文章目录
- 为什么学习string
- string的底层
- 怎么学习string
- string的遍历方法
-
- [下标+ ](#下标+[ ])
- 迭代器遍历
- 范围for遍历
- 迭代器遍历与范围for
- 用反向迭代器反向遍历
- 迭代器的分类
- auto
-
- 一般用于替代长类型
- 必须有初始值设定项
- 缺陷
- 可用typeid来得知具体类型
- [加 * 或 &](#加 * 或 &)
- capacity(string的空间类接口)
- [operator ](#operator [ ])
- Modifiers:
- [String operations:](#String operations:)
- 非成员函数
为什么学习string
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
string的底层
大概是下面这样子,简单来说就是一个字符顺序表

怎么学习string
比较通用的方法是直接去查文档,这里我提供一下C++文档的链接:点击跳转C++文档。
string的遍历方法
下标+
如下图,其中size()函数是获取字符串的长度(不包含\0 )

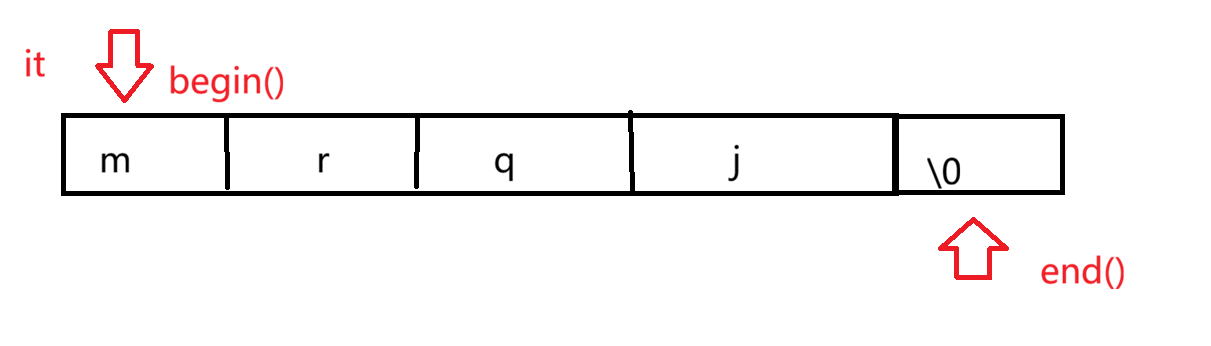
迭代器遍历
所谓迭代器和指针很类似,甚至在string类中,迭代器的底层就是指针。但在像链表等不连续的数据结构中,迭代器的底层不是指针。

关于begin()和end(),可以根据下图来理解
范围for遍历

范围for其实底层就是迭代器,只是换了个形式而已,没有什么本质的不同。自动赋值,自动迭代,自动判断结束。
auto 中文自动的意思,这里指的是自动判断类型 ,这里的auto换成char也可
范围for同样适用于容器和数组
下图是两种 Int 数组遍历方法的对比。

迭代器遍历与范围for
用迭代器遍历时我们可以直接对string作出修改 ,如下将字母的ASCII码+1。注意 *i t +1要加括号,因为<<的优先级要比+=的要高

而范围for则不一定,如果auto(或char)后不加& ,那么范围for得到的仅仅只是string的一个拷贝
用反向迭代器反向遍历
当我们想要反向遍历string的时候,我们可以使用反向迭代器来遍历。如下

