目录
[1 QK-LSTM 复现(续上周)](#1 QK-LSTM 复现(续上周))
[1.1 数据预处理](#1.1 数据预处理)
[1.2 基线构建与训练](#1.2 基线构建与训练)
[2 总结](#2 总结)
摘要
本周主要在上周的基础上对基线模型进行了训练,同时对预处理部分进行了完善。
Abstract
This week, building on last week's work, I mainly trained the baseline models and further refined the preprocessing part.
1 QK-LSTM 复现(续上周)
1.1 数据预处理
训练时发现每轮loss均为Nan,如下图:
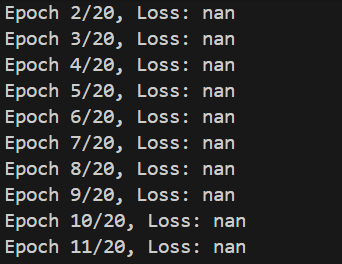
检查代码发现可能是因为插值无法处理首尾数据,导致数据边界处仍存在部分无效值,于是在原插值处理后加入下面代码:
python
df_6months[pollutants] = df_6months[pollutants].ffill().bfill()问题得以解决,可视化效果与上周类似。
1.2 基线构建与训练
模型代码与上周一样,训练部分首先设置超参数;
python
SEQ_LEN = 3 # 序列(论文
INPUT_DIM = 6 # 输入(实际数据)
HIDDEN_DIM = 16 # 隐藏层(论文)
EPOCHS = 20 # 训练轮次(论文)
LR = 1e-3 # 学习率 (论文)
BATCH_SIZE = 1其次,取数据、构造时间序列并划分训练与测试集;
python
# 取数据
X_raw = df_6months_clean[pollutants].values
y_raw = df_6months_clean["AQI"].values.reshape(-1,1)
#归一化
scaler_x = MinMaxScaler()
scaler_y = MinMaxScaler()
X_raw = scaler_x.fit_transform(X_raw)
y_raw = scaler_y.fit_transform(y_raw)
# 时间序列构造(data-污染物特征,target-AQI,seq_len=3-论文参数)
def build_sequences(data, target, seq_len):
X, y = [], []
# 遍历所有时间点,取连续seq_len天作为输入,再后一天作为目标
for i in range(len(data) - seq_len):
X.append(data[i:i+seq_len])
y.append(target[i+seq_len])
return np.array(X), np.array(y)
# 构建序列数据
X, y = build_sequences(X_raw, y_raw, SEQ_LEN)
# 训练测试划分(原文15~19年训练,20年测试)
split = int(len(X) * 5 / 6)
X_train = torch.tensor(X[:split], dtype=torch.float32)
y_train = torch.tensor(y[:split], dtype=torch.float32)
X_test = torch.tensor(X[split:], dtype=torch.float32)
y_test = torch.tensor(y[split:], dtype=torch.float32)然后进行训练;
python
#模型
model = BaselineLSTM(
input_dim=6,
hidden_dim=16,
output_dim=1
)
# 损失与优化
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
for epoch in range(EPOCHS):
model.train()
optimizer.zero_grad() # 清空上一次梯度
output = model(X_train)
loss = criterion(output, y_train)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{EPOCHS}, Loss: {loss.item():.6f}")
model.eval()
with torch.no_grad():
pred = model(X_test)
# 反归一化
pred = scaler_y.inverse_transform(pred.numpy())
y_true = scaler_y.inverse_transform(y_test.numpy())效果如下:
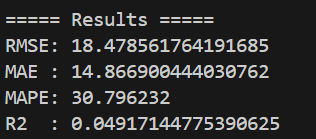
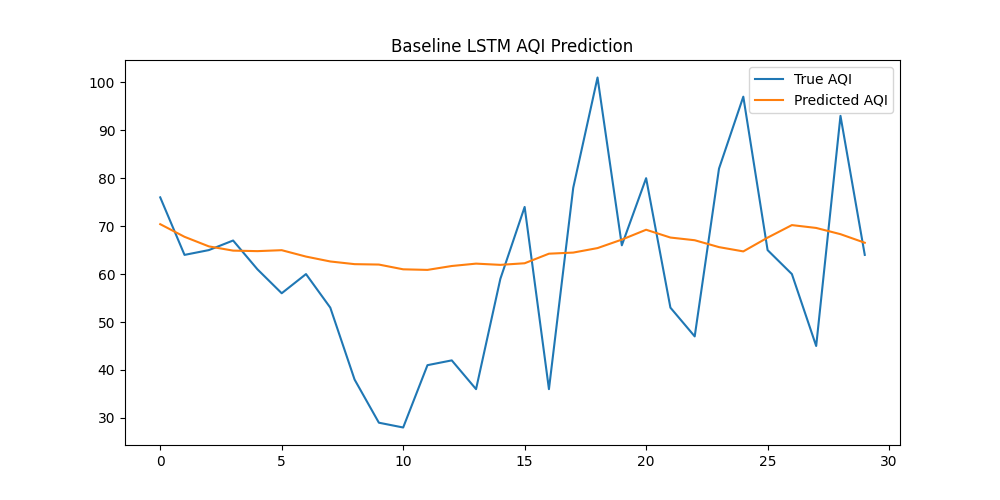
预测曲线总体比较平滑,而真实曲线波动幅度比较大。
2 总结
下周努力一把把剩下的主体都搞了,同时对比一下两个模型的效果,同时训练的时候为了固定结果可以加一个随机种子。