作者:来自 Elastic Jeff Vestal

为你的人工智能代理使用Elasticsearch实现持久跨会话记忆:混合检索、知识图谱和跨设备交接。三条安装命令。
Elasticsearch 与行业领先的生成式 AI 工具和提供商具有原生集成。查看我们的网络研讨会,了解如何在 超越 RAG 基础 或使用 Elastic 向量数据库**构建生产就绪应用**。
为了为你的用例构建最佳搜索解决方案,可以启动一个**免费云试用,或立即在你的 本地机器**上尝试 Elastic。
当你需要 AI 代理的持久记忆时,一个常见的方案是使用专用的记忆层,例如专用的记忆编排服务和独立的向量数据库。这些都是真实的解决方案。但它们也意味着另一个服务、另一个 API、以及更多需要构建和维护的组件。如果 Elastic 搜索已经在你的技术栈中,你可能已经拥有所需的一切。
仅会话内记忆的问题
Claude Code agent 是无状态的。每个会话都从全新开始。你的 agent 不会记得昨天做出的决策,上周重构的文件,或者三天前标记的阻塞依赖。你可以在指向文件时让它读取文件,但读取文件并不等同于回忆相关上下文。
具体成本体现在以下几个方面:
-
重新推导结论。 一个没有记住之前推理的 agent 会反复读取相同文件,重新检查相同权衡,有时甚至得出不同答案。开发者会在不同会话之间遇到不一致的 agent 行为,却无法理解原因。
-
多设备摩擦。 在多台机器上工作的开发者对此感受尤其明显。如果没有跨设备记忆,切换机器意味着必须从头加载 agent 的上下文:执行
git pull,用 grep 搜索相关文件,并手动把项目状态粘贴进对话。这会在每一次交接中增加摩擦成本。 -
跨会话上下文丢失。 agent 生成的最有价值内容 ------ 架构决策、阻塞依赖的任务 ID、方法变更的理由、解释为什么选择某条路径的上下文锚点 ------ 都存在于工作内存中,并在会话结束时消失。文件提交只记录了成果产物,并不记录推理过程。
常见的解决方案是使用专用的记忆层或独立的 向量数据库。这些都是可靠的工具。但如果你已经在运行 Elasticsearch,那么在你的技术栈中再添加一个服务可能会带来不必要的开销。
你的搜索索引已经在做什么
在查看 agent-memory 之前,有必要先说明 Elasticsearch 在不做任何自定义的情况下,已经为这个问题提供了什么能力。
-
开箱即用的 Hybrid search。 Elasticsearch 结合了 BM25 词法评分与稠密的 vector search。
semantic_text字段类型可以自动处理 embedding 生成。将字段映射为semantic_text,指向一个 inference endpoint,你就可以在不自己管理 embedding 流水线的情况下获得混合检索能力。 -
通过 ES|QL 实现查询表达能力。 在 Elasticsearch 中,你的 memory 是可以通过完整查询语言访问的文档。ES|QL 支持按类型、日期范围、agent ID、访问范围或任意组合进行过滤,同时支持聚合、时间函数以及 FUSE 多 retrieval 融合。ES|QL 是一门完整的查询语言,具备聚合与时间函数能力,这比大多数 vector store 提供的轻量级 metadata 过滤更强。不过一些专用 vector store 确实在查询表达能力上更灵活,但与该类别中常见的轻量过滤 API 相比差距最大。
-
在语义评分之前进行 metadata 过滤。 按 agent 作用域隔离 memory、时间窗口过滤、基于类型过滤,这些都是 Elasticsearch 的标准查询能力。你不需要构建自定义逻辑,只需要组合已有原语。
-
通过 DECAY 实现时间衰减。 在 hybrid recall 部分会详细说明,但系统会对最近的 memory 赋予更高权重,使其排名高于过时内容。这使用 ES|QL 中的 DECAY 函数。注意:DECAY 需要 Elasticsearch 9.3+ 或 Elasticsearch Serverless。请使用 interval literal 语法 ------
45 days(而不是带引号的"45d"),因为某些 Serverless 部署会拒绝带引号的形式。如果仍然遇到类型错误(third argument of [DECAY(...)] must be [time_duration]),可以使用 fallback 评分方式:EVAL final_score = _score / (1 + DATE_DIFF("day", created_at, NOW()) / 45.0)。该 fallback 会产生等价的时间衰减效果,并且适用于所有版本。 -
