环境准备
yaml
192.168.10.132 ##ELK
192.168.10.133 ##kafka ElasticSearch
部署
修改linux参数,使得适配Elasticsearch
修改默认限制内存
plain
cat >>/etc/security/limits.conf<< EOF
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
* hard memlock unlimited
* soft memlock unlimited
EOF优化内核,对es支持
plain
cat >>/etc/sysctl.conf<< EOF
# 关闭交换内存
vm.swappiness =0
# 影响java线程数量,建议修改为262144或者更高
vm.max_map_count= 262144
# 优化内核listen连接
net.core.somaxconn=65535
# 最大打开文件描述符数,建议修改为655360或者更高
fs.file-max=655360
# 开启ipv4转发
net.ipv4.ip_forward= 1
EOF重启使配置生效
plain
reboot拉取镜像
plain
docker pull elasticsearch:7.17.28
## 使用镜像源加速
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/elasticsearch:7.17.28
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/elasticsearch:7.17.28 elasticsearch:7.17.28挂载目录
plain
mkdir -p /usr/local/docker/elk/es/data
mkdir -p /usr/local/docker/elk/es/logs
mkdir -p /usr/local/docker/elk/es/config
chmod a+w /usr/local/docker/elk/es/data
chmod a+w /usr/local/docker/elk/es/logs
chmod a+w /usr/local/docker/elk/es/config创建配置文件
plain
vim /usr/local/docker/elk/es/config/elasticsearch.yml
plain
cluster.name: my-application
network.host: 0.0.0.0
http.port: 9200
# 开启es跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
# 增加单个节点的最大分片数,太小会影响新索引的创建
cluster.max_shards_per_node: 2000运行
plain
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-v /usr/local/docker/elk/es/data:/usr/share/elasticsearch/data \
-v /usr/local/docker/elk/es/logs:/usr/share/elasticsearch/logs \
-v /usr/local/docker/elk/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms2g -Xmx2g" \
elasticsearch:7.17.28进入elasticsearch容器 运行以下命令
plain
docker exec -it elasticsearch /bin/bash设置密码 按y确认后即可设置密码
plain
elasticsearch-setup-passwords interactive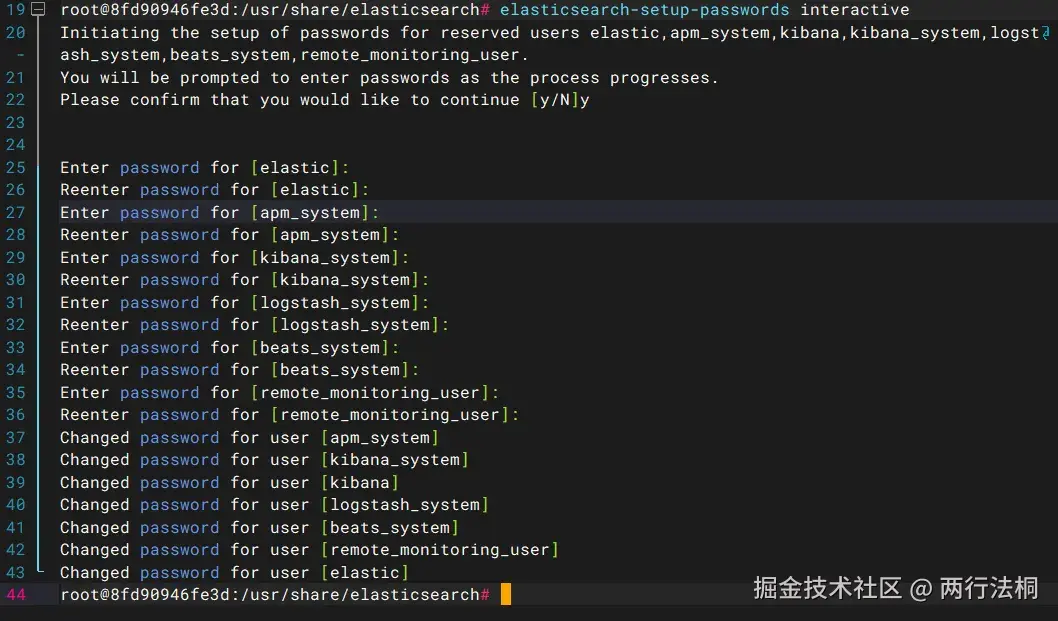
访问ES 输入刚刚设置elastic用户的密码即可访问
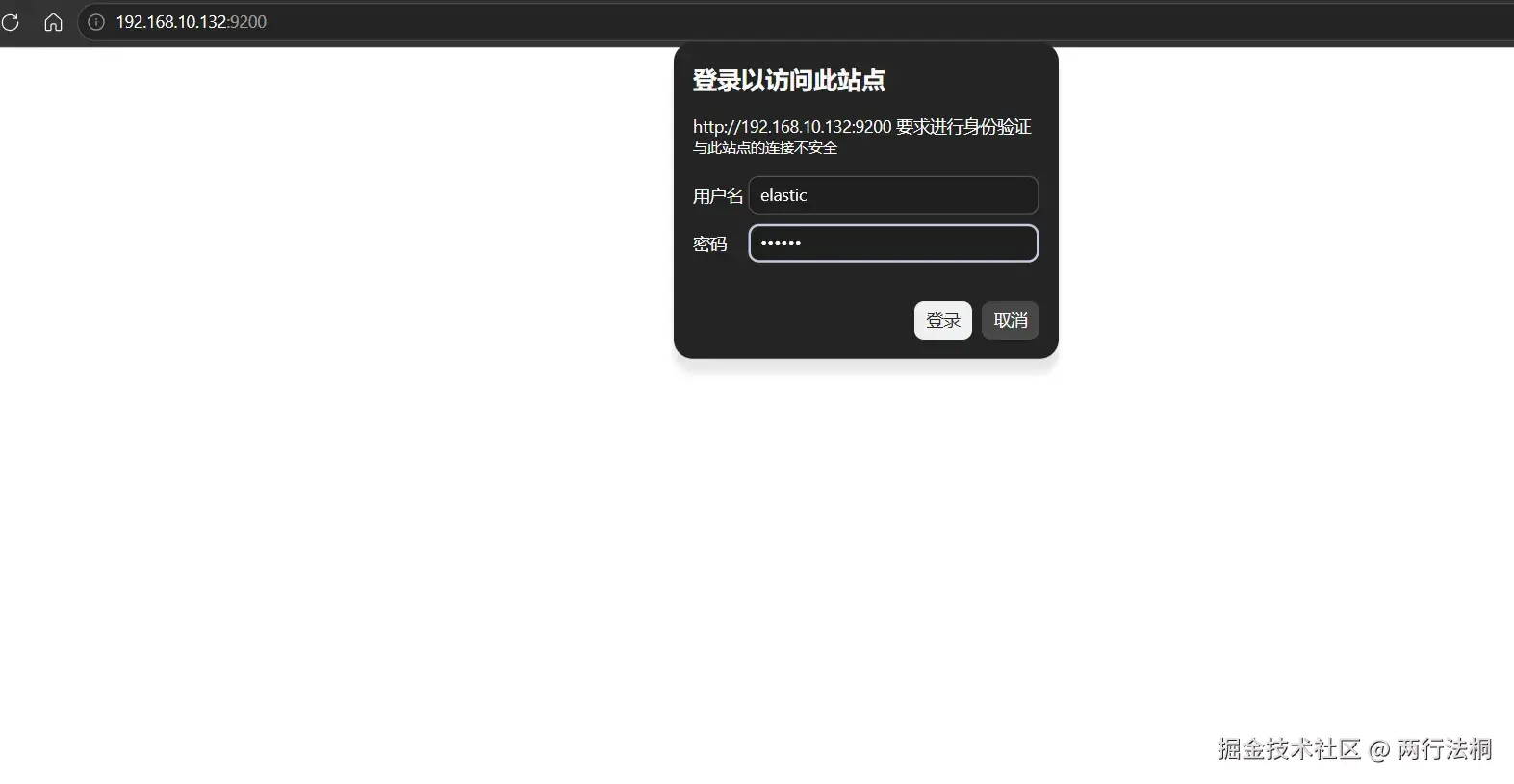
设置自动启动
plain
docker container update --restart=always elasticseatch定时清理过期的es数据
elasticsearch 如何清理过期的数据_es清理过期数据-CSDN博客
安装ik分词器
