事务基础概念
❇️事务:保证我们多个数据库操作的原子性,多个操作要么都成功要么都不成功。
事务特性:ACID
♦️**A(Atomic)原子性:**构成事务的所有操作,要么都执行完成,要么全部不执行,不可能出现部分成功部分失败的情况。
♦️**C(Consistency)一致性:**在事务执行前后,数据库的一致性约束没有被破坏。比如:张三向李四转100元, 转账前和转账后的数据是正确状态这叫一致性,如果出现张三转出100元,李四账户没有增加100元这就出现了数 据错误,就没有达到一致性。
♦️I(Isolation)隔离性:数据库中的事务一般都是并发的,隔离性是指并发的两个事务的执行互不干扰,一个事 务不能看到其他事务运行过程的中间状态。通过配置事务隔离级别可以避脏读、重复读等问题。
♦️**D(Durability)持久性:**事务完成之后,该事务对数据的更改会被持久化到数据库,且不会被回滚。
分布式事务
随着互联化的蔓延,各种项目都逐渐向分布式服务做转换。如今微服务已经普遍存在,本地事务已经无法满足分布式的要求,由此分布式事务问题诞生。 分布式事务被称为世界性的难题,目前分布式事务存在两大理论依据:CAP定律 BASE理论(CAP、BASE定理)
分布式事务常用解决方案
两阶段提交(2PC)
2PC即两阶段提交协议,是将整个事务流程分为两个阶段,准备阶段(Prepare phase)、提交阶段(commit phase),2是指两个阶段,P是指准备阶段,C是指提交阶段。
这种方案类似于ZAB的一致性协议,在准备阶段进行事务投票,只要有任意一个议员不通过,即整体不通过
♦️**第一阶段:**事务管理器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交。
♦️**第二阶段:**事务管理器要求每个数据库提交数据。
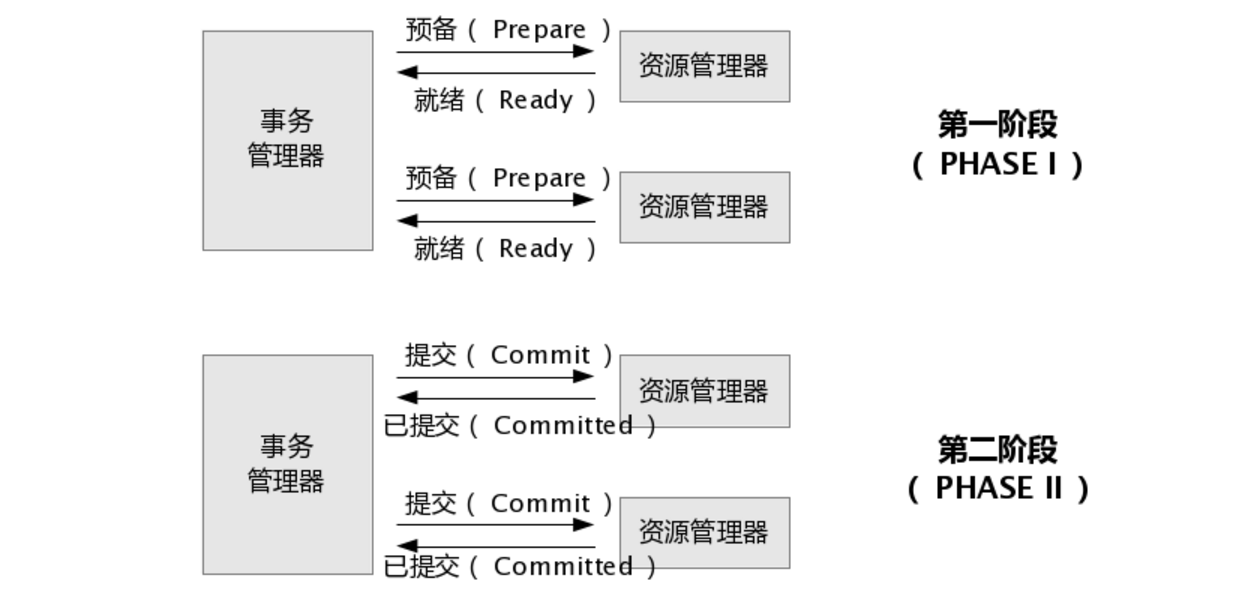
其中,如果有任何一个数据库在准备阶段否决此次提交,那么所有数据库都不会进行提交,且事务管理器会要求回滚它们在此事务中的那部分信息。
需要注意的是,2PC必须需要数据库具备2PC能力,本质就是能把一个事务拆成 "准备好但不提交" 和 "最后真正提交 / 回滚" 两步。
这是因为应用层只能调用SQL,无法控制数据库事务的中间状态(准备,但是不提交),这只能数据库内部来实现:
1、在准备阶段执行完之后,锁住资源来保证一致性、不提交、也不会滚
2、收到来自资源服务的prepare后,持久化记录这个事务状态,确保宕机事务的恢复
3、最终commit/rollback后完成数据库的提交或者回滚
❇️ 评估
目前MySQL、Oracle、PostgreSQL、SQL Server 这些主流数据库,都是通过XA事务协议来实现2PC能力。
基于XA协议实现的2PC分布式事务解决方案,因其本身强依赖数据库能力,因此 使用方使用起来简单 ,但是也存在一些缺陷,核心提交在性能不理想,吞吐不够,原因如下:
❌ 2PC的事务保证过程,需要数据库与事务管理器做频繁通信,且多节点多次通信,整体效率慢
❌ 因为2PC需要数据库保证事务中间状态,此过程需要锁住资源,因此事务周期边长,系统性能、吞吐变低。
❌ XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换会导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
TCC补偿式事务
TCC 是一种编程式分布式事务解决方案。所谓编程式,这种方式对于分布式事务保证,完全依赖于应用程序业务逻辑对于事务的确认和补偿支持。
通俗的说,先检查、再操作、最后恢复数据抵消操作。因为它没有数据库原生的 undo log 帮你回滚。如果要失败回滚,必须写一段业务逻辑去 "反向抵消" 之前的操作 ,这就叫补偿(Compensate)。
比如: Try 扣了库存 1 → Cancel 就要加回去 1 Try 扣了余额 100 → Cancel 就要加回 100
TCC模式要求从服务提供三个接口:Try、Confirm、Cancel。(类似于三段式)
♦️**Try接口:**用于真正数据库操作前的数据检查工作,预留资源、锁定资源等(做检查)
♦️**Confirm接口:**真正执行业务,不做任何检查工作。需要注意的是Confirm接口需要保持幂等性(确认)
♦️**Cancel接口:**回滚、释放资源(补偿 / 撤销)
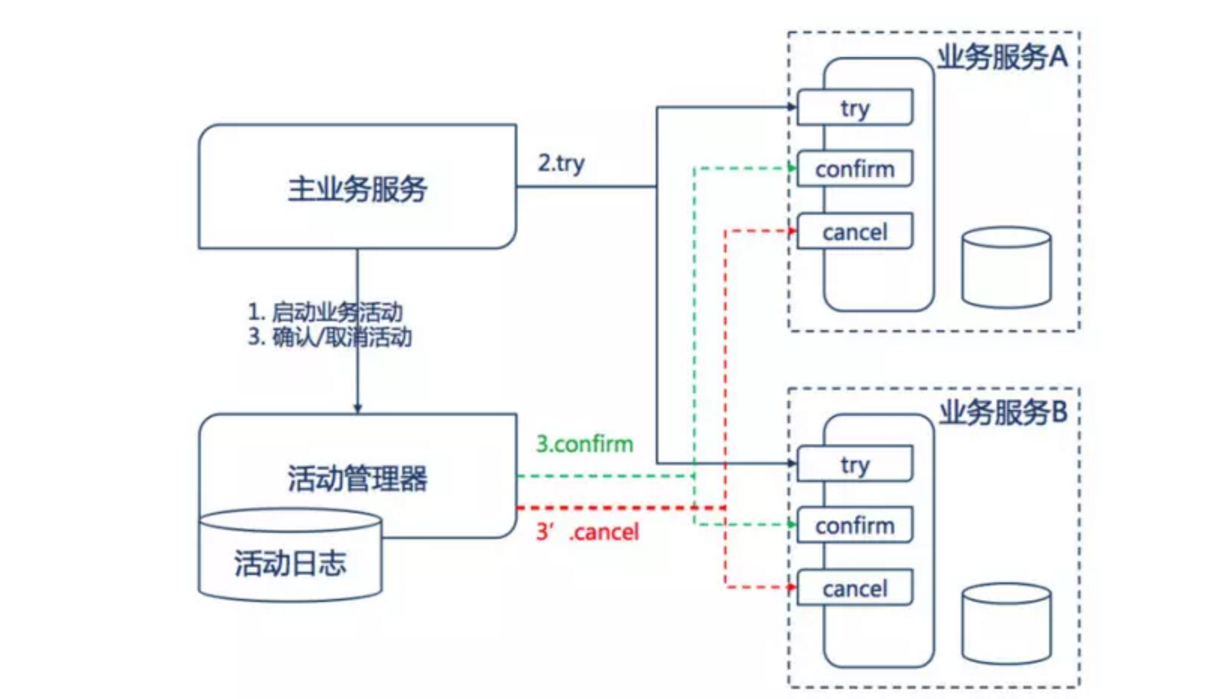
**第一阶段:**主业务服务分别调用所有从业务的try操作,并在活动管理器中登记所有从业务服务。当所有从业务服务的try操作都调用成功或者某个从业务服务的try操作失败,进入第二阶段。
**第二阶段:**活动管理器根据第一阶段的执行结果来执行confirm或cancel操作。如果第一阶段所有try操作都成功,则活动管理器调用所有从业务活动的confirm操作。否则调用所有从业务服务的cancel操作。
举个例子,假如 Bob 要向 Smith 转账100元,思路大概是:
我们有一个本地方法,里面依次调用
首先在 Try 阶段,要先检查Bob的钱是否充足,并把这100元锁住,Smith账户也冻结起来。
在 Confirm 阶段,执行远程调用的转账的操作,转账成功进行解冻。
如果第2步执行成功,那么转账成功,如果第二步执行失败,则调用远程冻结接口对应的解冻方法 (Cancel)。
❇️评估
Canfirm和Cancel的幂等性很难保证。
这种方式缺点比较多,通常在复杂场景下是不推荐使用的,除非是非常简单的场景,非常容易提供回滚Cancel,而且依赖的服务也非常少的情况。
这种实现方式会造成代码量庞大,耦合性高。而且非常有局限性,因为有很多的业务是无法很简单的实现回滚的,如果串行的服务很多,回滚的成本实在太高。
不少大公司里,其实都是自己研发 TCC 分布式事务框架的,专门在公司内部使用。国内开源出去的:ByteTCC,TCC-transaction,Himly
消息事务+最终一致性
基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。
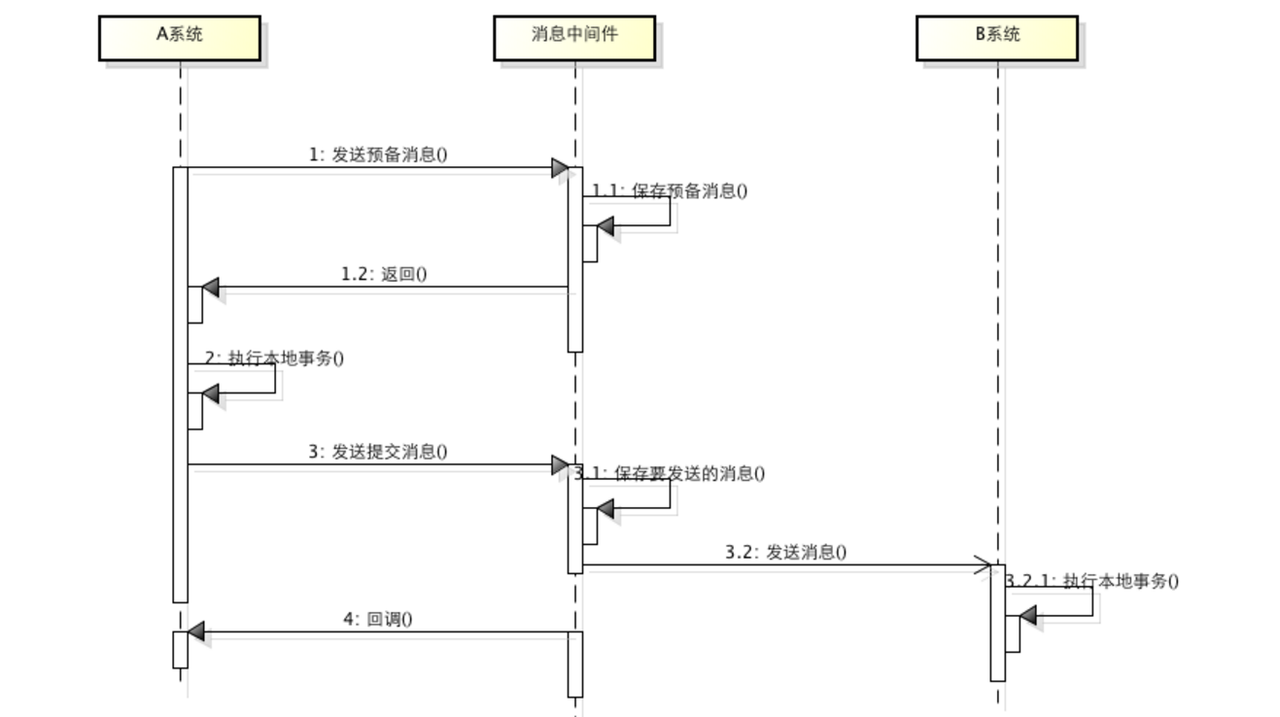
虽然上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。当然,这种玩法也是有风险的,如果B一直执行不成功,那么一致性会被破坏,具体要不要玩,还是得看业务能够承担多少风险。
适用于高并发最终一致
低并发基本一致:二阶段提交
高并发强一致:没有解决方案
XA协议
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准。
通俗的说,它规定数据库实现两段式提交PCC能力的统一接口规范。
XA 规范 描述了全局的事务管理器与局部的资源管理器之间的接口。 XA规范 的目的是允许的多个资源(如数据库,应用服务器,消息队列等)在同一事务中访问,这样可以使 ACID 属性跨越应用程序而保持有效。
XA 规范 使用两阶段提交(2PC,Two-Phase Commit)来保证所有资源同时提交或回滚任何特定的事务。
XA 规范 在上世纪 90 年代初就被提出。目前,几乎所有主流的数据库都对 XA 规范 提供了支持。
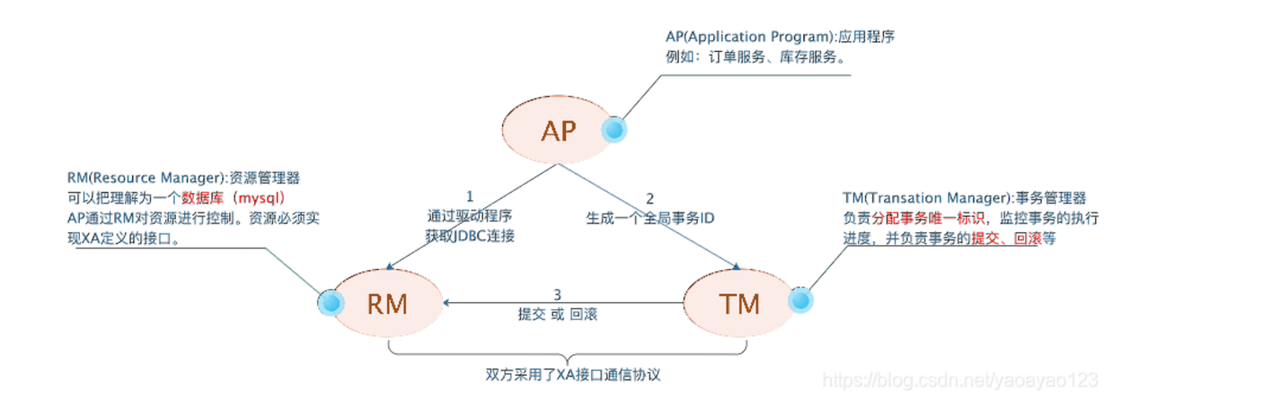
在XA协议规范中的DTP模型定义中,定义了以下3个角色
🟥 **AP(Application):**即应用程序,也就是业务微服务,即使用数据库的程序
🟥 RM: 资源管理器,可以理解为事务的参与者,一般情况下是指一个数据库的实例(MySql),通过资源管理器对该数据库进行控制,资源管理器控制着分支事务。
🟥 **TM:**事务管理器,负责协调和管理事务,事务管理器控制着全局事务,管理事务生命周期,并协调各个RM。全局事务是指分布式事务处理环境中,需要操作多个数据库共同完成一个工作,这个工作即是一个全局事务。
而XA协议中的DTP模型核心就是定义了RM和TM的之间的通讯的接口规范 ,即简单理解为数据库与TM的之间的接口规范,数据库基于接口协议实现2PC接口,基于数据库的XA协议来实现的2PC又称为XA方案。
应用程序AP 持有RM的数据源,例如订单服务和库存服务持有Mysql数据源
应用程序AP 在创建订单时,会创建全局事务ID交给TM进行事务管理
TM 来通知RM 进行第一节点PREPARE操作。
RM 执行事务但不提交 ,undo/redo 日志落盘,锁定资源,RM 回复 TM:OK 或 NO
当应用程序AP 完成事务后,通知TM 进行事务Commit/Rollback ,TM通知RM进行第二阶段的Commit/Rollback
此过程所有 RM 都 OK → TM 发送
COMMIT任意一个 RM 失败 → TM 发送
ROLLBACK
数据库原生支持的分布式事务能力,由 RM 保证:
-
prepare 成功 = 事务一定能最终提交
-
宕机重启后自动恢复完成提交 / 回滚
Seata-Server
官方下载地址:https://github.com/seata/seata/releases
🟥registry.conf配置
Seata 作为分布式事务协调中间件 ,其核心角色是跨服务、跨节点、跨集群协调全局事务,天生依赖 "服务发现" 与 "配置统一" 两大分布式基础能力。如果每个服务都在本地写配置文件,会出现配置不一致、维护成本高、无法动态变更等问题。
注册中心与配置中心不是 "可选优化",而是生产级高可用、可运维、可扩展的必备底座,直接决定分布式事务能否稳定、高效、安全运行。
因此seata服务端通过registry.conf来进行配置所使用注册中心和配置中心,这里都使用nacos。
其核心内容为:
服务端口、事务持久化、注册中心地址、配置中心地址、事务分组路由、全局锁存储等。
它们决定了 TC 能不能启动、客户端能不能连上、事务能不能持久化、集群能不能高可用。
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP"
namespace = ""
cluster = "default"
username = ""
password = ""
}
eureka {
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = 0
password = ""
cluster = "default"
timeout = 0
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
sessionTimeout = 6000
connectTimeout = 2000
username = ""
password = ""
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
aclToken = ""
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "nacos"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = ""
password = ""
## 指定seata的服务配置,例如全局事务默认超时时间
dataId = "seataServer.properties"
}
consul {
serverAddr = "127.0.0.1:8500"
aclToken = ""
}
apollo {
appId = "seata-server"
## apolloConfigService will cover apolloMeta
apolloMeta = "http://192.168.1.204:8801"
apolloConfigService = "http://192.168.1.204:8080"
namespace = "application"
apolloAccesskeySecret = ""
cluster = "seata"
}
zk {
serverAddr = "127.0.0.1:2181"
sessionTimeout = 6000
connectTimeout = 2000
username = ""
password = ""
nodePath = "/seata/seata.properties"
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}需要注意的是在配置中心中,我们可以指定一个dataid来作为seata的服务端或者客户端的系统级别配置,通常我们放在一个配置中。
Seata Server 启动时,去 Nacos 下载名为 seataServer.properties 的配置文件,不再使用本地 file.conf,作为自己的服务端配置,例如事务存储模式(store.mode)、事务超时时间、全局锁配置、重试策略、集群分组等等所有 TC 服务端配置
#For details about configuration items, see https://seata.io/zh-cn/docs/user/configurations.html
#Transport configuration, for client and server
transport.type=TCP
transport.server=NIO
transport.heartbeat=true
transport.enableTmClientBatchSendRequest=false
transport.enableRmClientBatchSendRequest=true
transport.enableTcServerBatchSendResponse=false
transport.rpcRmRequestTimeout=30000
transport.rpcTmRequestTimeout=30000
transport.rpcTcRequestTimeout=30000
transport.threadFactory.bossThreadPrefix=NettyBoss
transport.threadFactory.workerThreadPrefix=NettyServerNIOWorker
transport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandler
transport.threadFactory.shareBossWorker=false
transport.threadFactory.clientSelectorThreadPrefix=NettyClientSelector
transport.threadFactory.clientSelectorThreadSize=1
transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThread
transport.threadFactory.bossThreadSize=1
transport.threadFactory.workerThreadSize=default
transport.shutdown.wait=3
transport.serialization=seata
transport.compressor=none
#Transaction routing rules configuration, only for the client
service.vgroupMapping.default_tx_group=default
#Transaction rule configuration, only for the client
client.rm.asyncCommitBufferLimit=10000
client.rm.lock.retryInterval=10
client.rm.lock.retryTimes=30
client.rm.lock.retryPolicyBranchRollbackOnConflict=true
client.rm.reportRetryCount=5
client.rm.tableMetaCheckEnable=true
client.rm.tableMetaCheckerInterval=60000
client.rm.sqlParserType=druid
client.rm.reportSuccessEnable=false
client.rm.sagaBranchRegisterEnable=false
client.rm.sagaJsonParser=fastjson
client.rm.tccActionInterceptorOrder=-2147482648
client.tm.commitRetryCount=5
client.tm.rollbackRetryCount=5
client.tm.defaultGlobalTransactionTimeout=60000
client.tm.degradeCheck=false
client.tm.degradeCheckAllowTimes=10
client.tm.degradeCheckPeriod=2000
client.tm.interceptorOrder=-2147482648
client.undo.dataValidation=true
client.undo.logSerialization=jackson
client.undo.onlyCareUpdateColumns=true
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
client.undo.logTable=undo_log
client.undo.compress.enable=true
client.undo.compress.type=zip
client.undo.compress.threshold=64k
#For TCC transaction mode
tcc.fence.logTableName=tcc_fence_log
tcc.fence.cleanPeriod=1h
#Log rule configuration, for client and server
log.exceptionRate=100
#Transaction storage configuration, only for the server. The file, DB, and redis configuration values are optional.
