| 属性 | 内容 |
|---|---|
| 链接 | bike-sharing-demand-randomforest-time-features |
| 摘要 | 基于 UCI Bike Sharing 数据集,通过高峰时段、夜间、周末等时间特征工程,使用随机森林回归预测每小时共享单车租赁量,并解释关键影响因素。 |
| 描述 | 本文基于 UCI Bike Sharing 数据集,展示时间序列回归的完整流程:构造高峰时段、夜间、周末等特征,使用随机森林回归预测每小时租车量,R² 达到 0.931,并分析哪些时间因素最影响需求。 |
本项目由 星枢 支持
星枢官网:https://claudeaihub.cloud/

共享单车需求预测:时间特征工程 + 随机森林,R² 达到 0.931
前面几个项目覆盖了分类、回归、聚类、医疗二分类和特征工程二分类。这次做一个时间序列回归:用 UCI Bike Sharing 数据集预测每小时共享单车租赁量。重点是展示时间特征工程的价值------ hour、是否高峰、是否夜间、是否周末,这些特征对预测结果影响巨大。
项目已开源:
text
https://github.com/coderWang404/xingshuProjects/tree/main/2026-06-14-bike-sharing-demand核心结论:
- 数据规模:17,379 条小时级记录
- 模型:RandomForestRegressor
- R²:0.9307
- RMSE:46.84
- MAE:28.73
- 最强特征 :
is_night(是否夜间)
1. 数据集
数据来自 UCI Machine Learning Repository 的 Bike Sharing Dataset,包含华盛顿特区 Capital Bikeshare 系统 2011-2012 年的每小时租车记录。
原始字段包括:
| 字段 | 含义 |
|---|---|
| season | 季节(1=春,2=夏,3=秋,4=冬) |
| yr | 年份(0=2011,1=2012) |
| mnth | 月份 |
| hr | 小时(0-23) |
| holiday | 是否节假日 |
| weekday | 星期几 |
| workingday | 是否工作日 |
| weathersit | 天气状况 |
| temp | 归一化温度 |
| atemp | 归一化体感温度 |
| hum | 归一化湿度 |
| windspeed | 归一化风速 |
| casual | 临时用户租车数 |
| registered | 注册用户租车数 |
| cnt | 总租车数(目标) |
目标 cnt = casual + registered。为了防止数据泄漏,训练时去掉了 casual 和 registered,只用时间、气象和构造的特征预测总量。
2. 环境准备
text
pandas
numpy
scikit-learn
matplotlib
seaborn
requests
bash