使用Docker来安装ElasticSearch,并且配置ik分词器本文安装的是ElasticSearch 6.8的版本 - 掘金
Kibana
安装
plain
docker pull kibana:7.17.28
## 国内镜像加速
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/kibana:7.17.28
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/kibana:7.17.28 kibana:7.17.28挂载目录
plain
mkdir -p /usr/local/docker/elk/kibana/config
chmod a+w /usr/local/docker/elk/kibana/config创建配置文件
plain
vim /usr/local/docker/elk/kibana/config/kibana.yml
plain
server.host: 0.0.0.0
server.port: 5601
##注意替换成自己的elastic地址
elasticsearch.hosts: ["http://192.168.10.132:9200"]
elasticsearch.username: "kibana"
elasticsearch.password: "123456"
# 设置kibana为中文
#i18n.locale: "en"
#i18n.locale: "zh-CN"运行
plain
docker run -d --name kibana \
-p 5601:5601 \
-v /usr/local/docker/elk/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml \
kibana:7.17.28访问测试
plain
http://192.168.10.132:5601/使用elastic账号登陆即可
遇到问题
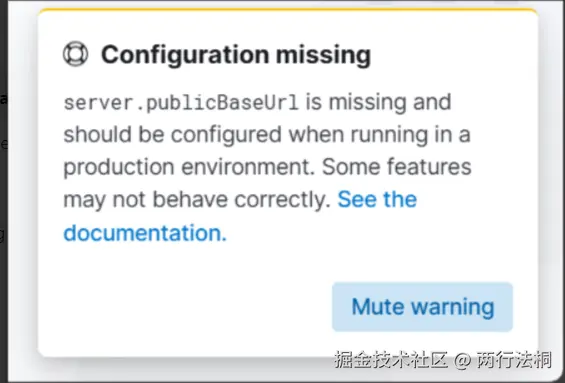
解决:kibana.yml文件增加配置
plain
server.publicBaseUrl: "http://192.168.10.132:5601"重启kibanna服务
plain
docker restart kibana 设置自动启动
plain
docker container update --restart=always kibanaKafka
创建docker集群
- 创建docker-compose-kafka.yml
plain
version: "2"
services:
kafka1:
container_name: kafka1
image: 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/bitnami/kafka'
ports:
- '19092:9092'
- '19093:9093'
environment:
### 通用配置
# 允许使用kraft,即Kafka替代Zookeeper
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_NODE_ID=1
# kafka角色,做broker,也要做controller
- KAFKA_CFG_PROCESS_ROLES=controller,broker
# 定义kafka服务端socket监听端口(Docker内部的ip地址和端口)
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
# 定义外网访问地址(宿主机ip地址和端口)ip不能是0.0.0.0
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.10.133:19092
# 定义安全协议
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
# 集群地址
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
# 指定供外部使用的控制类请求信息
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
# 设置broker最大内存,和初始内存
- KAFKA_HEAP_OPTS=-Xmx512M -Xms256M
