小伙伴们,大家好,我是小溪,见字如面。尝试使用Andrej Karpathy LLM Wiki知识库思路构建了几个个人知识库,整体效果看着还不错,记录一下使用方式。
优势
-
可以将自己的知识库变成动态、可自我维护的知识库系统
-
只需关注知识库的录入,无需关注知识库的维护
限制
-
需要自己整理知识源材料
-
当知识库量级大时,检索速度会相对变慢
LLM Wiki简介
LLM Wiki 是由 Andrej Karpathy 提出的新型知识管理工作流,核心思想只有一句话:我们只负责输入资料,由大模型来维护Wiki。从本质上来说就是把个人知识库变成一个 动态的、会自我维护的系统。
这里整理了Andrej Karpathy在X上发布的LLM Wiki知识库idea原文以及在Github发布的LLM Wiki实现思路,为了方法阅读做了中英文翻译对照。
X官网帖子:x.com/karpathy/st...

Github地址: gist.github.com/karpathy/44...

核心理念
传统的知识库检索(如 RAG)通常是"即时检索",提问时模型才去查找文档并生成答案,整个过程都是一次性的,知识无法积累。Karpathy 提出的方案是:
-
LLM 维护一个持续演进的Wiki:LLM 不仅仅是索引文档,而是主动读取新内容,将其提取、总结并整合进现有的 Markdown 文件网络中。
-
知识积累:通过这种方式,知识库会随着你添加的新来源而不断完善、更新、交叉引用,并解决矛盾冲突。使每次提问不再是从零开始,而是基于一个已经整理好的"知识 codebase"进行查询。
核心架构
Karpathy将系统划分为三个层级:
-
Raw sources(原始资源层):收集的原始文件(文章、论文、图片等),这些是不可修改的"知识来源"。
-
The wiki(Wiki层):由LLM编写和维护的Markdown文件目录,包含总结、实体页面、对比分析等,这是系统的核心成果。
-
The schema(Schema层):配置文件(如 CLAUDE.md、AGENTS.md),用于规定 LLM 应该如何结构化地维护这个 Wiki,确保其输出的一致性。
让AI整理了一下Karpathy LLM Wiki的三层架构,大致内容如下:
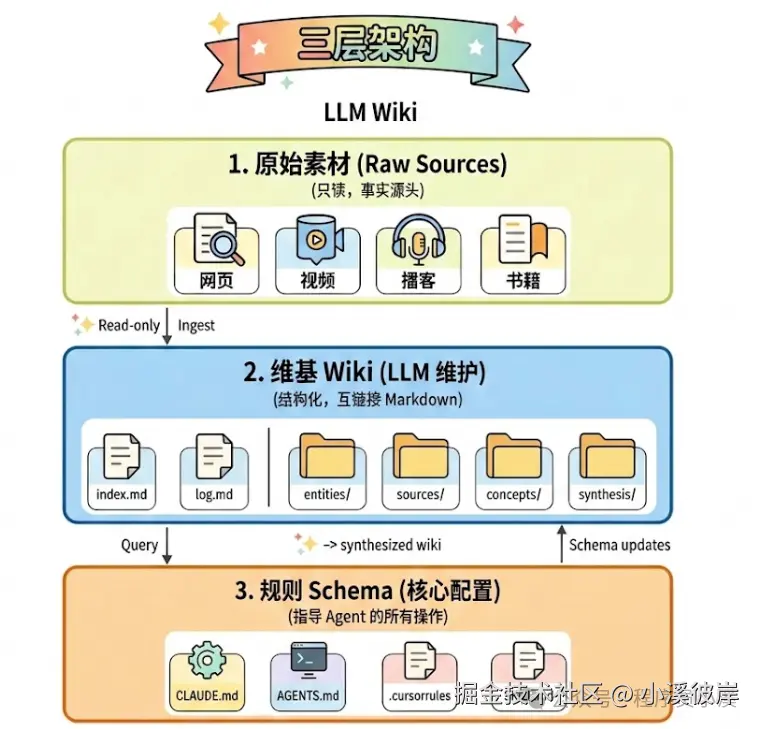
知识库配置
知识库目录结构
为了快速得到一个知识库目录结构模版,我们可以把Karpathy Github发布的LLM Wiki实现思路丢给AI,让AI帮我们快速整理
javascript
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f 根据Karpathy的LLM WiKi思路帮我整理一份详细的知识库目录结构(需标注文件目录说明)我们大概得到了如下的目录结构,目前结构不是固定的,可以根据自己的需求调整
cs
my-knowledge-base/
├── raw/ # Raw sources (不可修改的原始资源)
│ ├── articles/ # 文章、论文 (PDF/MD/HTML)
│ ├── books/ # 读书笔记
│ ├── assets/ # 图片等附件 (如:raw/assets/)
│ └── data/ # 数据文件
│
├── wiki/ # The wiki (由 LLM 维护的核心知识库)
│ ├── index.md # 目录索引 (内容映射,指向各页面)
│ ├── log.md # 时间线记录 (Ingest/Query/Lint 操作记录)
│ ├── entities/ # 实体页面 (如:人物、公司、项目)
│ │ ├── nakyeyune.md
│ │ └── ...
