上个月刚把我做的 HiCAD 2.0 AI渲染引擎正式发布!一句话生成酷炫3D模型 项目加上了 Harness Engineering,还没来得及写文章分享,AI圈就出了"大事":
6月7号谷歌工程师 Addy Osmani 发布了一篇题为《Loop Engineering》的文章
,正式将这个正在 AI 编程圈悄然兴起的新范式推向了大众视野。
短短三天,这篇文章就引发了全球开发者社区的热烈讨论,被称为 "AI 编程的第三次革命"。
而且很多AI圈技术大佬早已带头掀起了 "AI Loop" 的热潮,比如:

作为一名 AI 技术博主,我花了3天时间,整理和实践了 Loop Engineering 范式,下面我就和大家详细聊聊这个技术,并在文章最后给大家一个详细且完整的 Loop 工程化的代码案例,帮助大家快速上手 Loop Engineering。
什么是 Loop Engineering?
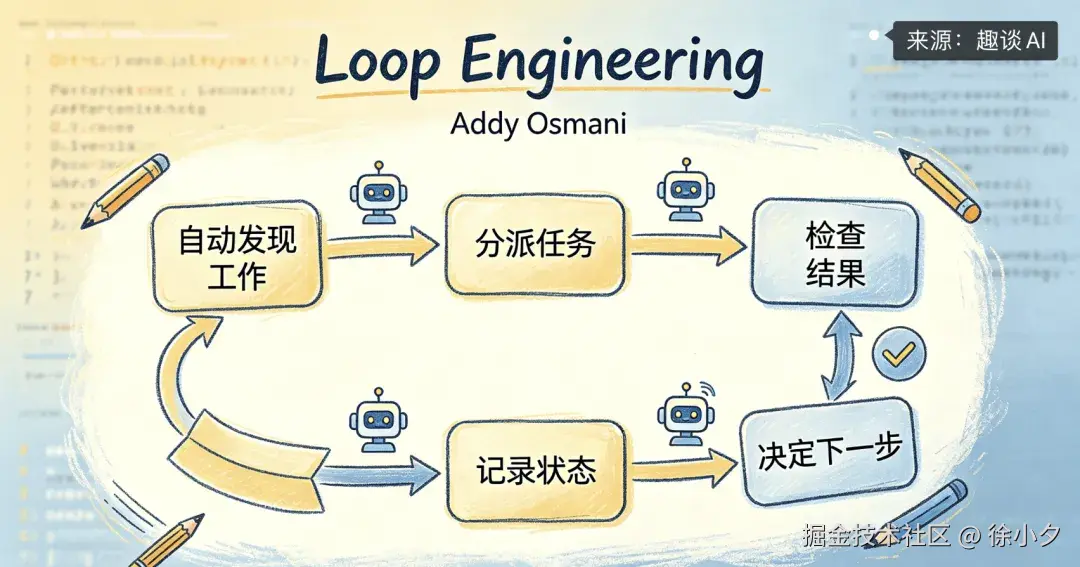
Loop Engineering 是一种全新的 AI 编程思想,用大白话来说,就是我们不用手动向 AI 编程工具一条条地输入提示词,而是通过设计一个能够自动发现需求、分发任务、检查成果、记录当前状态并决定下一步做什么的自循环系统。
这个系统会不断地调用 AI 模型/工具,直到我们指定的目标被达成为止。
这有点像我们工程学里面的 PDCA 循环。
简单来说,它和传统模式的差异如下:
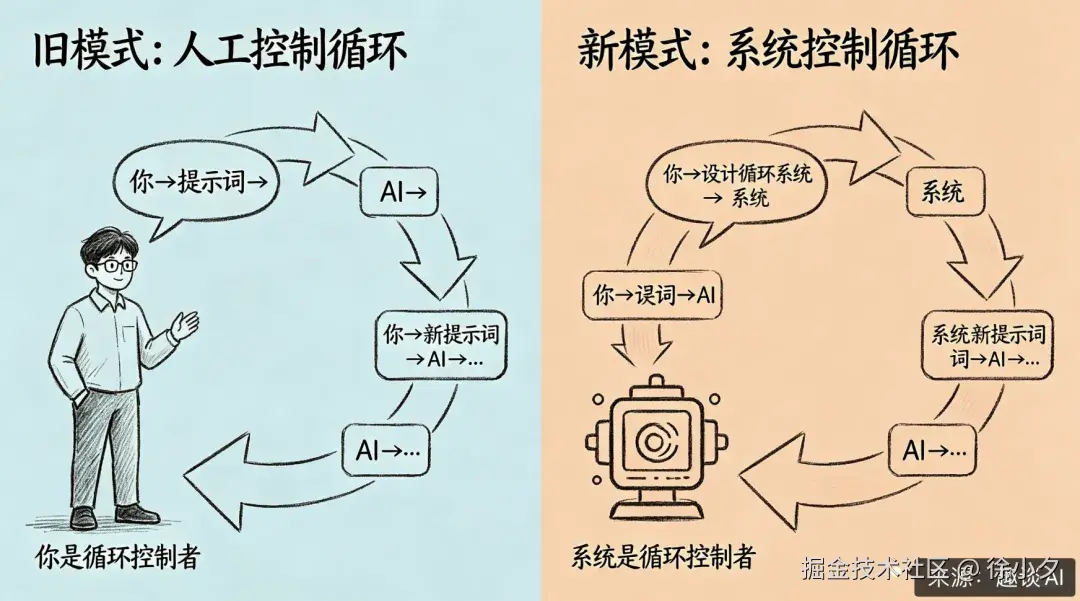