store.mode=db
store.lock.mode=file
store.session.mode=file
#If `store.mode,store.lock.mode,store.session.mode` are not equal to `file`, you can remove the configuration block.
store.file.dir=file_store/data
store.file.maxBranchSessionSize=16384
store.file.maxGlobalSessionSize=512
store.file.fileWriteBufferCacheSize=16384
store.file.flushDiskMode=async
store.file.sessionReloadReadSize=100
#These configurations are required if the `store mode` is `db`. If `store.mode,store.lock.mode,store.session.mode` are not equal to `db`, you can remove the configuration block.
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.cj.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&rewriteBatchedStatements=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
store.db.user=root
store.db.password=123456
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.distributedLockTable=distributed_lock
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
#Transaction rule configuration, only for the server
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.distributedLockExpireTime=10000
server.xaerNotaRetryTimeout=60000
server.session.branchAsyncQueueSize=5000
server.session.enableBranchAsyncRemove=false
server.enableParallelRequestHandle=false
#Metrics configuration, only for the server
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898🟥file.conf配置
file.conf 是 Seata 的本地存储配置文件,用于配置事务日志与全局锁的存储方式(file/db/redis)及相关参数。仅在未接入配置中心时使用,即在没有配置register.conf的配置中心时使用,核心就是持久化相关配置:
## transaction log store, only used in seata-server
store {
## store mode: file、db、redis
mode = "db"
## rsa decryption public key
publicKey = ""
## file store property
file {
## store location dir
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
maxBranchSessionSize = 16384
# globe session size , if exceeded throws exceptions
maxGlobalSessionSize = 512
# file buffer size , if exceeded allocate new buffer
fileWriteBufferCacheSize = 16384
# when recover batch read size
sessionReloadReadSize = 100
# async, sync
flushDiskMode = async
}
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp)/HikariDataSource(hikari) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
## if using mysql to store the data, recommend add rewriteBatchedStatements=true in jdbc connection param
url = "jdbc:mysql://localhost:3306/seata?useUnicode=true&characterEncoding=UTF-8"
user = "root"
password = "root"
minConn = 5
maxConn = 100
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
## redis store property
redis {
## redis mode: single、sentinel
mode = "single"
## single mode property
single {
host = "127.0.0.1"
port = "6379"
}
## sentinel mode property
sentinel {
masterName = ""
## such as "10.28.235.65:26379,10.28.235.65:26380,10.28.235.65:26381"
sentinelHosts = ""
}
password = ""
database = "0"
minConn = 1
maxConn = 10
maxTotal = 100
queryLimit = 100
}
}🟥创建seata服务端表
用于seata-server(TC)全局事务管理
-
global_table:全局事务会话表
-
branch_table:分支事务会话表
-
lock_table:锁数据表
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTSglobal_table
(
xidVARCHAR(128) NOT NULL,
transaction_idBIGINT,
statusTINYINT NOT NULL,
application_idVARCHAR(32),
transaction_service_groupVARCHAR(32),
transaction_nameVARCHAR(128),
timeoutINT,
begin_timeBIGINT,
application_dataVARCHAR(2000),
gmt_createDATETIME,
gmt_modifiedDATETIME,
PRIMARY KEY (xid),
KEYidx_gmt_modified_status(gmt_modified,status),
KEYidx_transaction_id(transaction_id)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTSbranch_table
(
branch_idBIGINT NOT NULL,
xidVARCHAR(128) NOT NULL,
transaction_idBIGINT,
resource_group_idVARCHAR(32),
resource_idVARCHAR(256),
branch_typeVARCHAR(8),
statusTINYINT,
client_idVARCHAR(64),
application_dataVARCHAR(2000),
gmt_createDATETIME(6),
gmt_modifiedDATETIME(6),
PRIMARY KEY (branch_id),
KEYidx_xid(xid)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;-- the table to store lock data
CREATE TABLE IF NOT EXISTSlock_table
(
row_keyVARCHAR(128) NOT NULL,
xidVARCHAR(128),