# 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可(22byte)
- KAFKA_KRAFT_CLUSTER_ID=xYcCyHmJlIaLzLoBzVwIcP
# 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
- ALLOW_PLAINTEXT_LISTENER=yes
# 允许自动创建主题
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
# broker.id,必须唯一,且与KAFKA_CFG_NODE_ID一致
- KAFKA_BROKER_ID=1
volumes:
- /opt/kafka/broker1:/bitnami/kafka:rw
kafka2:
container_name: kafka2
image: 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/bitnami/kafka'
ports:
- '29092:9092'
- '29093:9093'
environment:
### 通用配置
# 允许使用kraft,即Kafka替代Zookeeper
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_NODE_ID=2
# kafka角色,做broker,也要做controller
- KAFKA_CFG_PROCESS_ROLES=controller,broker
# 定义kafka服务端socket监听端口(Docker内部的ip地址和端口)
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
# 定义外网访问地址(宿主机ip地址和端口)ip不能是0.0.0.0
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.10.133:29092
# 定义安全协议
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
# 集群地址
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
# 指定供外部使用的控制类请求信息
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
# 设置broker最大内存,和初始内存
- KAFKA_HEAP_OPTS=-Xmx512M -Xms256M
# 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可(22byte)
- KAFKA_KRAFT_CLUSTER_ID=xYcCyHmJlIaLzLoBzVwIcP
# 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
- ALLOW_PLAINTEXT_LISTENER=yes
# 允许自动创建主题
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
# broker.id,必须唯一,且与KAFKA_CFG_NODE_ID一致
- KAFKA_BROKER_ID=2
volumes:
- /opt/kafka/broker2:/bitnami/kafka:rw
kafka3:
container_name: kafka3
image: 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/bitnami/kafka'
ports:
- '39092:9092'
- '39093:9093'
environment:
### 通用配置
# 允许使用kraft,即Kafka替代Zookeeper
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_NODE_ID=3
# kafka角色,做broker,也要做controller
- KAFKA_CFG_PROCESS_ROLES=controller,broker
# 定义kafka服务端socket监听端口(Docker内部的ip地址和端口)
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
# 定义外网访问地址(宿主机ip地址和端口)ip不能是0.0.0.0
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.10.133:39092
