在文档管理和长期归档领域,PDF/A 格式扮演着至关重要的角色。作为 ISO 标准化的 PDF 子集,PDF/A 专为电子文档的长期保存而设计,确保文档在未来数十年内仍能被正确查看和打印。与普通 PDF 不同,PDF/A 文件必须是自包含的,所有字体、颜色配置和必要的显示信息都必须嵌入到文件中,不能依赖外部资源。
本文将详细介绍如何使用 Spire.PDF for Python 库将普通 PDF 转换为 PDF/A 格式。我们将涵盖基本转换流程、不同合规级别的选择、以及实际应用场景中的最佳实践,帮助你构建符合档案管理要求的文档解决方案。
环境准备
在开始之前,你需要安装 Spire.PDF for Python 库。可以使用 pip 命令进行安装:
bash
pip install Spire.PDF安装完成后,你就可以在 Python 项目中使用该库来操作 PDF 文档并执行 PDF/A 转换操作了。
PDF/A 的应用场景
在实际工作中,PDF/A 转换有多种典型应用场景:
- 法律文档归档:法院判决书、合同等法律文件需要长期保存且不可篡改
- 政府档案管理:政府部门需要将大量纸质文档数字化后进行标准化归档
- 医疗记录保存:病历、检查报告等医疗文档需要满足法规要求的保存期限
- 财务审计材料:财务报表、审计报告等需要长期保存以备查阅
- 学术研究资料:论文、研究报告等学术成果需要确保长期可访问性
- 企业知识管理:公司重要文档需要标准化存储以便未来检索和使用
PDF/A 有多个合规级别,其中最常见的包括:
- PDF/A-1b:最基本的合规级别,确保文档视觉上可重现
- PDF/A-2b:支持更多现代特性,如透明度和 JPEG2000 压缩
- PDF/A-3b:允许嵌入任意文件格式(如 XML、CSV)
Spire.PDF for Python 提供了 PdfStandardsConverter 类来实现这些转换,让你能够轻松地将普通 PDF 转换为符合档案标准的格式。
基本的 PDF 转 PDF/A 转换
最简单的转换方式是使用 PdfStandardsConverter 类直接将现有 PDF 文件转换为 PDF/A 格式。以下示例展示了如何完成这一基本任务:
python
from spire.pdf.common import *
from spire.pdf import *
def ConvertToPDFA():
"""将普通 PDF 转换为 PDF/A 格式"""
inputFile = "/示例文档.pdf"
outputFile = "ToPDFA_A1B.pdf"
# 创建标准转换器
converter = PdfStandardsConverter(inputFile)
# 转换为 PDF/A-1B 格式
converter.ToPdfA1B(outputFile)
print(f"PDF/A 文件已保存至: {outputFile}")
if __name__ == "__main__":
ConvertToPDFA()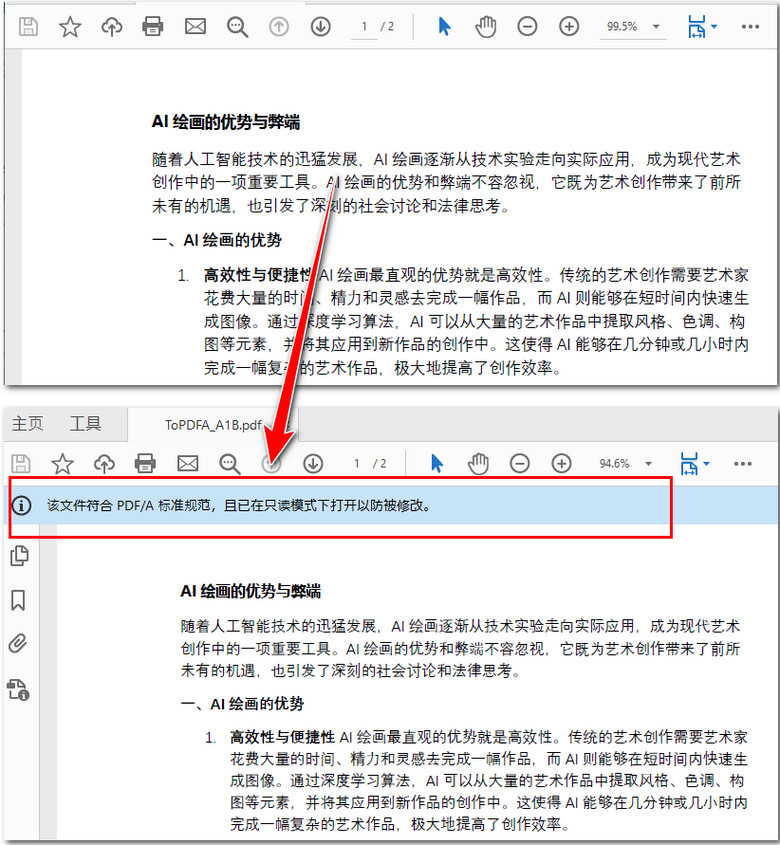
在这个示例中,我们使用了 PdfStandardsConverter 类的 ToPdfA1B() 方法来完成转换。这个方法会自动处理所有必要的操作,包括字体嵌入、颜色空间转换和元数据添加,以确保生成的文件符合 PDF/A-1B 标准。
