论文总结
- 整体框架:多模态可解释深度学习模型,融合药物多类特征、生物学先验知识与药物引导注意力(DGA)机制,实现药物敏感性预测与机制解析。
- 药物模块:整合分子结构、预测药物差异基因表达(DE)、预测激酶抑制谱(KI)三类模态,借助专属编码器提取特征并融合。
- 细胞模块:基于通路子图、蛋白互作(PPI)构建层级化图网络,结合通路图注意力网络(Pathway-GAT)处理转录组数据。
- 交互与预测:通过 DGA 建模药 - 细胞动态交互,最终拼接药物与细胞表征,利用前馈网络预测药物 AUC 值,以均方误差作为损失函数。
摘要
精确肿瘤学在解释复杂的细胞信号和预测跨异质癌症环境的药物反应方面面临着关键挑战。在这里,我们提出了BioGDR,一个多模态可解释的深度学习框架,它集成了基于结构的预测生物特征差异基因表达和激酶抑制谱,消除了对实验测量的需要。通过通过路径信息图形神经网络对肿瘤转录状态进行建模,并采用药物引导的注意策略,BioGDR能够对化合物和细胞环境中的药物敏感性进行机械性的洞察。综合评估表明,BioGDR在与早期药物发现相关的化合物筛选和预测精确肿瘤学特征的不同细胞状态的细胞系敏感性方面优于现有方法,而对临床病例队列的分析进一步证实了该方法的实用性和推广能力。一种新的ALDH1B1抑制剂的实验验证证实了它识别敏感细胞群和揭示潜在机制的能力。这项工作建立了一个强大的、生物信息的框架,连接了临床前药物开发和临床应用,通过集成的多模式学习和可解释的机制分析促进了精确肿瘤学的发展。
引言
精准肿瘤学依托多组学数据分析技术解析癌细胞内部异常信号调控网络,旨在为不同患者定制个体化治疗干预方案 ¹。尽管该领域前景广阔,但其临床转化进程仍面临巨大阻碍:2020 年一项综合分析数据显示,仅 13.60% 的患者符合基因组导向疗法的适用指征,而最终获得显著临床疗效应答的患者占比更是低至 7.04%²⁻⁴。这一显著疗效落差的核心成因在于肿瘤自身固有的异质性问题,该特性大幅削弱了单基因生物标志物检测方案的可信度⁵。 为突破这一瓶颈,学界已发展出若干整合分析策略:将基因组数据与生物学先验知识相融合,从分子机制层面阐释药物敏感性差异的内在缘由⁶。但基因组图谱分析结果表明,约半数患者体内不存在可靶向干预的基因变异,这一现状凸显了研发更精细、完备的治疗策略以应对肿瘤复杂病理特征的迫切需求⁷。
转录组学通过捕捉基因表达模式和细胞状态的动态变化提供了独特的优势,为下一代药物决策支持系统提供了有前途的基础。7尽管转录组学分析取得了进展,但药物发现仍然严重依赖传统的基于结构的方法。将转录图谱与化学和生物数据相结合已变得越来越重要,以解决单模式分析的局限性和满足对综合药物反应预测模型的迫切需求。5虽然基于结构的化学信息学能够在没有实验验证的情况下有效筛选类药物化合物,但这些方法固有地缺乏生物学背景,从而限制了它们对药物敏感性的预测能力。8为了缓解这一限制,几种方法扩大了具有改进的细胞特征的基于结构的药物表示,包括DeepTTA、9 HiDRA、10 Precly、11和CANDELA12。另一项工作试图通过直接在药物方面引入生物前体来增强化合物的特性,通常是通过实验来实现的这种多模式模型依赖外部实验资源,限制了实际适用性,特别是在新化合物发现情景中。例如,DGDRP17依赖于经过筛选的药物-目标相互作用注释来构建药物特异性基因网络,因此当目标信息不可用时不能直接应用。最近的多模式框架探索了整合化学和生物信息,而不需要在推断时进行新的实验测量。DTLCDR18将预测的药物-靶点相互作用曲线与在单细胞转录数据上预先训练的细胞嵌入结合在一起,而CSG2A19将分子结构与通过扰动预训练的基因-基因注意机制学习的基线或扰动信息转录表示相结合。这些方法说明了基于预测的多模式集成的前景,但它们的部分机械性覆盖以及缺乏将化学结构与生物信息特征联系起来的统一表示,突显了在药物敏感性预测中继续需要研究化学和生物因素之间的协同关系。
此外,深入解析药物作用机制对于优化治疗方案、助力新药研发并最终改善患者预后至关重要。既往研究多依托事后可解释分析方法开展机制解析工作。例如可视化神经网络模型 DrugCell,采用基于正则化线性回归的运算流程(RLIPP),仅通过事后可解释性分析,筛选出与药物敏感性相关的生物子系统⁶。与之类似,EXPRESS 模型借助集成特征归因算法,识别出能够影响急性髓系白血病(AML)联合用药疗效的造血分化特征 ²⁰。尽管上述方法已产出诸多有价值的研究结论,但学界仍有空间构建全新算法,在模型训练阶段便可更直观地捕获其内在决策逻辑 ²¹。
基于上述单一模式分析的局限性,我们强调,对药物机制的全面了解是推进治疗策略、加快药物开发和优化患者结果的基础。通过广泛的分析,我们确定了开发强大的药物决策支持系统的三个关键挑战:(1)转录组驱动的药物敏感性预测:鉴于药物反应受复杂的基因表达网络控制,迫切需要复杂的方法来有效地提取和整合复杂的生物信息。(2)超越化学相似性:虽然分子尽管结构仍然很重要,但单靠它不能完全阐明生物系统内的药物行为,这就需要整合不同的分子和细胞数据流来进行全面的药物表征。(3)上下文依赖机制建模:癌症固有的异质性要求模型能够跨化合物特定和细胞上下文识别药物机制,考虑到在不同生物环境中观察到的不同治疗反应。
为应对上述挑战,本文提出一种深度学习框架 BioGDR。该框架无缝融合多模态药物表征与高精度生物通路图神经网络,以此提升肿瘤药物敏感性的预测精度。 BioGDR 的核心思路是依托双重生物功能上下文 ------ 通路结构与蛋白质相互作用,对细胞微环境进行完整仿真,从而实现转录组特征精细化表征。该框架的关键创新在于引入两类由化合物结构直接预测得到的前沿生物源性特征:化合物扰动差异基因表达谱(DE)与激酶抑制谱(KI);两类特征由本团队前期研发的 TranSiGen、KinomeMETA 两种深度学习模型生成 ²²⁻²⁴。 TranSiGen 基于大规模化合物诱导转录扰动数据集完成训练,可捕捉药物作用引发的表型变化;KinomeMETA 依托全面的激酶活性图谱数据训练,能够推演化合物对关键肿瘤相关激酶的特异性抑制效应。相较于传统基于分子结构的描述符,这两个模型可学习丰富的生物语义,更真实地反映小分子化合物的功能效应与作用机制。 上述特征突破了传统化学描述符的局限,完善了化合物的生物学表征体系。此外,BioGDR 引入药物引导注意力机制(DGA),可有效解析复杂的药物作用模式,为阐释药物作用机制提供理论依据。
