强化学习 = 玩电子游戏,死了重来、赢了记住
哪种更强?没有标准答案。不同场景用不同方法,就像你不会用螺丝刀钉钉子。

机器学习的实战七步法
理论聊完了,来点实用的。机器学习从数据到预测,要走几步?说出来你可能不信,七步。
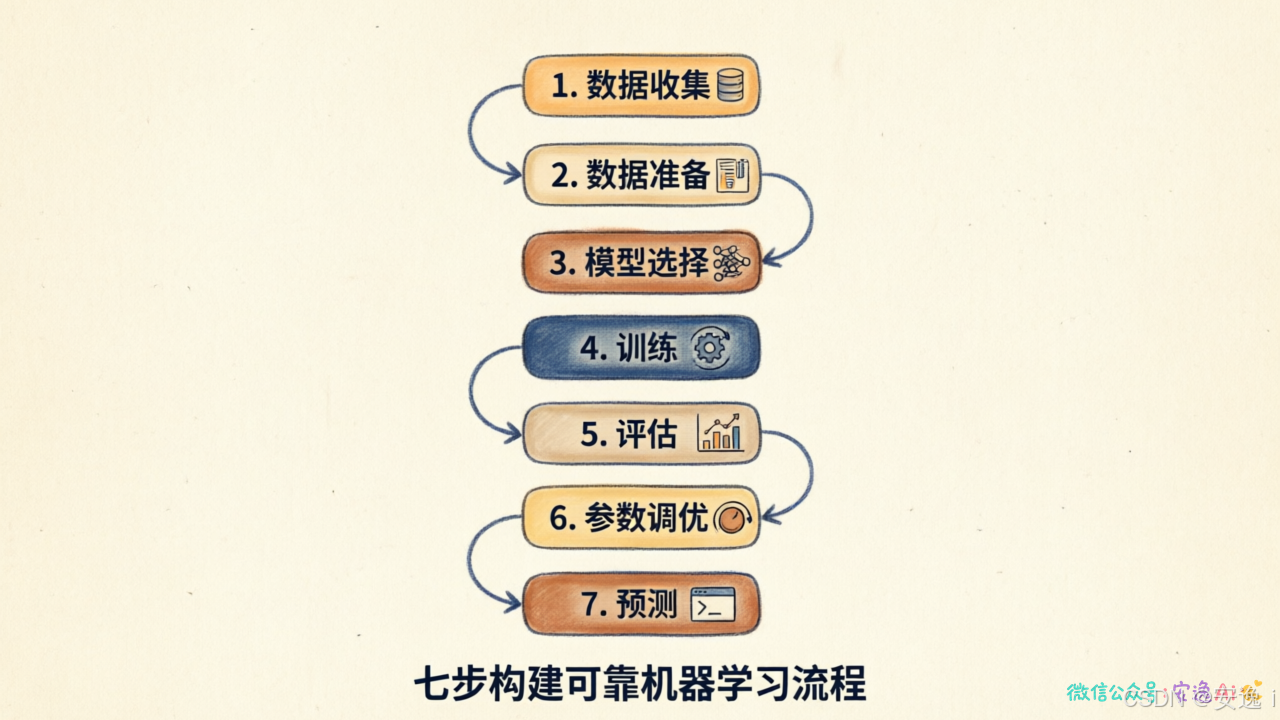
第一步:数据收集
没有数据,一切免谈。Garbage in, garbage out------喂进去的是垃圾,出来的也是垃圾。
第二步:数据准备
原始数据不能直接用。要清洗、要处理缺失值、要去掉异常值。还会把数据分成三份:训练集、验证集、测试集,常见比例是6:2:2。训练集用来"学",验证集用来"调",测试集用来"考"。
第三步:模型选择
选什么算法?分类问题用分类模型,预测数值用回归模型,找规律用聚类模型。没有最好的模型,只有最适合的模型。
第四步:训练
把数据喂给模型,让它学习参数。这个过程可能会跑很久------几小时、几天,甚至几周。我第一次跑模型的时候,等得都想睡觉了。
第五步:评估
学完了,得看看学得怎么样。准确率、召回率、F1值------一堆指标等着你。
不过要注意,准确率80%听起来不错,但如果垃圾邮件只占5%,那全判断成"不是垃圾"也有95%准确率。所以指标要结合业务看。
第六步:参数调优
模型有"超参数",需要手动设置。调参就像调咖啡------水温高了苦,低了酸,得反复试。
第七步:预测
上线。用测试集做最后验证,没问题就部署。之后持续监控,效果下降就重新训练。
做个类比。做菜懂吧?
数据收集 = 去菜市场买菜
数据准备 = 洗菜、切菜
模型选择 = 选菜谱
训练 = 炒菜
评估 = 尝味道
参数调优 = 调整火候、调料
预测 = 端上桌
每一道工序都重要。但我踩过坑才发现:数据质量比训练本身更重要。好的食材,半小时能做出美味。烂的食材,大厨也救不了。
理解数据,才能理解机器学习
聊到这里,你应该对机器学习有了一个整体印象。它不是魔法,是数学。它不是要取代人,是帮人处理海量数据。它不是万能药,有些问题适合,有些问题不适合。
而理解它的第一步,就是搞清楚它到底在学什么。
机器学习的核心是数据------但数据本身不会说话。数据里的"特征"才是关键。颜色、形状、大小、频率------这些具体的信息,才是机器真正消化吸收的东西。
那特征到底是什么?机器是怎么从一堆数字里找出规律的?这就是下一篇要聊的内容了。