在编译原理中,将 DFA 化简(最小化)是词法分析器优化的重要步骤。在将 DFA 转换为"全状态"后,我们通常使用分割法(Partition Refinement,也称 Hopcroft 算法或等价划分法来判定状态等价并完成化简。
以下是完整的理论讲解、判定方法,以及一个具体且典型的 DFA 化简实例演示。
一、 为什么要转为"全状态"?
"全状态 DFA"(Complete DFA)是指:对于字母表中的每一个符号,每个状态都必须有且仅有一条明确对应的转移边。
如果原 DFA 中某些状态对某些输入符号没有定义转移,我们需要引入一个"死状态 "(Trap State / Dead State,通常记为 TTT. :
- 将所有缺失的转移均指向该死状态。
- 死状态在输入任何符号时,都自我循环(即转移回自身)。
这样做的目的是确保在后续的等价性判定中,所有状态的转移函数都是完全定义的,避免因"无路可走"而导致的行为对齐混乱。
二、 状态等价性的判定方法
两个状态 ppp 和 qqq 是等价的 (记作 p≡qp \equiv qp≡q),当且仅当:对于任意的输入字符串 www,从 ppp 出发和从 qqq 出发,要么同时到达终态(接收状态),要么同时到达非终态。如果存在某个字符串能让它们一个走向终态、一个走向非终态,则称它们是可区分的(Distinguishable)。
我们使用分割法来找出这些等价状态:
-
初始划分(P0P_0P0) :
将全部状态集 QQQ 划分为两个子集:
- 终态集 GFG_FGF
- 非终态集 GNFG_{NF}GNF(引入的死状态也属于非终态集)
显然,终态和非终态是天然可区分的。
-
迭代分割(Refinement) :
对于当前划分中的某一个状态组 GGG,以及字母表中的任意输入符号 aaa:
- 观察 GGG 中的每个状态在输入 aaa 后的目标状态。
- 如果 GGG 中的状态在输入 aaa 后,走向了当前划分中不同的状态组 ,说明这些状态在输入 aaa 时表现出了不同的行为。
- 此时,必须将 GGG 拆分 为更小的子组,使得每个子组内的状态在输入 aaa 后都走向同一个状态组。
-
结束条件 :
重复上述分割步骤,直到在某轮迭代中,对所有组、所有输入符号进行检查,没有产生任何新的拆分。此时的划分即为最终的等价类划分。
三、 得到最终化简 DFA 的步骤
在划分稳定后:
- 合并状态:将最终处于同一组(等价类)的所有状态合并为一个新状态。
- 确定初态和终态 :
- 包含原初态的组,即为新 DFA 的初态。
- 包含原终态的组,即为新 DFA 的终态。
- 重构转移关系 :如果原状态 p∈G1p \in G_1p∈G1,且 p→aqp \xrightarrow{a} qpa q(其中 q∈G2q \in G_2q∈G2),则新 DFA 中有转移:G1→aG2G_1 \xrightarrow{a} G_2G1a G2。
- 清理多余状态(可选):如果合并后的死状态组不需要在最终的自动机中体现,可以将其以及所有指向它的边删去,恢复为非全状态但更清爽的 DFA(在实际词法分析中,无法匹配直接报错即可,不一定非要画出死状态)。
四、 复杂 DFA 化简实例演示
假设我们有一个 DFA,字母表 Σ={a,b}\Sigma = \{a, b\}Σ={a,b},状态集为 {A,B,C,D,E}\{A, B, C, D, E\}{A,B,C,D,E},其中 AAA 为初态 ,DDD 为唯一的终态 。
其初始转换关系如下(部分转移缺失):
- A→aBA \xrightarrow{a} BAa B
- B→aCB \xrightarrow{a} CBa C
- B→bDB \xrightarrow{b} DBb D
- C→aBC \xrightarrow{a} BCa B
