收到采集条件,真实情况的限制,不管是二分类的正负样本还是多分类中,都会普遍存在样本不平衡的问题。
Asymmetric Loss(非对称损失函数,简称 ASL)
. 概率计算与非对称裁剪 (Asymmetric Clipping)
xs_pos = torch.sigmoid(x)
xs_neg = 1 - xs_pos
# Asymmetric Clipping
if self.clip is not None and self.clip > 0:
xs_neg = (xs_neg + self.clip).clamp(max=1)- 原理解读 :首先通过 Sigmoid 将模型输出的 logits (
x) 转换为正样本的概率xs_pos,那么负样本的概率就是xs_neg = 1 - xs_pos。 - 代码亮点 :这里实现了 ASL 独有的概率位移(Probability Margin Shifting) 。代码对负样本概率进行了
(xs_neg + clip)的操作,然后截断在 1 以内。这相当于给简单负样本设定了一个硬阈值边界,当负样本的原始预测概率极低时,加上clip后的对数损失会被大幅削弱甚至归零,从而直接丢弃这些无用的梯度。注意,这个操作只针对负样本,体现了非对称性。
基础交叉熵计算与掩码分离 (Basic CE & Masking)
los_pos = y * torch.log(xs_pos.clamp(min=self.eps))
los_neg = (1 - y) * torch.log(xs_neg.clamp(min=self.eps))
loss = los_pos + los_neg- 原理解读:这是标准的二元交叉熵(BCE)计算过程。
- 代码亮点:交叉指的是权重和log部分分别是真实标签和预测值;
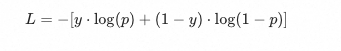
- 掩码则指的是利用标签
y(0或1矩阵)作为天然的掩码(Mask) 。因为当y=1时,loss=los_pos;当y=0时,loss=los_neg。所以los_pos实际上只保留了真实为正类的样本的损失,而los_neg只保留了真实为负类的样本的损失。两者相加后,就得到了一个包含所有样本基础损失的矩阵。
非对称聚焦权重 (Asymmetric Focusing)
pt = xs_pos * y + xs_neg * (1 - y)
one_sided_gamma = self.gamma_pos * y + self.gamma_neg * (1 - y)
one_sided_w = torch.pow(1 - pt, one_sided_gamma)
loss *= one_sided_w- 原理解读:这是 Focal Loss 核心调制因子 (1−pt)γ的非对称升级版。
- 代码亮点 :
pt巧妙地提取了每个样本对应的正确类别概率(正样本取xs_pos,负样本取xs_neg)。含义是分对的概率/自信程度。one_sided_gamma同样利用标签y作为掩码,为每一个样本动态分配 γ 值:正样本获得gamma_pos,负样本获得gamma_neg。- pt是自信程度,那么1-pt就是犹豫程度,使用pow可以使得犹豫程度低的压低权重,犹豫程度高的接近1,则不被抑制。
- 针对负样本(
gamma_neg) :在多标签分类中,一张图通常只有少数几个正标签,剩下的绝大多数都是负标签。因为负样本数量极多,且其中大部分是毫无难度的"简单负样本",所以必须设置一个较大的gamma_neg(如默认值 4),以强力抑制它们,防止模型被负样本主导。 - 针对正样本(
gamma_pos) :正样本本身就是稀缺资源。如果给正样本设置过大的 γγ ,会导致大量正样本的损失被削弱,模型反而学不到东西。因此,gamma_pos通常设置得较小,甚至为 0(即不对正样本做 Focal 降权,保持标准交叉熵的学习强度)。 - 抑制程度就是gamma控制,正/负样本分别对应一个gamma,gamma越大,抑制越厉害。
- 最后将这个非对称权重
one_sided_w乘到基础loss上,完成了对难易样本的动态降权 - 正负失衡 vs 类间失衡。ASL 的原始设计并不直接处理这种类间的不平衡,它默认所有正样本(无论是人还是长颈鹿)在训练初期都同样稀缺。
- 对于4分类,
pt = [0.1, 0.8, 0.05, 0.05],那么1 - pt = [0.9, 0.2, 0.95, 0.95],真实标签y=[0,1,0,0],one_sided_gamma = 4, 1, 4, 4,指数之后的权重张量one_sided_w = [0.6561, 0.2, 0.8145, 0.8145]。可以看到,索引0,2,3处本来错误率很高,加权之后权重相对索引1被降低了,所以模型可以更专注于正样本索引1.
梯度控制优化 (Gradient Control)
if self.disable_torch_grad_focal_loss:
torch.set_grad_enabled(False)
# ... 计算 one_sided_w ...
if self.disable_torch_grad_focal_loss:
torch.set_grad_enabled(True)工程细节:这是一个非常高级的工程优化。在计算聚焦权重 one_sided_w 时,如果开启了此选项,会临时关闭 PyTorch 的自动求导功能,计算出one_sided_w之后,乘到loss之前,再打开梯度。
-
因为
one_sided_w是一个常数权重,但是 PyTorch 并不知道你的"数学意图"。它会忠实地把torch.pow和*这两个操作都加入计算图。它不仅会计算基础 BCE Loss 对模型预测概率 pt 的梯度,还会额外计算 one_sided_w 对 pt 的梯度,然后利用链式法则把它们加起来。这样反向传播时需要多做一次复杂的链式求导,拖慢了训练速度,还容易显存爆炸。 -
所以临时设置torch.set_grad_enabled(False),我们通常只需要让基础 BCE Loss 参与梯度回传,而不需要对这个复杂的权重项再求一次高阶导数。这不仅能节省显存,还能加快训练速度。