STM32H7 Cortex-M7 内核+存储+总线+三域+DMA 完整版全覆盖复习总结报告
一、前言
本报告完整复盘本次全部学习内容,覆盖从基础存储速度、Cache命中/未命中原理、变量存放规则、各存储读写时钟周期、双发射流水线瓶颈、AXI矩阵ASIB/AMIB端口详解、D1/D2/D3三域架构本质、三类DMA全域访问权限、跨域DMA传输规则、STOP2低功耗模式、所有框图看不懂的隐藏走线、日常开发全部误区与答疑,无知识点遗漏,兼顾原理、时序、硬件框图盲区、工程实操、面试问答,完整闭环所有底层知识点。
---
二、四大存储完整对比(含精准时钟周期、变量存放规则、全部答疑细节)
2.1 整体速度排序(精准时钟,无误差)
ITCM/DTCM(1时钟周期) > Cache命中(2时钟周期) > 未命中读SRAM(3-4时钟) > 读Flash(6-9时钟)
2.2 ITCM/DTCM 紧耦合内存(最快)
-
硬件通路 :CPU专属64bit私有直连总线,完全不走AXI总线矩阵、完全不经过ICache/DCache,无总线仲裁、无标签比对、无任何等待开销
-
访问时序:固定1个内核时钟周期,零等待访问,M7性能上限
-
使用方式:无硬件自动缓存机制,必须软件手动配置;高频代码拷贝至ITCM,实时变量/系统栈放入DTCM
-
访问权限(核心考点):仅CPU、MDMA具备硬件访问通路;DMA1/DMA2/BDMA硬件无布线,彻底无法访问TCM
-
框图核心答疑(你之前的疑问) :官方架构图没有画出MDMA到TCM的连线 ,不是没有通路,而是这条通路属于AXI矩阵内部隐藏路由,外部示意图只画外部总线,内部矩阵走线不展示,总线寄存器表格可佐证通路存在
-
适用场景:中断服务函数、PID闭环控制、高频while循环、系统栈、实时关键变量,杜绝总线卡顿
-
补充区别:TCM是真实物理内存,数据永久存放,不会自动清理覆盖
2.3 ICache / DCache 高速缓存(I/D/D/D,各32KB)
2.3.1 基础分工
-
ICache(指令缓存):只缓存Flash中程序代码、只读const常量,只管CPU取指令
-
DCache(数据缓存):只缓存SRAM中全局变量、静态变量,只管CPU读写数据
-
两套缓存硬件独立,互不干扰,所有DMA均无法读取CPU内部Cache
2.3.2 命中&未命中完整原理(你最初的核心疑问)
-
Cache命中:CPU需要的指令/变量副本已经存在Cache内,无需访问外部内存,耗时2个时钟周期
-
Cache未命中:Cache无对应数据,CPU必须跳转至原始物理内存读取:代码去Flash读、变量去SRAM读,流水线直接停顿
2.3.3 关键答疑:能不能手动把变量放进Cache?
绝对不能。Cache是硬件全自动管理的临时缓冲区,不属于可寻址物理内存,编译器无法分配变量到Cache;空间不足时硬件自动采用LRU算法,淘汰长时间未使用的缓存行,覆盖新数据。仅能通过高频读写临时留住数据,无法永久锁定。
2.3.4 Cache容量不足解决方案
-
治标:高频访问热数据,减少缓存淘汰
-
治本:核心代码放入ITCM,关键变量放入DTCM,彻底脱离Cache机制
2.4 片上SRAM(SRAM1/SRAM2/AXI-SRAM)
-
用途:全局变量、大数组、以太网/LTDC/DMA大容量缓冲区,断电数据丢失
-