这是一个根本性的思维转变:从 "与 AI 对话" 转向 "编程式 AI" 。我们的工作不再是写出完美的提示词,而是设计出完美的反馈系统。
(还记得大学计算机课程最头疼的就是"循环"遍历)
AI 编程的三次革命: Prompt Engineering 到 Loop Engineering
AI 编程在短短三年内经历了三次重大的范式转变,每一次变革都极大地提升了我们的编程"生产力",从 提示词生成代码到 上下文 + Harness 工程化思想,其实已经能解决大部分软件开发场景了。
比如我们以前需要手写的静态网站,现在采用提示词 + skills,基本上没程序员什么事了,公司的运营和产品经理都能搞定。
再比如一个CRM系统,我们只需要搭建一套成熟的 上下文 和 Harness工程,再采用AI编程工具,一天时间就能完成 80% 的工作量,剩下的就是不断的人工测试,优化,然后上线。
现在的 Loop Engineering,就是要把我们的人工参与部分,直接"砍掉"。下面我画了一个3阶段的演进图,来致敬这次AI变革:
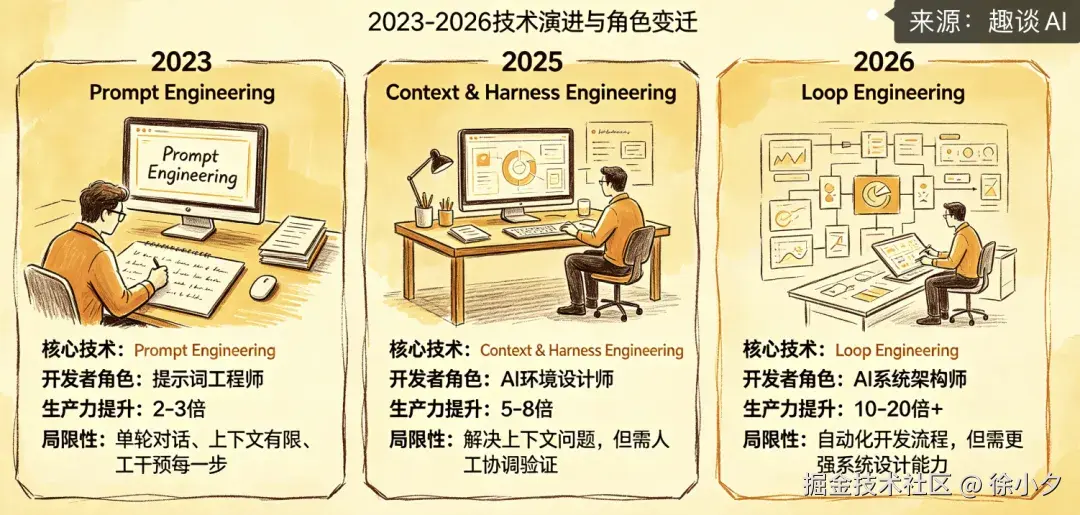
说了这么多,我想告诉大家的是,我们需要再次转变编程思维,从"手艺活"转变成"规则制定者"。
Loop Engineering 并不是孤立存在的,它建立在上面我介绍的所有技术的基础之上,我总结成了四层架构,大家可以参考一下:
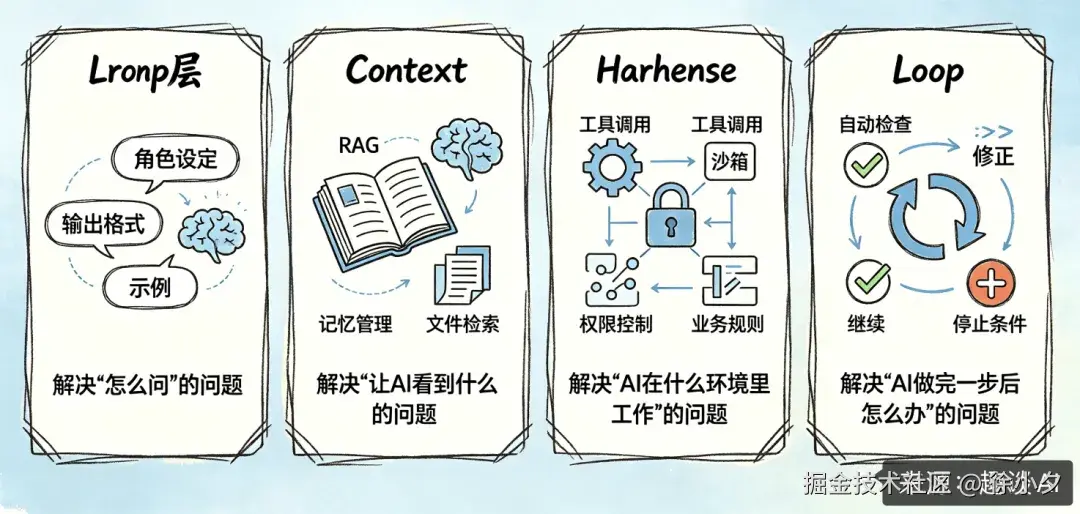 下面给大家详细介绍一下这4个模块:
下面给大家详细介绍一下这4个模块:
