摘要
时间序列预测是数据挖掘与机器学习领域的重要课题。单一模型往往难以兼顾泛化能力与预测精度,而集成学习通过组合多个弱学习器可以显著提升性能。本文介绍一种基于Adaboost算法增强的随机森林回归模型(RF-Adaboost),用于多变量时间序列的单步预测。文章将简述研究背景、核心功能、算法步骤、技术路线、关键公式与参数设置,并给出运行环境及应用场景。代码基于MATLAB实现,已在公开数据集上验证有效性。
一、研究背景
在实际工程与商业场景中,如股票价格、电力负荷、交通流量、环境监测等,数据往往以时间序列形式存在。准确预测未来趋势对于决策支持至关重要。
- 传统方法:ARIMA、指数平滑等线性模型难以捕捉非线性模式。
- 机器学习方法:支持向量回归(SVR)、人工神经网络(ANN)等具有一定非线性拟合能力,但容易过拟合或调参复杂。
- 集成学习方法:随机森林(Random Forest, RF)通过多棵决策树投票/平均,具有抗过拟合、可解释性好的优点;Adaboost(Adaptive Boosting)通过迭代调整样本权重,聚焦难例,进一步提升精度。
将Adaboost与随机森林结合(RF-Adaboost),既保留随机森林的稳定性,又利用Boosting的纠错能力,适用于中小规模时间序列预测任务。
二、主要功能
本代码实现以下核心功能:
-
数据预处理
- 读取Excel表格数据。
- 采用滑动窗口构造监督学习样本:用过去
n_in个时刻的多维特征,预测未来n_out个时刻的目标值(本代码为单步预测)。 - 自动控制生成样本数量(
num_samples)及滑动步长(scroll_window)。
-
训练/测试集划分
- 按指定比例(默认80%)划分训练集与测试集。
-
数据归一化
- 使用
mapminmax函数将输入和输出特征线性缩放到 0,1 区间,消除量纲影响。
- 使用
-
Adaboost增强的随机森林回归
- 迭代训练
K个随机森林弱回归器。 - 每轮迭代根据上一轮预测误差更新样本权重。
- 计算每个弱回归器的权重,最后加权组合得到强预测器。
- 迭代训练
-
结果反归一化与误差评估
- 将预测值还原至原始量纲。
- 计算多项评估指标:MAE、MAPE、MSE、RMSE、R²、RPD。
-
可视化输出
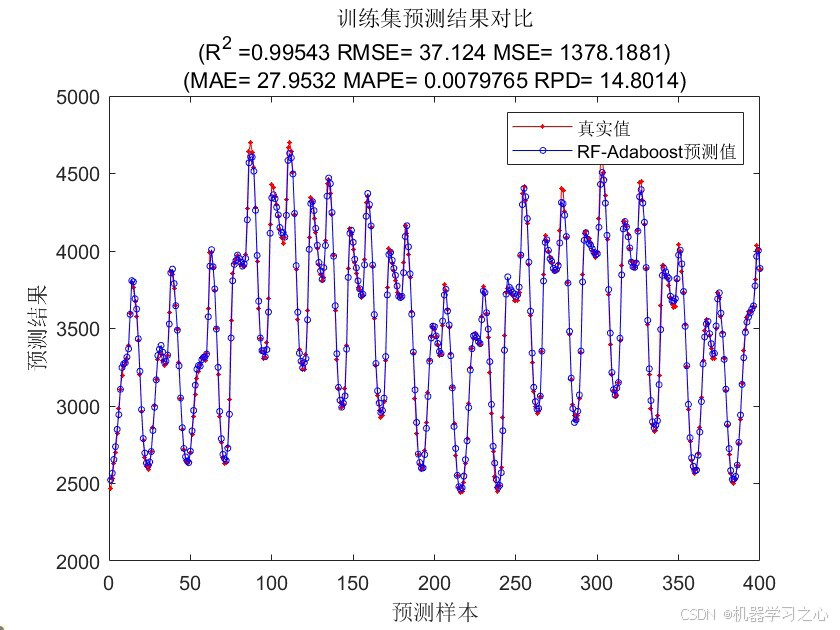
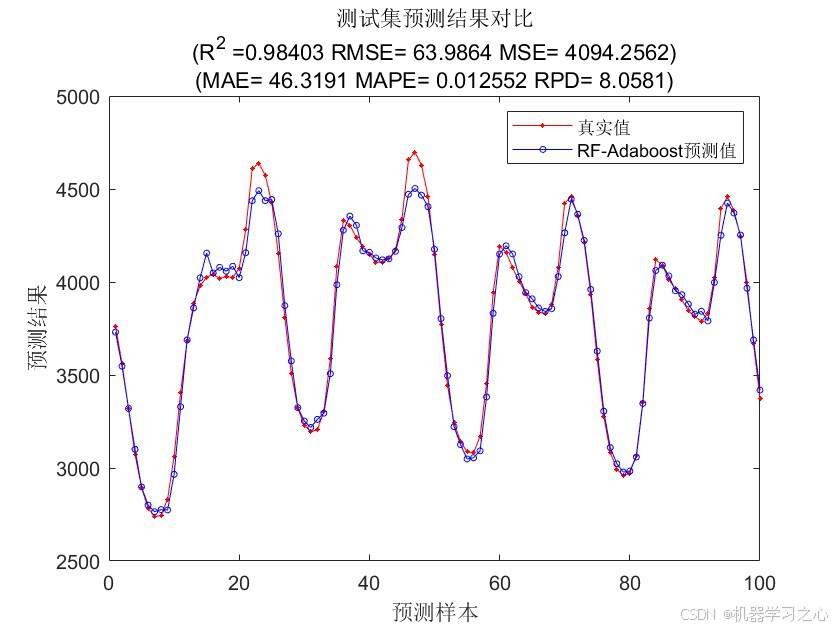
- 绘制训练集/测试集真实值与预测值对比图。
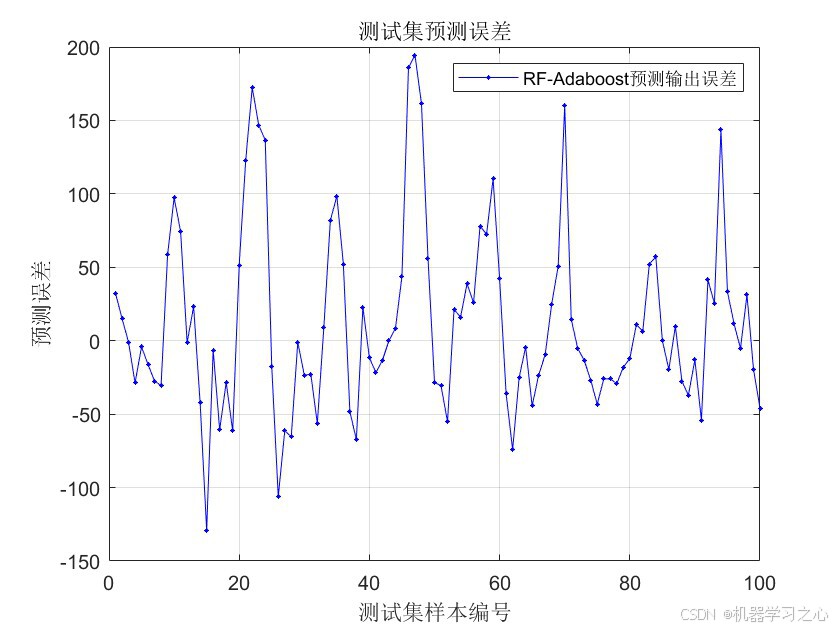
- 绘制测试集预测误差曲线。
三、算法步骤
RF-Adaboost 的具体实现流程如下:
3.1 数据整理
- 输入:原始多变量时间序列矩阵
X(每列为一个特征)。 - 设定时间步长
n_in=3,即用第t-2, t-1, t时刻的所有特征,预测第t+1时刻的目标变量。 - 通过滑动窗口生成
num_samples个样本,每个样本的输入形状为(n_in * or_dim),输出为标量。
3.2 初始化
- 训练样本数
M,测试样本数N。 - 样本权重向量
D初始化为均匀分布:D(1, j) = 1/M。 - 弱回归器个数
K = 10,随机森林参数:树的数量n_trees = 50,每棵树的随机特征数n_layer = 30。
3.3 迭代训练弱回归器
对于第 i 轮(i = 1..K):
- 根据当前样本权重分布
D(i, :)训练随机森林模型(注:本代码未显式使用权重进行重采样,实际使用时需修改regRF_train支持样本权重;默认代码仅按原始数据训练,权重的调整仅用于后续弱学习器权重计算)。 - 对训练集预测,得到预测值
t_sim1(i, :),计算绝对误差Error(i, j)。 - 更新样本权重 :
若|Error(i, j)| > 0.02,则增大该样本权重:D(i+1, j) = D(i, j) * 1.1;
否则权重不变。 - 计算弱学习器权重 :
weight(i) = 0.5 / exp( |sum_{j:误差>0.02} D(i, j)| )
其中分母中的weight(i)实际为误差大于阈值的样本权重和。 - 归一化
D(i+1, :)使其总和为1。
3.4 构建强预测器
- 将所有弱学习器的权重归一化:
weight = weight / sum(weight)。 - 强预测器输出为各弱学习器预测值的加权和:
T_sim = Σ_i weight(i) * t_sim_i
3.5 后处理与评估
- 将预测值反归一化至原始量纲。
- 计算训练集与测试集上的误差指标,并绘图。
四、技术路线
下图展示了本模型的完整技术路线:
#mermaid-svg-3yKAPnTFMi1q4gJs{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-3yKAPnTFMi1q4gJs .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-3yKAPnTFMi1q4gJs .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-3yKAPnTFMi1q4gJs .error-icon{fill:#552222;}#mermaid-svg-3yKAPnTFMi1q4gJs .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-3yKAPnTFMi1q4gJs .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-3yKAPnTFMi1q4gJs .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-3yKAPnTFMi1q4gJs .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-3yKAPnTFMi1q4gJs .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-3yKAPnTFMi1q4gJs .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-3yKAPnTFMi1q4gJs .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-3yKAPnTFMi1q4gJs .marker{fill:#333333;stroke:#333333;}#mermaid-svg-3yKAPnTFMi1q4gJs .marker.cross{stroke:#333333;}#mermaid-svg-3yKAPnTFMi1q4gJs svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-3yKAPnTFMi1q4gJs p{margin:0;}#mermaid-svg-3yKAPnTFMi1q4gJs .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-3yKAPnTFMi1q4gJs .cluster-label text{fill:#333;}#mermaid-svg-3yKAPnTFMi1q4gJs .cluster-label span{color:#333;}#mermaid-svg-3yKAPnTFMi1q4gJs .cluster-label span p{background-color:transparent;}#mermaid-svg-3yKAPnTFMi1q4gJs .label text,#mermaid-svg-3yKAPnTFMi1q4gJs span{fill:#333;color:#333;}#mermaid-svg-3yKAPnTFMi1q4gJs .node rect,#mermaid-svg-3yKAPnTFMi1q4gJs .node circle,#mermaid-svg-3yKAPnTFMi1q4gJs .node ellipse,#mermaid-svg-3yKAPnTFMi1q4gJs .node polygon,#mermaid-svg-3yKAPnTFMi1q4gJs .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-3yKAPnTFMi1q4gJs .rough-node .label text,#mermaid-svg-3yKAPnTFMi1q4gJs .node .label text,#mermaid-svg-3yKAPnTFMi1q4gJs .image-shape .label,#mermaid-svg-3yKAPnTFMi1q4gJs .icon-shape .label{text-anchor:middle;}#mermaid-svg-3yKAPnTFMi1q4gJs .