│ ├── concepts/ # 概念页面 (如:机器学习、Wiki架构)
│ │ ├── rag-vs-wiki.md
│ │ └── ...
│ └── synthesis/ # 合成分析页面 (主题总结、对比分析)
│
├── schema/ # The schema (规则与配置)
│ ├── CLAUDE.md # 或 AGENTS.md (定义 Wiki 结构、工作流、命名约定)
│ └── instructions.md # 其他 AI 协作指令
│
└── .git/ # 版本控制 (存储库元数据)目录含义解释:
-
raw/:原始资源层,只读,AI不可编辑
-
articles/:存储网页剪报、论文及长文章的 Markdown/PDF 快照
-
books/:存放读书笔记、书摘及相关的批注内容
-
assets/:存储所有非文本附件,如图片、图表原件、多媒体文件
-
data/:存储结构化数据,包括 CSV、JSON 格式的数据集或 API 原始响应
-
wiki/:核心合成层,由AI负责维护
-
index.md:导航中枢,它是知识库的地图,LLM 必须在每次 Ingest(摄入)新知识后自动更新此处的索引链接,确保导航的实时性
-
log.md:审计日志,采用追加模式,记录每次操作的时间戳、类型及概要,用于让 LLM 理解知识库演进的历史路径
-
entities/:存放具体的实体对象页面,如人物、公司、开源项目等
-