我们进行了全面的评估,以评估BioGDR在不同生物医学背景下的表现。评估框架包括多个关键方面:首先,我们通过仅针对结构的预测和结合预测的生物特征的综合预测来评估模型对新化合物的泛化能力。其次,我们评估了它在以前未见过的细胞系上的表现,包括挑战非实体肿瘤,如AML,以验证其在处理细胞异质性方面的稳健性。第三,我们对BioGDR的生物注意模式进行了深入的分析,揭示了化合物和细胞特定背景下的关键基因和途径。
第四,通过对敏感细胞系进行前瞻性实验药物筛选,验证了该方法的实用性。最后,我们通过成功地区分患者队列中的药物敏感性模式,证明了它的临床相关性。通过这项系统评估,我们证明了BioGDR的多模式表示法、生物学知识和DGA策略的集成,为药物敏感性建模建立了一个健壮和通用的框架,推动了精确肿瘤学领域的发展。
结果
BioGDR模型概述
将高维组学数据整合至临床药物决策支持系统面临三大核心难题:多组学特征异质性带来的复杂干扰、化学分子结构与药物敏感性临床结果之间的转化鸿沟,以及解析药物应答内在生物学机制的现实需求。针对上述问题,BioGDR 构建了一套整合框架:依托药物引导注意力(DGA)策略融合多模态药物表征与生物通路网络,同步实现药物敏感性预测与药物 - 细胞相互作用的机制解析。
在药物模块(图 1A)中,BioGDR 采用多特征架构:一方面通过图神经网络(GNN)提取化合物化学属性 ²⁵,另一方面引入预测型生物特征 ------ 转录扰动谱(DE)与多靶点效应谱(KI)。多维度特征融合可完整刻画细胞状态改变特征 ²⁶与肿瘤关键通路信息 ²⁷,²⁸。该架构一大核心优势在于,DE、KI 两类特征均可依托前沿人工智能模型,仅从化合物分子结构直接计算生成 ²²⁻²⁴,这使得 BioGDR 仅凭借分子结构信息即可完成全新化合物的药效评估。
细胞模块(图1B)实现了一个先进的生物路径图网络,该网络结合了路径基因关系和蛋白质-蛋白质相互作用。通过嵌入这些具有生物意义的结构,该模型处理转录图谱,以生成细胞状态和子系统活动的详细表示,从而建立一个捕获疾病和细胞异质性的强大框架。此外,该模型使用药物引导注意(DGA)策略(图1C)来动态模拟药物与细胞之间的相互作用,从而使识别构成化合物作用机制(MOA)的上下文特定基因和途径。10最后,在预测模块(图1D)中,我们通过神经网络结构将来自生物功能上下文的上下文特定细胞表示与多模式药物特征相结合,以生成药物敏感性预测。
BioGDR 可精准建模复杂的药物 - 细胞相互作用,同时在多类预测场景中具备优异的泛化稳定性。本研究采用三套差异化验证方案对模型开展严谨性能评估:
- 随机划分测试:用于识别全新的药物 - 细胞配对相互作用;
- 未知药物测试:模拟新药研发场景,评估全新化合物的治疗潜力;
- 未知细胞测试:模拟精准医疗中异质性细胞环境,评估化合物在不同细胞背景下的药效差异。
本研究将 BioGDR 与多款当前顶尖预测模型完成全面对比,对比基线包括:
- DeepTTA:依托原始转录组图谱构建预测框架⁹
- HiDRA:采用通路映射后的转录组图谱建模 ¹⁰
- Precily:基于单样本基因集富集分析(ssGSEA)通路得分搭建模型 ¹¹
- CANDELA:融合模块化药物图与表达图神经网络(GNN)进行预测 ¹²
同时额外选取多模态框架开展对照实验,包含 CSG2A(基于扰动预训练基因 - 基因注意力机制)¹⁹、DTLCDR(融合预测药物 - 靶点互作(DTI)谱与 scBERT 转录组特征)¹⁸,以及一套纳入活性药物信息、架构复杂度与 BioGDR 相近的经典深度神经网络(DNN)模型;全部对比数据详见补充表 3。
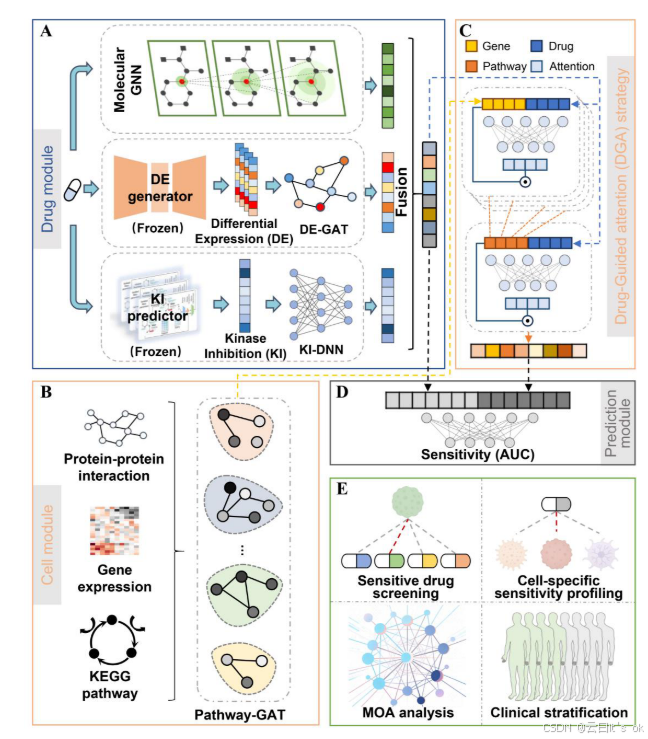
图1.BioGDR概述。(A)药物模块集成了三个复杂的特征编码器:用于提取分子结构信息的AttentiveFP,以及分别用于生成化合物诱导差异表达谱(DE)和激酶抑制谱(KI)的预先训练的TranSiGen和KinomeMETA模型。这两个预先训练的模块都以冻结的方式使用,它们的输出在BioGDR训练期间被视为固定的输入特征。DE特征通过蛋白质-蛋白质相互作用映射和图注意网络(DEGAT)来处理,而KI特征通过优化的深度神经网络(KI-DNN)来处理。这些多模式特征通过双DNN无缝集成和转换,为预测和创新的药物引导注意(DGA)策略生成全面的药物表示。(B)该模型通过路径特定的子图结合了生物学背景,其中基因通过蛋白质-蛋白质相互作用(PPI)相互连接。
Path-GAT模块处理这些子图,利用基因表达数据作为初始节点特征来捕获路径水平的动态。(C)DGA策略通过在基因和途径水平上集成药物特征,生成上下文感知的细胞表示以进行精确预测,从而促进复杂的药物-细胞相互作用建模。(D)预测模块采用先进的全连接DNN架构来生成以曲线下面积(AUC)值表示的药物敏感性预测。(E)BioGDR在多种应用中表现出多功能性:敏感药物筛选、细胞特异性敏感性分析、MOA分析,以及基于预测的药物反应对患者群体进行临床分层。
BioGDR有效提高药物敏感性预测
BioGDR 在药物敏感性预测任务中表现出优异效能,尤其在全新药物 - 细胞配对识别与药物筛选场景中优势突出。随机划分验证的全面评估结果证实,BioGDR 具备更优越的预测性能(见图 2A、补充图 1、补充表 5)。 该模型在 21 种不同组织来源的细胞系中性能稳定,斯皮尔曼相关系数(SCC)区间为 0.796~0.867,其中多达 20 类组织的相关系数高于 0.8(见图 2C)。按照药物作用机制(MOA)分类开展分析时,BioGDR 在所有主流药物类别中均可维持稳定预测水准(见图 2B)。 研究在 GDSC 数据集上完成独立建模与验证,观测到完全一致的性能变化趋势,进一步佐证 BioGDR 预测能力的稳健性(补充表 6)。上述多维度结果充分证明:依托多模态分子特征融合与双重生物学知识框架,BioGDR 能够精准解析复杂的药物 - 细胞互作关系。
为了评估BioGDR的实用价值,我们将其应用于PRISM数据库中对结直肠癌(CRC)细胞系HCT-116的药物敏感性预测。图2D显示了BioGDR对测试化合物的预测和实验测量之间的强烈相关性。对预测的前5%敏感药物的分析显示,经过实验验证的敏感化合物显著丰富(图2e)。值得注意的是,在之前没有在HCT-116上进行测试的前10种预测的敏感化合物中,有7种得到了文献中实验证据的支持,包括梅坦辛醇-异丁酸酯、29 SB-743921、30 SN-38、31、32和PF-0375830933(补充表7)。这些预测还确定了潜在的药物再利用机会。例如,k-Strophanthidin,一种心脏糖苷,34被预测对HCT-116细胞株有效。这一预测与高通量筛选研究表明,心脏糖苷对结直肠癌细胞的抑制作用是一致的。建议k-strophanthidin在CRC.35,36对三阴性乳腺癌进行平行筛查分析,结果详见补充章节B.3:"结直肠癌和TNBC细胞系的药物筛选"和补充表8。
