NVIDIA CPU 特性演进解析
Vera CPU 特性设计满足业务需求对照表
|---------------------|------------------------------------------------------------------------------------------------|-----------------------------------------------------------------|---------------------------------------------------|
| CPU 特性设计 | 技术规格 | 满足的业务需求 | 解决的核心痛点 |
| Olympus 自定义核心 | * 88 个定制核心,176 线程,每核心 2MB L2 缓存,162MB L3 缓存 * 具备更出色的分支预测、预取以及负载存储性能,并针对控制密集型和数据移动密集型工作负载进行了优化。 | * AI 工厂大规模编排调度 * 控制密集型工作负载 * 多租户环境隔离 | ・传统 CPU 核心数不足、线程密度低 ・多租户性能干扰与隔离性差 ・分支预测与数据移动效率低 |
| 空间多线程技术 | 物理分区资源分配而非时间切片 | * 性能与效率之间的平衡 * 提升吞吐量和虚拟 CPU 密度 * 保障可预测的性能和强隔离性满足多租户 AI 工厂的关键需求。 | ・传统超线程的性能波动 ・时间切片带来的延迟不确定性 ・虚拟 CPU 资源竞争 |
| 第二代 SCF 可扩展一致性结构 | 单芯片 88 核心互联,>90% 峰值带宽保持率 | ・确定性低延迟数据传输 ・核心数量线性扩展 ・持续 GPU 数据供给 | ・小芯片边界延迟不一致 ・核心与内存控制器瓶颈 ・高负载下带宽衰减严重 |
| 高带宽内存子系统 | 1.5TB LPDDR5X SOCAMM,1.2TB/s 带宽 | ・数据密集型工作负载 ・KV-cache 卸载 ・高可用性运维 | ・传统 CPU 内存容量不足 (仅 480GB) ・内存带宽瓶颈 ・维护性差、故障隔离难 |
| NVLink-C2C 第二代 | 1.8TB/s 一致性带宽,CPU-GPU 统一地址空间 | ・CPU-GPU 显存一致性访问 ・多模型高效执行 ・整机架级协同 | ・PCIe 带宽瓶颈 (仅 900GB/s) ・CPU-GPU 数据移动开销大 ・内存地址空间割裂 |
| PCIe Gen6 + CXL 3.1 | 新一代高速互联标准 | ・高速外设连接 ・内存池化扩展 ・异构计算互联 | ・Gen5 带宽限制 ・缺乏 CXL 内存扩展支持 |
| 机密计算原生支持 | Arm v9.2 架构,跨 CPU-GPU 安全执行 | ・多租户 AI 工厂安全 ・模型与数据隐私保护 ・合规性要求 | ・无硬件级安全隔离 ・机密计算性能损失大・CPU-GPU 边界安全漏洞 |
