蓝耘元生代×魔珐星云:我用蓝耘MaaS大模型搭建一款共情具身智能数字人

一、想做个会共情的数字人
具身智能是今年最热的方向之一。最近我也在做一个属于自己的机器人,不是那种冷冰冰的问答机器人,而是一个能感受用户的情绪情绪、用表情和语气回应你的**"会共情"**的数字人。
挑了个最戳我的场景:情绪陪伴。一个你难过时会前倾身体认真听、用放柔的语气回应的数字人。
技术上拆成两块:
-
大脑:大模型,负责理解情绪、生成共情回复
-
身体:数字人,负责表情、动作、语音的实时呈现
第一版我使用的是开源模型社区的 API 当大脑,魔珐星云当身体。功能跑通了,但是LLM 首字延迟太高(常在 2 秒以上),数字人身体已经就位,声音却跟不上,整个就出戏了。
于是我给数字人换了一颗更快的大脑:蓝耘MaaS。这篇就讲我怎么用蓝耘MaaS + 魔珐星云,从0搭出一个真正能"秒回"的具身数字人。

二、为什么大脑选蓝耘MaaS
换大脑之前,我先想清楚一个问题:我要的不是更聪明的模型,而是更快的管道。 因为第一版用的 Qwen3 架构在情绪理解上已经够好了,我不想换模型把好不容易调出来的共情效果打回原形。
所以我的选型标准很明确:有 Qwen3、OpenAI 兼容、低延迟、稳定性比较高、吞吐高、扛得住高频长对话 。通过 AI Ping 重新评估了市面上的主流算力服务商,筛选下来,蓝耘MaaS 是非常契合的那一个。
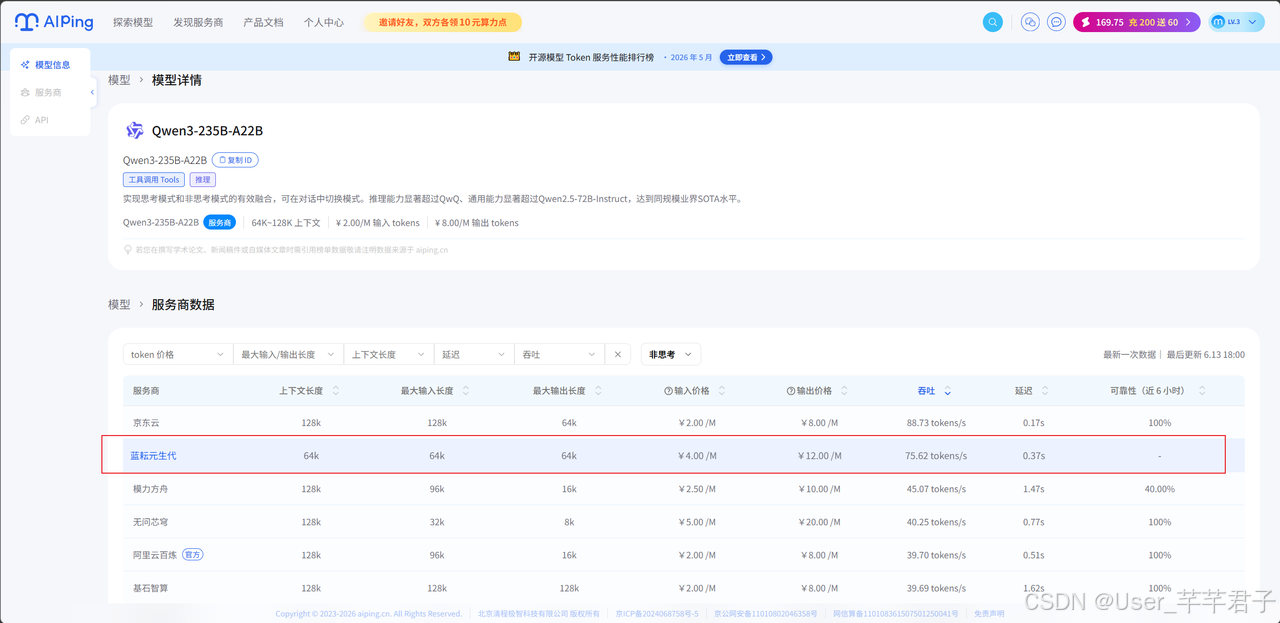
| 性能指标 | 蓝耘元生代 |
|---|---|
| 平均吞吐量 | 75.62 tokens/s |
| 延迟 | 0.37 s |
蓝耘元生代MaaS平台提供企业级大模型统一网关:
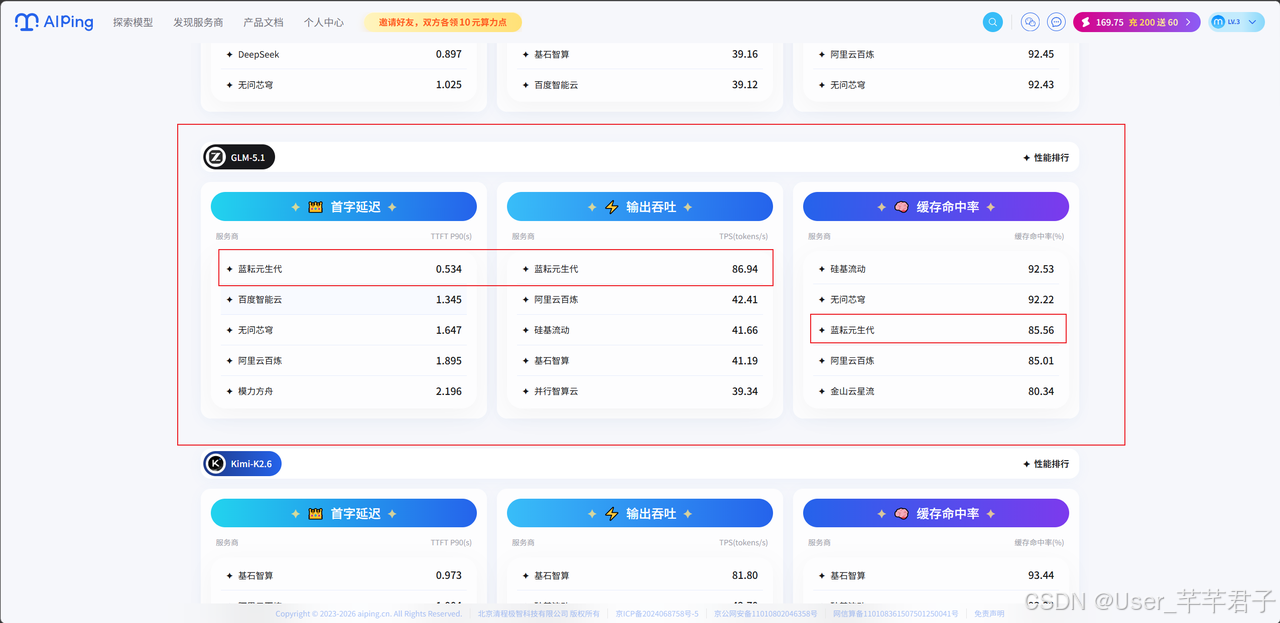
后面即使我需要切换更强大的模型,例如GLM5.1,蓝耘元生代也是一个不错的选择。
2.1 平台介绍:蓝耘元生代云