细胞扰动和多靶点特征将化合物与反应联系起来
预测全新化合物的药物敏感性是药物研发早期阶段的核心刚需,但庞大的化学分子空间与全面注释数据匮乏使其成为一大难题。与既往研究结论一致⁸,仅依托化学结构构建的模型,在评估从未见过的新药时预测效果十分有限(见图 3A、补充图 2、补充表 9--10)。 与之相对,BioGDR 这类多模态模型通过引入生物学先验特征突破了该局限,大幅提升了新化合物药效预测的准确度。在所有对比方法中 BioGDR 性能最优,原因大概率是其同时整合了肿瘤相关靶点信息与药物诱导转录扰动信息。 除此之外,即便仅将扩展连通性指纹(ECFP)、激酶抑制谱(KI)、差异基因表达扰动谱(DE)组合搭建标准深度神经网络(DNN),性能也全面超越所有仅依赖分子结构的基线模型,这充分证明在化合物表征体系中融入生物学背景信息具备关键价值。
消融研究证明了生物特征在模型性能中的关键作用(详见方法)。差异表达(DE)特征成为最重要的贡献因素,有效地捕获了药物诱导的细胞反应。激酶抑制(KI)图谱显示相对温和的影响,主要是增强了对激酶靶向治疗的预测。有趣的是,与排除DE特征相比,删除结构特征导致的性能降级较小,并显示出与KI特征相似的影响(图3B,补充图3和补充表11)。我们还评估了仅使用单一特征类型作为输入的BioGDR变体,它们的性能趋势与相应的单特征消融模型中观察到的趋势一致(补充表11)。在对476个不同的细胞系进行的综合评估中,BioGDR的表现始终优于其仅限于结构的变体,469例(98.5%)的预测有所改善(图3C)。UMAP对学习到的表示的可视化显示,与纯结构方法相比,BioGDR在区分敏感和非敏感化合物方面的能力得到了增强(补充图4)。这些发现表明,多模式生物特征编码的相互作用模式比单独的结构相似性更有效地概括。
为进一步验证模型在真实新药研发场景下的泛化能力,本研究开展十折结构相似度受控的盲药物评估:测试集化合物与训练集不存在结构近似的邻近分子(详见实验方法部分)。本次评估选取三款综合性能最优的代表性模型开展对照测试。 在这一严苛实验条件下,所有模型的预测精度均出现回落,但 BioGDR 的表现始终优于其余基线模型(见图 3D、补充图 5、补充表 12--13)。三款对比模型各有技术侧重:CANDELA 依托面向分子结构的预训练流程构建表征;DTLCDR 可输出直观的靶点层级相互作用谱;CSG2A 则利用化学扰动信息建模。但上述模型均采用信息容量有限的单模态表征方案,这大概率是其在分子结构差异极大时性能衰减的核心原因。 综合全部结果可见:将预测得到的差异基因表达扰动特征(DE)、激酶抑制特征(KI)与通路感知细胞建模相融合,可形成具备协同增益效应的复合表征;即便无法依靠化学相似性提供预测线索,该表征依旧保持可靠预测能力。这一结论印证,BioGDR 十分适配高难度全新分子(de novo)药物发现任务,可有效筛选活性化合物。
因此,我们评估了DE和KI特征在复合亚群中的贡献。对于DE分析,根据其转录扰动程度37对化合物进行分层(详见补充部分B.7"基于DE变化的药物分类"和补充图6A)。分析表明,与DE消融模型相比,BioGDR在Largechange组中取得了显著更高的性能,而在小变化组中表现出类似的性能,表明DE特征在预测转录活性化合物的反应方面发挥了关键作用(图3e)。这一点对于HDAC抑制剂尤其明显,如Belinostat,它们已知可以诱导广泛的转录调节,并且当DE特征被去除时,预测准确性表现出最显著的下降(图3F)。对KI特征的分析显示,在与KI相关的组中,BioGDR表现出比KI消融模型更好的性能(图3G)。这一点以Tozasertib为例,它是一种靶向多靶点的激酶抑制剂极光激酶,在缺乏KI特征的模型中表现出显著的性能下降(图3H)。分析还显示,某些被注释为非激酶MOA的化合物由于包含了KI特征而显示出更高的预测精度。一个值得注意的例子是常青酮,它最初是作为一种针对Pro-tRNA合成酶的抗原虫药物而开发的。这种化合物在KI-消融模型中表现出显著的性能恶化(图3I和补充图6B)。重要的是,KI图谱显示了潜在的p38 MAPK抑制,这随后被公布的实验数据所证实。38这些发现表明,纳入KI图谱可以揭示以前未知的多靶点效应,为癌症治疗中潜在的药物再利用策略提供见解。
以前的研究已经证明了DE和KI特征在预测药物敏感性方面的价值。14-16然而,对实验产生的DE或KI数据的要求大大限制了这些方法的实际应用。BioGDR通过利用DE和KI特征的基于结构的预测来解决这一限制,这不仅提高了预测的准确性,而且在保持只需要输入分子结构的简单性的同时使更广泛的适用性成为可能,从而为现实世界的新型药物发现场景提供了更实用的解决方案。
BioGDR 整合多层级生物网络,用以应对细胞异质性问题
在以前未经测试的细胞环境中预测药物敏感性对于精确肿瘤学至关重要,治疗必须在不同的细胞状态下推广。BioGDR通过将已建立的生物学知识与特定于药物的环境相结合,建立了一个信息提取框架,最大限度地减少了对从头学习的依赖,以增强对不同细胞环境的泛化。BioGDR通过在路径和PPI结构的分层基因网络上通过图形建模建立细胞表示,并使用药物引导的注意策略(DGA)进一步细化它们,以生成动态的、药物特定的细胞表示。在看不见的细胞环境中,这些集成的方法增强了对不同类型细胞的敏感性预测,表现出优于基线模型和多种消融变体的性能,包括那些去除路径结构(w/o通路)、PPI先验(w/o True-PPI)、整个图形编码器(w/o图)或药物-细胞相互作用机制(w/o DGA)的方法(见方法;图4A-B补充图7-8和补充表14-16)。我们通过进行10倍相似性控制的细胞盲评估,进一步评估了BioGDR在更严格条件下的稳健性,在该评估中,测试细胞系与训练集没有接近的基本表达邻居。BioGDR再次保持了与代表性基线相比的明显性能优势(见方法;图4C,补充图9和补充表17-18)。DTLCDR通过预先训练的scBERT嵌入增强了细胞模块,但不编码途径结构或基因-基因相互作用模式,当推广到新的细胞环境时,它获得了第二好的性能。总体而言,BioGDR保持了持续较高的预测精度,这证实层级化生物细胞模块是模型在未知细胞环境下维持性能的核心支撑。