你已经具备的运维能力。 监控、告警、索引生命周期管理、备份:这些在你的 Elasticsearch 部署中都已经存在。增加更多索引并不会带来新的运维面。
记忆存储的实际索引映射显示该模式非常简单:
bash
`
1. {
2. "mappings": {
3. "properties": {
4. "memory_id": { "type": "keyword" },
5. "agent": { "type": "keyword" },
6. "type": { "type": "keyword" },
7. "category": { "type": "keyword" },
8. "title": { "type": "text", "fields": { "keyword": { "type": "keyword" } } },
9. "title_semantic": { "type": "semantic_text", "inference_id": "jina-v5-embeddings" },
10. "content": { "type": "text" },
11. "content_semantic": { "type": "semantic_text", "inference_id": "jina-v5-embeddings" },
12. "tags": { "type": "keyword" },
13. "source": { "type": "keyword" },
14. "created_at": { "type": "date" },
15. "updated_at": { "type": "date" },
16. "access_scope": { "type": "keyword" }
17. }
18. }
19. }
`AI写代码semantic_text 字段(title_semantic、content_semantic)是 Jina v5 embeddings 存放的位置。Elasticsearch 在索引时通过 inference endpoint 处理 embedding 生成。你写入一个 memory document;embeddings 会被自动计算。在 Elasticsearch Serverless 上,semantic_text 默认通过 Elastic Inference Service 使用 Jina v5 text-small。
这里真正区分 Elasticsearch 的有两点:
-
查询表达能力。 ES|QL 是一门完整的查询语言,而不是一个过滤 API。你可以在同一个查询中组合基于 embedding 的检索、精确匹配、时间衰减以及聚合。
-
运维整合能力。 如果 Elasticsearch 已经在你的技术栈中,这只是一个索引,而不是一个新服务。其他向量数据库同样允许你定义 schema,但关键差异在于定义之后你能做什么,以及你是否引入了新的运维依赖。
agent-memory 架构
agent-memory 是让 Elasticsearch 能够作为 Claude Code 的 agent memory 使用的层。入口是一个叫 bridge 的 CLI。其背后有七个 Elasticsearch indices。
各组件如何组合如下:
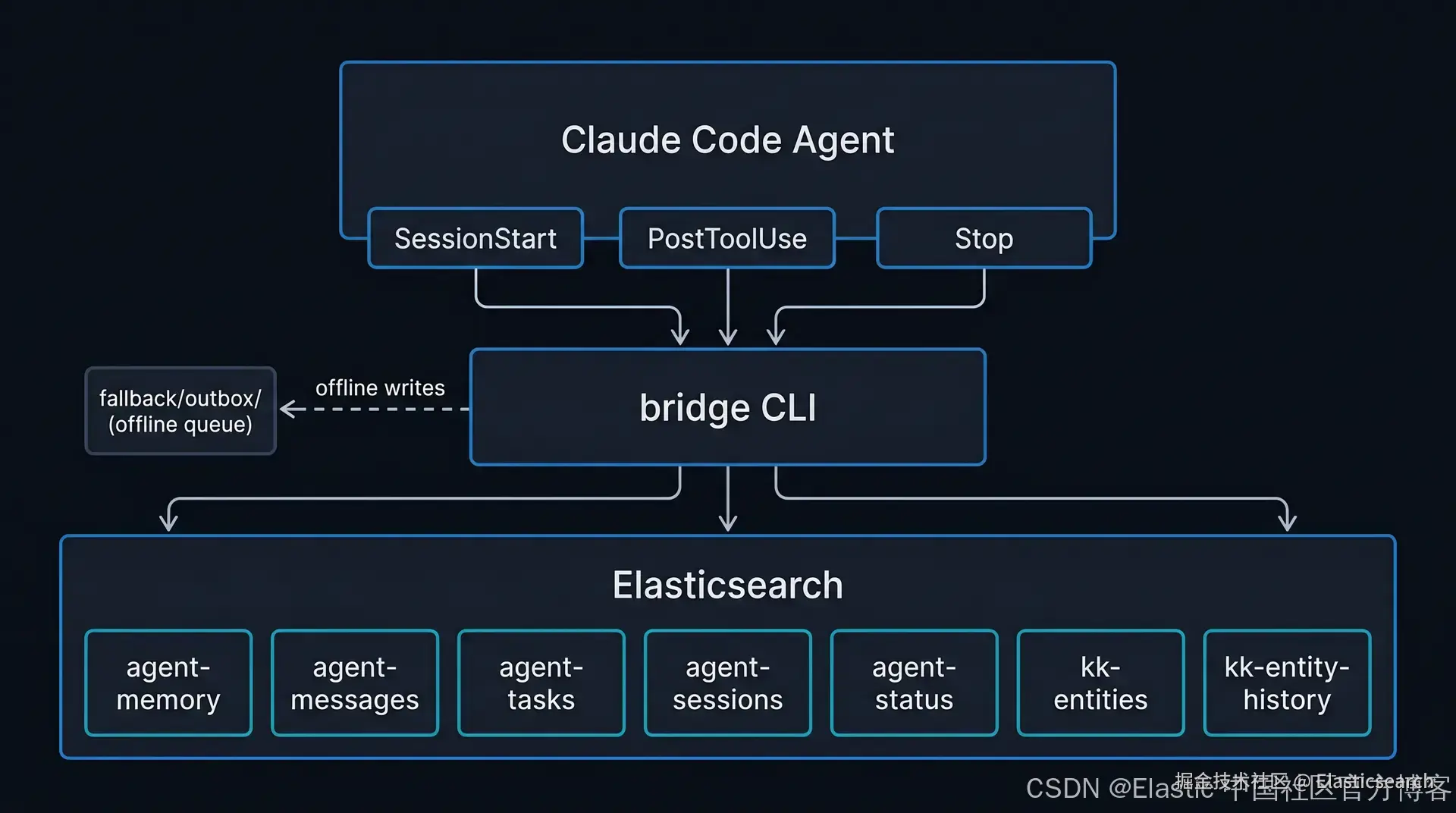
Claude Code agent 与 Elasticsearch 的通信完全通过 bridge 命令行界面(CLI)完成。三个 hooks 会将 bridge 自动接入 agent 生命周期;agent 无需显式调用。当 Elasticsearch 可访问时,bridge 会直接写入。当离线时,写入会进入本地 fallback/outbox/ 队列,以 JSON 文件形式保存,bridge sync 会在下一次在线会话时通过 bulk API 批量写回。
在 bridge 之下,Elasticsearch 保存七个索引:agent-memory(决策、模式、上下文)、agent-messages(agent 间通信)、agent-tasks(任务生命周期)、agent-sessions(动作历史)、agent-status(心跳)、{agent}-entities(markdown 知识图谱)、以及 {agent}-entity-history(用于 diff 的时间序列快照)。bridge graph 命令(search、related、check-blockers、semantic-diff 和 gen-handoff、reconcile)运行在 entity 索引之上。