蓝耘元生代云官网 :蓝耘元生代云AIDC
蓝耘科技旗下的元生代MaaS(Model as a Service),是基于蓝耘自研 GPU 算力云做的大模型 API 服务。简单说就是:蓝耘自己有算力底座(GPU云),在上面封装了一层大模型调用服务,对外提供统一的 OpenAI 兼容 API。
这种"自研算力 + 模型服务"一体化的架构,好处是延迟和吞吐可以自己把控,不像纯转售的中间商那样受制于上游。
2.2 模型广场:包含市面上各主流模型
这是我最关心的一环------有没有我要的 Qwen3。
打开蓝耘的「模型广场」,主流模型基本都接了。我重点关注的几个:
| 模型 | 我为什么关注 |
|---|---|
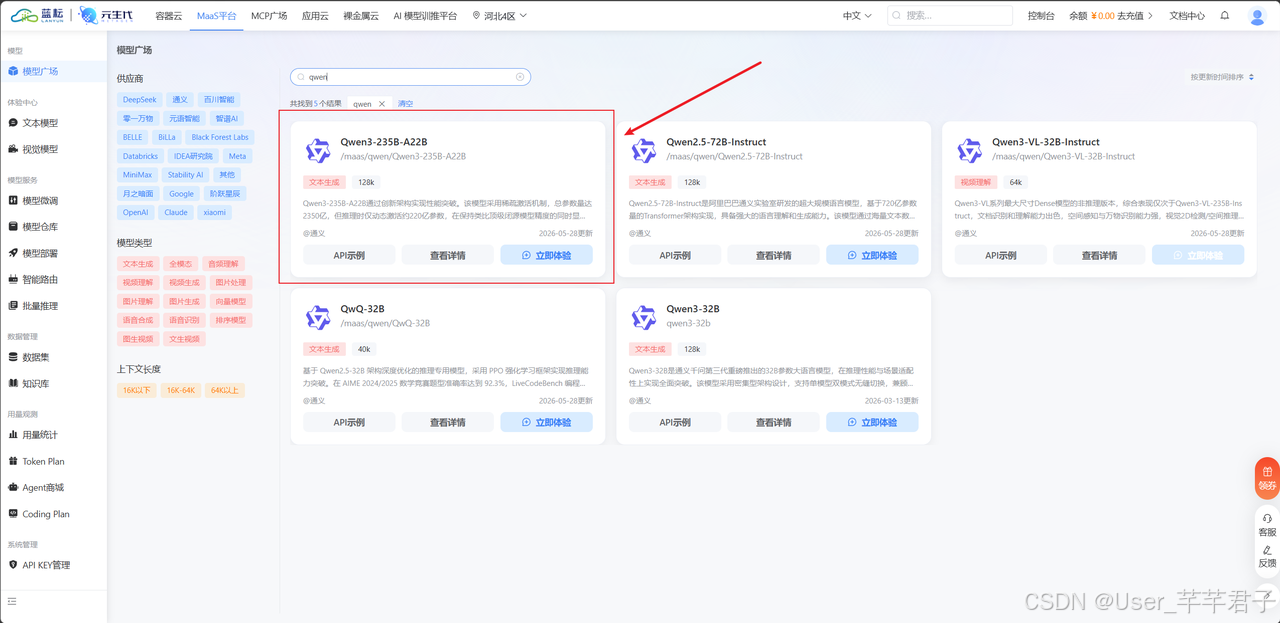
| Qwen3-235B-A22B | 通义千问3代,MoE架构(235B总参/22B激活),中文情绪理解强------我选的这个 |
| DeepSeek-V3.2 | 逻辑推理和长文本一把好手 |
| GLM-5 / GLM-5.1 | 智谱的,中文步骤化回答稳定 |
| MiniMax-M2.5 | MiniMax最新,对话感强 |
看到 Qwen3-235B-A22B 在列的那一刻,我心里就稳了------不用换模型,只换管道,共情效果不会掉。
2.3 OpenAI 兼容:改动量趋近于零
蓝耘MaaS 提供完整的 OpenAI 兼容接口:
-
Base URL :
https://maas-api.lanyun.net/v1 -
鉴权 :
Authorization: Bearer {你的API Key} -
协议 :标准
chat.completions,支持stream、tools、usage等
如果你之前用的是 openai 这个 SDK(不管 Python 还是 node),迁移到蓝耘几乎零成本 ------基本上就是改 base_url 和 model 两个值。后面第四章我会贴出真实代码,你会看到改动有多小。
