二叉树遍历与红黑树的完美平衡艺术------从递归崩溃到自平衡的硬核拆解
一、面试真题引入
先说一个真实发生过的面试场景:
"用非递归写一个二叉树的中序遍历。"
"......我能用递归吗?"
"递归当然可以,但递归本质是系统栈帮你在做,你能自己用栈模拟吗?"
"......"
这个场景在很多大厂面试中反复上演。递归写法谁都会------三行代码的事。但面试官想看的是:你对递归底层机制的理解、你能否在不能用递归的场合(比如嵌入式、深度极大的树)自己写出来。
更狠的追问还在后面:
"AVL 树和红黑树有什么区别?为什么 JDK 选了红黑树?"
这个问题直接考验你对数据结构设计的工程权衡有没有概念------不是背定义,是理解"为什么"。
本期读完,你将获得:
- 四种遍历的非递归手写能力(面试手撕代码稳拿分)
- 红黑树自平衡三步操作的一眼看懂
- 一道大厂面试连环炮的标准答案
- 一个可运行的公司组织架构建模案例
二、底层的时空解构与源码透视
2.1 树的分类:三句话讲清
| 类型 | 定义 | 关键性质 |
|---|---|---|
| 满二叉树 | 除叶子外每个节点都有两个子节点 | 深度 k 时节点数 = 2^k - 1 |
| 完全二叉树 | 从上到下、从左到右填满,最后一层可不满 | 适合数组存储,父节点下标 i 时左子 = 2i+1 |
| 二叉搜索树(BST) | 左子树 < 根 < 右子树 | 中序遍历即升序序列 |
一句话记忆:满二叉树讲"对称",完全二叉树讲"紧凑",BST 讲"有序"。
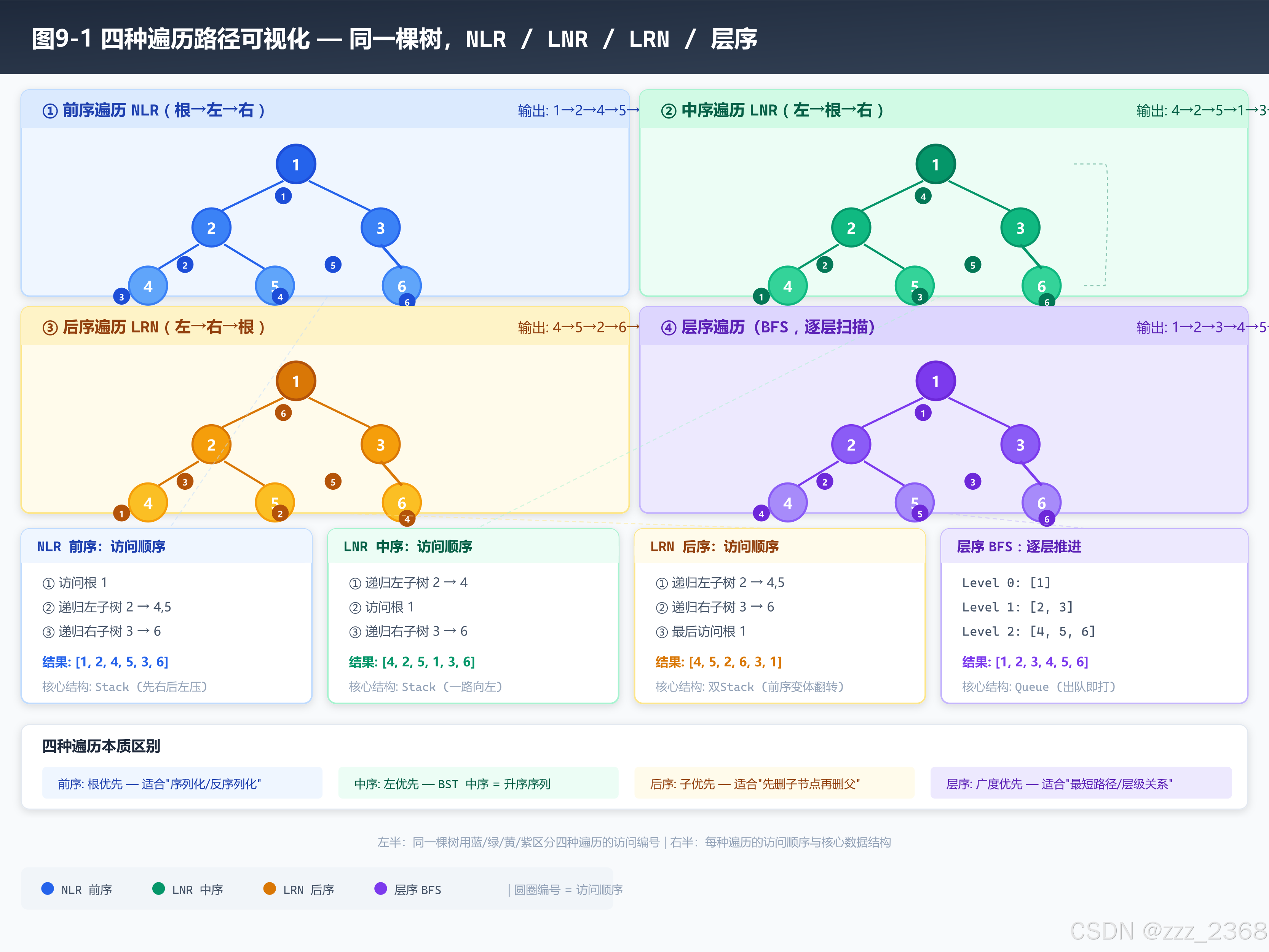
2.2 四种遍历:非递归才是真功夫
先看一棵示例树:
1
/ \
2 3
/ \ \
4 5 6前序遍历(NLR):根 → 左 → 右
递归版(人人会写):
java
void preOrder(Node root) {
if (root == null) return;
System.out.print(root.val + " ");
preOrder(root.left);
preOrder(root.right);
}
// 输出:1 2 4 5 3 6非递归版(手撕代码重点):
java
void preOrderNR(Node root) {
if (root == null) return;
Deque<Node> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
Node node = stack.pop();
System.out.print(node.val + " ");
if (node.right != null) stack.push(node.right); // 先右后左
if (node.left != null) stack.push(node.left);
}
}
// 输出:1 2 4 5 3 6记忆技巧:前序最简单------根入栈 → 弹出打印 → 右子入栈 → 左子入栈。为什么先右后左?因为栈是后进先出,我们要先处理左子。
中序遍历(LNR):左 → 根 → 右
递归版:
java
void inOrder(Node root) {
if (root == null) return;
inOrder(root.left);
System.out.print(root.val + " ");
inOrder(root.right);
}
// 输出:4 2 5 1 3 6非递归版:
java
void inOrderNR(Node root) {
Deque<Node> stack = new ArrayDeque<>();
Node curr = root;