七个索引
| 索引 | 存储内容 |
|---|---|
| agent-memory | 决策、模式、上下文、反馈(记忆存储) |
| agent-messages | agent 之间的类型化消息,支持线程与优先级 |
| agent-tasks | 任务生命周期:从创建到完成或失败 |
| agent-sessions | 会话级动作日志,可按 agent、时间范围或标签查询 |
| agent-status | 心跳记录:哪些 agent 处于活跃状态以及所在机器 |
| {agent}-entities | 将 markdown 文件作为可检索的知识图谱实体 |
| {agent}-entity-history | 实体状态的时间快照,用于做 temporal diff |
Hook 集成
集成点在 hooks。三个 Claude Code hooks 将系统接入 normal agent 行为,而无需显式调用:
-
SessionStart :运行
bridge sync-memories将自动 memory 文件同步到 Elasticsearch,并运行bridge heartbeat注册该 agent 处于活跃状态。 -
PostToolUse (在 Write、Edit、MultiEdit 时触发):在每一次
.md写入时调用bridge entity index-file。你的项目文件会在工作过程中持续被索引。 -
Stop :记录一个 session-end 事件到
agent-sessions。
结果是:agent 不需要记得去更新 memory,它会自动发生。SessionStart 会对本地 memory 文件进行 hash,同步并且只重新索引发生变化的文件 ------ 未变化的文件会被跳过。首次 session sync(所有文件都是新的)会比后续 session 更慢。
离线队列
当 Elasticsearch 不可用时,写入不会失败,而是会进入 fallback/{agent}/outbox/,以 JSON 文件形式保存。bridge sync(在 SessionStart 时自动调用)会在连接恢复后通过 bulk API 清空队列。你可以离线工作,不会丢失任何数据。
读取操作(bridge recall、bridge graph search)在 ES 不可用时会以非零退出码优雅失败,没有本地读取缓存。但 agent session 仍然可以正常继续,只是 memory 降级。fallback 队列没有自动大小限制;如果离线时间较长,可以使用 bridge sync --batch-size 100 来避免 bulk 请求过大。
bridge CLI 供 agent 直接使用的命令如下:
sql
`
1. # Store a decision with type and scope
2. bridge remember decision "Use Jina v5 for all embedding inference" \
3. --title "embedding model choice" \
4. --tags "ml,infrastructure" \
5. --scope shared
7. # Recall with hybrid search (default)
8. bridge recall "embedding model decisions"
10. # Recall with keyword-only (exact term matching)
11. bridge recall "Jina v5" --keyword
13. # Knowledge graph search
14. bridge graph search "blocked infrastructure projects" --types initiative --days 90
16. # Generate a cross-device handoff payload
17. bridge graph gen-handoff --hours 8
19. # Surface stale blockers
20. bridge graph check-blockers --stale-days 3
`AI写代码混合召回:记忆检索的实际工作方式
许多 agent memory 实现只使用单一的 vector lookup。查询输入后,通过 cosine similarity 找到最近邻结果并返回。这种方式在语义召回上有效,但在两种常见模式下会失败:精确词项匹配和时间新鲜度。