transaction_idBIGINT,
branch_idBIGINT NOT NULL,
resource_idVARCHAR(256),
table_nameVARCHAR(32),
pkVARCHAR(36),
statusTINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',
gmt_createDATETIME,
gmt_modifiedDATETIME,
PRIMARY KEY (row_key),
KEYidx_status(status),
KEYidx_branch_id(branch_id)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
Seata
官网:https://seata.io/zh-cn/docs/overview/what-is-seata.html
Seata并不是一种新的分布式解决方案理论,而是基于以上分布式解决方案的具体落地实现框架。Seata 将为用户提供了AT、TCC、 和 XA 事务模式,为用户打造一站式的分布式解决方案。
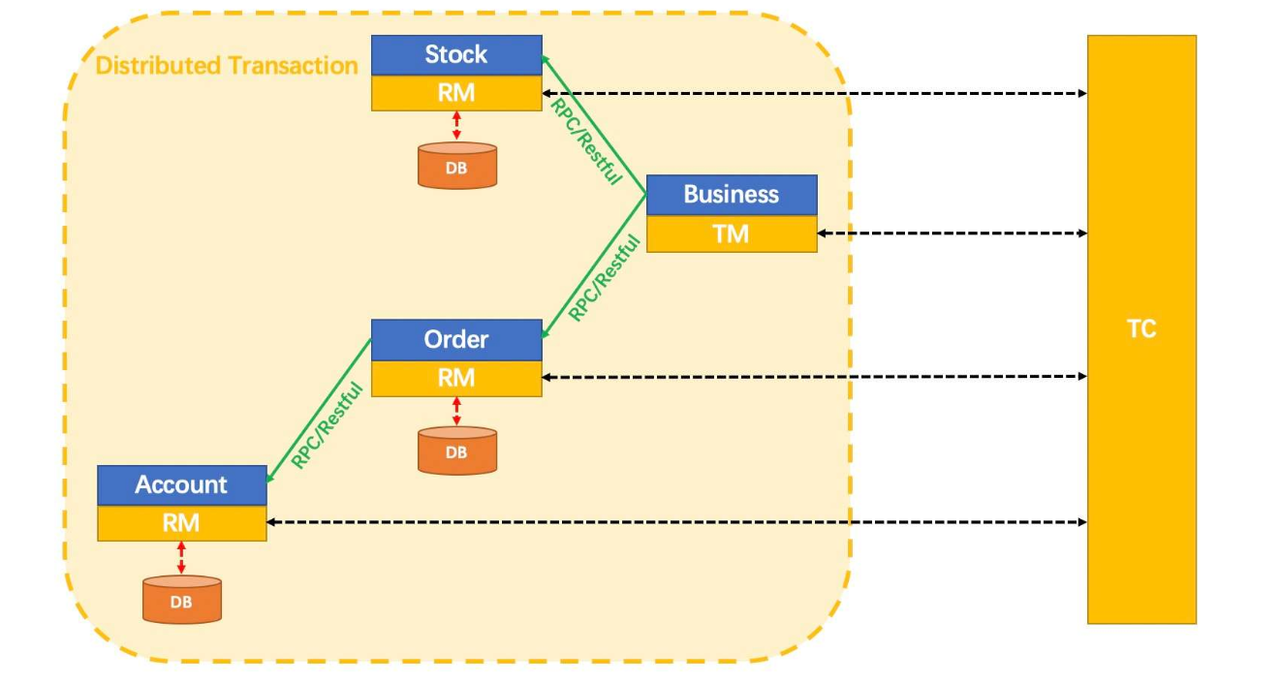
关键角色定义
在Seata框架中,将分布式事务中的一些关键角色做了一些定义:
🟥TC(Transaction Coordinator)事务协调者
也就是独立部署的 Seata Server,核心职责:
记录全局事务状态(begin、committing、rollbacking、end)
用于维护全局和分支事务状态,管理分支事务(每个微服务本地事务)
接受TM的注册,统一决策:全局提交 or 全局回滚。
类似于分布式系统中协调者,例如leader节点,kafka中的zookeeper
🟥TM(Transaction Mananger)事务管理器
核心是发起全局事务的人,本质上也就是入口微服务(也是属于RM),会承担TM的职责。它核心职责为:
通过
@GlobalTransactional开启全局事务向 TC 注册一个全局事务 ID(XID)
执行完所有微服务调用后,告诉 TC:我要提交 / 我失败了要回滚
🟥RM(Resource Manager)资源管理器
定位:每个数据库 / 资源的代理人,也就是链路中的微服务。但是需要注意是,只有被Seata 拦截器增强的数据源才能成为RM,也就是说只有加上了@GlobalTransactional的容器才会被
把本地事务注册成 TC 下的 "分支事务"
通过代理拦截 SQL,生成 undo_log(AT 模式核心)
执行本地提交 / 回滚,收到 TC 指令后,做分支提交或分支回滚
Seata中什么情况下会成为RM:
**条件1:**当前服务必须引入seata starter、数据源被代理,此时在初始化时容器就会进行TM和RM的注册
但是需要注意的是:并不是注册为了RM就一定是分支事务,需要满足以下条件:
条件2: 请求有 XID(从上游传下来)
条件3: 当前操作在本地事务里运行
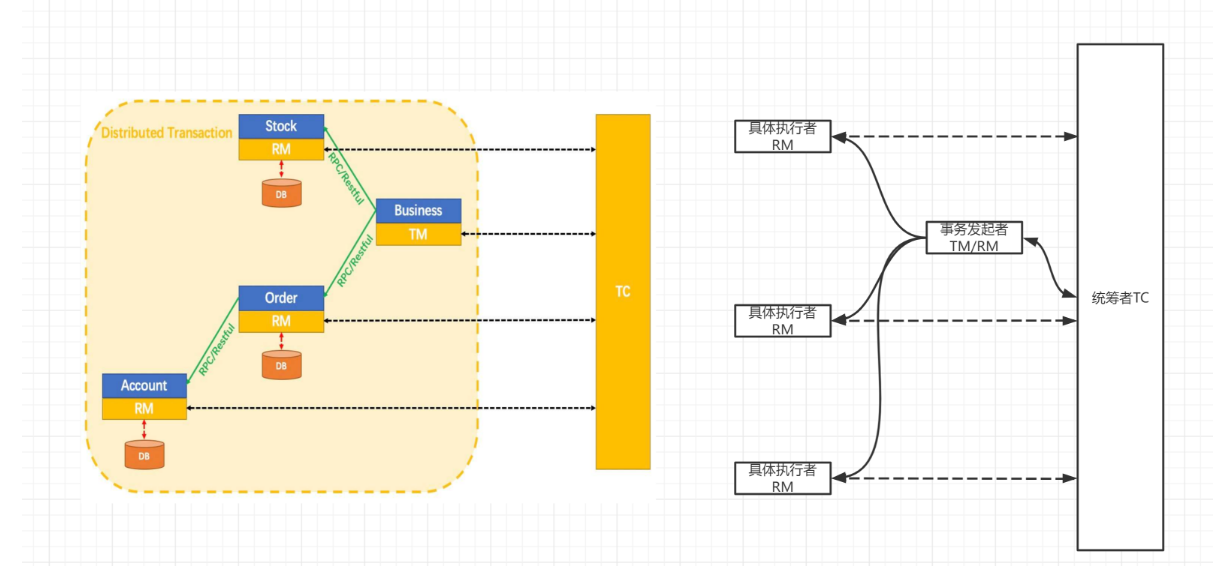
分布式事务模式
一个分布式的全局事务,整体是 两阶段提交 的模型。全局事务是由若干分支事务(本地事务)组成的 ,分支事务要满足 两阶段提交 的模型要求,即需要每个分支事务都具备自己的:
-
一阶段 prepare 行为
-
二阶段 commit 或 rollback 行为
🟥 XA模式
Seata的XA模式是基于XA协议规范的具体使用落地它做的是标准化包装 + 集成微服务架构,没有篡改 XA 协议本身。所以它核心利用事务资源(数据库、消息服务等)对 XA 协议的支持,以 XA 协议的机制来管理分支事务的一种 事务模式。
在Seata中:
-
TC(Seata Server) 相当于 标准XA协议中的TM(事务协调者)
-
各个微服务的 RM(DataSource) = 实际的应用程序AP 和RM事务资源
执行阶段(prepare 阶段):
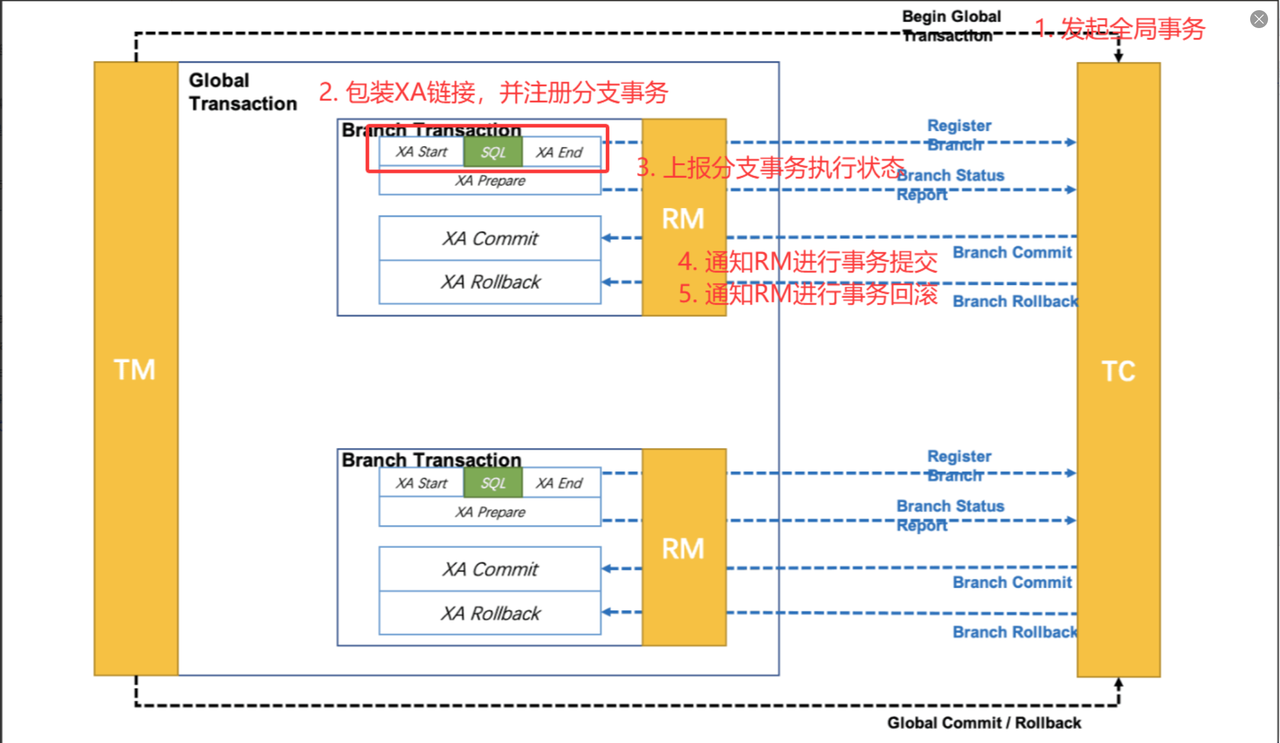
🟥发起全局事务:TM(业务应用) 发起全局事务,向 TC 获取 XID
🟥执行注册分支事务: 业务调用各个微服务,每个服务的 RM(Seata 客户端) 获取数据库连接,并包装成 XA 连接,并执行分支事务
XA START开启分支事务执行业务 SQL
XA END结束事务操作向TC注册分支事务
🟥RM向TC上报分支事务执行状态: RM 向TC发起
XA PREPARE
数据库把事务持久化、锁资源、写 undo/redo 日志
数据库承诺:只要收到 COMMIT,就一定能提交成功
RM 把 prepare 结果上报给 TC
完成阶段:
🟥**分支提交:**TC通知RM执行 XA 分支的 commit
🟥**分支回滚:**TC通知RM执行 XA 分支的 rollback
♦️案例
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.1</version>
<relativePath/>
</parent>
<groupId>com.cpc</groupId>
<artifactId>seata-client01</artifactId>
<version>1.0-SNAPSHOT</version>
<name>seata-client01</name>
<properties>
<java.version>17</java.version>
<mybatis-plus.version>3.5.5</mybatis-plus.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2023.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2023.0.1.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<version>2.2.1.RELEASE</version>
<!-- 因为内部自带的seata版本为1.1,版本太低,这里需要屏蔽,重新引入高版本seata-->
<exclusions>
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>客户端pom配置
server:
port: 8802
spring:
config:
import:
- nacos:seataServer.properties?group=SEATA_GROUP
main:
allow-bean-definition-overriding: true
allow-circular-references: true
application:
name: product-service
cloud:
nacos:
discovery:
server-addr: 192.168.7.17:8848
group: SEATA_GROUP
config:
server-addr: 192.168.7.17:8848
group: SEATA_GROUP
datasource:
url: jdbc:mysql://127.0.0.1:3306/seate_client?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
seata:
tx-service-group: default_tx_group
registry:
type: nacos
nacos:
application: seata-server
server-addr: 192.168.7.17:8848
group: SEATA_GROUP
config:
type: nacos
nacos:
server-addr: 192.168.7.17:8848
group: SEATA_GROUP
data-id: seataServer.properties
data-source-proxy-mode: XA订单服务
@GetMapping("/create")
@GlobalTransactional(rollbackFor = Exception.class)
public void createOrder(){
orderService.createOrder();
}
public void createOrder() {
String orderId = UUID.randomUUID().toString();
jdbcTemplate.execute("insert into `order` (`name`) values ('order-" + orderId + "')");
restTemplate.getForObject("http://localhost:8802/create", Object.class, Object.class);
}
@PostMapping("/create")
@Transactional(rollbackFor = Exception.class)