while (curr != null || !stack.isEmpty()) {
while (curr != null) { // 一路向左,沿路压栈
stack.push(curr);
curr = curr.left;
}
curr = stack.pop(); // 左到头了,弹出打印
System.out.print(curr.val + " ");
curr = curr.right; // 转向右子树
}
}
// 输出:4 2 5 1 3 6记忆技巧 :中序最经典------一路向左走到黑,弹出一个转向右。
后序遍历(LRN):左 → 右 → 根
非递归版(最难的,用双栈法记):
java
void postOrderNR(Node root) {
if (root == null) return;
Deque<Node> stack1 = new ArrayDeque<>();
Deque<Node> stack2 = new ArrayDeque<>();
stack1.push(root);
while (!stack1.isEmpty()) {
Node node = stack1.pop();
stack2.push(node); // 模拟"根→右→左",反序入栈2
if (node.left != null) stack1.push(node.left);
if (node.right != null) stack1.push(node.right);
}
while (!stack2.isEmpty()) { // 反转得到真正的"左→右→根"
System.out.print(stack2.pop().val + " ");
}
}
// 输出:4 5 2 6 3 1记忆技巧:后序 = 前序变体。前序是「根→左→右」,把左右顺序改为「根→右→左」入辅助栈,反转即得「左→右→根」。
层序遍历(BFS):逐层扫描
java
void levelOrder(Node root) {
if (root == null) return;
Queue<Node> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
Node node = queue.poll();
System.out.print(node.val + " ");
if (node.left != null) queue.offer(node.left);
if (node.right != null) queue.offer(node.right);
}
}
// 输出:1 2 3 4 5 6四种遍历对比速记表
| 遍历 | 顺序 | 非递归核心结构 | 一句话 |
|---|---|---|---|
| 前序 | 根→左→右 | 栈(先右后左压) | 根入栈,弹出即打 |
| 中序 | 左→根→右 | 栈(一路向左) | 一路向左,弹出转右 |
| 后序 | 左→右→根 | 双栈(前序变体翻转) | 前序左右换,反转得后序 |
| 层序 | 逐层 | 队列 | 出队打印,左右子入队 |
2.3 二叉搜索树(BST):为什么有序但会退化
BST 的核心规则:左 < 根 < 右。查找路径沿着这条规则一路向下,理想情况下 O(log n)。
但理想是理想,现实是:
插入顺序:1 → 2 → 3 → 4 → 5 → 6
BST 变成了:
1
\
2
\
3
\
4
\
5
\
6退化成一条链,查找退化为 O(n)。这就是为什么需要"平衡"------红黑树登场。
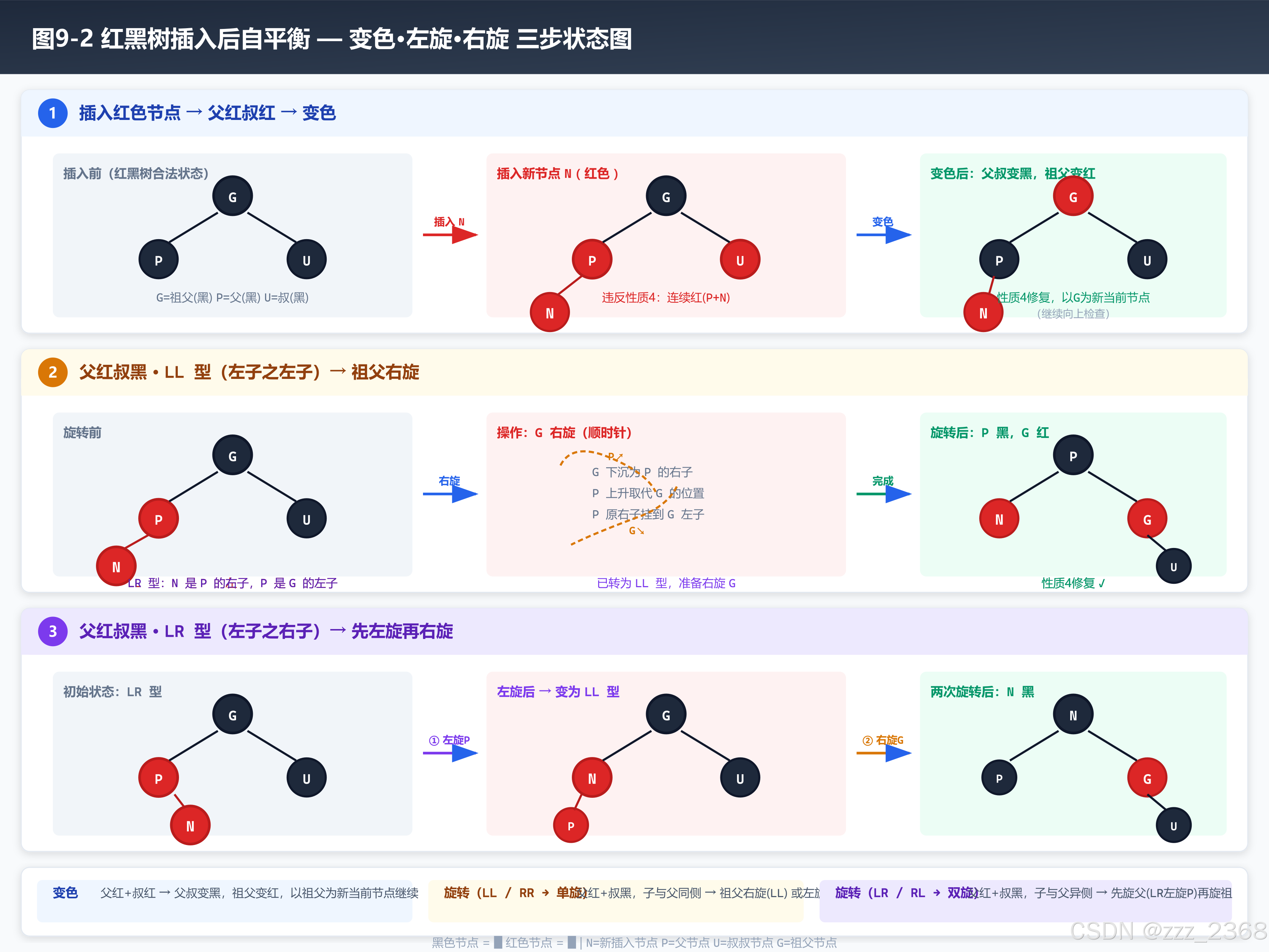
2.4 红黑树五大性质与自平衡三步