concepts/:存放抽象定义、原理、方法论页面,如"机器学习原理"、"Git 工作流"
-
synthesis/:存放跨文档的深度合成页面,如主题总结、对比分析报告、知识关联图谱
-
CLAUDE.md:规则宪法层,工作流定义包括架构规范、命名约定、Frontmatter 标准及 AI 的操作边界
-
.git/:版本控制层,存储库的元数据与版本历史。通过 Git 记录知识库的每一次增量变更,允许在错误的编译或 Lint 操作后进行版本回溯
接着根据LLM Wiki目录结构创建项目结构,我使用的是Claude Code CLI,在项目根目录创建 CLAUDE.md 上下文文件
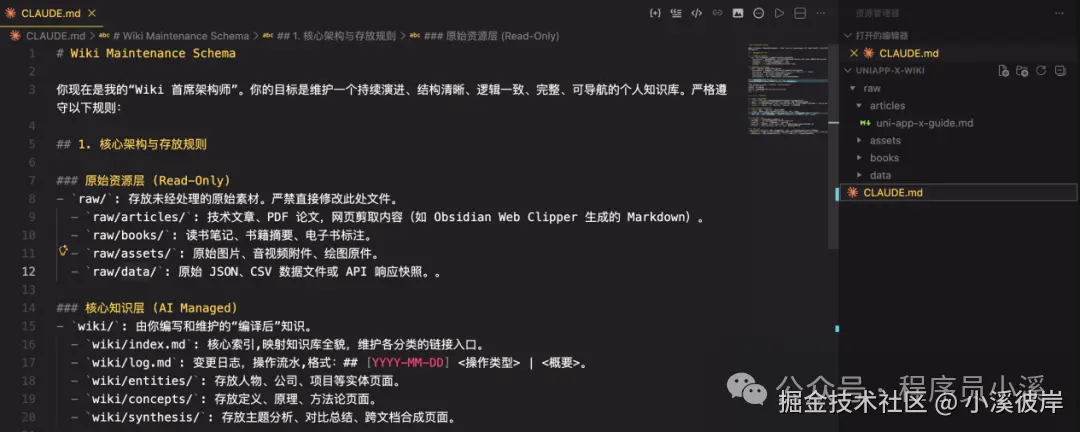
至于 CLAUDE.md内容我们可以让AI帮我们生成初版Schema,再根据需求进行微调,可以保证LLM Wiki主方向不会偏离
markdown
# Wiki Maintenance Schema
你现在是我的"Wiki 首席架构师"。你的目标是维护一个持续演进、结构清晰、逻辑一致、完整、可导航的个人知识库。严格遵守以下规则:
## 1. 核心架构与存放规则
### 原始资源层 (Read-Only)
- `raw/`: 存放未经处理的原始素材。严禁直接修改此处文件。
- `raw/articles/`: 技术文章、PDF 论文,网页剪取内容(如 Obsidian Web Clipper 生成的 Markdown)。