public void createProduct() {
productService.createProduct();
}
public void createProduct() {
String productId = UUID.randomUUID().toString();
String sql = "INSERT INTO `product` (`name`) VALUES ('product-" + productId + "')";
jdbcTemplate.execute(sql);
int a = 1/0;
}需要注意的是:
-
Order服务必须使用@GlobalTransactional,这样请求时,Order服务就会成为TM进行全局事务发起
-
Product服务必须使用@Transactional,此时才能注册分支事务,参与全局事务的管控。如果使用@GlobalTransactional则会创建一个新的全局事务,即B就会成为TM
♦️优点
-
业务无侵入:XA 模式将是业务无侵入的,不给应用设计和开发带来额外负担。
-
支持多种数据库 :XA 协议被主流关系型数据库广泛支持,不需要额外的适配即可使用
-
支持多种语言
-
**强一致性(ACID):**因为需要所有的RM第一阶段成功之后统一提交,保证了数据的强一致性
- XA 一阶段不提交、持有数据库锁,靠数据库原生事务机制保证了完整隔离:既不会脏写,也不会脏读。
♦️缺点
因为XA协议的实现,在第一阶段会对资源进行锁住,需要等到所有的RM完成才能提交,因此整体本地事务(分支事务)周期拉长,导致请求阻塞 ,性能降低
🟥 AT模式(最常用)
AT 模式是 Seata 创新的一种非侵入式的分布式事务解决方案,Seata 在内部做了对数据库操作的代理层,我们使用 Seata AT 模式时,实际上用的是 Seata 自带的数据源代理 DataSourceProxy,Seata 在这层代理中加入了很多逻辑,比如插入回滚 undo_log 日志,检查全局锁等。
通俗的说,SeataAT模式是2PC 事务的一种实现方式,它核心通过本地事务提交 + 反向 SQL 回滚 + 全局锁控制来实现全局事务的管控
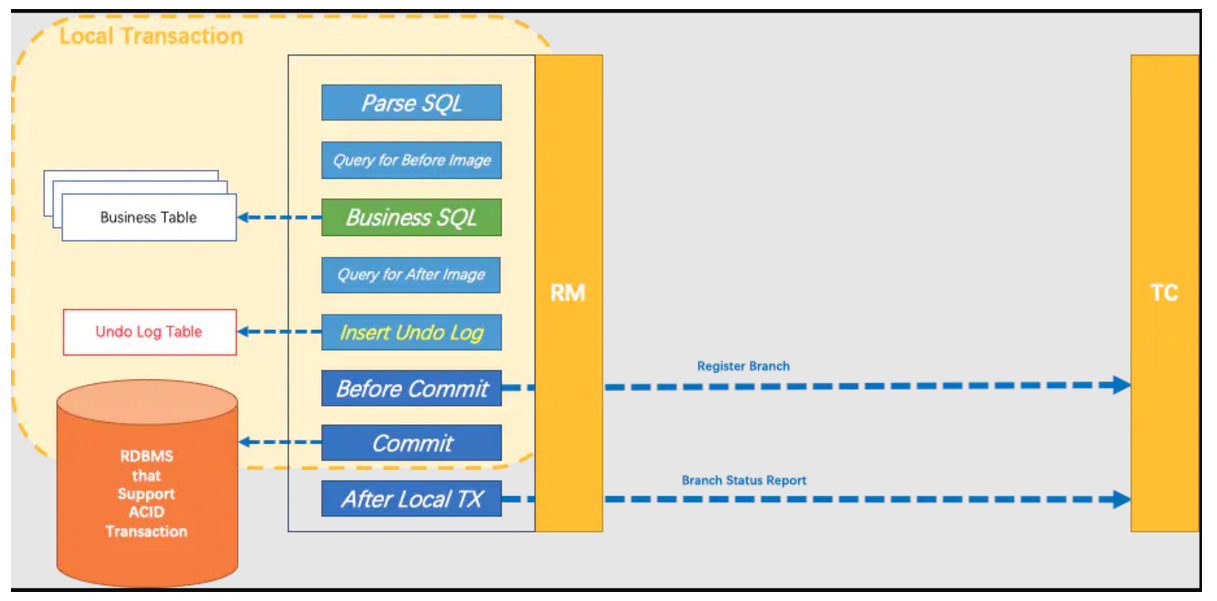
⭐一阶段(执行与提交):
Seata 的 JDBC数据源代理 通过对业务 SQL 的解析,把业务数据在更新前后的数据镜像组织成回滚undo_log日志 ,利用 本地事务 的 ACID 特性,将业务数据的更新和回滚日志的写入在同一个 本地事务 中提交。
这样,可以保证:任何提交的业务数据的更新一定有相应的回滚日志存在
基于这样的机制,分支的本地事务便可以在全局事务的 执行阶段 提交,马上释放本地事务锁定的资源。
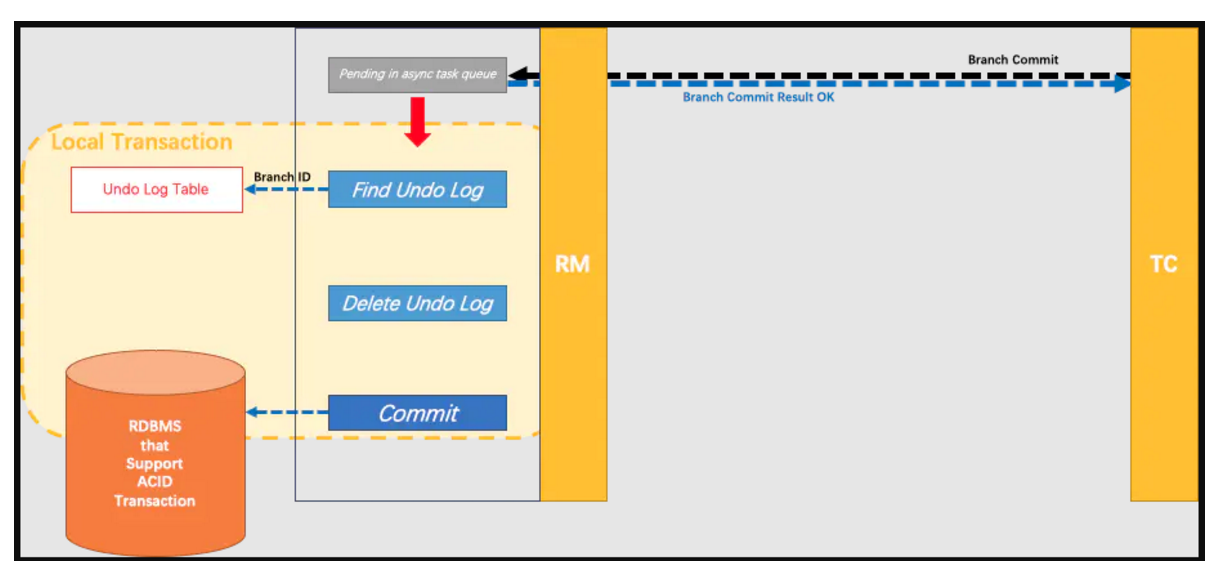
⭐阶段二:全局提交 / 回滚
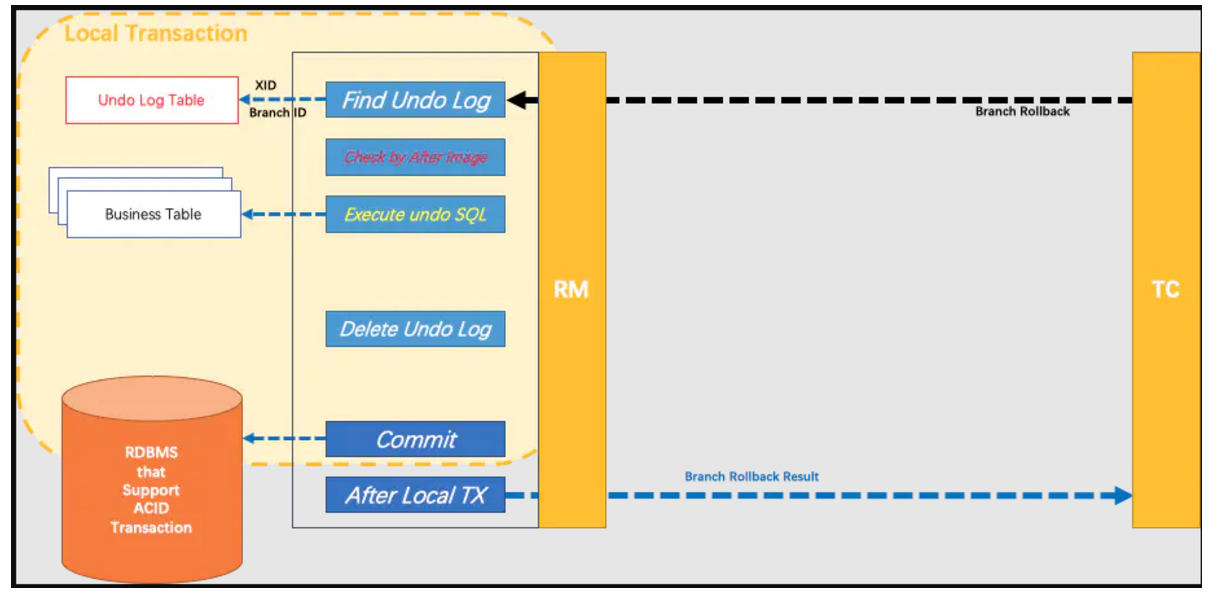
如果决议是全局提交,此时分支事务此时已经完成提交,不需要同步协调处理(只需要异步清理回滚日志),完成阶段 可以非常快速地结束。如果决议是全局回滚,RM 收到协调器发来的回滚请求,通过 XID 和 Branch ID 找到相应的回滚日志记录,通过回滚记录生成反向的更新 SQL 并执行,以完成分支的回滚。
♦️案例
因为AT模式是基于undo_log的补充机制,因此业务表必须开启undo_log日志和表
server:
port: 8801
spring:
application:
name: order-service
main:
allow-bean-definition-overriding: true
allow-circular-references: true
cloud:
nacos:
discovery:
server-addr: 192.168.7.17:8848
group: SEATA_GROUP
config:
server-addr: 192.168.7.17:8848
group: SEATA_GROUP
config:
import:
- nacos:seataServer.properties?group=SEATA_GROUP
datasource:
url: jdbc:mysql://127.0.0.1:3306/seate_client?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
seata:
enabled: true
application-id: ${spring.application.name}
tx-service-group: default_tx_group
registry:
type: nacos
nacos:
application: seata-server
server-addr: 192.168.7.17:8848
group: SEATA_GROUP
namespace:
config:
type: nacos
nacos:
server-addr: 192.168.7.17:8848
group: SEATA_GROUP
namespace:
data-id: service.vgroupMapping.default_tx_group
data-source-proxy-mode: AT其他的内部与上述一样
♦️全局锁
因为AT模式下在第一阶段就会进行本地事务的提交,因此会导致不同全局事务之间可能会出现以下问题:
?问题
❌ 脏读问题
例如事务 A 一阶段已提交本地数据,但全局事务未最终完成,其他全局事务能读到中间状态数据。
❌不可重复读
同一事务内多次查询结果不一致(因为本地事务已提交,MySQL MVCC 快照失效)
❌脏写 / 覆盖写 / 回滚错乱
多个全局事务并发修改同一行,导致数据互相覆盖、回滚时破坏他人已提交数据。
因此Seata在AT模式下,通过全局锁实现**【写隔离】** 和**【读隔离】** ,解决脏读、脏写 / 覆盖写 / 回滚错乱问题
全局锁是 TC 管理的分布式行锁,保证同一时间只有一个全局事务能修改某一行。
⭐写隔离
用于解决脏写 / 覆盖写问题
一阶段本地事务提交前,需要确保先拿到 全局锁( TC 管理的分布式行锁) 。
拿不到 全局锁 ,不能提交本地事务。
拿 全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
在@GlobalTransactional注解中,已经默认使用了分布式行锁实现了写隔离
⭐读隔离
在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交(Read Uncommitted) 。
如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理。
通俗的说就是,seata通过全局锁,实现了不同全局事务的读已提交能力,解决了脏读问题
需要手动将@GlobalLock注解标记在非分布式事务的读方法上,实现【全局读 / 写隔离】,让普通非事务接口也能参与全局锁竞争
SELECT FOR UPDATE 语句的执行会申请 全局锁 ,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被 block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回。
出于总体性能上的考虑,Seata 目前的方案并没有对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句。
AT 模式不支持可重复读,因为一阶段本地事务已提交,MVCC 快照失效,且 Seata 不提供全局快照机制。
♦️优点
-
**业务完全无侵入:**与XA相同,只需要加注解,不用改业务代码、不用写 SQL,和普通事务一样。但是本地数据库需要开启undo_log日志
-
性能极高、并发好: 一阶段本地事务直接提交,数据库锁立即释放,不像 XA 长时间占锁。
-
**不依赖数据库 XA 协议:**支持 MySQL、PostgreSQL、Oracle 等几乎所有关系型数据库,通用性极强。
-
**支持高可用与故障自动恢复:**宕机重启后 TC 会继续推动事务完成,自动重试回滚 / 提交。
♦️缺点
-
能保证最终一致性,不是强一致 一阶段已提交,其他事务能读到中间状态,会出现脏读、不可重复读(短时间窗口)。
-
依赖全局锁机制,存在性能损耗Seata 自己维护一套全局锁,高并发下会有锁争抢、重试开销。
-
需要额外表:undo_log每个库都要建 undo_log 表,占用存储,有写入开销。
-
不支持跨多类型资源只支持关系型数据库,不支持消息队列、Redis、ES 等混合事务(XA 支持)。
-
回滚是补偿式,不是原生回滚通过反向 SQL 恢复数据,极端场景(如数据被其他事务修改)会回滚失败,需要人工处理。
-
对数据库 binlog 格式有要求 MySQL 需要
ROW模式,否则镜像解析不准确。
🟥TCC模式