# 定义安全协议
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
# 集群地址
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
# 指定供外部使用的控制类请求信息
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
# 设置broker最大内存,和初始内存
- KAFKA_HEAP_OPTS=-Xmx512M -Xms256M
# 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可(22byte)
- KAFKA_KRAFT_CLUSTER_ID=xYcCyHmJlIaLzLoBzVwIcP
# 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
- ALLOW_PLAINTEXT_LISTENER=yes
# 允许自动创建主题
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
# broker.id,必须唯一,且与KAFKA_CFG_NODE_ID一致
- KAFKA_BROKER_ID=3
volumes:
- /opt/kafka/broker3:/bitnami/kafka:rw运行
plain
docker compose -f docker-compose-kafka.yml up -d- volumes 权限问题
这里把镜像里的路径挂载到宿主机了,但是这里开启的时候会遇到一个权限报错:
plain
mkdir: cannot create directory '/bitnami/kafka/config': Permission denied第一次开启后,./kafka/... 下的目录都创建好了,此时需要给 1001 用户和组添加权限:
plain
sudo chown -R 1001:1001 /opt/kafka再次启动镜像就没问题了
轻量级 Kafka 可视化工具 ------ kafka-console-ui
- 创建docker-compose-ui.yml
plain
version: '3'
services:
# 服务名
kafka-console-ui:
# 容器名
container_name: "kafka-console-ui"
# 端口
ports:
- "7766:7766"
# 持久化
# volumes:
# - ./data:/app/data
# - ./log:/app/log
# 防止读写文件有问题
privileged: true
user: root
# 镜像地址 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/wdkang/kafka-console-ui:v1.0.10
#image: "wdkang/kafka-console-ui"
image: "swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/wdkang/kafka-console-ui:v1.0.10"
expose:
- "7766"运行
plain
docker compose -f docker-compose-ui.yml up -d设置自动启动
plain
docker container update --restart=always kafka1
docker container update --restart=always kafka2
docker container update --restart=always kafka3
docker container update --restart=always kafka-ui配置集群
http://192.168.10.133:7766/#/op-page
打开管理工具的运维界面kafka-console-ui,我这里部署在了本地
选择集群切换 -> 新增集群,填好配置后,选择切换,就可以管理我们的 kafka 集群了
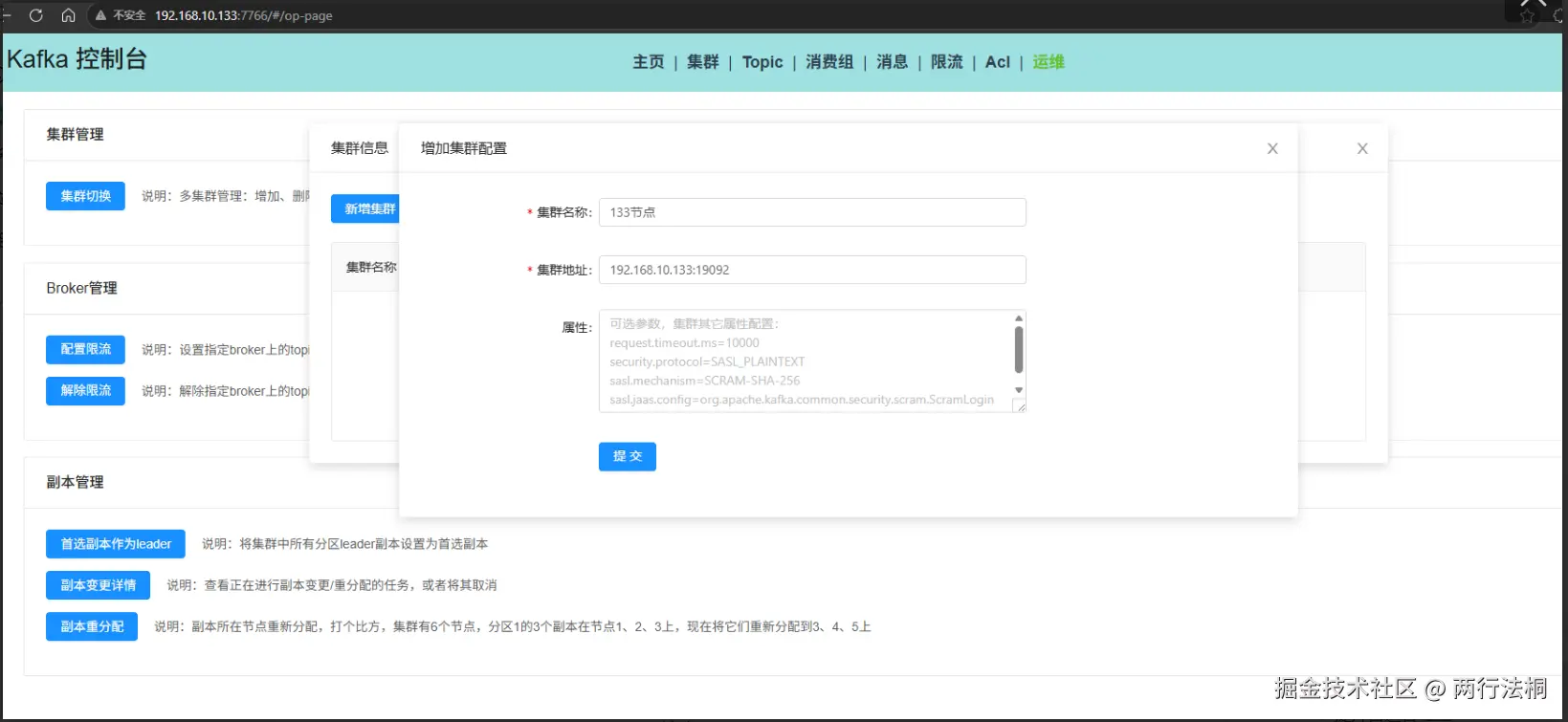
创建topic test
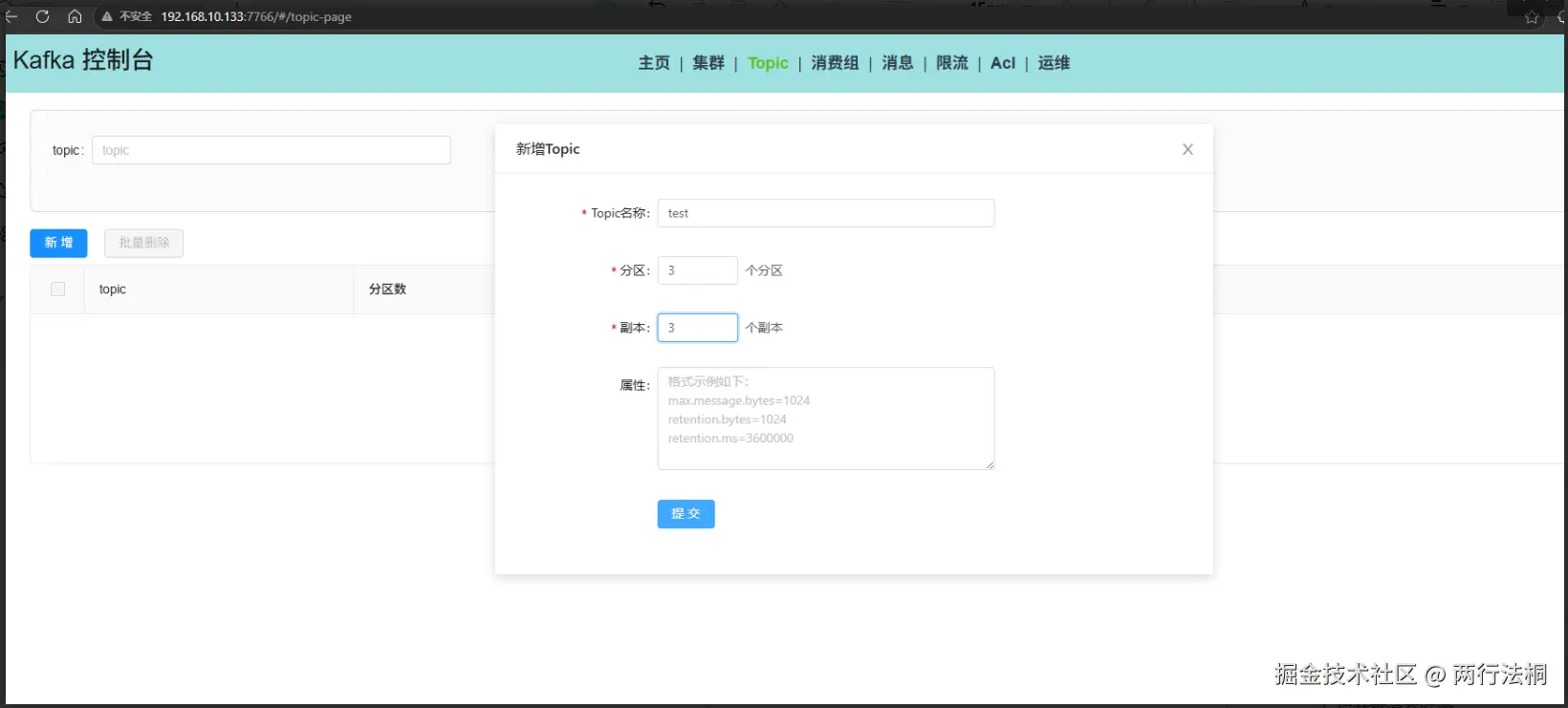 创建消费者组 test-group
