HAO PHUNG , 康奈尔大学, 美国
HADAR AVERBUCH-ELOR, 康奈尔大学, 美国
摘要
https://arxiv.org/pdf/2602.09016
我们的方法将栅格化的户型图图像转换为矢量化格式,同时重建其结构和语义。我们在保留的 CubiCasa5K 测试样本(左)上展示了结果。颜色表示独特的语义类别(例如,室外、卧室、浴室和入口)。此外,我们突出了我们的模型在来自 WAFFLE 的复杂真实世界户型图图像(右)上的泛化能力。3D 可视化是通过将 2D 边界垂直延伸构建的。
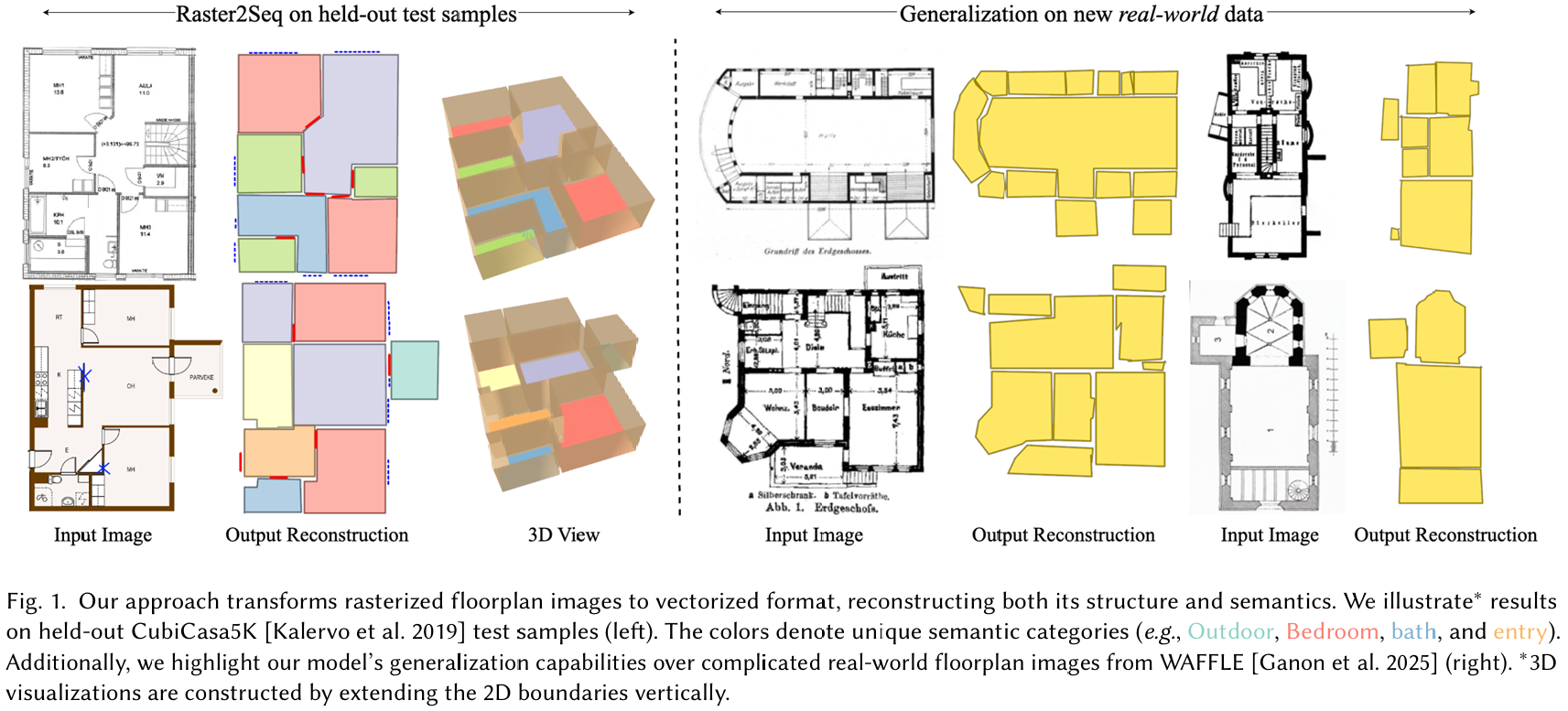
从栅格化户型图图像重建结构化的矢量图形表示,通常是涉及户型图的计算任务(如自动化理解或 CAD 工作流)的重要先决条件。然而,现有技术在忠实地生成描绘具有许多房间和可变数量多边形角点的大型室内空间的复杂户型图所传达的结构和语义时面临困难。
为此,我们提出了 Raster2Seq,将户型图重建构建为一个序列到序列(sequence-to-sequence)的任务,其中户型图元素(如房间、窗户和门)被表示为联合编码几何和语义的标记多边形序列。我们的方法引入了一个自回归解码器,该解码器在学习图像特征和先前生成的角点的条件下,在可学习锚点(learnable anchors)的引导下预测下一个角点。这些锚点表示图像空间中的空间坐标,从而允许有效地引导注意力机制聚焦于信息丰富的图像区域。通过采用自回归机制,我们的方法在输出格式上提供了灵活性,能够高效地处理具有众多房间和多样多边形结构的复杂户型图。我们的方法在 Structure3D、CubiCasa5K 和 Raster2Graph 等标准基准测试中达到了最先进的(state-of-the-art)性能,同时也展示了对包含多样房间结构和复杂几何变化的更具挑战性的数据集(如 WAFFLE)的强大泛化能力。
1. 引言 (Introduction)
户型图是建筑设计的基本元素,定义了室内空间的结构和语义,从曼哈顿的小工作室公寓到柏林的历史悠久的 Café Helms(如图 1 右上角所示)。虽然户型图通常使用专用软件(如 AutoCAD)以矢量图形表示绘制,但它们通常以栅格化图像格式分发。这种栅格化过程剥离了结构化的几何和语义信息,严重限制了它们在计算任务中的实用性,如自动化编辑、户型图理解和生成,或 3D 重建。
为了释放对栅格化户型图的计算能力, several works 探索了栅格到矢量的转换任务,旨在将输入的户型图图像转换回矢量化格式。然而,尽管基于 Transformer 的架构带来了显著的进步,现有方法在捕捉复杂真实世界户型图所传达的结构和语义方面仍面临挑战,通常依赖于预训练的检测器,并构建次优的多阶段流程来执行转换。
在这项工作中,我们提出了 Raster2Seq,一种使用标记多边形序列表示将栅格化户型图图像转换为矢量化格式的方法。与先前同时预测所有结构户型图元素(因此受限于固定的查询预算约束)的工作不同,我们的框架自回归地输出多边形序列,直接对空间结构和语义属性进行建模。我们框架设计的关键观察是:户型图元素可以被有效地建模为一个序列,利用掩码注意力模型的从左到右的生成偏差。这使我们能够将户型图重建分解为可解释的、顺序的预测,以反映自然的 CAD 设计工作流。我们将每个多边形表示为标记角点的序列,即用语义信息标记的空间坐标,并使用从左到右的顺序对户型图的多边形进行排序。具体而言,我们考虑房间、窗户和门,但这种表示可以很容易地容纳其他标记实体。