agent-memory 的 hybrid recall 使用了两种 fusion 策略。memory recall 查询使用 ES|QL 的 FUSE(Reciprocal Rank Fusion,k=60,ES|QL 默认值)。graph entity 查询使用 FUSE LINEAR 并显式设置权重 ------ 0.3 BM25 / 0.7 semantic ------ 因为 entity search 更依赖语义匹配。下面是来自 lib/memory.sh 的 memory recall 查询:
less
`
1. FROM agent-memory METADATA _id, _score, _index
2. | FORK (
3. WHERE (access_scope == "shared" OR access_scope == "kk-only" OR agent == "kk")
4. AND (content:"vector search" OR title:"vector search" OR tags:"vector search")
5. | SORT _score DESC | LIMIT 50
6. ) (
7. WHERE (access_scope == "shared" OR access_scope == "kk-only" OR agent == "kk")
8. AND content_semantic:"vector search"
9. | SORT _score DESC | LIMIT 50
10. )
11. | FUSE
12. | EVAL final_score = _score * DECAY(created_at, NOW(), 45 days)
13. | EVAL display = COALESCE(title, SUBSTRING(content, 1, 80))
14. | SORT final_score DESC | LIMIT 5
15. | KEEP memory_id, type, display, access_scope, agent
`AI写代码FORK 并行运行两种检索:第一条分支是在 title、content 和 tags 上进行 BM25 词法检索 ;第二条分支是在 content_semantic 字段上进行 语义检索 。FUSE 使用 Reciprocal Rank Fusion 将两个排序列表合并。DECAY 函数基于 created_at 应用时间权重。
为什么 hybrid 优于纯语义的 agent memory
关键词检索可以捕捉语义搜索遗漏的精确引用。如果 agent 存储了一条 memory:"task ID kk-task-20260428-deploy-blocker",那么对 "deploy blocker" 的语义查询会找到概念上相似的内容,但这个具体的 task ID 只会在 BM25 分支中获得较高排名。如果没有它,你只能得到概念,而无法得到需要的引用。
语义检索可以捕捉精确匹配遗漏的相关概念。一条 memory 标题是 "switched default chunking strategy to sentence-level for better recall on short queries",即使查询是 "chunking config",两者词面不重合,这条记录仍然相关。语义分支可以找到它,而仅靠关键词搜索无法做到。
BRIDGE_MEMORY_DECAY_WINDOW 变量(默认 45d)设置时间衰减函数的半衰期。今天写入的 memory 比 90 天前写入的 memory 得分更高(其他条件相同)。这反映了 agent memory 的实际使用方式:最近上下文几乎总是比旧上下文更相关,即使旧上下文在语义上更接近查询。
lib/graph.sh 中的 graph search 使用 FUSE LINEAR(而不是普通 FUSE),因为 entity recall 更依赖语义匹配而不是关键词精确匹配。下面是该查询:
sql
`
1. FROM kk-entities METADATA _id, _score, _index
2. | FORK (
3. WHERE MATCH(title, "vector search projects") OR MATCH(content, "vector search projects")
4. | WHERE updated_at >= NOW() - 180 days
5. | SORT _score DESC | LIMIT 20