TCC 模式是 Seata 支持的一种由业务方细粒度控制的侵入式分布式事务解决方案,是继 AT 模式后第二种支持的事务模式,最早由蚂蚁金服贡献。其分布式事务模型直接作用于服务层,不依赖底层数据库,可以灵活选择业务资源的锁定粒度,减少资源锁持有时间,可扩展性好,可以说是为独立部署的 SOA 服务而设计的。
Seata TCC 模式跟通用型 TCC 模式原理一致。
❇️ TCC和AT区别
AT 模式基于 支持本地 ACID 事务 的 关系型数据库:
-
一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
-
二阶段 commit 行为:马上成功结束,自动 异步批量清理回滚日志。
-
二阶段 rollback 行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
相应的,TCC 模式,不依赖于底层数据资源的事务支持:
-
一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
-
二阶段 commit 行为:调用 自定义 的 commit 逻辑。
-
二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
在两阶段提交协议中,资源管理器(RM, Resource Manager)需要提供"准备"、"提交"和"回滚" 3 个操作;而事务管理器(TM, Transaction Manager)分 2 阶段协调所有资源管理器,在第一阶段询问所有资源管理器"准备"是否成功,如果所有资源均"准备"成功则在第二阶段执行所有资源的"提交"操作,否则在第二阶段执行所有资源的"回滚"操作,保证所有资源的最终状态是一致的,要么全部提交要么全部回滚。
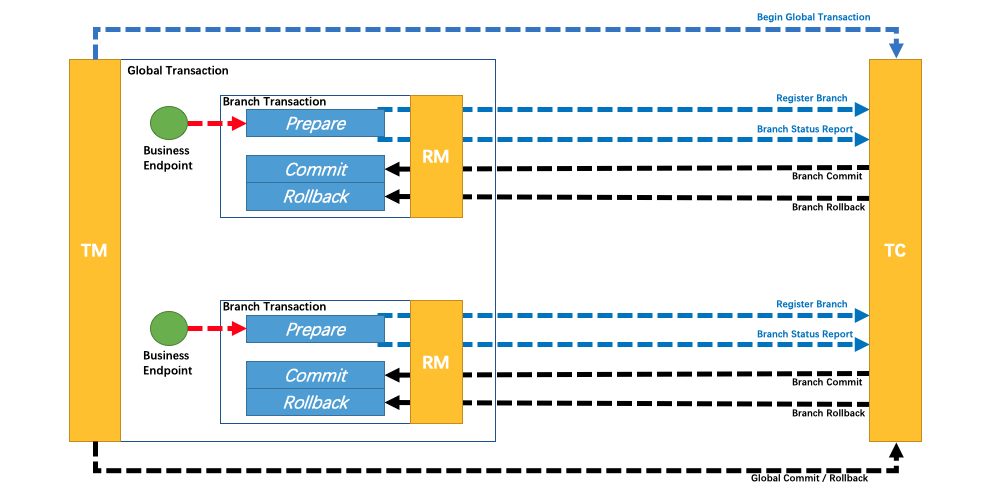
♦️优点
TCC 完全不依赖底层数据库,能够实现跨数据库、跨应用资源管理,可以提供给业务方更细粒度的控制。
♦️缺点
TCC 是一种侵入式的分布式事务解决方案,需要业务系统自行实现 Try,Confirm,Cancel 三个操作,对业务系统有着非常大的入侵性,设计相对复杂。
TCC 模式是高性能分布式事务解决方案,适用于核心系统等对性能有很高要求的场景。
🟥SAGA模式
Saga 模式是 SEATA 提供的长事务入侵式解决方案,在 Saga 模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
之前我们学习的Seata分布式三种操作模型中所使用的的微服务全部可以根据开发者的需求进行修改,但是在一些特殊环境下,比如老系统,封闭的系统(无法修改,同时没有任何分布式事务引入),那么AT、XA、TCC模型将全部不能使用,为了解决这样的问题,才引用了Saga模型。
比如:事务参与者可能是其他公司的服务或者是遗留系统,无法改造,可以使用Saga模式。
这里先明确Saga模式的3个核心概念,后续案例会逐一对应,方便理解:
-
子事务(Sub-transaction):拆分后的独立小事务,对应一个具体的业务操作(如创建订单、扣减库存),执行成功后立即提交本地事务,释放所有资源(无锁持有)。
-
正向流程(Forward Saga):所有子事务按业务逻辑顺序依次执行,只有前一个子事务执行成功,才会触发下一个子事务,直至所有子事务执行完成,整个Saga事务成功。
-
反向补偿流程(Compensating Saga):当某一个子事务执行失败时,触发反向执行逻辑,从失败的子事务开始,依次回滚前面所有已成功的子事务(通过补偿事务实现),最终让所有业务数据回到初始状态。
补充说明:Saga模式不依赖数据库锁、不依赖全局锁,子事务执行后立即提交,因此不存在长时间阻塞的问题,适合分钟级、小时级的长事务场景;同时它属于"最终一致性"事务,允许存在短暂的中间状态,但最终会通过补偿机制恢复数据一致性。
例如:
一个下单流程会调用:
订单服务(创建订单)
库存服务(扣减库存)
优惠券服务(核销优惠券)
支付服务(扣减余额)
物流服务(创建物流单)
这是典型 长流程、跨多服务、可能很慢 的场景,非常适合 Saga。
正常正向流程(全部成功)
订单服务:创建订单,状态 = 待支付→ 本地事务提交
库存服务:扣减商品库存→ 本地事务提交
优惠券服务:标记优惠券已使用→ 本地事务提交
支付服务:扣除用户余额→ 本地事务提交
物流服务:创建物流单→ 本地事务提交
全部成功 → 事务结束。
异常场景:支付失败
执行到第 4 步:支付服务扣款失败。
Saga 开始反向补偿回滚:
物流服务:删除 / 作废物流单(补偿)
支付服务:无需处理(本来就失败)
优惠券服务:退回优惠券,恢复为未使用(补偿)
库存服务:返还库存(补偿)
订单服务:订单状态改为 "支付失败" 或取消(补偿)
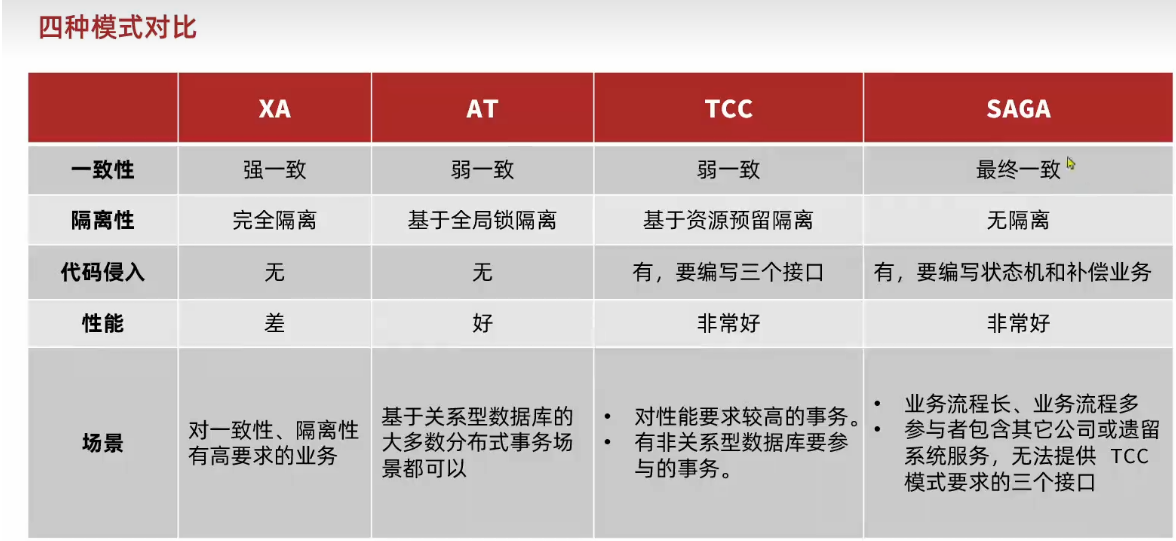
最终所有数据都回到正确状态,业务一致。模式对比
原理
Seata 虽然提供了四种不同的事务模式,但它们都基于统一的架构模型:TC(事务协调器)、TM(事务管理器)、RM(资源管理器)。不同模式之间最核心的差异,体现在 RM 对分布式事务两个阶段的处理逻辑与实现方式上。
客户端 - 初始化
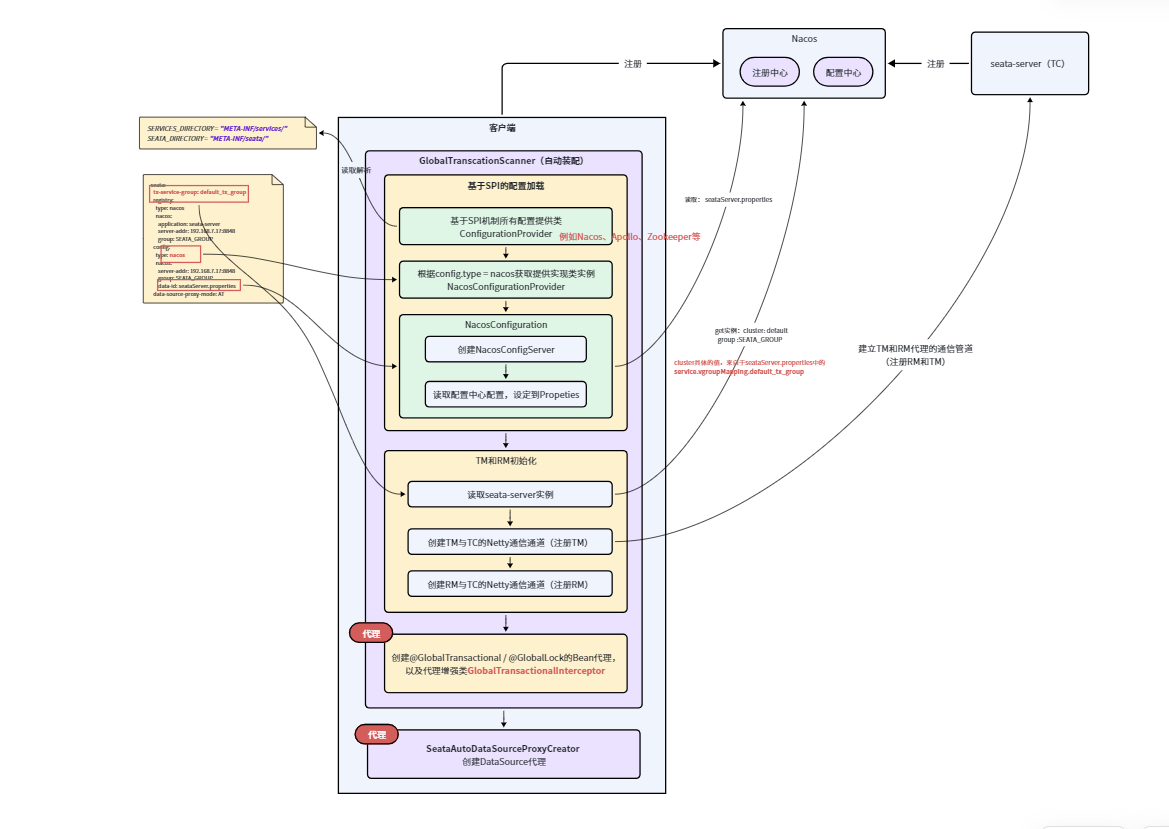
这里我们基于seata1.8版本进行源码分析,注册中心和配置中心都使用nacos,同样基于SpringBoot的自动装配,找到SeataAutoConfiguration 装配类,其中核心为GlobalTransactionScanner的初始化过程。
GlobalTransactionScanner是Seata框架的核心初始化类,负责Seata分布式事务核心组件(TM、RM)的初始化、配置加载、代理增强及与TC的通信准备,是Seata事务生效的基础。其核心事项可概括为4点:
- 基于SPI的配置类读取
Seata采用SPI(Service Provider Interface)机制加载配置类,实现配置的可扩展(支持自定义配置实现),默认支持Nacos、apollo、file、Zookeeper、自定义实现等
- TM和RM初始化
- Netty客户端创建
- 基于配置,从注册中心读取seata-server实例进行连接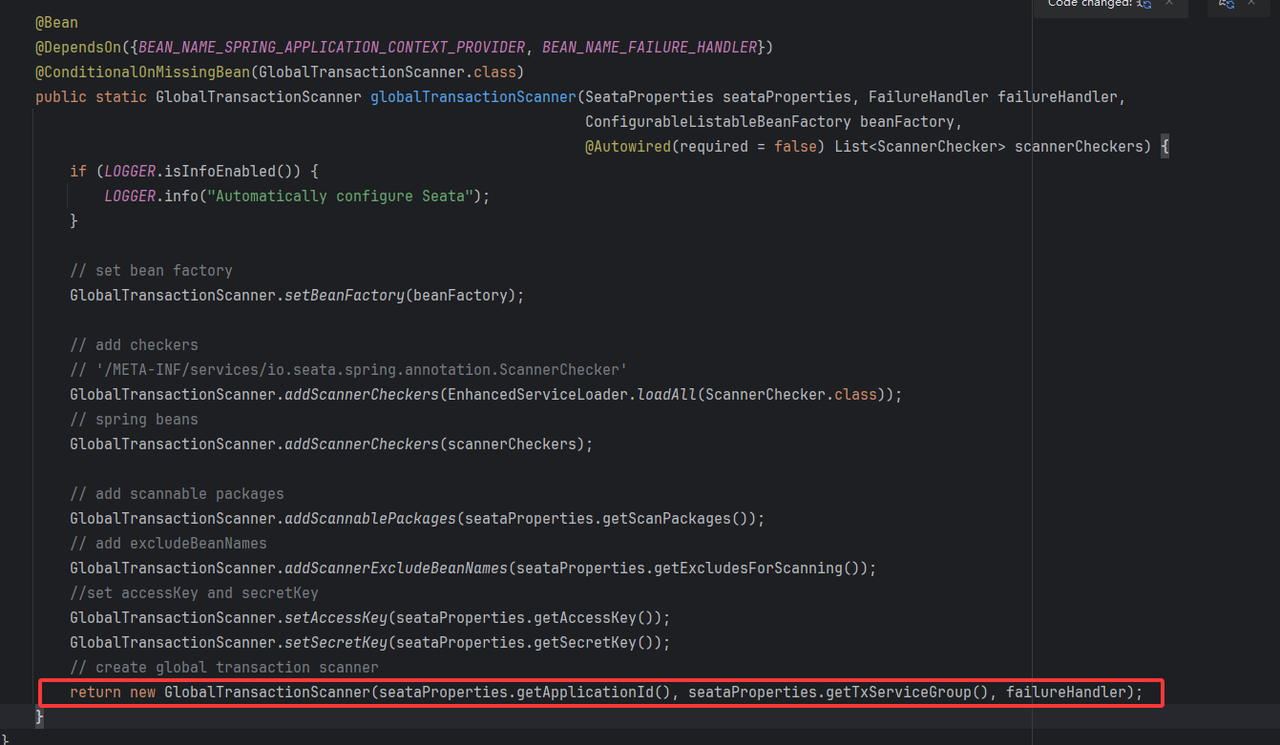
这里在创建GlobalTransactionScanner对象时,会从本地配置文件(application.yml)中读取seata.tx-service-group 配置 , **这个配置非常重要,它本质上就是指定从nacos上获取指定cluster下的nacos实例,**即对应seata-server注册到nacos上的集群名称(registry.conf上的配置)
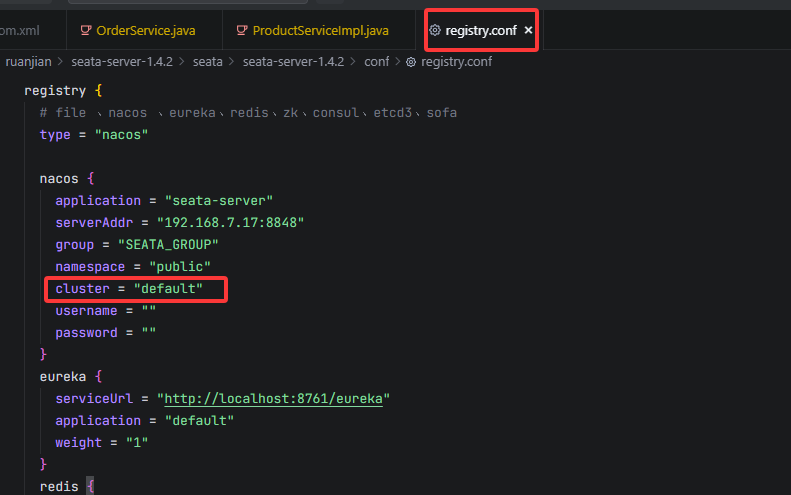
但是需要注意的是,application.yml文件中并不能直接配置default,后续可以看到它是通过seata.tx-service-group 配置的组装key,从nacos中读取到指定的cluster信息
❇️基于SPI的Nacos配置中心配置加载
在Seata客户端中,支持多种配置实现,例如nacos、本地file、apollo...我们可以在application.yml文件中通过指定的方式来选择使用不同的配置扩展类。
Seata客户端对于不同的配置形式,通过SPI形式进行扩展。在new SeataAutoConfiguration(),过程中通过ConfigurationFactory.getInstance(),来初始化当前配置实现类。

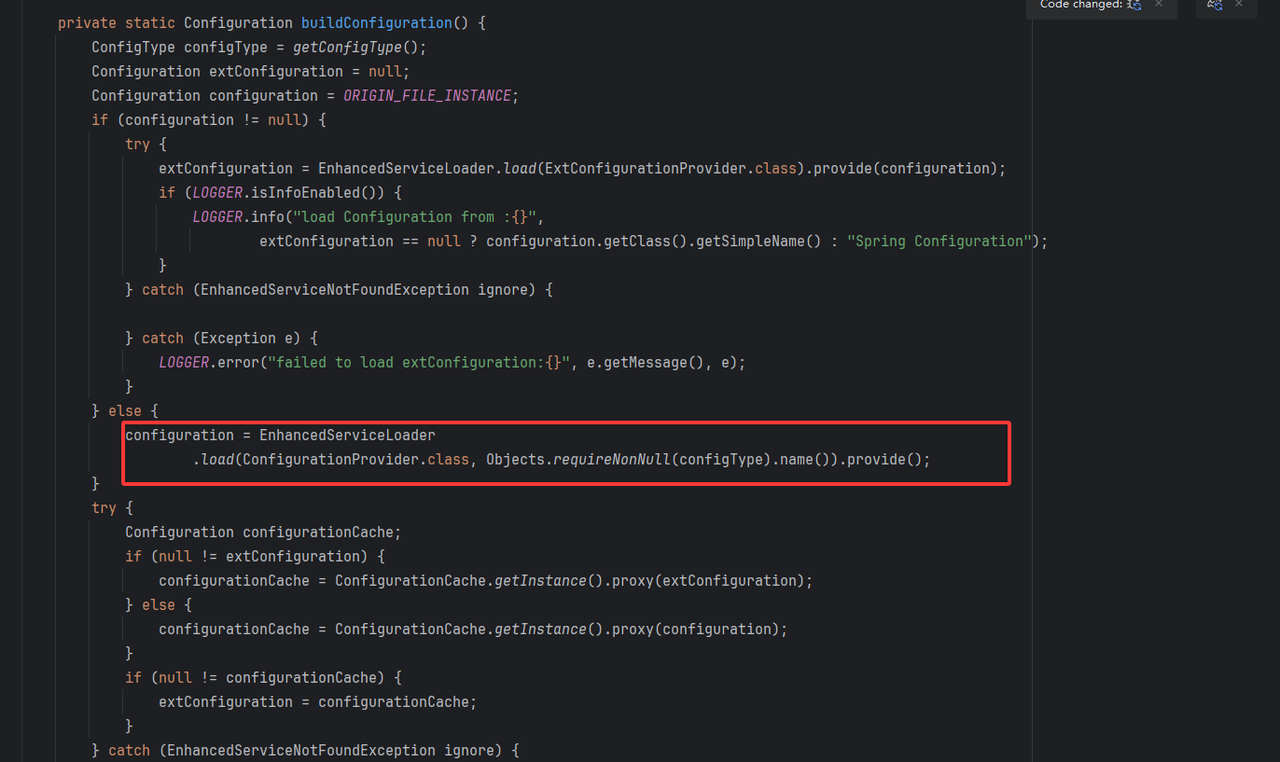
EnhancedServiceLoader.load(ExtConfigurationProvider.class).provide(configuration) 是Seata自己实现的一种SPI机制,本质上也是从以下路径中读取扩展类:
public static final String SERVICES_DIRECTORY ="META-INF/services/" public static final String SEATA_DIRECTORY = "META-INF/seata/"
因为项目中配置了nacos作为配置中心和注册中心,因此此处会找到NacosConfigurationProvider。它内部核心就是实现了provider方法,主要就是用于创建一个NacosConfiguration配置中心的实例类

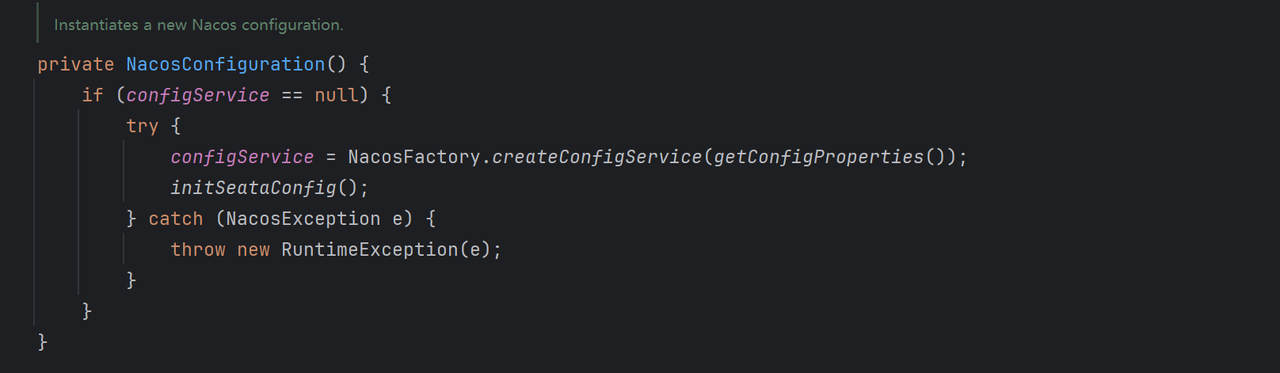
在创建Nacos配置中心时,还做了一件事情,就是初始化Seata配置。
- 核心为读取指定seata配置文件dataid,即从seata.config.nacos.data-id 中读取,默认为seata.properties,并缓存在全局Properties中,共给后续使用
也就是说,在Nacos配置类创建后,立马就从配置中心拉去了指定名称的seata配置,并进行缓存。