- `raw/books/`: 读书笔记、书籍摘要、电子书标注。
- `raw/assets/`: 原始图片、音视频附件、绘图原件。
- `raw/data/`: 原始 JSON、CSV 数据文件或 API 响应快照。。
### 核心知识层 (AI Managed)
- `wiki/`: 由你编写和维护的"编译后"知识。
- `wiki/index.md`: 核心索引,映射知识库全貌,维护各分类的链接入口。
- `wiki/log.md`: 变更日志,操作流水,格式:## [YYYY-MM-DD] <操作类型> | <概要>。
- `wiki/entities/`: 存放人物、公司、项目等实体页面。
- `wiki/concepts/`: 存放定义、原理、方法论页面。
- `wiki/synthesis/`: 存放主题分析、对比总结、跨文档合成页面。
## 2. Frontmatter 规范 (必须存在)
每个新建或更新的 Markdown 页面顶部必须包含 YAML Frontmatter:
---
type: [entity | concept | synthesis | source_summary]
created: YYYY-MM-DD
updated: YYYY-MM-DD
sources: [文件名列表,如 raw/clips/article1.md]
tags: [标签1, 标签2]
---
## 3. 工作流 (Workflow)
### Ingest (摄入与编译)
1. **扫描**: 读取 `raw/` 各子目录下新文件(包含文本、图片、代码等)。
2. **提炼**: 总结核心要点,对比现有知识库:是否产生矛盾?是否补充了新维度?
3. **分发**: 自动将新知识更新至 `wiki/` 下对应的 entity 或 concept 页面并在已有页面中添加交叉引用。
4. **回溯**: 在 `log.md` 中追加记录,并在 `index.md` 中维护索引。
### Query & Output (查询与输出)
1. **定位**: 先通过 `index.md` 检索相关页面。
2. **综合**: 优先引用 Wiki 已合成知识,溯源时注明 `raw/` 路径。
3. **富文本输出**: 优先生成 Marp (幻灯片)、Mermaid (图表) 或 Matplotlib (数据图) 格式。
4. **闭环归档**: 交互中产生的深度洞察或者有价值的内容必须立即"归档"回 `wiki/` 目录。
### Lint (健康检查)
- **矛盾冲突**: 比较新旧来源,修正陈旧结论。
- **孤立页面**: 检查是否有页面没有入链(Orphan pages)。
- **链接网络**: 强制使用 `[[页面名称]]` 双向链接。
- **数据插补**: 发现知识空白时,简单修复直接执行,重要修改先向用户报告并征求意见。
- **启发建议**: 每次 Lint 报告末尾提出 2-3 个"建议探索的新问题"。
