Google 又发新模型了。这次不叫 Gemma 5,也不叫 Gemini 后续版本,而是一个名字有点怪的------DiffusionGemma。
当地时间 6 月 10 日发布,Apache 2.0 协议开源,定位是"实验性"。它最大的看点其实不在参数,而在生成方式------不是从左到右一个字一个字往外蹦,而是整页整页地"印"出来。
Google 自己的官方比喻是:把**"单台打字机升级成同时印刷整页文字的大型印刷机"**。用这个比喻讲它做的事情,就顺了。
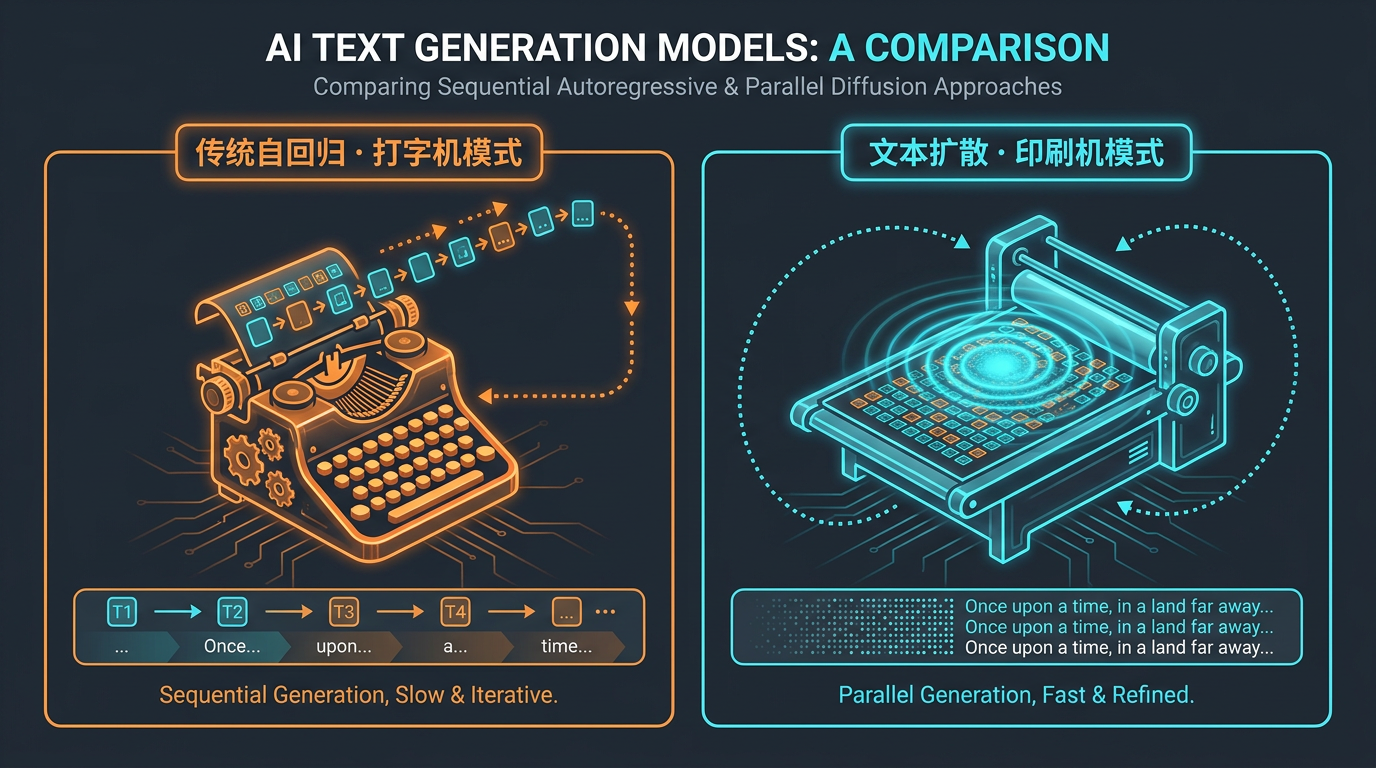 传统自回归 vs 文本扩散的生成逻辑
传统自回归 vs 文本扩散的生成逻辑
它的"印刷"流程到底长什么样
传统大模型(GPT、Gemini、Gemma 4)的工作方式大家都熟:你写一句"从前有",它接着写"一个",再写"公主"。每个新 token 都盯着前面所有 token,顺序往下推。这种"自回归"结构在云端批处理场景很高效,但在你一个人本地跑的时候,GPU 大部分时间都在等内存喂数据,算力大量闲置。
DiffusionGemma 反过来:先在"画布"上铺一长串随机的占位 token(你可以理解成一堆乱码),然后做多轮迭代去噪。
每过一轮,模型会锁定一部分已经"看清楚"的 token,把它们当上下文,去修正剩下的乱码。一轮又一轮,整页文字从模糊变清晰,最后收敛成一段完整回答。
这个机制带来两个直接好处:一是每次前向计算能并行处理 256 个 token ,把 GPU 的算力真正用满;二是每个 token 在生成时都能"看见"段落里其他所有 token------也就是双向注意力,而不是从左到右的单向。
速度数据:4 倍这个数字是怎么来的
Google 公布的实测数据是:在低到中等并发的本地推理场景下,DiffusionGemma 的吞吐是同体量自回归 Gemma 4 模型的约 4 倍。具体到硬件上:
 不同硬件下的实测生成速度
不同硬件下的实测生成速度
单张 NVIDIA H100 上,每秒能生成 1000+ token;消费级旗舰卡 RTX 5090 上,每秒也能到 700+ token;NVIDIA 自家的工作站 DGX Station 更夸张,能冲到每秒 2000+ token;桌面级 DGX Spark 大约是每秒 150 token。
这个提速不是"卷参数卷出来的",是改变了语言模型使用硬件的方式------把瓶颈从"内存带宽"挪到了"并行计算"。这恰好是本地 GPU 最缺、最值得利用的资源。
一个冷知识: Google 也坦言,这个 4 倍优势不是"放之四海皆准"的。在云端那种高并发批量服务 场景里,自回归模型能把几千个用户的请求打包一起算,吞吐反而更高;DiffusionGemma 的并行解码优势主要体现在单卡、低到中等 batch 的本地场景。换句话说,它更像是为"你自己的电脑/工作站"准备的,不是为"云端 API 集群"准备的。
26B 参数只激活 3.8B,本地部署门槛不高
模型结构上,DiffusionGemma 用的是**混合专家(MoE)**架构:总参数 26B,但每次推理实际只激活其中 3.8B------名字里的"A4B"(Activated 4B)就是这个意思。
这套设计的直接收益是显存压力小:经过 4-bit 量化后,模型整体可以塞进18GB 显存的消费级高端 GPU里。考虑到 RTX 4090/5090 的显存就在 24GB 上下,对个人开发者来说,门槛已经从"数据中心级"降到了"书房级"。
Google 也和英伟达做了全栈优化,覆盖 MLX、vLLM、Hugging Face Transformers、Unsloth、NVIDIA NeMo 等主流框架;Hopper、Blackwell 这种企业级 GPU 走 NVFP4 内核路径,消费级走量化路径。属于"不管你用哪一套工具栈,基本都能跑起来"。