这种方法的优点是简单直接,只需两行核心代码即可完成转换。适合用于批量处理已有的 PDF 文档,将其转换为符合归档要求的格式。
从新创建的 PDF 生成 PDF/A
如果你是从头开始创建 PDF 文档,并希望直接生成 PDF/A 格式的文件,可以采用先创建临时 PDF 再转换的方法。以下示例展示了完整的流程:
python
from spire.pdf.common import *
from spire.pdf import *
def CreatePDFFromScratchAndConvertToPDFA():
"""创建新 PDF 并转换为 PDF/A 格式"""
outputFile1 = "/output/TempDocument.pdf"
outputFile2 = "/output/FinalPDFA1B.pdf"
imageFile = "/Logo1.png"
# 创建新的 PDF 文档
doc = PdfNewDocument()
# 添加 A4 页面并设置边距
page = doc.Pages.Add(PdfPageSize.A4(), PdfMargins(40.0))
# 获取页面宽度
pageWidth = page.Canvas.ClientSize.Width
y = 0.0
# 绘制标题
y = y + 5
brush = PdfSolidBrush(PdfRGBColor(Color.get_Black()))
font = PdfTrueTypeFont("Arial", 16.0, PdfFontStyle.Bold, True)
format = PdfStringFormat(PdfTextAlignment.Center)
format.CharacterSpacing = 1
text = "AI Integration Module Introduction"
page.Canvas.DrawString(text, font, brush, pageWidth / 2, y, format)
size = font.MeasureString(text, format)
y = y + size.Height + 6
# 绘制图片
image = PdfImage.FromFile(imageFile)
page.Canvas.DrawImage(image, PointF(pageWidth - image.PhysicalDimension.Width, y))
imageLeftSpace = pageWidth - image.PhysicalDimension.Width - 2
imageBottom = image.PhysicalDimension.Height + y
# 绘制参考信息
font3 = PdfTrueTypeFont("Arial", 9.0, PdfFontStyle.Regular, True)
format3 = PdfStringFormat()
format3.ParagraphIndent = font3.Size * 2
format3.MeasureTrailingSpaces = True
format3.LineSpacing = font3.Size * 1.5
text1 = "(The sample text was made by "
text2 = "Gemini"
text3 = ", an AI module of Google.)"
page.Canvas.DrawString(text1, font3, brush, 0.0, y, format3)
size = font3.MeasureString(text1, format3)
x1 = size.Width
format3.ParagraphIndent = 0.0
font4 = PdfTrueTypeFont("Arial", 9.0, PdfFontStyle.Underline, True)
brush3 = PdfBrushes.get_Blue()
page.Canvas.DrawString(text2, font4, brush3, x1, y, format3)
size = font4.MeasureString(text2, format3)
x1 = x1 + size.Width
page.Canvas.DrawString(text3, font3, brush, x1, y, format3)
y = y + size.Height
# 绘制正文内容
format4 = PdfStringFormat()
with open("/input/Technical Specification AI Integration Module.txt", 'r', encoding='utf-8') as f:
text = f.read()
font5 = PdfTrueTypeFont("Arial", 10.0, PdfFontStyle.Regular, True)
format4.LineSpacing = font5.Size * 1.5
textLayouter = PdfStringLayouter()
imageLeftBlockHeight = imageBottom - y
result = textLayouter.Layout(text, font5, format4, SizeF(imageLeftSpace, imageLeftBlockHeight))
if result.ActualSize.Height < imageBottom - y:
imageLeftBlockHeight = imageLeftBlockHeight + result.LineHeight
result = textLayouter.Layout(text, font5, format4, SizeF(imageLeftSpace, imageLeftBlockHeight))
for line in result.Lines:
page.Canvas.DrawString(line.Text, font5, brush, 0.0, y, format4)
y = y + result.LineHeight
textWidget = PdfTextWidget(result.Remainder, font5, brush)
textLayout = PdfTextLayout()
textLayout.Break = PdfLayoutBreakType.FitPage
textLayout.Layout = PdfLayoutType.Paginate
bounds = RectangleF(PointF(0.0, y), page.Canvas.ClientSize)
textWidget.StringFormat = format4
textWidget.Draw(page, bounds, textLayout)
# 保存临时文档到流
stream = Stream(outputFile1)
doc.Save(stream)
# 使用标准转换器转换为 PDF/A-1B
converter = PdfStandardsConverter(stream)
converter.ToPdfA1B(outputFile2)
# 关闭文档
doc.Close(True)
print(f"PDF/A-1B 文件已保存至: {outputFile2}")
if __name__ == "__main__":
CreatePDFFromScratchAndConvertToPDFA()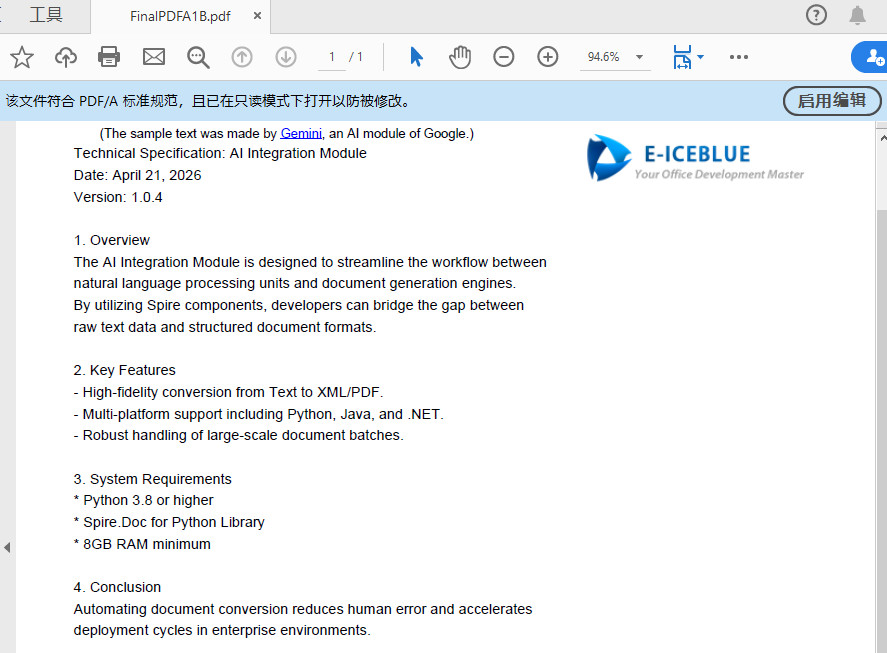
这个示例展示了从零开始创建 PDF 文档并转换为 PDF/A 格式的完整流程。关键步骤包括:
- 使用
PdfNewDocument()创建新文档 - 在页面上绘制文本、图片等内容
- 将文档保存到流(Stream)中
- 使用
PdfStandardsConverter从流读取并转换为 PDF/A
这种方法特别适合用于生成需要长期保存的报表、证书或官方文档,确保从创建之初就符合归档标准。
实用技巧与高级应用
封装 PDF/A 转换工具类
在实际项目中,你可能需要灵活地进行 PDF/A 转换。以下是一个实用的工具类,展示了如何封装这些功能:
python
from spire.pdf.common import *
from spire.pdf import *
import os
class PDFAConverter:
"""PDF/A 转换工具类"""
def __init__(self):
"""初始化"""
pass
def convert_file_to_pdfa1b(self, input_file, output_file):
"""将单个文件转换为 PDF/A-1B 格式"""
if not os.path.exists(input_file):
print(f"文件不存在: {input_file}")
return False
try:
converter = PdfStandardsConverter(input_file)
converter.ToPdfA1B(output_file)
print(f"✓ 转换成功: {os.path.basename(input_file)} -> PDF/A-1B")
return True
except Exception as e:
print(f"✗ 转换失败: {os.path.basename(input_file)} - {str(e)}")
return False
def convert_file_to_pdfa2b(self, input_file, output_file):
"""将单个文件转换为 PDF/A-2B 格式"""
if not os.path.exists(input_file):
print(f"文件不存在: {input_file}")
return False
try:
converter = PdfStandardsConverter(input_file)
converter.ToPdfA2B(output_file)
print(f"✓ 转换成功: {os.path.basename(input_file)} -> PDF/A-2B")
return True
except Exception as e:
print(f"✗ 转换失败: {os.path.basename(input_file)} - {str(e)}")
return False
def convert_file_to_pdfa3b(self, input_file, output_file):
"""将单个文件转换为 PDF/A-3B 格式"""
if not os.path.exists(input_file):
print(f"文件不存在: {input_file}")
return False
try:
converter = PdfStandardsConverter(input_file)
converter.ToPdfA3B(output_file)
print(f"✓ 转换成功: {os.path.basename(input_file)} -> PDF/A-3B")
return True
except Exception as e:
print(f"✗ 转换失败: {os.path.basename(input_file)} - {str(e)}")
return False
def batch_convert_folder(self, input_folder, output_folder,
pdfa_level="A1B"):
"""批量转换文件夹中的所有 PDF 文件"""
if not os.path.exists(input_folder):
print(f"输入文件夹不存在: {input_folder}")
return
# 创建输出文件夹
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 查找所有 PDF 文件
pdf_files = [f for f in os.listdir(input_folder)
if f.lower().endswith('.pdf')]
if not pdf_files:
print(f"在 {input_folder} 中未找到 PDF 文件")
return
print(f"找到 {len(pdf_files)} 个 PDF 文件,开始转换为 PDF/A-{pdfa_level}...")
success_count = 0
fail_count = 0
for pdf_file in pdf_files:
input_path = os.path.join(input_folder, pdf_file)
base_name = os.path.splitext(pdf_file)[0]
output_path = os.path.join(output_folder, f"{base_name}_PDFA.pdf")
# 根据选择的级别进行转换
if pdfa_level.upper() == "A1B":
if self.convert_file_to_pdfa1b(input_path, output_path):
success_count += 1
else:
fail_count += 1
elif pdfa_level.upper() == "A2B":
if self.convert_file_to_pdfa2b(input_path, output_path):
success_count += 1
else:
fail_count += 1
elif pdfa_level.upper() == "A3B":
if self.convert_file_to_pdfa3b(input_path, output_path):
success_count += 1
else:
fail_count += 1
print(f"\n转换完成!")