- Prompt 层解决 "怎么问" 的问题 ------ 比如角色设定、输出格式、示例等
- Context 层解决 "让 AI 看到什么" 的问题 ------如 RAG、记忆管理、文件检索等
- Harness 层解决 "AI 在什么环境里工作" 的问题 ------ 如工具调用、沙箱、权限控制,业务规则等
- Loop 层解决 "AI 做完一步后怎么办" 的问题 ------ 自动检查、修正、继续、停止条件
Loop Engineering 是站在这四层架构的最顶端,它关心的不是单次对话的质量,而是整个系统的自运行能力。
下面就和大家上干货了,建议收藏。
Loop Engineering 的核心原理
下面分享一下国外大佬设计的 Loop 通用五阶段循环:
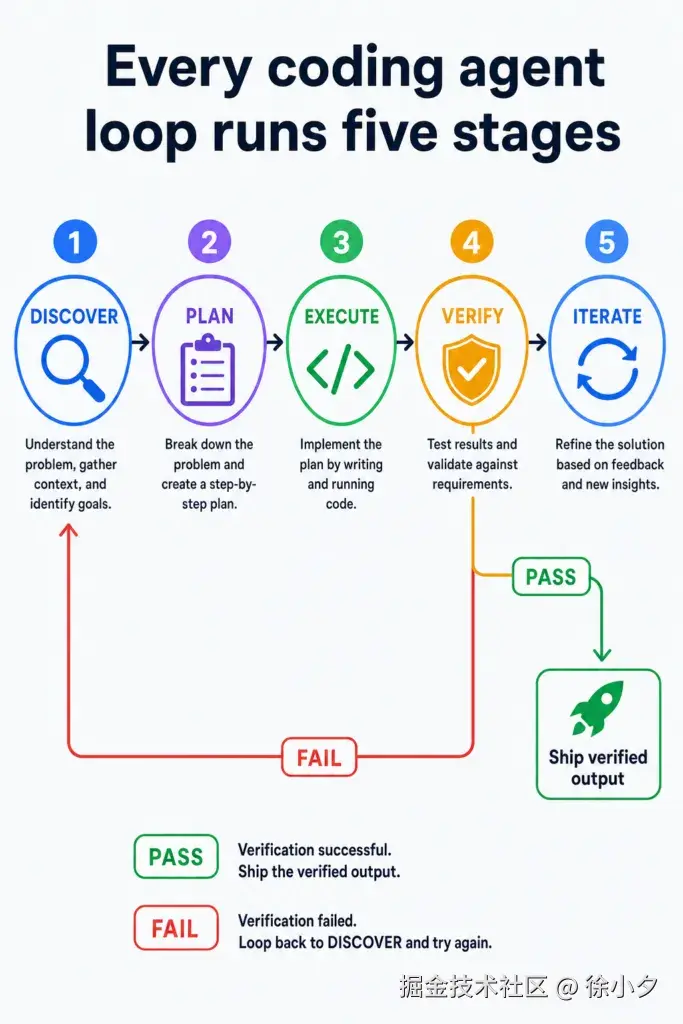
每一个编码循环,无论是单 Agent 还是多 Agent ------ 都遵循完全相同的五阶段循环,直到满足可验证的停止条件。
上面图片中提到的5层循环,包括:
- Discover (发现)
- Plan (计划)
- Execute (执行)
- Verify (验证)
- Iterate (迭代)
我结合自己的理解,梳理了一个流程图,大家可以参考一下:
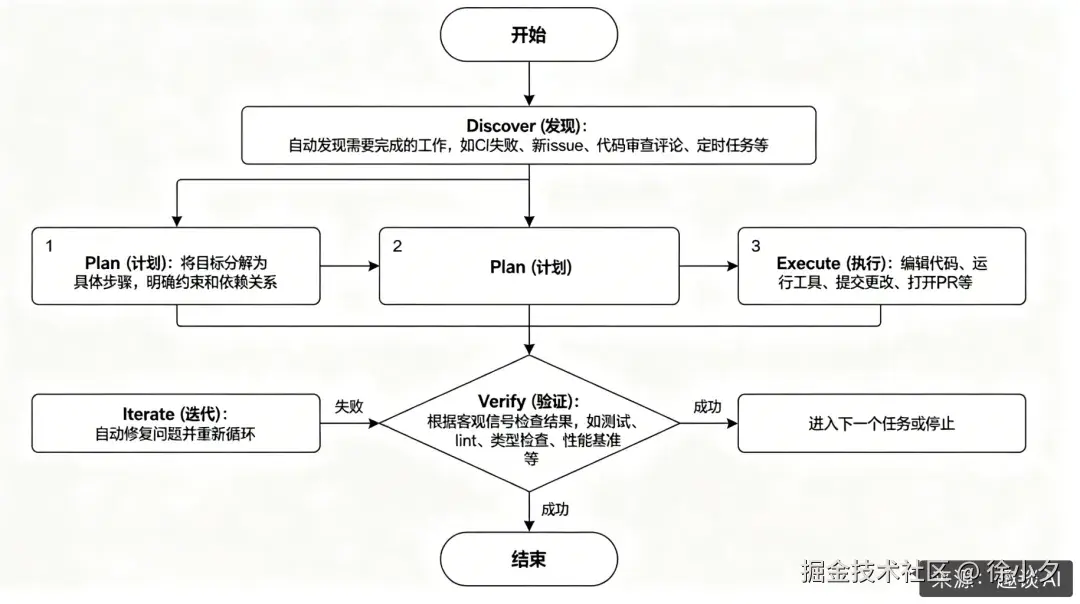
一个经验反思:状态存在于外部,而非上下文窗口
我认为 Loop Engineering 最核心的思想哲学是:不要信任模型的上下文窗口作为持久化存储。模型会遗忘,会漂移,会压缩信息导致约束丢失。
