"谁锁了我的表?"------搞懂数据库行锁冲突和等待事件架构

上一篇我们聊了会话生命周期那个事,把僵尸进程(idle in transaction)搞出来的资源耗尽问题给解决了。那么,如果说你遇到双十一大促,或者说月末财务结账这种并发特别高的情况,往往就会发现另外一种很头疼的现象。系统突然就不响应了,其实这就是**锁竞争与锁冲突(Lock Contention & Conflicts)**在捣鬼。
业务线研发经常跑来找你,拿一段测试没问题的 UPDATE 代码。他们就问,为什么这SQL在开发环境跑只要1毫秒,上了生产环境就一直转圈,最后还超时报错了呢?
遇到这种情况的话,千万别急着找系统组去加CPU加内存。因为其实这大概率不是硬件瓶颈的情况,也不是什么索引没命中。往往仅仅只是因为遇到了数据库底层的保护机制,也就是行级锁在排队等待。
那么今天,我们就用金仓数据库里面那些现成的内部监控视图,还有诊断函数,带你在那一堆并发连接里面,把那个拿着锁不撒手的家伙给揪出来。接着,我们还会聊聊企业层级里的应用,悲观锁跟乐观锁怎么选,怎么在架构上避开这种坑。
@toc
第一步:案发现场还原 ------ 自己动手搞一个"高并发更新冲突"
想搞懂锁是怎么运作的,光看理论没用。我们还是用老办法,开两个窗口对比一下。弄个干净的测试环境,自己模拟一下业务并发抢数据的情况。
那么先准备好之前我们建好的那张 test_lock 测试表。假设里面有一条 id=1 的数据,你可以把它当成是那种抢得很凶的商品库存。
1. 窗口 A:又慢又霸道的"业务流 A"(占位置的人)
先开第一个 ksql 终端,我们叫它会话 A。假设现在有个批量更新的业务,处理起来特别慢。我们手动开个事务,去改这行数据。然后故意卡住不提交。也就是说,用这个动作来模拟业务代码正在调第三方接口校验,半天没返回的情况。
sql
-- 会话 A:开启显式事务控制,夺取 id=1 这行数据的排他锁
BEGIN;
UPDATE test_lock SET name = '数据已被核心业务A无情锁定' WHERE id = 1;
-- 警报:千万不要敲击 COMMIT; 就让它光标闪烁,挂靠在后台这个时候你虽然看不见,但其实在数据库内核的锁管理器里面,会话 A 已经给这行数据加上了最高级别的行级排他锁(Row Exclusive Lock)。它就霸占着了。
2. 窗口 B:很急但没办法的"业务流 B"(等的人)
接着,我们打开第二个 ksql 终端,叫它会话 B。模拟一下手机端页面过来的并发请求,它刚好也要去改这条热门的数据:
sql
