关键词:DeepFace.analyze、MediaPipe Pose 33 关键点、性别/年龄/族裔外貌、姿势分类、取景分类、SQLite ALTER TABLE 迁移、
gh.idayer.com镜像、enforce_detection=False误报修正
一、背景
上一篇 我们做了一个"自动给图打 ImageNet 标签"的本地图库浏览器。但 ImageNet 标签对"人物"几乎没区分力------所有有人的图都被分到 groom、suit、miniskirt 之类的衣物类里,搜不到"亚洲女性、约 30 岁、站姿、半身"这种维度。
这篇我们给图库里"图里的人"叠加结构化属性:
- DeepFace:性别、年龄、族裔外貌;
- MediaPipe PoseLandmarker:从 33 个人体关键点推姿势(站立/坐姿/双臂上举/插腰/抱臂...)和取景(全身/半身/上半身/仅面部)。
集成进上一篇的 image_indexer,前端加一排过滤器,能按这些维度组合检索。
声明 :种族/族裔识别在很多场景里有伦理争议。我把字段命名为
ethnic_appearance(族裔外貌 ),明示这是 DeepFace 基于像素的视觉判断,不是身份/国籍/血统。生产场景里用此功能前请评估法律和伦理风险。"C:\Users\86182\Desktop\MediaPipe\demo_image_indexer.py"
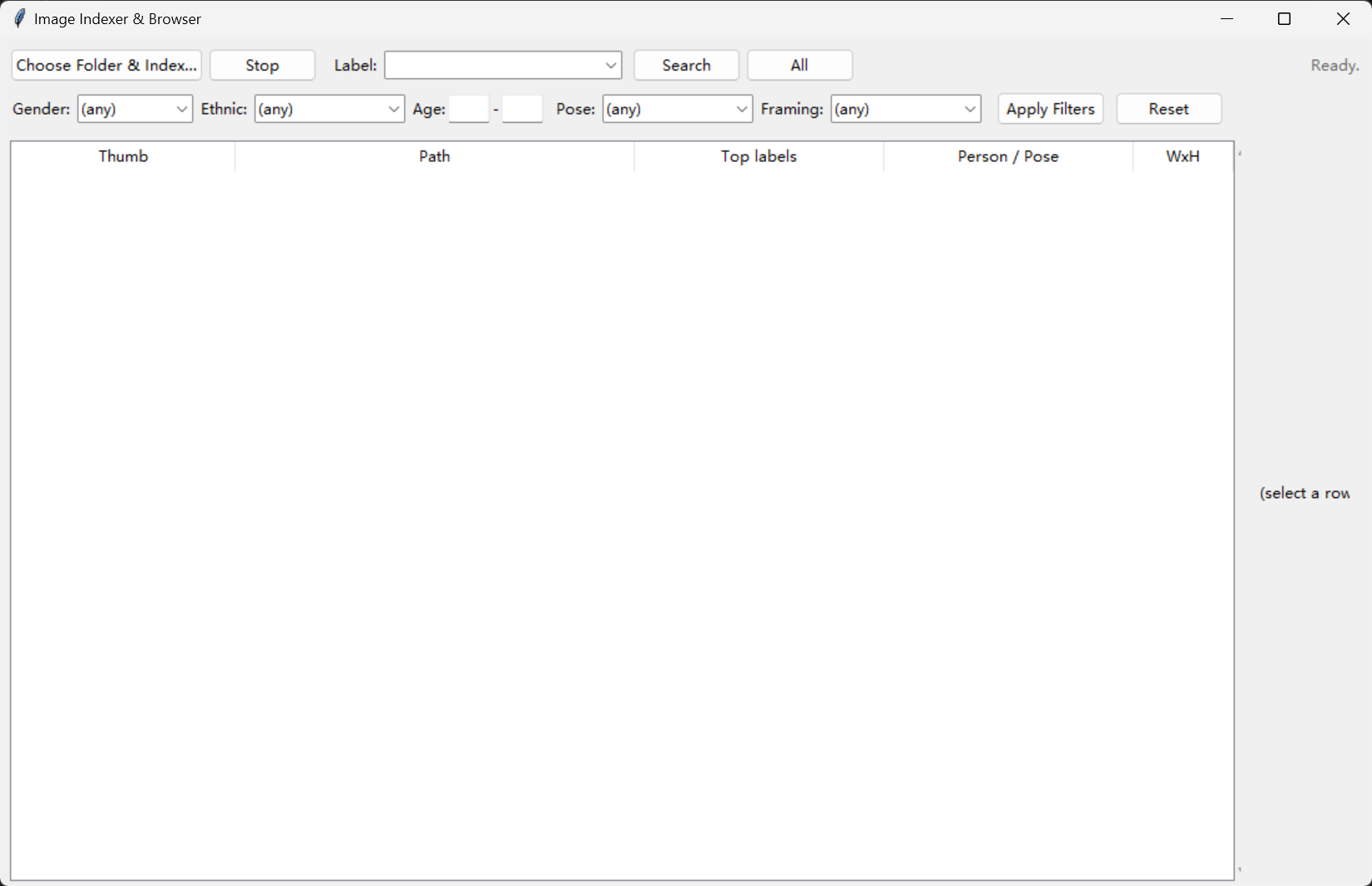
二、工具能做什么、不能做什么
| 想要的属性 | 能 / 不能 | 用什么 |
|---|---|---|
| 性别 | 能 | DeepFace gender |
| 年龄 | 能 | DeepFace age |
| 族裔外貌 | 能 | DeepFace race(6 类) |
| 姿势 | 能 | MediaPipe Pose + 几何规则 |
| 半身/全身 | 能 | MediaPipe Pose 关键点可见性 |
| 衣着颜色 | 不能 | 需要 CLIP 或自训分类器 |
| 发型 / 发色 | 不能 | 同上 |
| 是否化妆 | 不能 | 同上,且训练数据极敏感 |
| 国籍 | 不能 | 视觉无法可靠判别,逻辑上不成立 |
我把"国籍"重新框定为"族裔外貌","衣着/发型/化妆"暂不做(要真做就得叠 CLIP,下一篇再写)。
三、安装与一个绕不开的网络坑
bash
pip install deepface tensorflow opencv-python pillowDeepFace 第一次调用 DeepFace.analyze 会自动从 GitHub Releases 下载权重。在国内网络环境下:
github.com → raw.githubusercontent.com → 经常超时DeepFace 内部直接 urlretrieve,没有 proxies 选项也不会自动重试。我在多次失败后用 gh.idayer.com 这个反代镜像手动下载,把三个文件放到 DeepFace 默认缓存目录:
C:\Users\<you>\.deepface\weights\
├── age_model_weights.h5 (514 MB)
├── gender_model_weights.h5 (513 MB)
└── race_model_single_batch.h5 (513 MB)镜像 URL 格式(在原始 GitHub 链接前加 https://gh.idayer.com/):
bash
curl -L -C - -o age_model_weights.h5 \
https://gh.idayer.com/https://github.com/serengil/deepface_models/releases/download/v1.0/age_model_weights.h5-C - 是断点续传,512 MB 文件半路断了不用从 0 重来。
我亲测过
ghfast.top、mirror.ghproxy.com、ghps.cc都不稳,gh.idayer.com是当前最可靠的(2026 年初)。如果镜像也不行,最简单的办法是去 GitHub Releases 页用浏览器手动下载然后丢进去。
下载完成一定要校验大小不能截断(一个特别迷的事是:DeepFace 加载残缺的 .h5 时会抛 OSError: Unable to synchronously open file (truncated file),但很多教程没提)。
四、DeepFace 的多张脸输出
DeepFace.analyze 有个有意思的设计:单脸返回 dict ,多脸返回 listdict。统一处理:
python
results = DeepFace.analyze(
img_path=img_bgr, # 可以直接传 numpy BGR