企业级AI开发的最佳实践是:所有状态都存储在外部系统中------git 仓库、markdown 文件、数据库、issue 跟踪系统等。每个循环迭代都从一个全新的上下文窗口开始,但需要在实际持久化的内容基础上进行工作。
这就是为什么最原始的 Ralph Loop 这么有影响力,只用了一行 bash 代码,就让AI永无止境的帮你干活:
bash
while :; do cat PROMPT.md | claude-code; done给大家分析一下这行循环的作用:
每次循环都会重新读取 PROMPT.md 和当前代码库状态,完全忽略之前的对话历史。
这种看似简单粗暴的方式,实际上解决了所有长对话上下文带来的问题。
(当然不得不说,那个时间段的AI能力,国内用这种做法只能是"白烧钱")
Loop Engineering 的六大核心要素
Addy Osmani 指出,所有现代 AI 编码工具(Claude Code、Codex 等)都已经内置了 Loop Engineering 所需的六大核心要素:
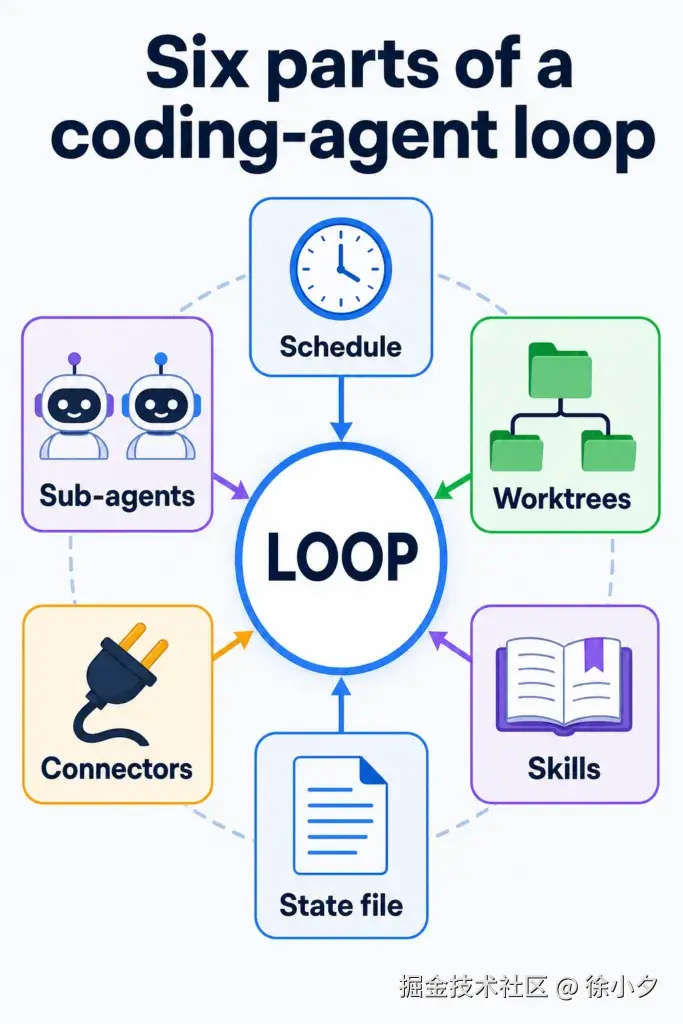
一旦我们理解了这些要素,就可以在任何AI工具中设计出有效的循环。下面我详细和大家介绍一下这6大要素。
1. Automations (自动化)
自动化是将一次性 AI 运行转变为真正循环的关键。它允许我们指定任务何时运行、运行频率以及在什么环境下运行。
这里分享一个典型案例:
- 每日早上 7 点30分自动运行脚本,处理前一天的 bug
- 每当有新 PR 被打开时,自动运行代码审查