| Arm 软件生态全兼容 | Arm v9.2 架构,主流 Linux/AI 框架原生支持 | ・现有基础设施平滑迁移 ・软件零修改适配・生态工具链复用 | ・定制架构软件生态断裂 ・迁移成本高、编译适配工作量大 |
Vera CPU:专为 AI 工厂打造
随着 AI 工厂规模的扩大,仅凭 GPU 性能已不足以维持吞吐量。数千个 GPU 的高利用率,依赖于数据、内存与控制流在系统中的高效流转。Vera CPU 专为这一角色设计,作为高带宽、低延迟的数据移动引擎,保障 AI 工厂在大规模运行下的高效性。
与传统的通用主机不同,Vera 针对整机架的编排、数据移动和一致性内存访问进行了优化。Vera 可与作为主机 CPU 的 Rubin GPU 搭配使用,也可作为独立平台用于代理式处理,能够消除训练和推理环境中的 CPU 端瓶颈,从而提升持续利用率。

图 1搭载 NVIDIA 定制核心的 Vera CPU
从 NVIDIA Grace 到 Vera -- 拓展 AI 工厂的 CPU
NVIDIA Grace 奠定了 NVIDIA 在高带宽、高能效 CPU 设计方面的基础。Vera 在此基础上进一步提升,通过增加核心密度、显著增强显存带宽、扩展一致性支持以及实现全面的机密计算能力,全面优化以满足 AI 工厂工作负载的需求。
如下表所示,Vera 可提供高达 2.4 倍的显存带宽和高达 3 倍的显存容量,以支持数据密集型工作负载,同时将 NVLink-C2C 带宽提升一倍,确保在机架规模下实现 CPU 与 GPU 的协同操作。这些改进相结合,使 CPU 从辅助角色转变为 AI 工厂中新一代 GPU 高效运行的关键推动力。
|------------|---------------------|----------------------------|
| 特征 | Grace CPU | Vera CPU |
| 核心 | 72 个 Neoverse V2 核心 | 88 个 NVIDIA 自定义 Olympus 核心 |
| 线程 | 72 | 176 每核心空间多线程 |
| 二级缓存 | 1MB | 2MB |
| 统一的三级缓存 | 114MB | 162MB |
| 显存带宽 (BW) | 高达 512GB/s | 高达 1.2 TB/s |
| 显存容量 | 480GB LPDDR5X | 1.5 TB LPDDR5X |
| SIMD | 4x 128b SVE2 | 6x 128b SVE2 FP8 |
| NVLINK-C2C | 900GB/s | 1.8 TB/s |
| PCIe/CXL | Gen5 | Gen6/CXL 3.1 |
| 机密计算支持 | NA | 支持 |
表 1 Grace 与 Vera CPU 对比
采用空间多线程技术的 NVIDIA OLYMPUS 核心