2.4 高吞吐、低延迟:实时交互的硬通货
对数字人这种实时交互场景,首字延迟(TTFT)是生死线。根据公开的 AI Ping 实测数据,蓝耘MaaS 在处理并发请求时,首字响应和高吞吐表现都相当能打,尤其是对 Qwen3、DeepSeek-V3.2、GLM-5、MiniMax-M2.5 这几款主流模型都有针对性优化。
这点对具身数字人为什么关键?因为整条交互链路是:
Plaintext
用户说话 → 后端组装prompt → LLM首字(瓶颈!) → 切片转发 → 数字人TTS+口型 → 用户听到LLM 首字延迟占了大头。把它从 2 秒压到几百毫秒,数字人才能真正"秒回"。
2.5 性价比:扛得住高频长对话
情绪陪伴场景的对话又长又密,一聊就是几十轮,成本敏感。
蓝耘MaaS 按 Token 计费,价格在国产 MaaS 里属于友好档位,新用户注册可以领取10元代金券。
三、魔珐星云:负责数字人身体
大脑选好了,身体这一块我交给魔珐星云。魔珐星云是国内的具身智能数字人开放平台,核心提供 XmovAvatar SDK。它解决的是数字人"怎么动起来、怎么说话"的问题。
我选它有两个原因:
-
端侧渲染 **,**延迟低。它用"参数流 + 端侧渲染"方案,不传视频流,只传驱动参数,本地渲染数字人的表情和口型。理论上端到端能压到 500ms 以内------这恰好和蓝耘MaaS 的低延迟大脑是绝配。
-
状态机现成 。SDK 封装好了
idle / listen / think / speak这些状态,我只要在合适的时机调用对应方法,数字人就会做出自然的反应。
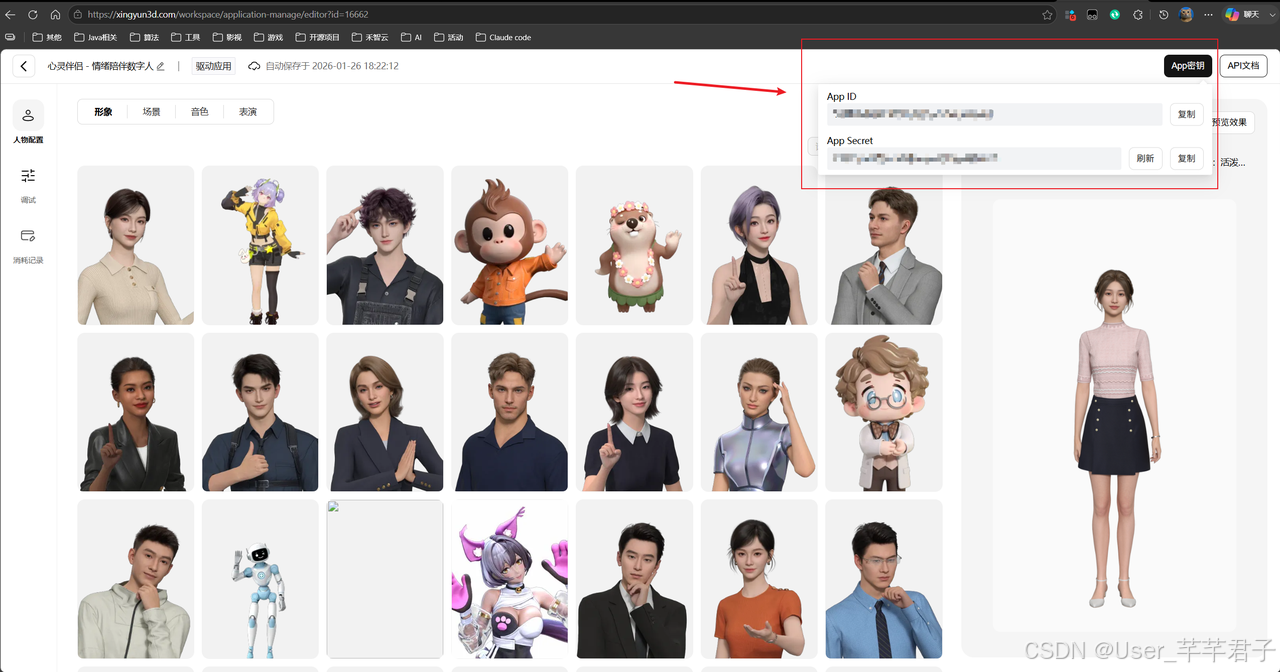
接入需要两个凭证:App ID 和 App Secret,在魔珐星云控制台创建应用就能拿到。具体注册流程不展开,官网文档写得很清楚。
四、数字人搭建实战