在我们的框架核心,我们引入了一个基于锚点的自回归解码器,该解码器有效地融合了来自图像特征和先前生成的角点的信息,以预测下一个标记角点。特别是,我们的自回归模块由可学习的锚点引导,这些锚点引导注意力机制聚焦于信息丰富的区域,从而能够高效地处理复杂的户型图图像。我们在不牺牲语义保真度的情况下实现了这一点,方法是额外引入了一个 token 级别的语义分类损失,该损失对单个角点嵌入上的语义信息进行监督。
我们在多个基准测试上展示了我们框架的有效性,在不同的户型图重建设置下进行了实验,这些设置考虑了栅格化 RGB 图像和 2D 密度图作为输入。我们的方法在广泛的几何和语义指标上始终优于现有方法。值得注意的是,我们的结果表明,更复杂的户型图(包含更多数量的角点和房间)会产生更大的性能差距。我们还展示了对具有挑战性的真实世界互联网数据集的强大泛化能力。
2. 相关工作 (Related Work)
2.1 户型图重建 (Floorplan Reconstruction)
栅格到矢量的户型图转换旨在从栅格化户型图图像中重建矢量化表示。在深度学习之前,多步系统依赖于手工特征来检测户型图组件(如墙壁)。Liu 等人首次集成了神经网络来解决此任务,预测角点表示,然后使用整数规划来恢复几何图元。随后的工作利用像素级分割和图神经网络对户型图元素之间的层次关系进行建模。Raster2Graph 采用带有图像空间增强的 Transformer 来突出可见角点以进行顺序角点预测。相比之下,我们的方法将户型图转换构建为序列到序列任务,自回归地生成多边形坐标。这自然地处理了可变长度的多边形和密集的布局,而无需图像增强或角点采样策略。
语义集成:与大多数仅关注结构预测的先前工作不同,我们的方法还集成了语义信息。RoomFormer 和 Raster2Graph 也集成了语义。然而,RoomFormer 通过在统一长度的房间序列内平均角点嵌入(不可避免地包括填充角点)然后再进行分类,从而丢失了细粒度的语义信息。Raster2Graph 通过预测每个角点的四个相邻房间类别引入了不必要的复杂性,可能导致误差传播和额外的计算开销。相比之下,我们提出了一种标记多边形序列,采用细粒度的 token 级别监督,其中每个角点接收直接的梯度更新,而不会被填充稀释。由于房间本质上是可变长度的多边形,我们的 token 级别损失自然地与这种表示对齐。
2.2 视觉任务的序列到序列建模 (Sequence-to-Sequence Modeling for Visual Tasks)
序列到序列(seq2seq)建模最初是为机器翻译提出的,目的是学习从源序列到目标序列的映射。该框架后来通过提供图像特征作为解码器(通常是 RNN 或 Transformer)的输入来生成目标序列,从而适应了大量的计算机视觉任务。值得注意的是,Liu 等人采用了 seq2seq 范式来表示对象分割为多边形序列。虽然我们的方法在概念上相似,但我们的框架在执行户型图重建时引入了几种表示和架构上的差异。例如,除了预测空间坐标外,我们还在表示中引入了语义标签,并结合了新颖的语义训练目标以实现语义感知的户型图识别。
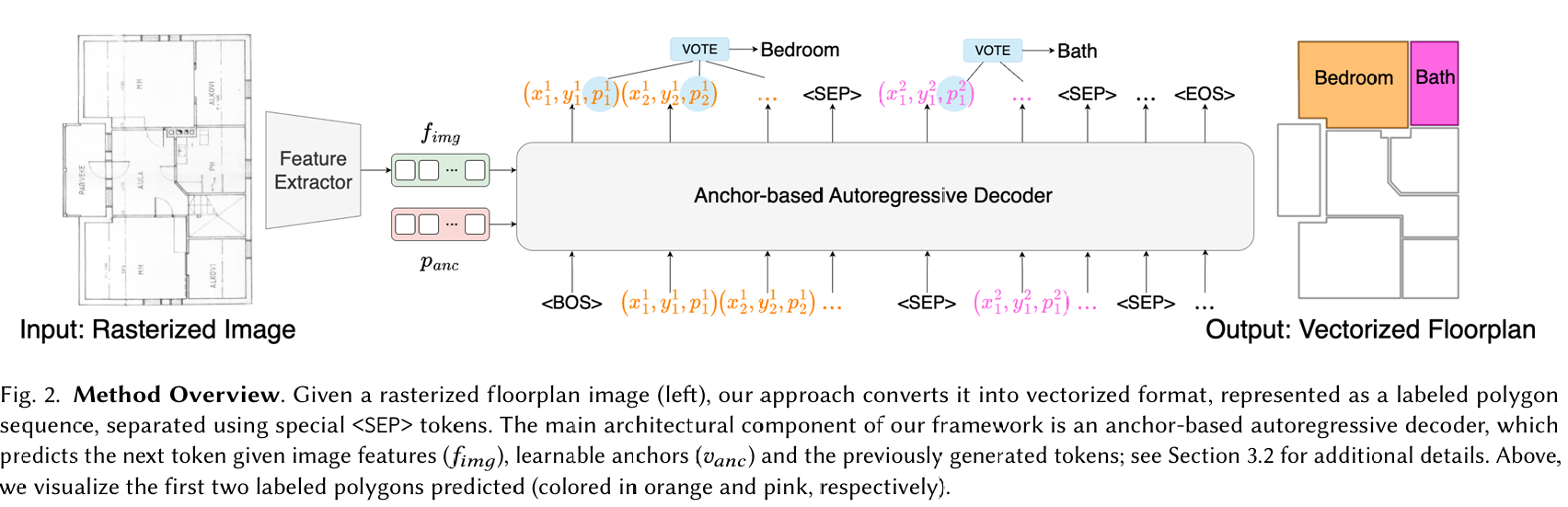
3. 方法 (Method)
我们提出的方法的概述如图 2 所示。我们的目标是将栅格化户型图图像转换为矢量化格式,重建其结构和语义。具体而言,我们假设我们被提供了一个栅格化户型图的 RGB 图像 I∈RH×W×3I \in \mathbb{R}^{H \times W \times 3}I∈RH×W×3,其中 HHH 和 WWW 表示图像的高度和宽度。输入图像 III 通过特征提取器(Feature Extractor)模块进行编码,以产生特征向量 fimg∈RLI×Df_{img} \in \mathbb{R}^{L_I \times D}fimg∈RLI×D,其中 LIL_ILI 是图像特征的长度,DDD 是通道数。
与通过中间几何元素(如边、角点或房间分割)提取矢量化户型图的现有户型图重建技术不同,我们提出直接使用标记多边形序列来表示矢量化户型图。
3.1 标记多边形序列户型图表示 (Labeled Polygon Sequence Floorplan Representation)
我们提出使用标记多边形序列来表示矢量化户型图。所谓"标记",我们指的是多边形的语义。例如,房间可以被标记为厨房、卧室等。我们将多边形参数化为标记角点 token ccc 的序列,其中 ci=(xi,yi,pi)c_i = (x_i, y_i, p_i)ci=(xi,yi,pi) 表示多边形中的第 iii 个角点,vi=(xi,yi)v_i = (x_i, y_i)vi=(xi,yi) 表示其空间位置,pi∈0,1Cp_i \in 0, 1^Cpi∈0,1C 表示其语义概率向量(假设有 CCC 个独特的语义类别)。正如我们在第 3.3 节中详细阐述的那样,房间级别的语义预测是通过在 token 级别聚合语义信息获得的。
除了房间,我们还考虑窗户和门。这些简单地被表示为额外的两个语义类别(在房间类型之上)。
为了表示包含多个房间(或户型图实体,如窗户)的户型图------每个实体如上所述表示为标记多边形------我们使用分隔符 <SEP> token 将它们的序列连接起来。我们还使用 <BOS> 和 <EOS> token 来指示序列的开始和结束。综上所述,标记多边形序列的结构如下:
<BOS>,c11,c12,⋯ ,<SEP>,cn1,cn2,⋯ ,<EOS><BOS>, c_1^1, c_1^2, \cdots, <SEP>, c_n^1, c_n^2, \cdots, <EOS><BOS>,c11,c12,⋯,<SEP>,cn1,cn2,⋯,<EOS>
由于 Raster2Seq 被训练为回归连续值而不依赖于离散分词器,每个 token 都增广了一个 token 类型概率向量 q∈0,13q \in 0, 1^3q∈0,13,其中三个 token 类型类别是 <CORNER>、<SEP> 或 <EOS>。在训练期间,<CORNER> 类型被用作每个角点 token cic_ici 的监督标签,但不显式包含在序列中。<BOS> 被省略在 token 类型建模之外。训练目标是预测序列中的下一个角点 token。
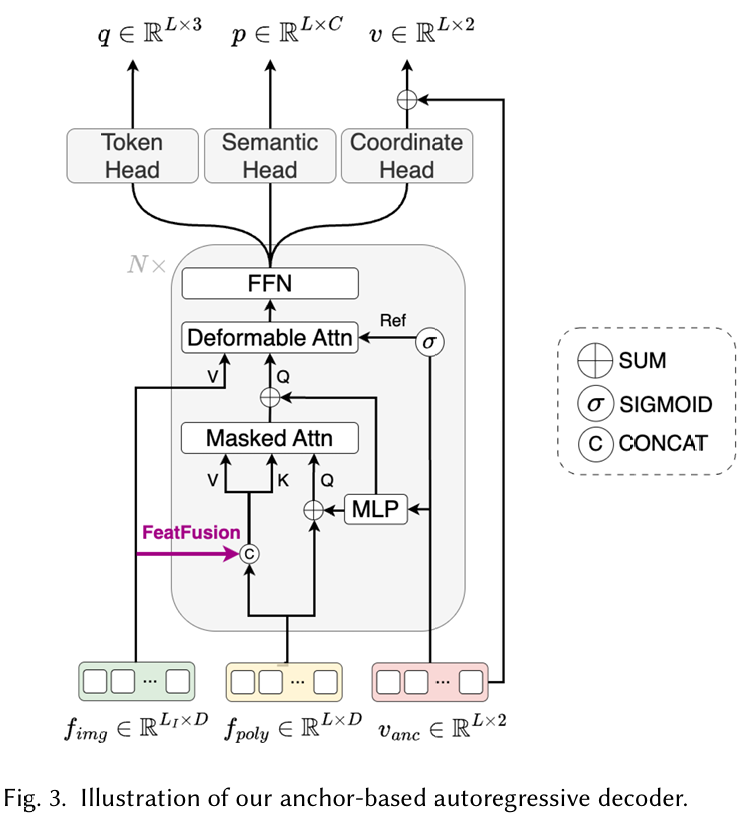
3.2 基于锚点的自回归解码器 (Anchor-based Autoregressive Decoder)
接下来,我们介绍预测标记多边形序列的基于锚点的自回归解码器模块。我们提出的模块提供了三种不同的输入:(i) 特征提取器模块提取的图像特征,(ii) 坐标 token 序列,以及 (iii) 可学习的锚点。
坐标 token 序列是在使用可学习码本 C∈RHb×Wb×D\mathcal{C} \in \mathbb{R}^{H_b \times W_b \times D}C∈RHb×Wb×D 将连续 2D 坐标量化为离散 1D 嵌入空间后提供的,其中 Hb×WbH_b \times W_bHb×Wb 是量化桶(bins)的数量,DDD 是嵌入维度。具体而言,解码器被提供 LLL 个坐标 token,表示为 fpoly∈RL×Df_{poly} \in \mathbb{R}^{L \times D}fpoly∈RL×D。引入了可学习锚点,表示为 vanc∈RL×2v_{anc} \in \mathbb{R}^{L \times 2}vanc∈RL×2,以避免直接回归连续坐标值。相反,模型学习相对于这些锚点的残差。采用锚点的概念借鉴了目标检测方法,这些方法利用分配的锚点来产生可靠的预测。
解码器架构 :解码器包含一个自回归块,该块包含三个不同的层:掩码注意力(masked attention)、可变形注意力(deformable attention)和前馈网络层。在掩码注意力层中,应用因果掩码(causal mask)以确保每个 token 只能关注其前面的 token,从而强化从左到右的生成偏差。查询(Q)、键(K)和值(V)向量三元组源自坐标 token 序列。查询向量包含来自引入的锚点的附加位置嵌入,而键和值向量源自形状为 LI+L,DL_I + L, DLI+L,D 的融合特征向量。该融合向量通过张量拼接(称为 FeatFusion)将来自编码器的图像特征与坐标 token 嵌入结合起来。
随后,前一个掩码注意力层的输出向量在可变形注意力模块中作为查询。在我们的自回归解码器中,该机制允许关注图像特征图 fimgf_{img}fimg 中稀疏的一组相关空间位置。具体而言,输入锚点首先使用 sigmoid 函数归一化到 0,10, 10,1。然后,可变形注意力层接收查询向量,并使用线性层预测相对于这些归一化锚点的偏移量。这些偏移量被加到锚点上以产生采样点,允许注意力机制聚焦于图像特征的信息丰富区域。
最后,解码器模块在最后一个自回归块之上包含三个轻量级头:用于预测 token 类型的 token 头、用于预测语义标签的语义头,以及用于预测 2D 角点坐标的坐标头。坐标头本质上产生残差输出,这些输出与可学习锚点结合以产生连续坐标值。
3.3 训练与推理细节 (Training and Inference Details)
我们的方法使用三种不同的损失函数进行监督:坐标回归损失、token 类型分类损失和语义分类损失。
坐标损失 (Coordinate loss) :对于坐标损失,我们使用 L1 损失来测量预测坐标 v^\hat{v}v^ 和真实空间坐标 vvv 之间的差异,跨越序列中的所有 LLL 个 token(即角点):
Lcoord=1L∑l=1Lml∥v^l−vl∥L_{coord} = \frac{1}{L} \sum_{l=1}^L m_l \| \hat{v}_l - v_l \|Lcoord=L1l=1∑Lml∥v^l−vl∥
此损失仅针对非填充 token 计算,使用额外的掩码 mmm 来排除不相关的位置。
Token 类型损失 (Token-type loss) :如第 3.1 节所定义,我们考虑三个 token 类别:<CORNER>、<SEP> 和 <EOS>。模型被训练使用标准交叉熵损失将单个 token 分类为这些类别之一:
Ltoken=1L∑l=1LmlCE(q^l,ql)L_{token} = \frac{1}{L} \sum_{l=1}^L m_l \text{CE}(\hat{q}_l, q_l)Ltoken=L1l=1∑LmlCE(q^l,ql)
其中 q^l\hat{q}_lq^l 是预测的三个 token 类型的概率分布,qlq_lql 是第 lll 个 token 的真实 one-hot 向量。
语义损失 (Semantic loss) :我们使用为每个 token 定义的交叉熵损失来监督语义标签的预测:
Lsem=1L∑l=1LmlCE(p^l,pl)L_{sem} = \frac{1}{L} \sum_{l=1}^L m_l \text{CE}(\hat{p}_l, p_l)Lsem=L1l=1∑LmlCE(p^l,pl)
其中 p^l\hat{p}_lp^l 是预测的 CCC 个预定义房间类别的概率分布,plp_lpl 是表示序列中第 lll 个 token 的真实房间类别的 one-hot 向量。
总训练损失为:
L=λcoord∗Lcoord+λtoken∗Ltoken+λsem∗LsemL = \lambda_{coord} * L_{coord} + \lambda_{token} * L_{token} + \lambda_{sem} * L_{sem}L=λcoord∗Lcoord+λtoken∗Ltoken+λsem∗Lsem
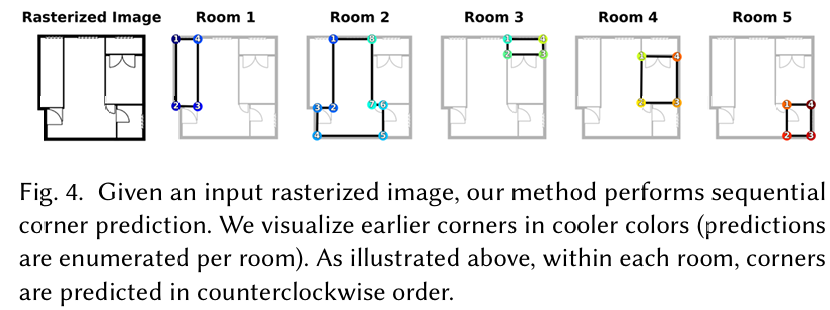
其中 λcoord\lambda_{coord}λcoord、λtoken\lambda_{token}λtoken 和 λsem\lambda_{sem}λsem 是加权系数。为了引入强大的几何归纳偏置,我们在训练期间对多边形序列执行从左到右的排序,其中房间按左上角坐标使用从上到下、从左到右的扫描优先级进行排序。
在推理时,Raster2Seq 顺序预测 token,直到获得 <EOS> token。为了预测语义房间标签,我们使用多数投票策略聚合 token 级别的预测。具体而言,每个多边形序列的房间标签首先通过选择每个 token 处具有最高概率的类别来确定,然后取整个序列中最频繁预测的类别。
4. 实验 (Experiments)
4.1 实验设置 (Experimental Setup)
数据集:我们在四个数据集上进行实验:Structured3D、CubiCasa5K、Raster2Graph 和 WAFFLE。Structured3D 是一个 3D 点云数据集。CubiCasa5K 是一个基于栅格的户型图数据集。Raster2Graph 包含训练/验证/测试样本。WAFFLE 包含 20K 从互联网上抓取的真实世界户型图图像。由于该数据集仅包含约 100 个带注释的样本,我们仅在此数据上评估零样本(zero-shot)泛化能力。
指标:我们遵循先前工作使用的评估协议,重点关注通过将模型预测与真实注释匹配获得的几何和语义指标。三个评估标准是 Room(房间)、Corner(角点)和 Angle(角度),每个标准都使用 Precision(精确率)、Recall(召回率)和 F1 分数进行评估。
基线 :我们主要利用 HEAT、RoomFormer、FRI-Net(最初为点云密度图设计)进行定量评估,并将这些模型微调以从栅格化户型图输入执行户型图重建。我们还与 Raster2Graph 进行了比较。
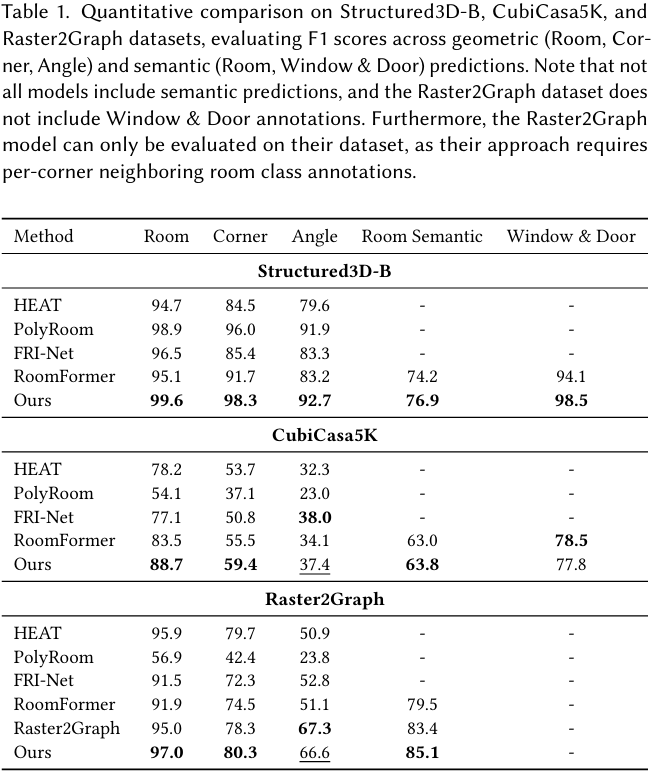
4.2 定量评估 (Quantitative Evaluation)
我们在三个数据集上比较了栅格到矢量转换任务的性能(见表 1)。总体而言,我们的方法在结构指标(Room 和 Corner)和语义指标(Room Semantic 和 Window & Door)上均达到了最先进的性能。我们注意到,与直接优化 token 级别语义预测的我们的方法不同,RoomFormer 通过在统一长度序列内平均不相关的角点来稀释语义信息,导致在几乎所有语义指标上的语义预测较差。
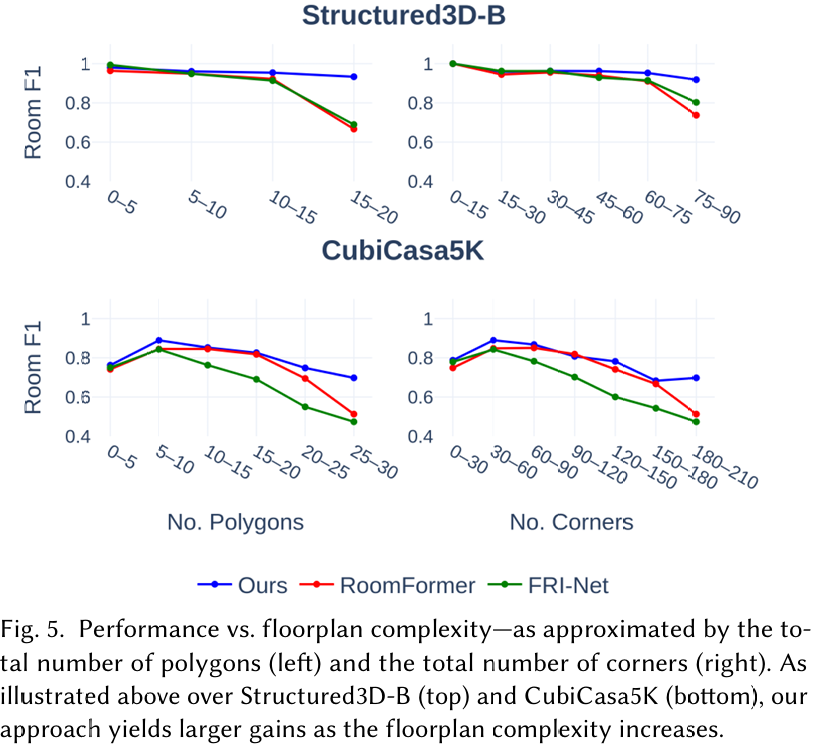
模型对户型图复杂性的鲁棒性 :图 5 显示了 RoomFormer、FRI-Net 和我们的模型在 Structured3D-B 和 CubiCasa5K 数据集上跨不同多边形和角点数量的 Room F1 性能。随着户型图复杂性的增加,我们的方法始终表现出更强的鲁棒性。
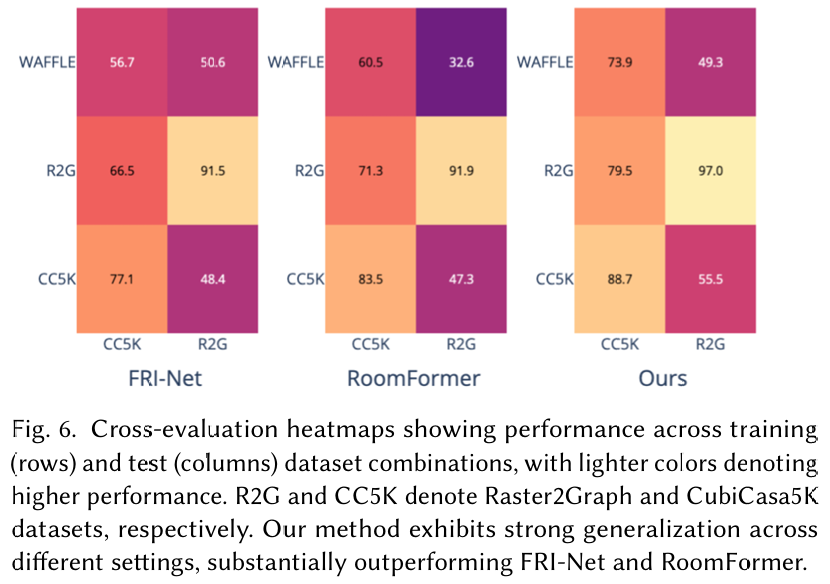
模型泛化能力 :我们跨不同的训练-测试数据集配置执行了交叉评估实验。结果如图 6 所示。我们的方法在各种设置(包括同数据集和跨数据集评估)中表现出最强的泛化性能,大幅优于其他基线。
4.3 定性结果 (Qualitative Results)
我们在 Structured3D-B 数据集(图 9)、CubiCasa5K 和未见过的 WAFFLE 样本(图 1)上提供了我们方法的定性示例。同时,我们在 CubiCasa5K 测试样本(图 10)和 WAFFLE 图像(图 12)上提供了与 RoomFormer 模型的视觉比较。这些图说明了与 RoomFormer 基线相比更优越的视觉质量。特别是,我们观察到 RoomFormer 模型经常产生"捷径"三角形多边形,而我们的模型允许更准确地重建户型图的结构。
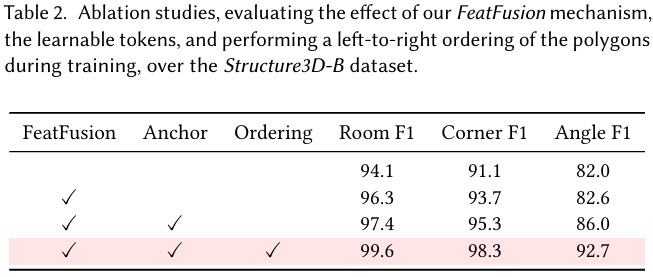
4.4 消融实验 (Ablations)
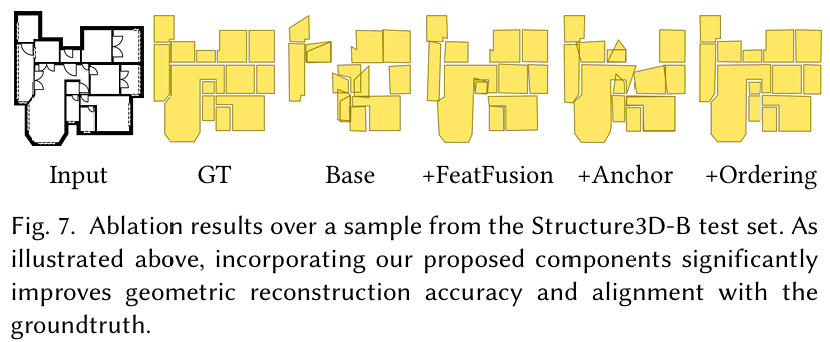
我们在 Structure3D-B 数据集上进行了广泛的消融实验,评估了我们框架中各个组件的效果。表 2 突出了三个关键组件的影响:FeatFusion(融合多边形和图像特征)、可学习锚点,以及在训练期间对序列中的多边形执行从左到右的排序。总体而言,每个提出的组件都对模型性能做出了有意义的贡献。特别是,可学习锚点提供了显著的模型性能提升,而集成多边形生成排序则产生了最佳性能。