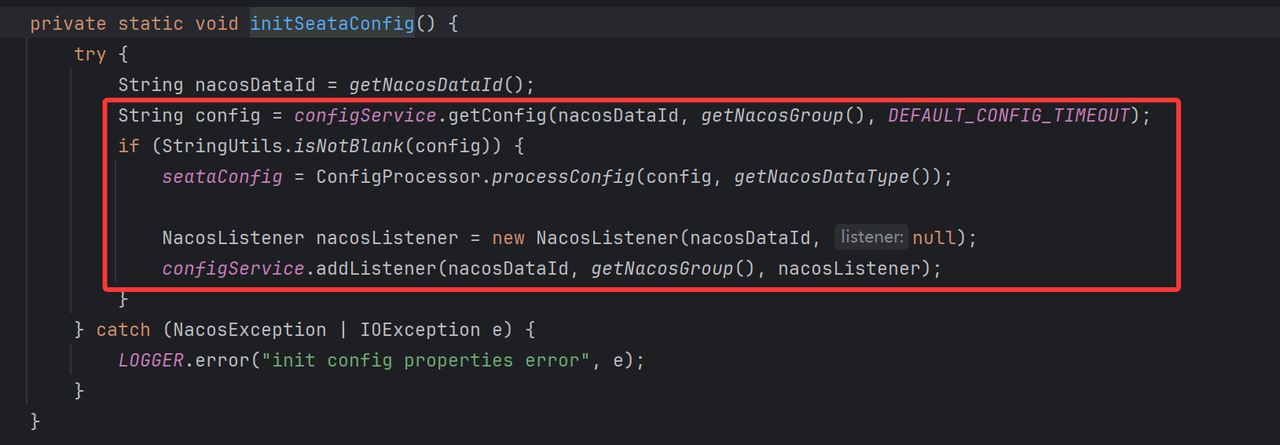
需要注意的是,通常nacos配置中心的全局配置我们会将seata服务端系统配置和客户端配置放到一起,但是本质上可以是分开的。例如客户端主要是需要读取集群分组:service.vgroupMapping.default_tx_group=default(虽然叫group,本质上对应的nacos的cluster)
本质上就是在做集群环境隔离。
-
在以上Nacos注册中心配置时,默认cluster为default,那么未来seata-server会注册到nacos,并在default集群下
-
seata客户端作为TM或者RM,需要从注册中心拉去Seata-servetr实例,进行连接。此时会优先读取service.vgroupMapping.default_tx_group=default配置,获取到指定集群,然后拉取该集群下的seata-server实例,如果此处如果不能对应,则无法拉去到seata服务端实例。
❇️ TM初始化
在完成了Seata配置读取之后,便开始了当前客户端TM的注册工作,需要了解的是,所有的客户端只要引入了seata依赖,即装配了GlobalTransactionScanner,就会初始化为TM,本质上就是创建了一个Netty客户端,建立与TC的TM通道,在运行态只要使用了全局事务注解,便会使用该通道进行通信,行使TM职责。
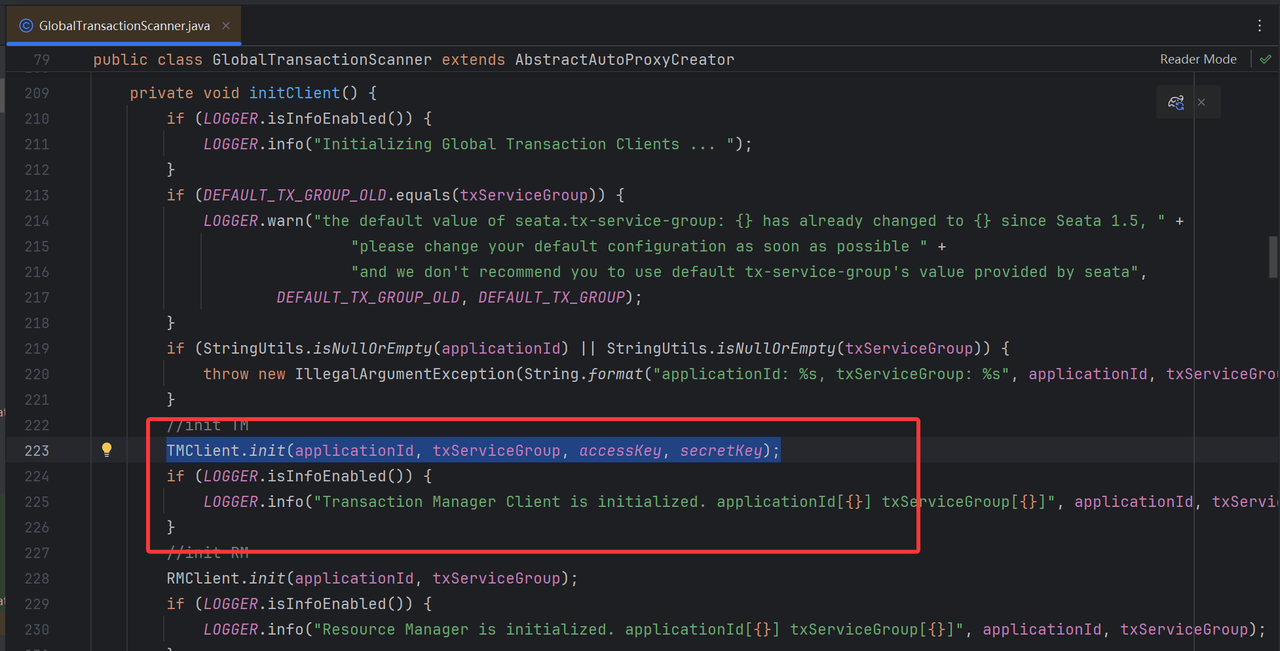
TM客户端使用了TmNettyRemotingClient实现类初始化,其中核心干了两件事:
- 注册返回执行器
把「TC 发回给 TM 的每一种响应 / 消息」和「对应的处理逻辑 + 线程池」绑定起来,用于处理TC的不同消息返回。
TYPE_GLOBAL_BEGIN_RESULT:全局事务开启结果 TYPE_GLOBAL_COMMIT_RESULT:全局提交结果 TYPE_GLOBAL_ROLLBACK_RESULT:全局回滚结果 TYPE_GLOBAL_STATUS_RESULT:全局事务状态查询结果 TYPE_REG_CLT_RESULT:TM 客户端注册结果 TYPE_SEATA_MERGE_RESULT:批量消息结果
-
基于Netty建立与TC的通信连接,该过程内部细分为:
-
通过seata集群分组,从注册中心找到TC实例
-
对每个 TC 节点异步创建 Netty 长连接(核心)
-
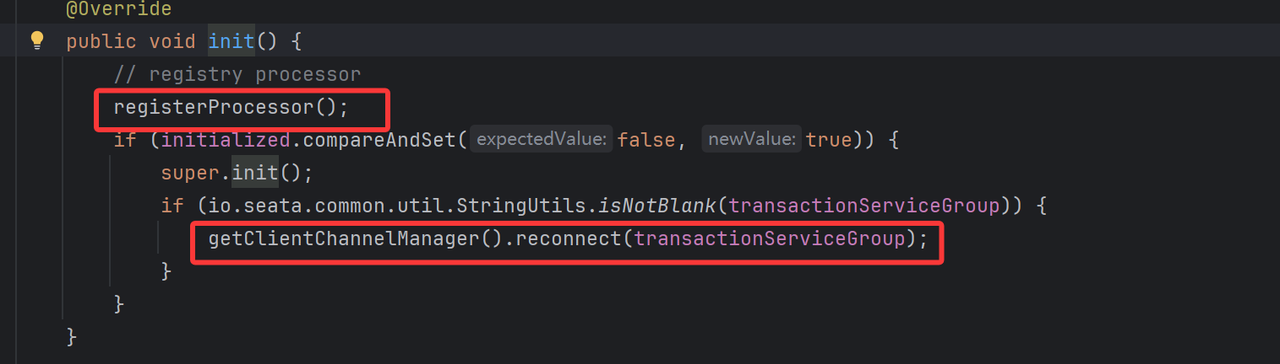
下面核心说下基于Netty建立与TC的通信连接过程
transactionServiceGroup值为application.yml中配置的seata.tx-service-group: default_tx_group
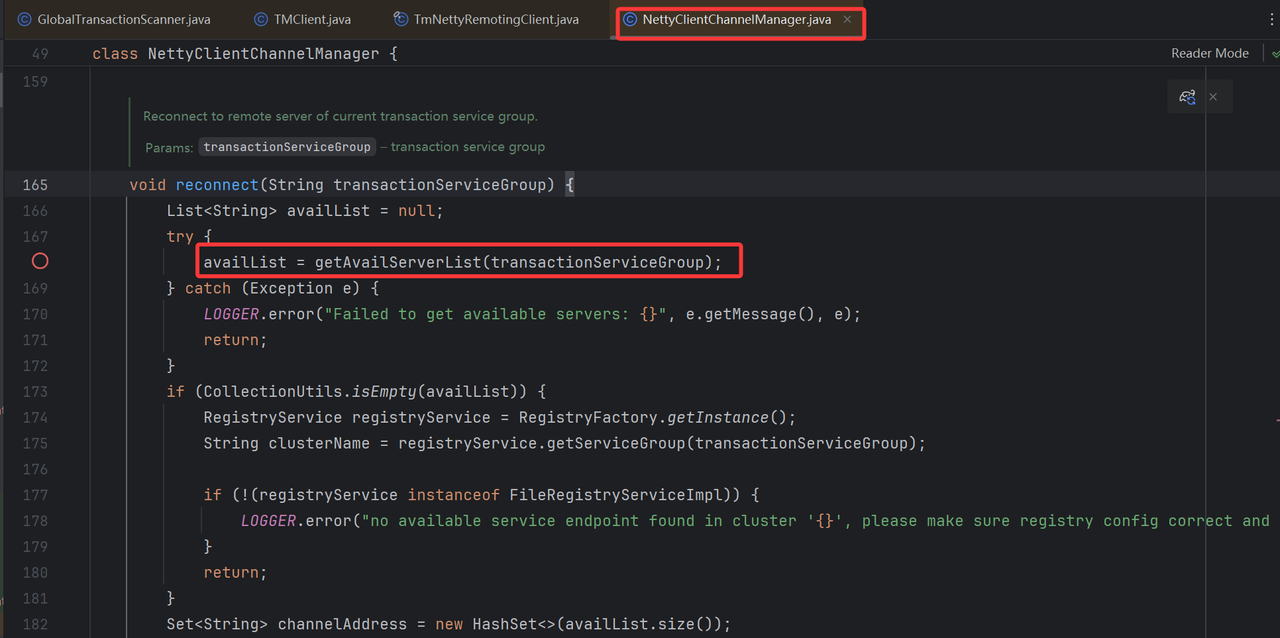
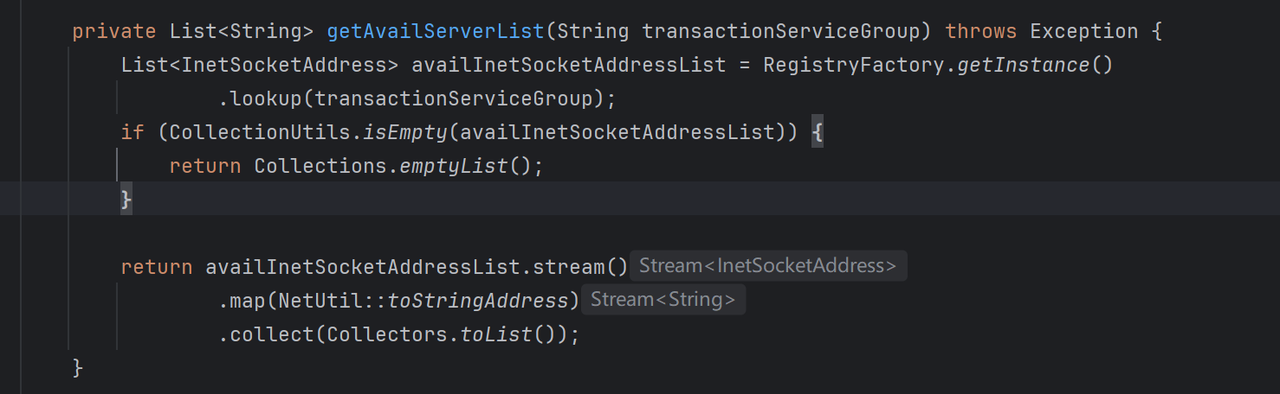
@Override
public List<InetSocketAddress> lookup(String key) throws Exception {
// 1. 读取指定集群配置,即读取配置中心中配置的:service.vgroupMapping.default_tx_group = default
String clusterName = getServiceGroup(key);
if (clusterName == null) {
String missingDataId = PREFIX_SERVICE_ROOT + CONFIG_SPLIT_CHAR + PREFIX_SERVICE_MAPPING + key;
throw new ConfigNotFoundException("%s configuration item is required", missingDataId);
}
if (useSLBWay) {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("look up service address of SLB by nacos");
}
if (!CLUSTER_ADDRESS_MAP.containsKey(PUBLIC_NAMING_ADDRESS_PREFIX + clusterName)) {
Service service = getNamingMaintainInstance().queryService(DEFAULT_APPLICATION, clusterName);
String pubnetIp = service.getMetadata().get(PUBLIC_NAMING_SERVICE_META_IP_KEY);
String pubnetPort = service.getMetadata().get(PUBLIC_NAMING_SERVICE_META_PORT_KEY);
if (StringUtils.isBlank(pubnetIp) || StringUtils.isBlank(pubnetPort)) {
throw new Exception("cannot find service address from nacos naming mata-data");
}
InetSocketAddress publicAddress = new InetSocketAddress(pubnetIp,
Integer.valueOf(pubnetPort));
List<InetSocketAddress> publicAddressList = Arrays.asList(publicAddress);
CLUSTER_ADDRESS_MAP.put(PUBLIC_NAMING_ADDRESS_PREFIX + clusterName, publicAddressList);
return publicAddressList;
}
return CLUSTER_ADDRESS_MAP.get(PUBLIC_NAMING_ADDRESS_PREFIX + clusterName);
}
if (!LISTENER_SERVICE_MAP.containsKey(clusterName)) {
synchronized (LOCK_OBJ) {
if (!LISTENER_SERVICE_MAP.containsKey(clusterName)) {
List<String> clusters = new ArrayList<>();
clusters.add(clusterName);
// 2. 读取指定cluster下的seata服务端实例
// getServiceName()为 application.yml中的seata.registry.nacos.application
// getServiceGroup() 为 application.yml中的seata.registry.nacos.group
// clusters为上述从配置中心拿到的集群分组信息
List<Instance> firstAllInstances = getNamingInstance().getAllInstances(getServiceName(), getServiceGroup(), clusters);
if (null != firstAllInstances) {
// 3. 每个TC实例都创建Socket对象
List<InetSocketAddress> newAddressList = firstAllInstances.stream()
.filter(eachInstance -> eachInstance.isEnabled() && eachInstance.isHealthy())
.map(eachInstance -> new InetSocketAddress(eachInstance.getIp(), eachInstance.getPort()))
.collect(Collectors.toList());
CLUSTER_ADDRESS_MAP.put(clusterName, newAddressList);
}
subscribe(clusterName, event -> {
List<Instance> instances = ((NamingEvent) event).getInstances();
if (CollectionUtils.isEmpty(instances) && null != CLUSTER_ADDRESS_MAP.get(clusterName)) {
LOGGER.info("receive empty server list,cluster:{}", clusterName);
} else {
List<InetSocketAddress> newAddressList = instances.stream()
