Linux文件为什么文件名和inode分开存储?路径查找为什么这么快?大文件是如何跨磁盘块存储的?分区、格式化、挂载到底有什么区别?
本文从零起步,顺着磁盘硬件→文件系统格式化→核心结构体→文件存储→路径解析→缓存机制→大文件存储的完整链路,吃透Linux Ext系列文件系统核心原理,全覆盖底层核心细节,无知识盲区。
一、磁盘分区与格式化:文件系统的地基
1.1 分区的本质
整块物理磁盘是一块空白的存储硬件,操作系统无法直接精细化管理。分区就是对物理磁盘进行逻辑切割,将一块磁盘划分为多个独立的逻辑区域(如 /dev/sda1、/dev/sda2)。
每个分区相互隔离,拥有独立的存储管理空间,可单独格式化为不同文件系统(Ext2/Ext3/Ext4、XFS等),互不干扰,这是磁盘资源精细化管理的第一步。
1.2 格式化的本质(核心)
分区完成后,磁盘分区只是一块「空白逻辑空间」,没有任何管理规则,操作系统无法识别文件、存储文件。
格式化的本质:给空白分区写入文件系统规则,搭建标准化的磁盘管理结构。具体会完成三件事:
-
将整个分区统一划分为大小相等的逻辑块 (默认4KB,文件系统最小读写单位),并对所有块进行全局统一编号;
-
将分区整体拆分为多个块组(Block Group),均衡分散存储元数据和数据,提升读写效率;
-
预先创建并初始化所有管理结构体:超级块、块组描述符、块位图、inode位图、inode表,划定元数据区域和用户数据区域。
1.3 格式化后的分区能否直接使用?
不能。
格式化仅完成了「底层规则搭建」,让磁盘分区具备了存储文件的能力,但此时操作系统的虚拟文件系统(VFS)目录树还没有关联该分区。系统无法识别这个分区对应的目录入口,用户也无法通过路径访问分区内的文件。
1.4 挂载的核心作用
挂载的本质:将物理文件系统(分区)关联到系统虚拟目录树的某个目录节点。
只有完成挂载,空白的物理分区才能接入系统的统一目录体系,对应的目录将成为该分区的入口,所有写入该目录的文件,都会存储到对应的物理分区中。比如将/dev/sda2挂载到/home,所有/home下的文件,都存储在sda2分区中。
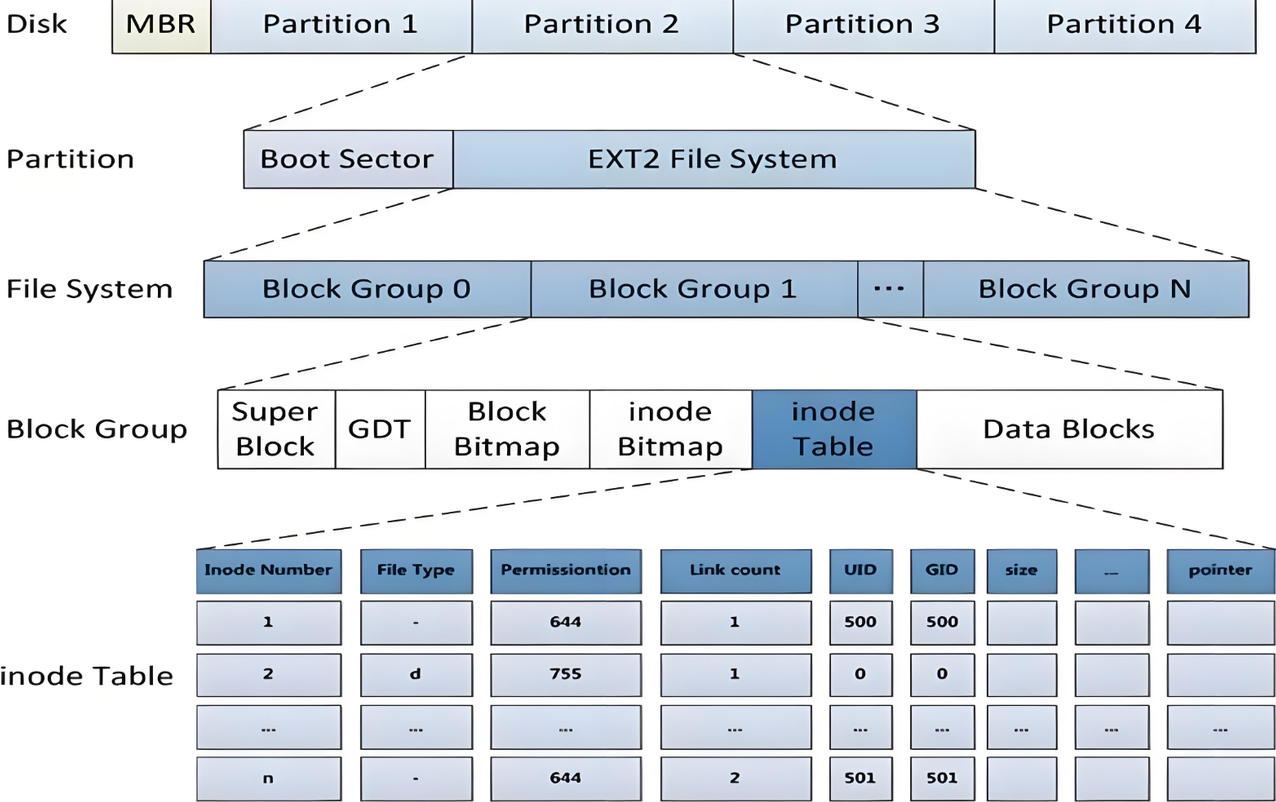
二、文件系统层级:分区 → 块组 → 组内核心结构