6. ) (
7. WHERE MATCH(title_semantic, "vector search projects") OR MATCH(content_semantic, "vector search projects")
8. | WHERE updated_at >= NOW() - 180 days
9. | SORT _score DESC | LIMIT 20
10. )
11. | FUSE LINEAR WITH { "weights": { "fork1": 0.3, "fork2": 0.7 }, "normalizer": "minmax" }
12. | SORT _score DESC | LIMIT 10
13. | KEEP _id, entity_id, entity_type, title, status, priority, updated_at
`AI写代码The FUSE LINEAR 语法带有显式权重是你在 ES|QL 中调优 BM25 / 语义平衡的方式。将权重向 0 调整会获得更强的关键词精确匹配;向 1 调整会获得更强的语义泛化。
知识图谱层
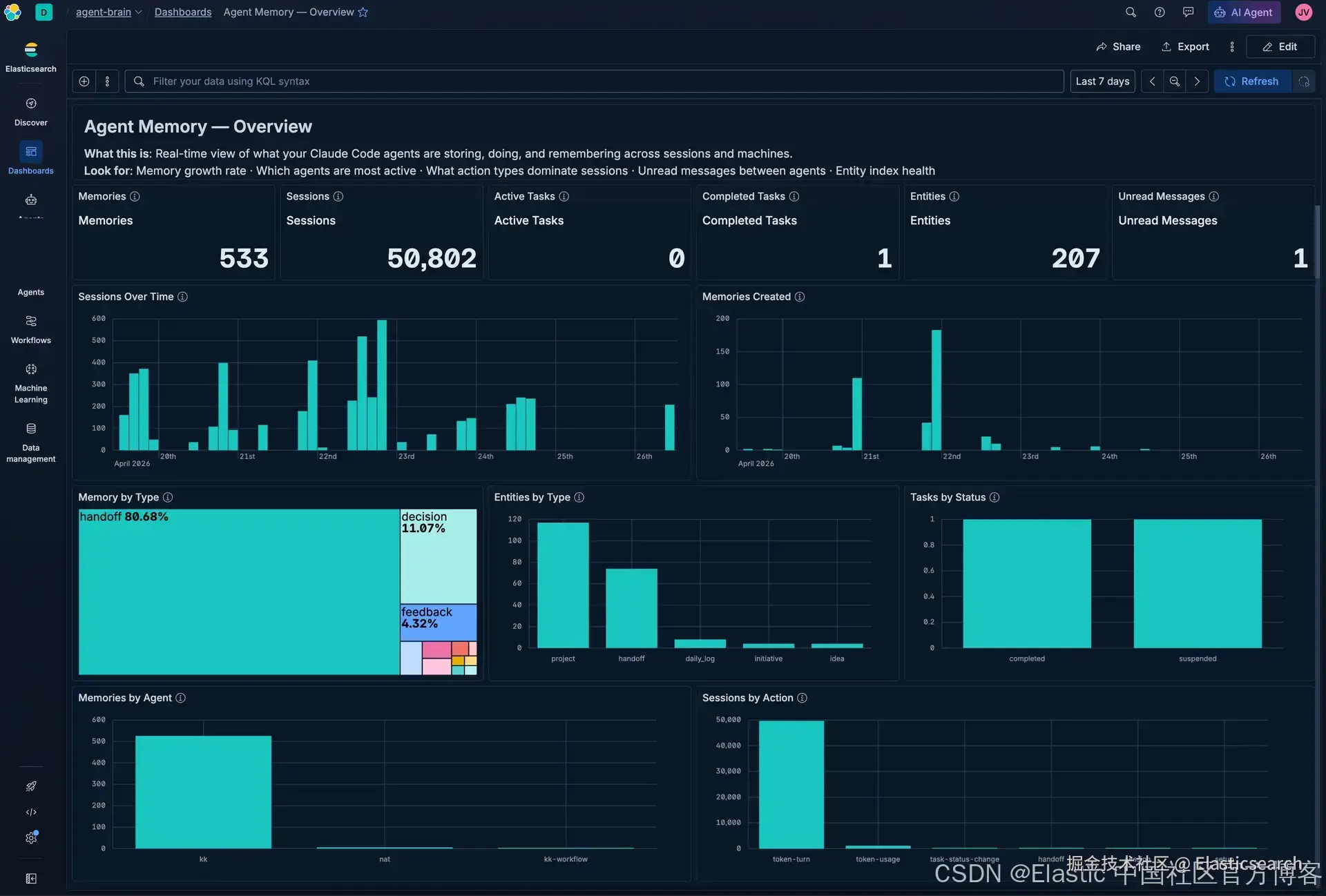
来自一个正在运行的实例的数据:每个项目、决策以及被阻塞的依赖关系都跨会话进行跟踪;大约有 1,364 条关系边是从 frontmatter 字段(initiative、blocked_by、depends_on)解析出来的。这些数据来自一个 Kuchi Kopi agent 实例,它在两台笔记本电脑上已经持续运行了数个月。
需要先明确一点:这不是一个图数据库。遍历深度被限制在 2,没有 Cypher 查询语言或属性图模型,并且一致性完全依赖 frontmatter 的规范性。它本质上是一个可查询的实体层,拥有足够的关系数据来暴露 agent 工作中的阻塞项和差异。
这个索引所保存的内容,是 agent 自身随时间产生的工作记录(决策、项目状态以及被阻塞的依赖),而不是一个经过整理的外部事实或世界知识的 知识库。检索通过 embedding 相似度和 BM25 在这些工作记录上进行。
实体层是构建在 Elasticsearch 文档之上的知识图谱。每一个被监控目录中的 markdown 文件都会通过 PostToolUse hook 被索引为一个实体。实体 ID 采用 {agent}-{type}-{slug} 的格式,这使得重新 indexing 是幂等的。重写文件时,实体会在原地更新。关系边从三个 frontmatter 字段中提取:initiative(项目分组)、blocked_by(依赖关系)以及 depends_on(软依赖)。实体 ID 通过 {agent} 前缀进行命名空间隔离------不会检查跨 agent 的冲突,因此运行多个 agent 的团队需要确保 agent 标识符唯一。
图谱命令在这个索引之上运行:
bash
`
1. # Hybrid semantic search across all entities
2. bridge graph search "infrastructure blockers"
4. # Traverse relationships from a specific entity (depth 1 or 2)
5. bridge graph related kk-initiative-platform --depth 2 --rel-type blocks
7. # Surface stale blocked or waiting entities
8. bridge graph check-blockers --stale-days 3
10. # Diff entity state between two dates
11. bridge graph semantic-diff 2026-04-01 2026-04-20
13. # Generate a structured context payload for cross-device handoff
14. bridge graph gen-handoff --hours 8
16. # Remove ES entities whose source files no longer exist
17. bridge graph reconcile
`AI写代码关系边是从 markdown 文件中的 frontmatter 字段(initiative、blocked_by、depends_on)推断出来的。这个图谱不需要单独的关系存储,它直接读取你已有的文档结构。
