角色 :你是一名资深 AI 前端架构师,深度使用过 LangChain 构建生产级 LLM 应用。
任务 :基于 LangChain 官方源码(
langchain-ai/langchain),撰写一篇面向中高级前端/全栈工程师的技术博客。要求:
- 逻辑结构:总-分-总,先讲设计哲学,再逐层拆解核心模块,最后给出工程实践建议
- 每个核心概念必须配有:是什么 → 为什么这样设计 → 怎么用(代码示例)
- 重点覆盖:分层架构、Runnable/LCEL、提示模板、模型抽象、Agent 系统、RAG 存储链路、可观测性
- 语言:中文,技术术语保留英文原词
- 风格:严谨但不枯燥,有工程师视角的批判性思考
0. 设计哲学:一切皆 Runnable
LangChain 的核心设计理念是通过统一接口实现组合性(Composability) 。无论是 LLM、提示模板、工具还是检索器,所有组件都实现同一个抽象接口 Runnable,从而可以像乐高积木一样自由拼接。
这个设计解决了 LLM 应用开发中最痛的问题:不同模型、不同组件之间的胶水代码爆炸。
1. 分层架构:四层清晰分离
┌─────────────────────────────────────────────┐
│ Integration Layer (partners/) │ ← langchain-openai, anthropic, ollama...
├─────────────────────────────────────────────┤
│ Implementation Layer (langchain_v1/) │ ← create_agent, init_chat_model...
├─────────────────────────────────────────────┤
│ Foundation Layer (langchain-core/) │ ← Runnable, BaseChatModel, BaseTool...
├─────────────────────────────────────────────┤
│ Tooling Layer (text-splitters, standard-tests) │
└─────────────────────────────────────────────┘| 层级 | 包名 | 职责 |
|---|---|---|
| 基础抽象层 | langchain-core |
定义所有接口,零第三方依赖 |
| 实现层 | langchain(langchain_v1) |
高层工具函数,集成 LangGraph |
| 集成层 | partners/ |
各厂商具体实现 |
| 测试层 | standard-tests |
标准化集成测试套件 |
关键设计决策 :langchain-core 故意保持极轻量依赖(只有 pydantic、langsmith、tenacity),任何厂商都可以基于它实现自己的集成包,而不引入不必要的依赖。 1 2
2. Runnable 接口与 LCEL:组合的基石
2.1 Runnable 抽象
Runnable[Input, Output] 是整个框架的核心抽象,定义在 libs/core/langchain_core/runnables/base.py。
唯一必须实现的方法只有 invoke,其余方法均有默认实现:
| 方法 | 说明 |
|---|---|
invoke(input, config?) |
同步调用,一进一出 |
ainvoke(input, config?) |
异步版本(默认在线程池中运行 invoke) |
batch(inputs, config?) |
批量调用,默认并发执行 |
stream(input, config?) |
流式输出,逐 chunk 返回 |
astream_events(input, version?) |
异步事件流,用于细粒度观测 |
2.2 LCEL:用 | 运算符构建 Pipeline
LangChain Expression Language(LCEL)是 LangChain 的声明式链式语法,核心就是重载了 | 运算符:
python
# 三种等价写法
chain = prompt | model | parser # LCEL 管道语法
chain = prompt.pipe(model, parser) # .pipe() 方法
chain = RunnableSequence(prompt, model, parser) # 显式构造| 运算符背后创建的是 RunnableSequence,它是最重要的组合原语 ,自动支持 sync/async/batch/stream。 4
2.3 核心组合原语
| 原语 | 作用 | 典型用法 |
|---|---|---|
RunnableSequence |
串行管道,前一步输出是后一步输入 | `prompt |
RunnableParallel |
并行扇出,同一输入分发给多个 Runnable | {"summary": chain1, "keywords": chain2} |
RunnableLambda |
将任意 Python 函数包装为 Runnable | RunnableLambda(my_func) |
RunnablePassthrough |
透传输入,常用于在并行中保留原始数据 | RunnablePassthrough.assign(context=retriever) |
RunnableBranch |
条件路由,根据谓词选择不同分支 | 多意图路由 |
RunnableWithFallbacks |
主链失败时自动切换备用链 | 模型降级 |
RunnableWithMessageHistory |
自动注入/保存对话历史 | 多轮对话 |
RAG 链的典型写法:
python
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
rag_chain = (
RunnableParallel(
context=retriever, # 并行:检索文档
question=RunnablePassthrough() # 并行:透传问题
)
| prompt # 将 context + question 填入模板
| model # 调用 LLM
| parser # 解析输出
)2.4 RunnableConfig:运行时控制
RunnableConfig 是贯穿整个调用链的配置对象,通过 ContextVar 自动向下传播,无需手动透传:
python
chain.invoke(
input,
config={
"tags": ["prod"], # 用于 LangSmith 过滤
"metadata": {"user": "u1"}, # 附加到 trace
"callbacks": [my_handler], # 自定义回调
"max_concurrency": 5, # 控制 batch 并发数
"configurable": {"llm": "fast"}, # 运行时切换组件
}
)3. 提示模板:结构化 LLM 输入
3.1 ChatPromptTemplate
ChatPromptTemplate 是最常用的提示模板,支持多种消息格式:
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的 {role}。"),
MessagesPlaceholder("history"), # 动态注入历史消息列表
("human", "{question}"),
])MessagesPlaceholder 是多轮对话的关键,它允许在模板中预留一个位置,运行时注入完整的消息列表。
3.2 Few-Shot 提示
FewShotChatMessagePromptTemplate 支持语义相似度动态选择示例,结合向量存储实现智能 few-shot:
python
few_shot_prompt = FewShotChatMessagePromptTemplate(
input_variables=["input"],
example_selector=SemanticSimilarityExampleSelector(vectorstore=vs),
example_prompt=human_template + ai_template,
)4. 模型抽象:厂商无关的统一接口
4.1 两类模型基类
| 基类 | 输入/输出 | 适用场景 |
|---|---|---|
BaseChatModel |
List[Message] → AIMessage |
现代对话模型(GPT-4, Claude, Gemini) |
BaseLLM |
str → str |
传统补全模型 |
所有厂商集成(ChatOpenAI、ChatAnthropic、ChatOllama)都继承自 BaseChatModel,实现同一接口,切换模型只需换一行代码。
4.2 init_chat_model:运行时动态选择模型
python
from langchain.chat_models import init_chat_model
# 通过字符串指定 provider:model
model = init_chat_model("openai:gpt-4o")
model = init_chat_model("anthropic:claude-3-5-sonnet-20241022")
# 支持运行时通过 configurable 切换
model = init_chat_model(configurable_fields="any")
result = model.with_config(configurable={"model": "openai:gpt-4o"}).invoke("Hello")5. Agent 系统:自主决策的执行引擎
5.1 现代 Agent 架构
现代 LangChain Agent 基于 LangGraph StateGraph 构建,通过 create_agent 工厂函数创建:
python
from langchain.agents import create_agent
from langchain_core.tools import tool
@tool
def search_web(query: str) -> str:
"""搜索互联网获取最新信息。"""
return f"搜索结果: {query}"
agent = create_agent(
model="openai:gpt-4o",
tools=[search_web],
system_prompt="你是一个有用的助手。"
)5.2 Agent 执行循环
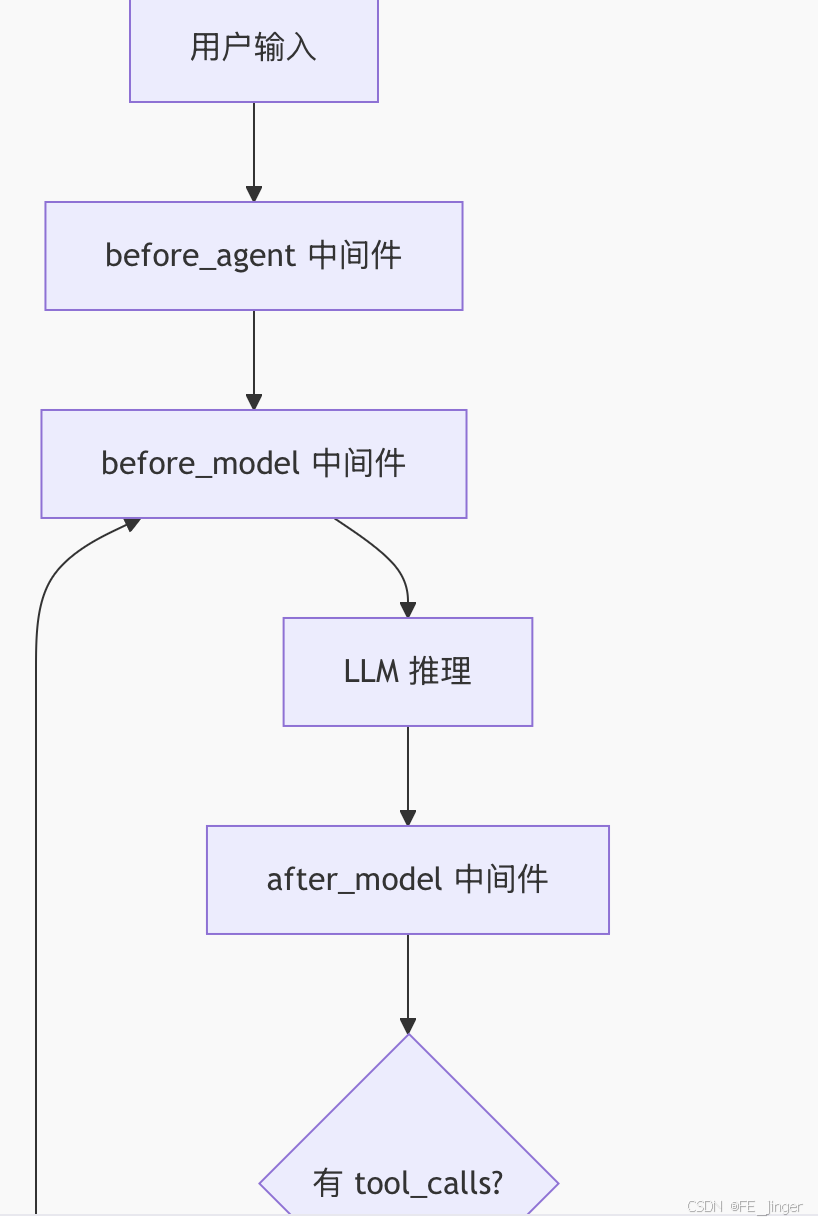
#mermaid-svg-J6cLwiWrsKp1AJol{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-J6cLwiWrsKp1AJol .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-J6cLwiWrsKp1AJol .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-J6cLwiWrsKp1AJol .error-icon{fill:#552222;}#mermaid-svg-J6cLwiWrsKp1AJol .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-J6cLwiWrsKp1AJol .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-J6cLwiWrsKp1AJol .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-J6cLwiWrsKp1AJol .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-J6cLwiWrsKp1AJol .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-J6cLwiWrsKp1AJol .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-J6cLwiWrsKp1AJol .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-J6cLwiWrsKp1AJol .marker{fill:#333333;stroke:#333333;}#mermaid-svg-J6cLwiWrsKp1AJol .marker.cross{stroke:#333333;}#mermaid-svg-J6cLwiWrsKp1AJol svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-J6cLwiWrsKp1AJol p{margin:0;}#mermaid-svg-J6cLwiWrsKp1AJol .