前言
掌握Python的基础语法只是编程旅程的起点。当你开始处理复杂的文本匹配、追求更优雅的代码组织方式,或者需要手动实现高效的数据存储与查找时,进阶知识便成了绕不开的必修课。
Python正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式,
1、比如:检索一个串是否含有某种子串(检索)
2、比如:匹配的子串做替换(替换)
3、比如:从一个串中取出符合某个条件的子串(提取)
模式:一种特定的字符串模式,这个模式是通过一些特殊的符号组成的。
正则表达式并不是Python所特有的,在Java、PHP、Go以及JavaScript等语言中都是支持正则表达式的。
正则表达式的功能
数据验证(表单验证、如手机、邮箱、IP地址)
数据检索(数据检索、数据抓取) => 爬虫功能
数据隐藏(135****6235 王先生)
数据过滤(论坛敏感关键词过滤)
re模块的介绍
在Python中需要通过正则表达式对字符串进行匹配时,可使用re模块
re模块使用三步走
python
# 第一步:导入re模块
import re
# 第二步:使用match方法进行匹配操作
result = re.match(pattern正则表达式, string要匹配的字符串, flags=0)
#flags : 可选,表示匹配模式,比如忽略大小写,多行模式等
# 第三步:如果数据匹配成功,使用group方法来提取数据
result.group()
python
def search():
# 扫描字符返回第一个成功的匹配 def search(pattern, string, flags=0)
import re
result = re.search("\d.*", "city:1beijing2.shanghai") # "\d.*": 数字开头,任意多个字符字符结尾
# result = re.search(".\d.", "cityp.1.beijing2.shanghai")
if result:
print(result.group())
else:
print('没有匹配到')
pass
if __name__ == '__main__':
search()
正则表达式编写
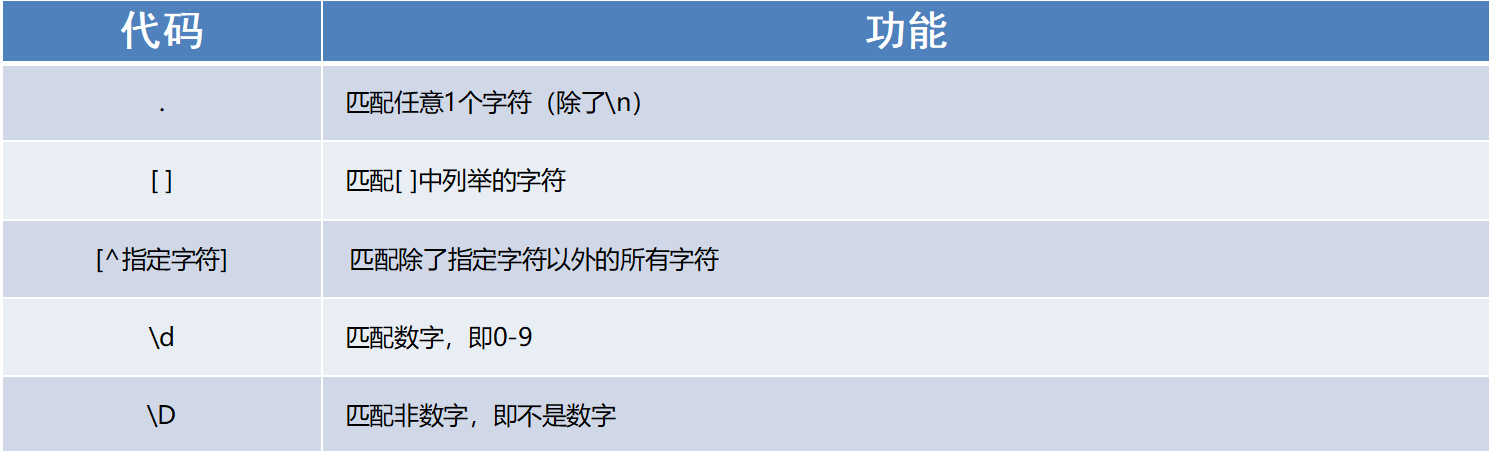
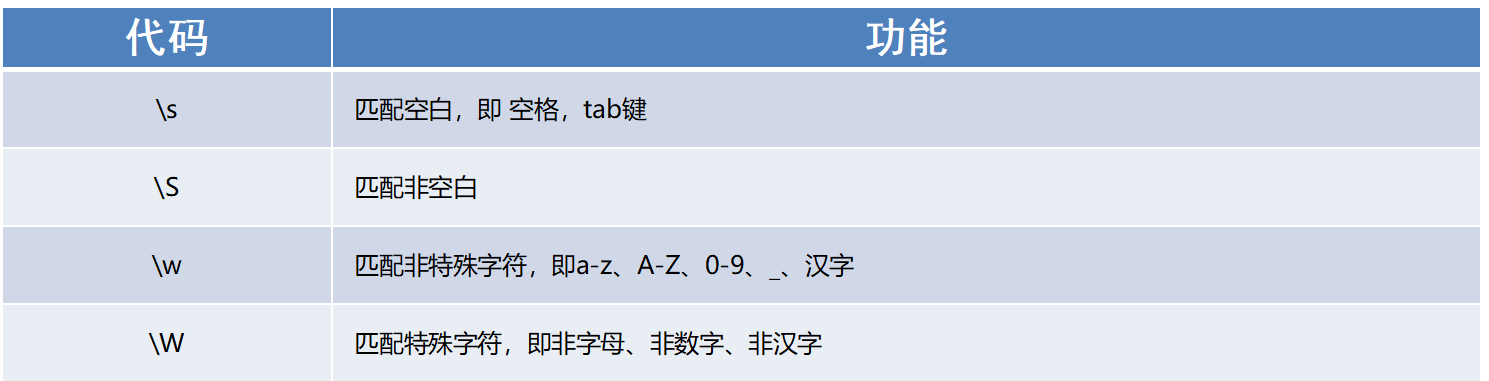
能够使用re模块匹配单个字符
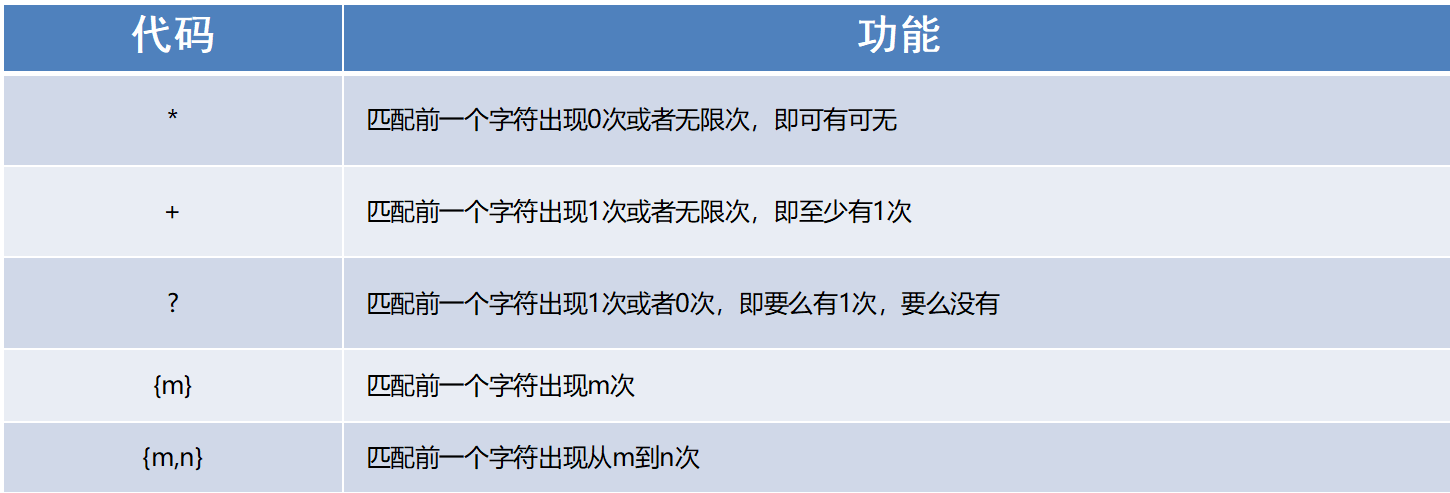
