作者:陈廷彬(颍川)
使用云监控官方 CLI + Agent Skill,让 AI Agent 安全执行可观测运维任务。
30 秒读懂
阿里云云监控 CLI(aliyun cms2)把 CMS(Cloud Monitor Service)2.0 控制台中的接入、配置、查询、告警、事件等能力统一沉淀为命令行入口;CMS Agent Skill 则把这些命令组织成面向 AI Agent 的业务工作流。
过去,运维自动化往往从 API 开始:查文档、拼参数、写脚本、调接口;现在,通过云监控 CLI + Agent Skill,这些能力可以被组织成 AI Agent 可理解、可执行、可校验的标准化工作流。
对运维人员来说,它的价值不是"多一个工具",而是让你用自然语言描述运维目标,由 AI Agent 完成场景理解、CLI 调用、API 执行和结果校验,将重复、多步骤、易出错的可观测运维操作变成可确认、可审计、可复用的自动化流程。
为什么需要 CLI+Agent Skill
随着云上业务规模和基础设施持续增长,可观测运维贯穿了资源接入、指标/日志采集、告警治理、链路排查、根因分析和稳定性运营的全流程,运维工作量和操作复杂度随之攀升。与此同时,AI Agent 凭借强大的语言理解与任务编排能力,正在成为新的运维协作入口,越来越多团队开始尝试把重复、标准化、多步骤的任务交给 Agent 辅助执行,把复杂的问题排查交给 AI 辅助分析。
但要让 AI Agent 真正进入生产运维闭环,不能只停留在"理解问题、生成建议或脚本"的阶段,还需要一套稳定的云监控能力执行入口、标准化的领域流程、必要的人工确认和可校验的执行结果。云监控 CLI + Agent Skill 正是面向这一需求构建的能力套件。
CLI+Skill 的解决方案
阿里云云监控 CLI(aliyun cms2)提供统一、稳定、可审计的能力入口,CMS Agent Skill ** **1 则把云监控领域的业务语义和操作流程沉淀为 AI Agent 可理解、可执行的工作流。二者配合,AI Agent 可以从"帮我把这个 ACK 集群接入云监控"这样的自然语言指令出发,自动完成场景识别、参数生成、CLI 调用、API 执行和结果校验。
- 统一命令树:CLI 已覆盖 CMS 2.0 控制台中的接入中心、Prometheus 服务、应用监控、用户体验监控、告警中心、事件中心等能力。后续将继续覆盖云拨测、Grafana 大盘等能力,实现对 CMS 2.0 控制台的完整覆盖。
- AI Agent 原生适配:
- 提供规范、明确、细致的
--help信息,支持--show-schema、--show-example-body等辅助能力,帮助 AI 准确处理各类业务场景; - 默认使用 -o text 输出紧凑 CSV,显著降低 AI Token 消耗;
- 通过结构化 JSON 错误码,支持 Agent 根据错误原因自动决策和修复。
- 提供规范、明确、细致的
- Skill 驱动:配套 Skill 文档沉淀完整业务工作流,Agent 无需硬编码即可完成复杂多步操作。
CLI+Skill 工作流程
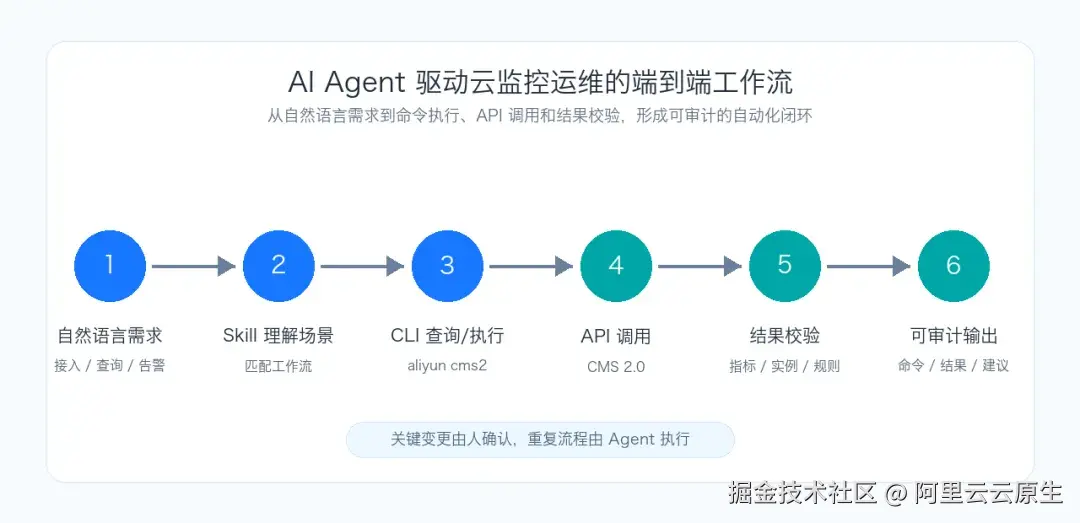