git clone https://github.com/coderWang404/xingshuProjects.git
cd xingshuProjects/2026-06-14-bike-sharing-demand
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt3. 运行实验
bash
python experiments/bike-sharing/run_experiment.py4. 时间特征工程
这个项目的核心是构造有效的时间特征。原始数据里 hr 已经很有用,但模型很难直接理解"0-5 点是夜间"、"7-9 点和 17-19 点是通勤高峰"这些业务知识。
我构造了三个关键二值特征:
python
data["is_rush_hour"] = (
(data["workingday"] == 1) & (data["hr"].isin([7, 8, 9, 17, 18, 19]))
).astype(int)
data["is_weekend"] = (data["weekday"].isin([0, 6])).astype(int)
data["is_night"] = ((data["hr"] >= 22) | (data["hr"] <= 5)).astype(int)另外还加了一个气象交互特征:
python
data["temp_atemp_diff"] = data["atemp"] - data["temp"]分类变量(season, yr, mnth, hr, holiday, weekday, workingday, weathersit)做了 one-hot 编码。最终输入模型的特征有 57 个。
5. 建模与结果
模型参数:
python
RandomForestRegressor(
n_estimators=300,
max_depth=15,
min_samples_leaf=2,
random_state=42,
n_jobs=-1,
)测试集结果:
| 指标 | 数值 |
|---|---|
| R² | 0.9307 |
| RMSE | 46.8373 |
| MAE | 28.7267 |
R² 0.93 非常高,说明模型能解释 93% 的租车量方差。对于共享单车这种受天气、节假日、突发事件影响很大的业务场景,这个表现已经很好。
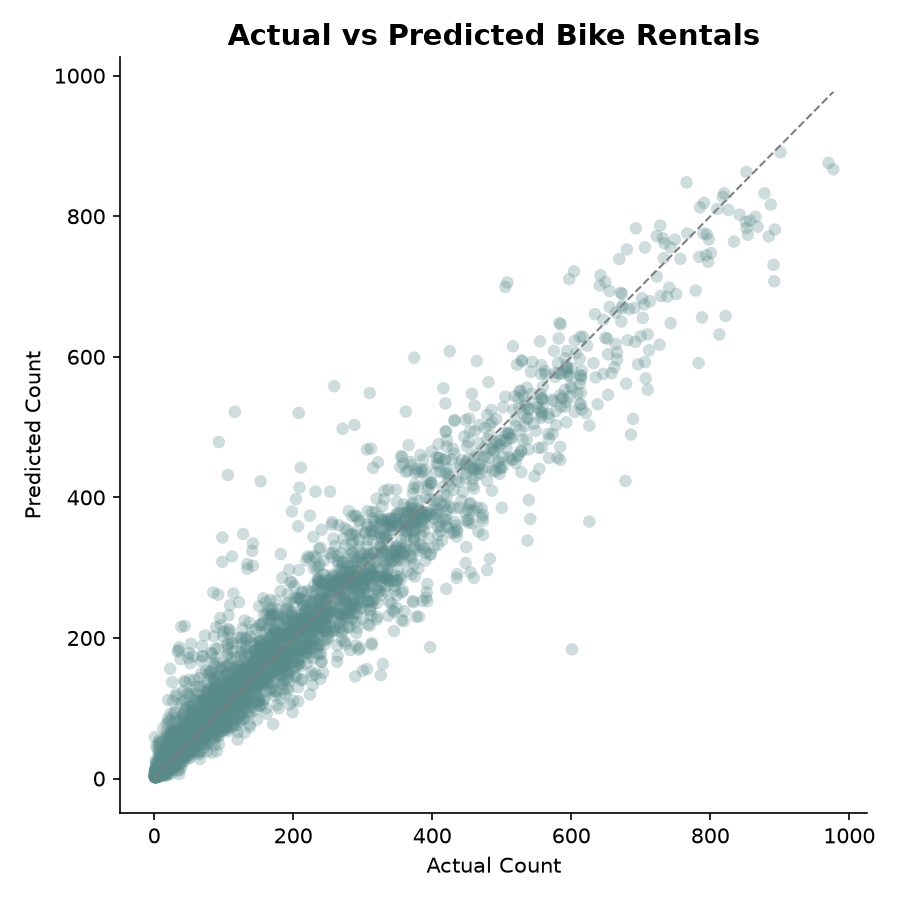
散点图显示预测值和实际值高度集中在对角线附近。
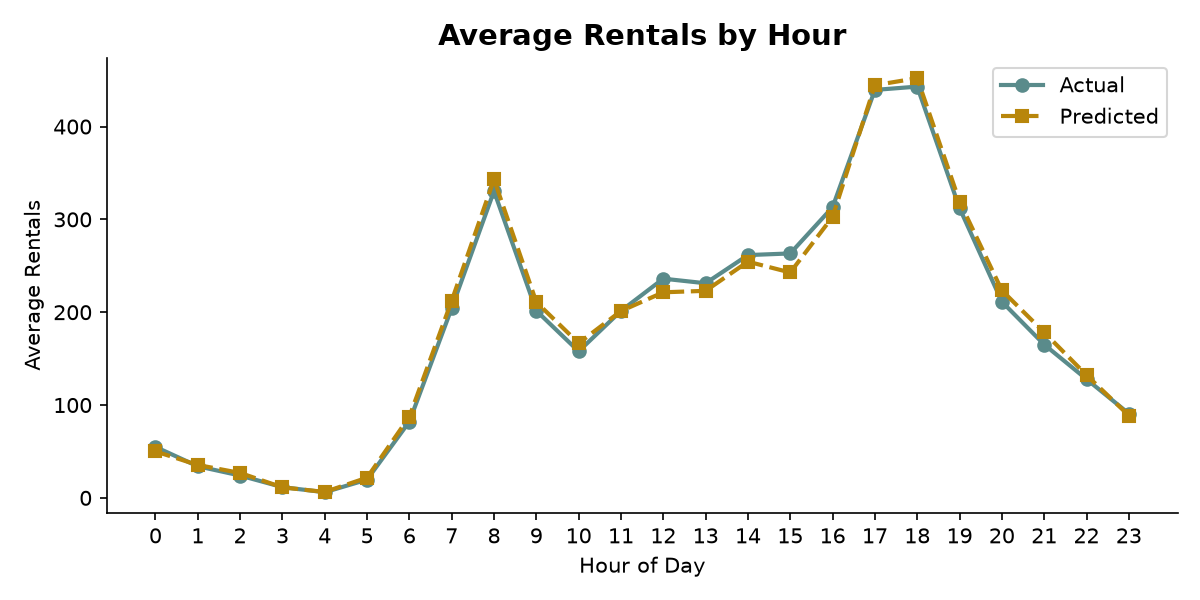
按小时聚合后,模型几乎完美复刻了实际租车量的双峰模式:早高峰和晚高峰。这说明 hr 和 is_rush_hour 两个特征捕获了主要的日内周期。
6. 特征重要性:夜间是最强信号
Permutation Importance 排名前 10:
| 排名 | 特征 | 重要性 |
|---|---|---|
| 1 | is_night | 0.6707 |
| 2 | is_rush_hour | 0.4940 |
| 3 | temp | 0.1930 |