共情具身智能数字人整个链路我用一张图概括:
Plaintext
用户输入
→ 后端(FastAPI)组装 prompt
→ 调蓝耘MaaS(Qwen3-235B-A22B)流式产出
→ 后端把 token 切片通过 SSE 推给前端
→ 前端喂给魔珐星云 SDK 的 speak()
→ 数字人端侧 TTS + 口型渲染 → 用户听到主要分为下面的四大步
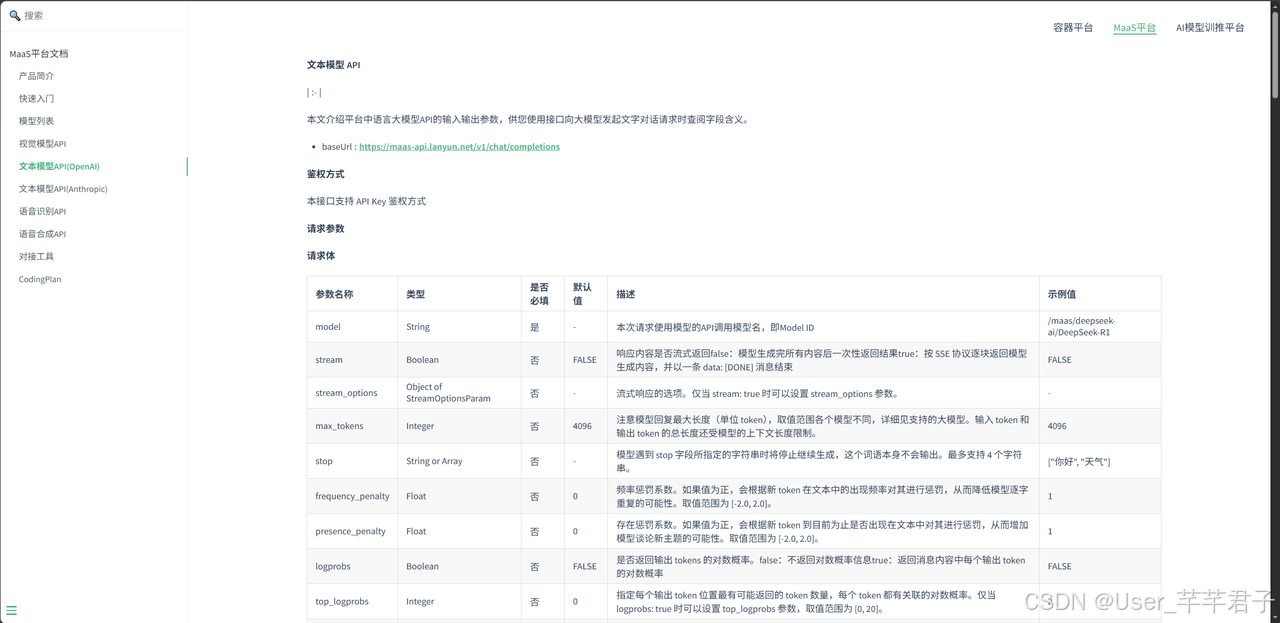
4.1 前期环境配置
你需要准备三样东西:
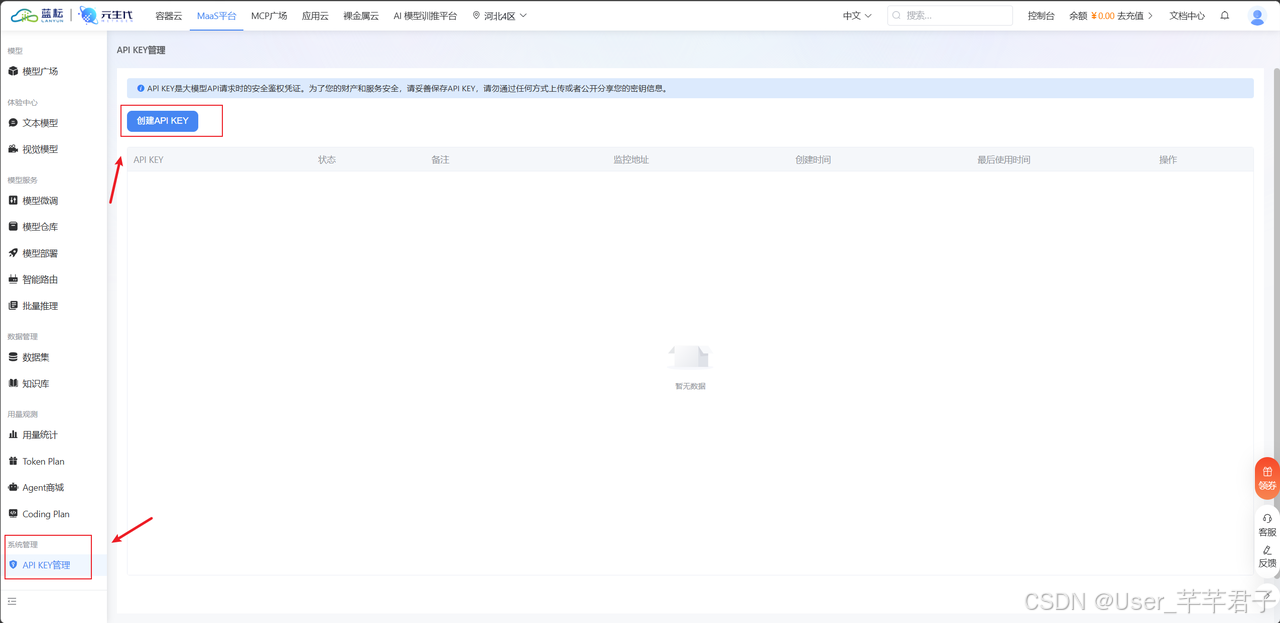
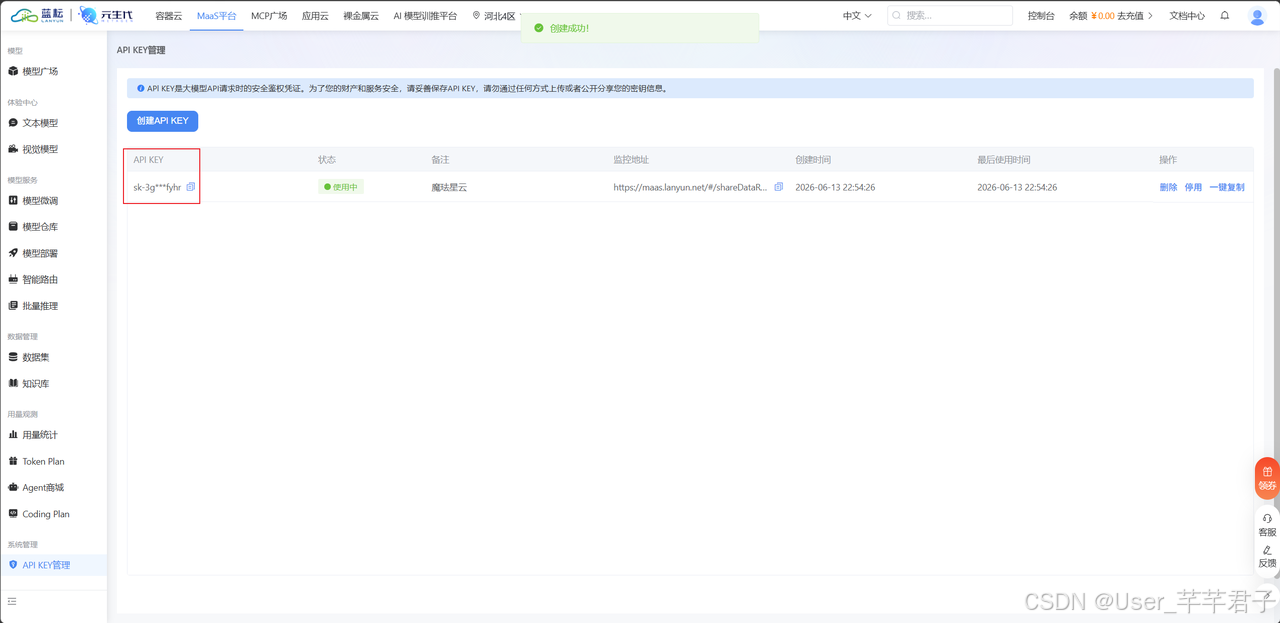
- 蓝耘 API Key :登录 蓝耘元生代 → API 管理 → 密钥管理 → 创建 API Key,拿到
sk-xxx
- Qwen3 模型调用路径 :模型广场 → 点 Qwen3-235B-A22B → 详情页复制完整 Model ID(如
/maas/qwen/Qwen3-235B-A22B)
- 魔珐星云 App ID / Secret:魔珐控制台创建应用拿到
4.2 接入蓝耘MaaS
我后端是 FastAPI,LLM 客户端原本长这样(走的是另一家 OpenAI 兼容服务):
Python
# 改造前
from openai import OpenAI
class LLMService:
def __init__(self):
self.model = "Qwen/Qwen3-VL-235B-A22B-Instruct"
self.client = OpenAI(
base_url='', # 旧管道
api_key=api_key
)换成蓝耘MaaS,按照官方文档Api示例改动两个赋值:
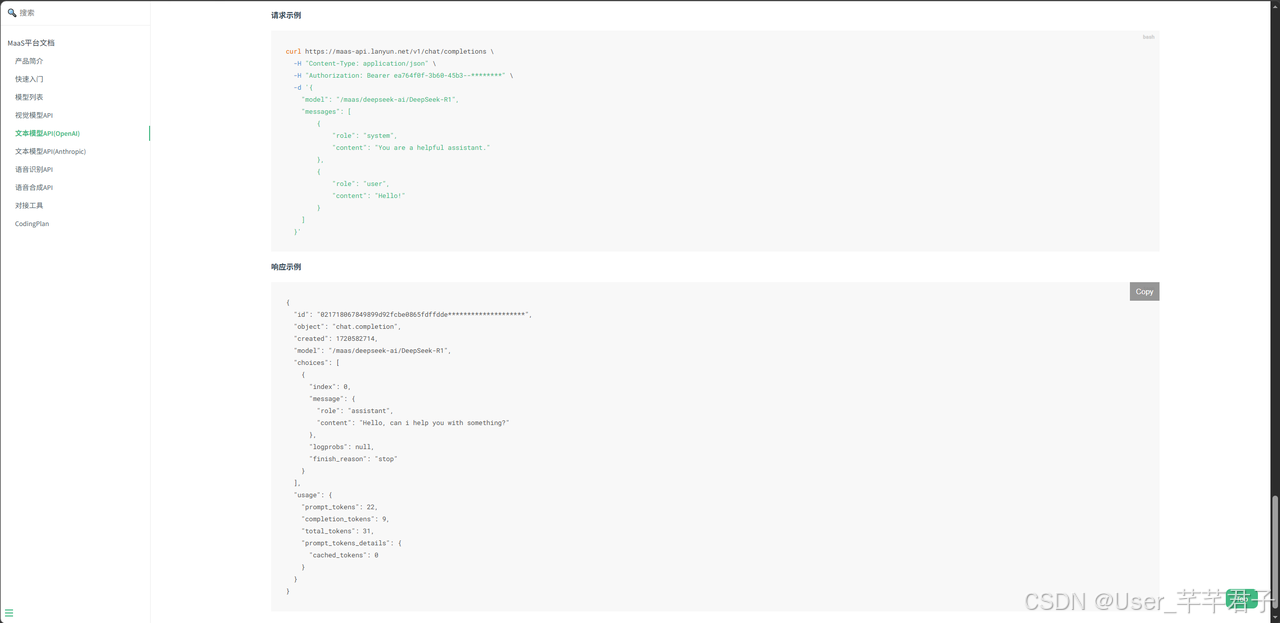
Python