-- 会话 B:同样尝试修改 id=1 的数据,触发争抢
BEGIN;
UPDATE test_lock SET name = '业务B急需强行修改此数据' WHERE id = 1;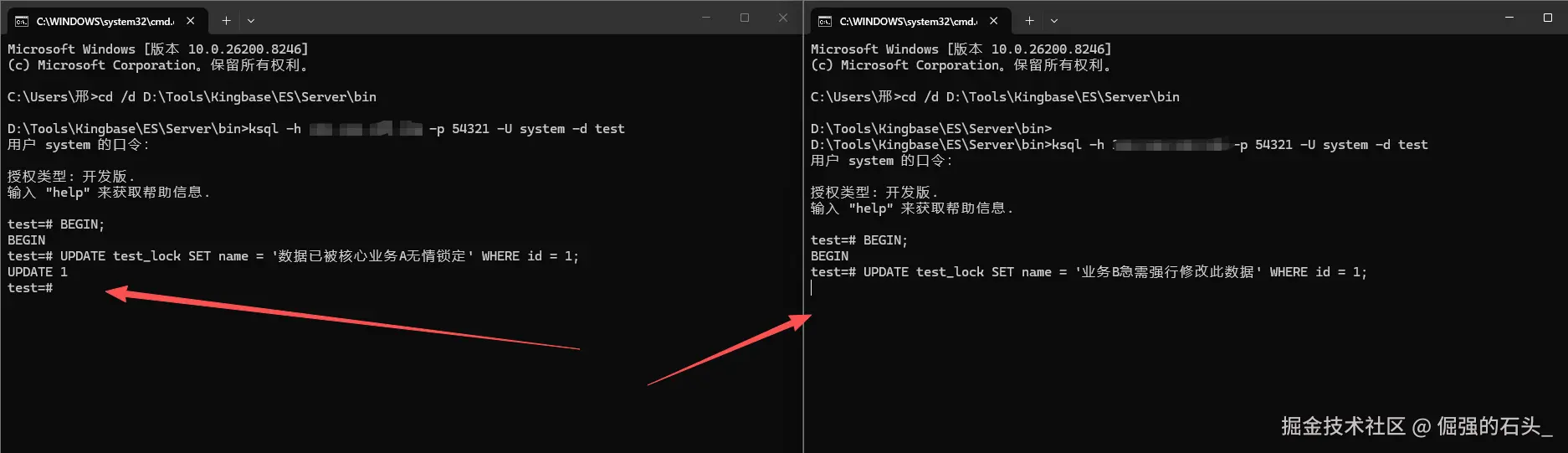
内核原理大白话:怎么就卡住了呢? 数据库为了保住数据不乱套,底层有个锁兼容性的规则。会话 B 想去拿更新锁的时候,发现这行数据上面已经有会话 A 的排他锁了。这两个锁是互相排斥的。那怎么办呢?内核只能把会话 B 挂起来,让它休眠等着的。一直等到会话 A 敲了 COMMIT,也就是把锁释放了数据生效了,或者敲了 ROLLBACK 撤销修改了,会话 B 才会被叫醒接着跑。
第二步:用雷达扫一扫 ------ sys_stat_activity 里的等待事件
如果你生产环境里头有三千个连接都在活跃着,前端页面全卡白板了,你怎么去查这三千个连接里面,哪些在跑,哪些在底层排队等着呢?
那么开第三个 ksql 终端,用DBA巡检的角度来看。我们再把那个全局雷达 sys_stat_activity 视图拿出来用。这回我们不只看基础的状态字段了,我们要看两个很专业的东西:一个是 wait_event_type,就是等待事件的大类;另一个是 wait_event,就是具体在等什么。
执行以下精准捕获等待队列的 SQL 查询:
sql
SELECT
pid,
usename,
state,
wait_event_type,
wait_event,
query
FROM sys_stat_activity
WHERE state = 'active' AND wait_event_type IS NOT NULL;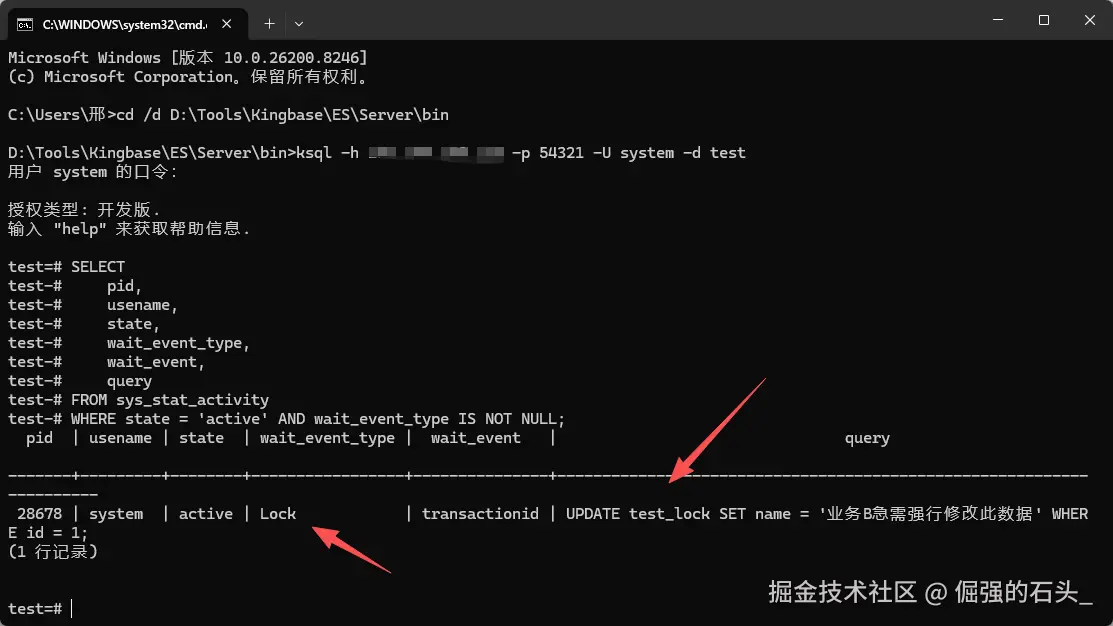
DBA 体检报告怎么看: 数据库里面会话等资源的原因有很多种的,比如等磁盘 I/O 的 IO 事件。但是如果你看到截图里 wait_event_type = 'Lock' 这个值,具体事件是 transactionid。那问题就大了。说明有业务进程因为抢事务锁,被实实在在地卡死了! 然后 query 字段里面写的那个文本,就是我们在窗口B里面跑的那条一直出不来结果的 UPDATE 语句。另外记住这个出事的进程号:PID 28678,这是我们后面找人的关键线索。
第三步:顺藤摸瓜 ------ 用函数一秒锁定"源头真凶"
我们已经知道窗口 B(PID:28678)被卡住了,那么在微服务那一堆调用里面,到底是谁卡住了 28678呢?