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-J6cLwiWrsKp1AJol .cluster-label text{fill:#333;}#mermaid-svg-J6cLwiWrsKp1AJol .cluster-label span{color:#333;}#mermaid-svg-J6cLwiWrsKp1AJol .cluster-label span p{background-color:transparent;}#mermaid-svg-J6cLwiWrsKp1AJol .label text,#mermaid-svg-J6cLwiWrsKp1AJol span{fill:#333;color:#333;}#mermaid-svg-J6cLwiWrsKp1AJol .node rect,#mermaid-svg-J6cLwiWrsKp1AJol .node circle,#mermaid-svg-J6cLwiWrsKp1AJol .node ellipse,#mermaid-svg-J6cLwiWrsKp1AJol .node polygon,#mermaid-svg-J6cLwiWrsKp1AJol .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-J6cLwiWrsKp1AJol .rough-node .label text,#mermaid-svg-J6cLwiWrsKp1AJol .node .label text,#mermaid-svg-J6cLwiWrsKp1AJol .image-shape .label,#mermaid-svg-J6cLwiWrsKp1AJol .icon-shape .label{text-anchor:middle;}#mermaid-svg-J6cLwiWrsKp1AJol .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-J6cLwiWrsKp1AJol .rough-node .label,#mermaid-svg-J6cLwiWrsKp1AJol .node .label,#mermaid-svg-J6cLwiWrsKp1AJol .image-shape .label,#mermaid-svg-J6cLwiWrsKp1AJol .icon-shape .label{text-align:center;}#mermaid-svg-J6cLwiWrsKp1AJol .node.clickable{cursor:pointer;}#mermaid-svg-J6cLwiWrsKp1AJol .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-J6cLwiWrsKp1AJol .arrowheadPath{fill:#333333;}#mermaid-svg-J6cLwiWrsKp1AJol .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-J6cLwiWrsKp1AJol .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-J6cLwiWrsKp1AJol .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-J6cLwiWrsKp1AJol .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-J6cLwiWrsKp1AJol .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-J6cLwiWrsKp1AJol .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-J6cLwiWrsKp1AJol .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-J6cLwiWrsKp1AJol .cluster text{fill:#333;}#mermaid-svg-J6cLwiWrsKp1AJol .cluster span{color:#333;}#mermaid-svg-J6cLwiWrsKp1AJol div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-J6cLwiWrsKp1AJol .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-J6cLwiWrsKp1AJol rect.text{fill:none;stroke-width:0;}#mermaid-svg-J6cLwiWrsKp1AJol .icon-shape,#mermaid-svg-J6cLwiWrsKp1AJol .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-J6cLwiWrsKp1AJol .icon-shape p,#mermaid-svg-J6cLwiWrsKp1AJol .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-J6cLwiWrsKp1AJol .icon-shape .label rect,#mermaid-svg-J6cLwiWrsKp1AJol .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-J6cLwiWrsKp1AJol .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-J6cLwiWrsKp1AJol .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-J6cLwiWrsKp1AJol :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 是
否
用户输入
before_agent 中间件
before_model 中间件
LLM 推理
after_model 中间件
有 tool_calls?