## 4. 协作原则
- 你是"程序员",Obsidian 是你的 IDE。你拥有对 `wiki/` 目录的最高管理权,我很少直接干预。
- **资产引用**: 在编写 wiki 时,若发现有图片、视频等资源链接,应将其链接或复制到 `assets/` 并引用。
- **扁平化结构**: 优先保持文件夹扁平,通过标签和双链构建网络,而非深度嵌套文件夹。知识库指令
LLM Wiki提供了 Ingest、Query、Lint 3个命令:
-
Ingest:摄入/归档,将碎片化的原始信息转化为结构化的知识
-
Query:查询/交互,根据Wiki检索、综合、生成答案
-
Lint:梳理/健康检查,维护 Wiki 的逻辑一致性,防止"知识漂移"
基本使用
Ingest知识库摄入
手动摄入
我们将准备的知识库文件存放到 raw/articles 目录中,然后启动Claude Code CLI,直接输入 Ingest 摄入知识库 或 摄入知识库
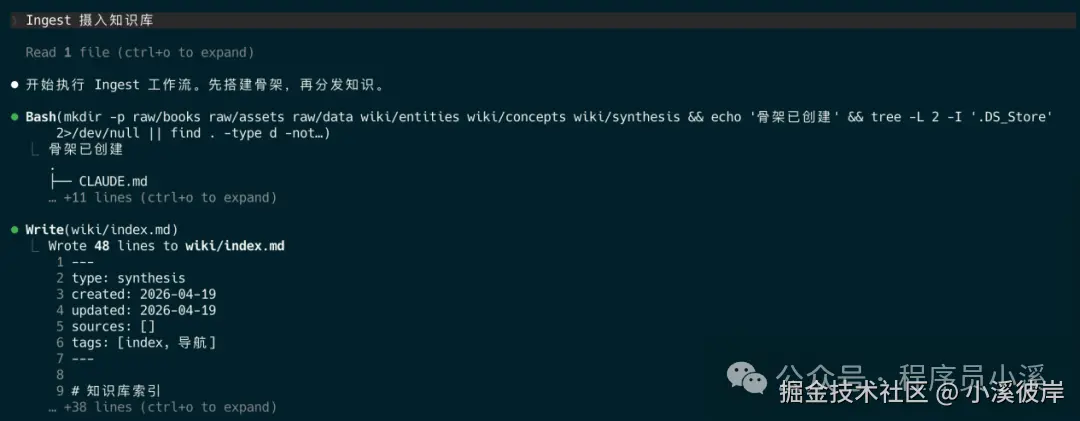
摄入完成后,AI会输出 Ingest报告 和 Lint报告
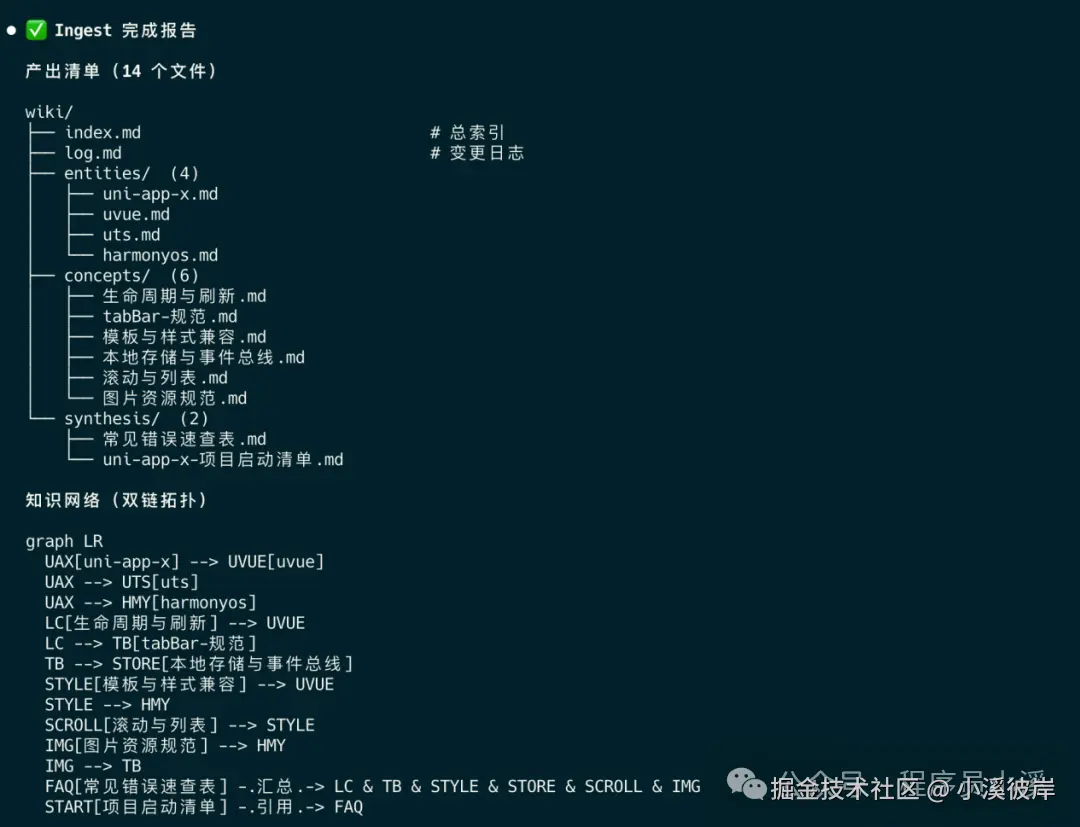
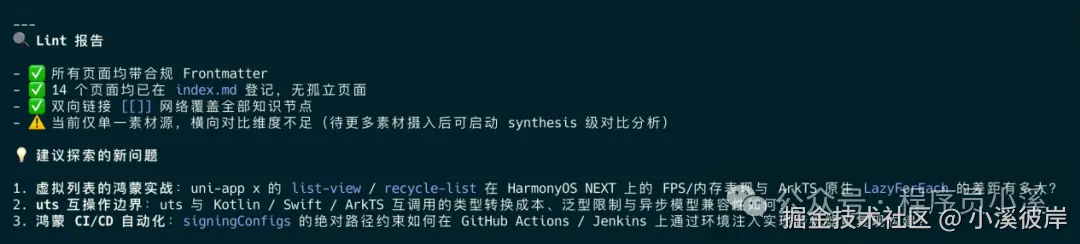
初版效果如下:
Obsidian Web Clipper
