摘要
本文介绍了逻辑回归的基本原理与应用。逻辑回归通过在线性回归基础上引入Sigmoid函数,将输出映射为概率值,用于解决二分类问题。文章阐述了其假设函数与损失函数,并通过乳腺癌预测案例展示了完整的建模流程。
Abstract
This article introduces the basic principles and applications of logistic regression. By introducing the Sigmoid function on top of linear regression, it maps outputs to probability values for binary classification. The article explains its hypothesis function and loss function, and demonstrates a complete modeling process through a breast cancer prediction case.
一.逻辑回归简介
逻辑回归是解决二分类问题的利器,如预测是否患有疾病、情感正负面的的分析、广告是否点击、银行是否放贷等。

其基本思想是利用模型根据特征的重要性计算出一个值,再使用sigmoid函数将f(x)的输出映射为概率值,例如设置阈值为0.6,输出概率大于0.6,则将未知样本输出为A类,否则输出为B类。
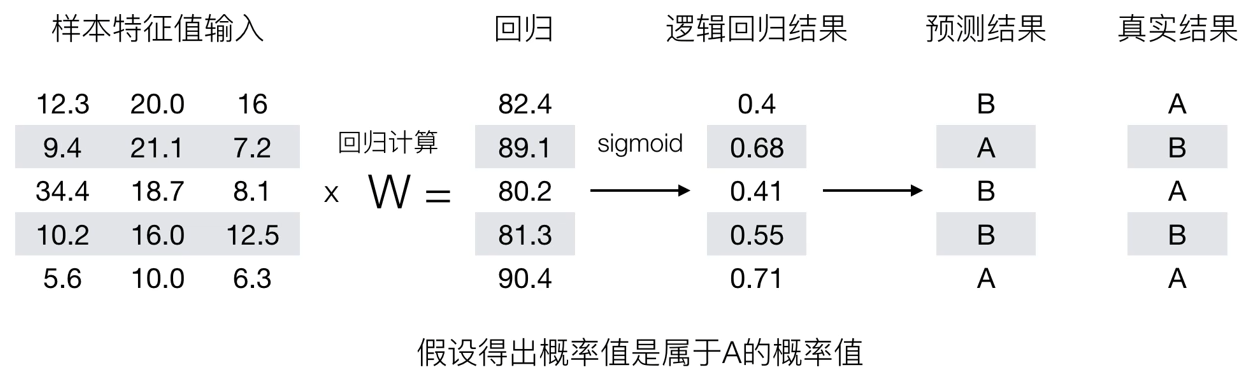
二.Sigmoid函数
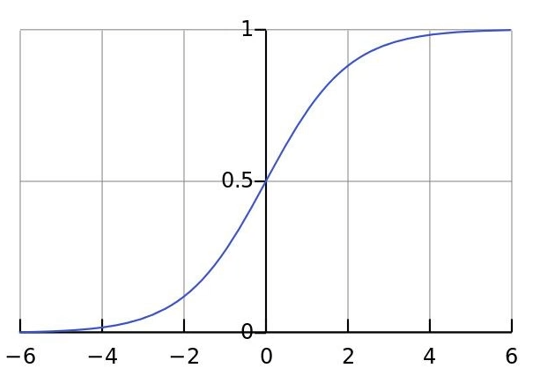
逻辑回归是在传统线性回归的基础上,引入了一个 Sigmoid函数(也称为Logistic函数)将线性输出映射为概率,函数公式如下:
其是将映射到(0,1)之间,单调递增,拐点为(0,0.5)的函数。
三.逻辑回归原理
1.假设函数
通过上面我们可以了解到逻辑回归是一种分类模型,将线性回归的输出,作为逻辑回归的输入,输出的值在(0,1)之间,所以逻辑回归的假设函数为:。
2.损失函数
逻辑回归的损失函数如下:
其中就是前面提到的h(w)逻辑回归的输出结果,其工作原理就是每个样本预测值有A、B两个类别,真实类别对应的位置,概率值越大越好。
所以逻辑回归的优缺点如下:
优点:模型简单、计算高效、输出具有概率含义、不易过拟合、可解释性强(能观察各特征对结果的影响权重)。
缺点:线性决策边界(仅能处理线性可分问题)、对特征独立性较敏感、在多分类时需扩展为Softmax回归。
四.逻辑回归API及简单案例
1.常用API
sklearn.linear_model import LogisticRegression(solver='liblinear', penalty='l2', C=1.0)
参数说明:
其中solver是损失函数优化方法,有三个方法可以选择,liblinear对于小数据集场景训练速度更快,sag和saga对于大数据集更快些。
Penalty表示正则化方法,前面优化方法中,sag和saga支持L2正则化或者没有正则化,liblinear和saga支持L1正则化。C表示正则化力度。
2.数据集说明
下面用到的数据集共699条样本,11列数据,第一列用于检索的id,后9列分别是与肿瘤相关的医学特征,最后一列表示肿瘤类型的数值(2表示良性,4表示恶性)。在数据中是有16个缺失值,用"?"标出。

3.完整代码实现
python
# 导包
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression # 逻辑回归模型
from sklearn.preprocessing import StandardScaler # 标准化
from sklearn.model_selection import train_test_split # 测试集训练集划分
from sklearn.metrics import accuracy_score # 模型评估
# 1.加载数据
data = pd.read_csv('./data/breast-cancer-wisconsin.csv')
# data.info() # 查看数据信息
# 2.数据预处理
# 2.1原数据有异常值?,则将?转成np.nan
# 参1:待替换的值,参2:替换的值
data.replace('?', np.nan, inplace=True) # 或者data = data.replace('?', np.nan)
# 2.2缺失值处理:删除
data.dropna(inplace=True) # axis=0表示行,1表示列,默认0
# data.info()
# 3.特征工程(特征提取,预处理)
# 3.1提取特征和标签
x = data.iloc[:, 1:-1] # :表示所有行,1:-1表示从第1列到倒数第2列(包左不包右)
y = data.iloc[:, -1] # 获取最后一列 或者 y = data.Class
# 3.2切割训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# 3.3特征工程:标准化
# 创建标准化对象
transfer = StandardScaler()
# 对训练集进行标准化 训练+标准化
x_train = transfer.fit_transform(x_train)
# 对测试集进行标准化
x_test = transfer.transform(x_test)
# 4.模型训练
# 4.1创建模型对象
estimator = LogisticRegression()
# 4.2模型训练
estimator.fit(x_train, y_train)
# 5.模型预测
y_pre = estimator.predict(x_test)
print(f'预测值前五个:{y_pre[:5]}')
# 6.模型评估
# 准去率,公式为:预测对的/样本总数
print(f'预测前评估,准确率:{estimator.score(x_test, y_test)}') # 测试集的特征和标签
print(f'预测后评估,准确率:{accuracy_score(y_test, y_pre)}') # 测试集的预测结果和标签运行后结果如下:
预测值前五个:2 4 4 2 2
预测前评估,准确率:0.9854014598540146
预测后评估,准确率:0.9854014598540146
但是这里我们要注意一下,准确率在某些情况下(如类别不平衡)不能全面反映模型性能。更科学的评估方法是使用混淆矩阵,可以进一步计算精确率、召回率、F1-score 等指标。
总结
本文系统讲解了逻辑回归的原理与实践。逻辑回归利用Sigmoid函数将线性输出转换为概率,采用交叉熵损失函数进行优化。通过乳腺癌预测案例,演示了从数据预处理到模型评估的完整流程。逻辑回归作为分类任务的基础算法,理解其原理对后续学习具有重要意义。