创建消费者组 test-group 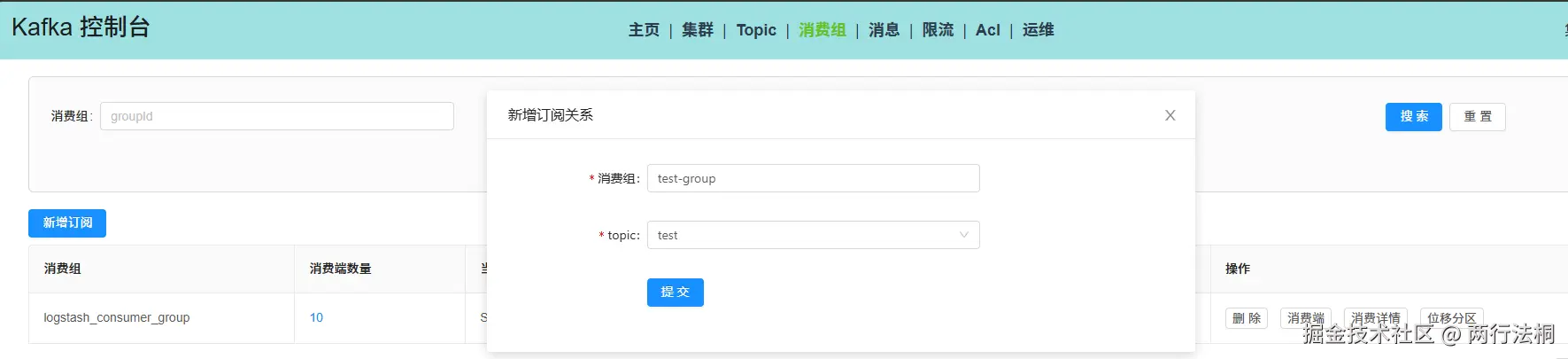
注意:
KAFKA_CFG_ADVERTISED_LISTENERS外网访问的 ip 地址不能是 0.0.0.0KAFKA_BROKER_ID必须与KAFKA_CFG_NODE_ID保持一致KAFKA_KRAFT_CLUSTER_ID可以使用菜鸟工具生成一个 22 位随机字符- 以上两个部署 kafka 的 yaml 文件中,都设置了
KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=false,表示不自动创建 topic,必须手动创建,比如可以通过 kafka-console-ui 的 Topic 页签来操作:
定时清理topic,防止占满磁盘
Kafka磁盘写满日志清理操作_kafka磁盘占用过大-CSDN博客
集群配置
plain
delete.retention.ms=7200000topic配置
plain
retention.ms=3600000
compression.type=lz4Logstash
配置说明:
6.3. 访问事件数据和字段 | 创建 Logstash 管道 |《Logstash 中文文档 8.9》| Laravel China 社区
filebeat metricbeat区分不同服务
ELK入门(八)------Logstash多beat配置(以Filebeat、Metricbeat为例)_logstash 如何处理不同的filebeat-CSDN博客
grok表达式
ELK --- Grok正则过滤Linux系统登录日志 - 简书
安装
拉取镜像
shell
docker pull logstash:7.17.28
## 国内镜像
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.elastic.co/logstash/logstash:7.17.28
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.elastic.co/logstash/logstash:7.17.28 logstash:7.17.28挂载目录
shell
mkdir -p /usr/local/docker/elk/logstash/config
chmod a+w /usr/local/docker/elk/logstash/config创建配置文件
shell
vim /usr/local/docker/elk/logstash/config/logstash.conf
plain
input {
## 通过filebeat输入
beats {
port => 5044
}
## 通过kafka输入
kafka {
bootstrap_servers => "192.168.10.133:19092"
topics => ["test"]
group_id => "logstash-consumers"
# 优化参数
fetch_max_bytes => 10485760 # 单次拉取最大数据量(默认 50MB,可调至 10MB)
fetch_min_bytes => 1024000 # 单次拉取最小数据量(默认 1B,调至 1MB)
max_poll_records => 2000 # 单次拉取最大消息数(默认 500)
consumer_threads => 3 # 消费者线程数(建议与分区数一致)
decorate_events => false # 关闭元数据装饰(减少处理开销)
#精准一次消费,缺少以下配置会导致grok处理后的内容出现重复
enable_auto_commit => true
auto_commit_interval_ms => 1000 # 更频繁提交偏移量
isolation_level => "read_committed" # 仅读取已提交消息
}
}
filter {
grok{
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:level} %{JAVALOGMESSAGE:msg}" }
}
date {
match => ["timestamp","yyyy-MM-dd HH:mm:ss,SSS","ISO8601"]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ["192.168.10.132:9200"]
index => "test"