print(f"成功: {success_count} 个文件")
print(f"失败: {fail_count} 个文件")
print(f"输出目录: {output_folder}")
def validate_pdfa_compliance(self, pdf_file):
"""验证文件是否符合 PDF/A 标准(基础检查)"""
if not os.path.exists(pdf_file):
print(f"文件不存在: {pdf_file}")
return False
try:
doc = PdfDocument()
doc.LoadFromFile(pdf_file)
# 检查文档属性
info = doc.DocumentInformation
# 基本检查:文件大小不为空
file_size = os.path.getsize(pdf_file)
doc.Close()
print(f"文件: {os.path.basename(pdf_file)}")
print(f"大小: {file_size} 字节")
print(f"页数: {doc.Pages.Count if hasattr(doc, 'Pages') else 'N/A'}")
return True
except Exception as e:
print(f"验证失败: {str(e)}")
return False
def main():
converter = PDFAConverter()
# 示例 1: 转换单个文件为 PDF/A-1B
converter.convert_file_to_pdfa1b(
"./Documents/Report.pdf",
"./Output/Report_PDFA1B.pdf"
)
# 示例 2: 转换单个文件为 PDF/A-2B(支持更多特性)
converter.convert_file_to_pdfa2b(
"./Documents/Presentation.pdf",
"./Output/Presentation_PDFA2B.pdf"
)
# 示例 3: 批量转换文件夹中的所有 PDF
converter.batch_convert_folder(
"./Documents/Archive",
"./Output/PDFA_Archive",
pdfa_level="A1B"
)
# 示例 4: 验证转换后的文件
converter.validate_pdfa_compliance("./Output/Report_PDFA1B.pdf")
if __name__ == "__main__":
main()这个工具类封装了多种 PDF/A 转换功能,支持不同的合规级别(A1B、A2B、A3B),并提供批量转换和基础验证功能。通过实例化这个类,你可以轻松地在项目中复用这些功能。
常见应用场景示例
场景 1:法律文档归档
python
def ArchiveLegalDocuments():
"""归档法律文档为 PDF/A 格式"""
converter = PDFAConverter()
# 将法院判决书转换为 PDF/A-1B(最严格的合规级别)
converter.batch_convert_folder(
"./Legal/Court_Rulings/2024",
"./Archive/Legal_PDFA1B",
pdfa_level="A1B"
)场景 2:医疗记录长期保存
python
def ArchiveMedicalRecords():
"""归档医疗记录为 PDF/A 格式"""
converter = PDFAConverter()
# 将患者病历转换为 PDF/A-2B(支持更多现代特性)
converter.batch_convert_folder(
"./Medical/Patient_Records",
"./Archive/Medical_PDFA2B",
pdfa_level="A2B"
)场景 3:财务报告归档
python
def ArchiveFinancialReports():
"""归档财务报告为 PDF/A 格式"""
converter = PDFAConverter()
# 将年度财务报告转换为 PDF/A-1B
converter.convert_file_to_pdfa1b(
"./Finance/Annual_Report_2024.pdf",
"./Archive/Annual_Report_2024_PDFA.pdf"
)PDF/A 合规级别选择指南
不同的应用场景需要选择不同的 PDF/A 合规级别:
PDF/A-1b(基本级别)
- 适用于:法律文档、政府档案、历史记录
- 特点:确保文档视觉上可重现,最广泛的兼容性
- 限制:不支持透明度、图层、加密等特性
PDF/A-2b(中级级别)
- 适用于:技术文档、包含图表的报告、现代办公文档
- 特点:支持透明度、JPEG2000 压缩、数字签名
- 优势:更好的压缩率,更小的文件大小
PDF/A-3b(高级级别)
- 适用于:需要嵌入原始数据的文档,如发票、表单
- 特点:允许嵌入任意文件格式(XML、CSV、Excel 等)
- 应用:电子发票系统、数据密集型文档
最佳实践与注意事项
转换前的准备工作
- 检查字体:确保所有使用的字体都可以嵌入到 PDF 中
- 优化图片:压缩高分辨率图片以减小文件大小
- 移除加密:PDF/A 不允许加密,转换前需要解密
- 清理元数据:添加适当的文档信息和元数据
性能优化建议
- 批量处理:对于大量文件,考虑分批处理以避免内存问题
- 临时文件管理:转换过程中产生的临时文件应及时清理
- 错误处理:实现完善的异常处理机制,记录转换失败的详细信息
常见问题与解决方案
问题 1:转换后文件体积显著增大
解决方案:这是因为字体和其他资源被嵌入到文件中。可以通过优化字体子集化和图片压缩来减小文件大小。
问题 2:某些内容在转换后丢失
解决方案:检查源 PDF 是否使用了 PDF/A 不支持的特性(如透明度、加密)。可能需要调整源文档或使用更高级别的 PDF/A 标准。
问题 3:转换失败,提示字体问题
解决方案:确保所有字体都是可嵌入的。某些受版权保护的字体可能不允许嵌入,需要替换为其他字体。
总结
本文介绍了使用 Spire.PDF for Python 将普通 PDF 转换为 PDF/A 格式的多种方法,涵盖了从现有文件转换、新文档生成到封装工具类进行批量处理的实用技术。通过合理选择 PDF/A-1B、2B 或 3B 等合规级别,并注意字体嵌入与兼容性,您可以轻松应对法律、医疗、财务及政府档案等不同场景的长期归档需求,确保重要文档在未来数十年内始终保持其完整性与可访问性。