为严谨验证 BioGDR 应对肿瘤异质性的能力,本研究采用急性髓系白血病(AML)药物敏感性数据集开展外部验证 ³⁹。本次验证难度极高:AML 属于非实体肿瘤,其肿瘤生物学特征与训练所用、基于实体肿瘤构建的 PRISM 数据集存在本质差异(见图 4D);测序平台差异、数据处理流程不同、基因表达谱数据残缺等技术偏差进一步放大了验证难度。 即便存在多重严苛阻碍,BioGDR 仍展现出优异性能,斯皮尔曼相关系数(SCC)达到 0.597,大幅优于所有对照模型。更突出的是,AML 数据集中有 19 种药物(占比 25%)对模型而言属于完全全新化合物,在这种药物、细胞均为零样本的双重未知场景下,BioGDR 依旧保持稳健预测精度(SCC=0.436)(见图 4E、补充表 19)。
我们通过量化转录相似细胞的数量,系统地评估了AML细胞和PRISM训练队列之间的相似性。当遇到与训练数据集的相似度降低的单元时,传统的机器学习方法通常表现出预测性能降低。然而,BioGDR通过在不同程度的细胞相似程度上保持一致的性能,展示了非凡的健壮性(图4F和G)。这种非凡的能力突显了BioGDR在识别和利用超越表面相似性度量的基本生物机制方面的复杂架构。
依托药物引导注意力机制解析不同药物与细胞环境下的药物作用机制
破译药物的作用机制(MOA)仍然是精确医学中的一个关键挑战,需要全面了解药物诱导的生物调节。为了应对这一挑战,BioGDR实施了一种创新的药物引导注意(DGA)战略,该战略系统地识别并优先考虑功能相关的基因和途径(图1C)。通过对目标基因和目标包含路径的注意模式的严格分析,我们验证了DGA方法的有效性。结果表明,BioGDR成功地对已知的药物靶标进行了优先排序,与非靶标基因相比,靶标基因在顶级区间的注意力得分和丰富模式显著提高(图5A)。此外,围绕药物靶点的途径("靶点途径")表现出更明显的浓缩模式(图5B),强化了治疗效果通常通过整个途径网络而不是单个分子靶点传播的生物学原理。
对基因注意力模式的分析揭示了对应于不同MOA的不同簇,展示了BioGDR区分药物机制的复杂能力(图5C)。这些集群的空间组织进一步表明,BioGDR有效地捕捉到了MOA内部的关系和机制不同MOA之间的相关性。这一点的例证是EGFR抑制物(EGFRi)、MEK抑制物(Meki)和mTOR抑制物(MTORi)簇的紧密接近,这与生物学上公认的MEK和mTOR作为EGFR调节的信号级联中的关键效应因子的理解一致。41在平行的观察中,微管蛋白聚合抑制物(TPI)、极光激酶抑制物(Aurki)和拓扑异构酶抑制物(Topoi)的空间聚集--尽管它们的分子靶标不同--反映了它们对有丝分裂过程的趋同作用,包括调节微管动力学、42纺锤体的形成、43和DNA拓扑。
由于复杂的多靶点相互作用,共享相同MOA的药物可能会引起不同的细胞反应,这可能会混淆仅基于基因水平注意力分析的机制解释。为了解决这一限制,BioGDR实施了路径级别的注意力分析,它聚合了跨多个基因的信号,以提供对药物机制的更全面的理解。事实证明,这种方法在检查药物反应模式时特别有价值。例如,虽然某些药物在基因水平的注意力分析中未能与主要的EGFRi组聚集在一起(图5C),但路径水平的检查显示,聚集的和非聚集的EGFRi药物在EGFR相关的通路中的注意力得分明显高于非EGFRi化合物(图5D)。一个引人注目的例子是CUDC-101,尽管它在EGFRi组中处于非聚集状态,但它的功能是双重HDAC/EGFR抑制剂。45 CUDC-101的通路注意力特征准确地反映了这种双重机制,在HDAC和EGFR通路中都有很高的排名(图5e)。这一案例证明了BioGDR通过其药物背景指导的分层生物网络分析揭示复杂药物机制的复杂能力。
药物的反应在不同的细胞环境中可以有很大的不同,即细胞系的不同分子状态。传统的单基因标记,如靶基因表达,往往无法捕捉到这些复杂的、不同种类的模式--特别是对于具有多个MOA的化合物。为了评估BioGDR是否能更好地模拟这种异质性,我们分析了多目标化合物CUDC-101在不同细胞系中的路径注意力得分的变化,并将它们与其已知目标EGFR、ERBB2和HDACs的表达水平进行了比较(图5F)。BioGDR推断的途径激活状态在癌症类型中显示出不同的簇,其中一些(例如簇2和簇5)在敏感细胞系中丰富,而其靶标的基因表达没有显示出有意义的分层。这些结果表明,BioGDR通过以下方式更有效地捕获特定于上下文的药物机制模拟通路水平的活动,使不同种群中敏感和耐药的细胞状态之间的区分得到改善。
实验场景中的实践性评估
为了评估BioGDR在药物发现中的翻译潜力,我们使用新型ALDH1B1抑制剂高尔基体A-2进行了前瞻性验证研究(补充图10)。尽管在我们的初步研究中确认了靶向参与,但对该化合物的作用机制和治疗应用的全面表征需要在不同的细胞环境中进行系统评估。虽然传统的方法主要利用靶基因表达来选择细胞系,但46种这样的单基因生物标记物未能捕捉到药物反应背后复杂的转录网络。这一限制强调了迫切需要先进的系统级预测工具来提高筛查效率。利用BioGDR,我们在1153个CCLE细胞系中进行了对高尔基剂A-2'S药效的全面分析,确定结直肠癌细胞系T84(排名第46位,商业可用,独立于训练数据)以及另外八个代表ALDH1B1相关恶性肿瘤(结直肠癌/胰腺癌;补充图11和补充表20)的细胞株是有前途的候选细胞系。
对比分析表明,BioGDR通过其生物信息嵌入空间具有优越的泛化能力(图6A)。虽然原始基因表达谱显示了新细胞状态的有限分布重叠,但BioGDR的习得嵌入有效地弥合了这一差距,使可见和不可见细胞系中的预测敏感群体能够一致地聚集在一起。实验验证证实了T84的预测准确性(预测AUC:0.289对实验:0.288;完整的预测结果见附加表21-22;IC50=1.09μM,详细的实验数据如图6B和补充图1214所示)。对所有测试细胞系的综合评估显示,BioGDR的表现明显更强与两种基线模型和单独的ALDH1B1表达相比,预测和观察的敏感性排名之间的相关性(图6C和补充表21)。值得注意的是,虽然靶基因的表达传统上被认为是药物敏感性的一般标志,46ALDH1B1的表达--高尔基剂A-2的靶标--显示出可以忽略的预测能力,在泛癌背景下没有显示出显著的相关性,在结直肠癌中只显示出微弱的相关性。其他基线模型,尽管包含了完整的转录转录特征,但仅显示出适度的预测性能,甚至产生了与结直肠癌细胞系中ALDH1B1表达水平相当的结果。
