一、变量问题:扣子工作流崩溃的第一大元凶
如果你在扣子社区里翻翻求助帖,会发现一个规律:
"为什么我的工作流报错?"
"变量取不到值怎么办?"
"明明上游有数据,下游节点为什么收到的是空?"
根源几乎都指向同一个东西:变量传递出了问题。
扣子工作流的可视化编排降低了入门门槛,但也掩盖了一个事实------节点之间的数据流动,本质上是一套完整的变量体系。不理解这套体系,你的工作流永远在「碰运气」。
本文的目标:一次性讲透扣子工作流的变量体系,让你从此告别「变量地狱」。
二、变量的三个核心概念
2.1 变量的来源:谁生成了这个变量
扣子工作流中,变量的来源只有两种:
| 来源 | 说明 | 示例 |
|---|---|---|
| 输入变量 | 工作流启动时从外部传入 | 用户输入的文本、Bot 传入的参数 |
| 节点输出变量 | 每个节点执行完毕后产出的数据 | LLM 节点输出的 output、HTTP 节点的 body |
注意:没有任何变量是凭空出现的。 如果你在某个节点里引用了一个「感觉应该存在」但实际不存在的变量,必报错。
2.2 变量的作用域:谁能访问这个变量
这是扣子工作流变量体系中最核心、也最容易被误解的概念。
扣子工作流的变量作用域分为两级:
工作流级变量:在整个工作流的所有节点中都可以访问。通常在「开始节点」或「变量赋值节点」中定义。
节点级变量:仅在该节点及其下游节点中可访问。每个节点的输出变量默认都是节点级。
关键规则:上游节点的输出变量可以被下游节点引用,但不能被上游节点引用。
举个容易犯错的例子:
节点A(LLM)→ 输出变量 output_A
节点B(代码)→ 引用了 output_A ✅ 正确
节点C(HTTP)→ 想引用 output_A,但 C 在 A 的上游 ❌ 报错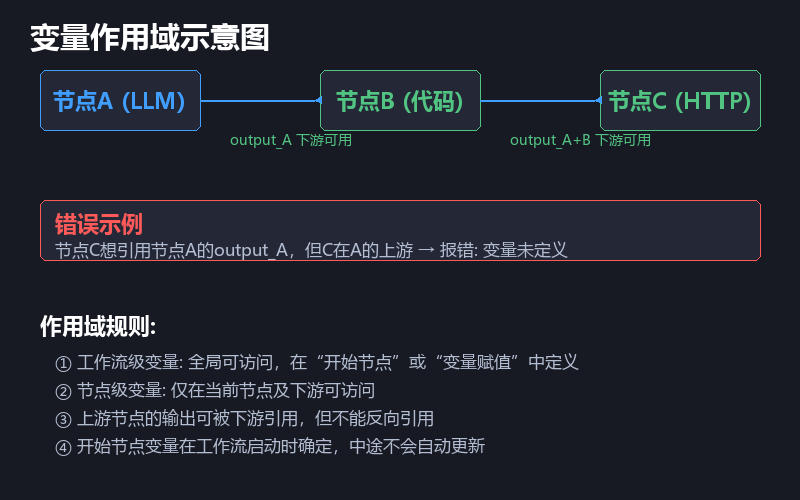
2.3 变量的数据类型
扣子工作流中常见的变量类型有:
| 类型 | 说明 | 常见来源 | 典型问题 |
|---|---|---|---|
| String | 字符串 | LLM 输出、API 返回的文本 | 需要数字时没转换 |
| Number | 数字 | 代码节点计算、API 返回数值 | 需要字符串时没转换 |
| Array | 数组 | JSON 解析、循环节点 | 不能直接传给期望字符串的节点 |
| Object | 对象/字典 | JSON 解析 | 需要用 .字段名 提取子字段 |
| Boolean | 布尔值 | 条件判断 | 在条件表达式里比较时容易出错 |
| null/undefined | 空值 | 上游未输出、API 返回空 | 下游直接引用导致报错 |
三、五个最常见的变量错误及修复
错误 1:下游取不到上游的值
场景:工作流报错「变量 xxx 未定义」
根因:99% 的情况是作用域问题。你在节点 B 里引用了节点 A 的输出,但 B 不在 A 的下游。
检测方法:在工作流画布中顺着连接线看,从变量生成的节点往下游追踪。
修复:重新调整节点顺序,确保「生产数据的节点」在「消费数据的节点」之前。
错误 2:类型不匹配
场景:代码节点报了 TypeError,或者 LLM 节点的 Prompt 没有正确渲染变量。
根因:你把数组传给了期望字符串的节点,或者把 Object 传给了需要 Number 的地方。
典型坑:HTTP 节点的 body 是 Object 类型。如果你直接把 body.xxx 传给代码节点,代码节点里需要 int() 或 str() 显式转换。
修复:在传递变量前,用「代码节点」或「类型转换节点」做显式类型转换。
# 推荐的防御性写法
def main(input_value):
# 安全转数字
try:
num = int(input_value)
except:
num = 0 # 兜底
# 安全转字符串
text = str(input_value) if input_value else ""
return {"num": num, "text": text}错误 3:循环内变量被覆盖
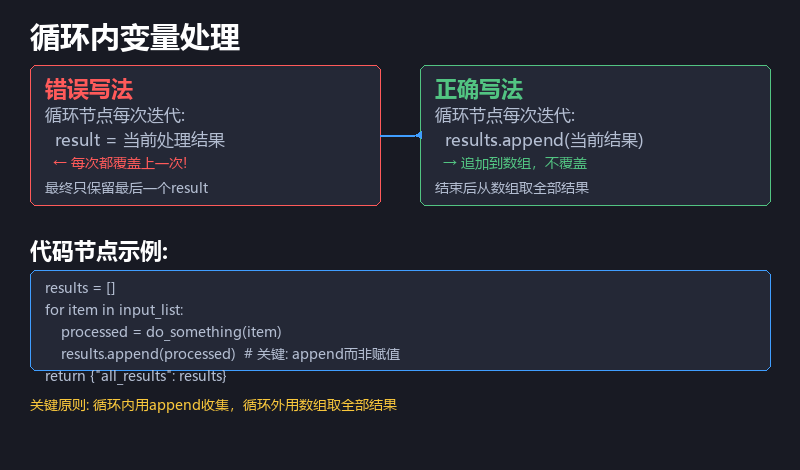
场景:循环节点里每次迭代,变量值都被下一次覆盖,最终只拿到最后一个值。