actions=("age", "gender", "race"),
detector_backend="opencv", # 内置 cv2 Haar,最快
enforce_detection=False, # 没检到脸时也别抛异常
silent=True,
)
if isinstance(results, dict):
results = [results]每个 r 字段:
python
r["age"] # int
r["gender"] # {"Man": 12.3, "Woman": 87.7}
r["dominant_gender"] # "Woman"
r["race"] # {"asian": 60.5, "white": 30.2, ...}
r["dominant_race"] # "asian"
r["region"] # {"x":..., "y":..., "w":..., "h":...}我同时保留 dominant_* 和最大值的 score:
python
gender_dict = r.get("gender") or {}
gender = max(gender_dict, key=gender_dict.get)
gender_score = float(gender_dict[gender]) / 100.0/100 是因为 DeepFace 给的是百分比,不是 0,1 概率。
五、enforce_detection=False 的副作用与修正
设了 enforce_detection=False,DeepFace 在没检到脸时也会返回结果------拿整张图当一张脸。这会污染数据。我加了 bbox 三重过滤:
python
H, W = img_bgr.shape[:2]
if w <= 1 or h <= 1: continue # 无效尺寸
if w * h >= 0.95 * W * H: continue # 整图回退
if w < 0.03 * W or h < 0.03 * H: continue # 太小,多半是误检加完之后大量"风景照里硬塞进一个 Man/27 岁/asian"的脏数据消失了。
六、MediaPipe PoseLandmarker
跟 第一篇 HandLandmarker 同一套 Tasks API,模型换成 pose_landmarker_full.task(9 MB,Google CDN 直连):
https://storage.googleapis.com/mediapipe-models/pose_landmarker/pose_landmarker_full/float16/latest/pose_landmarker_full.task
python
opts = vision.PoseLandmarkerOptions(
base_options=mp_python.BaseOptions(model_asset_path=str(POSE_MODEL)),
running_mode=vision.RunningMode.IMAGE, # 离线批处理
num_poses=1,
min_pose_detection_confidence=0.5,
)
landmarker = vision.PoseLandmarker.create_from_options(opts)
result = landmarker.detect(mp_image) # 同步调用返回 result.pose_landmarks[0] 是 33 个点的 list,每个点有 .x .y .z .visibility。visibility 是关键:很多关节在画面外或被遮挡时分数低,正好让我们判断取景。
常用索引:
python
LM_NOSE = 0
LM_L_SHOULDER, LM_R_SHOULDER = 11, 12
LM_L_HIP, LM_R_HIP = 23, 24
LM_L_KNEE, LM_R_KNEE = 25, 26
LM_L_ANKLE, LM_R_ANKLE = 27, 28七、取景分类(face_only / upper_body / half_body / three_quarter / full_body)
简单但实用的可见性级联:
python
POSE_VIS_THRESH = 0.5
def _classify_framing(vis):
def seen(*idx):
return all(vis.get(i, 0.0) >= POSE_VIS_THRESH for i in idx)
if seen(LM_L_ANKLE) or seen(LM_R_ANKLE): return "full_body"
if seen(LM_L_KNEE) or seen(LM_R_KNEE): return "three_quarter"
if seen(LM_L_HIP) or seen(LM_R_HIP): return "half_body"
if seen(LM_L_SHOULDER) or seen(LM_R_SHOULDER): return "upper_body"
if seen(LM_NOSE): return "face_only"
return "unknown"seen 用 or 容许遮挡------只要有一只脚踝可见就算全身入画。
八、姿势分类的几何规则
肩膀连线为参考,归一化坐标在 0,1 范围内,各种阈值都是经验值:
python
def _classify_pose(landmarks, vis):
def lm(i): return landmarks[i]
def seen(*idx): return all(vis.get(i, 0.0) >= POSE_VIS_THRESH for i in idx)
if not seen(LM_L_SHOULDER, LM_R_SHOULDER):
return "unknown"
sh_y = (lm(LM_L_SHOULDER).y + lm(LM_R_SHOULDER).y) / 2
sh_x_l, sh_x_r = lm(LM_L_SHOULDER).x, lm(LM_R_SHOULDER).x
# 双手腕都高于肩 5%:双臂上举
if seen(LM_L_WRIST, LM_R_WRIST):
if lm(LM_L_WRIST).y < sh_y - 0.05 and lm(LM_R_WRIST).y < sh_y - 0.05:
return "arms_raised"
# 手腕位于髋附近:插腰
if seen(LM_L_WRIST, LM_R_WRIST, LM_L_HIP, LM_R_HIP):
hip_y = (lm(LM_L_HIP).y + lm(LM_R_HIP).y) / 2
l_close = abs(lm(LM_L_WRIST).y - hip_y) < 0.08 and abs(lm(LM_L_WRIST).x - lm(LM_L_HIP).x) < 0.1
r_close = abs(lm(LM_R_WRIST).y - hip_y) < 0.08 and abs(lm(LM_R_WRIST).x - lm(LM_R_HIP).x) < 0.1
if l_close and r_close:
return "hands_on_hips"
# 左腕靠近右肩 + 右腕靠近左肩:抱臂
if seen(LM_L_WRIST, LM_R_WRIST):
l_to_rsh = abs(lm(LM_L_WRIST).x - sh_x_r) + abs(lm(LM_L_WRIST).y - sh_y)
r_to_lsh = abs(lm(LM_R_WRIST).x - sh_x_l) + abs(lm(LM_R_WRIST).y - sh_y)
if l_to_rsh < 0.15 and r_to_lsh < 0.15:
return "arms_crossed"
# 髋y与膝y几乎相等:坐姿
# (站立时膝远低于髋;坐下时它们几乎同高)
if seen(LM_L_HIP, LM_L_KNEE) or seen(LM_R_HIP, LM_R_KNEE):
# ...略
if abs(np.mean(hips_y) - np.mean(knees_y)) < 0.08:
return "sitting"
if seen(LM_L_HIP) or seen(LM_R_HIP):
return "standing"
return "unknown"判别力没有训练出来的姿势模型强,但是0 训练成本、几行代码、可解释------很适合"图书馆型"的批处理标注。后面如果想升级,可以把 33 个关键点拍平成 99 维向量训一个 MLP。
九、模块化:person_analyzer.py
把上面这些封到一个独立模块,索引器只调一个函数:
python
@dataclass
class PersonAttrs:
person_idx: int
bbox: tuple[int, int, int, int] | None
gender: Optional[str] = None
gender_score: Optional[float] = None
age: Optional[int] = None
ethnic_appearance: Optional[str] = None
ethnic_score: Optional[float] = None
@dataclass
class ImageAnalysis:
persons: list[PersonAttrs] = field(default_factory=list)
pose: Optional[str] = None
framing: Optional[str] = None
pose_keypoint_visibility: dict = field(default_factory=dict)
error: Optional[str] = None
def analyze_image(path):
out = ImageAnalysis()
try:
with Image.open(path) as im:
arr_rgb = np.array(im.convert("RGB"))
bgr = arr_rgb[:, :, ::-1].copy()
out.persons = _analyze_persons(bgr)
if out.persons: # 没人就不跑 pose
pose, framing, vis = _analyze_pose(arr_rgb)
out.pose, out.framing, out.pose_keypoint_visibility = pose, framing, vis
except Exception as e:
out.error = f"{type(e).__name__}: {e}"
return out两个函数都用模块级懒加载,第一次调用时初始化 DeepFace(其实 DeepFace 是首次调用 analyze 才载权重)和 PoseLandmarker,多次调用复用:
python
_pose_landmarker = None
def _get_pose_landmarker():
global _pose_landmarker
if _pose_landmarker is None:
_pose_landmarker = vision.PoseLandmarker.create_from_options(opts)
return _pose_landmarker十、SQLite 老库迁移
第一篇生成的 images 表没有 pose / framing 列。直接 ALTER TABLE:
python
cols = {r[1] for r in con.execute("PRAGMA table_info(images)").fetchall()}
if "pose" not in cols:
con.execute("ALTER TABLE images ADD COLUMN pose TEXT")
if "framing" not in cols:
con.execute("ALTER TABLE images ADD COLUMN framing TEXT")人物属性单建一表,一对多(一张图可能多人):
sql
CREATE TABLE IF NOT EXISTS person_attrs (
image_id INTEGER NOT NULL REFERENCES images(id) ON DELETE CASCADE,
person_idx INTEGER NOT NULL,
gender TEXT, gender_score REAL,
age INTEGER,
ethnic_appearance TEXT, ethnic_score REAL,
bbox_x0 INTEGER, bbox_y0 INTEGER, bbox_x1 INTEGER, bbox_y1 INTEGER
);
CREATE INDEX IF NOT EXISTS idx_person_image ON person_attrs(image_id);
CREATE INDEX IF NOT EXISTS idx_person_gender ON person_attrs(gender);
CREATE INDEX IF NOT EXISTS idx_person_age ON person_attrs(age);
CREATE INDEX IF NOT EXISTS idx_person_ethnic ON person_attrs(ethnic_appearance);十一、动态 SQL:组合过滤器
GUI 里给了一排控件:性别 / 族裔 / 年龄区间 / 姿势 / 取景。用户可以勾任意子集。后端按勾的字段动态拼 SQL:
python
def _query(self, f):
clauses, params, joins = [], [], ""
if "label" in f:
joins += " JOIN labels l ON l.image_id = i.id"
clauses.append("l.label LIKE ?"); params.append(f"%{f['label']}%")
person_keys = {"gender", "ethnic", "age_min", "age_max"}
if person_keys & f.keys():
joins += " JOIN person_attrs p ON p.image_id = i.id"
if "gender" in f: clauses.append("p.gender = ?"); params.append(f["gender"])
if "ethnic" in f: clauses.append("p.ethnic_appearance = ?"); params.append(f["ethnic"])
if "age_min" in f: clauses.append("p.age >= ?"); params.append(f["age_min"])
if "age_max" in f: clauses.append("p.age <= ?"); params.append(f["age_max"])
if "pose" in f: clauses.append("i.pose = ?"); params.append(f["pose"])
if "framing" in f: clauses.append("i.framing = ?"); params.append(f["framing"])
where = ("WHERE " + " AND ".join(clauses)) if clauses else ""
sql = f"SELECT DISTINCT i.id, i.path, i.thumb, ... FROM images i {joins} {where} " \
f"ORDER BY i.indexed_at DESC LIMIT 500"
return con.execute(sql, params).fetchall()SELECT DISTINCT 防止 JOIN labels/person_attrs 之后重复行------一张图的 5 个标签会让它出现 5 次。
十二、效果
我有一个 600 张图的"参考图册",里面是各种站姿、坐姿、人像照,跑了一遍:
- 索引时间:~12 分钟(DeepFace 推理是大头,每张大约 1-2 秒,CPU);
- DB 大小:从 30 MB 涨到 38 MB(缩略图占大头,属性 < 1 MB);
- 用
Gender=Woman, Framing=full_body, Pose=standing过滤:返回 80 多张,瞄一眼基本都对。
姿势规则的局限:人像侧拍 / 半身镜头里手腕和髋盖经常被裁掉,规则就 fall back 到 standing/unknown。这是当前最大的遗憾。
十三、几个工程上的坑
1. TensorFlow 在 Windows 下首次 import 输出一堆警告:
python
os.environ.setdefault("TF_CPP_MIN_LOG_LEVEL", "3")
os.environ.setdefault("TF_ENABLE_ONEDNN_OPTS", "0")放在 import deepface 之前。
2. 控制台 GBK 编码错误 :DeepFace 抛异常带 emoji ⛓,Windows 控制台默认 GBK 直接挂掉。统一加:
python
import sys
sys.stdout.reconfigure(encoding="utf-8")
# 或者
os.environ["PYTHONIOENCODING"] = "utf-8"3. DeepFace 第一次调用很慢:要载入 age/gender/race 三个模型(共 1.5 GB)。子线程后台索引时这个延迟就不那么扎眼了。
4. 数据库 WAL 文件 :跑完之后看到 image_index.db-wal 和 image_index.db-shm,不要手动删,正常关闭后会被合并。
十四、整体架构小结
demo_image_indexer.py
├── DB 层(建表 + 迁移 + 缩略图 BLOB)
├── Classifier (MediaPipe ImageClassifier)
├── index_folder()
│ └── 调 person_analyzer.analyze_image() ← 本篇
└── App (Tkinter Treeview + 过滤器 + 预览)
person_analyzer.py
├── _analyze_persons() → DeepFace.analyze + bbox 过滤
├── _analyze_pose() → MediaPipe PoseLandmarker + 几何规则
└── analyze_image() → ImageAnalysis(persons, pose, framing)十五、下一步
- CLIP 开放词表 :
ViT-B/32ONNX 版本约 350 MB,把图和"穿红色连衣裙的女性"这类自然语言查询放到同一向量空间里,直接补衣着/发型/化妆维度; - 更稳的姿势识别:把 99 维关键点喂给一个 3 层 MLP,少量人工标注就能比规则强很多;
- 重复图检测:pHash 或 CLIP embedding;
- 多人去重 :当前同一张图里多人都进
person_attrs,但 DeepFace 在大合照上经常漏掉远处的脸------可以再叠 MediaPipe FaceDetector 取人脸候选,再喂给 DeepFace 强制 enforce 模式。
代码量上:person_analyzer.py 约 300 行,demo_image_indexer.py 集成后约 580 行。一个完整的"人物属性图库"从写第一行到能用,全部本地,三天不到。MediaPipe Tasks + DeepFace 这一对组合的性价比真的很高。
十六、下载的模型源地址和目标地址
================================================================================
本项目下载的所有模型文件清单
【一】MediaPipe 官方模型 (Google CDN, 直连可达)
-
hand_landmarker.task 7.5 MB
用途: 手部 21 关键点检测 (用于 demo_hand_landmarker.py)
存放路径: C:\Users\86182\Desktop\MediaPipe\models\hand_landmarker.task
-
face_detector.task 225 KB
用途: 人脸检测 BlazeFace short-range (用于 demo_face_capture.py)
存放路径: C:\Users\86182\Desktop\MediaPipe\models\face_detector.task
-
efficientnet_lite0.tflite 18 MB
用途: ImageNet 1000 类图像分类 (用于 demo_image_indexer.py)
存放路径: C:\Users\86182\Desktop\MediaPipe\models\efficientnet_lite0.tflite
-
pose_landmarker_full.task 9.0 MB
用途: 人体 33 关键点姿势检测 (用于 person_analyzer.py)
存放路径: C:\Users\86182\Desktop\MediaPipe\models\pose_landmarker_full.task
【二】DeepFace 模型 (GitHub, 通过 gh.idayer.com 镜像下载)
-
age_model_weights.h5 514 MB
用途: 年龄回归 (DeepFace age 任务)
原始地址: https://github.com/serengil/deepface_models/releases/download/v1.0/age_model_weights.h5
存放路径: C:\Users\86182.deepface\weights\age_model_weights.h5
-
gender_model_weights.h5 513 MB
用途: 性别二分类 (DeepFace gender 任务)
原始地址: https://github.com/serengil/deepface_models/releases/download/v1.0/gender_model_weights.h5
存放路径: C:\Users\86182.deepface\weights\gender_model_weights.h5
-
race_model_single_batch.h5 513 MB
用途: 族裔外貌六分类 (DeepFace race 任务: asian/white/black/indian/middle_eastern/latino_hispanic)
原始地址: https://github.com/serengil/deepface_models/releases/download/v1.0/race_model_single_batch.h5
存放路径: C:\Users\86182.deepface\weights\race_model_single_batch.h5
【三】总计
文件总数: 7
项目模型目录 (C:\Users\86182\Desktop\MediaPipe\models): 约 35 MB
DeepFace 权重目录 (C:\Users\86182.deepface\weights): 约 1.6 GB
合计: 约 1.6 GB
注: pip 安装的 Python 包 (mediapipe / opencv / deepface / tensorflow 等)
位于 C:\Users\86182\Desktop\MediaPipe\venv, 不在本清单中。