为阐明 BioGDR 能否有效捕获药物内在作用机制(MOA),本研究针对靶点 ALDH1B1,从基因、通路两个层级全面解析模型的注意力权重分布模式。 在基因层面,BioGDR 展现出优异的靶点识别能力:针对药物高尔基体抑制剂 A-2(Golgicide A-2),ALDH1B1 基因的平均注意力分位排名(R%)超过 PRISM 数据集中 95% 的药物,证实模型具备精准的药效预测能力(见图 6D)。 在通路层面,模型对包含 ALDH1B1 的精氨酸与脯氨酸代谢通路赋予更高注意力权重(见图 6E),这一结果与已发表结论一致:ALDH1B1 是调控代谢稳态的关键线粒体酶⁴⁸。
耐人寻味的是,在这个途径中,BioGDR的分析揭示了一个比简单的目标识别更微妙的视角。它不仅强调了ALDH1B1,还强调了其他几个基因的重要性,包括CKMT1A、P4HA3和NAG,所有这些基因都已被独立验证为肿瘤发生和癌症进展的关键角色49-51(图6F)。这些发现突显了BioGDR不仅识别直接药物靶点,而且还绘制出管理药物敏感性的更广泛的机制网络的复杂能力。此外,BioGDR还发现了ALDH1B1调节的其他具有重要功能意义的通路,包括"RIG I样受体信号通路"(与抗病毒免疫反应52有关)和"Noch信号通路"(在结直肠肿瘤发生中至关重要53)。这一全面的途径分析为该化合物的抗肿瘤疗效提供了机制上的见解,并表明ALDH1B1抑制可能具有超出其传统代谢功能的治疗意义。
总的来说,这些发现展示了BioGDR在解决早期药物开发中的两个关键挑战方面的非凡能力:(1)识别超越传统单基因的敏感细胞模型生物标记物的限制,以及(2)新化合物作用机制(MOA)的阐明。通过在生物知情的注意框架中嵌入转录数据的创新方法,BioGDR实现了双重目标-提供高精度的预测,同时揭示上下文相关的行动机制。这一全面的功能使BioGDR成为高通量药物筛选活动和深入机制研究的宝贵工具,代表着计算药物发现方面的重大进步。
临床应用的真实评估
精准肿瘤学领域的一大核心难题是精准预判临床治疗应答效果,而这是制定高效个体化治疗方案的关键前提⁵⁴。为验证 BioGDR 的临床应用价值,本研究依托癌症基因组图谱(TCGA)临床数据集开展外部独立验证⁵⁵。 模型展现出稳健的预测性能,在区分药物敏感与耐药患者时取得更优的受试者工作特征曲线下面积(AUROC)数值(见图 7A、补充表 23)。值得注意的是,多西他赛等药物的预测存在特殊难点:耐药患者样本队列规模偏小,且既往治疗会诱导肿瘤产生分子层面适应性改变,这也凸显了构建临床药物应答预测模型本身具备极高的复杂程度。
为了全面评估BioGDR的临床适用性,我们进行了一项深入的案例研究,重点是奥沙利铂对结直肠癌患者的疗效预测。奥沙利铂虽然是结直肠癌治疗的基石化疗药物,但在患者的反应中表现出相当大的变异性,这对治疗优化构成了重大挑战。56先前的研究表明,CDK5的表达是转移性结直肠癌对奥沙利铂敏感性的潜在生物标志物。然而,对TCGA Oxaliplatin-Coad队列的分析表明,CDK5的单独表达不能有效地对患者的反应进行分层,57可能是由于更广泛的患者群体中固有的复杂的分子异质性。我们的生存分析也证实了这一点,该分析显示按CDK5表达中值水平分层的患者组之间没有统计学上的显著差异(图7B)。值得注意的是,BioGDR显示了卓越的预测能力,成功地识别了生存结果显著不同的患者亚组(图7C)。这一成就突显了BioGDR捕获和整合生物网络中复杂的多基因相互作用的复杂能力,从而超越了传统单基因生物标记物方法的固有限制。
这些全面的发现表明,BioGDR通过其强大的、知识驱动的药物反应预测,在理论建模和现实世界临床应用之间弥合差距方面具有巨大的潜力。BioGDR成功地整合到临床实践中,可以通过实现更准确的治疗选择和改善患者分层来促进精确肿瘤学。随着人工智能驱动的方法继续发展,像这样的模型BioGDR有望成为临床决策支持系统中的重要工具,最终促进针对个别肿瘤分子特征优化的个性化治疗策略的开发。
讨论
目前的药物敏感性预测方法面临两个重大挑战:第一,缺乏具有良好注释的结构多样化的化合物,第二,高维组学数据的复杂性,以及现有计算方法有限的机械洞察力。为了克服这些限制,我们提出了BioGDR,这是一个无缝集成多个组成部分的多模式框架:预测的生物学特征(包括差异表达和激酶抑制曲线)、已建立的生物学知识(包括途径信息和蛋白质-蛋白质相互作用),以及复杂的药物引导注意策略,以在特定情景下模拟药物与细胞的相互作用。这种以生物为中心的架构设计不仅提高了预测的准确性,而且通过阐明驱动药物反应的关键基因和途径提供了可解释性。
BioGDR在各种具有挑战性的场景中进行了全面的评估,包括与早期药物发现相关的新药化合物和代表精确医学的不同细胞环境。前瞻性实验验证和临床患者队列分析进一步证明了该方法的实用性和推广能力。该模型在多个维度上表现出普适性:分子结构多样性、细胞异质性和翻译应用。尤其重要的是,在现实世界的实验验证中,BioGDR在识别ALDH1B1抑制剂高尔基体A-2的敏感细胞系方面表现出了高度的准确性,同时其路径水平的注意机制成功地突出了与ALDH1B1功能相关的生物相关信号网络。这些发现证明了BioGDR的双重能力,既是一个强大的药物敏感性预测工具,又是一个机械洞察的可解释工具,有效地弥合了计算预测和实验验证之间的传统鸿沟。尽管取得了这些有希望的进展,BioGDR仍面临着几个值得进一步研究的局限性。主要的挑战在于它从化学结构预测生物特征(DE和KI)。实验测量的DE和KI图谱的稀缺性和稀疏性限制了将这些生物特征固定在高通量分析中的机会,尽管未来大规模扰动和生物活性数据集的可获得性可能有助于缓解这一限制,并使化学结构和下游细胞反应之间能够更紧密地耦合。
此外,DE和KI特征的独立预测潜在地限制了该模型捕捉不同模式之间的协同关系的能力。这种独立性可能会导致特征表示的不一致,并影响模型在不同数据集上的泛化能力。为了解决这一局限,可以整合跨模式注意、58对比学习、59和共享潜在空间学习60、61等新兴方法,以便在化学、结构和生物信息之间建立更连贯的联系。第二个显着的限制来自BioGDR对现有生物学知识库的依赖。虽然这一基础增强了特征提取能力,但由于当前生物数据库的不完全性质,它固有地引入了偏差。尽管知识图谱和路径数据库覆盖范围很广,但它们可能并不完全涵盖所有现实世界的生物相互作用。然而,这一限制提供了通过集成新出现的高吞吐量数据源进行改进的机会。特别是,快速扩展的单细胞转录学和功能基因组学领域提供了增强这些表示法的有希望的途径,潜在地使捕获更复杂的细胞状态并最终提高预测准确性成为可能。37展望未来,我们的研究将优先加强多模式数据表示法的集成,以更好地理解药物敏感性的分子机制。我们的目标是改进BioGDR的架构和特征融合方法,以实现跨不同生物背景和数据类型的更可靠的预测。通过整合新的高通量实验数据和优化的深度学习方法,我们预计BioGDR将有助于弥合计算预测和临床实践之间的差距,为肿瘤学中更精确和个性化的治疗策略做出贡献。