双向注意力和"自纠错",让它能干一些奇怪的事
传统自回归模型生成 token 的时候,只能看见"前面已经写过的东西"。DiffusionGemma 因为是整页并行,每个 token 在生成时都能看到段落内所有其他 token。这种"全局视野"在两类任务上特别合适:
**行内编辑类。**比如你写到一半想改某句话,模型可以把改动"传播"到上下文里,前后逻辑自动保持一致。
需要"瞻前顾后"的推理。 最直观的例子是解数独------每一格的填法都得同时考虑行、列、宫内其他格子。第三方 Unsloth 团队就基于 DiffusionGemma 微调出了一个能解数独的版本,这种事对传统自回归模型来说是老大难。
此外,模型还有生成过程中自纠错的能力------它会在去噪的多轮迭代里反复评估整段文字,发现矛盾就改。这跟人类写作时"先打草稿、再通读改稿"的过程是同一个逻辑。
还有一些被官方点名的"非典型"用例:代码内联补全、JSON 这类结构化文本的填空、氨基酸/分子序列的生成、数学图形的逐步构建。共同特征是:需要"同时看到所有位置"的任务。
性能基准:和 Gemini 2.0 Flash-Lite 旗鼓相当
数字层面,DiffusionGemma 在代码类基准上:LiveCodeBench 30.9%、BigCodeBench 45.4%、HumanEval 89.6%;数学类的 AIME 2025 上拿到了 23.3%。综合表现,Google 给的参考对照是和Gemini 2.0 Flash-Lite 大体相当。
也就是说,能力层面它并没有"超过 Gemma 4 主力",更多的是**"用接近的智能水平换 4 倍速度"**。
那它有什么短板
Google 自己也没藏着掖着。DiffusionGemma 目前的输出质量整体仍低于标准 Gemma 4,在需要高精度、长链推理的复杂任务上,基准成绩会下来。
更直观的限制在于"短输出"场景。你只想要 5 个 token 的回复,扩散模型还是要先铺满一整页占位 token 再去噪,做了大量"无效劳动";自回归模型 5 步就能干完的活,扩散可能要多花好几倍力气。所以短回答、短分类、短指令这种场景,它反而吃亏。
还有一点容易被忽略:文本是离散的,图像是连续的。图像里一两个像素错了不致命,文本里一个 token 错了,可能整段意思就崩了。所以文本扩散对错误的容忍度天然更低,扩散范式要"印"出高质量段落,比"印"一张猫的照片要难得多。
这些也解释了 Google 为什么明确说:"追求最高质量输出的生产应用,请继续部署标准 Gemma 4。"
它到底适合谁
Google 给的官方定位是研究者和开发者,目标是"对速度敏感、需要即时反馈的本地交互工作流"。具体一些,可以分这三类:
**本地实时编辑器/AI 助手。**比如在你自己的 IDE 里挂一个内联补全、行内改写工具,每次回复延迟低一些体验差距巨大。
**结构化文本快速生成。**JSON、配置代码、表格等。扩散对"占满一段长度"天然友好,反而比逐字生成更顺。
**研究"双向/并行解码"这件事本身。**毕竟文本扩散在学术界被聊了好几年,但能稳定放出 26B 体量、还跑得动的开源模型,此前并不多见。微调、做实验、写论文的素材这一波都给齐了。
DiffusionGemma 不是一个"取代 Gemma 4"的版本,而是一个把"扩散"这条老路重新搬上大模型舞台的实验。它的看点不在于多强,而在于打开了一个此前没被工业级开源模型认真填过的生态位------"本地、低并发、追求实时反馈"的场景。
当然,4 倍速度这个数字是有适用边界的,质量上 Google 也明确说了"低于标准 Gemma 4"。把这层定位看清楚,才不会高估它,也不会错过它真正有意思的地方。
如果你正打算在本地搞个交互式 AI 工具,又对延迟敏感,那这次值得花点时间看一眼------尤其是在消费级显卡上的实际表现。