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-3yKAPnTFMi1q4gJs .rough-node .label,#mermaid-svg-3yKAPnTFMi1q4gJs .node .label,#mermaid-svg-3yKAPnTFMi1q4gJs .image-shape .label,#mermaid-svg-3yKAPnTFMi1q4gJs .icon-shape .label{text-align:center;}#mermaid-svg-3yKAPnTFMi1q4gJs .node.clickable{cursor:pointer;}#mermaid-svg-3yKAPnTFMi1q4gJs .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-3yKAPnTFMi1q4gJs .arrowheadPath{fill:#333333;}#mermaid-svg-3yKAPnTFMi1q4gJs .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-3yKAPnTFMi1q4gJs .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-3yKAPnTFMi1q4gJs .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-3yKAPnTFMi1q4gJs .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-3yKAPnTFMi1q4gJs .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-3yKAPnTFMi1q4gJs .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-3yKAPnTFMi1q4gJs .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-3yKAPnTFMi1q4gJs .cluster text{fill:#333;}#mermaid-svg-3yKAPnTFMi1q4gJs .cluster span{color:#333;}#mermaid-svg-3yKAPnTFMi1q4gJs div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-3yKAPnTFMi1q4gJs .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-3yKAPnTFMi1q4gJs rect.text{fill:none;stroke-width:0;}#mermaid-svg-3yKAPnTFMi1q4gJs .icon-shape,#mermaid-svg-3yKAPnTFMi1q4gJs .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-3yKAPnTFMi1q4gJs .icon-shape p,#mermaid-svg-3yKAPnTFMi1q4gJs .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-3yKAPnTFMi1q4gJs .icon-shape .label rect,#mermaid-svg-3yKAPnTFMi1q4gJs .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-3yKAPnTFMi1q4gJs .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-3yKAPnTFMi1q4gJs .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-3yKAPnTFMi1q4gJs :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 原始时间序列
滑动窗口构造样本
划分训练集/测试集
归一化
初始化样本权重D
迭代i=1..K
训练随机森林弱学习器
预测并计算误差
更新样本权重D
计算弱学习器权重
加权组合强预测器
反归一化
误差指标计算与可视化
五、公式原理
Adaboost回归的变种较多,本代码采用类似 Adaboost.R2 的机制,但进行了简化。
5.1 样本权重更新
设第 i 个弱学习器在训练样本 j 上的绝对误差为
e_ij = | y_j - f_i(x_j) |。
设定一个误差容忍阈值 θ = 0.02(归一化后的误差界限)。
则样本权重更新规则为:
D i + 1 ( j ) = { D i ( j ) × β , if e i j > θ D i ( j ) , otherwise D_{i+1}(j) = \begin{cases} D_i(j) \times \beta, & \text{if } e_ij > \theta \\ D_i(j), & \text{otherwise} \end{cases} Di+1(j)={Di(j)×β,Di(j),if eij>θotherwise
其中 β = 1.1 为放大因子。随后归一化:
D i + 1 ( j ) ← D i + 1 ( j ) ∑ j = 1 M D i + 1 ( j ) D_{i+1}(j) \leftarrow \frac{D_{i+1}(j)}{\sum_{j=1}^{M} D_{i+1}(j)} Di+1(j)←∑j=1MDi+1(j)Di+1(j)
5.2 弱学习器权重计算
首先计算加权误差率:
ε i = ∑ j : e i j > θ D i ( j ) ∑ j = 1 M D i ( j ) \varepsilon_i = \frac{\sum_{j: e_ij > \theta} D_i(j)}{\sum_{j=1}^{M} D_i(j)} εi=∑j=1MDi(j)∑j:eij>θDi(j)
由于 D_i 已经归一化,分母为1,故 ε_i 即为误差超过阈值的样本权重和。
然后弱学习器权重为:
α i = 0.5 exp ( ∣ ε i ∣ ) \alpha_i = \frac{0.5}{\exp(|\varepsilon_i|)} αi=exp(∣εi∣)0.5
该函数使得误差率越高,α_i 越小(指数衰减),但始终为正。最后将所有 α_i 归一化得到最终集成权重。
5.3 强预测器输出
F ( x ) = ∑ i = 1 K α i ⋅ f i ( x ) ∑ i = 1 K α i F(x) = \frac{\sum_{i=1}^{K} \alpha_i \cdot f_i(x)}{\sum_{i=1}^{K} \alpha_i} F(x)=∑i=1Kαi∑i=1Kαi⋅fi(x)
即为加权平均。
六、参数设定
| 参数名 | 取值 | 说明 |
|---|---|---|
n_in |
3 | 输入历史时刻数 |
n_out |
1 | 预测未来时刻数(单步) |
num_samples |
500 | 生成的样本总数 |
scroll_window |
1 | 滑动窗口步长 |
num_size |
0.8 | 训练集比例 |
n_trees |
50 | 随机森林中决策树的数量 |
n_layer |
30 | 每棵树随机选择的特征数 |
K |
10 | 弱回归器个数(迭代次数) |
| 误差阈值 | 0.02 | 用于判定样本是否"难例" |
| 权重放大因子 | 1.1 | 难例权重增加倍数 |
这些参数可根据实际数据集规模与特性进行调节。例如,对于噪声较大的数据,可增大n_trees和K,或调高误差阈值。
七、运行环境
- 软件:MATLAB R2018b 及以上版本(推荐)
- 依赖工具箱 :
- 随机森林回归函数(
regRF_train.m,regRF_predict.m),可从 Random Forest for MATLAB 获取。 - 基础函数
calc_error.m(计算MAE, MAPE等指标),需自行实现或包含在工程中。
- 随机森林回归函数(
- 操作系统:Windows / Linux / macOS
- 数据格式 :Excel 文件(
.xlsx),第一行为变量名或直接为数值矩阵。
执行前请确保所有自定义函数位于 MATLAB 搜索路径中,并且已安装必要的读取 Excel 的支持包。
八、应用场景
RF-Adaboost 模型适用于以下典型场景:
- 金融时间序列预测:股票收盘价、基金净值、汇率等短期趋势预测。
- 电力负荷预测:基于历史功率、温度、湿度等特征预测未来1-6小时的负荷。
- 环境监测:PM2.5、空气质量指数(AQI)的短期预测。
- 工业过程控制:设备传感器数据(振动、电流)的异常趋势预警。
- 交通流预测:根据过去几个时间点的车流量预测下一时段的路段通行时间。
本模型对中等规模数据(几百到几千样本)效果较好,且由于集成随机森林,对噪声和缺失值有一定鲁棒性。若数据具有强周期性,建议先进行差分或季节分解。
总结
本文详细介绍了基于Adaboost增强的随机森林回归模型(RF-Adaboost)的MATLAB实现。该模型通过Boosting框架迭代更新样本权重,聚焦于难以预测的样本,从而提升整体回归精度。代码结构清晰,包含数据预处理、模型训练、加权集成、误差评估与可视化全套流程。读者可根据实际需求修改参数、替换数据集,快速应用于自己的时间序列预测任务。