方法
药物敏感数据
在这项研究中,我们使用PRISM数据集62,并将药物敏感性预测作为一个回归问题。AUC作为连续预测目标值,值越小,药物敏感性越高。在这个数据集中,由于不同批次的不同,一些药物具有相同的名称但不同的药物ID。对于这种情况,我们保留了根据数据库建议被认为更可靠的批次的药物测试记录。在没有批次推荐的情况下,我们使用较大的数据量对药物测试记录进行优先排序。经过数据的预处理和清理,最终的数据集包括611295个药物-细胞系对,涉及1447个化合物和476个细胞系。
分子和化合物数据
细胞系基础基因表达数据取自癌症细胞系百科(CCLE)数据库⁶³,⁶⁴;目前 CCLE 数据库已并入 DepMap 项目。本研究采用 DepMap 22Q1 版本的 RNA 测序(RNA-Seq)数据,仅保留蛋白编码基因,表达量统一采用log2(TPM+1)标准化格式。 通路信息源自京都基因与基因组百科(KEGG)数据库⁶⁵,并从分子特征数据库(MSigDB)下载获取⁶⁶。BioGDR 选用 MSigDB 中 C2 层级 CP 分类下的 KEGG_LEGACY 子集;最终筛选得到 186 条 KEGG 通路,包含 5201 个同时存在于 KEGG 通路数据与 CCLE 表达数据中的独特基因。 基因间互作(PPI)关系取自 STRING 数据库 11.5 版本⁶⁷,仅将互作评分>700 的相互作用判定为可靠互作。基于前述筛选基因对 PPI 连接关系做二次过滤,确保每条互作连线的两端基因均属于筛选基因集,最终得到 39679 组可靠蛋白互作连接。
PRISM数据库提供化合物的SMILE,没有SMILE的化合物的结构信息从PubChem.68获得。化合物的化学结构特征如补充表11所示,并用作分子GNN,AttentiveFP.25的输入。根据化学结构信息预测DE和KI特征。DE特征,包括978个标志性基因在药物治疗后的表达变化,是由TranSiGen生成的,22这是一个采用自我监督表征学习的深度生成模型。TranSiGen分析基础细胞基因表达和分子结构,以准确重建化学诱导的转录本。这种自监督方法有效地降低了噪声,并揭示了潜在的扰动信号。我们从不同的组织来源中选择了数据量最大的7个主要细胞系来代表不同组织中的药物行为(补充表2)。所有这些特征的形状和类型对于每种药物都保持一致。KinomeMETA,23,24预测了KI的特征,包括527个人类野生型和突变型KI的抑制概率。KinomeMETA是一个通过元学习过程开发的预测框架,为数据有限的未被研究的激酶提供了更高的准确性。进一步补充信息部分B.1提供了实施细节。
BioGDR模型体系结构和总体框架
BioGDR 融合多模态数据,构建药物与细胞的联合表征,用于药物应答预测。在该框架中,一个模态指代输入模型的一类独立信息源。
- 药物端:纳入三类互补模态 ------ 分子结构、预测得到的药物诱导差异基因表达谱(DE)、预测激酶抑制谱(KI),每类模态均配备专属特征提取器完成编码。
- 细胞端:基础转录组图谱作为细胞模态输入,经由通路先验图网络处理,生成具备生物学层级结构的细胞表征。
每一类药物模态均通过独立编码器完成表征与运算:
- 分子结构转化为分子图结构,由图神经网络编码;
- 预测 DE 向量作为基因水平特征标识,依托蛋白互作(PPI)先验图注意力网络编码;
- 预测 KI 谱转化为激酶概率向量,经由前馈神经网络编码。
各模态生成独有嵌入向量后,全部映射至同一隐空间,通过拼接融合得到统一药物表征,供给下游药物引导注意力(DGA)模块与预测模块使用。
多模态药物模块
药物模块(图1A)包括三个特征编码器,每个特征编码器提取与化学信息、基因表达扰动和激酶抑制相关的特征。具体地说,使用图形神经网络AttentiveFP.25提取化学信息特征。与传统的分子描述符和指纹不同,AttentiveFP将分子抽象为由代表原子的节点和代表键的边组成的分子图,直接输入整个分子结构(补充表1)。AttentiveFP的优势在于它在全局和局部两个层面上的双重注意机制,动态地关注任务中最相关的信息。为了在推断时生成生物丰富的药物表示而不需要新的实验测量,BioGDR结合了两个预先训练的预测器-用于药物诱导的差异表达(DE)签名的TranSiGen和KinomeMETA,以了解激酶抑制(KI)的概况。这两种模型都以分子结构为输入,在BioGDR内以冻结状态使用,提供固定的DE和KI模式,补充药物分支中的结构编码器。下面提供了这些预先培训的组件的详细说明。TranSiGen仅使用化学结构预测药物诱导的转录干扰。它是在Lincs程序的大规模L1000轮廓上进行训练的,其中每个化合物都表示为分子图,并由图神经网络编码器映射到潜在嵌入中。然后,多基因解码器为标志性基因产生差异表达(DE)签名,协同表达感知调节鼓励协调转录反应,而不是独立的基因输出。目前的TRANSiGen实施没有明确编码剂量或曝光时间;相反,它是在标准化条件下生成的LINCS L1000微扰曲线上进行训练的--主要是24小时的10μM复合处理--因此学习与这些固定实验设置对应的规范DE响应。TranSiGen为七个Lincs细胞株提供预测的扰动特征,并提供广泛的转录图谱支持-A375、HA1E、HeLa、HT29、MCF7、PC3和YAPC-这些特征构成了可用于下游建模的DE特征(补充表2)。七个细胞系的选择反映了生物多样性和预测可靠性之间的平衡。虽然公共数据集中存在数百个细胞系,但只有很小的子集在LINCS中具有足够的扰动覆盖范围,从而使TranSiGen能够准确预测DE。使用太多稀疏轮廓的细胞系会增加噪音而不是好处,而限制在一个小的、特征良好的集合会产生更稳定和更有生物学意义的DE特征。相比之下,KinomeMETA通过预测一大批野生型和突变的人类激酶的激酶抑制概率,提供了一种机械性的模式。它接受了60多万种生化分析测量的培训,涵盖了大约16万种化合物和600多种激酶。该模型采用了元学习设计,其中每个激酶都被视为单独的预测任务。基于AttentiveFP的共享分子编码器学习跨任务表示法,捕捉与激酶抑制相关的化学模式,而特定于任务的碱基学习器快速适应每个激酶的抑制情况,即使是特征稀少的激酶也能进行准确预测。在训练过程中,KinomeMETA使用可信的负采样和任务正则化优化来减少假阳性噪声和在KEK数据集中常见的不平衡。BioGDR使用称为DE-GAT的图形注意网络(GAT)来提取DE中嵌入的信息功能。边缘,例如基因之间的连接,是基于蛋白质-蛋白质相互作用的。每个节点的输入特征向量代表了药物治疗后基因在7个细胞系中的表达变化。利用KI-DNN提取每种药物的KI特征。这是一个经典的DNN结构,其中的输入是这些化合物对527个人类野生型和突变的激酶的预测抑制概率。重要的是,DE和KI预测器都是以冻结的方式使用的,它们的输出被视为固定的输入特征,在BioGDR训练期间没有任何微调。