红黑树是一种自平衡二叉搜索树,通过五条规则和三种操作维持近似平衡。
五大性质(必须全部满足):
| # | 性质 | 作用 |
|---|---|---|
| 1 | 节点非红即黑 | 用颜色标记平衡状态 |
| 2 | 根节点是黑色 | 保证树顶稳定 |
| 3 | 每个叶子(NIL)是黑色 | 统一空节点处理 |
| 4 | 红色节点的两个子节点必须是黑色 | 禁止连续红(防止路径失衡) |
| 5 | 从任一节点到其每个叶子的路径上黑色节点数相同 | 核心:黑高一致保证平衡 |
性质 5 是灵魂:它保证了从根到叶子的最长路径不超过最短路径的 2 倍(最极端情况:全黑 vs 红黑交替),从而保证 O(log n)。
三种自平衡操作:
| 操作 | 触发条件 | 效果 |
|---|---|---|
| 变色 | 父红叔红 | 父叔变黑,祖父变红,以祖父为当前节点继续向上修复 |
| 左旋 | 父红叔黑,且当前节点是右子 | 逆时针旋转,降低右子树高度 |
| 右旋 | 父红叔黑,且当前节点是左子 | 顺时针旋转,降低左子树高度 |
一句话总结自平衡流程:新插节点必红色 → 父黑则无事 → 父红则看叔叔 → 叔红就变色 → 叔黑就旋转(LR 型先左旋再右旋,RL 型先右旋再左旋)。
2.5 AVL 树 vs 红黑树:面试必问的工程权衡
| 维度 | AVL 树 | 红黑树 |
|---|---|---|
| 平衡条件 | 严格:左右子树高度差 ≤ 1 | 宽松:最长路径 ≤ 2×最短路径 |
| 查询性能 | 略优(更平衡,树更矮) | 略差(树稍高) |
| 插入/删除代价 | 高(旋转次数多) | 低(最多旋转 2~3 次) |
| 适用场景 | 读多写少(数据库索引、字典) | 读写均衡(Java HashMap/TreeMap、Linux CFS 调度器、epoll) |
为什么 JDK 选红黑树? Java 的 HashMap/TreeMap 插入和删除操作极其频繁,AVL 树每次插入都可能触发多次旋转------红黑树用"不那么严格的平衡"换来了更高的写入吞吐量。这是一个经典的读写性能的工程权衡。
三、"纯手工、零依赖"原创案例实战
案例:公司组织架构建模
假设一家公司的层级结构:CEO → VP(技术)/VP(市场) → 各 Director → 各 Manager。用树结构建模,支持三种操作:
- 按层级打印组织架构(层序遍历)
- 查找某个员工的所有下属(前序遍历子树)
- 按汇报线打印(中序遍历,BST 模式下)
java
// OrgTree.java ------ 公司组织架构建模,基于 JDK 17
import java.util.*;
public class OrgTree {
static class Employee {
String name;
String title; // CEO / VP / Director / Manager
List<Employee> subordinates = new ArrayList<>();
Employee(String name, String title) {
this.name = name;
this.title = title;
}
void addSubordinate(Employee e) {
subordinates.add(e);
}
}
// --- 层序遍历:按层级打印组织架构 ---
public void printOrgChart(Employee root) {
if (root == null) return;
Queue<Employee> queue = new LinkedList<>();
queue.offer(root);