对运维人员来说,最直观的变化是:不再从控制台入口或 API 参数开始操作,而是从一个明确的运维目标开始,由 Agent 按标准流程完成后续执行与校验。这条链路的核心是"可控自动化":Agent 不会绕过运维体系,而是通过统一 CLI 入口和 Skill 中沉淀的业务规则执行操作。这样既能减少重复劳动,又能保留必要的权限、确认和审计边界。
安装与配置
安装 Skill/CLI
- 打开阿里云 Agent Skills 门户 ** **1 的 alibabacloud-cms-manage Skill,按界面引导完成 Skill 安装。
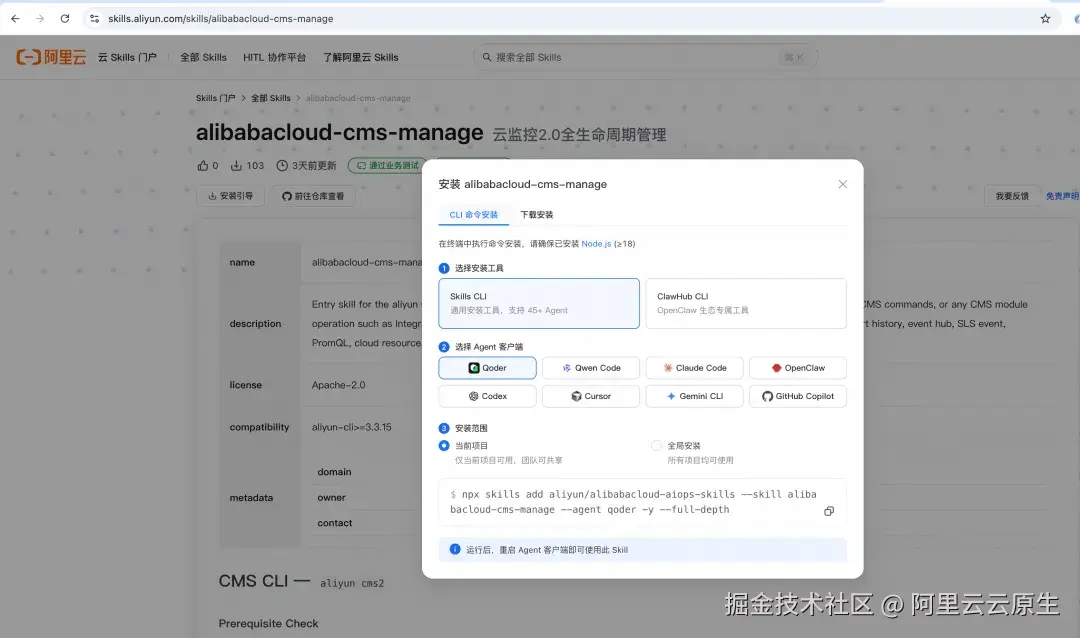
- 安装完成后,AI Agent 使用 Skill 时会自动检测并引导安装或更新阿里云 CLI 及
cms2插件到所需版本,无需手动处理环境依赖。
bash
# 验证 CLI 安装成功
aliyun version
# 验证 cms2 插件可用
aliyun cms2 --help配置凭证
支持 AccessKey、STS Token 等多种凭证类型,详见:配置阿里云 CLI 身份凭证 ** **2 。
python
# 交互式配置(推荐首次使用)
aliyun configure
# 非交互式配置
aliyun configure set \
--access-key-id YOUR_AK \
--access-key-secret YOUR_SK \
--region cn-hangzhou实战场景一(接入中心):ACK 集群接入云监控
业务场景
SRE 团队新建了一个 ACK 集群用于部署微服务,需要将集群的节点、Pod、容器等指标接入云监控。
使用方式
您只需要在 AI Agent 对话中输入:
帮我看看杭州有哪些容器集群没有可观测能力,帮我接入一下。
Agent 就会自动完成整个接入流程,用户只需在关键节点确认即可。
AI Agent 支持的核心能力
| 步骤 | Agent 自动执行的操作 |
|---|---|
| 步骤1:查询容器集群 | 通过云资源中心,查询符合条件的容器集群列表 |
| 步骤2:已接入实例判断 | 查询实体数据(EntityStore),过滤掉已接入云监控的实例 |
| 步骤3:资源验证 | 通过云资源中心查询集群 ID,确认其真实身份、所属账号等信息 |
| 步骤4:组件选择 | 从接入组件目录中匹配适合 ACK 场景的 Addon(监控组件),获取参数 schema 和工作流模板 |
| 步骤5:策略创建 | 创建集成策略(Integration Policy),关联目标 Workspace |
| 步骤6:组件部署 | 创建 Addon Release,将集群的指标采集接入到 Prometheus 实例 |
| 步骤7:结果验证 | 检查存储实例、关联大盘和采集 Job 目标,确认数据链路畅通 |
接入中心的常见场景和提示词示例
按资源组接入: 将默认资源组下,北京区域的所有 RDS 接入云监控的 {workspace} 下。
按标签接入: 将匹配标签key= {tagKey},value={tagValue}的所有 ECS 接入云监控的 {workspace}下。
跨账号接入: 将 {资源目录成员账号uid} 的上海区域下,所有 AI 网关接入云监控下。