Ext文件系统的核心设计:大分区拆分块组,块组统一管理资源,避免元数据集中存储导致的性能瓶颈。
2.1 层级关系
一块磁盘分区 → 均等拆分多个块组 → 每个块组独立管理一组元数据和数据块
2.2 每个块组内部完整结构
-
超级块(Super Block):文件系统全局描述表,存储分区总大小、块大小、inode总数、空闲inode/块数量、块组数量等全局信息,是整个文件系统的「总说明书」;
-
块组描述符 (GTP):记录当前块组的资源分布、空闲资源状态,每个块组对应一个;
-
块位图(Block Bitmap):二进制位图,标记当前块组内所有数据块的使用状态(0空闲、1已占用),用于快速分配/回收数据块;
-
inode位图(Inode Bitmap):二进制位图,标记当前块组内所有inode的使用状态(0空闲、1已占用),用于快速分配/回收inode节点;
-
inode表(Inode Table):当前块组的所有inode节点集合,固定大小、固定数量,每个文件/目录独占一个inode;
-
数据块(Data Block):真正存储用户文件数据、目录数据的区域。
三、Inode内部结构与存储内容(文件元数据核心)
inode(索引节点)是文件的唯一身份载体 ,核心特性:inode不存储文件名,只存储文件元数据和数据块指针。
3.1 inode内部存储的所有信息
-
文件属性:文件大小、创建/修改/访问时间、权限、所有者、所属组、硬链接计数;
-
标识信息:全局唯一inode编号(分区内全局有效);
-
核心寻址数组:i_block15(15个块指针,Ext2标准结构);
-
状态信息:文件类型(普通文件/目录/链接等)、数据块占用状态。
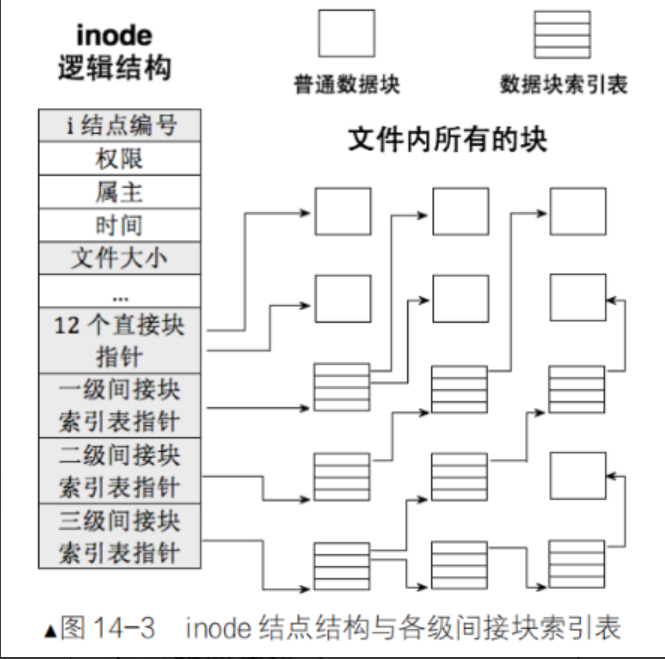
3.2 i_block数组详解(大文件存储核心)
i_block数组是文件存储数据的核心,所有元素均存储分区全局逻辑块号,15个指针分为4类,精准适配大小文件:
-
12个直接指针(i_block0~i_block11):直接指向文件的数据块,无需中间索引。块大小4KB时,可直接寻址 12×4KB = 48KB 的小文件;
-
一级间接指针(i_block12,第13个指针):不存文件数据,指向一个「一级索引块」。索引块内存储大量数据块指针,4KB块可存 4096/4=1024个指针,可寻址1024×4KB=4MB数据;