int level = 0;
while (!queue.isEmpty()) {
int levelSize = queue.size();
System.out.println("\n===== Level " + level + " =====");
for (int i = 0; i < levelSize; i++) {
Employee emp = queue.poll();
System.out.println(" [" + emp.title + "] " + emp.name);
for (Employee sub : emp.subordinates) {
queue.offer(sub);
}
}
level++;
}
}
// --- 前序遍历:查找某员工的所有下属(递归版,清晰直观) ---
public List<String> findAllSubordinates(Employee root, String targetName) {
List<String> result = new ArrayList<>();
findSubordinatesDFS(root, targetName, false, result);
return result;
}
private boolean findSubordinatesDFS(Employee node, String target,
boolean found, List<String> result) {
if (node == null) return found;
if (found) {
result.add(node.name + " (" + node.title + ")");
}
if (node.name.equals(target)) {
found = true;
}
for (Employee sub : node.subordinates) {
found = findSubordinatesDFS(sub, target, found, result);
}
return found;
}
// --- 前序遍历非递归版:完整遍历(面试手撕代码常客) ---
public void preOrderNR(Employee root) {
if (root == null) return;
Deque<Employee> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
Employee emp = stack.pop();
System.out.println(" " + emp.name + " - " + emp.title);
// 子节点倒序压栈(先压最后一个,确保第一个子节点先弹出)
List<Employee> subs = emp.subordinates;
for (int i = subs.size() - 1; i >= 0; i--) {
stack.push(subs.get(i));
}
}
}
// --- 构建示例公司 ---
public static Employee buildDemoCompany() {
Employee ceo = new Employee("张总", "CEO");
Employee vpTech = new Employee("李VP", "VP-技术");
Employee vpMarket = new Employee("王VP", "VP-市场");
ceo.addSubordinate(vpTech);
ceo.addSubordinate(vpMarket);