图谱之所以是连贯的,是因为 markdown 文件具有结构化 frontmatter,而系统会持续一致地读取这些结构。schema 纪律性是其可用性的关键。如果你的文件没有一致的 frontmatter 字段,图谱会退化为扁平的实体搜索。缺失或格式错误的 frontmatter 字段会导致关系边被静默跳过;实体仍然会被索引,但不会出现在图遍历中。运行 bridge graph reconcile 可以找出缺失关系的实体。实体删除不会级联,而 bridge graph reconcile 也会清理指向已删除实体的边。
从规模来看,这套系统已经在数百个实体、跨数月的实际使用中得到验证。Elasticsearch 理论上可以处理更大规模的数据,但 agent-memory 本身没有做过大规模压力测试。对于更大的实体集合,可以使用 --types 和 --days 过滤器来限定遍历范围。
graph semantic-diff 命令是其中一个非常有用的应用。它用于比较两个日期之间的实体状态快照:新增实体、状态变化、新增阻塞工作以及已完成项目。在每周同步之前运行它,可以生成一个结构化的变更日志,而不需要逐条读取 session log。注意:如果请求的时间范围内没有实体快照,该命令会返回错误(Cannot iterate over null)。需要先运行 bridge entity index-all 来生成初始快照基线。
跨设备记忆在实践中的表现
我在出差笔记本上启动了一个 session,三天后在公司台式机上继续处理同一个项目,这两个公司机器上都在工作。agent 在一次 search round-trip 内就回忆起了相关 memory entries。没有等待 git pull。没有通过文件扫描来重建上下文。跨设备交接通过 Elasticsearch 完成。
原因如下:我在两台机器之间工作,而 Elasticsearch 可以从两端访问。共享 index 是唯一事实来源,而不是本地文件系统。agent 调用 bridge recall,并从共享 index 获取上下文,而不管是哪台机器存储的。
没有 agent-memory:Git repository 之外没有任何内容。agent 可以读取文件,但无法回忆上一轮 session 的推理过程、没有写入 commit 的决策、或者已经标记但尚未解决的阻塞依赖。
有 agent-memory:SessionStart hook 会运行 bridge sync-memories,读取 Claude Code 自动 memory 文件(~/.claude/projects/<cwd>/memory/*.md),对每个文件进行 hash,并只将发生变化的文件重新写入 Elasticsearch。本地 memory 文件在每台机器上都作为事实来源,而 bridge sync-memories 会将本地状态推送到 Elasticsearch。在另一台机器上未同步的更改,在切换时会被新机器的本地状态覆盖。来自两台设备的并发写入由 Elasticsearch 的 document versioning 正确处理。不会丢失数据,但每个 document 是 last write wins,因此应避免在两台机器同时编辑同一个 memory 文件。
需要如实说明:这依赖 Elasticsearch Serverless(或任何可被两台机器访问的 Elasticsearch 实例)。部署在 VPN 或防火墙后的自建 Elasticsearch 也可以工作,但连接性要求是真实存在的。这不是一个纯本地方案。
bridge graph gen-handoff 命令会生成一个结构化 JSON payload,包含时间窗口内更新的 entities、active blockers 和最近 session logs。使用可选的 --synthesize 参数时,会通过 Agent Builder agent 生成一段叙述性段落。该 payload 就是新 session 用来重建上下文而无需逐个读取文件的输入。
什么时候这是正确答案(以及什么时候不是)
这种方案在以下情况下效果很好:
-
Elasticsearch 已经在你的技术栈中。 在现有部署上增加 indices 代价很低,运维模型是熟悉的。
-
查询表达能力很重要。 你希望用完整 query language 将 memory 当作数据来查询,而不是 vendor filter API。
-
你的 agent 产出结构化 artifact。 带一致 frontmatter 的 markdown 文件让 knowledge graph 保持一致性。如果 agent 不产生结构化输出,这一层价值有限。