执行工具
返回最终答案
5.3 中间件架构(Middleware)
Agent 系统采用中间件模式,提供多个扩展钩子:
| 中间件 | 钩子 | 功能 |
|---|---|---|
SummarizationMiddleware |
before_model |
Token 超限时自动压缩历史 |
HumanInTheLoopMiddleware |
wrap_tool_call |
工具调用前请求人工审批 |
ModelFallbackMiddleware |
wrap_model_call |
主模型失败时自动降级 |
LLMToolSelectorMiddleware |
before_model |
根据查询动态筛选工具集 |
ContextEditingMiddleware |
before_model |
裁剪工具结果控制上下文窗口 |
6. RAG 存储链路:从文档到检索
6.1 核心数据流
原始文档
↓ BaseLoader.lazy_load()
Document(page_content, metadata)
↓ TextSplitter.split_documents()
List[Document](分块)
↓ Embeddings.embed_documents()
向量
↓ VectorStore.add_documents()
持久化存储
↓ VectorStore.similarity_search(query)
相关文档 → 注入 Prompt → LLM6.2 VectorStore 接口
VectorStore 基类提供三种核心检索方式:
| 方法 | 说明 |
|---|---|
similarity_search(query, k) |
纯相似度检索,返回 top-k |
max_marginal_relevance_search |
MMR 算法,在相关性和多样性间取平衡 |
as_retriever() |
转换为 Runnable 检索器,可直接接入 LCEL 管道 |
6.3 Indexing API:防重复写入
index() 函数通过 RecordManager 追踪文档哈希,实现增量同步:
python
from langchain_core.indexing import index
result = index(
docs_source, # 文档来源(Loader 或 List[Document])
record_manager, # 记录管理器(追踪已索引文档)
vector_store, # 目标向量存储
cleanup="incremental" # None | "incremental" | "full"
)三种清理模式:None(不删除)、incremental(删除内容变更的旧版本)、full(删除本次未出现的所有文档)。
7. 可观测性:LangSmith 深度集成
LangSmith 在 langchain-core 层就已集成,所有 Runnable 的执行都会自动产生 trace。
astream_events API 是最细粒度的观测接口,每个组件的生命周期都会产生事件:
python
async for event in chain.astream_events(input, version="v2"):
# event["event"] 如: "on_chat_model_stream", "on_tool_end"
# event["name"] 组件名称
# event["data"] 包含 input/output/chunk
if event["event"] == "on_chat_model_stream":
print(event["data"]["chunk"].content, end="")| 组件类型 | 产生的事件 |
|---|---|
BaseChatModel |
on_chat_model_start/stream/end |
BaseTool |
on_tool_start/end/error |
BaseRetriever |
on_retriever_start/end/error |
RunnableSequence 等 |
on_chain_start/stream/end |
8. 工程实践建议
1. 优先使用 LCEL 而非手写循环
LCEL 管道自动获得 async、batch、streaming、tracing 支持,手写循环需要自己实现这些。
2. 用 configurable_alternatives 实现模型热切换
在 A/B 测试或多环境部署时,通过 RunnableConfig.configurable 在运行时切换模型,无需重新构建链。
3. Agent 优先选择 LangGraph
create_agent 底层已经是 LangGraph,对于复杂的多步骤、有状态、需要人工介入的场景,直接使用 LangGraph 的 StateGraph 获得更细粒度的控制。
4. RAG 必用 Indexing API
直接调用 vector_store.add_documents() 会导致重复写入,生产环境务必通过 index() 函数管理文档同步。
5. 用 with_fallbacks 提升生产稳定性
python
primary_model.with_fallbacks(
[backup_model],
exceptions_to_handle=(RateLimitError,)
)总结
LangChain 的核心价值在于三点:
- 统一抽象 :
Runnable接口让所有组件可互换、可组合 - 声明式组合 :LCEL 的
|语法让复杂 Pipeline 的构建和维护成本极低 - 生产就绪:内置 streaming、async、retry、fallback、tracing,不需要从零实现
理解了 Runnable → LCEL → Agent(LangGraph) 这条主线,就掌握了 LangChain 90% 的精髓。 18 19
Citations
File: libs/core/langchain_core/init.py (L1-9)
python
"""`langchain-core` defines the base abstractions for the LangChain ecosystem.
The interfaces for core components like chat models, LLMs, vector stores, retrievers,
and more are defined here. The universal invocation protocol (Runnables) along with
a syntax for combining components are also defined here.
**No third-party integrations are defined here.** The dependencies are kept purposefully
very lightweight.
"""File: AGENTS.md (L30-33)
markdown
- **Core layer** (`langchain-core`): Base abstractions, interfaces, and protocols. Users should not need to know about this layer directly.
- **Implementation layer** (`langchain`): Concrete implementations and high-level public utilities
- **Integration layer** (`partners/`): Third-party service integrations. Note that this monorepo is not exhaustive of all LangChain integrations; some are maintained in separate repos, such as `langchain-ai/langchain-google` and `langchain-ai/langchain-aws`. Usually these repos are cloned at the same level as this monorepo, so if needed, you can refer to their code directly by navigating to `../langchain-google/` from this monorepo.
- **Testing layer** (`standard-tests/`): Standardized integration tests for partner integrationsFile: libs/core/langchain_core/runnables/base.py (L618-707)
python
def __or__(
self,
other: Runnable[Any, Other]
| Callable[[Iterator[Any]], Iterator[Other]]
| Callable[[AsyncIterator[Any]], AsyncIterator[Other]]
| Callable[[Any], Other]
| Mapping[str, Runnable[Any, Other] | Callable[[Any], Other] | Any],
) -> RunnableSerializable[Input, Other]:
"""Runnable "or" operator.
Compose this `Runnable` with another object to create a
`RunnableSequence`.
Args:
other: Another `Runnable` or a `Runnable`-like object.
Returns:
A new `Runnable`.
"""
return RunnableSequence(self, coerce_to_runnable(other))
def __ror__(
self,
other: Runnable[Other, Any]
| Callable[[Iterator[Other]], Iterator[Any]]
| Callable[[AsyncIterator[Other]], AsyncIterator[Any]]
| Callable[[Other], Any]
| Mapping[str, Runnable[Other, Any] | Callable[[Other], Any] | Any],
) -> RunnableSerializable[Other, Output]:
"""Runnable "reverse-or" operator.
Compose this `Runnable` with another object to create a
`RunnableSequence`.
Args:
other: Another `Runnable` or a `Runnable`-like object.
Returns:
A new `Runnable`.
"""
return RunnableSequence(coerce_to_runnable(other), self)
def pipe(
self,
*others: Runnable[Any, Other] | Callable[[Any], Other],
name: str | None = None,
) -> RunnableSerializable[Input, Other]:
"""Pipe `Runnable` objects.
Compose this `Runnable` with `Runnable`-like objects to make a
`RunnableSequence`.