Vera CPU 的核心由 88 个 NVIDIA 定制的 OLYMPUS 核心组成,专为实现卓越的单线程性能和高能效而设计,且完全兼容 Arm 架构。这些核心采用广泛而深入的微架构设计,具备更出色的分支预测、预取以及负载存储性能,并针对控制密集型和数据移动密集型工作负载进行了优化。
Vera 引入了空间多线程,这是一种新型多线程技术,通过物理分区而非时间切片来分配资源,每个核心运行两个硬件线程,从而在运行时实现性能与效率之间的平衡。该方法可提升吞吐量和虚拟 CPU 密度,同时保障可预测的性能和强隔离性,满足多租户 AI 工厂的关键需求。
可扩展一致性架构 -- 确定性数据传输
第二代 NVIDIA 可扩展一致性结构 (SCF) 能将所有 88 个 OLYMPUS 核心连接至单个计算芯片上的共享三级缓存和内存子系统。通过避免小芯片边界,SCF 提供一致的延迟表现,并在负载下维持超过 90% 的峰值内存带宽,有效消除核心与内存控制器之间的瓶颈。
通过在 CPU 中实现确定性且高吞吐量的数据移动,SCF 能够确保编排和数据处理工作负载随核心数量的增加而线性扩展。这对于持续向 GPU 供给 AI 工厂规模的数据和指令至关重要。
内存带宽和一致性执行
Vera 将 SCF 与高达 1.5 TB 的 LPDDR5X 内存子系统相结合,在低功耗下提供高达 1.2 TB/s 的带宽。采用 LPDDR5X 的小型压缩附加内存模块(SOCAMM)可提升可维护性与故障隔离能力,从而满足 AI 工厂对高正常运行时间的需求。
第二代 NVLink-C2C 可在 Vera CPU 和 Rubin GPU 之间提供 1.8 TB/s 的一致性带宽,实现 CPU 与 GPU 显存间的统一地址空间。应用程序可将 LPDDR5X 与 HBM4 视为单一一致性内存池,从而降低数据移动开销,并支持 KV-cache 卸载与高效多模型执行等技术。
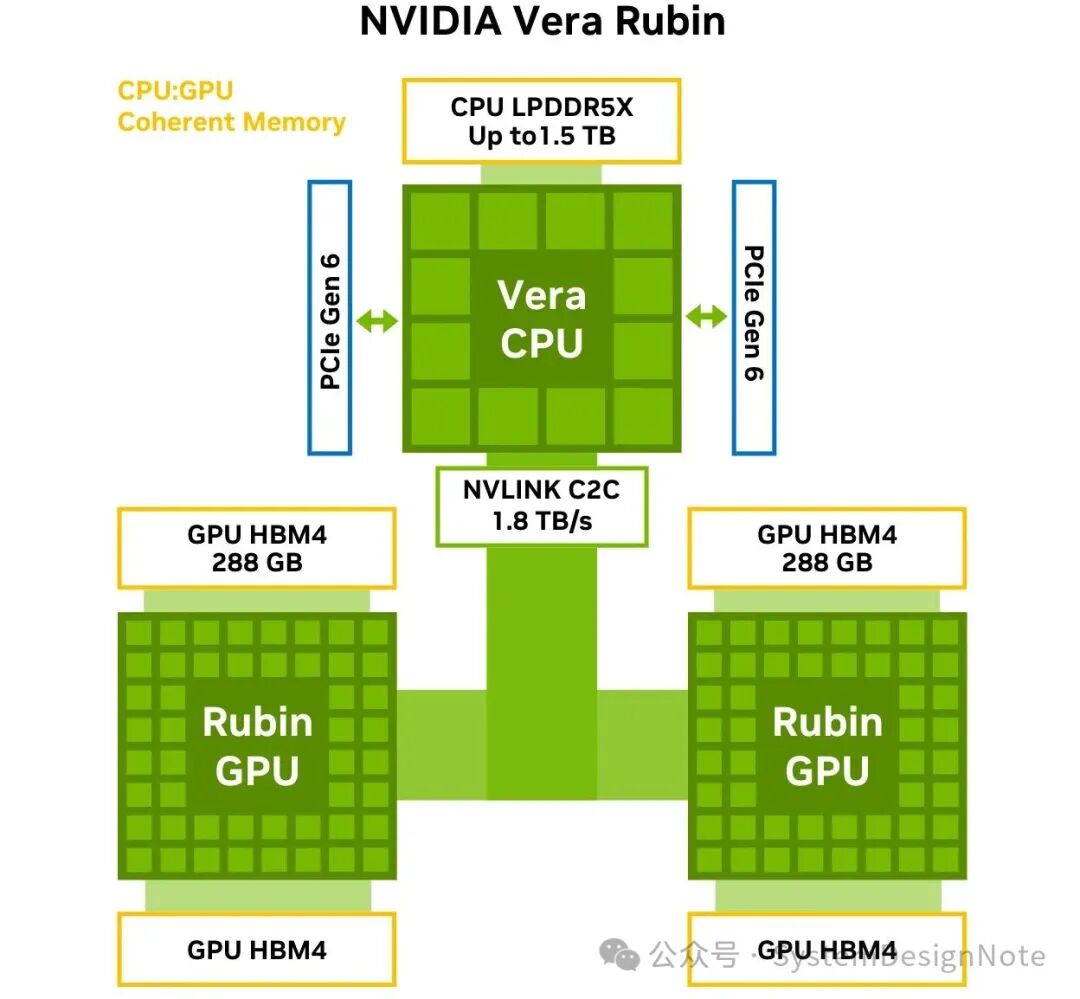
图 2 NVLink-C2C 一致性显存架构
软件兼容性和安全操作
Vera 支持 Arm v9.2 架构,并与 Arm 软件生态系统实现无缝集成。主流的 Linux 发行版、AI 框架和编译排平台可不经修改直接运行,因此现有基础设施软件能够平滑扩展至基于 Vera 的系统。
本机支持机密计算,可在跨 CPU -- GPU 边界及多路配置下实现安全执行,同时保障性能。
AI 工厂的数据引擎
Vera 是一款专用 CPU,旨在通过高效移动、处理和协调 AI 工厂规模的数据来充分释放 GPU 的潜力。Vera 并非被动主机,而是一个数据引擎,可加速控制密集型通信路径,涵盖数据暂存、调度、编排以及代理式工作流。同时,它在分析、云、存储和基础设施服务方面也展现出卓越的独立性能。
通过结合 Olympus CPU 核心、第二代 SCF、高带宽 LPDDR5X 显存以及一致性 NVLink-C2C 连接,Vera 能够确保 Rubin GPU 在训练、后训练和推理等各类工作负载中保持高效,即使在计算、显存和通信主导的阶段之间切换亦能稳定运行。