| 4 | yr_1 | 0.1916 |
| 5 | workingday_1 | 0.0929 |
| 6 | hum | 0.0639 |
| 7 | hr_9 | 0.0591 |
| 8 | hr_7 | 0.0405 |
| 9 | atemp | 0.0361 |
| 10 | hr_6 | 0.0355 |
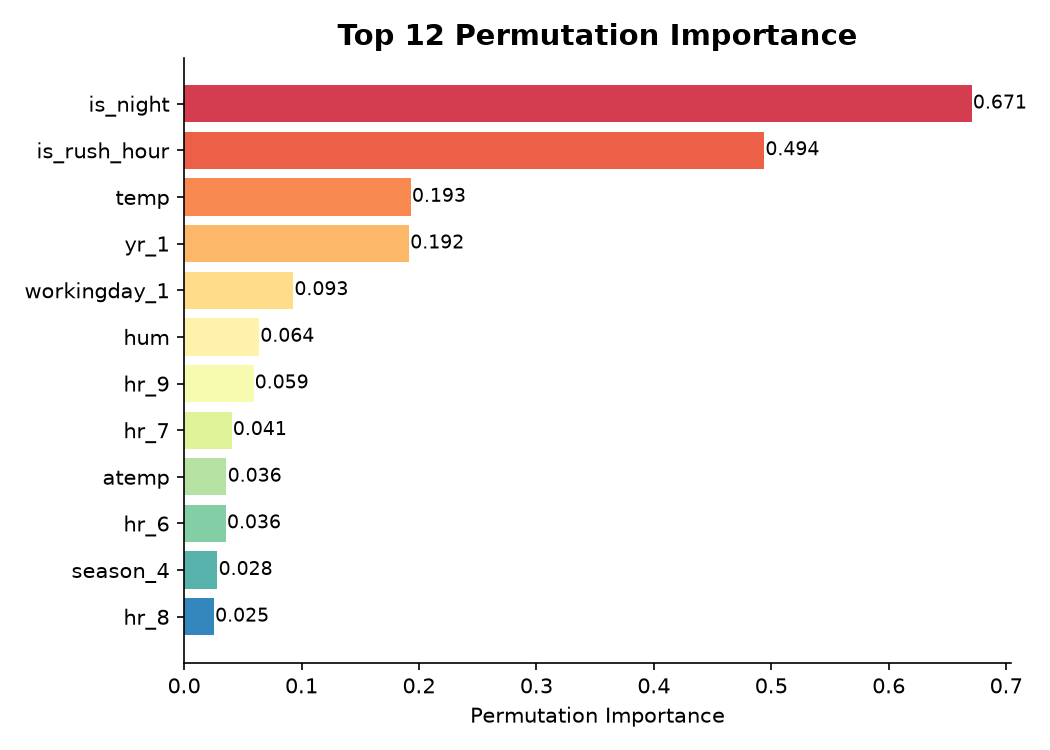
is_night 排名第一,这很合理:夜间(22:00-05:00)租车量几乎降到接近 0,这个二值特征能直接切掉一大块方差。
is_rush_hour 排名第二,说明通勤时段是工作日的核心需求。
temp 排名第三,温度对共享单车需求有显著正向影响------天气越暖和,骑车的人越多。
yr_1(2012 年)排名第四,说明租车量在逐年增长,系统用户基数在扩大。
一个有趣的观察是:hr_9、hr_7、hr_6 这些单个小时 one-hot 特征也进入了前十,说明通勤高峰的具体小时有额外的信息,不是光靠 is_rush_hour 就能完全捕捉。
7. 这个实验的业务含义
共享单车需求预测是一个典型的时间序列回归问题。这个结果可以指导实际业务:
- 调度:高峰前把车辆调度到通勤热点
- 维护:夜间低需求时段进行车辆维护
- 营销:温度高的晴天加大推广力度
- 容量规划:根据年增长趋势(yr_1)扩容
当然,真实系统还需要考虑更复杂的因素:特殊事件、地铁罢工、共享单车竞争、实时天气预警等。但这个实验展示了基础时间特征工程就能达到很好的效果。
8. 实验输出
运行脚本后 experiments/bike-sharing/outputs/ 会生成:
text
metrics.json # 完整指标 JSON
feature_importance.csv # 全部特征重要性
dataset_profile.csv # 数据统计
actual_vs_predicted.png # 实际 vs 预测散点图
residuals.png # 残差分布图
hourly_pattern.png # 按小时聚合趋势图
feature_importance.png # 特征重要性图
summary.md # 实验摘要9. 总结
这个实验让我重新认识了时间特征工程在回归任务中的价值:
- 业务知识可以转化为强特征 。"夜间租车少"、"早晚高峰租车多"这些常识,通过
is_night和is_rush_hour变成模型能直接使用的信号。 - 随机森林对时间周期模式学习能力强 。配合 one-hot 编码的
hr,模型能准确拟合双峰曲线。 - 温度是气象因素中最关键的。这和日常经验一致。
- R² 0.93 不代表可以无脑上线。真实业务中还需要考虑极端天气、特殊事件、实时性等更复杂因素。
如果想继续优化,可以试试:
- 用 Gradient Boosting(XGBoost / LightGBM)对比
- 加入前一天同时段的滞后特征(lag features)
- 加入移动平均特征
- 把预测目标从总量拆分为 casual 和 registered 分别建模
本项目由 星枢 支持