template_overwrite => true
}
}示例中使用filebeat或者kafka作为logstash的输入源 ,输出源为es
创建配置文件logstash.yml
shell
vim /usr/local/docker/elk/logstash/config/logstash.yml
plain
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.username: logstash_system
xpack.monitoring.elasticsearch.password: "sanquan"
xpack.monitoring.elasticsearch.hosts: ["http://192.168.10.132:9200"]
pipeline.workers: 8
pipeline.batch.size: 5000
pipeline.batch.delay: 100创建配置文件jvm.options
plain
vim /usr/local/docker/elk/logstash/config/jvm.options
plain
## JVM configuration
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms5g
-Xmx5g
################################################################
## Expert settings
################################################################
##
## All settings below this section are considered
## expert settings. Don't tamper with them unless
## you understand what you are doing
##
################################################################
## GC configuration
8-13:-XX:+UseConcMarkSweepGC
8-13:-XX:CMSInitiatingOccupancyFraction=75
8-13:-XX:+UseCMSInitiatingOccupancyOnly
## Locale
# Set the locale language
#-Duser.language=en
# Set the locale country
#-Duser.country=US
# Set the locale variant, if any
#-Duser.variant=
## basic
# set the I/O temp directory
#-Djava.io.tmpdir=$HOME
# set to headless, just in case
-Djava.awt.headless=true
# ensure UTF-8 encoding by default (e.g. filenames)
-Dfile.encoding=UTF-8
# Set enableADS to true to enable Logstash to run on certain versions of the JDK
-Djdk.io.File.enableADS=true
# use our provided JNA always versus the system one
#-Djna.nosys=true
# Turn on JRuby invokedynamic
-Djruby.compile.invokedynamic=true
# Force Compilation
-Djruby.jit.threshold=0
# Make sure joni regexp interruptability is enabled
-Djruby.regexp.interruptible=true
## heap dumps
# generate a heap dump when an allocation from the Java heap fails
# heap dumps are created in the working directory of the JVM
-XX:+HeapDumpOnOutOfMemoryError
