与其反复解释"应该怎么做",不如给模型看几份合格样例。 Few-shot Prompting 的本质,是利用上下文中的 demonstrations 暂时建立一套任务规则。
Few-shot Prompting 是指在 Prompt 中放入少量输入---输出示例, 让 Large Language Model 在不更新参数的情况下,根据这些示例推断任务规则, 再处理后面的新输入。
1. Few-shot Prompting 是什么
Large Language Model 往往具备不错的 Zero-shot 能力:只给任务说明,也能完成分类、抽取、改写或生成。 但当任务包含自定义标签、特殊格式、隐含边界或领域表达时,单靠一句说明通常不够稳定。
Few-shot Prompting 的解决方式很直接:先给模型看几份 demonstrations。 每一份 demonstration 都像一张临时的"参考答案",告诉模型什么输入对应什么输出。 模型随后会在当前上下文中延续这种模式,这种现象通常被称为 In-Context Learning。

**关键区别:**Few-shot Prompting 不是 Fine-tuning。 它不会修改模型权重,示例只在本次请求或当前 conversation context 中生效。
2. 模型究竟从示例里学到了什么
初学者常把 Few-shot 理解成"让模型模仿答案"。这只说对了一部分。 一组 demonstrations 通常会同时向模型传递四类信息。

这也解释了为什么有时一条简单 instruction 写了很多遍,效果仍然不如两三个清晰示例。 自然语言说明经常存在歧义,而示例把抽象规则落到了具体输入和具体输出上。
3. Zero-shot、One-shot 与 Few-shot
| 方式 | 示例数量 | 适用情况 | 主要代价 |
|---|---|---|---|
| Zero-shot | 0 | 任务常见、要求简单、标签含义明确 | 边界和格式可能不稳定 |
| One-shot | 1 | 需要展示一次输出形式或表达风格 | 单个示例可能造成偏置 |
| Few-shot | 通常为 2--10 个 | 自定义分类、结构化抽取、固定文风、领域任务 | 占用 context window,并增加维护成本 |
"多少个示例才算合适"没有固定答案。3-shot、5-shot、10-shot 只是常见叫法, 并不意味着示例越多越好。一个覆盖边界情况的 3-shot Prompt, 往往比十个内容高度重复的示例更有效。
4. 从一个完整示例开始
假设我们要做客服消息分类,标签不是常见的 Positive 或 Negative, 而是业务内部定义的 REFUND、LOGISTICS、 ACCOUNT 和 OTHER。只给标签名称时, 模型可能不知道"快递显示签收但我没收到"究竟属于物流还是退款。
任务:将用户消息分类为 REFUND、LOGISTICS、ACCOUNT 或 OTHER。
只输出标签,不要解释。
示例 1
用户:订单取消三天了,钱还没退回来。
标签:REFUND
示例 2
用户:物流显示已签收,但我没有收到包裹。
标签:LOGISTICS
示例 3
用户:换了手机号后无法登录原来的账号。
标签:ACCOUNT
待处理消息
用户:退款已经审核通过,银行卡里为什么还没有到账?
标签:这里的 demonstrations 不只是展示了三个标签,还悄悄确定了两条规则: "退款进度"归入 REFUND,最终输出只保留一个大写标签。 因而模型更容易输出 REFUND,而不是写一段客服式解释。
**注意:**示例中的答案本身必须可靠。 一旦 demonstrations 混入错误标签,模型可能把错误边界当成任务规范。
5. 如何选择高质量 demonstrations
Few-shot 的效果很大程度上取决于"选了什么例子",而不只是"放了几个例子"。 下面几条比盲目增加 shot 数更重要。
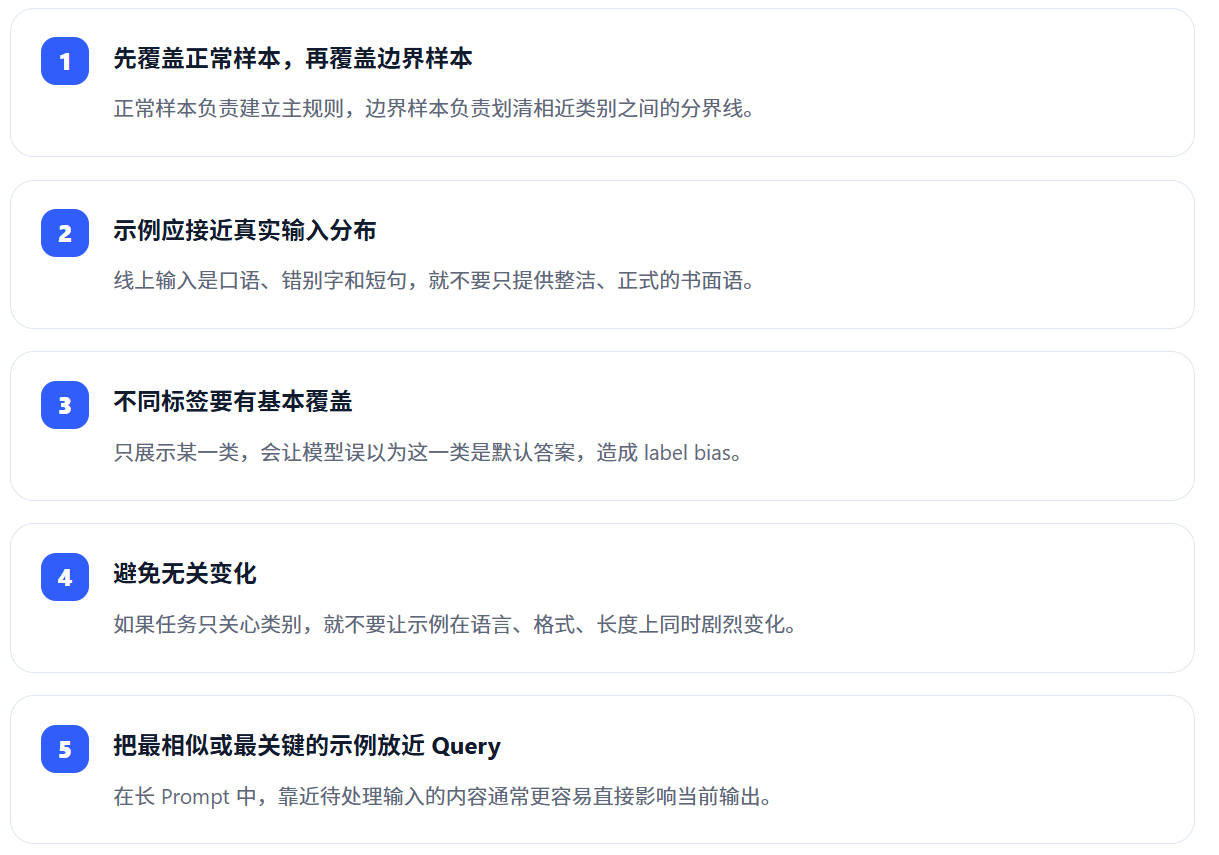
静态示例与动态示例
最简单的实现,是把一组固定 examples 写死在 Prompt 中。这适合任务稳定、类别较少的场景。 当数据复杂时,可以先从案例库中检索与当前 Query 最相似的若干样本, 再动态拼接 Prompt。这种方法常被称为 Dynamic Few-shot Prompting 或 example retrieval。