-
你需要跨设备或跨 agent memory。 共享 Elasticsearch index 可以实现这一点,而不需要额外基础设施。
以下情况 purpose-built memory service 更优:
-
你没有现成的 search infrastructure。 用 Elasticsearch 解决 memory 问题是合理的,但这是一个明显的基础设施投入。
-
你希望纯语义 recall 且零 schema 管理。 专用 vector database service 会完全抽象 index mapping。如果你不想处理 mapping 和 fields,这种取舍是有价值的。
-
你预期 schema 高频演进。 你控制的 schema 同时也是你维护的 schema。如果 memory 结构经常变化,index mapping 的迁移成本可能超过灵活性收益。托管服务通常会帮你处理 schema evolution。
-
你需要低运维 SaaS。 Elasticsearch Serverless 已经显著缩小了差距,但仍然不是零运维。
诚实总结:agent-memory 不是通用答案。它是在你已经运行 Elasticsearch,并且不想在 AI 技术栈中再增加一个依赖时的正确答案。
开始使用
三条命令即可运行系统:
bash
`
1. git clone https://github.com/jeffvestal/agent-memory && cd agent-memory
2. ./install.sh
3. ./bridge status
`AI写代码install.sh 会交互式引导你输入凭据(或读取已有的 .env),如果不存在则创建 Jina v5 语义 inference endpoint,创建所有七个索引并使用正确的 mappings,并安装 Claude Code hooks。它是幂等的(同一个操作执行一次和执行多次,结果都是一样的,不会产生额外副作用)。如果出错或者你添加了新机器,可以重新运行它。
在运行 installer 之前需要了解几件事:
-
Jina v5 inference endpoint :在自建 Elasticsearch 上,installer 会创建该 endpoint,但需要在
service_settings中配置 Jina API key。在 Elasticsearch Serverless 上,Elastic Inference Service 会自动提供 Jina v5,不需要 API key;installer 会检测 Serverless 并跳过这一步。 -
Elasticsearch Serverless vs. 9.3+ :两者都可以使用。
DECAY函数和FUSE语法用于 recall queries,需要 Serverless 或 Elasticsearch 9.3+。 -
Dashboard import :Kibana dashboard(位于
setup/dashboards/)会在.env中设置KIBANA_URL时由install.sh自动导入。如果你跳过这一步,可以设置KIBANA_URL后重新运行install.sh(它是幂等的)。
你需要:
-
一个 Elasticsearch Serverless endpoint(或 Elasticsearch 9.3+)。
-
一个具有
agent-*索引权限的 API key。 -
本地安装
jq(macOS 上可用brew install jq)。
在 bridge status 确认连接之后,运行:
python
`
1. bridge entity index-all # index existing markdown files
2. bridge remember decision "First memory --- install confirmed working" --title "setup"
3. bridge recall "install" # confirm hybrid recall works
`AI写代码然后把 hooks/settings.json.template 中的 hooks 添加到你的 Claude Code settings.json 中。从那一刻起,每次 session start、文件写入和 session end 都会自动更新 memory store。
完整源码(包括用于 memory analytics 的 Kibana dashboard)在这里:github.com/jeffvestal/...