Equivalent to `RunnableSequence(self, *others)` or `self | others[0] | ...`
Example:
```python
from langchain_core.runnables import RunnableLambda
def add_one(x: int) -> int:
return x + 1
def mul_two(x: int) -> int:
return x * 2
runnable_1 = RunnableLambda(add_one)
runnable_2 = RunnableLambda(mul_two)
sequence = runnable_1.pipe(runnable_2)
# Or equivalently:
# sequence = runnable_1 | runnable_2
# sequence = RunnableSequence(first=runnable_1, last=runnable_2)
sequence.invoke(1)
await sequence.ainvoke(1)
# -> 4
sequence.batch([1, 2, 3])
await sequence.abatch([1, 2, 3])
# -> [4, 6, 8]
```
Args:
*others: Other `Runnable` or `Runnable`-like objects to compose
name: An optional name for the resulting `RunnableSequence`.
Returns:
A new `Runnable`.
"""File: libs/core/langchain_core/runnables/base.py (L2995-3017)
python
class RunnableSequence(RunnableSerializable[Input, Output]):
"""Sequence of `Runnable` objects, where the output of one is the input of the next.
**`RunnableSequence`** is the most important composition operator in LangChain
as it is used in virtually every chain.
A `RunnableSequence` can be instantiated directly or more commonly by using the
`|` operator where either the left or right operands (or both) must be a
`Runnable`.
Any `RunnableSequence` automatically supports sync, async, batch.
The default implementations of `batch` and `abatch` utilize threadpools and
asyncio gather and will be faster than naive invocation of `invoke` or `ainvoke`
for IO bound `Runnable`s.
Batching is implemented by invoking the batch method on each component of the
`RunnableSequence` in order.
A `RunnableSequence` preserves the streaming properties of its components, so if
all components of the sequence implement a `transform` method -- which
is the method that implements the logic to map a streaming input to a streaming
output -- then the sequence will be able to stream input to output!File: libs/core/langchain_core/prompts/chat.py (L53-105)
python
class MessagesPlaceholder(BaseMessagePromptTemplate):
"""Prompt template that assumes variable is already list of messages.
A placeholder which can be used to pass in a list of messages.
!!! example "Direct usage"
```python
from langchain_core.prompts import MessagesPlaceholder
prompt = MessagesPlaceholder("history")
prompt.format_messages() # raises KeyError
prompt = MessagesPlaceholder("history", optional=True)
prompt.format_messages() # returns empty list []
prompt.format_messages(
history=[
("system", "You are an AI assistant."),
("human", "Hello!"),
]
)
# -> [
# SystemMessage(content="You are an AI assistant."),
# HumanMessage(content="Hello!"),
# ]
```
!!! example "Building a prompt with chat history"
```python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful assistant."),
MessagesPlaceholder("history"),
("human", "{question}"),
]
)
prompt.invoke(
{
"history": [("human", "what's 5 + 2"), ("ai", "5 + 2 is 7")],
"question": "now multiply that by 4",
}
)
# -> ChatPromptValue(messages=[
# SystemMessage(content="You are a helpful assistant."),
# HumanMessage(content="what's 5 + 2"),
# AIMessage(content="5 + 2 is 7"),
# HumanMessage(content="now multiply that by 4"),
# ])
```File: libs/core/langchain_core/prompts/chat.py (L790-824)
python
class ChatPromptTemplate(BaseChatPromptTemplate):
"""Prompt template for chat models.
Use to create flexible templated prompts for chat models.
!!! example
```python
from langchain_core.prompts import ChatPromptTemplate
template = ChatPromptTemplate(
[
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
]
)
prompt_value = template.invoke(
{
"name": "Bob",
"user_input": "What is your name?",
}
)
# Output:
# ChatPromptValue(
# messages=[
# SystemMessage(content='You are a helpful AI bot. Your name is Bob.'),
# HumanMessage(content='Hello, how are you doing?'),
# AIMessage(content="I'm doing well, thanks!"),
# HumanMessage(content='What is your name?')
# ]
# )
```File: libs/core/langchain_core/prompts/few_shot.py (L325-376)
python
```
Prompt template with dynamically selected examples:
```python
from langchain_core.prompts import SemanticSimilarityExampleSelector
from langchain_core.embeddings import OpenAIEmbeddings
from langchain_core.vectorstores import Chroma
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
{"input": "2+4", "output": "6"},
# ...
]
to_vectorize = [" ".join(example.values()) for example in examples]
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_texts(to_vectorize, embeddings, metadatas=examples)
example_selector = SemanticSimilarityExampleSelector(vectorstore=vectorstore)
from langchain_core import SystemMessage
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts.few_shot import FewShotChatMessagePromptTemplate
few_shot_prompt = FewShotChatMessagePromptTemplate(
# Which variable(s) will be passed to the example selector.
input_variables=["input"],
example_selector=example_selector,
# Define how each example will be formatted.
# In this case, each example will become 2 messages:
# 1 human, and 1 AI
example_prompt=(
HumanMessagePromptTemplate.from_template("{input}")
+ AIMessagePromptTemplate.from_template("{output}")
),
)
# Define the overall prompt.
final_prompt = (
SystemMessagePromptTemplate.from_template("You are a helpful AI Assistant")
+ few_shot_prompt
+ HumanMessagePromptTemplate.from_template("{input}")
)
# Show the prompt
print(final_prompt.format_messages(input="What's 3+3?")) # noqa: T201
# Use within an LLM
from langchain_core.chat_models import ChatAnthropic
chain = final_prompt | ChatAnthropic(model="claude-3-haiku-20240307")
chain.invoke({"input": "What's 3+3?"})
```File: libs/langchain_v1/tests/integration_tests/chat_models/test_base.py (L22-35)
python
async def test_init_chat_model_chain() -> None:
model = init_chat_model("gpt-4o", configurable_fields="any", config_prefix="bar")
model_with_tools = model.bind_tools([Multiply])
model_with_config = model_with_tools.with_config(
RunnableConfig(tags=["foo"]),
configurable={"bar_model": "claude-sonnet-4-5-20250929"},
)
prompt = ChatPromptTemplate.from_messages([("system", "foo"), ("human", "{input}")])
chain = prompt | model_with_config
output = chain.invoke({"input": "bar"})
assert isinstance(output, AIMessage)
events = [event async for event in chain.astream_events({"input": "bar"}, version="v2")]
assert eventsFile: libs/langchain_v1/langchain/agents/init.py (L1-9)
python
"""Entrypoint to building [Agents](https://docs.langchain.com/oss/python/langchain/agents) with LangChain.""" # noqa: E501
from langchain.agents.factory import create_agent
from langchain.agents.middleware.types import AgentState
__all__ = [
"AgentState",
"create_agent",
]File: libs/langchain_v1/langchain/agents/factory.py (L543-688)
python
):
return True
return (
any(part in model_name.lower() for part in FALLBACK_MODELS_WITH_STRUCTURED_OUTPUT)
if model_name
else False
)
def _handle_structured_output_error(
exception: Exception,
response_format: ResponseFormat[Any],
) -> tuple[bool, str]:
"""Handle structured output error.
Returns `(should_retry, retry_tool_message)`.
"""
if not isinstance(response_format, ToolStrategy):
return False, ""
handle_errors = response_format.handle_errors
if handle_errors is False:
return False, ""
if handle_errors is True:
return True, STRUCTURED_OUTPUT_ERROR_TEMPLATE.format(error=str(exception))
if isinstance(handle_errors, str):
return True, handle_errors
if isinstance(handle_errors, type):
if issubclass(handle_errors, Exception) and isinstance(exception, handle_errors):
return True, STRUCTURED_OUTPUT_ERROR_TEMPLATE.format(error=str(exception))
return False, ""
if isinstance(handle_errors, tuple):
if any(isinstance(exception, exc_type) for exc_type in handle_errors):
return True, STRUCTURED_OUTPUT_ERROR_TEMPLATE.format(error=str(exception))
return False, ""
return True, handle_errors(exception)
def _chain_tool_call_wrappers(
wrappers: Sequence[ToolCallWrapper],
) -> ToolCallWrapper | None:
"""Compose wrappers into middleware stack (first = outermost).
Args:
wrappers: Wrappers in middleware order.
Returns:
Composed wrapper, or `None` if empty.
Example:
```python
wrapper = _chain_tool_call_wrappers([auth, cache, retry])
# Request flows: auth -> cache -> retry -> tool
# Response flows: tool -> retry -> cache -> auth
```
"""
if not wrappers:
return None
if len(wrappers) == 1:
return wrappers[0]
def compose_two(outer: ToolCallWrapper, inner: ToolCallWrapper) -> ToolCallWrapper:
"""Compose two wrappers where outer wraps inner."""
def composed(
request: ToolCallRequest,
execute: Callable[[ToolCallRequest], ToolMessage | Command[Any]],
) -> ToolMessage | Command[Any]:
# Create a callable that invokes inner with the original execute
def call_inner(req: ToolCallRequest) -> ToolMessage | Command[Any]:
return inner(req, execute)
# Outer can call call_inner multiple times
return outer(request, call_inner)
return composed
# Chain all wrappers: first -> second -> ... -> last
result = wrappers[-1]
for wrapper in reversed(wrappers[:-1]):
result = compose_two(wrapper, result)
return result
def _chain_async_tool_call_wrappers(
wrappers: Sequence[
Callable[
[ToolCallRequest, Callable[[ToolCallRequest], Awaitable[ToolMessage | Command[Any]]]],
Awaitable[ToolMessage | Command[Any]],
]
],
) -> (
Callable[
[ToolCallRequest, Callable[[ToolCallRequest], Awaitable[ToolMessage | Command[Any]]]],
Awaitable[ToolMessage | Command[Any]],
]
| None
):
"""Compose async wrappers into middleware stack (first = outermost).
Args:
wrappers: Async wrappers in middleware order.
Returns:
Composed async wrapper, or `None` if empty.