- 每2小时检查一次性能基准,并进行回归
- 每周五下午5点自动生成 CHANGELOG.md
上面的场景,对应到 Claude Code 的代码示例如下:
bash
# 每天早上6点运行,处理CI失败
/loop "Run the triage skill on yesterday's CI failures and open PRs for fixes" --schedule "0 6 * * *"
# 运行直到所有测试通过
/goal all tests in test/auth pass and the lint step is clean如果大家用了其他 AI Coding 工具,原理也是类似的。
2. Worktrees (工作树):无冲突协作并行
当我们同时运行多个 AI 时,需要考虑最多的问题就是文件冲突。Git 工作树 为每个 AI Agent 提供了一个独立的工作目录,共享相同的仓库历史但不共享文件
。
Worktrees 的工作原理如下:
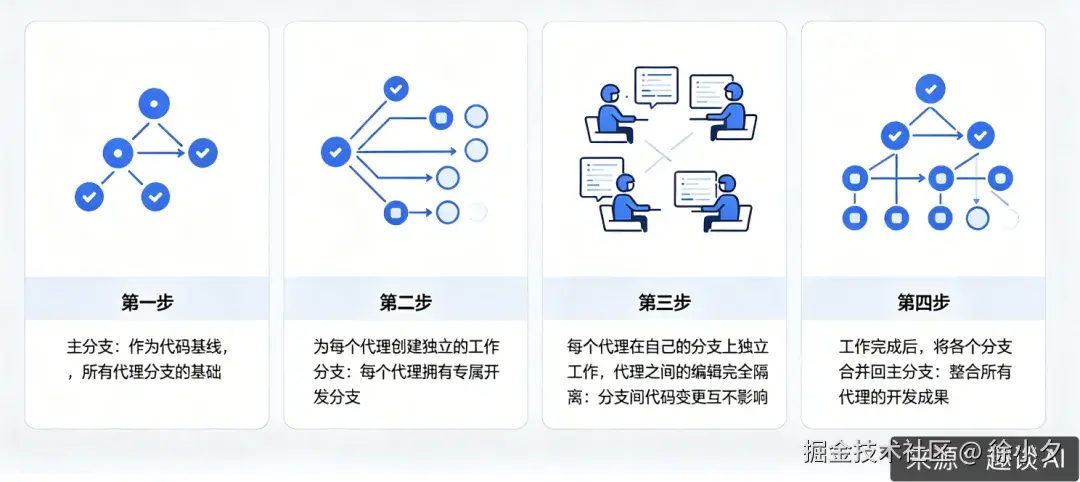
我个人理解其实就是 git 那套协作机制,我们把它搬到了 Loop 工程里来了。
这里我写了一个 Claude Code 示例,供大家参考:

3. Skills (技能)
Skills 技能是将项目知识编码到磁盘上的一种方式。它包含了:
SKILL.md文件- 可选脚本
- 参考资料
采用文件夹来组织。有关 skills 的详细落地经验,我在之前文章里有深度分享,大家感兴趣的可以参考一下.