根因:在循环体内,每次迭代变量被重新赋值,如果不及时收集到数组里,只会保留最后一次的结果。
修复:循环体内的每一步处理结果,立即追加到一个「结果数组」变量中。循环结束后再从数组里取数据。
错误 4:JSON 解析后的嵌套字段取不到
场景:API 返回了复杂的 JSON,你用扣子的「JSON 解析」节点解析后,字段总是取不到。
根因:JSON 解析节点的输出是 Object 类型,嵌套字段需要用点号逐层访问:data.result.items0.name。
如果 API 返回的 JSON 结构不是你预期的(比如有时 result 是 Object,有时是 Array),解析就会失败。
修复:不要完全依赖扣子的 JSON 解析节点。用代码节点做解析,加 try/except 处理各种情况。
错误 5:开始节点变量全局可见,但不更新
场景:你在工作流中间某个节点修改了开始节点传入的变量值,以为后续节点会用到新值。
根因:开始节点的变量在工作流启动时就确定了,中途不会被自动更新。你不是在修改原变量,而是在创建一个同名的新的节点级变量。
修复:如果需要中途更新全局变量,用「变量赋值」节点显式赋值。养成习惯:开始节点变量只读不写。

四、变量调试三板斧
当你遇到变量相关的报错,按以下顺序排查:
第一斧:看日志
点击报错节点 → 查看「输入参数」→ 确认上游传过来的值到底是什么。很多时候你「以为」传了字符串,实际传的是 Object。
第二斧:加临时输出
在可疑节点后面加一个「输出」节点或「飞书通知」节点,把变量值打印出来。这是最快定位问题的方法。
第三斧:最小化复现
把工作流复制一份,删掉无关节点,只保留出问题的 2-3 个节点,用固定数据测试。问题隔离后,修复起来就快了。
五、变量管理最佳实践
5.1 命名规范
| 类型 | 命名建议 | 示例 |
|---|---|---|
| 输入变量 | input_xxx | input_keyword、input_url |
| 中间结果 | tmp_xxx | tmp_parsed_data、tmp_score |
| 最终输出 | result_xxx | result_summary、result_list |
| 配置常量 | config_xxx | config_api_url、config_max_retry |
用前缀区分变量的角色,三个月后回来看自己搭的工作流,一眼就能看懂。
5.2 变量赋值节点:被低估的神器
很多用户从不使用「变量赋值」节点,这是个巨大的浪费。
它的核心价值:在流程中显式地定义关键变量,而不是把所有变量都隐式地通过节点连接线传递。
建议用法:
- 在工作流关键节点后,用变量赋值把重要的中间结果存起来,起个清晰的名字
- 在条件分支合并前,用变量赋值统一变量名,避免不同分支的变量名不一致
5.3 代码节点:变量处理的万能钥匙
当你发现扣子自带节点处理变量不够灵活时,直接上代码节点。一个熟悉的 Python 环境,比任何可视化工具都可靠。
建议:把常用的变量处理逻辑封装成函数,做成代码片段的模板库。遇到变量问题时,从模板库里复制粘贴,改一下参数就能用。
六、变量问题排查清单
下次遇到变量报错,按这个清单过一遍:
变量定义的节点是在使用时节点的上游吗?
*
变量名拼写完全一致吗?(包括大小写和下划线)
*
变量类型和下游节点期望的类型一致吗?
*
如果是循环内变量,是否每次迭代都正确收集了?
*
如果是 JSON 字段,嵌套路径写对了吗?
*
开始节点变量是否被误当作可修改变量?
*
有没有用变量赋值节点显式定义关键变量?

七、总结
扣子工作流的变量体系,本质上就是一条数据流管线。理解了「数据从哪里来、怎么传递、给谁用」,90% 的变量问题都能迎刃而解。
三个核心原则:
- 先定位来源:任何时候变量报错,第一反应不是改配置,而是追溯这个变量的源头
- 显式优于隐式:多用变量赋值节点,少依赖隐式传递
- 防御式编程:每个接收变量的节点都做好空值和类型检查
变量不是扣子工作流的「附加知识」,而是基础中的基础。把这一课补上,你的工作流稳定性能提升一大截。
你在扣子工作流里遇到过最坑的变量问题是什么?评论区分享,帮大家避雷。
遇到问题可以让我来帮你解决:米核AI易山,全网同名。