很多没用好工具的DBA,遇到这种情况就去翻 sys_locks 视图。用底层的事务 ID 去写几十行的 JOIN 查询。这样排查效率其实很低的,而且在出故障的时候很容易写错。
那么为了省事,金仓数据库内核里面自带了一个很好用的诊断函数:sys_blocking_pids(pid)。这个函数怎么用呢?你把被卡住的那个进程ID传给它,它就在内存里面顺着找,一秒钟就能反查出到底是谁在源头阻塞了它。
我们把这个函数用上,把刚才查到的受害者PID套进去,整理了这么一个排查锁的SQL模板。建议你直接存到你的巡检脚本里面去:
sql
SELECT
blocked.pid AS 受害者_等待进程PID,
blocked.query AS 被迫挂起的悲惨SQL,
blocking.pid AS 源头阻塞_罪魁祸首PID,
blocking.state AS 罪魁祸首当前生命周期,
blocking.query AS 罪魁祸首最后执行的SQL文本
FROM sys_stat_activity AS blocked
JOIN sys_stat_activity AS blocking
-- 这里利用 sys_blocking_pids 函数,瞬间找出谁阻塞了受害者
ON blocking.pid = ANY(sys_blocking_pids(blocked.pid))
WHERE blocked.wait_event_type = 'Lock';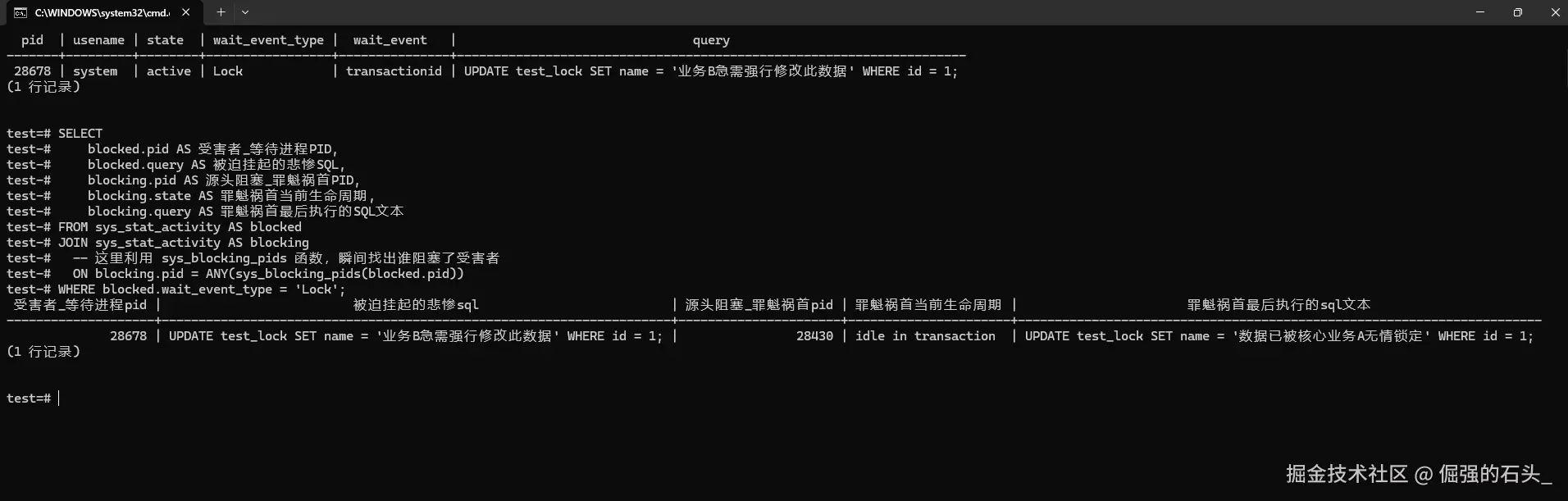
有了这个查询结果,事情就清楚了。我们能看到窗口 B 的 PID 在那边等,而且系统把窗口 A 的 PID 也给找出来了,就是它堵住了别人。而且窗口 A 当前的状态(idle in transaction),还有它在这个事务里面最后执行了什么SQL,都显示出来了。证据确凿,你可以直接截图去找研发同事对线了。
第四步:怎么解决以及架构上怎么避坑(治标和治本)
找到了源头,后面排查优化的思路就清楚了。我们得从紧急处理和底层架构改这两个方面来做。
1. 紧急处理方案(治标:动作要快)
生产环境抢修的时候,最要紧的是让业务先跑通。这里有个很容易犯的错:一看报警,很多初级运维就去把那个被卡住的进程给杀了。这没用的!你把受害者杀了重试多少次都没用,只要源头那把锁不释放,后面进来的请求还是会被卡住的。