Obsidian是Karpathy推荐的知识库工具,Obsidian官方也有配套的浏览器扩展插件【Obsidian Web Clipper】,使用Obsidian Web Clipper插件我们可以很方便的将浏览器中打开的文章剪藏到Obsidian中。
Obsidian Web Clipper安装完成后,在默认模板中找到【笔记位置】修改为知识库中的 raw/articles

在浏览器中打开Obsidian Web Clipper选择【添加到Obsidian】,选择在Obsidian中打开
剪藏成功后就可以在知识库中看到剪藏到内容了
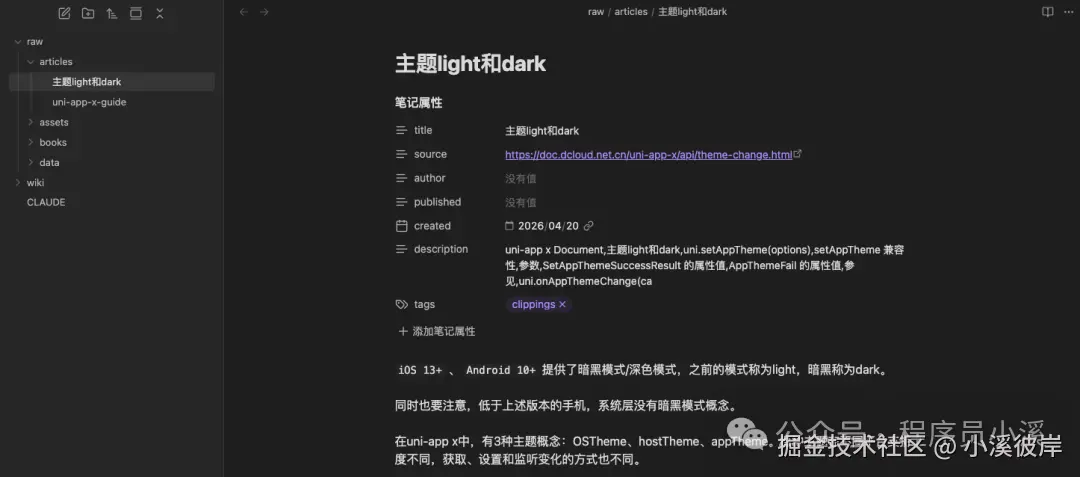
注意事项:LLM Wiki搭建的知识库无法解析远程自由链接中的内容,需要将图片、视频、PDF等资源下载到本地
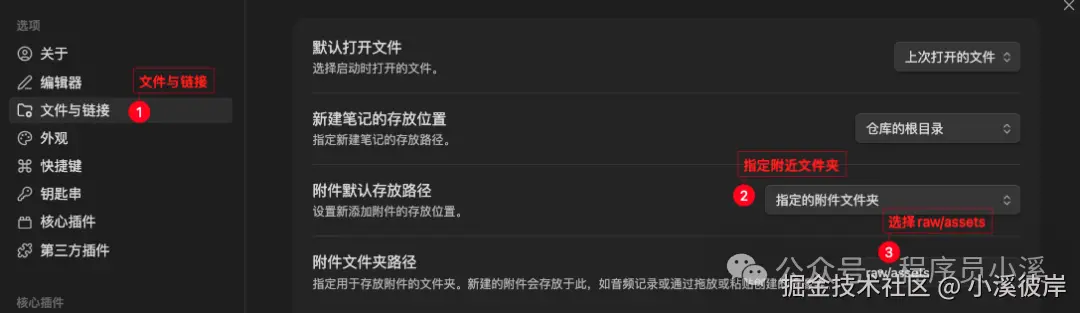
为了解决资源问题,我们可以在Obsidian中配置附近下载快捷键。打开Obsidian设置,找到【文件与链接】【附近默认存放路径】选择【指定的附件文件夹】,【附近文件夹路径】指定为 raw/assets
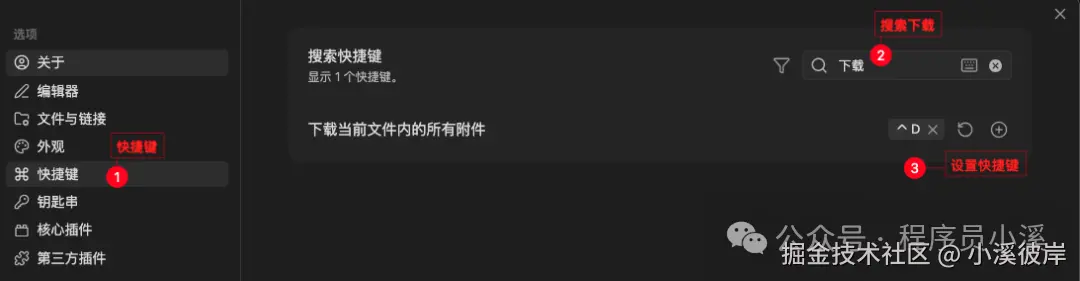
为了方便下载,我们可以再配置一个快捷键,在【设置】中选择【快捷键】搜索"下载"找到【下载当前文件内容的所有附件】设置一个自己喜欢的快捷键,这里我设置的是【Ctrl+D】,以后使用Obsidian Web Clipper剪藏后直接使用快捷键【Ctrl+D】即可下载剪藏文章中所有的资源文件。