-
二级间接指针(i_block13):指向一级索引块的索引块,二次跳转寻址,支持GB级文件;
-
三级间接指针(i_block14):三层索引跳转,支持TB级超大文件。
3.4、大文件存储原理:inode数据块数组工作机制
小文件依靠12个直接指针即可存储,大文件依靠多级间接指针扩容,彻底突破单块、单组存储限制。
以4KB块大小为例:
-
0~48KB文件:仅用12个直接指针,直接寻址数据块;
-
48KB~4MB文件:启用一级间接指针,通过索引块批量寻址1024个数据块;
-
4MB以上文件:启用二级、三级间接指针,多层索引跳转,支持TB级超大文件。
核心:inode的多级指针体系,让文件数据块无需连续,可离散存储在磁盘任意位置。
四、普通文件与目录文件
4.1 普通文件
文本、二进制程序、图片、日志等都属于普通文件。其inode标记为普通文件类型,数据块仅存储用户业务数据(文本内容、二进制代码等),无任何文件管理信息。
4.2 目录文件
Linux中目录也是文件,拥有独立inode、独立数据块。
目录文件的核心作用:维护「文件名与inode的映射关系」。其数据块中不存储用户数据,只存储一条条dirent目录项。
4.2.1 dirent是什么?
dirent(目录项)是磁盘端的结构化数据,存储在目录文件的数据块中,是磁盘上真实存在的记录。
每条dirent结构体核心字段:
-
inode编号:当前文件/目录对应的全局inode号;
-
文件名:字符串名称(如log.txt、wkz);
-
记录长度:当前dirent条目占用大小;
-
文件类型:标识是普通文件、目录、链接文件等。
简单说:dirent就是磁盘上的「文件名→inode号」对照表。
4.3 普通文件与目录文件的核心区别
-
数据块存储内容不同:普通文件存用户业务数据;目录文件存dirent目录项(文件名+inode映射);
-
功能定位不同:普通文件用于存储数据;目录文件用于组织和检索文件,构建系统目录树;
-
权限含义不同:普通文件r/w权限控制读写内容;目录文件x权限控制「能否进入、遍历目录」,r权限控制「能否查看目录内文件列表」;
-
使用场景不同:普通文件是数据载体;目录文件是路径检索的索引载体。
五、内存核心结构:dentry详解 + 路径缓存机制
5.1 dentry是什么?