监控组件部署: 在接入策略 {策略id/名称} 下增加 ACK 成本洞察组件接入。
指标采集 target 检查: 检查 ACK 集群 {集群Id/名称} 的 apiserver 相关 scrape target 是否正常。
自定义采集规则查询: 查询接入策略 {策略id/名称} 的 serviceMonitor/podMonitor/customJob 列表。
实战场景二(告警中心):智能告警规则管理
业务场景
SRE 需要为生产环境建立完善的告警体系,以容器服务集群节点为例,配置专业的节点告警规则。
使用方式
以下是典型的对话示例:
针对容器的告警有什么建议,然后帮我 apply。
AI Agent 支持的核心能力
| 步骤 | Agent 自动执行的操作 |
|---|---|
| 步骤1:查询现有告警规则 | 查询容器实例对应的现有告警规则列表 |
| 步骤2:查询指标信息 | 查询容器实例现有的指标列表和labels |
| 步骤3:生成告警规则配置 | 结合现有告警规则,生成各主要组件的告警规则配置 |
| 步骤4:Dry Run 告警规则 | Dry Run 生成的告警规则,确认其有效性 |
| 步骤5:创建告警规则 | 创建现有未覆盖的告警规则 |
| 步骤6:修改现有告警规则 | 对现有不合理的告警规则进行修改 |
告警中心的常见场景和提示词示例
智能分析告警规则: 分析现有告警是否配置合理,是否存在告警噪声,不合理就一键修改。
查询告警规则: 查询工作空间 {workspace} 下,云产品监控的所有运行中的告警规则。
修改告警规则联系人: 将告警规则 {规则id/名称} 的通知对象改为 {联系人}。
删除告警规则: 删除 Prometheus 实例 {实例id/名称} 的 {规则名称} 告警规则。
查询告警历史: 查询告警规则 {规则id/名称} 的1 周内的告警历史。
实战场景三(Prometheus 服务):Prometheus 实例管理与数据查询
业务场景
运维团队需要管理多个 Prometheus 实例,分析监控指标和业务健康状况,并配置 Recording Rule 预聚合高频指标。
使用方式
以下是典型的对话示例:
帮我看看杭州有哪些 Prometheus 实例,按工作空间分组展示。
以下为 Agent 支持的核心能力概览
| 能力 | Agent 自动执行的操作 |
|---|---|
| Prometheus 实例管理 | 创建、查询、更新、删除 Prometheus 实例,支持按标签、地域过滤 |
| Prometheus 聚合视图管理 | 创建、查询、更新、删除 Prometheus 聚合视图 |
| Recording Rule 管理 | 创建/删除预聚合规则,管理规则的启停状态 |
Prometheus 服务的常见场景和提示词示例
修改 Prometheus 实例存储时长: 修改 Prometheus 实例 {实例Id/名称} 的存储时长为 90 天,归档时长为 180 天。
创建RecordingRule: 在 Prometheus 实例 {实例Id/名称} 下,创建一个 Recording Rule,预聚合各节点的 5 分钟平均 CPU 利用率。
停止RecordingRule: 停止 Prometheus 实例 {实例id/名称} 下的 {聚合任务名} 预聚合任务。