最终,三类特征经由线性层统一映射至 512 维向量空间,再通过向量拼接融合得到药物融合表征。该融合药物表征分两路送入深度神经网络(DNN)运算:一路生成供给预测模块使用的药物特征;另一路经由另一组 DNN 计算,得到适配药物引导注意力(DGA)机制的药物导向表征。
层级化生物细胞模块
BioGDR 将每条通路视作一张小型图结构,命名为通路子图(pathway subgraph)(见图 1B)。通路子图的节点代表基因,节点间的连线对应基因编码蛋白之间的相互作用关系。由于模型采用转录组数据作为细胞的组学特征,每个节点的初始输入特征即为对应基因的表达量。
每条通路子图的基础网络结构为图注意力网络(GAT),记为 pathway-GAT。基因信息先经由 pathway-GAT 在通路内部完成信息传播,每个基因节点被更新为一维隐特征;随后拼接所有节点特征,生成通路层级向量(向量维度等于该通路包含的基因总数)。
通路向量与药物导向特征共同输入药物引导注意力(DGA)模块,为每个基因分配注意力权重。对基因级隐特征做加权求和,得到一维通路表征,作为原始通路层级特征。该表征再结合药物导向特征送入注意力模块,计算得到适配当前药物环境的细胞专属表征;该表征最终作为细胞嵌入向量供给预测模块使用。
生成特定于上下文的单元格表示的DGA策略
DGA策略10(图1C)模拟了化合物在基因和途径水平上作用于细胞的过程,从而促进了特定于上下文的细胞表示的产生。在该模块中,药物特征向量充当查询向量D(类似于标准尺度点积注意中的Q)。基因和途径特征在这个模块中起着关键和价值载体的作用。为了清楚起见,我们将基因水平的特征表示为G,将路径水平的特征表示为P,分别对应于K和V的角色。查询和关键字向量被串联并馈入前馈网络以计算关注度分数。具体地说,在基因水平上,基因特征为Gk={gi1,gi2,...每个途径的GIK}--其中维度等于该途径中的基因数目--通过途径-GAT来提取。每个基因向量与药物特征向量D(32维)连接,计算基因水平的注意分数,反映每个基因在其途径中的重要性。基因注意分数和路径激活分数计算如下:


上下文感知分子表示向量。
预测模块
预测模块接收两组输入:药物模块生成的药物表征、细胞模块输出的药物环境特异性细胞表征(见图 1D)。将这两组向量拼接后送入前馈神经网络,网络输出单一标量数值,代表该药物 - 细胞配对的预测药物敏感性(AUC 值)。模型训练过程以最小化预测 AUC 与实测 AUC 之间的均方误差(MSE)为优化目标。
数据划分
对于随机分裂评估,PRISM数据集以8:1:1的比例被划分为非重叠的训练、验证和测试集,并在每次重复中重新洗牌药物-细胞对。我们进一步评估了两个实际相关场景中的模型泛化。在看不见的药物环境中,对应于新化合物的筛选,模型预测了先前未测试的药物在已知细胞系上的敏感性。在看不见的细胞环境中,对应于精确肿瘤学和药物再利用应用,模型推断了已知药物对新细胞环境的敏感性,而在培训期间没有药物反应测量。在这两种情况下,要么完全坚持药物,要么完全坚持细胞系,剩余的数据按8:1:1的比例被分成训练、验证和测试集,再次在五个随机种子上重复。为了更严格地评估化学或生物差异下的稳健性,我们还进行了10倍相似性控制的盲交叉验证,应用于BioGDR和三个最强的多模式基线(CSG2A、DTLCDR和Candela)。构建药物折叠使得测试化合物与任何训练化合物没有ECFP 4田本相似性≥0.7,并且构建细胞折叠使得测试细胞系与训练细胞系没有基础表达余弦相似性≥0.97(考虑到癌细胞系之间的高内在相似性,降低阈值是不可行的)。每个相似性定义的簇作为测试折叠一次,八个折叠用于训练,一个用于验证。
超参数调整
我们通过对PRISM数据集的5个重复随机8:1:1分裂进行小规模网格搜索,微调了BioGDR的超参数。对于每个候选配置,模型都在训练拆分上进行了训练,验证拆分专门用于选择,而测试拆分在调整过程中从未访问过。最终的超参数是根据五次重复的平均验证性能选择的,补充表4提供了完整的搜索空间和选定的值。
消融实验
BioGDR 的核心设计思路为:融合三类来源的药物特征、纳入两类生物学先验知识,并建模药物与细胞之间的交互关系。为量化各模块的贡献度,本研究通过剔除五类信息以及 DGA 交互机制,构建了一系列消融实验变体模型。
一、药物端消融实验
遍历分子结构(Structure)、差异表达(DE)、激酶抑制(KI)三类特征的全部组合形式,包含两两组合、单特征独立使用两种情形:
- w/o Structure 模型:移除提取化学结构特征的 AttentiveFP 编码器,输入不再包含分子结构信息;
- w/o DE 模型:移除 DE-GAT 模块,剔除药物诱导差异表达谱的特征贡献;
- w/o KI 模型:移除整合激酶抑制信息的 KI-DNN 模块; 当移除某一药物特征编码器时,对应特征会直接从模型输入中删除。 额外单独搭建了仅结构、仅 DE、仅 KI 三组基准单特征模型。
二、细胞端消融实验
为评估生物学先验知识与 DGA 交互机制的影响,对细胞模块做多重结构修改:
- w/o Pathway 模型:删除通路拓扑结构,基因间仅依靠蛋白互作(PPI)建立连接;
- w/o True-PPI 模型:对每条通路内部的 PPI 连线做随机重连处理,模型无法利用真实生物邻近关系,但保留通路整体框架;
- w/o Graph 模型:移除全部图结构,pathway-GAT 编码器替换为全连接网络,同时舍弃通路、PPI 两类先验;
- w/o DGA 模型:删除药 - 细胞交互调控机制,仅使用原生细胞特征,无药物导向的特征调制。
AML数据集的评估
AML药物敏感性数据集来自文献,39为中国AML患者提供了全面的组学资源。它包括在56名患者的原发肿瘤细胞上测试的77种临床相关化合物的药物敏感性数据。这些化合物的微笑来自PubChem.68基于基因表达谱和化合物结构信息的可用性,最终的AML数据集包括75种化合物和50个原发AML患者来源的细胞的数据,总计3737条敏感性记录。在这些药物中,56种药物被纳入PRISM数据库,19种被认为是未知药物。
癌症基因组图谱(TCGA)临床数据集评估