访问时序:Cache命中2周期;Cache未命中,CPU走AXI总线读取SRAM,整条指令耗时3-4个时钟周期
-
访问逻辑:CPU读写SRAM变量,数据会自动缓存至DCache,后续重复访问直接命中提速
2.5 片内Flash
-
用途:存储整机固件、常量数据,掉电数据保存,芯片上电默认启动地址
-
访问时序:自带硬件等待周期,Cache未命中时读取一次需要6-9个时钟周期,速度最慢
-
运行缺陷:直接在Flash运行代码,频繁触发Cache未命中,流水线大量空泡,CPU性能大幅下降
三、变量存放位置全明细(你之前混乱的变量存储问题)
-
全局/静态变量:默认存SRAM,CPU读写自动走DCache,会进入缓存
-
局部栈变量:栈配置在DTCM→不走Cache;栈配置在SRAM→自动进入DCache
-
const常量:默认存Flash,读取会进入ICache
-
手动指定DTCM变量 :直接存DTCM物理内存,完全不走DCache,无缓存命中/未命中
四、Cortex-M7 双发射机制+降级单发射完整原理(重难点全覆盖)
4.1 双发射硬件硬性要求
M7支持双发射,想要1个时钟周期同时执行2条指令,必须同时满足两个条件:
-
硬件层面:每时钟周期必须连续读出64bit数据(2条32bit ARM指令)
-
软件层面:两条指令无寄存器依赖、无硬件资源抢占
4.2 ITCM为何可以稳定满双发射
ITCM拥有独立64bit私有取指总线,绕开全部AXI矩阵、绕开Cache,每一个时钟周期固定输出64bit双指令,流水线持续满载,无任何空泡,完美跑满双发射性能。
4.3 Flash运行代码,双发射必然退化为单发射(完整底层原因)
-
Flash本身存在硬件等待周期,取指响应延迟高,流水线取指阶段直接停顿,出现大量空泡
-
CPU取指需要经过AXI矩阵,会和LTDC、MDMA等主机抢占总线,额外增加排队延迟
-
无法保证每一个时钟周期都能拿到2条连续指令,流水线指令供给断流
通俗总结:双发射需要源源不断的双指令供给,Flash速度太慢喂不饱流水线,硬件只能自动降级,一个时钟周期只能执行一条指令,性能直接腰斩。
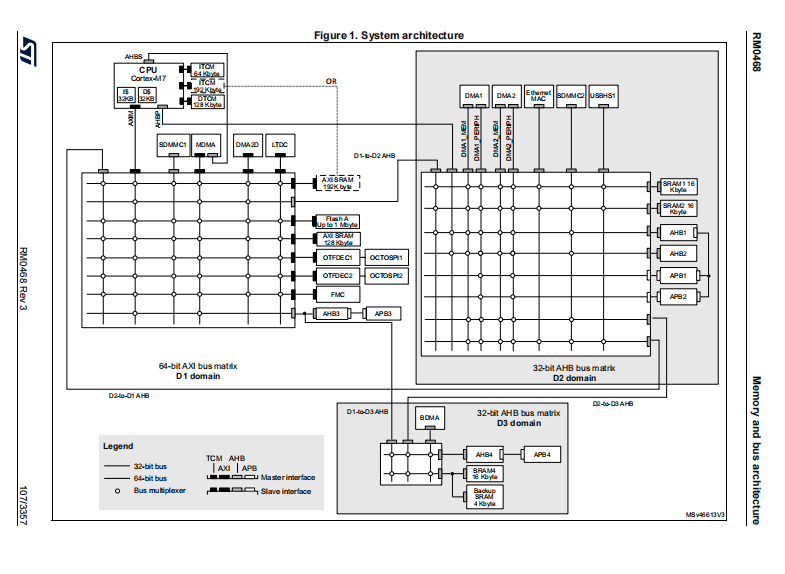
五、D1/D2/D3三大域完整详解(含分域初衷、供电、总线、权限、低功耗)
5.1 三域硬件组成(全覆盖)
-
D1高性能域:Cortex-M7内核、AXI64bit总线矩阵、MDMA、LTDC显示屏、DMA2D图形加速器、ITCM/DTCM、片内Flash、SDMMC1;总线带宽最高,负责整机核心运算与高速传输
-
D2通用外设域:DMA1/DMA2、以太网ETH、USB、SDMMC2、SRAM1、SRAM2;常规通信外设,32bit AHB总线
-
D3低功耗备份域:BDMA、RTC实时时钟、SRAM4、备份寄存器、WKUP唤醒引脚;低速外设,主打超低功耗
5.2 芯片划分三个独立域的三大核心目的
-
总线带宽隔离(最重要):各域总线相互独立,以太网、屏幕等大数据传输,不会抢占CPU高速总线,保证实时控制任务不卡顿
-
独立电源功耗管控:三域电源轨完全独立,支持单独断电,不用关闭整个芯片,精准控制功耗
-
硬件访问权限隔离:封锁D2、D3域DMA访问TCM和Flash的通路,防止普通DMA误篡改CPU实时关键数据,提升系统稳定性
5.3 低功耗核心问题:能否只保留D3域运行?