rbegin()指向字符串的最后一个字符,即 /0 的前一个字符。
rend()指向字符串第一个字符的前一个位置 。
如下图
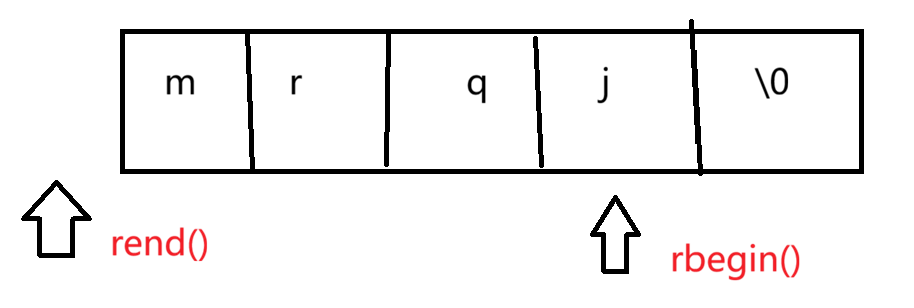
与正向遍历的begin()和end()是比较不同的,rebin()没有指向 \0 ,所以当要反向遍历的时候,尽量使用反向迭代器。
迭代器的分类
主要分为,正向,反向,const,非const 。const和非const与const指针和非const指针是很类似的,就是指向的内容是否可以修改,两者可以比较理解。
指定const迭代器:const_iterator.
如果用auto则由string的类型来决定是const还是非const
auto
一般用于替代长类型
比如在上面的迭代器遍历中,迭代器的类型时string: :iterator,我们可以直接用auto代替。

必须有初始值设定项
必须有初始值设定项,因为auto其实是靠初始值来得知该变量是什么类型,该开多大空间的。
缺陷
牺牲了可读性,有时较难得知变量的类型。
注意:auto不能做定义数组,不能做参数 。
但是可以做返回值,但建议谨慎使用,最好不用。因为无法直接得知返回值的类型,在函数多层嵌套时,就难以得出返回值的具体类型,非常恶心
可用typeid来得知具体类型
用法如下

注意typeid会丢失const&,如下图示例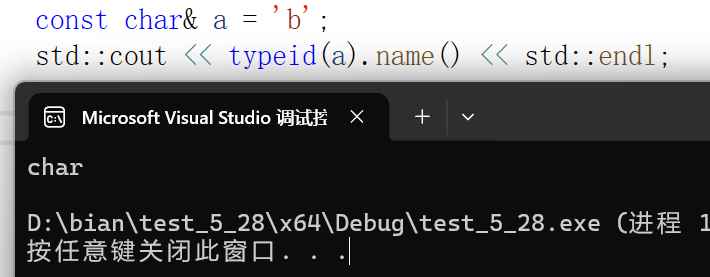
加 * 或 &
auto后面可以加 * ,加&,变成auto* ,auto& 表示后面只能是地址,是引用。
capacity(string的空间类接口)
size()和length()
两者都是获取字符串的长度,本质上并没有区别 。那为什么会有两个作用相同的接口呢?这其实是历史遗留的问题,string的诞生早于STL,在string刚出来的时候用的是length(),后面STL出来了,为了与STL保持一致 就又推出了size()

扩容的逻辑
在不同的平台上 ,扩容的逻辑有所不同,C++标准库并没有明确规定。在VS上,当小于16字节时,数据会存在一个叫 buf 的数组上,当大于16字节时才会开辟空间。
capacity()
capacity的大小比实际的空间大小 小 一字节,原因是为了去掉 \0。

reserve()
中文意思为预定保留(与翻转reverse)区分开来。主要作用就是开空间给capacity,可以一定程度上避免连续扩容。
关于reserve()文档里是这样描述的,看不懂也没关系,下面我会逐步讲解

