Python 学习第 35 天。
一、防盗链
防盗链是网站的一种反盗链、反爬虫防护机制,为了保护自身的资源(图片、视频、音频、接口数据)不被盗用而设置的机制,只允许访问者通过本网站的域名访问资源,通过第三方直接引用则会 403 或虚假资源。(可以类比理解为:公司规定,客户可以通过公司的官方渠道找到公司内的一个员工为他提供技术服务,但不能私下与他个人联系,直接与其达成合作)
所以,网站设置防盗链的目的就是防止他人盗用带宽与流量、保护版权。
那么,网站是怎么判定访问者是不是在本网站的域名下访问资源的呢?本质上是在访问者提出 "访问" 请求时,通过 HTTP 请求头中的 Referer 字段记录来源页、跳转来源来告诉服务器 "现在这个请求是从哪个页面发起 / 跳转过来的"。
二、模拟浏览器跳转 - 防盗链处理
正常我们用浏览器访问网站(隐私模式、HTTPS 跳转 HTTP 场景除外),再通过网站点击其中的某个链接,跳转时 HTTP 请求头中会自动携带 Referer,但 Python 中与爬虫相关的主流库 requests / urllib 默认不会携带 Referer,这就导致它在设置有防盗链机制的网站下爬取信息时会被拦截。对此,我们的处理思路就是:让爬虫带上合法的 Referer。
1. 安装包
pip install requests首次安装,运行结果末端出现 Successfully installed 后面跟 模块名称、版本号的语句就说明安装成功了。
已经安装过的,这一部分可以跳过,直接导入包即可,但如果执行这段代码,运行结果会提示Requirement already satisfied: 后面跟 模块名、版本号的语句,提示我们已经安装过了,以及存储的路径和版本。
2. 导入包
import requests3. 处理过程
**步骤一:**打开目标网站
**步骤二:**打开 "开发人员工具"
(1) 快捷键:F12 或 Ctrl + Shift + I(Window 系统)或 Cmd + Opt + I(Mac 系统)
(2) 鼠标操作:右键 → 检查 或 网页右上方三个点 → 更多工具 → 开发人员工具
**步骤三:**勾选 "保留日志(Preserve log)",右键 → 刷新界面 / 点击资源链接

**步骤四:**打开 "网络面板(Network)"(文字 / 图标按钮,每个系统不太一样,在上方或者侧方的菜单栏中找一下)
步骤五: 在网页中点击需要跳转的资源(图片、视频、音频、链接等),复制它的链接,并将其粘贴存储到代表 "爬取目标地址的变量" 中,格式:代表目标资源地址的变量名 = "爬取目标资源的地址"
re_url = "https://image.baidu.com/search/detail?adpicid=0&b_applid=11005773261565612244&bdtype=0&commodity=©right=&cs=2230194132%2C3215431079&di=7646086322926387201&fr=click-pic&fromurl=http%253A%252F%252Fwww.douyin.com%252Fnote%252F7369250740084182307&gsm=1e&hd=&height=0&hot=&ic=&ie=utf-8&imgformat=&imgratio=&imgspn=0&is=2367359700%2C3655770656&isImgSet=&latest=&lid=9b01b4d700998f89&lm=&objurl=https%253A%252F%252Fp3-pc-sign.douyinpic.com%252Ftos-cn-i-0813%252FoIBAaon18AZNR1E4A9KzACeAAbeEIDAbgmNrSD~tplv-dy-aweme-images%253Aq75.webp%253Fbiz_tag%253Daweme_images%2526from%253D3213915784%2526s%253DPackSourceEnum_SEO%2526sc%253Dimage%2526se%253Dfalse%2526x-expires%253D1718532000%2526x-signature%253DVvjVekWXLRjEusjcBpxmPKzPGSM%25253D&os=2367359700%2C3655770656&pd=image_content&pi=0&pn=2&rn=1&simid=2230194132%2C3215431079&tn=baiduimagedetail&width=0&word=%E7%AB%A0%E9%B1%BC%E5%93%A5&z="**步骤六:**在请求列表的 "名称" 找到刚刚点击跳转的请求并点开
**步骤七:**在 "标头" 中的 "请求标头" 中找到 Referer 字段,后面跟着的就是请求来源页(一般是网站首页 / 上级页)
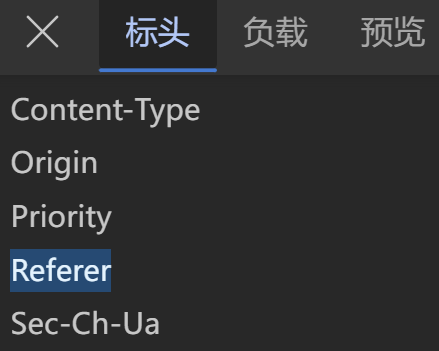
**步骤八:将 Referer 设置到伪装请求头中,格式:****代表伪装请求头的变量名 = {"Referer":"请求来源页"},"User-agent":......**的设置也是为了反爬,用于模拟设备信息,告诉服务器用的是什么浏览器、操作系统、设备类型("User-agent" 同样能在 "请求标头" 中找到)
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/126.0.0.0 Safari/537.36",
"Referer":"https://image.baidu.com/"
}步骤九: 验证是否能正常访问(返回状态码:200),格式:requests.get(目标资源链接, headers = 代表伪装头请求头的变量名)
response = requests.get(re_url, headers=headers)
print("状态码:", response.status_code)运行结果:状态码: 200