完全可以,通过STOP2深度停机模式实现
-
停机动作:软件关闭D1、D2域时钟与电源,CPU、MDMA、屏幕、网口全部断电停止工作
-
剩余运行模块:仅D3域RTC、BDMA、SRAM4、唤醒引脚持续工作
-
核心限制:D1域CPU断电后,无法运行任何业务代码,只能依靠硬件外设自动运行
-
系统唤醒:依靠RTC闹钟中断、外部WKUP引脚中断,自动上电恢复D1/D2域,CPU重新运行程序
-
数据保存:仅D3域SRAM4和备份RAM数据不掉电,D1/D2所有内存数据全部丢失
六、三类DMA全域访问权限+跨域搬运规则(无死角)
6.1 三类DMA归属与能力
-
MDMA(挂载D1域):全域全能DMA,唯一可以访问ITCM/DTCM、片内Flash的DMA;支持D1↔D2、D1↔D3全部跨域传输;独立AXI总线,不占用CPU内核带宽
-
DMA1/DMA2(挂载D2域) :仅能访问D2域全部外设与SRAM1/SRAM2;仅支持D2→D3单向跨域搬运;彻底无法访问D1域TCM、Flash,硬件无任何布线
-
BDMA(挂载D3域):仅支持D3域内部数据搬运;不能跨域访问D1、D2;是STOP2停机模式下唯一可用的DMA
6.2 跨域传输补充说明
所有跨域DMA传输都需要经过域间AHB桥接器,总线带宽会损耗、传输延迟会增加;工程开发中尽量将缓冲区放在同域内存,减少跨域数据搬运。
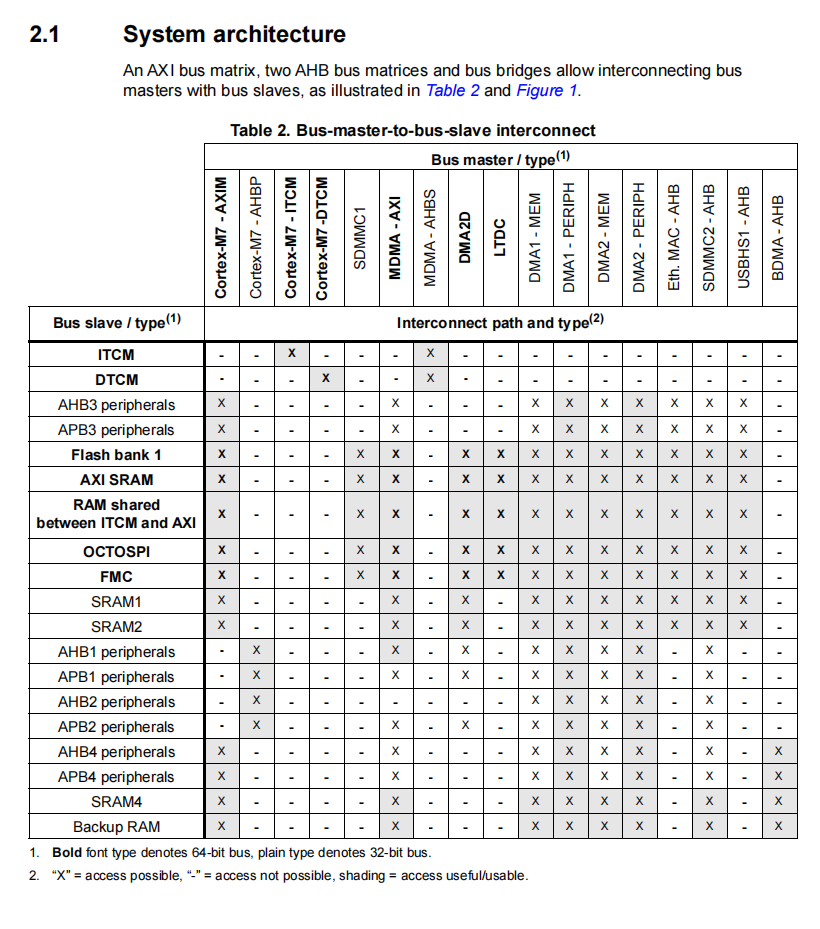
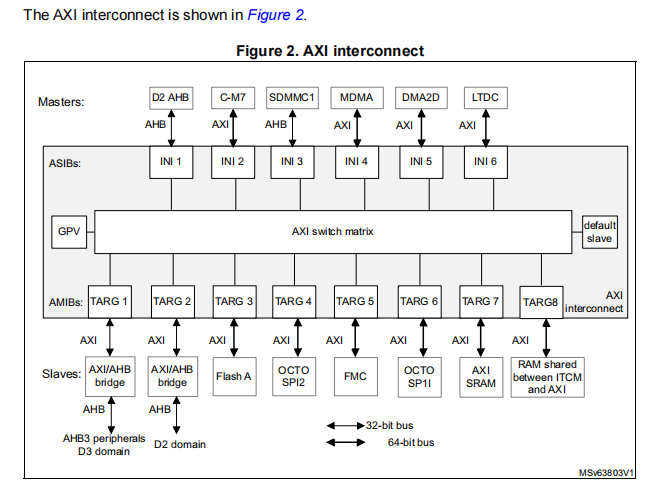
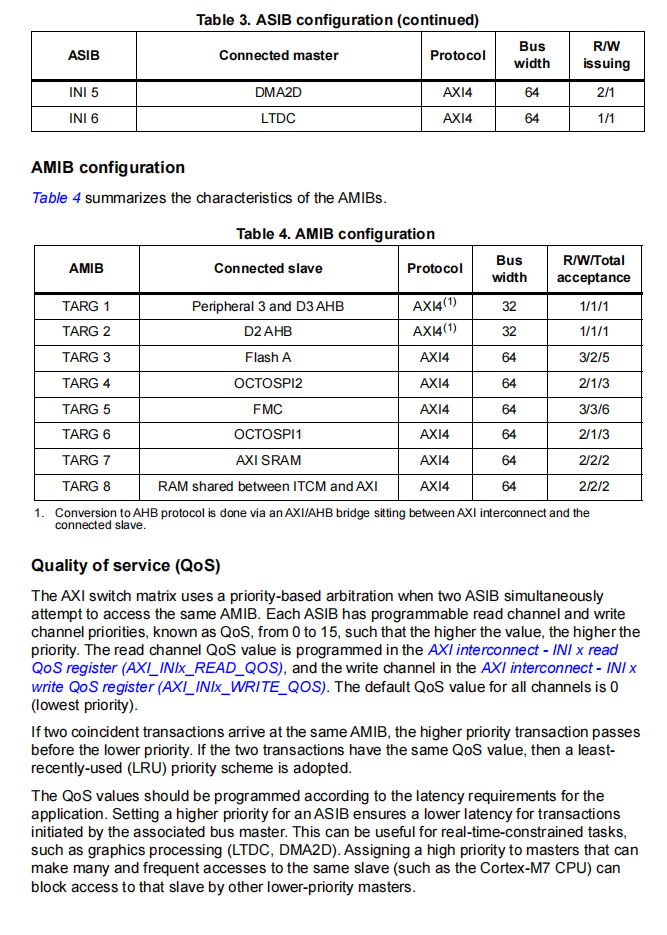
七、AXI总线矩阵 ASIB / AMIB 完整详解(含表格端口含义)
7.1 AXI矩阵通俗理解
AXI矩阵相当于芯片内部的高速网络交换机,所有总线主机(CPU、MDMA、屏幕)、所有存储从机(Flash、SRAM、TCM)全部接入交换机,由交换机统一仲裁总线请求,分配带宽。
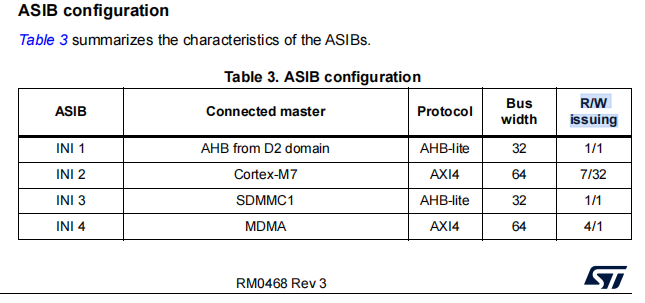
7.2 ASIB 全面解释(你提问的ASIB configuration)
-
全称:AXI Slave Interface Block,AXI从机接口模块
-
实质:INI输入端口,所有总线主机进入AXI矩阵的入口