# specify an alternative path for heap dumps
# ensure the directory exists and has sufficient space
#-XX:HeapDumpPath=${LOGSTASH_HOME}/heapdump.hprof
## GC logging
#-XX:+PrintGCDetails
#-XX:+PrintGCTimeStamps
#-XX:+PrintGCDateStamps
#-XX:+PrintClassHistogram
#-XX:+PrintTenuringDistribution
#-XX:+PrintGCApplicationStoppedTime
# log GC status to a file with time stamps
# ensure the directory exists
#-Xloggc:${LS_GC_LOG_FILE}
# Entropy source for randomness
-Djava.security.egd=file:/dev/urandom
# Copy the logging context from parent threads to children
-Dlog4j2.isThreadContextMapInheritable=true
17-:--add-opens java.base/sun.nio.ch=ALL-UNNAMED
17-:--add-opens java.base/java.io=ALL-UNNAMED
17-:--add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED
17-:--add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED
17-:--add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED
17-:--add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED
17-:--add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED创建配置文件startup.options
shell
vim /usr/local/docker/elk/logstash/config/startup.options
plain
################################################################################
# These settings are ONLY used by $LS_HOME/bin/system-install to create a custom
# startup script for Logstash and is not used by Logstash itself. It should
# automagically use the init system (systemd, upstart, sysv, etc.) that your
# Linux distribution uses.
#
# After changing anything here, you need to re-run $LS_HOME/bin/system-install
# as root to push the changes to the init script.
################################################################################
# Override Java location
#JAVACMD=/usr/bin/java
# Set a home directory
LS_HOME=/usr/share/logstash
# logstash settings directory, the path which contains logstash.yml
LS_SETTINGS_DIR=/etc/logstash
# Arguments to pass to logstash
LS_OPTS="--path.settings ${LS_SETTINGS_DIR}"
# Arguments to pass to java
LS_JAVA_OPTS=""
# pidfiles aren't used the same way for upstart and systemd; this is for sysv users.
LS_PIDFILE=/var/run/logstash.pid
# user and group id to be invoked as
LS_USER=logstash
LS_GROUP=logstash
# Enable GC logging by uncommenting the appropriate lines in the GC logging
# section in jvm.options
LS_GC_LOG_FILE=/var/log/logstash/gc.log
# Open file limit
LS_OPEN_FILES=16384
# Nice level
LS_NICE=19
# Change these to have the init script named and described differently
# This is useful when running multiple instances of Logstash on the same
# physical box or vm
SERVICE_NAME="logstash"
SERVICE_DESCRIPTION="logstash"
# If you need to run a command or script before launching Logstash, put it
# between the lines beginning with `read` and `EOM`, and uncomment those lines.
###
## read -r -d '' PRESTART << EOM
## EOM运行
shell
docker run -it -d --restart always --log-opt max-size=10m --log-opt max-file=3 --user root \
-p 4560:4560 -p 5044:5044 -p 514:514/udp -p 5045:5045 --name logstash \
-v /usr/local/docker/elk/logstash/config/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /usr/local/docker/elk/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /usr/local/docker/elk/logstash/config/jvm.options:/usr/share/logstash/config/jvm.options \
-v /usr/local/docker/elk/logstash/config/startup.options:/usr/share/logstash/config/startup.options \
logstash:7.17.28root运行
复制启动配置文件
shell
docker cp logstash:/usr/share/logstash/config/startup.options .修改
LS_USER=logstash
LS_GROUP=logstash,
改为LS_USER=root
LS_GROUP=root
运行
shell
docker run -it -d --restart always --log-opt max-size=10m --log-opt max-file=3 --user root \
-p 4560:4560 -p 5044:5044 -p 514:514/udp -p 5045:5045 --name logstash \
-v /usr/local/docker/elk/logstash/config/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /usr/local/docker/elk/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /usr/local/docker/elk/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /usr/local/docker/elk/logstash/config/startup.options:/usr/share/logstash/config/startup.options \
logstash:7.17.28Logstash 配置优化
1. 提升管道吞吐量
| 参数 | 优化建议 | 描述 |
|---|---|---|
| pipeline.workers | 设置为 CPU 核数(或核数 * 2) | 增加并行处理线程,充分利用多核性能 |
| pipeline.batch.size | 调整为 5000-10000(默认 125) | 增大批处理数量,减少 I/O 频率 |
| pipeline.batch.delay | 调整为50-100ms(默认 50ms) | 适当延长批次等待时间,累积更多数据减少请求次数 |
| queue.type | 设置为persisted(需启用持久化队列) | 避免内存队列溢出,支持断点续传 |
| queue.max_bytes | 设置为内存的 50%-70%(如 4gb) | 提高队列容量,缓冲突发流量 |
示例配置 (<font style="color:#000000;">logstash.yml</font>):
plain
pipeline.workers: 8
pipeline.batch.size: 5000
pipeline.batch.delay: 100
queue.type: persisted
queue.max_bytes: 4gb2. Kafka 输入插件优化
调整 Kafka 消费者参数(input/kafka 插件):
json
input {
kafka {
bootstrap_servers => "kafka1:9092,kafka2:9092"
topics => ["test"]
group_id => "test-group"
# 优化参数
fetch_max_bytes => 10485760 # 单次拉取最大数据量(默认 50MB,可调至 10MB)
fetch_min_bytes => 1024000 # 单次拉取最小数据量(默认 1B,调至 1MB)
max_poll_records => 2000 # 单次拉取最大消息数(默认 500)
consumer_threads => 3 # 消费者线程数(建议与分区数一致)
decorate_events => false # 关闭元数据装饰(减少处理开销)
#精准一次消费,缺少以下配置会导致grok处理后的内容出现重复
enable_auto_commit => true
auto_commit_interval_ms => 1000 # 更频繁提交偏移量
isolation_level => "read_committed" # 仅读取已提交消息
}
}3. logstash 报堆内存溢出 增加内存
shell
docker cp logstash:/usr/share/logstash/config/jvm.options /usr/local/docker/elk/logstash/config/运行
shell
docker run -it -d --restart always --log-opt max-size=10m --log-opt max-file=3 --user root \
-p 4560:4560 -p 5044:5044 -p 514:514/udp -p 162:162/udp --name logstash \
-v /usr/local/docker/elk/logstash/config/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /usr/local/docker/elk/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /usr/local/docker/elk/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /usr/local/docker/elk/logstash/config/startup.options:/usr/share/logstash/config/startup.options \
-v /usr/local/docker/elk/logstash/config/jvm.options:/usr/share/logstash/config/jvm.options \
logstash:7.17.28