创建 Prometheus 聚合视图: 创建一个聚合视图 {聚合视图名},包含 {workspace} 空间下 {区域名} 区域的所有 Prometheus 实例。
实战场景四(应用性能监控 APM):应用监控/AI 可观测接入
此场景的接入流程包括初始化 APM 基础设施、获取凭证、注册应用、获取配置模板、验证接入等步骤,传统接入过程较复杂。通过 CLI + Skill 可极大简化流程,实现自然语言交互式接入。
详情参考《告别复杂接入流程:用 AI Agent Skill 驱动云监控可观测接入》。
实战场景五(数据查询):元数据、PromQL 和基础云监控指标查询
业务场景
查询元数据、Prometheus 指标数据、基础云监控指标数据,以便分析业务运行情况、排查故障/问题。
使用方式
以下是典型的对话示例:
CPU使用率最高的 ECS 列表: 找出最近半小时内 CPU 使用率最高的10台 ECS 实例。
以下为 Agent 支持的核心能力概览
| 能力 | Agent 自动执行的操作 |
|---|---|
| 元数据(Meta)查询 | 执行指标、namespace、事件元数据查询 |
| PromQL 查询 | 对接入云监控指标监控的资源,执行即时查询和范围查询,以及 label、labelValues、series 元数据查询 |
| 基础云监控指标查询 | 执行基础云监控的top、latest、range、points等查询 |
| Trace查询 | 执行链路追踪数据查询 |
数据查询的常见场景和提示词示例
RDS 慢查询: 查询过去 30 分钟内执行时间超过 1 秒的慢查询数量趋势。
容器资源请求浪费: 查找容器集群内,过去 7 天内资源申请过大但实际使用很少的"僵尸"资源。
容器 Pod 内存泄漏嫌疑: 查找容器集群 {集群名/id} 的 {ns} 下,过去 1 小时内存使用量持续增长,且当前值超过限值 90% 的 Pod 列表。
总结
阿里云云监控 CLI(aliyun cms2)与配套的 CMS Agent Skill,不只是将控制台/API 能力迁移至命令行,更是在为可观测运维构建一套面向 AI Agent 的标准操作界面。它把分散在接入、配置、查询、告警、事件等场景中的能力统一起来,让运维人员可以用更自然的方式表达目标,用更可控的方式完成执行,用更清晰的链路完成验证和审计。
对运维团队来说,这意味着可观测建设正在从"人找入口、人拼参数、人做验证"的手工阶段,逐步走向"人定义目标、Agent 编排流程、CLI 执行操作、AI 校验结果"的协同阶段。
AI 不是要替代运维判断,而是显著降低重复操作、跨系统协作和复杂流程执行的成本,提升问题排查与故障定位的效率,让 SRE 把更多精力投入到稳定性设计、告警治理和故障复盘等更高价值的工作中。
后续我们将持续丰富 CLI 与 Skill 的能力范围,全面覆盖云监控业务场景。面向 AI 时代,云监控 CLI + Skill 希望成为运维人员和 AI Agent 之间稳定、可信、可扩展的可观测能力底座,推动自动化、智能化运维从单点尝试走向规模化落地。
相关链接:
1 CMS Agent Skill / 阿里云 Agent Skills 门户
skills.aliyun.com/skills/alib...