AI Agent 可以在需要的时候调用这些技能,而不是每次都重新学习项目的约定。
skills 核心解决的问题有:
- 每次会话都要重新解释项目结构
- AI 经常忘记编码规范和最佳实践
- 相同的错误在不同会话中反复出现
我个人感觉其本质上就是经验的复用包。
为了照顾到不熟悉Skills的朋友,我再分享一下 Skills 的企业级文件结构:

Skills.md 的文件示例如下:

- Connectors(连接器)
连接器(基于MCP协议)主要作用是让循环能够与我们已在使用的工具进行交互。它是"AI告诉你该做什么事情"和"AI实际帮你完成了哪些事情"之间的关键区别。
这里分享几个常见连接器,供大家研究参考:
- Issue跟踪:GitHub Issues、Linear、Jira 等
- 通讯:Slack、Discord、Teams 等
- 数据库:PostgreSQL、MySQL、MongoDB 等
- CI/CD:GitHub Actions、Jenkins、GitLab CI 等
- 云服务:AWS、GCP、Azure 等
- Sub-agents(子代理)
最高效的循环设计原则是:一个代理负责实现,另一个代理负责验证。
我个人认为,让编写代码的模型来评判自己的代码,就像让学生给自己的考试打分一样不可靠。所以一定要让不同的 Agent 来实现从生产到检验的完整流程。
分享一下经典的三层代理协作架构:
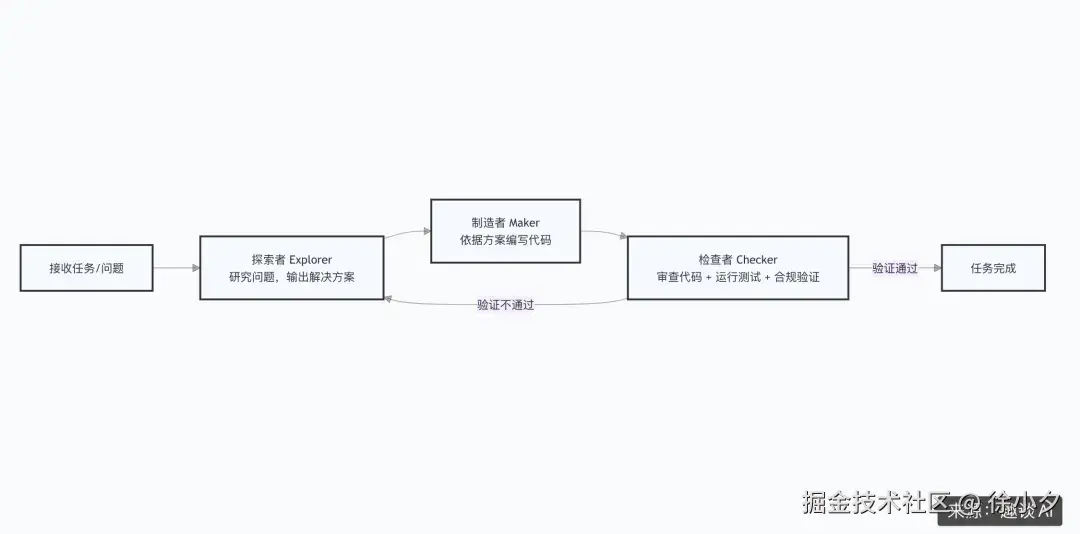
6. State (状态):Loop范式的记忆保障
模型会遗忘,但仓库不会。所有复杂运行循环都依赖外部状态来记住自己的运行阶段,比如什么已经完成了,什么还在运行阶段。
常见的状态存储方式有:
- Markdown 文件:
STATE.md、AGENTS.md、PROGRESS.md - 任务队列:
tasks.json - Issue 跟踪系统:GitHub Issues、Linear