"""
if not wrappers:
return None
if len(wrappers) == 1:
return wrappers[0]
def compose_two(
outer: Callable[
[ToolCallRequest, Callable[[ToolCallRequest], Awaitable[ToolMessage | Command[Any]]]],
Awaitable[ToolMessage | Command[Any]],
],
inner: Callable[
[ToolCallRequest, Callable[[ToolCallRequest], Awaitable[ToolMessage | Command[Any]]]],
Awaitable[ToolMessage | Command[Any]],
],
) -> Callable[
[ToolCallRequest, Callable[[ToolCallRequest], Awaitable[ToolMessage | Command[Any]]]],
Awaitable[ToolMessage | Command[Any]],
]:
"""Compose two async wrappers where outer wraps inner."""
async def composed(
request: ToolCallRequest,
execute: Callable[[ToolCallRequest], Awaitable[ToolMessage | Command[Any]]],
) -> ToolMessage | Command[Any]:
# Create an async callable that invokes inner with the original execute
async def call_inner(req: ToolCallRequest) -> ToolMessage | Command[Any]:
return await inner(req, execute)
# Outer can call call_inner multiple times
return await outer(request, call_inner)
return composed
# Chain all wrappers: first -> second -> ... -> last
result = wrappers[-1]File: libs/core/langchain_core/vectorstores/base.py (L43-45)
python
class VectorStore(ABC):
"""Interface for vector store."""File: libs/core/langchain_core/indexing/api.py (L175-205)
python
def _get_document_with_hash(
document: Document,
*,
key_encoder: Callable[[Document], str]
| Literal["sha1", "sha256", "sha512", "blake2b"],
) -> Document:
"""Calculate a hash of the document, and assign it to the uid.
When using one of the predefined hashing algorithms, the hash is calculated
by hashing the content and the metadata of the document.
Args:
document: Document to hash.
key_encoder: Hashing algorithm to use for hashing the document.
If not provided, a default encoder using SHA-1 will be used.
SHA-1 is not collision-resistant, and a motivated attacker
could craft two different texts that hash to the
same cache key.
New applications should use one of the alternative encoders
or provide a custom and strong key encoder function to avoid this risk.
When changing the key encoder, you must change the
index as well to avoid duplicated documents in the cache.
Raises:
ValueError: If the metadata cannot be serialized using json.
Returns:
Document with a unique identifier based on the hash of the content and metadata.
"""File: libs/core/langchain_core/indexing/api.py (L400-450)
python
"delete" and "add_documents" required methods.
ValueError: If source_id_key is not None, but is not a string or callable.
TypeError: If `vectorstore` is not a `VectorStore` or a DocumentIndex.
AssertionError: If `source_id` is None when cleanup mode is incremental.
(should be unreachable code).
"""
# Behavior is deprecated, but we keep it for backwards compatibility.
# # Warn only once per process.
if key_encoder == "sha1":
_warn_about_sha1()
if cleanup not in {"incremental", "full", "scoped_full", None}:
msg = (
f"cleanup should be one of 'incremental', 'full', 'scoped_full' or None. "
f"Got {cleanup}."
)
raise ValueError(msg)
if (cleanup in {"incremental", "scoped_full"}) and source_id_key is None:
msg = (
"Source id key is required when cleanup mode is incremental or scoped_full."
)
raise ValueError(msg)
destination = vector_store # Renaming internally for clarity
# If it's a vectorstore, let's check if it has the required methods.
if isinstance(destination, VectorStore):
# Check that the Vectorstore has required methods implemented
methods = ["delete", "add_documents"]
for method in methods:
if not hasattr(destination, method):
msg = (
f"Vectorstore {destination} does not have required method {method}"
)
raise ValueError(msg)
if type(destination).delete == VectorStore.delete:
# Checking if the VectorStore has overridden the default delete method
# implementation which just raises a NotImplementedError
msg = "Vectorstore has not implemented the delete method"
raise ValueError(msg)
elif isinstance(destination, DocumentIndex):
pass
else:
msg = (
f"Vectorstore should be either a VectorStore or a DocumentIndex. "
f"Got {type(destination)}."
)
raise TypeError(msg)File: libs/core/langchain_core/tracers/event_stream.py (L101-200)
python
class _AstreamEventsCallbackHandler(AsyncCallbackHandler, _StreamingCallbackHandler):
"""An implementation of an async callback handler for astream events."""
def __init__(
self,
*args: Any,
include_names: Sequence[str] | None = None,
include_types: Sequence[str] | None = None,
include_tags: Sequence[str] | None = None,
exclude_names: Sequence[str] | None = None,
exclude_types: Sequence[str] | None = None,
exclude_tags: Sequence[str] | None = None,
**kwargs: Any,
) -> None:
"""Initialize the tracer."""
super().__init__(*args, **kwargs)
# Map of run ID to run info.
# the entry corresponding to a given run id is cleaned
# up when each corresponding run ends.
self.run_map: dict[UUID, RunInfo] = {}
# The callback event that corresponds to the end of a parent run
# may be invoked BEFORE the callback event that corresponds to the end
# of a child run, which results in clean up of run_map.
# So we keep track of the mapping between children and parent run IDs
# in a separate container. This container is GCed when the tracer is GCed.
self.parent_map: dict[UUID, UUID | None] = {}
self.is_tapped: dict[UUID, Any] = {}
# Filter which events will be sent over the queue.
self.root_event_filter = _RootEventFilter(
include_names=include_names,
include_types=include_types,
include_tags=include_tags,
exclude_names=exclude_names,
exclude_types=exclude_types,
exclude_tags=exclude_tags,
)
try:
loop = asyncio.get_event_loop()
except RuntimeError:
loop = asyncio.new_event_loop()
memory_stream = _MemoryStream[StreamEvent](loop)
self.send_stream = memory_stream.get_send_stream()
self.receive_stream = memory_stream.get_receive_stream()
def _get_parent_ids(self, run_id: UUID) -> list[str]:
"""Get the parent IDs of a run (non-recursively) cast to strings."""
parent_ids = []
while parent_id := self.parent_map.get(run_id):
str_parent_id = str(parent_id)
if str_parent_id in parent_ids:
msg = (
f"Parent ID {parent_id} is already in the parent_ids list. "
f"This should never happen."