2 配置阿里云 CLI 身份凭证
help.aliyun.com/zh/cli/conf...
附录:CMS CLI 命令树
sql
aliyun cms2
│
│ # 接入管理域
├── integration 接入管理(包含接入策略、Addon 组件、采集规则等的全生命周期)
│ ├── policy 接入策略管理,包含 create|get|update|delete|list 等命令
│ ├── storage 查询接入策略绑定的 Prometheus 存储实例,包含 list 等命令
│ ├── dashboard 查询接入策略关联的 Grafana 大盘,包含 list 等命令
│ ├── resource 容器服务类别接入策略的资源列表查询,包含 list 等命令
│ ├── job-target 接入策略的采集任务的 scrape targets 状态查询,包含 list 等命令
│ ├── service-monitor 接入策略的Kubernetes ServiceMonitor 采集规则查询,包含 list 等命令
│ ├── pod-monitor 接入策略的Kubernetes PodMonitor 采集规则查询,包含 list 等命令
│ ├── custom-job 接入策略的自定义 Prometheus 采集 Job 查询,包含 list 等命令
│ ├── addon-release 接入策略的已部署组件实例管理,包含 create|get|update|delete|list 等命令
│ └── addon 可用接入组件目录管理,包含 get|list 等命令
├── workspace 工作空间管理,包含 create|get|list|update|delete 等命令
│
│ # APP应用管理域
├── prometheus Prometheus 服务管理(包含Prometheus实例、聚合视图、RecordingRule等)
│ ├── instance Prometheus 实例管理,包含 create|get|update|delete|list 等命令
│ ├── view Prometheus 聚合视图管理,包含 create|get|update|delete|list 等命令
│ └── recording-rule RecordingRule 预聚合管理,包含 create|get|update|start|stop|delete|list 等命令
├── apm 应用性能监控管理
│ ├── service APM 应用服务管理,包含 create|get|update|delete|list 等命令
│ └── configuration APM 配置管理,包含 get|create 等命令
├── rum 用户体验监控管理
│ ├── service RUM 应用服务管理,包含 create|get|update|delete|list 等命令
│ └── configuration RUM 配置管理,包含 get|create 等命令
│
│ # 告警与事件域
├── alert 告警中心管理(包含告警规则、告警模板、告警历史等)
│ ├── rule 告警规则管理,包含 create|get|update|patch|delete|list|enable|disable 等命令
│ ├── template 告警规则模板管理,包含 list|get|create|update|delete|apply 等命令
│ └── history 告警触发与恢复的历史管理,包含 list 等命令
├── notification-channel 通知渠道管理
│ ├── contact 告警联系人(邮件、短信、钉钉)管理,包含 list 等命令
│ ├── robot 告警机器人(钉钉/飞书/企微群机器人)管理,包含 list 等命令
│ └── webhook Webhook 回调地址管理,包含 list 等命令
├── event-hub 事件中心管理, 包含 list|get 等命令
│
│ # 数据查询域
├── metric 指标查询
│ ├── promql PromQL 即时/范围查询及元数据检索,包含 query|query-range|labels|label-values|series 等命令
│ └── basic 云监控1.0指标查询,包含 points|latest|range|top|export 等命令
├── trace Trace数据查询,包含 search|tree 等命令
├── entity 云资源与 EntityStore 查询,包含 query 等命令
└── meta 元数据查询,包含 metrics|namespaces|events 等命令点击此处,了解云监控 2.0 全生命周期管理详情。