-
ASIB configuration:官方参考手册的主机输入端口配置表,记录每一路输入端口对应的硬件、总线位宽、协议、读写队列并发深度
7.3 AMIB 全面解释
-
全称:AXI Master Interface Block
-
实质:TARG输出端口,AXI矩阵通向各类内存、外设、域桥的出口
7.4 关键硬件通路佐证
MDMA通过AXI矩阵TARG8输出端口,内部直连TCM;整条通路完全独立,不经过CPU内核端口,MDMA读写TCM全程不需要CPU参与中转。
八、高频误区点对点答疑(全部你问过的问题集中汇总)
-
Q:架构图没画MDMA连TCM,是不是没有通路? A:不是,属于矩阵内部隐藏走线,示意图不画内部线路,寄存器表格可证明通路存在
-
Q:SRAM读写需要几个时钟? A:Cache命中2周期,Cache未命中3-4周期
-
Q:变量能不能强制放进Cache? A:不能,Cache硬件自动管理,软件无任何分配接口
-
Q:Cache满了怎么办? A:硬件LRU淘汰旧数据,自动覆盖
-
Q:为什么Flash跑代码双发射失效? A:取指延迟大,流水线断流,无法持续供给双指令
-
Q:DMA1能不能搬运TCM数据? A:不能,硬件无布线,只有MDMA可以
-
Q:休眠能不能只留D3? A:可以,进入STOP2,但是CPU断电不运行代码
九、TCM与Cache终极对比表(直观区分,彻底不混淆)
| 对比项 | ICache/DCache | ITCM/DTCM |
|---|---|---|
| 硬件属性 | CPU内部临时缓存,副本内存 | 独立物理高速内存 |
| 访问总线 | 走AXI矩阵总线 | CPU私有专线,不走AXI |
| 访问延时 | 命中2周期,未命中大幅延迟 | 固定1周期零等待 |
| 管理方式 | 硬件全自动,软件不可控 | 软件手动分配管控 |
| DMA访问 | 所有DMA均无法访问 | 仅MDMA可以访问 |
| 数据淘汰 | 空间不足自动淘汰覆盖 | 无淘汰,数据永久保留 |
十、工程开发最优配置方案(落地实操)
-
高频实时算法、中断代码 → MDMA搬运至ITCM运行,拉满CPU双发射性能
-
系统栈、PID变量、中断临时数据 → 放入DTCM,全程绕过Cache,无缓存同步问题
-