当 reserve(n)里的n大于capacity的时候,会扩容到n或者更大。
当 n 小于capacity的时候,是否会缩容看编译器,c++并没有明确规定。但是C++有这样一个说法:这个函数不能改变字符串,也就是说缩容是有限度的,最小不能小于size。
clear()
字面意思,就是把内容清空,也就是把size置为0.
shrink_to_fit()
缩容到size.
operator
大家应该也能猜到他的作用了,这就是运算符重载,获取第i个数据的值,可读可写。
Modifiers:
push_back,append和(真神)operator+=
push_back() 尾插应该字符
append() 尾插字符串。但其实这两个并不常用,因为+=完全可以替代他们。
+=尾插字符或者字符串都可以。
insert()
即插入,有多个重载,具体作用是向指定位置之前插入数据。
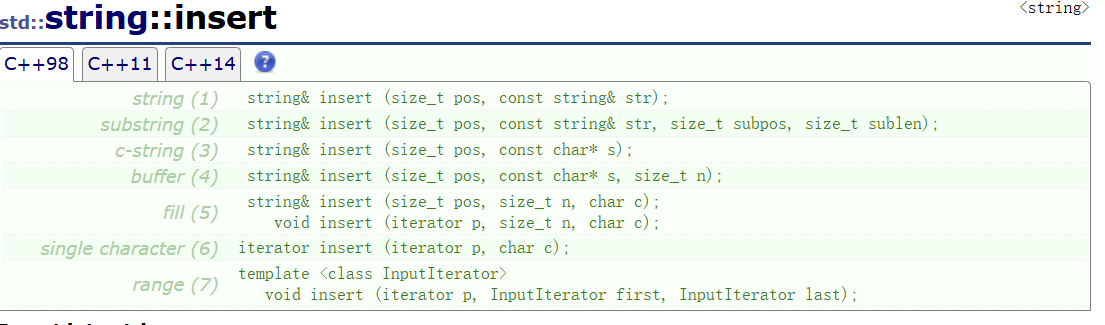
由前面的知识,我们知道数组的插入删除往往要挪动数据,消耗很大,所以插入尽量少用。
erase
即删除数据。有三个版本,如下

最常用的是第一个版本,即从pos位置开始,删除len个数据。其中npos表示整形的最大值。也就是说,当我们不传参数时会删除到末尾。
replace()
即中文替换的意思,在文档里的描述比较复杂。这里我简化一下他的大概逻辑,replace()会把从pos位置开始的len个字符替换为你所提供的字符。
如果你提供的字符的个数要小于len ,那么在len后面的数据就要往前 挪动到合适的位置。
如果你提供的字符的个数大于len ,那么len后面的数据会往后 挪动到合适的位置。

一道经典题目
用"%%"来替换字符串中的空格" ",如"hello world mr",需要被替换成"hello%%world%%mr"。
**解法一:**找到空格后直接用replace()替换。

思路还是很简单的,但是用replace替换的时候难免会涉及到数据的挪动,消耗较大,所以有没有消耗小一点的方法。当然有的,如下
**解法二:**以空间换时间,额外开辟一个数组来操作。

启示:当在原有空间上操作困难,效率低下的时候,额外开辟一个空间往往能使问题迎刃而解。
pop_back()
尾删,用的不多,因为用erase可以将其代替。
String operations:
c_str()
把string转换为C语言风格的字符串

使用场景
如下

find()
顾名思义,就是用来查找字符或者字符串的,有如下版本。

其实归纳起来就一句话:找什么,从哪个位置开始找,没找到就返回npos。
rfind()
即倒着找
substr()
获取子字符串。如下图的描述,从pos位置开始,获取len个字符

文档里的使用示例:

使用场景:找文件名后缀
用find()从前往后找

用rfind()从后往前找

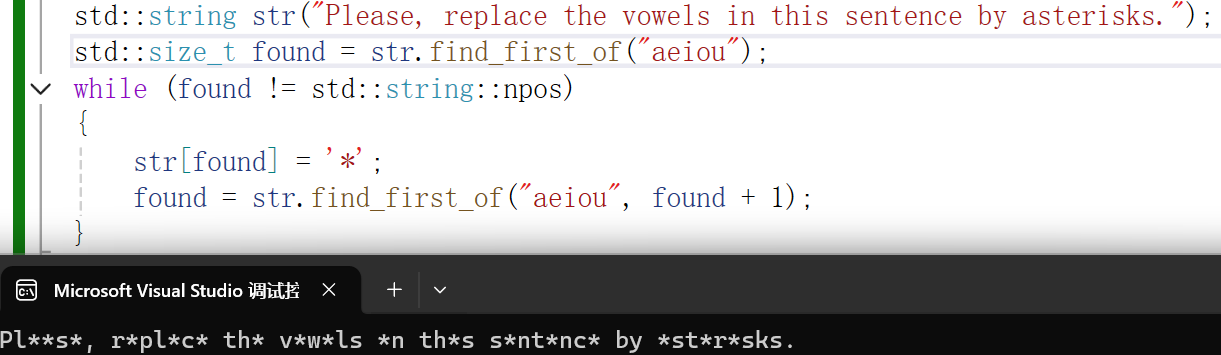
find_first_of()
和find的功能基本差不多,就是从找一个字符,变成了找多个字符。