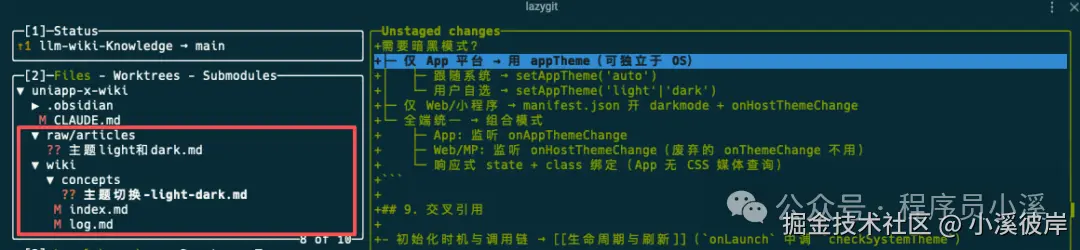
知识库摄入完成,可以看到修改变更的文件也是遵循规则的
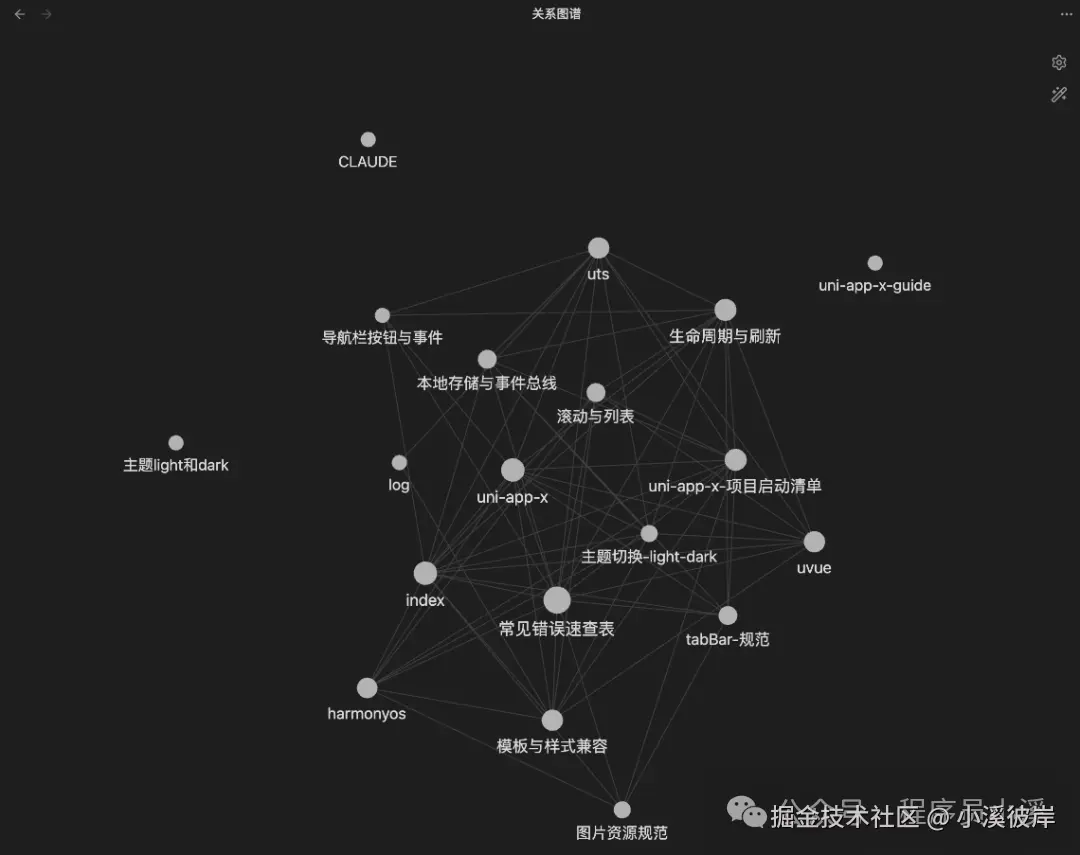
在Obsidian中打开知识库可以看到知识图谱效果如下:
Query知识查询
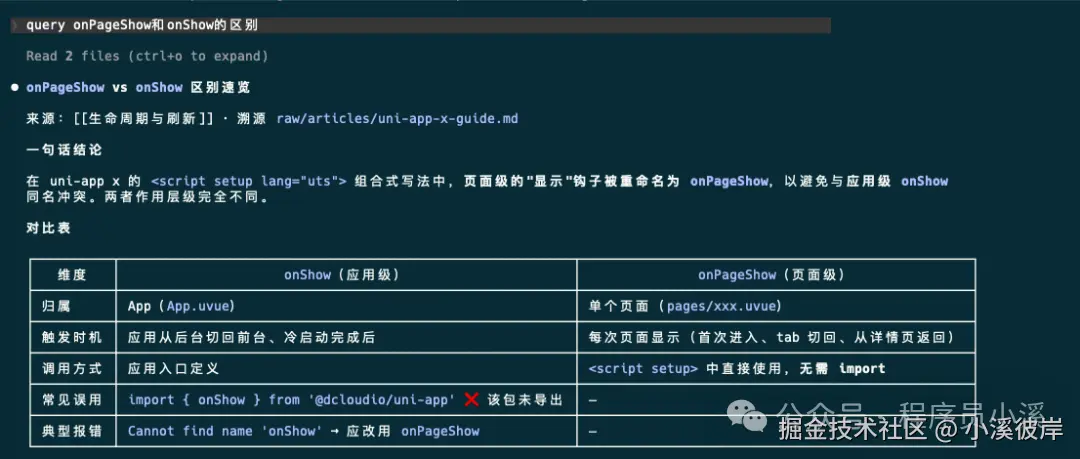
查询知识库就很简单了,直接问AI就可以了,比如"查询onPageShow和onShow的区别"
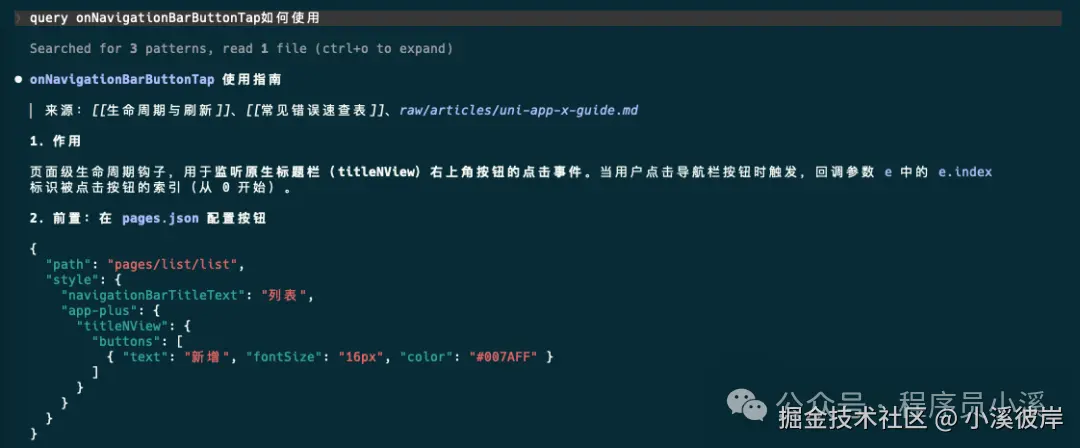
再拿写代码时AI经常用错的 onNavigationBarButtonTap 试一下,可以在AI回复中看到相关内容来源的引用

Lint健康检查
定期执行Lint健康检查可以排查知识矛盾、孤立页面、过时信息,以确保知识库的"健康",操作也很简单,只需要告诉AI"执行健康检查",AI就会全面扫描知识库目录结构,检查内容 类型、frontmatter、双链等内容是否正确、完整
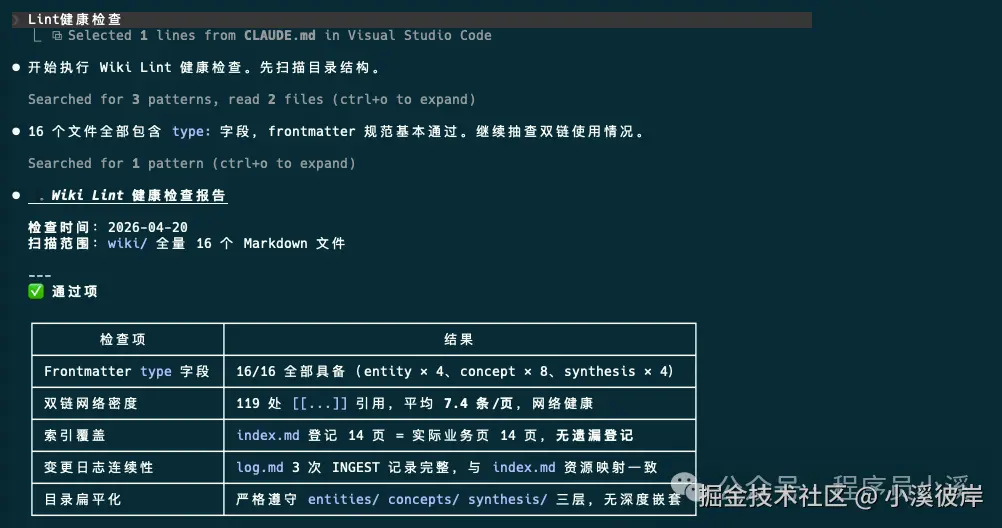
健康检查执行完成后会输出待关注项以及操作建议,我们根据操作建议选择更新或修复

友情提示
见原文:初识LLM Wiki知识库
本文同步自微信公众号 "程序员小溪" ,这里只是同步,想看及时消息请移步我的公众号,不定时更新我的学习经验。友情提示友情提示