- 数据库:SQLite、PostgreSQL
大家可以参考上面我分享的3种方式,来设计 Loop 的记忆层。下面分享一个实际的案例,说明如何设计记忆层:

Loop Engineering 的两大循环类型:闭环 vs 开环
Loop Engineering 有两种基本类型,分别适用于不同的场景,我整理了一个表格,大家可以对比参考一下:

闭环的五个必要组成包括:
- 明确的目标 (Goal) 精确地定义 "完成" 的样子
- 充足的上下文 (Context)
比如提供VISION.md、ARCHITECTURE.md、RULES.md等文件 - 受限的动作 (Action) 只允许使用必要的工具(约束行为)
- 客观的反馈 (Feedback) 包括如测试、lint、类型检查等
- 清晰的停止条件 (Stop Condition) 可验证的成功标准/结束条件
这里我个人是建议大家 从闭环开始。只有当我们完全掌握了闭环设计,并且有足够的预算和评估能力时,再尝试开环。
实战案例:构建自动修复 CI 失败的循环
接下来我带大家通过一个完整的实战案例来学习如何设计和实现一个 Loop Engineering 系统。
这里我将构建一个每天早上自动运行,修复前一天 CI 失败的循环。
步骤 1:准备项目结构
首先,在我们的项目中创建必要的文件夹和文件:

步骤 2:创建 CI 分类技能
这里直接分享我的 skills/ci-triage/SKILL.md:

步骤 4:配置子代理
.claude/agents/ci-fixer.toml 代码如下:

.claude/agents/code-reviewer.toml 代码如下:

步骤 5:创建 GitHub Actions 工作流
这里涉及到 Github 的自动部署工作流, 大家不熟悉的可以看我之前的文章,这里就直接上实际的代码了。