可以直接在你的 agent 上试用。如果你遇到问题,或者把它扩展到其他 AI 框架,可以提交 issue 或 PR。
常见问题
什么是 agent memory,为什么 AI agent 需要它?
像 Claude Code 这样的 AI agent 是跨 session 无状态的:一旦 session 结束,它们不会保留之前的对话、决策或上下文。agent memory 是一个持久化存储系统,让 agent 可以跨 session 和设备回忆之前的推理、决策和项目上下文。没有它,agent 会反复重新推导结论,在多设备工作流中丢失上下文,并且无法在已有工作的基础上继续构建。
Elasticsearch 能否替代专用 vector database 来做 agent memory?
对于已经在使用 Elasticsearch 的团队来说,可以,而且还有明显优势。Elasticsearch 通过 semantic_text 字段提供 BM25 + 语义 hybrid search,通过 ES|QL 提供结构化 memory 查询能力、metadata 过滤以及时间衰减评分。代价是你需要自己管理 schema 和运维体系。如果你没有现成的 search infrastructure,专用 vector database 的托管抽象会更合适。
hybrid search 如何提升 agent memory 召回,相比纯语义搜索有什么优势?
纯语义搜索只能匹配概念相似内容,但会遗漏精确引用:task ID、文件名、具体版本号等。纯关键词搜索可以捕捉精确匹配,但会遗漏相关概念。hybrid search(BM25 + Jina v5 dense vectors 通过 Reciprocal Rank Fusion 组合)可以同时覆盖两者。在实践中,这意味着无论是概念查询还是具体标识符查询,都能召回正确的 memory。
什么是 agent-memory 项目,如何安装?
agent-memory 是一个开源层,用于给 Claude Code agent 提供基于 Elasticsearch 的持久化跨 session、跨设备 memory。通过三条命令即可安装。installer 会自动创建 Elasticsearch indices 和 inference endpoint。
跨设备 memory 如何在多台机器之间工作?
在 session start 时,SessionStart hook 会运行 bridge sync-memories,将 Claude Code 的 auto-memory 文件同步到 Elasticsearch。由于多台机器连接的是同一个 Elasticsearch 实例,因此无论在哪台机器写入,都可以被统一检索。切换 laptop 时不需要 git pull 或手动重建上下文。agent 通过 bridge recall 从共享 index 获取上下文。
使用 Elasticsearch 作为 agent memory 系统有哪些限制?
主要限制包括:跨设备 memory 需要 Elasticsearch Serverless 或可网络访问的 cluster,因此不是纯本地方案。knowledge graph traversal 深度限制为 2。图谱一致性依赖 markdown frontmatter 的规范性,schema 不一致会降低质量。相比托管 memory SaaS,Elasticsearch 需要更多初始配置。在长时间离线情况下可以本地运行 session,并在恢复连接后用 bridge sync 手动同步,fallback queue 不会丢数据。导出或归档 memory 可以使用 bridge export --format ndjson 生成可用于 Elasticsearch bulk import 的文件。
BRIDGE_MEMORY_DECAY_WINDOW 是什么,它如何影响 recall?
BRIDGE_MEMORY_DECAY_WINDOW 定义了 memory recall score 的时间衰减半衰期,默认是 45d(45 天)。今天写入的 memory 比 90 天前写入的 memory 得分更高(其他条件相同)。这反映了 agent context 的实际特性:最近决策通常比旧决策更重要,即使旧内容在语义上更接近查询。你可以增大该窗口让旧 memory 更有竞争力,或者减小它以更强地强调新鲜度。
原文:Persistent memory for agents: Claude Code on Elasticsearch - Elasticsearch Labs