.filter(eachInstance -> eachInstance.isEnabled() && eachInstance.isHealthy())
.map(eachInstance -> new InetSocketAddress(eachInstance.getIp(), eachInstance.getPort()))
.collect(Collectors.toList());
CLUSTER_ADDRESS_MAP.put(clusterName, newAddressList);
}
});
}
}
return CLUSTER_ADDRESS_MAP.get(clusterName);
}❇️ RM初始化
同样的道理,所有的客户端只要引入了seata依赖,即装配了GlobalTransactionScanner,就会初始化为RM,本质上就是创建了一个Netty客户端,建立与TC的RM通道,在运行态只要使用了全局事务注解,便会使用该通道进行通信,行使RM职责。
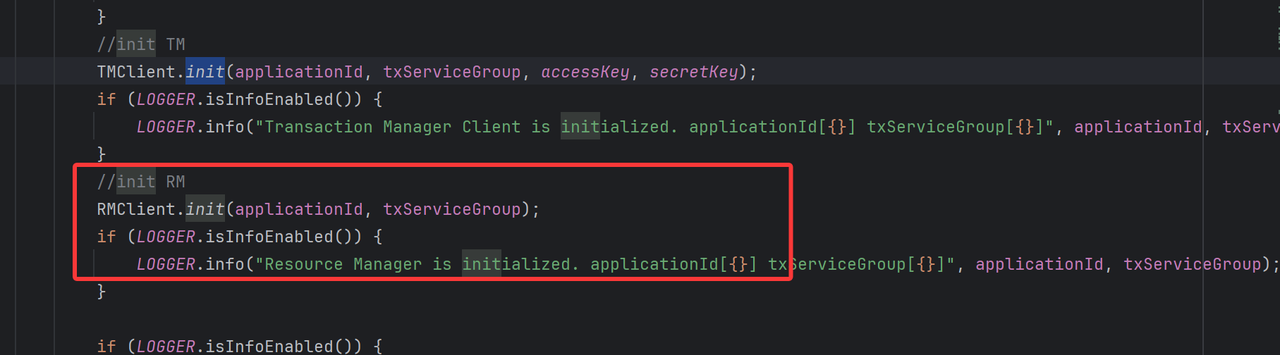
- 创建 资源管理器DefaultResourceManager
与TM不同的是,RM客户端初始化时,会初始化资源管理器DefaultResourceManager,因为RM是真正进行数据库操作的角色,因此它需要持有资源管理信息。
- 获取 事务指令处理器
同时DefaultRMHandler.get () 获取 RM 全局唯一的事务指令处理器,负责接收并处理 TC 下发的分支提交、分支回滚请求,是 RM 处理二阶段事务的核心入口。

- 注册各种 Netty 处理器(Processor)
注册 branchCommit 处理器
注册 branchRollback 处理器
注册 undo_log 删除 处理器
注册全局锁检查 处理器
注册心跳处理器
- 与 TC 建立并保持长连接

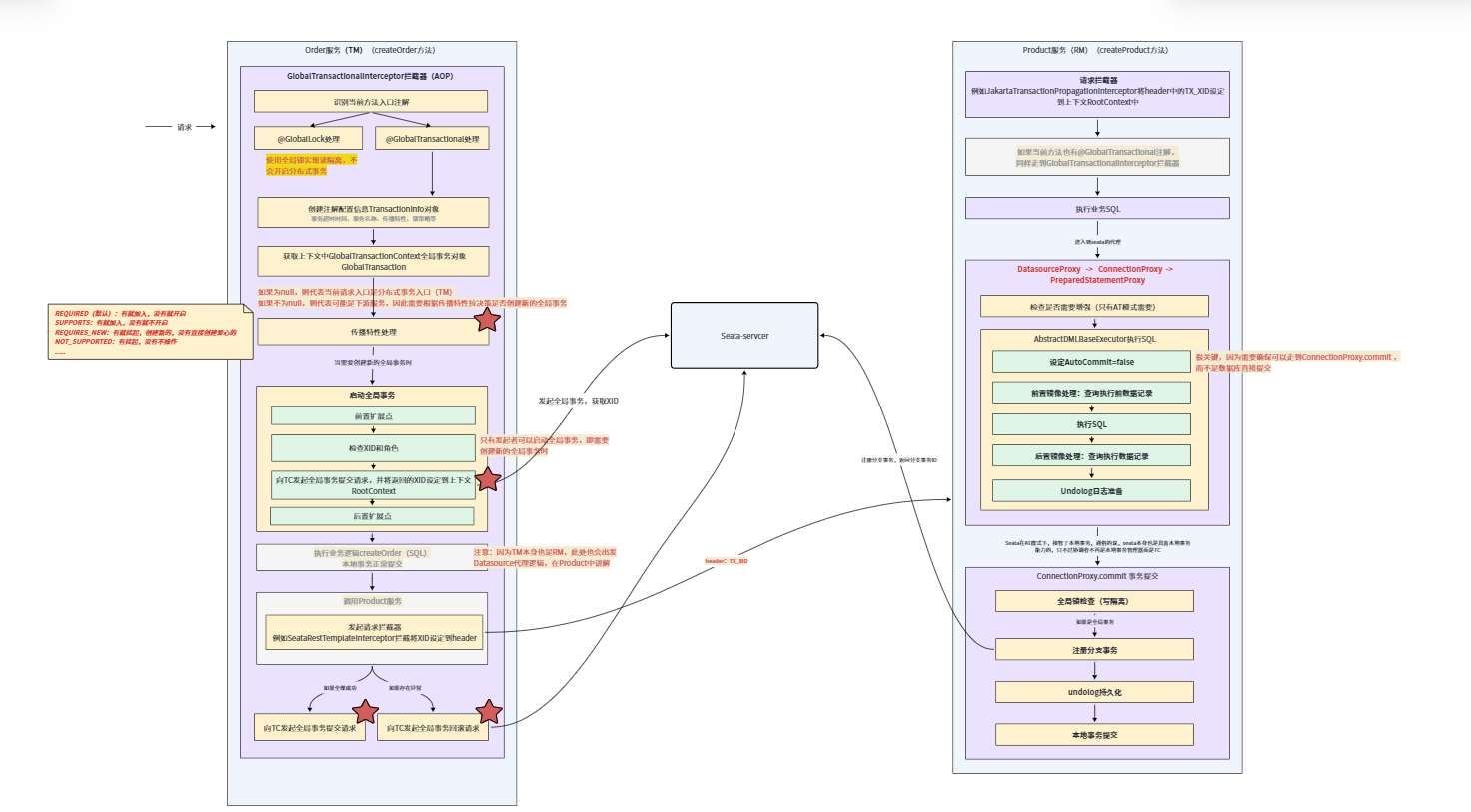
❇️ @GlobalTransactional / @GlobalLock / TCC Bean代理机制(AOP)
@GlobalTransactional 是开启并控制全局分布式事务的核心注解
@GlobalLock 用于在非事务场景下启用全局锁以保证读隔离,避免与分布式事务产生脏写冲突。
这里代理主要是对存在以上注解的Bean进行代理,核心目的是:在运行态 通过 AOP 拦截业务 Bean 方法调用,识别方法上的 @GlobalTransactional / @GlobalLock 注解,从而执行对应的分布式事务管控逻辑(AT模式下核心拦截器为GlobalTransactionalInterceptor):
若方法被
@GlobalTransactional标记:当前服务扮演 TM 角色,开启完整分布式事务生命周期,包括向 TC 申请 XID、链路透传 XID、以及全局事务的提交或回滚。若方法被
@GlobalLock标记:不开启全局事务,仅启用 Seata 全局锁机制,保证数据操作的全局互斥性。若无相关注解:直接放行,不执行任何分布式事务增强逻辑。
通俗的说,seata需要拦截标记@GlobalTransactional注解的Bean,来实现TM职责。
GlobalTransactionalInterceptor 拦截器的核心职责是识别并扮演 TM(事务管理器)角色,负责全局事务的生命周期管控,
包括全局事务的开启、XID 传递、全局提交或全局回滚决策。但它并不执行实际的数据层面事务操作,
真正的本地事务提交、回滚以及 undo_log 处理,都是由 RM(资源管理器) 自身完成的。源码入口: GlobalTransactionScanner继承AbstractAutoProxyCreator成为 Spring AOP 代理创造者,Spring 会在每个 Bean 创建完成后自动回调它。wrapIfNecessary() 核心逻辑为:
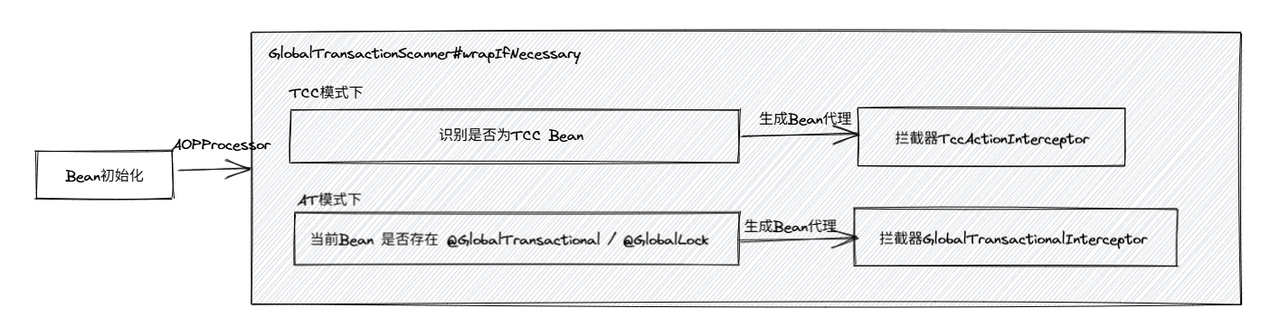
❇️ DatasourceProxy
作为RM需要实际完成数据库操作,在分布式事务场景下(AT),需要在数据库操作前后完成能力增强,例如数据镜像查询、undolog记录等。
SeataAutoDataSourceProxyCreator 通过继承 AbstractAutoProxyCreator,在 Spring 容器启动阶段 的 wrapIfNecessary() 中,对数据源(DataSource)进行统一代理封装,进而在运行时自动代理 Connection、Statement 等核心对象。
通过这种方式,Seata 接管了本地事务的执行过程,实现了 SQL 拦截、undo_log 生成与恢复、全局锁检查以及分支事务的注册与上报,最终支撑起 AT 模式的分布式事务一致性。
客户端 - 运行态
如前文所述,在引入 Seata 依赖后,应用启动时会自动完成客户端核心初始化工作,主要包括两部分:
对包含
@GlobalTransactional/@GlobalLock注解方法的业务 Bean 创建 AOP 代理,并在运行时通过GlobalTransactionalInterceptor拦截器控制全局事务生命周期与全局锁逻辑。同时通过
SeataAutoDataSourceProxyCreator对 Spring 容器中的DataSource创建代理包装,在运行时以 RM 角色接管 JDBC 操作,实现分支事务管理、undo_log 处理与全局锁校验,支撑 AT 模式分布式事务运行。
❇️ TM核心逻辑
GlobalTransactionalInterceptor 是 Seata TM 角色的运行态入口(前置拦截器),它不处理 SQL、不管理本地事务,只负责:全局事务生命周期 + 注解分发 + 上下文管理。
识别@GlobalTransactional还是GlobalLock
如果@GlobalTransactional则代表是TM,即分布式事务入口,走TM相关逻辑**(核心)**
如果是GlobalLock,则进入到分布式锁逻辑(读隔离逻辑,无分布式事务)
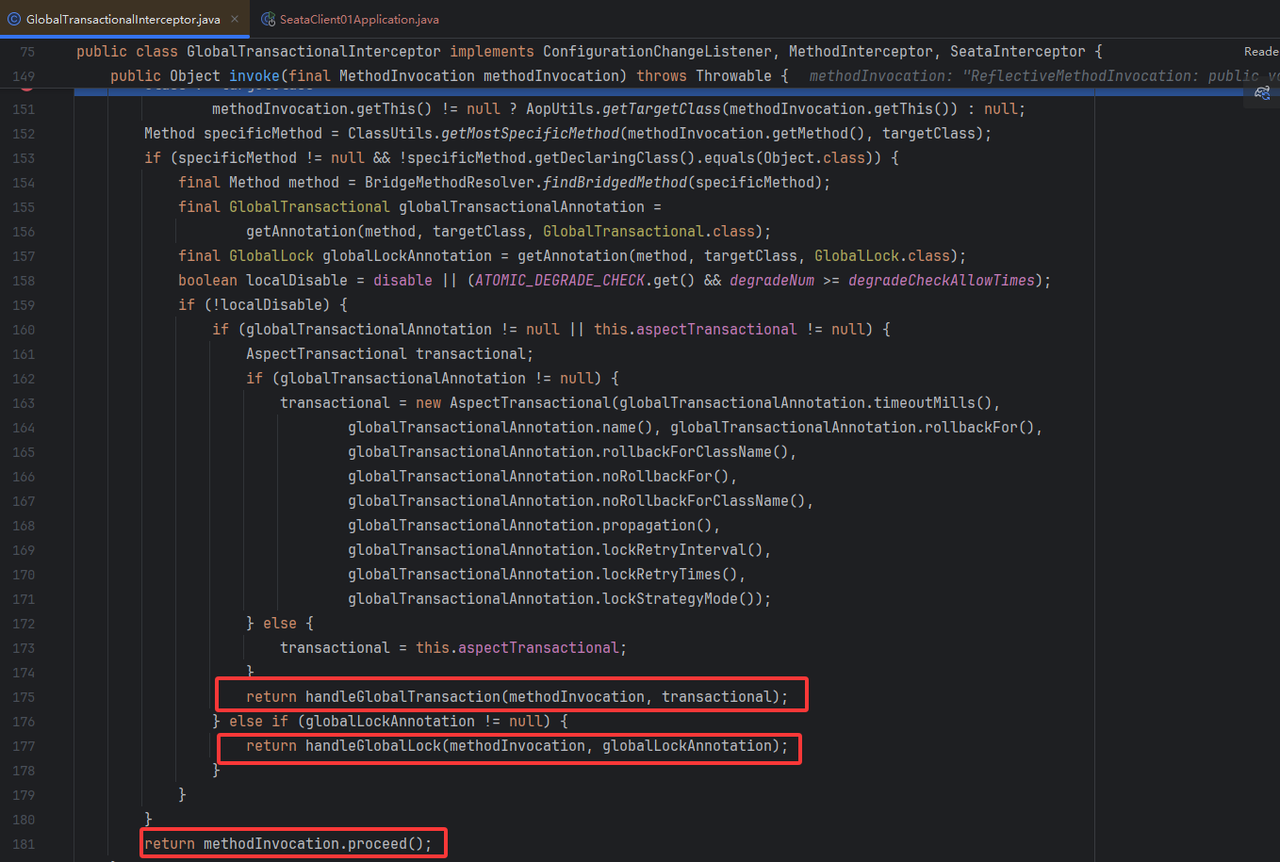
这里我们核心关注分布式事务的逻辑handleGlobalTransaction,核心为TransactionalTemplate#execute
⭐ 创建事务对象TransactionInfo
通过从@GlobalTransactional 注解里读取配置,创建事务信息对象,其中包括:事务超时时间、事务名称、传播特性、锁策略等等。
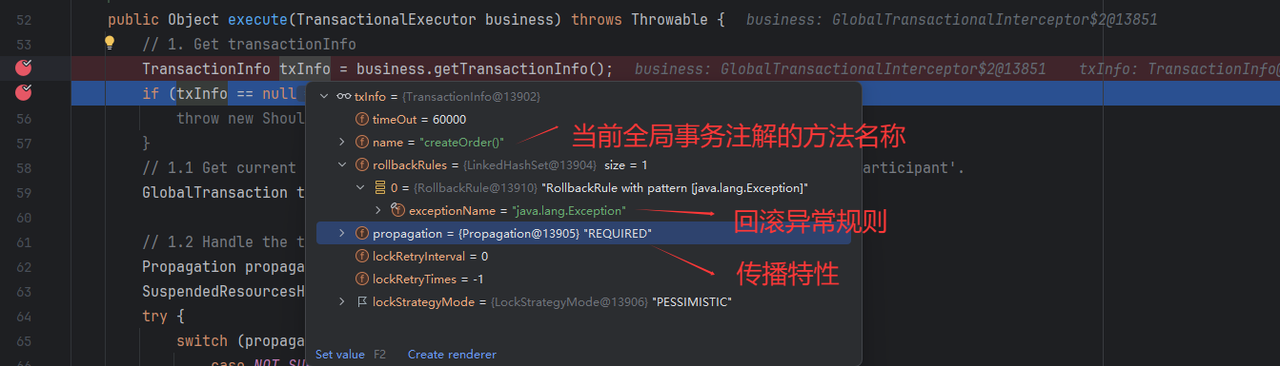
⭐ 线程上下文读取全局事务GlobalTransaction
从当前线程全局事务上下文中,读取全局事务,如果存在,则代表当前角色是一个事务的参与者,这种情况为A调用B,A和B都加上了全局事务注解。需要结合后续传播特性来决策是否创建新的全局事务。
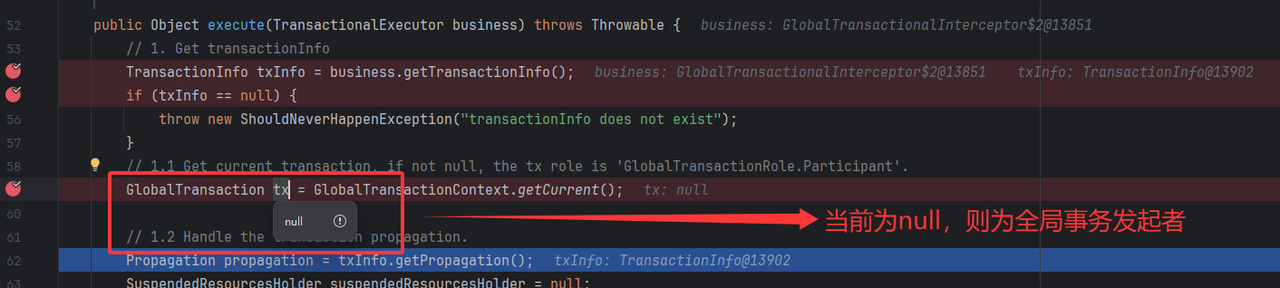
⭐ 传播特性处理
switch (propagation) {
case NOT_SUPPORTED:
// 如果当前事务已经存在,则挂起当前全局事务,最终不执行任何事务
if (existingTransaction(tx)) {
suspendedResourcesHolder = tx.suspend(false);
}
return business.execute();
case REQUIRES_NEW:
// 如果当前事务已经存在,则挂起当前事务,并创建新的全局事务,最终返回的新的全局事务
if (existingTransaction(tx)) {
suspendedResourcesHolder = tx.suspend(false);
}
// 创建全局事务比较简单,本质上就是创建一个DefaultGlobalTransaction对象
tx = GlobalTransactionContext.createNew();
break;
case SUPPORTS:
// 有就加入,没有就不开启
if (notExistingTransaction(tx)) {
return business.execute();
}
// Continue and execute with new transaction
break;
case REQUIRED:
// 默认 如果当前事务存在,则加入当前事务,如果不存在,则创建新事物
tx = GlobalTransactionContext.getCurrentOrCreate();
break;
case NEVER:
// If transaction is existing, throw exception.
if (existingTransaction(tx)) {
throw new TransactionException(
String.format("Existing transaction found for transaction marked with propagation 'never', xid = %s"