.github/workflows/ci-fix-loop.yml 代码如下:

步骤 6:初始化状态文件
这一步很简单但也非常关键, 大家需要重点关注。
STATE.md 内容如下:

下面我画了一个这个循环如何工作的流程图,大家可以参考一下:
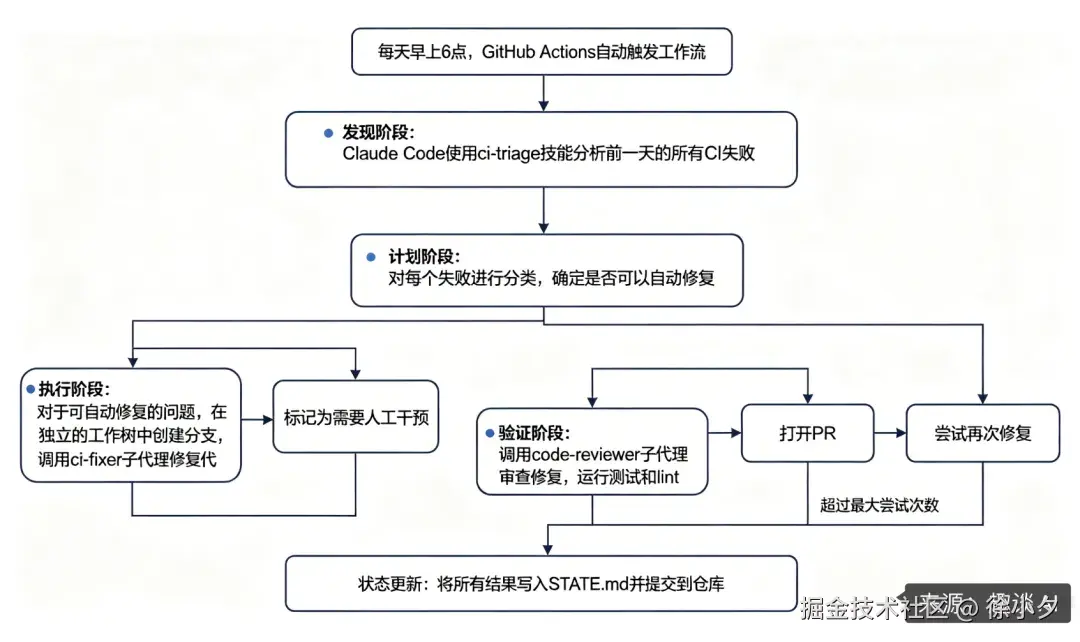
成本与安全考量
Loop Engineering 虽然强大,但如果使用不当,可能会带来高昂的成本和安全风险。
很显然,Loop 可能会消耗大量的 API 额度。在中等规模代码库上运行 50 -100 次迭代可能花费 ¥500 - 1000,甚至更高。
所以我们需要设计一套可靠的成本管控策略,下面分享一下我研究下来的一下方法和经验:
- 设置严格的迭代限制 永远不要省略
max-iterations(最大迭代数) - 从小规模开始先在 10-20 次迭代上测试,观察行为后再逐步扩大
- 计算 ROI这里需要设计一套符合公司自身的成本管控标准,比如 ¥500 的循环节省 20 小时工作?值得。完成 30 分钟能做的任务?不值得
- 使用成本较低的模型比如对于简单任务使用 Sonnet 而不是 Opus
- 监控和警报设置每日 API 使用警报,避免意外账单
下面再来分享一下技术层面的安全实践:
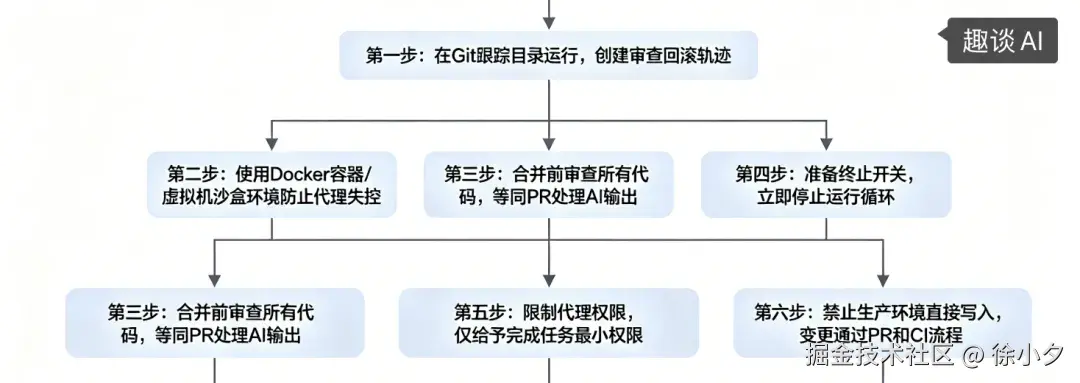
最后
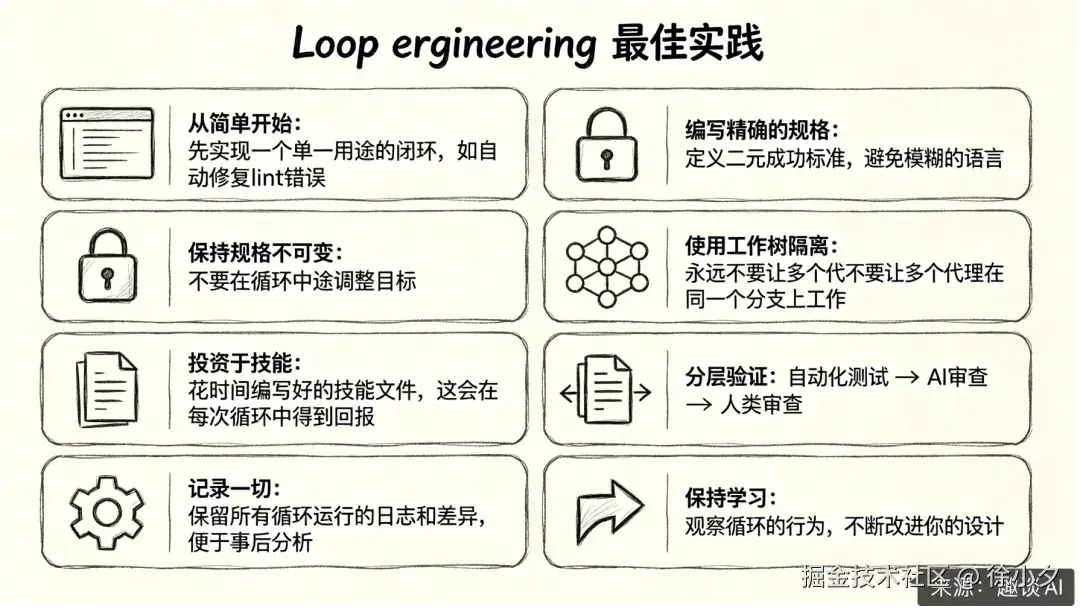
当然还有很多落地的实践,由于篇幅太长,我会在 《最系统的 AI 应用开发精品学习手册》中和大家深度分享,下面分享一下 Loop Engineering 的最佳实践,大家可以参考学习一下:
Loop Engineering 目前还处于早期阶段,但它已经展示出了巨大的潜力。后续我会持续实践和研究,挖掘更多的应用场景和价值,如果大家有好的经验和想法,也欢迎留言区交流反馈~