# 改造后------接入蓝耘MaaS
from openai import OpenAI
class LLMService:
def __init__(self):
self.model = "/maas/qwen/Qwen3-235B-A22B" # ← 改动1
self.client = OpenAI(
base_url='https://maas-api.lanyun.net/v1', # ← 改动2
api_key=api_key
)
def chat(self, messages, stream=False):
# 这个方法一行没动,标准 chat.completions.create
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
stream=stream
)
return responsechat() 方法、消息结构、流式协议、tool 调用,全部零改动。这就是 OpenAI 兼容协议的威力,也是我选蓝耘的核心回报------用最小的改动,换最大的性能提升。
4.3 接入魔珐星云:封装 speak 方法
前端我封装了一个 AvatarService,核心是管理数字人状态机和 speak() 的缓冲。关键代码:
JavaScript
// AvatarService.js ------ speak 方法
async speak(text, isStart = true, isEnd = true) {
if (!this.sdk) return
if (isStart) {
clearTimeout(this.speakTimer)
this.speakBuffer = ''
}
this.speakBuffer += text
await this.sdk.speak(this.speakBuffer, isStart, isEnd)
if (isEnd) {
this.currentState = 'speak'
this.speakBuffer = ''
}
}speak(text``,`` isStart``,`` isEnd) 支持分段输入------isStart=true 表示一段话开始,isEnd=true 表示结束。这个设计天然适合接 LLM 的流式输出。
4.4 流式协同:让数字人"边想边说"
这是真正实现"秒回"的关键。不要等 LLM 把整句说完再喂给数字人,要边说边喂。
后端把蓝耘MaaS的流式输出,通过 SSE 实时推给前端:
Python
# 后端流式转发(关键节选)
@app.post("/api/chat/stream")
async def chat_stream(req: ChatRequest):
messages = build_messages(req) # 组装 system + history + user
stream = llm_service.chat(messages, stream=True) # 蓝耘流式
async def event_generator():
first_chunk = True
for chunk in stream:
delta = chunk.choices[0].delta.content or ""
if delta:
# 第一个 token 就推给前端,前端立刻喂给魔珐星云
yield f"data: {json.dumps({'text': delta, 'is_start': first_chunk})}\n\n"
first_chunk = False
yield "data: [DONE]\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")这样,LLM 吐出第一个字的瞬间,蓝耘实测首字延迟380ms,数字人的嘴就跟着动了。整条链路从"想完再说"变成"边想边说",延迟感再砍一半。