如下图,只要找到" o r"中的任何一个都会立即停下来

文档里的示例:把字符串里的aeiou替换成 *
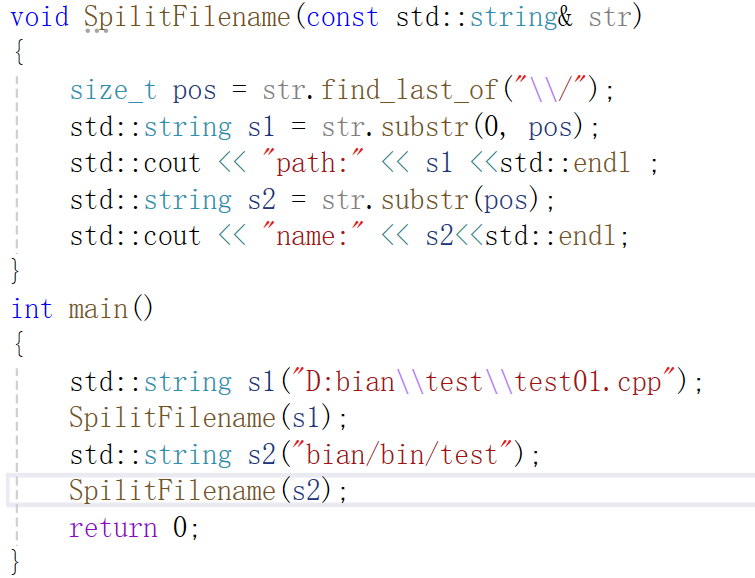
find_last_of()
与find_first_of是对偶的关系,就是倒着来找,
使用示例:区分路径与文件名
如下,找"\" 或"/",也就分别是windows 和linux系统下文件路径。需要注意的是,windows系统下路径用\区分,但是\又有转义字符的意思(如\0,\n),所以就需要把转义字符给转义一下,就是在 \ 前面再加 \。
非成员函数
主要有<<,>>和+,这个就没什么好讲的了。为什么+要重载为非成员函数?为了支持字符串+string,重载成成员函数的话,由于this指针的存在会使string称为左操作数。
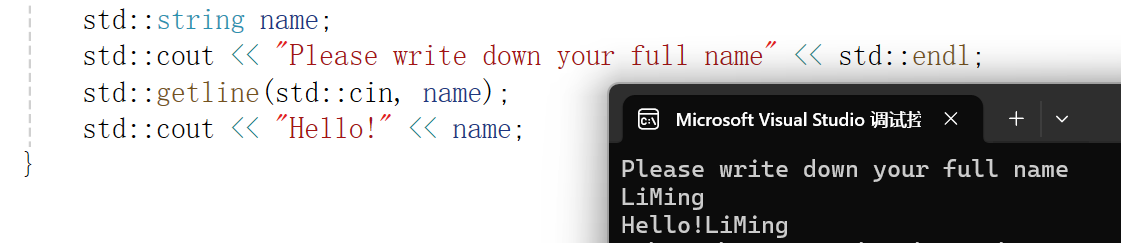
getline()
作用与cin是类似的,只不过cin是读到空格就结束,而getline()是读到换行符才结束,当然也可以自己指定读取的结束字符,但默认是换行符。

使用示例: