note
- OPD 的监督更多来自 teacher 分布或 teacher feedback;RL 更多来自 reward/verifier
- OPD 解决长轨迹误差累积(exposure bias),让学生模型自己 rollout,再由教师/奖励模型/验证器对学生真实轨迹提供监督信号,最后更新学生模型。
- OPSD = OPD 的自蒸馏版本:student 自己 rollout,然后用"带 ground truth / privileged information 的自己"当 teacher,去教"不带这些信息的自己"
- OPD 是一个大范式:学生自己 rollout,再接受监督。GRPO 是一种具体 RL 更新算法:rollout 多个样本,用 group reward 算 advantage 更新 policy。
文章目录
一、研究背景
链接:https://arxiv.org/pdf/2604.00626
- 研究问题:这篇文章要解决的问题是如何在大语言模型(LLMs)中有效地进行知识蒸馏,特别是针对推理密集型任务,减少推理错误并提高模型的鲁棒性。
- 研究难点:该问题的研究难点包括:传统知识蒸馏方法在推理任务中表现不佳,尤其是在长序列推理中,误差会累积导致性能下降;现有的蒸馏方法大多采用离线模仿,即学生模型在固定的数据集上进行训练,但在推理时生成的新序列与训练数据分布不匹配,导致误差放大。
- 相关工作:该问题的研究相关工作有:经典的知识蒸馏方法(Hinton et al., 2015),其目标是让学生模型继承教师模型的软输出结构;早期的方法主要关注如何采样和选择合适的散度函数(Agarwal et al., 2024; Gu et al., 2024),后续研究揭示了目标函数的形式等价于KL约束形式的强化学习(Yang et al., 2026d)。
二、OPD
1、OPD方法
-
f-散度最小化:OPD方法将训练过程重新组织为围绕学生采样的轨迹进行优化,目标是减少复合误差,使其线性化。公式如下:
L O P D ( θ ) = E y ∼ π mix ∑ t = 1 ∣ y ∣ D f ( p T ( ⋅ ∣ x , y \< t ) , p θ ( ⋅ ∣ x , y \< t ) ) \mathcal{L}{OPD}(\theta) = E{y \sim \pi_{\text{mix}}} \left \\sum_{t=1}\^{\|y\|} \\mathcal{D}_f \\left( p_T(\\cdot \\mid x, y_{\
其中, D f \mathcal{D}f Df 表示f-散度族, π mix \pi{\text{mix}} πmix 是混合策略。
-
混合策略:混合策略 π mix \pi_{\text{mix}} πmix 通过插值或混合不同的策略来控制蒸馏过程中的探索程度。例如,GKD方法使用 π mix = λ p θ + ( 1 − λ ) p data \pi_{\text{mix}} = \lambda p_\theta + (1 - \lambda) p_{\text{data}} πmix=λpθ+(1−λ)pdata 进行插值。
2、OPD的loss
OPD 通过修改训练期望值,使其从学生模型自身的 rollout(轨迹采样)或混合策略 π mix \pi_{\text{mix}} πmix 中进行采样,从而解决了曝光偏差(exposure bias)问题。这种广义的在线策略目标函数将采样轨迹与局部匹配度量解耦:
L O P D ( θ ) = E y ∼ π mix ∑ t = 1 ∣ y ∣ D f ( p T ( ⋅ ∣ x , y \< t ) , p θ ( ⋅ ∣ x , y \< t ) ) (8) \mathcal{L}{OPD}(\theta) = \mathbb{E}{y \sim \pi_{\text{mix}}} \left \\sum_{t=1}\^{\|y\|} \\mathcal{D}_f(p_T(\\cdot\|x, y_{\
这里, D f \mathcal{D}_f Df 代表来自 f-散度族(f-divergence family, Wen et al., 2023)的一种散度。形式上,给定两个分布 P P P 和 Q Q Q,f-散度定义为:
D f ( P ∥ Q ) = E y ∼ Q f ( P ( y ) Q ( y ) ) (9) D_f(P \| Q) = \mathbb{E}_{y \sim Q} \left f\\left( \\frac{P(y)}{Q(y)} \\right) \\right \tag{9} Df(P∥Q)=Ey∼Qf(Q(y)P(y))(9)
其中 f : ( 0 , ∞ ) → R f: (0, \infty) \to \mathbb{R} f:(0,∞)→R 是一个凸生成器(convex generator),且满足 f ( 1 ) = 0 f(1) = 0 f(1)=0。 f f f 的选择决定了似然比 p T ( y ) / p θ ( y ) p_T(y)/p_\theta(y) pT(y)/pθ(y) 的隐式加权方式:
- 前向 KL(Forward KL, f ( u ) = u log u f(u) = u \log u f(u)=ulogu) :覆盖模式(Mode-covering)(零避免)。鼓励学生模型在教师模型分布的任何地方分配概率质量,通常会连接不同的教师模式,并在模式间空间产生幻觉(hallucinating)。
- 反向 KL(Reverse KL, f ( u ) = − log u f(u) = -\log u f(u)=−logu) :寻找模式(Mode-seeking)(零强制)。学生模型将其质量坍缩到教师模型的单个最高峰值上,忽略次优的可接受输出,但专注于高精度。
- JSD( Jensen-Shannon Divergence, f ( u ) = u log u − ( u + 1 ) log u + 1 2 f(u) = u \log u - (u + 1) \log \frac{u+1}{2} f(u)=ulogu−(u+1)log2u+1):对称的、有界的,并在覆盖模式和寻找模式行为之间进行平滑插值。
- α \alpha α-散度( α \alpha α-divergence) :一个参数化的族,在前向 KL( α → 1 \alpha \to 1 α→1)和反向 KL( α → 0 \alpha \to 0 α→0)之间连续插值,允许对寻找模式/覆盖模式权衡进行细粒度控制。

- 目标函数选择:目标函数的选择取决于具体任务的需求。例如,对于数学推理任务,反向KL散度(Reverse KL)有助于集中概率质量在正确答案上;而对于开放式生成任务,前向KL散度(Forward KL)则有助于保留输出多样性。
kl和反向kl散度公式只是具体表象,更本质的是opd是student先rollout出轨迹,然后teacher给出supervision。
反向kl只是opd其中一个方法
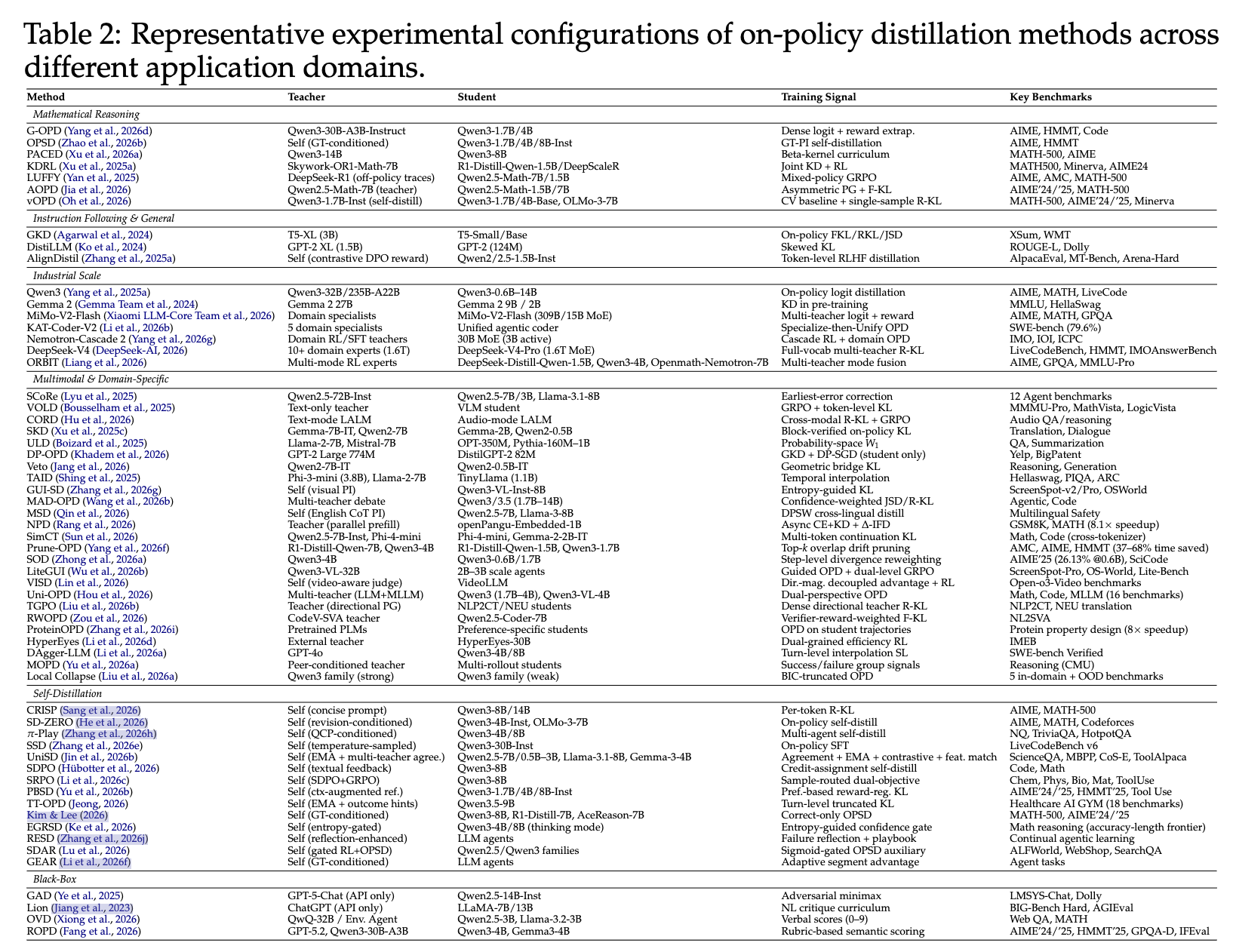
参考图中Training Signal列,R-KL=反向kl。图源自A Survey of On-Policy Distillation for Large Language Models
3、KL散度
Forward KL 会覆盖多个模式,但可能在两个模式中间"糊"出不好的答案;Reverse KL 会选择一个峰,答案更尖锐,但可能丢掉其他合理答案。
| 方法 | 特点 | 适合场景 |
|---|---|---|
| Forward KL | mode-covering,尽量覆盖 teacher 的多种可能答案 | 开放生成、翻译、摘要 |
| Reverse KL | mode-seeking,集中到 teacher 最有把握的高概率答案 | 数学、代码、推理、唯一答案任务 |
| JSD / Adaptive KL | 折中或按 token 动态切换 | 指令跟随、复杂混合任务 |
三、训练方法
1、三个维度
将OPD分为三个维度:
| 维度 | 问题 | 典型内容 |
|---|---|---|
| Objective / 优化目标 | 学 teacher 的什么? | Forward KL、Reverse KL、JSD、RL-augmented objective |
| Signal Source / 信号来源 | teacher 怎么给信号? | white-box logits、black-box API、self-distillation |
| Training Dynamics / 训练稳定性 | 怎么训稳、训快? | token weighting、curriculum、compute optimization |
2、OPD和OPSD
OPD和OPSD:
| 方法 | teacher 是谁 | 监督信号来自哪里 |
|---|---|---|
| 普通 OPD | 外部大 teacher | teacher logits / reward / critique |
| OPSD | 自己 | 自己在带答案/额外信息条件下的分布 |
一些具体的工作展示:
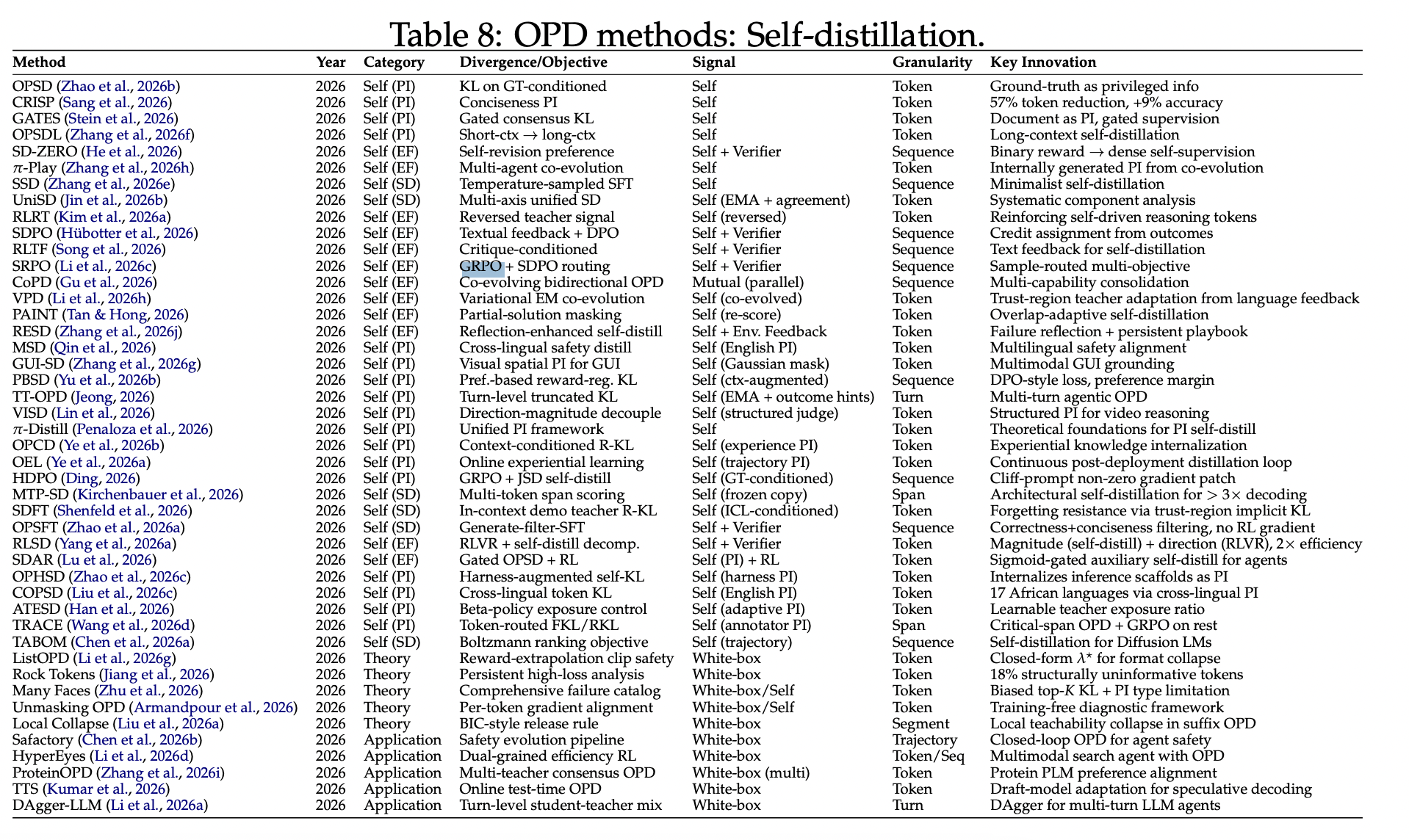
3、OPD和GRPO的区别
| 对比 | OPD | GRPO |
|---|---|---|
| 本质 | 蒸馏范式 | 强化学习算法 |
| rollout 来源 | student 当前策略 | policy 当前策略 |
| 监督信号 | teacher logits / teacher correction / reward / verifier | reward 分数 |
| 优化目标 | 让 student 接近 teacher 分布,或吸收 teacher 反馈 | 提高高 reward 轨迹概率,降低低 reward 轨迹概率 |
| 常见 loss | KL / JSD / Reverse KL / token-level distillation / sequence-level distillation | policy gradient + group advantage + clipping |
| teacher 是否必须 | 常见需要 teacher,但也有 self-distillation | 不需要 teacher,只需要 reward |
| 更像什么 | "老师批改学生真实输出" | "根据奖励强化好输出" |
四、实验效果
- 性能提升:实验结果表明,OPD方法在大多数推理任务中显著提升了学生的性能。例如,在MATH-500数据集上,OPD方法在7B模型上的准确率达到了79.3%,比离线知识蒸馏方法提高了7.9个百分点。
- 误差减少:OPD方法通过在训练过程中引入学生自己的错误状态,减少了误差累积现象。具体来说,OPD方法在推理任务中的误差率显著低于离线知识蒸馏方法。
- 计算效率:尽管OPD方法的计算开销较大,但通过前缀截断和离线预计算等技术,可以有效降低计算成本。例如,使用前缀截断技术后,OPD方法的训练时间减少了约2倍。
五、实验坑点
| 问题 | 通俗解释 |
|---|---|
| flawed prefix trap | student 生成了很烂的前缀,teacher 在这个烂上下文上给出的分布也可能不可靠 |
| diversity collapse | 模型越来越只会一种答案,熵下降、输出模板化 |
| length inflation | 输出越来越长,用长推理骗分 |
| self-play saturation | 自蒸馏到后面只能学到自己已有能力,无法突破 |
| agentic failure | 多步工具调用里,一步错会污染后续 observation 和决策 |
Reference
1 A Survey of On-Policy Distillation for Large Language Models