dirent是磁盘端结构,dentry是内存端的目录项缓存对象。操作系统为了避免频繁读磁盘,会将常用的目录/文件映射关系加载到内存,生成dentry对象,常驻缓存。
5.2 dentry内部存储内容
-
文件名:当前文件/目录名称;
-
父dentry指针:指向上级目录的dentry对象;
-
子dentry链表:挂载所有下级文件/目录的dentry;
-
inode指针:关联当前文件对应的内存inode;
-
缓存状态:正缓存(文件存在)、负缓存(文件不存在);
-
LRU链表节点:用于内存回收,淘汰低频缓存。
5.3 路径缓存(dcache)核心机制
dcache(目录项缓存)是内核维护的全局哈希缓存,Key为「父dentry+文件名」,Value为dentry对象。
核心作用:90%以上的路径查找无需读磁盘,直接内存命中。
缓存规则:
-
正缓存:缓存已存在的文件/目录dentry,加速重复查找;
-
负缓存:缓存不存在的文件路径,避免重复无效磁盘IO;
-
LRU淘汰:内存紧张时,回收最久未使用的dentry缓存。
5.4 路径解析
路径解析是操作系统将文件字符串路径转换为对应内存inode节点的核心过程,依托dcache缓存+磁盘解析双机制完成,所有绝对路径均从根目录开始逐层遍历,固定执行流程如下:
-
路径拆分:内核将完整文件路径按照 `/` 拆分多级路径分量,以系统常驻的根目录dentry、根目录inode为唯一解析起点;
-
逐级缓存校验:针对每一级路径分量,以「父目录dentry+当前文件名」为key,优先查询dcache目录项缓存;缓存命中直接复用内存dentry与inode,跳过磁盘IO;
-
缓存未命中磁盘解析:若缓存未命中,通过父目录inode的i_block数组读取父目录磁盘数据块,遍历内部dirent磁盘目录项,匹配当前文件名,获取对应inode号;
-
inode校验与加载:根据inode号定位对应块组,读取inode位图校验inode有效性,从磁盘inode表加载inode至内存;
-
创建缓存节点:新建对应dentry对象,绑定父子目录关系与内存inode,加入dcache缓存,供后续复用;
-
逐层循环遍历:更新父目录dentry,重复上述步骤,直至解析完所有路径分量,最终目标文件/目录的内存inode,完成路径解析。
核心本质:路径解析就是「字符串路径 → 逐级匹配映射 → 锁定内存inode」的转换过程,dcache缓存是提升解析效率的核心,规避了频繁磁盘读写的性能损耗。
六、dirent、inode、dentry 三者存储与关联关系
这三个结构是文件系统的核心,三者分层协作,缺一不可:
6.1 各自存储位置与内容
-
dirent(磁盘):存储在目录文件的磁盘数据块中,静态磁盘数据,存「文件名 + inode号」;
-
inode(磁盘+内存) :磁盘inode存于块组inode表,加载后缓存到内存;存文件元数据+数据块指针,不存文件名;
-
dentry(内存):纯内存缓存对象,内核动态创建,存文件路径层级关系+关联内存inode。
6.2 三者完整关联链路
磁盘dirent(文件名→inode号) → 通过inode号找到磁盘inode → 加载inode到内存 → 内核创建dentry绑定文件名与内存inode → 加入dcache缓存,完成路径映射。
核心逻辑:文件名由dirent/dentry维护,文件数据与属性由inode维护,彻底解耦,这也是硬链接可以实现的核心原理。
七、创建 /home/wkz/log.txt
核心前置逻辑(理解关键) :Linux 系统中,任何文件、子目录的 inode 号与文件名映射,都存放在上级目录的磁盘 dirent 中,文件自身不存储文件名、路径、上级关联信息,无法自我定位。
因此想要创建 log.txt,必须逐层溯源解析:先找到上级 wkz,再找到 wkz 的上级 home,最终溯源到系统唯一顶层入口根目录 /。
根目录是唯一特例:系统挂载文件系统时,会提前初始化根目录inode(固定编号2)、预创建根目录dentry,常驻内存与dcache缓存,是所有绝对路径解析的固定起点。
操作系统解析路径的固定规则:每一级路径,优先查询内存dcache缓存,缓存命中直接复用;缓存未命中,再走磁盘IO解析,极大减少磁盘开销。