临床药物敏感性数据集取自癌症基因组图谱(TCGA)项目⁵⁵。利用 R 包 TCGABiolinks 提取患者基因表达谱数据⁶⁹;临床生存终点、用药记录、药物疗效敏感性信息均从已发表文献中整理汇总得到⁷⁰,⁷¹。
结合临床实际应用场景与不同癌种间的异质性特征,本研究按照用药方案、癌症类型 两个维度对患者分组,以此检验模型能否在具备临床意义的患者队列中区分药物敏感程度差异。为保障统计结果稳健可靠,仅保留总样本量≥30、且敏感 / 耐药分组各自至少包含 3 例样本的「药物 - 癌种」组合,构建可信评估子集。 对全部临床记录完成匹配与清洗后,最终数据集包含 792 条用药记录,覆盖 578 名患者、11 种药物。参照既往研究标准⁷²:将疗效标注为完全缓解(Complete Response)、部分缓解(Partial Response) 的患者划为药物敏感样本;将**疾病稳定(Stable Disease)、疾病进展(Clinical Progressive Disease)**划为耐药样本。接受联合化疗的患者,拆分至对应单药下分别评估。 由于模型预测值与二分类敏感标签存在数值分布差异,本研究采用 AUROC 指标衡量模型对患者药物敏感性的排序区分能力。
重要的是,TCGA评估是一项严格的零射击测试。BioGDR专门针对PRISM进行培训。不使用患者级别的样本、标签或归一化程序进行培训或微调。在推断时,该模型仅接收原始患者转录组和药物结构。
用于机理分析的靶基因注释和定位
机制分析所用的药物 - 靶点注释信息取自 PRISM 重定位数据集,该数据集为部分化合物提供了经过人工整理验证的靶点信息。利用这些注释信息,可检验 BioGDR 在基因、通路层级的注意力分值是否匹配已知的生物作用机制。
对于 BioGDR 模型,细胞端注意力仅限定在通路层级基因集内,该基因集包含 5201 个同时出现在 KEGG 通路、且通过筛选后的 STRING 蛋白互作(PPI)网络建立关联的基因。研究将所有已注释靶点映射至这套通路 - PPI 基因集;若某化合物的全部靶点均不在该基因集范围内,则剔除该化合物。仅保留至少存在 1 个可映射靶点基因的药物,用于后续基因与通路层级注意力分析。该筛选流程保证所有机制解读均依托于 BioGDR 细胞模块中实际纳入建模的基因。
化合物与细胞培养
化合物高尔基体抑制剂 A-2 购自美国新泽西州蒙茅斯章克申的 MedChemExpress 公司。本研究使用的 HCT116、LS513、SW480、T84、BXPC3、HPAFII、MIA PaCa-2、Panc 0813 以及 PANC-1 细胞系均购自武汉普诺赛生命科技有限公司。HCT116 细胞采用 McCoy's 5A 培养基(BasalMedia,货号 L630KJ)培养。LS513、BXPC3 和 Panc 0813 细胞使用 RPMI-1640 培养基(BasalMedia,货号 L210KJ)培养。SW480 细胞采用 Leibovitz's L-15 培养基(BasalMedia,货号 L620KJ)培养。T84 细胞使用 DMEM/F12 培养基(BasalMedia,货号 L320KJ)培养。HPAFII 细胞采用 ATCC 改良型 MEM 培养基(BasalMedia,货号 L540KJ)培养。MIA PaCa-2 与 PANC-1 细胞使用 DMEM 培养基(BasalMedia,货号 L110KJ)培养。所有培养基均添加 100 单位 / 毫升青霉素、0.1 毫克 / 毫升链霉素(美伦生物,货号 PWL062)以及体积分数 10% 胎牛血清(美伦生物,货号 WL001)。Panc 0813 细胞的培养基额外添加 10 微克 / 毫升胰岛素。SW480 细胞置于 37℃常压空气环境下培养,其余细胞系均在 37℃、体积分数 5% 二氧化碳氛围中培养。所有细胞的最大传代次数均不超过 15 代。
细胞系的鉴定
为了验证我们研究中使用的所有细胞系的身份,我们通过北京清科生物科技有限公司在STR图谱结果中,所有细胞系与各自的参考图谱显示至少90%的符合率,这被广泛认为是确认细胞系真实性的阈值73。STR分析结果已在补充表20中提供。
支原体检测
用MyColor一步支原体检测仪(Vazyme,D201-01)评价细胞培养物中的支原体污染。在反应预混料中加入等量的1μL培养上清液,在65℃恒温孵育1h,通过观察比色变化来确定结果。从红色到黄色的转变表明支原体的存在,而没有污染的情况反映在没有明显的颜色变化上。我们的测试结果表明,本研究中使用的所有细胞系的支原体污染都是阴性的(见补充图11)。
细胞增殖实验
将肿瘤细胞接种于 96 孔细胞培养板(诺唯赞,货号 CCP01096-B),每孔接种约 1000 个细胞,37℃条件下过夜培养。测定半数抑制浓度(IC₅₀)时,加入终浓度介于 19 纳摩尔至 50 微摩尔区间的化合物。药物处理 7 天后⁴⁷,向每孔中加入 20 微升 CellTiter-Meiluncell 发光型细胞活力检测试剂(美伦生物,货号 PWL111)评估细胞活力。将培养板置于室温轻柔振荡孵育 10 分钟,采用帝肯 Spark 多功能酶标仪检测发光强度。细胞活力以二甲基亚砜(DMSO)处理对照组为基准归一化,以相对于 DMSO 对照组的百分比数值表示。使用 GraphPad Prism 软件(9.5.0 版本),依据参考文献⁶² 记载的公式,通过可变斜率非线性回归曲线拟合(四参数模型)计算化合物的 IC₅₀与曲线下面积(AUC)数值。
为了评估细胞增殖率,将化合物添加到4μM的最终浓度,而等量的二甲基亚砜作为载体对照。温和混合后,将平板在37℃下孵育,从复合处理后的第1天到第7天,每天在相应的时间点定量检测细胞活力。细胞存活率检测如IC₅₀测定部分所述。第一天的细胞存活率被正常化为1,并且通过归一化各组第1天的存活率,计算第2至7天的相对存活率倍数变化。用GraphPad Prism软件(9.5.0版)绘制增殖率曲线,显示细胞活力随时间的变化。
细胞集落形成试验
取生长状态良好的细胞,经胰酶消化、离心后重悬于完全培养基。用全自动细胞计数仪计数,调整细胞密度至 5×10³ 个 / 毫升。向六孔板(诺唯赞,货号 CCP01006-B)每孔接种 2 毫升细胞悬液,轻柔混匀后过夜孵育。次日加入梯度稀释的化合物,轻晃培养板后放回培养箱连续培养 7 天,直至肉眼可见克隆形成。7 天后弃去培养基,无水甲醇固定细胞;每孔加入 1 毫升结晶紫染色液(碧云天,货号 C0121)染色 30 分钟。磷酸盐缓冲液小心漂去多余染液,晾干培养板后拍照采集图像。