6. Few-shot Prompting 的局限
Few-shot 对分类、抽取、格式模仿和风格迁移很实用,但它不是通用解法。 原页面给出的算术判断例子说明:即使添加了若干输入---答案示例, 模型仍可能在需要多步计算时给出错误结论。
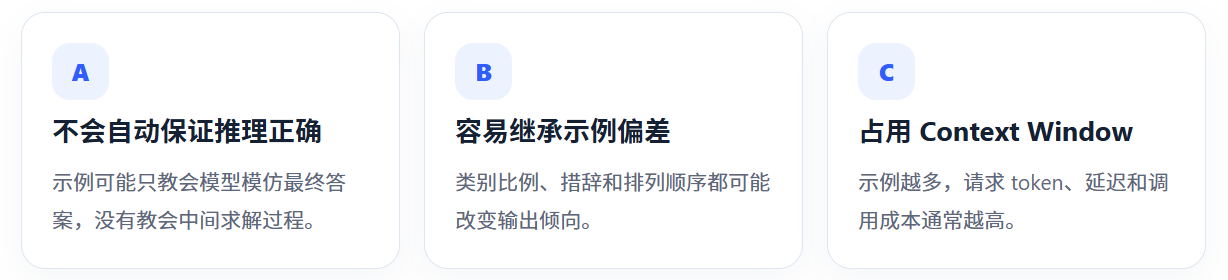
不要把 Few-shot 当作知识库。 它适合演示规则,不适合塞入大量事实材料。 需要外部知识时,更合理的方案通常是 RAG;需要长期稳定改变模型行为时,再考虑 Fine-tuning。
| 遇到的问题 | 优先考虑的方法 |
|---|---|
| 复杂算术、符号推理或多步决策不稳定 | 任务分解、工具调用、Program-Aided 方法或可验证的推理流程 |
| 缺少外部或最新知识 | RAG、搜索、数据库查询 |
| 示例太多,Prompt 成本持续上升 | Dynamic Few-shot、Prompt 压缩,或评估 Fine-tuning |
| 输出结构必须 100% 合法 | Structured Outputs、JSON Schema、parser 与 validation |