整体解析链路:根目录 / → 校验缓存/磁盘解析 home → 校验缓存/磁盘解析 wkz → 位图分配inode/数据块 → 新建 log.txt → 写入缓存
步骤1:初始化解析起点(根目录,常驻缓存)
根目录的 inode、dentry 永久常驻内存dcache,无需查询缓存、无需磁盘读取。内核直接通过根目录 inode 的 i_block 数组,获取根目录数据块全局块号,该数据块存储根目录下所有磁盘 dirent 映射。
步骤2:解析一级路径 home(先查缓存、再读磁盘+位图校验)
-
缓存校验:以「根目录dentry + 文件名home」为key,查询全局dcache缓存;
-
缓存未命中:执行磁盘解析流程;
-
磁盘IO读取根目录数据块至内存,遍历所有磁盘 dirent,匹配文件名
home,获取 home 目录全局 inode 号; -
根据 inode 号定位对应块组,读取该块组 inode 位图,校验该inode位为有效已占用状态;
-
从磁盘 inode 表加载 home 目录 inode 到内存;
-
新建 home 目录 dentry,挂载到根目录dentry,加入dcache缓存,完成一级路径解析。
步骤3:解析二级路径 wkz(先查缓存、再读磁盘+位图校验)
-
缓存校验:以「home目录dentry + 文件名wkz」为key,查询dcache缓存;
-
缓存未命中,进入磁盘解析;
-
通过 home inode 的
i_block数组,读取 home 目录磁盘数据块; -
遍历磁盘 dirent 匹配
wkz,获取 wkz 目录 inode 号; -
定位对应块组,读取inode位图校验inode有效,加载 wkz 目录磁盘 inode 至内存;
-
新建 wkz dentry 并挂载到 home 目录,加入dcache缓存,精准定位到目标父目录 /home/wkz。
步骤4:磁盘层创建全新文件 log.txt(inode位图分配)
-
定位 wkz 目录所属块组,读取该块组 inode 位图,遍历比特位找到空闲 inode 号,将对应位标记为已占用;
-
在 inode 表初始化新文件 inode:标记为普通文件、文件大小置0、
i_block数组全部置空、硬链接数为1; -
修改 wkz 目录磁盘数据块,新增一条磁盘 dirent 映射:log.txt 文件名 → 新文件 inode 号,完成磁盘层文件创建。
步骤5:内存构建节点并写入dcache缓存
-
内核新建 log.txt 对应的 dentry 内存对象;
-
dentry 父节点指向 wkz 目录dentry,绑定新创建的内存 inode;
-
将 log.txt dentry 加入全局dcache缓存,生成内存路径树,下次访问直接缓存命中。
步骤6:写入数据时,通过块位图分配全局数据块(新增位图查找逻辑)
-
当对 log.txt 执行写入操作时,内核定位文件所属块组,读取该块组的块位图;
-
遍历块位图比特位,查找空闲全局数据块号,将对应位图位修改为已占用;
-
将分配到的全局数据块号,写入文件 inode 对应的
i_block直接/间接指针数组; -
最终将用户数据写入对应磁盘数据块,完成文件数据落地存储。
核心总结
-
所有子文件/子目录无自我定位能力,依靠上级目录 dirent 记录映射关系,路径必须从根目录逐层解析;
-
路径解析固定顺序:优先查dcache缓存 → 未命中读磁盘dirent → 查inode位图校验inode → 加载inode → 创建dentry入缓存;
-
新建文件靠 inode位图 分配空闲inode;写入数据靠 块位图 分配空闲数据块;
-
创建文件本质:磁盘层分配空闲inode+新增dirent映射,内存层创建dentry并缓存,写入数据依赖块位图分配磁盘块。
所以想要找到/创建 log.txt,必须先找到它的上级目录 wkz;想要找到wkz,必须先找到它的上级 home;想要找到 home,必须溯源到系统最顶层的根目录 /。
八、inode号与块号的全局特性:文件跨块组存储原理
8.1 核心结论
inode编号、数据块号均是分区内全局有效、全局唯一的,并非块组局部编号。
8.2 为什么文件可以大于单个块组?