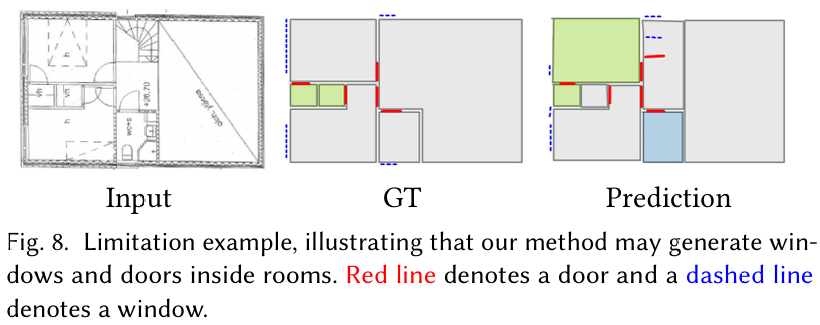
4.5 局限性 (Limitations)
虽然我们的方法在几何重建和泛化方面都取得了强劲的性能,但我们发现,对于不太常见的语义结构(如门和窗户),性能可以进一步完善。如图 8 所示,模型偶尔无法准确定位窗户和门,导致诸如交叉窗户等伪影。未来的工作可以调查定制的架构更改,以更好地适应其他元素类型,可能将这些元素与房间实体分开建模。
5. 结论 (Conclusion)
在这项工作中,我们提出将栅格到矢量的户型图转换构建为一个序列到序列的任务。我们引入了一个框架,该框架将矢量化表示预测为标记多边形序列。我们框架的驱动机制是一个基于锚点的自回归解码器,它学习在先前生成的角点的条件下预测下一个角点 token。在技术上,我们的解码器引入了几个架构组件,例如可学习锚点的集成和 FeatFusion 拼接操作,从而能够有效地学习复杂多边形序列的生成。我们的实验表明,我们的方法在针对类似任务的各种几何和语义指标上均优于先前的工作。
Raster2Seq 展示了对野外互联网数据的有希望的泛化性能,代表了向对由手绘户型图定义的历史建筑进行建模的目标迈出的一步。未来的工作可以结合进一步提高分布外(out-of-distribution)数据结果的机制。更广泛地说,恢复准确的矢量化户型图表示的能力将变得越来越重要,因为生成模型变得越来越强大,从而实现可控的下游应用,例如超越传统分析和编辑设置的大规模建筑场景的户型图引导 3D 生成。
附录关键部分翻译 (Appendix Highlights)
A. 数据准备 (Data preparation)
A.1 Structured3D:由于 Structured3D 作为从 3D 点云投影的密度图提供,我们使用伴随的数据注释将这些图转换为 RGB 格式的户型图图像,以更好地模仿标准 RGB 户型图的外观。
A.2 CubiCasa5K:CubiCasa5K 最初是为分割任务提出的,其中给定的注释是像素级分割图。我们首先选择 10 个语义房间类别,以及两个附加类别(窗户和门)。我们将这些相应类别的分割图转换为多边形,这些多边形用作每个房间的真实值角点。
B. 额外实现细节 (Additional Implementation Details)
双线性量化器 (Bilinear Quantizer) :为了在我们提出的输入序列上训练模型,我们需要找到一种合适的方法将这些连续坐标转换为相应的离散嵌入。我们将 2D 连续坐标离散化为 1D 嵌入空间,引入了大小为 C∈RHb×Wb×D\mathcal{C} \in \mathbb{R}^{H_b \times W_b \times D}C∈RHb×Wb×D 的可学习码本。具体而言,给定一个 2D 坐标 (x,y)(x, y)(x,y),对其应用向下取整(⌊⋅⌋\lfloor \cdot \rfloor⌊⋅⌋)和向上取整(⌈⋅⌉\lceil \cdot \rceil⌈⋅⌉)操作,以在 2D 网格中为其 4 个相邻点生成精确的嵌入。形式上,最终的嵌入 ex,ye_{x,y}ex,y 通过双线性插值获得以获取输入坐标的精确值:
ex,y=(⌈x⌉−x)(⌈y⌉−y)⋅e⌊x⌋,⌊y⌋+(x−⌊x⌋)(⌈y⌉−y)⋅e⌈x⌉,⌊y⌋+(⌈x⌉−x)(y−⌊y⌋)⋅e⌊x⌋,⌈y⌉+(x−⌊x⌋)(y−⌊y⌋)⋅e⌈x⌉,⌈y⌉e_{x,y} = (\lceil x \rceil - x)(\lceil y \rceil - y) \cdot e_{\lfloor x \rfloor, \lfloor y \rfloor} + (x - \lfloor x \rfloor)(\lceil y \rceil - y) \cdot e_{\lceil x \rceil, \lfloor y \rfloor} + (\lceil x \rceil - x)(y - \lfloor y \rfloor) \cdot e_{\lfloor x \rfloor, \lceil y \rceil} + (x - \lfloor x \rfloor)(y - \lfloor y \rfloor) \cdot e_{\lceil x \rceil, \lceil y \rceil}ex,y=(⌈x⌉−x)(⌈y⌉−y)⋅e⌊x⌋,⌊y⌋+(x−⌊x⌋)(⌈y⌉−y)⋅e⌈x⌉,⌊y⌋+(⌈x⌉−x)(y−⌊y⌋)⋅e⌊x⌋,⌈y⌉+(x−⌊x⌋)(y−⌊y⌋)⋅e⌈x⌉,⌈y⌉
这些量化值被用作解码器层的输入,与编码的图像特征一起回归连续坐标值。
E.5 基于 VLM 的细化 (VLM-based refinement)
虽然我们的方法产生了优于现有工作的合理户型图重建结果,但我们的技术并没有直接在框架内强制执行几何约束。因此,我们进行了通过基于 VLM(视觉语言模型)的矢量化细化来强制执行几何约束的实验。具体而言,我们向 VLM 提供我们标记的多边形(JSON 格式)、栅格化输入、矢量化的户型图(单独和叠加)、以及直接从我们的预测中得出的邻接图。为了指定几何约束,我们设计了一个文本提示,明确施加两个特定约束:相邻房间必须共享边缘且没有间隙或交叉,并且所有边缘必须保持正交,以便矢量精确地捕捉到墙壁。
实验表明,我们的方法实现了显著的几何改进(例如,Corner 和 Angle 分数分别从 54.0 提高到 59.0,从 33.0 提高到 45.1)。重要的是,我们的语义预测(大多数先前方法所缺乏的)作为关键的房间身份线索,使 VLM 能够区分房间实例并识别邻接关系以进行更有针对性的细化。
F. 额外消融研究 (Additional Ablation Studies)
量化分辨率 :表 3 展示了坐标量化分辨率(由离散化桶的数量表示,例如 16×1616 \times 1616×16, 32×3232 \times 3232×32)对户型图重建性能的影响。32×3232 \times 3232×32 的分辨率产生了最佳的整体性能,表明它在粒度和模型性能之间提供了最佳权衡。
序列长度:表 4 检查了输入序列长度对户型图生成性能的影响。结果清楚地表明,增加序列长度显著提高了所有指标的重建质量,从长度 256 移动时获得了 3-10 点的增益。长度 512 对应于最佳配置。
坐标损失系数:表 17 展示了坐标损失系数的消融研究。将坐标损失系数设置为 20 产生了最佳的整体性能。较低(10)和较高(40)的系数值导致所有指标的明显下降,表明适当平衡的坐标损失对于准确的几何预测至关重要。