能够使用re模块匹配多个字符
能够使用re模块匹配指定字符串开头或者结尾

能够使用re模块提取分组数据

Python其他高级语法
With语句和上下文管理器
with语句
上下文管理器with语句:该机制简单、更安全的处理资源和异常
特点:with 语句执行完成后,自动调用关闭文件操作,即使出现异常也会自动调用关闭文件操作
python
# 1、以写的方式打开文件
with open("1.txt", "w") as f:
# 2、读取文件内容
f.write("hello world")
上下文管理器
一个类只要实现了__enter__()和__exit__()这个两个方法,通过该类创建的对象我们就称之为上下文管理器
上下文管理器可以使用 with 语句
- with语句之所以这么强大,背后是由上下文管理器做支撑的
- 刚才使用 open 函数创建的文件对象就是就是一个上下文管理器对象。
- 大白话:with 管理的对象就是上下文管理器; with xxx as 后面的操作的对象就是被管理的对象
定义上下文管理器类,模拟文件操作
- 定义一个File类,实现 enter () 和 exit()方法
- 然后使用 with 语句来完成操作文件
python
class MyFile:
def __init__(self, file_name, file_mode):
self.file_name = file_name
self.file_mode = file_mode # 修正拼写
self.fp = None
def __enter__(self):
print('这是上文')
self.fp = open(self.file_name, self.file_mode)
return self.fp
def __exit__(self, exc_type, exc_val, exc_tb):
print('这是下文')
if self.fp: # 安全关闭
self.fp.close()
# 返回 False(默认)让异常继续传播,也可以根据需要处理 exc_type
if __name__ == '__main__':
with MyFile('./1.txt', 'r') as f:
filedata = f.read()
print('filedata-->', filedata)- 一个类只要实现了__enter__()和__exit__()这个两个方法,通过该类创建的对象我们就称之为上下文管理器
- #_enter__表示上文方法,需要返回一个操作文件对象
- #__exit__表示下文方法,with语句执行完成会自动执行,即使出现异常也会执行该方法
Python生成器
根据程序员制定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,可以节约大量的内存。
生成器推导式
python
# 创建生成器
# 注意1:括号()代表 这是一个生成器,不是元组
# 注意2:括号()里面写的是数据的生成规则,返回一个对象,
# 对象内不是存的数据,而是产生数据的规则
my_generator = (i * 2 for i in range(5)) # 根据注意2
print(my_generator)
# next获取生成器下一个值
# value = next(my_generator)
# print(value)
# 遍历生成器
for value in my_generator:
print(value)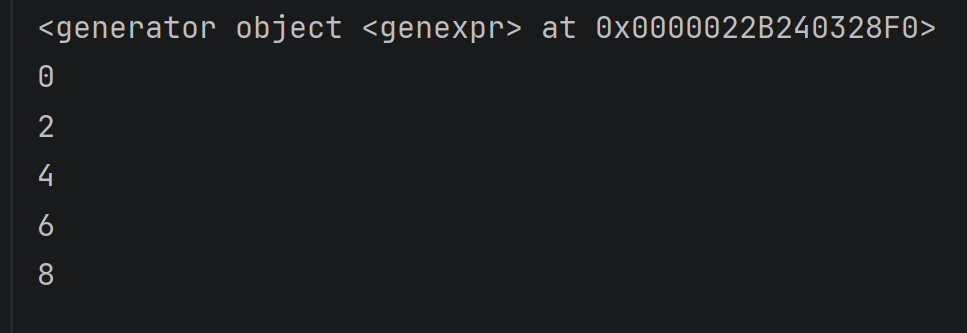
Property属性
property属性的介绍
负责把一个方法当做属性进行使用,这样做可以简化代码使用。
定义property属性有两种方式:① 装饰器方式 ② 类属性方式
python
class Person(object):
def __init__(self):
self.__age = 0
# 获取属性
@property
def age(self):
return self.__age
# 修改属性
@age.setter
def age(self, new_age):
self.__age = new_age
if __name__ == '__main__':
p1 = Person()
print(p1.age)
p1.age = 100
print(p1.age)
装饰器方式:
@property 修饰获取值的方法
@方法名.setter 修饰设置值的方法
python
class Person(object):
def __init__(self):
self.__age = 0
def get_age(self):
"""当获取age属性的时候会执行该方法"""
return self.__age
def set_age(self, new_age):
"""当设置age属性的时候会执行该方法"""
self.__age = new_age
# 类属性方式的property属性
age = property(get_age, set_age)
if __name__ == '__main__':
p1 = Person()
print(p1.age)
p1.age = 100
print(p1.age)
类属性方式:
类属性 = property(获取值方法, 设置值方法)
链表
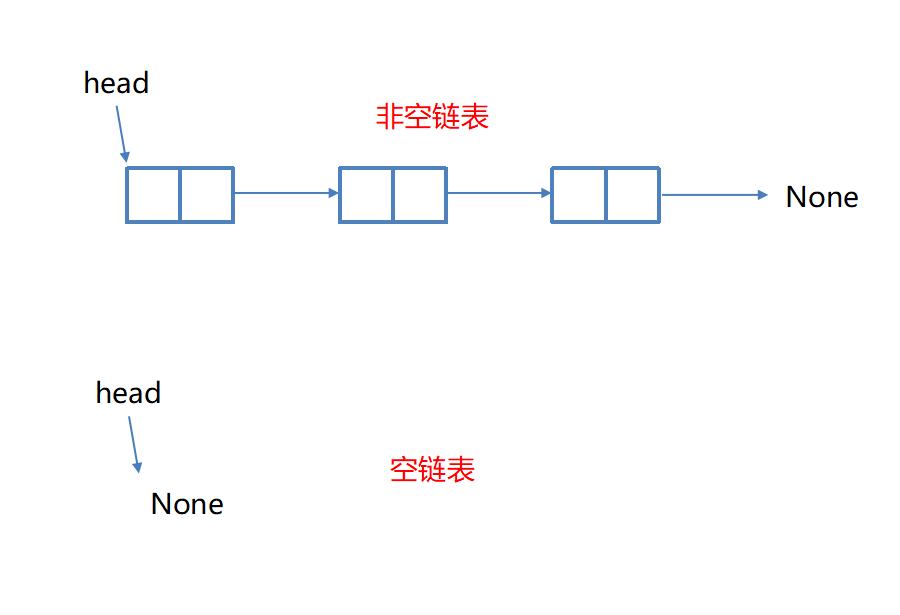
顺序表存储时需要连续的内存空间,当要扩充顺序表时会出现以下两种情况:
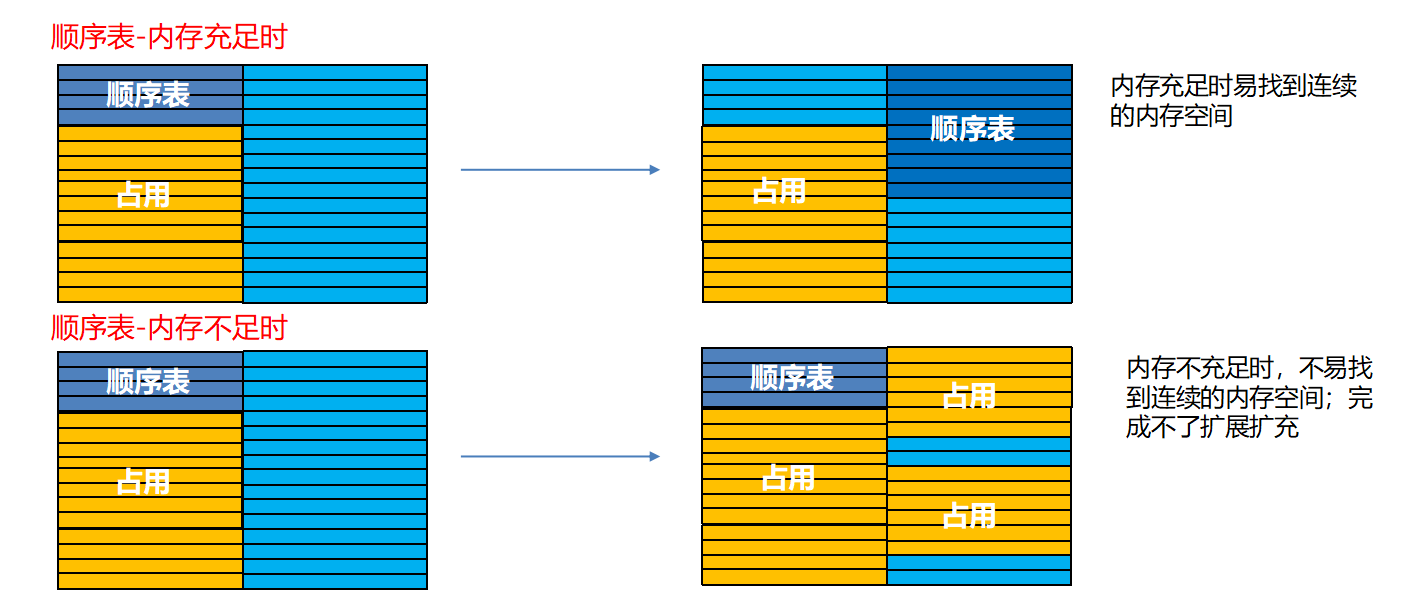
链表 不需要连续的存储空间

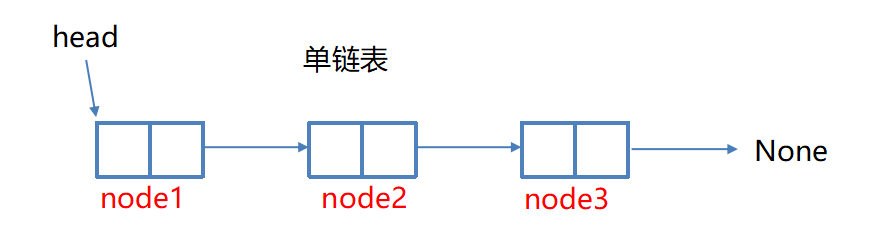
单链表(单向链表)是链表的一种形式,每个结点包含两个域:元素域和链接域 .
这个链接指向链表中的下一个结点 , 而最后一个结点的链接域则指向一个空值None
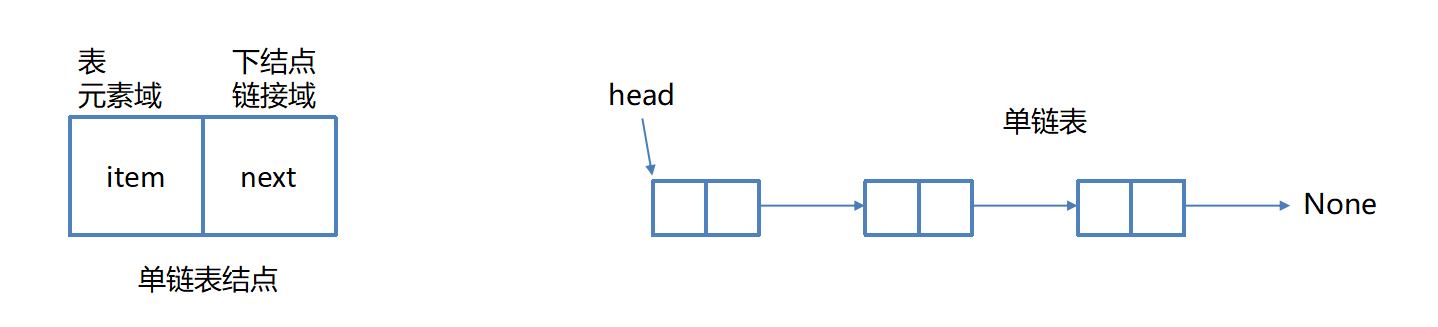
表元素域item用来存放具体的数据
链接域next用来存放下一个结点的位置
变量head指向链表的头结点(首结点)的位置,从head出发能找到表中的任意结点
结点对象SingleNode、链表对象SingLinkList
python
class Node(object):
"""链表结点实现"""
def __init__(self, item):
# item: 存放元素
self.item = item
# next: 标识下一个结点
self.next = None如果 node 是一个结点:
获取结点元素 : node.item
获取下一个结点 : node.next
python
class SingleLinkList(object):
"""单链表的实现"""
def __init__(self, node=None): # 调用时不传入 node 参数,则 node 默认为 None。
# 首结点
self.head = nodeis_empty(self) 链表是否为空
length(self) 链表长度
travel(self. ) 遍历整个链表
add(self, item) 链表头部添加元素
append(self, item) 链表尾部添加元素
insert(self, pos, item) 指定位置添加元素
remove(self, item) 删除节点
search(self, item) 查找节点是否存在
通过append(node) 方法不断添加元素 , 最终实现单链表
链表判空 , 长度 , 遍历
链表的判空
python
def is_empty(self):
"""判断链表是否为空"""
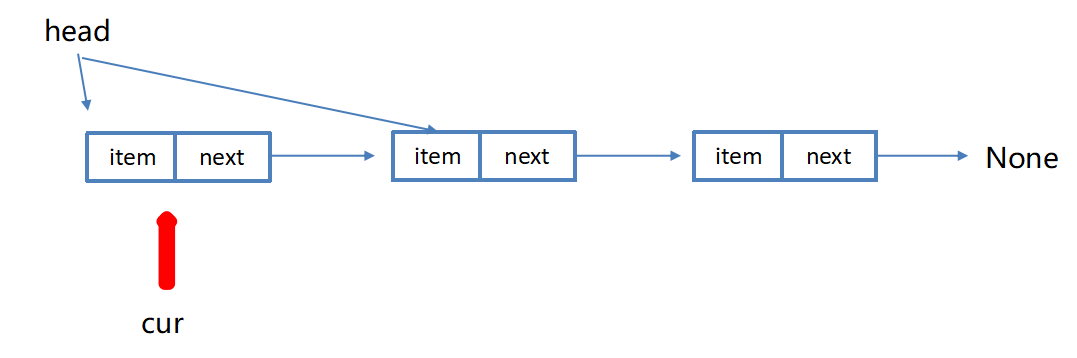
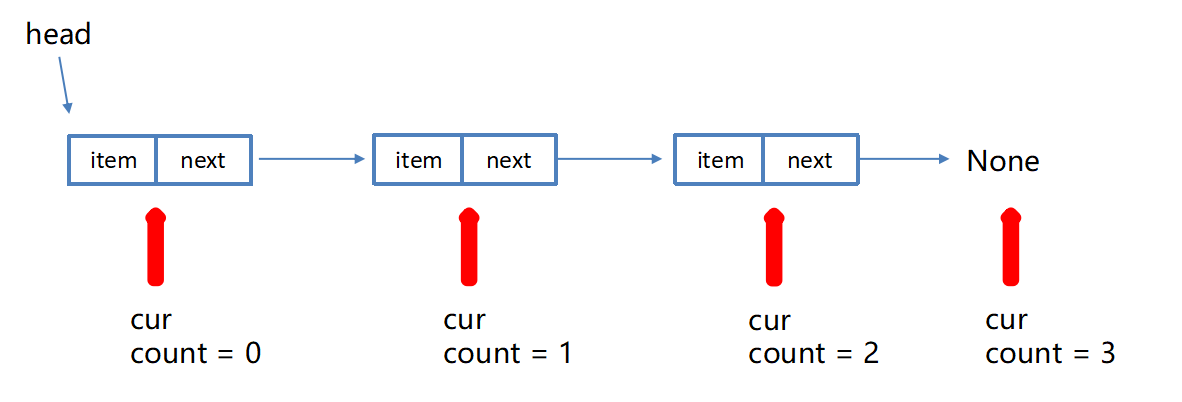
return self.head is None链表的长度测量
python
def length(self):
"""获取链表长度"""
cur = self.head # 游标,记录当前所在位置
count = 0 # 记录链表的长度
while cur is not None:
count += 1
cur = cur.next
return count链表的遍历
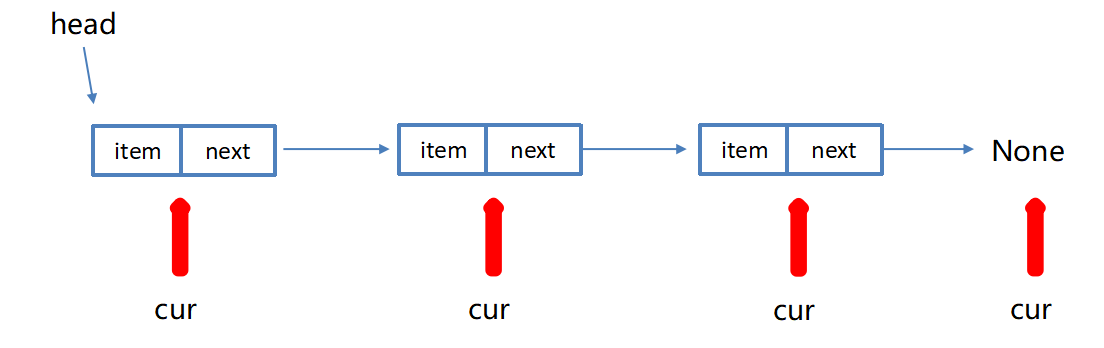
python
def travel(self):
"""遍历链表"""
cur = self.head
while cur is not None:
print(cur.item)
cur = cur.next链表增加节点
链表在头部增加结点
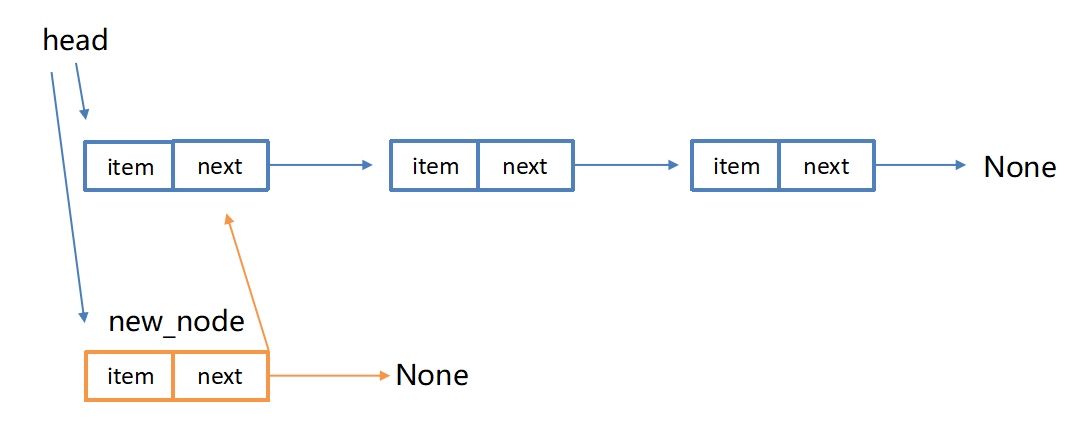
python
def add(self, item):
"""头部增加结点"""
node = SingleNode(item) # 新结点存储新数据
node.next = self.head
self.head = nodeappend(item) 链表尾部添加结点
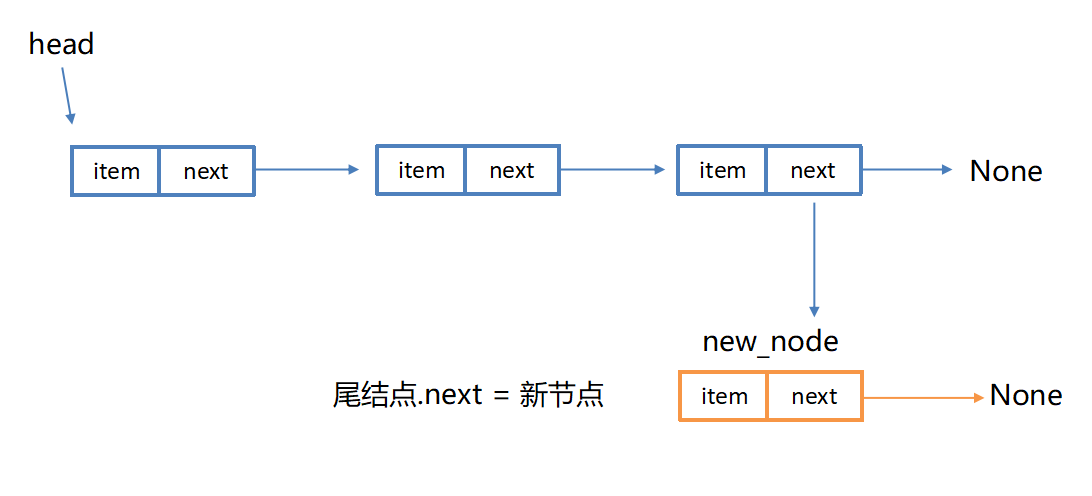
python
def append(self, item):
"""尾部增加结点"""
node = SingleNode(item) # 新结点存储新数据
if self.is_empty():
self.head = node
else:
cur = self.head
while cur.next is not None:
cur = cur.next
# 当前结点后面连接新结点
cur.next = nodeInsert(pos,item)在指定位置添加结点
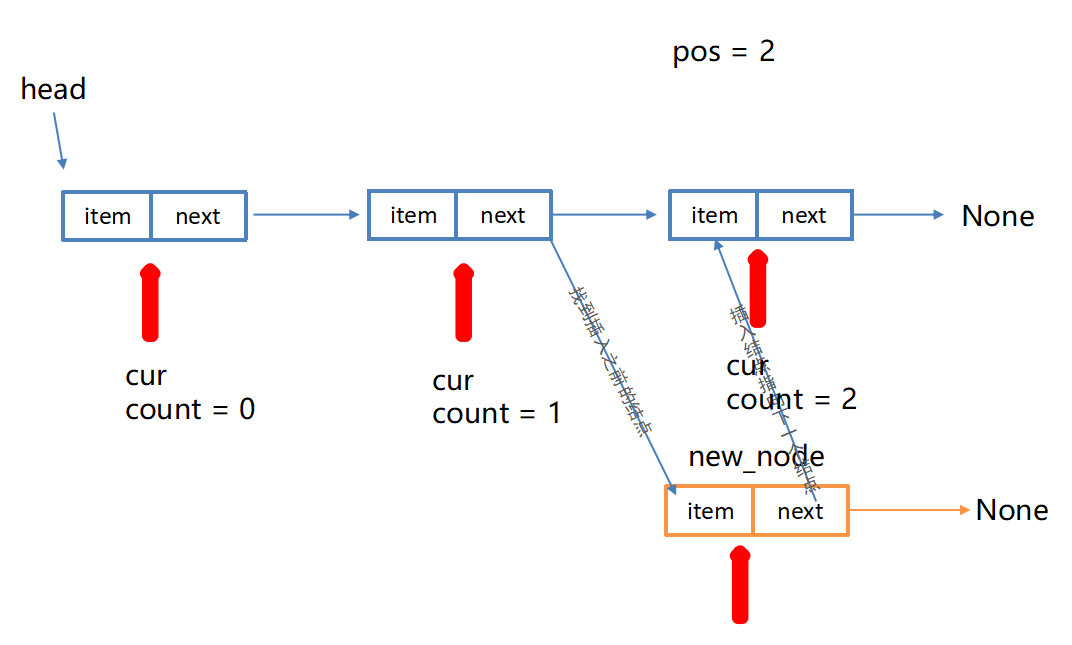
python
def insert(self, pos, item):
"""指定位置增加结点"""
# 头部添加新结点
if pos <= 0:
self.add(item)
# 尾部添加新结点
elif pos >= self.length():
self.append(item)
# 中间位置添加新结点
else:
cur = self.head # 游标
count = 0 # 计数
node = SingleNode(item) # 新结点
# 1. 找到插入位置的前一个结点
while count < pos - 1:
cur = cur.next
count += 1
# 2. 完成插入新结点
node.next = cur.next
cur.next = node链表删除和查找节点
链表删除节点
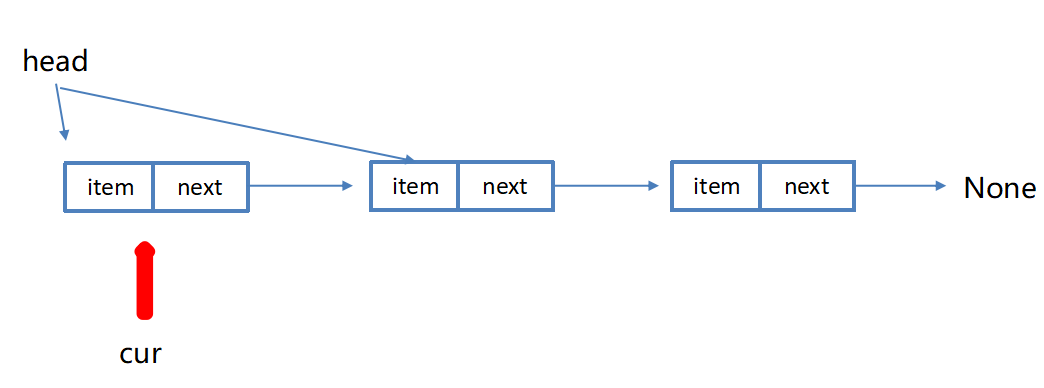
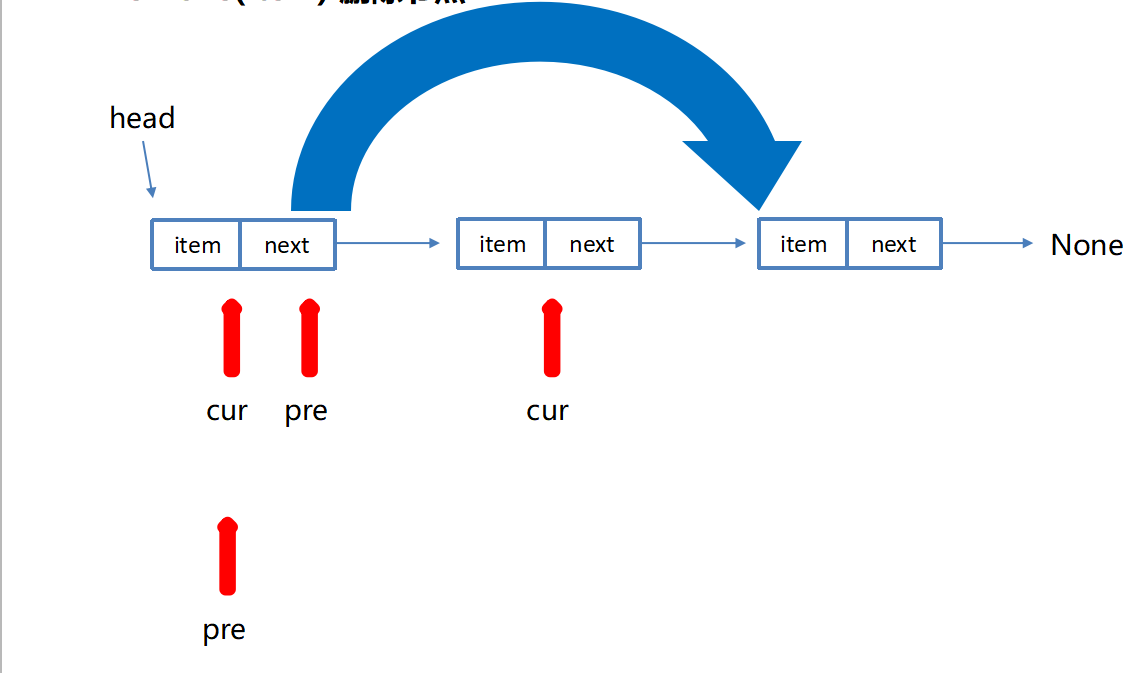
python
def remove(self, item):
"""删除结点"""
cur = self.head # 游标
pre = None # 辅助游标(指向前一个结点)
while cur is not None:
# 找到要删除的结点
if cur.item == item:
# 若删除的是头结点
if cur == self.head:
self.head = cur.next
else:
pre.next = cur.next
return
# 没有找到,继续向后移动
else:
pre = cur
cur = cur.nextsearch(item) 查找节点是否存在
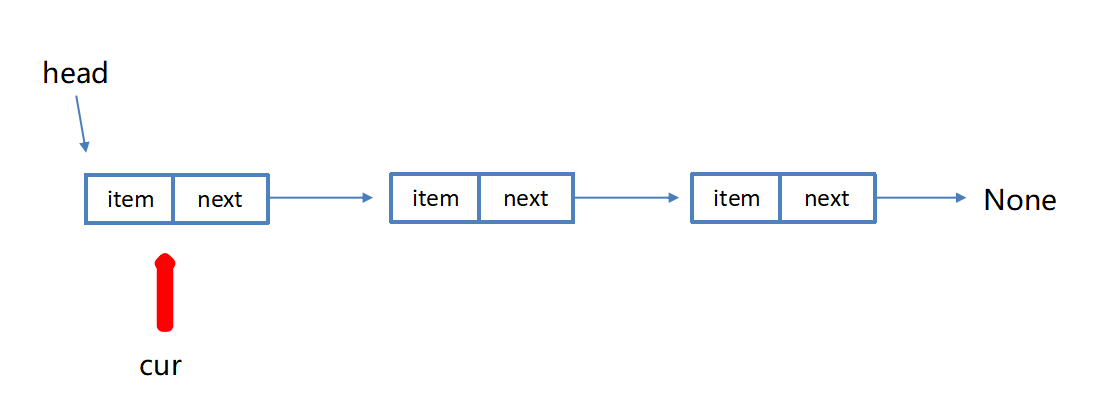
python
def search(self, item):
"""查找结点是否存在"""
cur = self.head # 游标
while cur is not None:
if cur.item == item:
return True
cur = cur.next
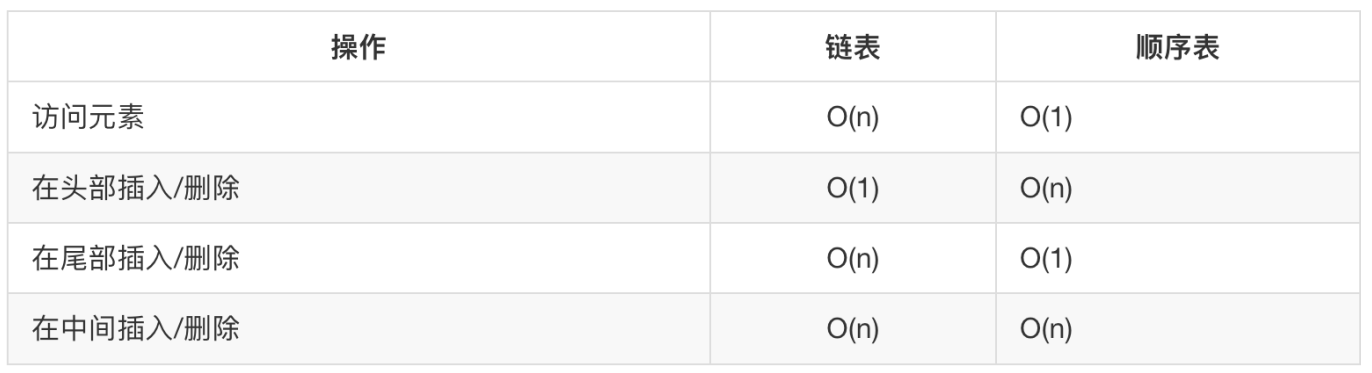
return False顺序表和链表的比较
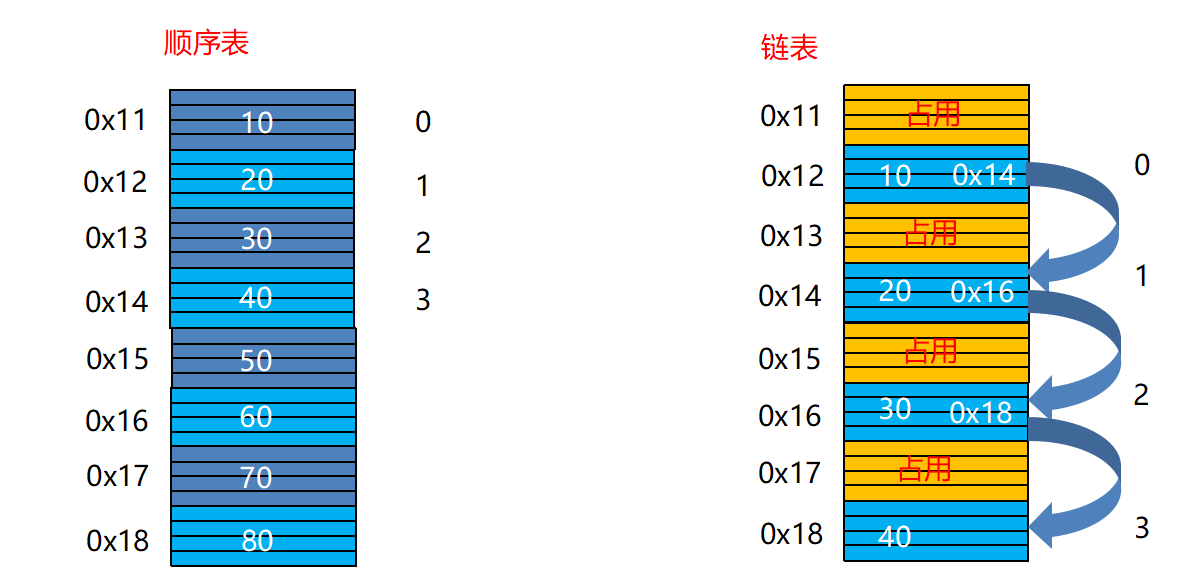
链表失去了顺序表随机读取的优点,链表由于增加了结点的连接域,空间开销比较大,但对存储空间的使用要相对灵活。
二叉树
树(英语:tree)就是一种非线性结构
它是用来模拟具有树状结构性质的数据集合. 它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做"树"是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的. 它具有以下的特点:
- 每个节点有零个或多个子节点
- 没有父节点的节点称为根节点
- 每一个非根节点有且只有一个父节点
- 除了根节点外,每个子节点可以分为多个不相交的子树
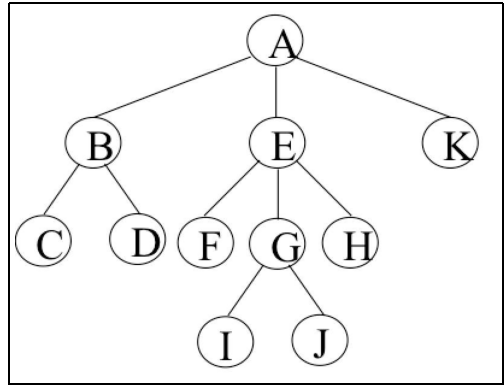
节点的度:一个节点含有的子节点的个数称为该节点的度
树的度:一棵树中,最大的节点的度称为树的度
叶节点或终端节点:度为零的节点
父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推
树的高度或深度:树中节点的最大层次
堂兄弟节点:父节点在同一层的节点互为堂兄弟
节点的祖先:从根到该节点所经分支上的所有节点
子孙:以某节点为根的子树中任一节点都称为该节点的子孙
森林:由m(m>=0)棵互不相交的树的集合称为森林
树的种类
无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树
有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树
有序树:
霍夫曼树(用于信息编码):带权路径最短的二叉树称为哈夫曼树或最优二叉树
B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多于两个的子树
二叉树:每个节点最多含有两个子树的树称为二叉树
完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二叉树的定义是所有叶节点都在最底层的完全二叉树
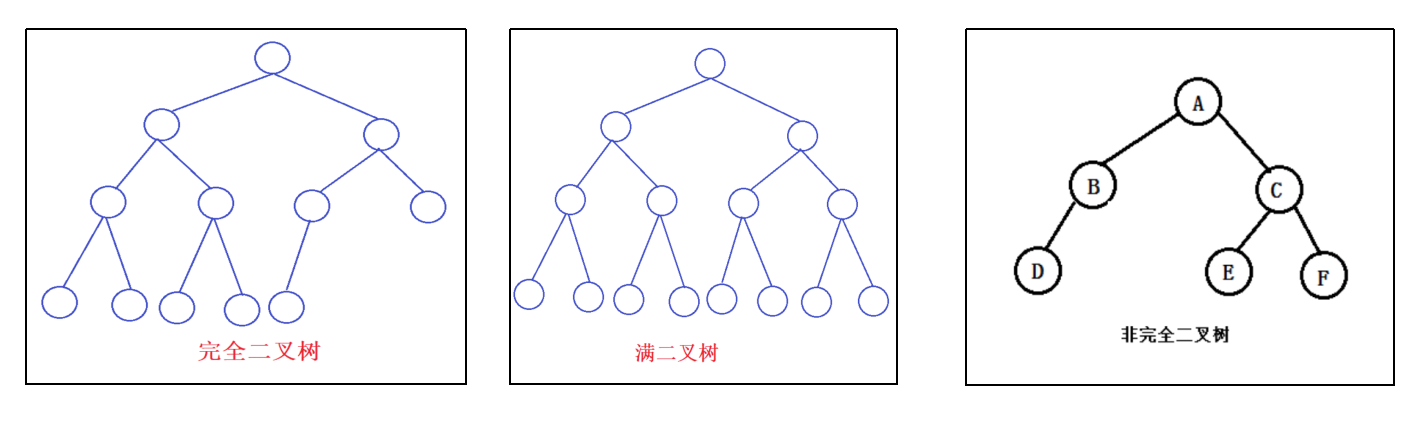
平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树
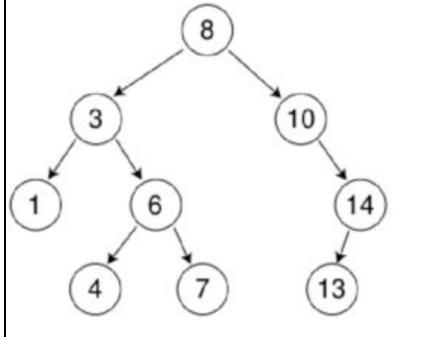
排序二叉树(二叉查找树(英语:Binary Search Tree),也称二叉搜索树、有序二叉树)
排序二叉树(BST)的要求:
1.若左子树不空,则左子树上所有节点的值均小于它的根节点的值
2.若右子树不空,则右子树上所有节点的值均大于它的根节点的值
3.左、右子树也分别为二叉排序树
排序二叉树包含空树
满二叉树:层次存储的时候,从左到右控制节点产生
平衡二叉树:防止树变成链表
排序二叉树:对数据排序,检索起来速度快。
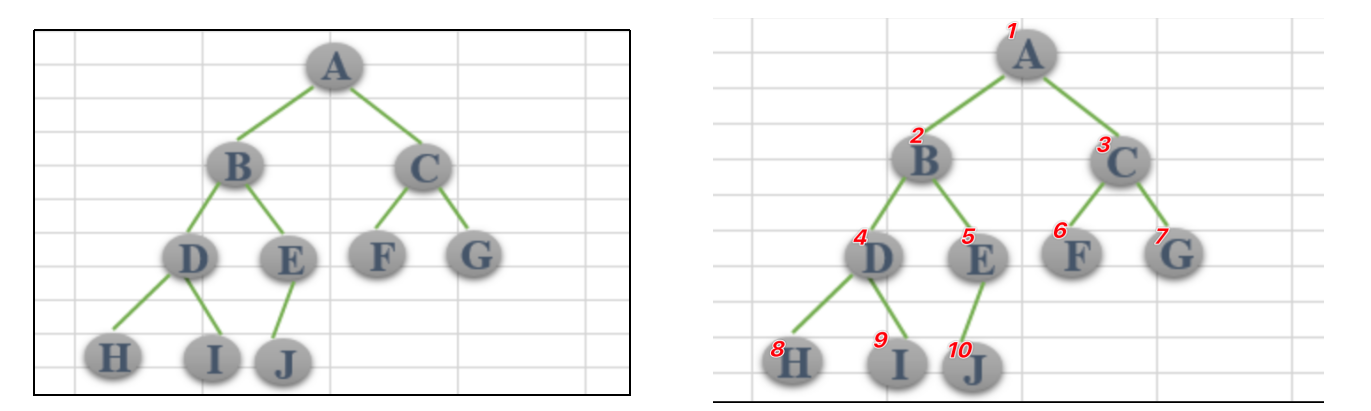
链式存储:由于对节点的个数无法掌握,常见树的存储表示都转换成二叉树进行处理,子节点个数最多为2
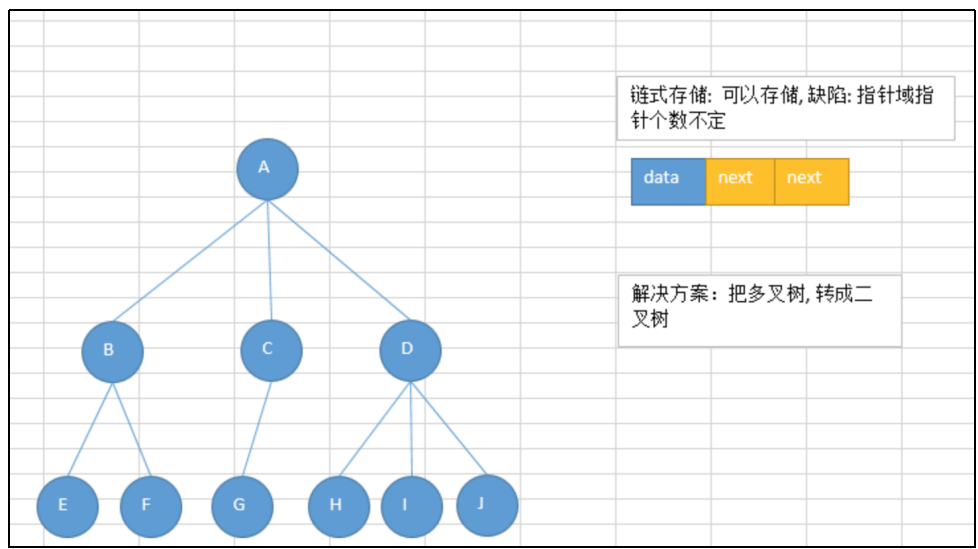
二叉树的性质

二叉树的广度优先遍历

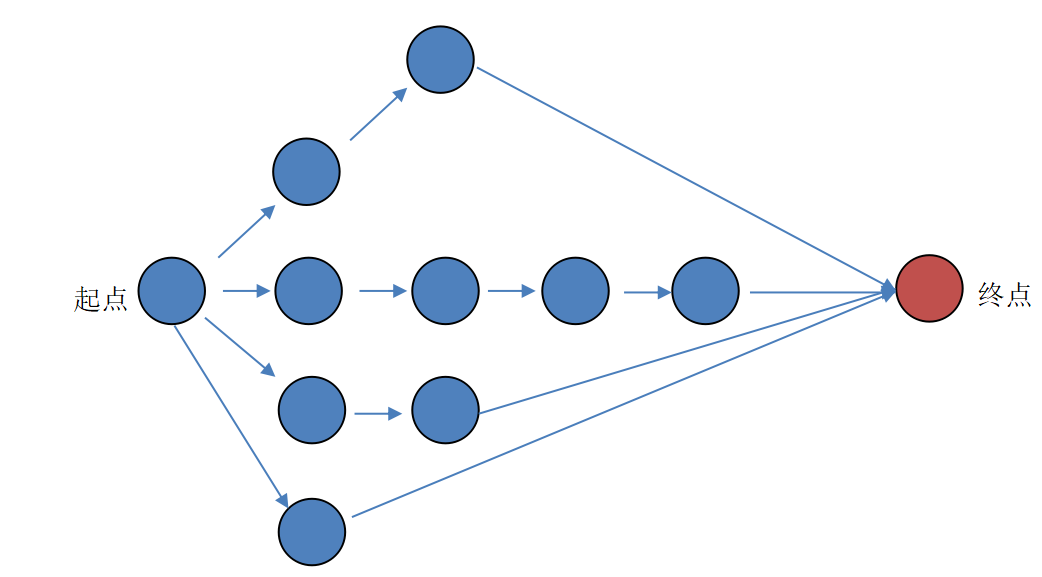
深度优先往往可以很快找到搜索路径:
比如:先找一个结点看看是不是终点,若不是继续往深层去找,直到找到终点。
中序,先序,后序属于深度优先算法
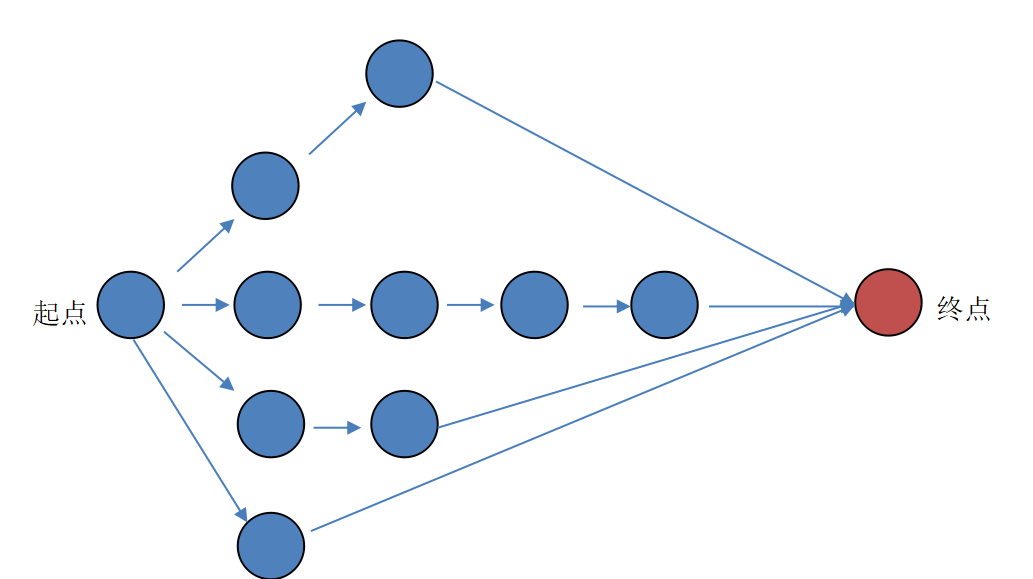
广度优先可以找到最短路径:
相当于层次遍历,先把第1层给遍历完,看有没有终点;再把第2层遍历完,看有没有重点。
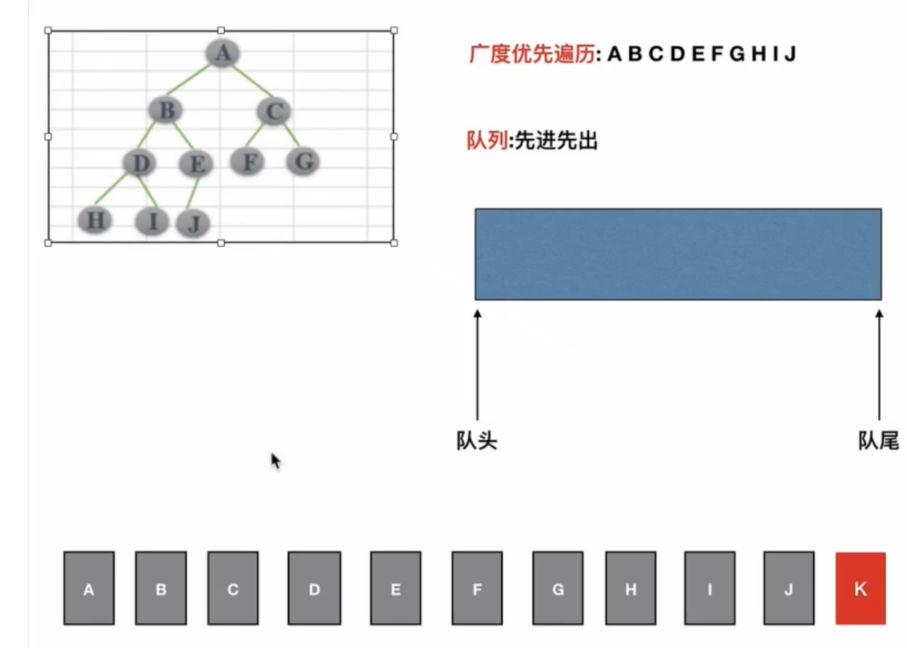
初始操作:
初始化队列、将根节点入队、准备加入到二叉树的新结点
重复执行:
获得并弹出队头元素
1、若当前结点的左右子结点不为空,则将其左右子节点入队列
2、若当前结点的左右子节点为空,则将新结点挂到为空的左子结点、或者右子节点
python
class Node(object):
"""二叉树结点实现"""
def __init__(self, item):
self.item = item
self.lchild = None # 左子树
self.rchild = None # 右子树
class BinaryTree(object):
"""二叉树的实现(基于队列的层次添加)"""
def __init__(self, node=None):
self.root = node
def add(self, item):
"""添加结点(层次遍历方式)"""
# 1. 树为空,把 item 设置成根结点
if self.root is None:
self.root = Node(item)
return
# 2. 准备队列,把根结点添加到队列
queue = [self.root]
while True:
# 3. 从队列中取出一个结点
node = queue.pop(0)
# 4-1. 若左子树为空,把新结点挂在左子树上,并返回;否则左子树加入队列
if node.lchild is None:
node.lchild = Node(item)
return
else:
queue.append(node.lchild)
# 4-2. 若右子树为空,把新结点挂在右子树上,并返回;否则右子树加入队列
if node.rchild is None:
node.rchild = Node(item)
return
else:
queue.append(node.rchild)总结
进阶之路没有终点,愿这份总结成为你继续探索Python深层奥秘的一块坚实跳板。