单个块组的inode数量、数据块数量是有限的,当文件极大,超出当前所在块组的空闲资源时:
-
inode号全局唯一:文件的inode固定(唯一身份),不会随数据存储位置改变;
-
块号全局编排:所有块组的数据块统一编号,无组间隔离;
-
inode的i_block数组可存储任意块组的全局块号。
简单说:一个文件的inode属于某一个块组,但它的数据块可以分散在整个分区的所有块组中,彻底突破单块组容量限制,这就是大文件存储的底层核心。
8.3 若存储文件时,文件大小大于单个块组大小怎么办?
核心答案:文件不会受单个块组容量限制,支持跨块组离散存储,具体底层原理如下:
-
资源归属分离:文件的inode创建时固定归属某一个块组(占用当前块组的inode资源),但文件的数据资源不绑定当前块组。
-
全局编号机制 :整个分区的inode号、数据块号都是全局统一编号,并非块组局部编号,所有块组的空闲数据块对全分区文件开放使用。
-
指针无组间限制 :文件inode的
i_block[]数组(直接/一级/二级/三级间接指针),可以存储任意块组的全局数据块号,不局限于自身inode所在的块组。 -
动态扩容机制 :当文件持续写入、单块组空闲数据块耗尽时,内核会自动遍历其他空闲块组,通过块位图查找全局空闲数据块,将新数据存储在其他块组,并把对应全局块号写入inode指针数组。
最终结论:单个块组仅限制inode数量,不限制文件数据大小。超大文件可以依靠多级指针+全局块号,离散存储在分区所有块组中,轻松突破单块组容量上限。
九、操作系统如何识别文件所属文件系统?
操作系统通过超级块+挂载结构体精准区分文件所属文件系统,核心逻辑:
-
磁盘分区格式化后,超级块中会固化文件系统标识(Ext2/Ext4/XFS)、块大小、元数据规则;
-
分区挂载时,内核读取超级块,加载对应文件系统的驱动与操作接口;
-
内核通过super_block超级块对象唯一标识一个文件系统,所有该分区的inode、dentry、数据块,都会关联对应的超级块指针;
-
路径解析、文件读写时,内核通过inode关联的超级块,判断文件所属的文件系统,调用对应的底层操作函数。
最终实现:VFS虚拟文件系统屏蔽差异,底层不同文件系统规则独立运行。
十、全文核心总结
-
分区是磁盘逻辑拆分,格式化是搭建文件系统管理规则,挂载是接入系统目录树,三者缺一不可;
-
文件系统分层:分区→块组,块组内通过位图、inode表、数据块实现资源管理;
-
文件名存在磁盘dirent、内存dentry,文件数据与属性存在inode,二者解耦支撑硬链接;
-
dcache路径缓存是系统高效检索的核心,大幅减少磁盘IO;
-
inode多级间接指针支撑超大文件存储,全局inode号、块号支持文件跨块组离散存储;
-
超级块是文件系统的身份证,内核依靠它识别、管理不同类型的文件系统。