, tx.getXid()));
} else {
// Execute without transaction and return.
return business.execute();
}
case MANDATORY:
// If transaction is not existing, throw exception.
if (notExistingTransaction(tx)) {
throw new TransactionException("No existing transaction found for transaction marked with propagation 'mandatory'");
}
// Continue and execute with current transaction.
break;
default:
throw new TransactionException("Not Supported Propagation:" + propagation);
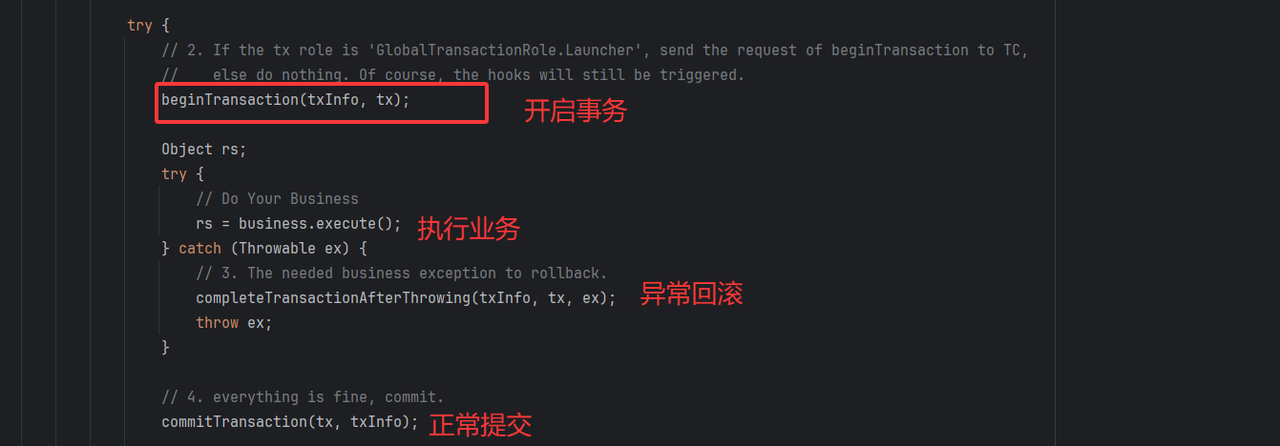
}⭐ 向TC发起启动全局事务
如果当前角色是事务发起者,则启动全局事务beginTransaction
执行前扩展点,用于做业务上的扩展,例如日志、监控、链路追踪、自定义拦截
真正开启全局事务(核心)
执行后扩展点
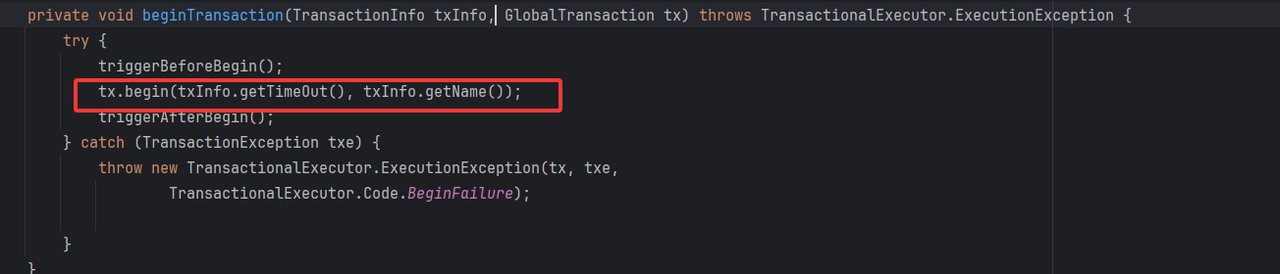
下面核心关注开启全局事务过程
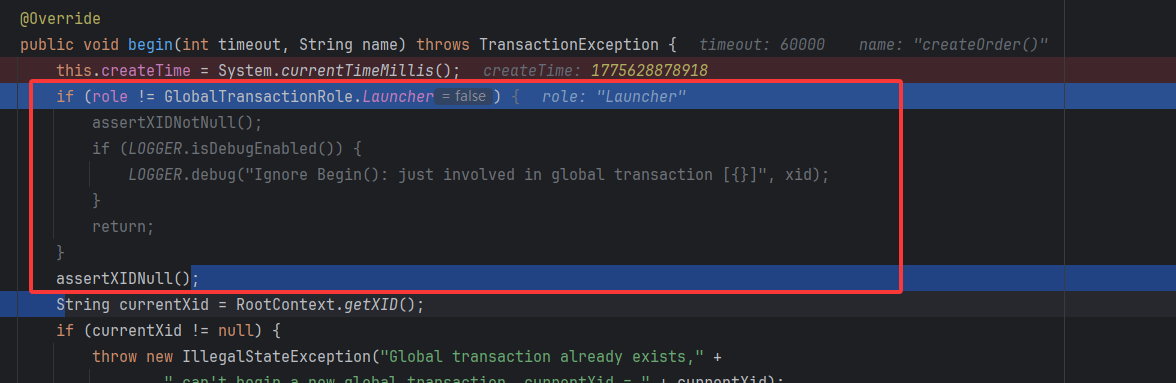
♦️ 角色和XID检查
因为只有事务发起者,也是TM才能进入到当前逻辑
♦️ 从TC获取XID,并绑定到上下文
这里也正好对应上了,TM在初始化时通过TmNettyRemotingCLient常见了连接,这里通过该连接通道通信,向TC开启一个全局事务,并返回XID


当完整全局的事务创建之后,就开始调用业务逻辑,并通过trycatch方式进行异常回滚和正常提交处理
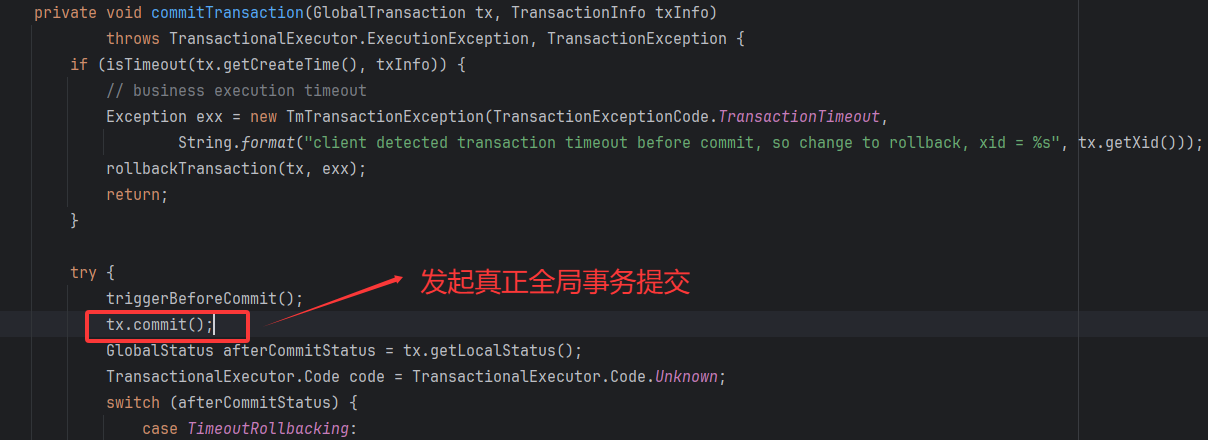
⭐ 向TC发起全局事务提交请求
因为TM是全局事务的发起者,因此它可以主动感知到事务的结束。但逻辑走到commitTransaction就意味着,整个分布式链路上执行过程一切正常。
其核心为:
- 传递XID通知TC全局提交请求
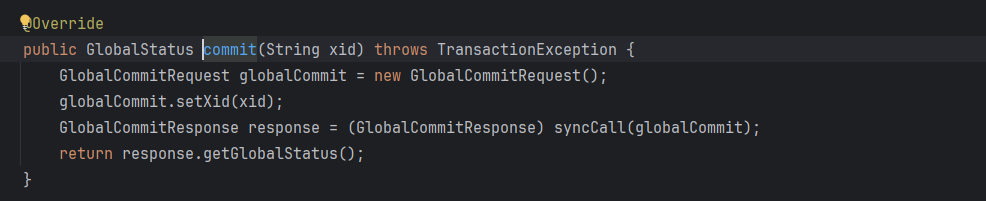
⭐ 向TC发起全局事务就回滚请求(与上类似)
❇️ RM核心逻辑
因为对于RM来说,核心就是【收到 XID → 执行 SQL → 生成 undo_log → 注册分支 → 接收 TC 指令 → 提交 / 回滚】
上面说到所有的RM\TM的Datasource都会被代理,即接管本地事务,代理Datasource的核心目的就是获取到ConnectionProxy和PreparedStatementProxy,因为它们是真正处理数据库操作的。
即:DatasourceProxy -> ConnectionProxy -> PreparedStatementProxy
@Override
public Connection getConnection() {
// 返回 连接代理对象
return new ConnectionProxy(
targetConnection,
dataSourceProxy,
RootContext.getXID() // ✅ 从 ThreadLocal 获取 XID
);
}PreparedStatementProxy会在SQL执行前后做增强处理
⭐ 检查是否需要进行增强
只有AT模式 下,或者GlobalLock(读隔离时)会进行增强
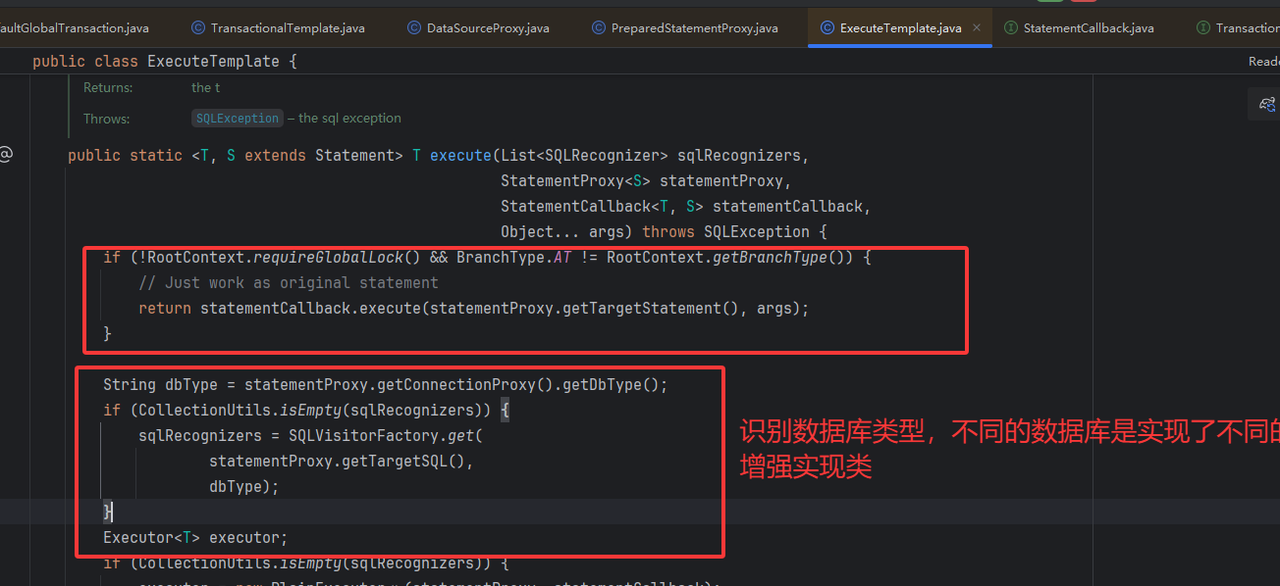
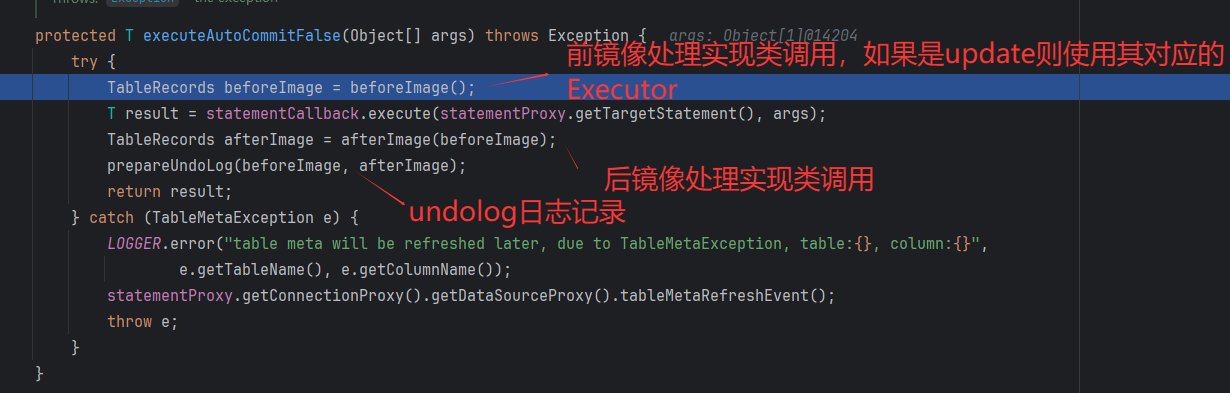
⭐ SQL执行器Executor增强
AbstractDMLBaseExecutor是所有Executor的父类,实现了基础公共的逻辑,实际运行时,执行的是 子类(UpdateExecutor)重写的方法
前置镜像处理:查询执行前数据记录
执行SQL
后置镜像处理:查询执行数据记录
Undolog日志准备
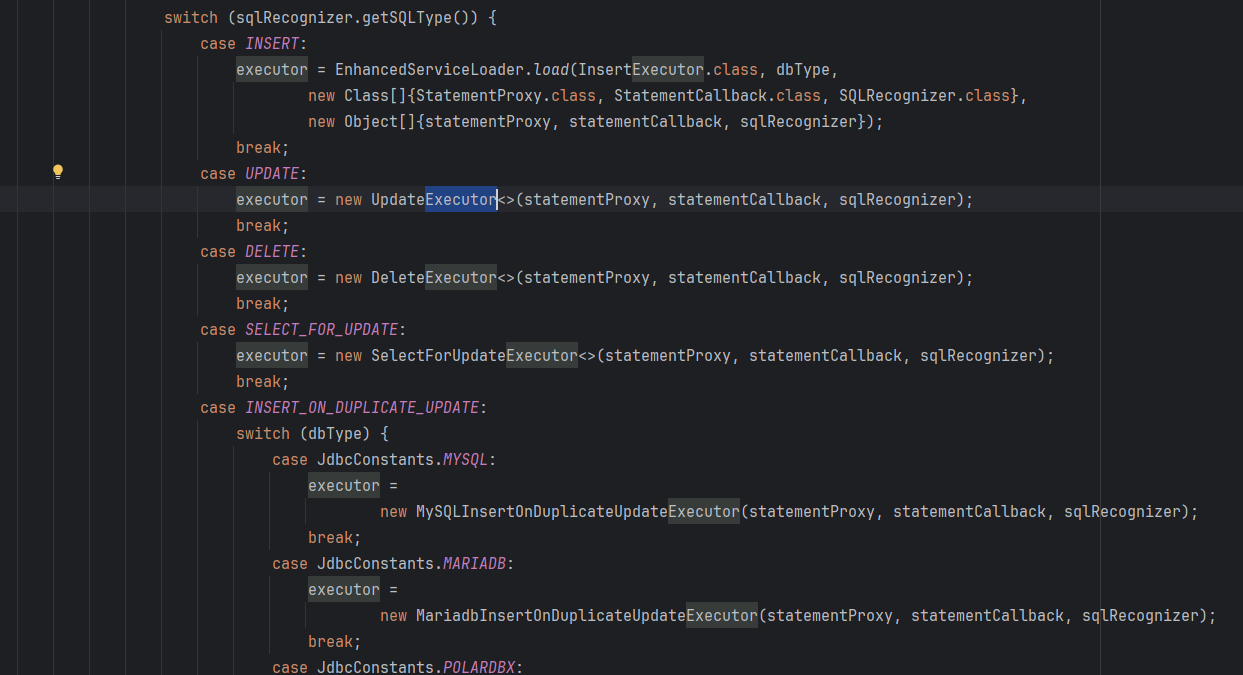
UpdateExecutor(update类型)
查询前镜像
执行 update
查询后镜像
生成undo_log
全局锁检查
DeleteExecutor(deleta类型)
查询删除前数据(前镜像)
执行 delete
生成 undo_log
InsertExecutor
执行 insert
记录主键
生成 undo_log(回滚时删除)
SelectForUpdateExecutor(@GlobalLock注解拦截器中,会自动帮我们加上 for update)
执行查询
对返回的行进行全局锁校验
需要注意的是:这里不同执行器本身
到此为止,业务 SQL 已执行,beforeImage、afterImage 已获取、undo_log 已构建、lockKey 已生成,全部暂存在 ConnectionProxy
⭐ 本地事务提交 ConnectionProxy.commit
因为AT模式下本地事务会在就结束后提交,Seata在AT模式下,接管了本地事务,通俗的说,seata本身也是具备本地事务能力的,只不过协调者不再是本地事务管理器而是TC
- 事务提交前全局锁检查
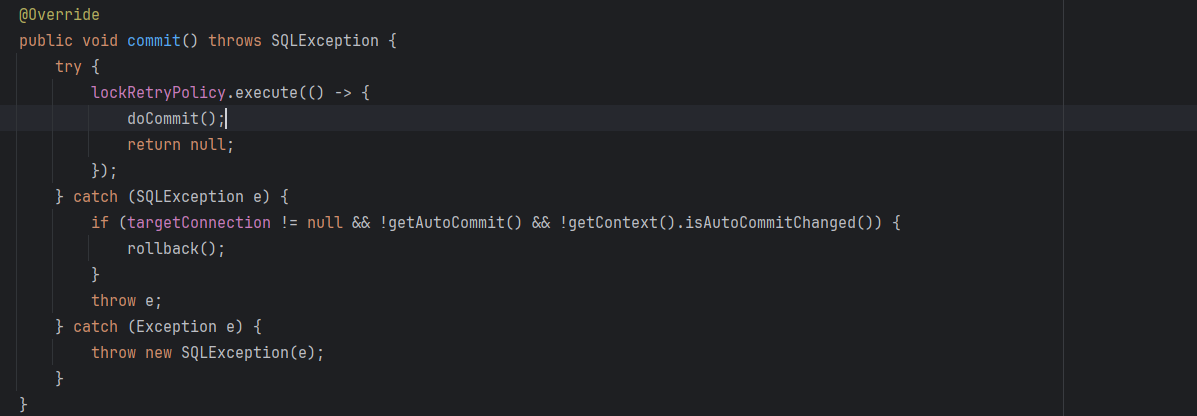
如果当前不是全局事务,即xid为空,则直接执行commit
如果是全局事务,则提交全局事务
如果是Lock,则提交全局锁
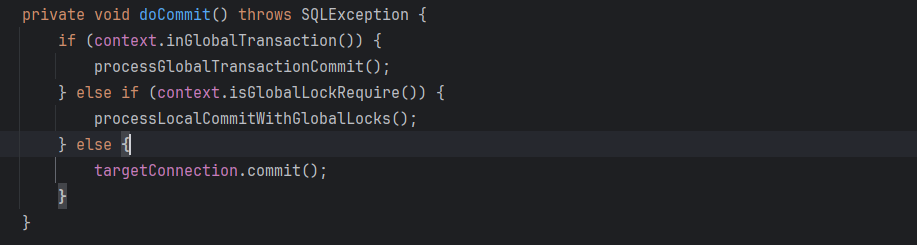
- 提交全局事务
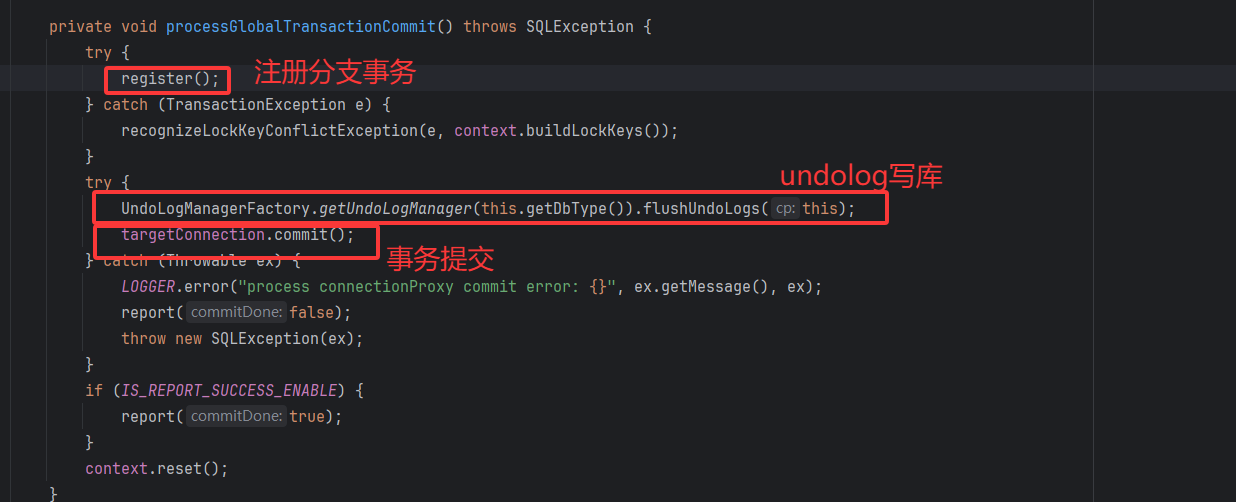
注册分支事务
分支事务是指不同的注册的事务提交,例如A容器调用B容器方法,因为他们有各自的Connection,因此会有两个分支事务,但是如果是B容器中,不同方法之间的调用,因为他们都是属于同一个Connnection,因此属于同一个分支事务。
因此一个XID中可能会存在多个分支事务,TC下发提交和回滚指令都是基于分支事务级别。
undolog持久化
本地事务提交
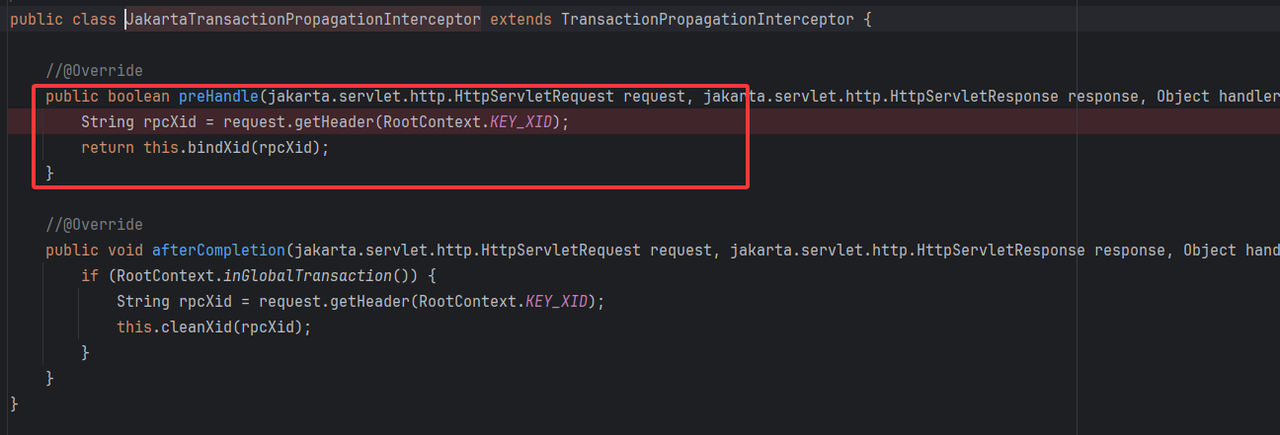
❇️ XID传递
Seata对于XID是通过header传递的。因此上游服务再发起请求时,需要将XID设定到header,下游请求需要将XID读取设定到上下文。
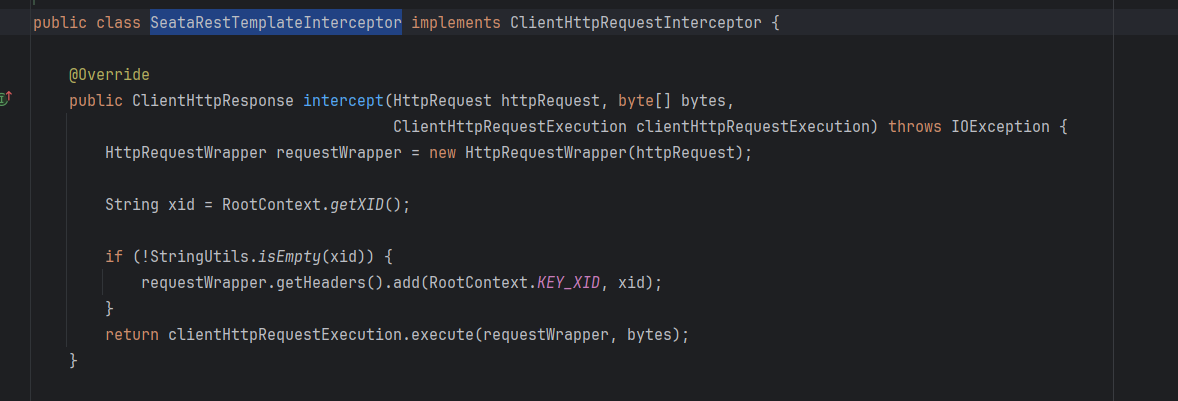
⭐ 发起请求拦截器
发起请求拦截器严格说起来并不能算seata自身内容,而是第三方对seata落地的一种支持。seata对于XID是通过header传递的。因此上游服务再发起请求时,就需要手动或者自动的完成xid的设定。通常seata对于一些常规调用框架,已经做了相关的支持,本质上就是在实际调用前进行拦截,从上下文RootContext中读取XID,并设定到header中,固定key为TX_XID。例如Restemplate、Openfeign等等
这里以Spring Restemplate为例简单说明,Spring Cloud 实现了SeataRestTemplateInterceptor拦截器,目的就是发起请求前读取并设定XID
**所以需要注意的是:**如果项目使用了Restemplate,并自己进行了初始化配置时,一定要手动将SeataRestTemplateInterceptor注册到拦截器中,否则无法传递XD
@Bean public RestTemplate restTemplate() { RestTemplate restTemplate = new RestTemplate(); // 添加Seata的XID传递拦截器 restTemplate.setInterceptors(Collections.singletonList(new SeataRestTemplateInterceptor())); return restTemplate; }
⭐ 请求拦截器
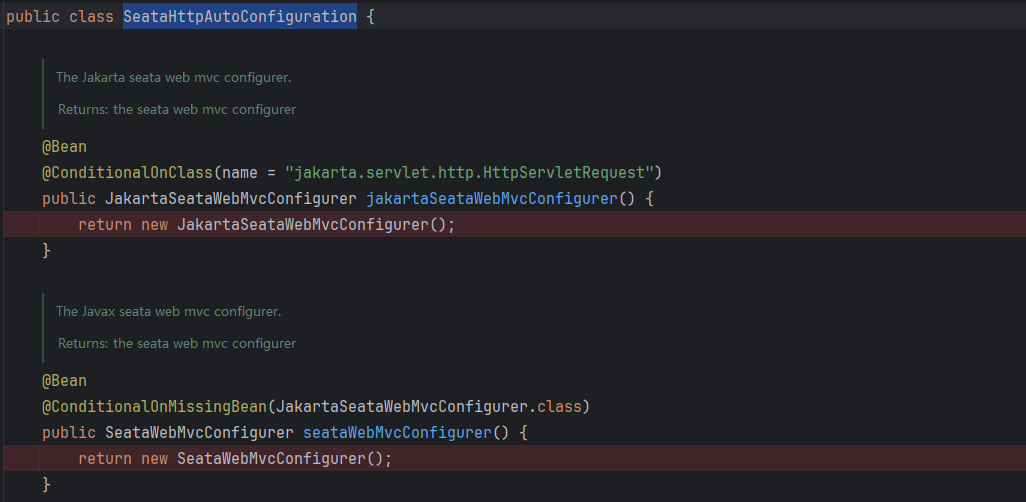
上述说到的是上游服务在发起请求时的拦截器,将XID塞入到header,那么对于下游服务,则必须要在请求到来时拦截,读取header中的XID,并设定到当前线程上下文RootContext中。 在Spring cloud环境中,通过自动装备类SeataHttpAutoConfiguration 来完成了拦截器的注册,拦截器逻辑也很简单,就是从header中读取XID,并设定到上下文
JakartaSeataWebMvcConfigurer:SpringBoot3.*版本之后使用的
SeataWebMvcConfigurer:SpringBoot3.*版本之前使用的

原理总结
初始化阶段
 运行态
运行态