屏幕、以太网大缓冲区 → 放在同域SRAM,减少跨域总线损耗
-
设备低功耗休眠 → 关键数据存入D3域SRAM4,关闭D1/D2进入STOP2模式
-
DMA搬运SRAM数据 → 必须手动刷新/失效DCache,避免CPU缓存与物理内存数据不一致
十一、面试一句话速记总纲(全文浓缩)
TCM最快不走总线和缓存,Cache自动管理不能手动放变量;Flash取指延迟打断流水线,双发射被迫降级单发射;三域分离隔离总线、省电、保护TCM;只有MDMA能访问TCM,跨域传输带宽下降;STOP2可关闭D1D2仅保留D3低功耗运行;ASIB是总线主机入口,AMIB是外设内存出口,MDMA依靠矩阵内部隐藏线访问TCM,框图不展示内部走线。
十二、配套全套面试真题(含标准答案,直接背诵)
本节题目全覆盖本次所有知识点,分为基础必答题、进阶深挖题、总线架构压轴题,完全贴合STM32H7面试高频考点,答案精简标准,适合口头作答。
12.1 基础必答题(入门必考)
-
Q1:简述STM32H7四种存储介质,速度从快到慢排序?各自时钟周期是多少?
**A:**速度排序:ITCM/DTCM(1周期) > Cache命中(2周期) > SRAM未命中(3-4周期) > Flash(6-9周期)。TCM是CPU私有专线零等待;Cache是CPU内部临时缓存;SRAM为片上运行内存;Flash存放固件,读取自带等待周期,速度最慢。
-
Q2:ICache和DCache分别作用是什么?二者有什么区别?
**A:**ICache是指令缓存,专门缓存Flash中的代码与常量;DCache是数据缓存,专门缓存SRAM中的运行变量。二者硬件独立、分工隔离,所有DMA都无法访问CPU内部Cache。
-
Q3:什么是Cache命中、Cache未命中?
**A:**CPU需要的指令或数据已经存在Cache中,直接读取即为命中,耗时2时钟;Cache无对应数据,需要跳转SRAM/Flash原始内存读取,流水线停顿,即为未命中。
-
Q4:能不能手动把变量强制放到Cache里?为什么?
**A:**不能。Cache是硬件全自动管理的临时缓冲区,不属于可寻址物理内存,软件无法分配变量;空间不足会自动用LRU算法淘汰旧数据,只能高频访问临时留存,无法永久锁定。
-
Q5:Cache容量不足32KB,装满之后会怎么处理?