- C→bDC \xrightarrow{b} DCb D
- D→aED \xrightarrow{a} EDa E
- E→aEE \xrightarrow{a} EEa E
- E→bEE \xrightarrow{b} EEb E
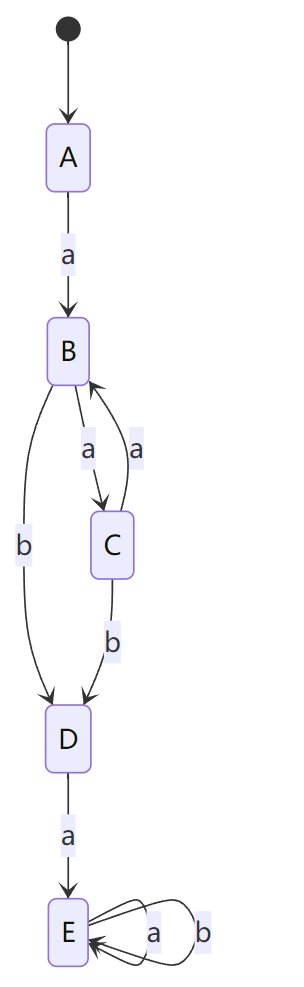
步骤 1:转为全状态 DFA
我们发现状态 AAA 缺少 bbb 的转移,状态 DDD 缺少 bbb 的转移。因此我们引入一个死状态 TTT,补全转换表:
| 状态 | 输入 aaa 的转移 | 输入 bbb 的转移 |
|---|---|---|
| A (初态) | B | T |
| B | C | D |
| C | B | D |
| D (终态) | E | T |
| E | E | E |
| T (死状态) | T | T |
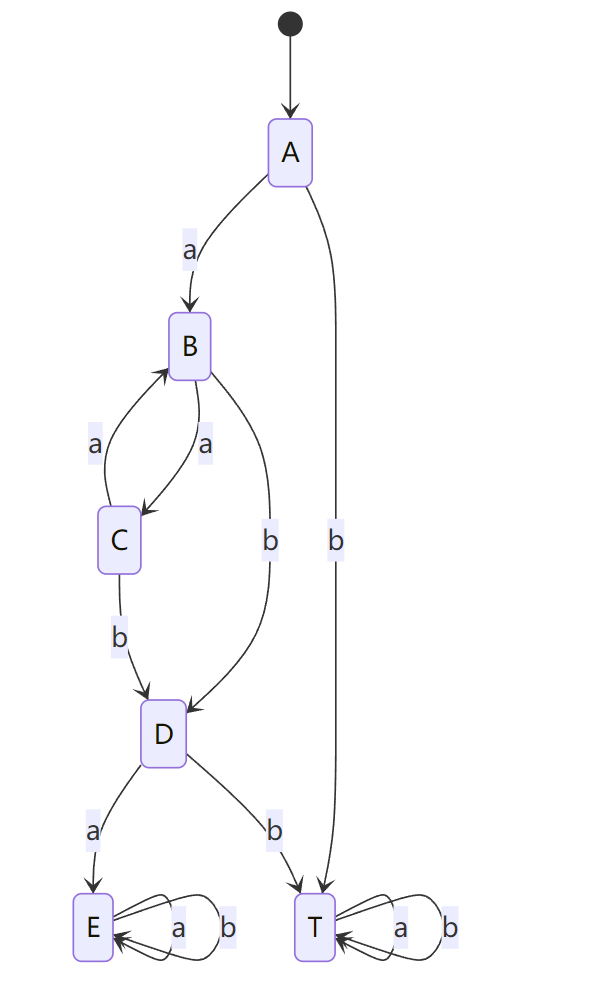
步骤 2:使用分割法判定等价性
1) 初始划分 P0P_0P0
将状态划分为非终态集和终态集:
- G1={A,B,C,E,T}G_1 = \{A, B, C, E, T\}G1={A,B,C,E,T} (非终态)
- G2={D}G_2 = \{D\}G2={D} (终态,单元素组无需再分)
2) 第一轮分割(针对 G1G_1G1)
我们检查 G1={A,B,C,E,T}G_1 = \{A, B, C, E, T\}G1={A,B,C,E,T} 中的状态在输入 aaa 和 bbb 后的走向:
-
输入 aaa 时:
- A→aB∈G1A \xrightarrow{a} B \in G_1Aa B∈G1
- B→aC∈G1B \xrightarrow{a} C \in G_1Ba C∈G1
- C→aB∈G1C \xrightarrow{a} B \in G_1Ca B∈G1
- E→aE∈G1E \xrightarrow{a} E \in G_1Ea E∈G1
- T→aT∈G1T \xrightarrow{a} T \in G_1Ta T∈G1
(在输入 aaa 时,所有状态都走向 G1G_1G1,无法区分)
-
输入 bbb 时:
- A→bT∈G1A \xrightarrow{b} T \in G_1Ab T∈G1
- B→bD∈G2B \xrightarrow{b} D \in G_2Bb D∈G2
- C→bD∈G2C \xrightarrow{b} D \in G_2Cb D∈G2
- E→bE∈G1E \xrightarrow{b} E \in G_1Eb E∈G1
- T→bT∈G1T \xrightarrow{b} T \in G_1Tb T∈G1
(我们发现 BBB 和 CCC 走向了 G2G_2G2,而 A,E,TA, E, TA,E,T 走向了 G1G_1G1。因此 G1G_1G1 必须被拆分)
拆分后的新划分 P1P_1P1 为:
- H1={A,E,T}H_1 = \{A, E, T\}H1={A,E,T}
- H2={B,C}H_2 = \{B, C\}H2={B,C}
- H3={D}H_3 = \{D\}H3={D}
3) 第二轮分割(针对 H1H_1H1 和 H2H_2H2)
现在我们有三个组,继续检查它们:
-
检查 H2={B,C}H_2 = \{B, C\}H2={B,C}:
- 输入 aaa:B→C∈H2B \to C \in H_2B→C∈H2 且 C→B∈H2C \to B \in H_2C→B∈H2(走向相同组)
- 输入 bbb:B→D∈H3B \to D \in H_3B→D∈H3 且 C→D∈H3C \to D \in H_3C→D∈H3(走向相同组)
- 结论:H2H_2H2 无法再分。
-