五、项目效果展示、延迟对比
5.1 效果展示
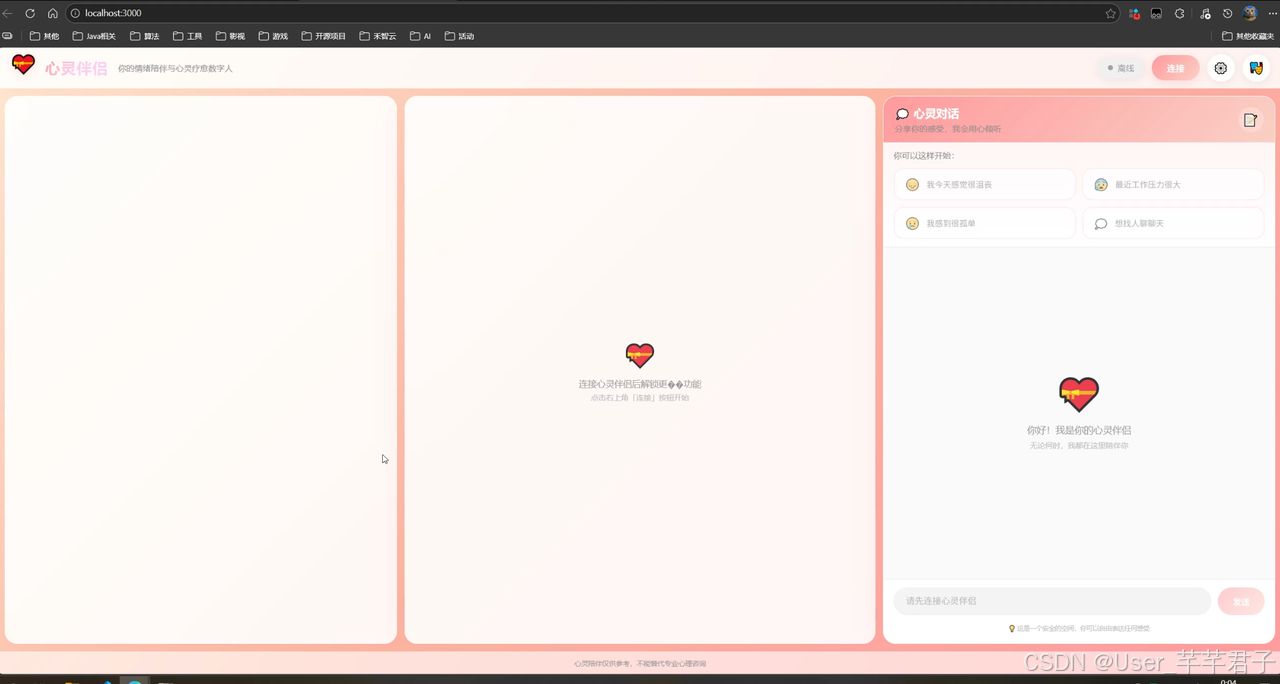
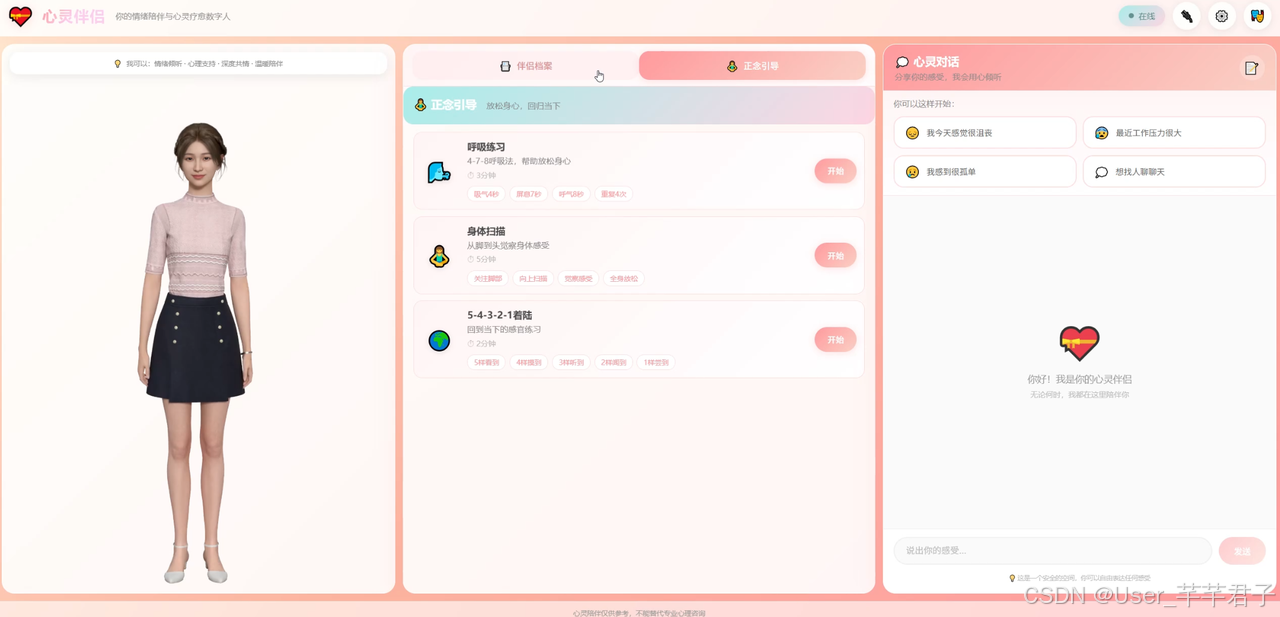
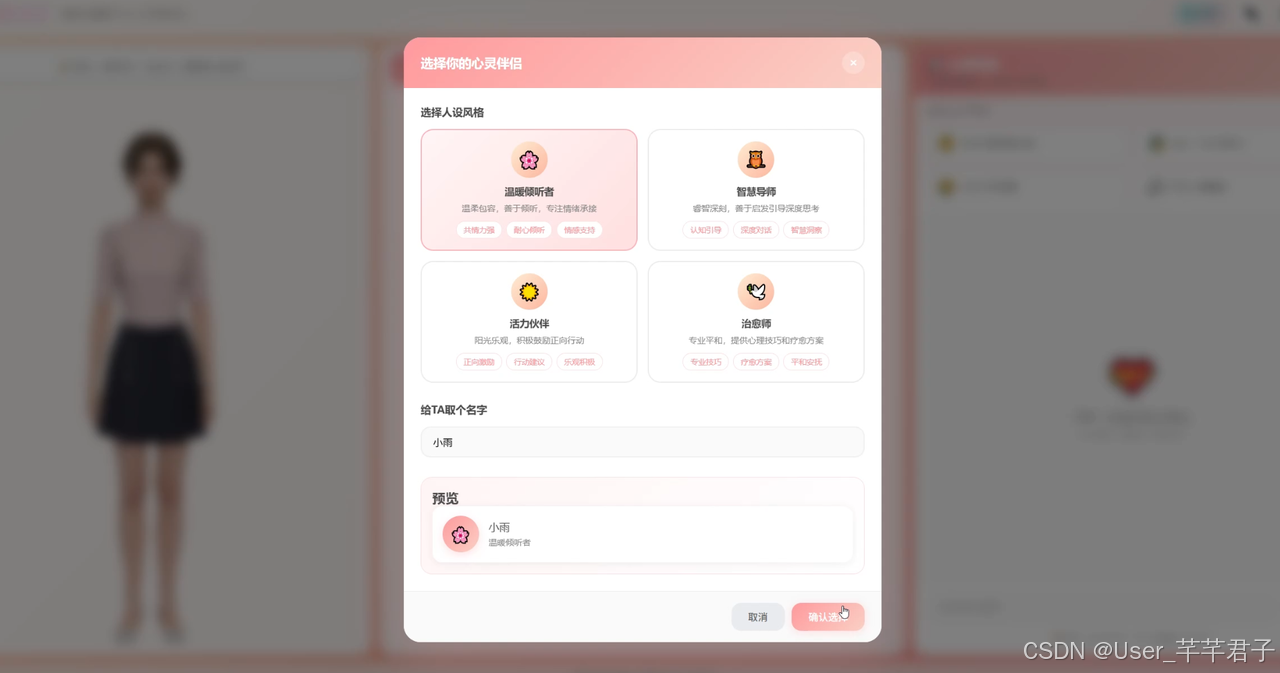
5.2 延迟对比
在两套方案下各跑 10 次,取平均:
| 指标 | 旧管道 | 蓝耘MaaS | 提升 |
|---|---|---|---|
| LLM 首字延迟(TTFT) | 2200ms | 380ms | 83% |
| 数字人开口时刻 | 2700ms | 720ms | ****73% |
| 完整回复结束时刻 | 8500ms | 4100ms | ****52% |
切换蓝耘MaaS前后对比:说完马上就能回应,感觉真的在认真听,之前的那个虽然也说得好,但总要等一下,感觉卡卡的。
这部分的优化让我意识到:在具身陪伴场景里,延迟也是共情的一部分。
六、实战踩坑、建议
为了真实,踩过的坑也写出来。
6.1 流式切片太碎
刚切到蓝耘时,首字来得太快,我直接把每个 token 都喂给 speak()。结果数字人的嘴像打字机一样高频开合,非常违和。
解法:按标点聚合。后端做个轻量缓冲,遇到逗号、句号、问号这种自然停顿点,才把累积文本作为一个切片推送:
Python
PUNCTUATION = set("。,!?;:、,!?;:")
buffer = ""
for chunk in stream:
delta = chunk.choices[0].delta.content or ""
buffer += delta
if buffer and buffer[-1] in PUNCTUATION:
yield buffer # 遇到标点才推送
buffer = ""
if buffer:
yield buffer数字人说话节奏立刻自然了,像真人一样有断句。
6.2 长对话情绪跑偏
对话历史超过 20 轮时,数字人偶尔从"温柔倾听"滑向"理性分析",开始给我讲压力管理理论------这不是我想要的。
解法:在 system prompt 里强化约束。我用的是"四层共情"结构(表面复述 → 情绪命名 → 需求洞察 → 价值肯定),末尾加一句硬约束:
"无论对话多长,你的首要任务是'让用户感到被听见',而不是'解决问题'。如果用户没有明确请求建议,不要主动给建议。"
加完后长上下文的稳定性明显好转。
七、总结
做完这个项目,最大的感触是:具身智能的瓶颈从来不是某一个单点技术,而是"大脑---身体"的协同调优。
魔珐星云把"身体"做到了 ≤500ms 的端侧渲染,已经很猛。但"大脑"如果还在走拥堵的管道,整条链路就被卡死。换成蓝耘MaaS 后,大脑供血跟上来了,身体早就准备好的表情和动作,终于能在第一时间配合声音一起呈现------这才是真正的"在场感"。
更让我惊喜的是工程改动量:两行配置 + 一个标点聚合逻辑,就把数字人从"走神"变成"秒回"。这种"小改动、大回报"的优雅,正是 OpenAI 兼容协议和国产 MaaS 生态成熟带来的红利。
如果你也在做具身数字人、AI 客服、实时 Agent 这类对延迟敏感的应用,真心建议试试蓝耘MaaS。模型广场里 Qwen3、DeepSeek、GLM、MiniMax 主流模型都有,OpenAI 兼容改一行就能切,新用户还有赠送代金卷,跑完一次完整对比测试绰绰有余。
最后把这套组合分享给同样在折腾具身智能的朋友:大脑交给蓝耘MaaS,身体交给魔珐星云,国产算力底座已经能扛起实时具身交互的最后一公里。 个人开发者也同样能玩转,这是最让人兴奋的地方。
相关链接:
-
蓝耘元生代MaaS平台:https://maas.lanyun.net/
-
蓝耘智算云控制台:https://cloud.lanyun.net/
-
AI Ping延迟测试:https://aiping.cn