**A:**硬件自动采用伪LRU算法,淘汰长时间未访问的缓存行,直接覆盖写入新数据;旧数据再次访问会触发未命中,重新读取底层内存,造成性能卡顿。
12.2 进阶深挖题(面试高频挖坑题)
-
Q6:为什么代码放在Flash运行,M7双发射会退化成单发射?
**A:**M7双发射要求每个时钟周期必须一次性读取64bit(2条32位指令)。Flash读取存在硬件等待周期,同时访问需要经过AXI总线矩阵,存在总线仲裁排队延迟,流水线频繁断流出现空泡,无法持续供给双指令,硬件自动降级为单发射,性能直接腰斩。
-
Q7:ITCM/DTCM和Cache核心区别是什么?
**A:**TCM是独立物理高速内存,走CPU私有专线,不走AXI总线、不走Cache,软件手动分配,无数据淘汰;Cache是CPU内部临时副本,走AXI总线,硬件全自动管理,空间不足自动淘汰数据,所有DMA均无法访问Cache。
-
Q8:STM32H7为什么要划分D1/D2/D3三个电源域?
**A:**三点核心作用:①总线隔离,各域总线独立,外设不会抢占CPU带宽,保障实时性;②功耗隔离,三域电源独立,可单独关闭D1/D2,仅保留D3极低功耗运行;③权限隔离,禁止D2/D3普通DMA访问TCM/Flash,保护CPU关键实时数据。
-
Q9:STM32H7三类DMA分别能访问哪些内存?谁能跨域?
**A:**MDMA:D1域专属,唯一可访问TCM、Flash,支持全域跨域搬运;DMA1/DMA2:D2域专属,无法访问TCM/Flash,仅支持D2到D3单向跨域;BDMA:D3域专属,仅能域内搬运,无跨域能力,低功耗模式唯一可用DMA。
-
Q10:官方架构图没有画出MDMA连接TCM的线,是不是二者没有通路?
A:不是没有通路,而是MDMA访问TCM依靠AXI矩阵内部隐藏路由,外部架构示意图只绘制外部总线,不展示芯片矩阵内部走线,参考手册总线端口表格可以佐证该通路真实存在,且全程不经过CPU内核。
12.3 总线架构压轴题(高薪面试必问)
-
Q11:解释AXI矩阵中ASIB和AMIB是什么?ASIB configuration含义?
**A:**ASIB是AXI主机输入端口(INI),是所有外设、CPU进入AXI矩阵的入口;AMIB是AXI从机输出端口(TARG),是矩阵通往内存、外设、域桥的出口。ASIB configuration指官方手册的主机输入端口配置表,记录每个输入端口的总线位宽、协议、并发读写队列深度。
-
Q12:STM32H7能否关闭D1、D2域,只保留D3域运行?有什么限制?
**A:**可以,进入STOP2深度停机模式即可。限制:D1域CPU彻底断电,无法运行任何业务代码;仅D3域RTC、BDMA、SRAM4、唤醒引脚工作;D1/D2所有内存数据丢失,仅D3域数据可保存;需要依靠中断唤醒整机恢复运行。
-
Q13:CPU读写SRAM变量,会不会经过DCache?不同变量存放位置有什么区别?
**A:**全局、静态变量默认存SRAM,读写自动经过DCache;栈放在SRAM时局部变量也会进DCache;栈放在DTCM、手动指定DTCM的变量,全程不经过DCache,无缓存同步问题;const常量存Flash,走ICache缓存。
-
Q14:DMA做内存搬运时,为什么一定要做Cache缓存同步?
**A:**CPU读写SRAM数据会缓存到DCache,物理SRAM内存和CPU内部缓存数据不一致;DMA直接访问物理SRAM内存,读取不到CPU缓存内的新数据,会出现数据错乱,因此必须手动刷新或失效DCache,保证数据一致。
12.4 面试官追问秒杀短句(临场快速作答)
-
问:谁最快?答:TCM私有专线最快,1个时钟无等待
-
问:Cache能控制吗?答:不能,硬件全自动,软件无权干预
-
问:谁能访问TCM?答:只有CPU和MDMA,其余DMA全部不行
-
问:Flash为什么慢?答:自带等待周期,总线抢带宽,流水线空泡
-
问:三域最大意义?答:隔离总线、省电、保护内核高速内存