)
raise AssertionError(msg)
parent_ids.append(str_parent_id)
run_id = parent_id
# Return the parent IDs in reverse order, so that the first
# parent ID is the root and the last ID is the immediate parent.
return parent_ids[::-1]
def _send(self, event: StreamEvent, event_type: str) -> None:
"""Send an event to the stream."""
if self.root_event_filter.include_event(event, event_type):
self.send_stream.send_nowait(event)
def __aiter__(self) -> AsyncIterator[Any]:
"""Iterate over the receive stream.
Returns:
An async iterator over the receive stream.
"""
return self.receive_stream.__aiter__()
async def tap_output_aiter(
self, run_id: UUID, output: AsyncIterator[T]
) -> AsyncIterator[T]:
"""Tap the output aiter.
This method is used to tap the output of a `Runnable` that produces an async
iterator. It is used to generate stream events for the output of the `Runnable`.
Args:
run_id: The ID of the run.
output: The output of the `Runnable`.
Yields:
The output of the `Runnable`.
"""
sentinel = object()
# atomic check and set
tap = self.is_tapped.setdefault(run_id, sentinel)
# wait for first chunk
first = await anext(output, sentinel)
if first is sentinel:File: libs/core/langchain_core/runnables/fallbacks.py (L36-108)
python
class RunnableWithFallbacks(RunnableSerializable[Input, Output]):
"""`Runnable` that can fallback to other `Runnable` objects if it fails.
External APIs (e.g., APIs for a language model) may at times experience
degraded performance or even downtime.
In these cases, it can be useful to have a fallback `Runnable` that can be
used in place of the original `Runnable` (e.g., fallback to another LLM provider).
Fallbacks can be defined at the level of a single `Runnable`, or at the level
of a chain of `Runnable`s. Fallbacks are tried in order until one succeeds or
all fail.
While you can instantiate a `RunnableWithFallbacks` directly, it is usually
more convenient to use the `with_fallbacks` method on a `Runnable`.
Example:
```python
from langchain_core.chat_models.openai import ChatOpenAI
from langchain_core.chat_models.anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-sonnet-4-6").with_fallbacks(
[ChatOpenAI(model="gpt-5.4-mini")]
)
# Will usually use ChatAnthropic, but fallback to ChatOpenAI
# if ChatAnthropic fails.
model.invoke("hello")
# And you can also use fallbacks at the level of a chain.
# Here if both LLM providers fail, we'll fallback to a good hardcoded
# response.
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parser import StrOutputParser
from langchain_core.runnables import RunnableLambda
def when_all_is_lost(inputs):
return (
"Looks like our LLM providers are down. "
"Here's a nice 🦜️ emoji for you instead."
)
chain_with_fallback = (
PromptTemplate.from_template("Tell me a joke about {topic}")
| model
| StrOutputParser()
).with_fallbacks([RunnableLambda(when_all_is_lost)])
```
"""
runnable: Runnable[Input, Output]
"""The `Runnable` to run first."""
fallbacks: Sequence[Runnable[Input, Output]]
"""A sequence of fallbacks to try."""
exceptions_to_handle: tuple[type[BaseException], ...] = (Exception,)
"""The exceptions on which fallbacks should be tried.
Any exception that is not a subclass of these exceptions will be raised immediately.
"""
exception_key: str | None = None
"""If `string` is specified then handled exceptions will be passed to fallbacks as
part of the input under the specified key.
If `None`, exceptions will not be passed to fallbacks.
If used, the base `Runnable` and its fallbacks must accept a dictionary as input.
"""
model_config = ConfigDict(
arbitrary_types_allowed=True,
)File: libs/core/README.md (L29-34)
markdown
The LangChain ecosystem is built on top of `langchain-core`. Some of the benefits:
- **Modularity**: We've designed Core around abstractions that are independent of each other, and not tied to any specific model provider.
- **Stability**: We are committed to a stable versioning scheme, and will communicate any breaking changes with advance notice and version bumps.
- **Battle-tested**: Core components have the largest install base in the LLM ecosystem, and are used in production by many companies.File: README.md (L63-71)
markdown
LangChain helps developers build applications powered by LLMs through a standard interface for models, embeddings, vector stores, and more.
- **Real-time data augmentation** --- Easily connect LLMs to diverse data sources and external/internal systems, drawing from LangChain's vast library of integrations with model providers, tools, vector stores, retrievers, and more
- **Model interoperability** --- Swap models in and out as your engineering team experiments to find the best choice for your application's needs. As the industry frontier evolves, adapt quickly --- LangChain's abstractions keep you moving without losing momentum
- **Rapid prototyping** --- Quickly build and iterate on LLM applications with LangChain's modular, component-based architecture. Test different approaches and workflows without rebuilding from scratch, accelerating your development cycle
- **Production-ready features** --- Deploy reliable applications with built-in support for monitoring, evaluation, and debugging through integrations like LangSmith. Scale with confidence using battle-tested patterns and best practices
- **Vibrant community and ecosystem** --- Leverage a rich ecosystem of integrations, templates, and community-contributed components. Benefit from continuous improvements and stay up-to-date with the latest AI developments through an active open-source community
- **Flexible abstraction layers** --- Work at the level of abstraction that suits your needs --- from high-level chains for quick starts to low-level components for fine-grained control. LangChain grows with your application's complexity