检查 H1={A,E,T}H_1 = \{A, E, T\}H1={A,E,T}:
- 输入 aaa :
- A→aB∈H2A \xrightarrow{a} B \in H_2Aa B∈H2
- E→aE∈H1E \xrightarrow{a} E \in H_1Ea E∈H1
- T→aT∈H1T \xrightarrow{a} T \in H_1Ta T∈H1
(这里发生了分化:AAA 走向了 H2H_2H2,而 E,TE, TE,T 走向了 H1H_1H1。因此 H1H_1H1 必须被拆分)
- 输入 aaa :
拆分后的新划分 P2P_2P2 为:
- K1={A}K_1 = \{A\}K1={A}
- K2={E,T}K_2 = \{E, T\}K2={E,T}
- K3={B,C}K_3 = \{B, C\}K3={B,C}
- K4={D}K_4 = \{D\}K4={D}
4) 第三轮分割(针对 K2K_2K2)
我们只需要检查大小大于 1 的组,即 K2={E,T}K_2 = \{E, T\}K2={E,T} 和 K3={B,C}K_3 = \{B, C\}K3={B,C}:
-
检查 K3={B,C}K_3 = \{B, C\}K3={B,C}:
- 输入 aaa:均走向 K3K_3K3
- 输入 bbb:均走向 K4K_4K4
- 结论:不拆分。
-
检查 K2={E,T}K_2 = \{E, T\}K2={E,T}:
- 输入 aaa:E→E∈K2E \to E \in K_2E→E∈K2 且 T→T∈K2T \to T \in K_2T→T∈K2
- 输入 bbb:E→E∈K2E \to E \in K_2E→E∈K2 且 T→T∈K2T \to T \in K_2T→T∈K2
- 结论:不拆分(EEE 是原 DFA 中的死循环状态,它与引入的死状态 TTT 在逻辑上是完全等价的,算法成功将它们归为了一类)。
至此,划分已无法进一步拆分,算法收敛。
最终的等价状态组为:
- {A}\{A\}{A}
- {B,C}\{B, C\}{B,C} (BBB 与 CCC 等价)
- {D}\{D\}{D}
- {E,T}\{E, T\}{E,T} (EEE 与 TTT 等价)
五、 构造最终化简后的 DFA
我们将上述 4 个等价类作为新 DFA 的 4 个状态,分别命名为:
- S0={A}S_0 = \{A\}S0={A} (初态)
- S1={B,C}S_1 = \{B, C\}S1={B,C}
- S2={D}S_2 = \{D\}S2={D} (终态)
- S3={E,T}S_3 = \{E, T\}S3={E,T} (死状态组)
根据原转移关系,重构最简 DFA 的转移表:
| 新状态 | 输入 aaa 的转移 | 输入 bbb 的转移 | 备注 |
|---|---|---|---|
| S0S_0S0 | S1S_1S1 | S3S_3S3 | 对应原 {A}\{A\}{A},是初态 |
| S1S_1S1 | S1S_1S1 | S2S_2S2 | 对应原 {B,C}\{B, C\}{B,C} 的合并 |
| S2S_2S2 | S3S_3S3 | S3S_3S3 | 对应原 {D}\{D\}{D},是终态 |
| S3S_3S3 | S3S_3S3 | S3S_3S3 | 对应原 {E,T}\{E, T\}{E,T} 的合并 |
化简成果说明:
- 状态数由原来的 5 个(算上死状态为 6 个)缩减为了实用的 3 个 (若不画出死状态 S3S_3S3)。
- 重构后的精简 DFA 结构非常清晰:从初态 S0S_0S0 出发,输入一个 aaa 进入 S1S_1S1;在 S1S_1S1 状态下可以输入任意多个 aaa(自环),一旦输入 bbb 则进入终态 S2S_2S2。后续再输入任何字符都将无法再匹配。