正确的做法是什么呢?就是我们上一篇文章说的,用 sys_terminate_backend(源头阻塞_罪魁祸首PID) 这个函数。去把那个拿着锁不撒手的会话 A 干掉。会话 A 一停,它手里的排他锁马上就被内核收回去了,窗口 B 就能拿到锁,接着把更新做完。
2. 研发架构层面的避坑规范(治本:提前预防)
做DBA的,不能光靠事后杀进程,那是最次的方法。我们要去理一理业务代码逻辑,从下面这三个架构规范方面去改:
- 事务逻辑越简单越好:
BEGIN和COMMIT之间的代码,执行时间必须短。千万别在事务里面塞那些耗时不可控的非数据库操作代码。比如说你去调外部微服务 API,或者请求短信网关发验证码,再或者去读写大文件。外部调用一旦超时,数据库的行锁就一直占着不放手了。 - 统一全系统的加锁顺序: 系统一复杂,就容易出死锁的情况。啥意思呢?比如业务线 1 的代码是先更新库存表,再去更新订单表。但是业务线 2 呢,是先更新订单表,再更新库存表。这俩一高并发碰一起,A等B,B等A,就死锁了,谁也动不了。所以,全公司更新核心表的顺序一定要统一下来,这是高并发架构稳不稳的底线。
- 悲观锁跟乐观锁怎么选: 如果你发现某张表更新冲突特别厉害,传统的悲观锁,也就是直接用 UPDATE 让数据库底层排队,肯定会卡成狗的。建议研发团队搞乐观锁架构。给表加个
version版本号字段。每次更新的时候看看版本号变没变。这样的话,数据库底层锁竞争的压力,就转到应用层去重试逻辑里面去了,问题就好解决多了。
结尾说两句
从前端页面卡死报警,到用 sys_stat_activity 查内核的等待事件,再到用 sys_blocking_pids 函数找出源头,这套流程走下来,高并发下的行锁冲突排查你就搞明白了。这套方法,你在企业层级里的数据库稳定运行维护中,是经常要用到的。
那么随着业务发展,数据量越来越大,下一个挑战就来了。你以后肯定会碰到这种奇怪的事情:明明用脚本删了好几千万条过期数据,怎么服务器磁盘使用率还是一点都没降下来呢?
下一篇文章,我们就来聊聊**"数据库磁盘保卫战"**。带你看看存储引擎底层是怎么回事,把 MVCC 底层机制说明白,搞懂什么是表膨胀,还有怎么安全地把那些看似消失了其实还占着磁盘的空间给收回来!