Employee dirBackend = new Employee("赵导", "Director-后端");
Employee dirFrontend = new Employee("钱导", "Director-前端");
vpTech.addSubordinate(dirBackend);
vpTech.addSubordinate(dirFrontend);
Employee dirBrand = new Employee("孙导", "Director-品牌");
vpMarket.addSubordinate(dirBrand);
Employee mgrUser = new Employee("周经", "Manager-用户组");
Employee mgrOrder = new Employee("吴经", "Manager-订单组");
dirBackend.addSubordinate(mgrUser);
dirBackend.addSubordinate(mgrOrder);
Employee mgrUI = new Employee("郑经", "Manager-UI组");
dirFrontend.addSubordinate(mgrUI);
Employee mgrAd = new Employee("冯经", "Manager-投放组");
dirBrand.addSubordinate(mgrAd);
return ceo;
}
// --- main 演示 ---
public static void main(String[] args) {
Employee ceo = buildDemoCompany();
OrgTree org = new OrgTree();
System.out.println("=== 公司组织架构(层序遍历) ===");
org.printOrgChart(ceo);
System.out.println("\n=== 前序遍历(非递归) ===");
org.preOrderNR(ceo);
System.out.println("\n=== 查找「赵导」(Director-后端)的所有下属 ===");
List<String> subs = org.findAllSubordinates(ceo, "赵导");
subs.forEach(s -> System.out.println(" -> " + s));
System.out.println("\n=== 查找「李VP」(VP-技术)的所有下属 ===");
subs = org.findAllSubordinates(ceo, "李VP");
subs.forEach(s -> System.out.println(" -> " + s));
}
}输出效果:
=== 公司组织架构(层序遍历) ===
===== Level 0 =====
[CEO] 张总
===== Level 1 =====
[VP-技术] 李VP
[VP-市场] 王VP
===== Level 2 =====
[Director-后端] 赵导
[Director-前端] 钱导
[Director-品牌] 孙导
===== Level 3 =====
[Manager-用户组] 周经
[Manager-订单组] 吴经
[Manager-UI组] 郑经
[Manager-投放组] 冯经代码解析:
printOrgChart()正是层序遍历(BFS),每层结束时记录 levelSize,实现按级换行findAllSubordinatesDFS()是前序遍历变体------找到目标后,其子树所有节点都加入结果preOrderNR()是非递归前序遍历,用栈模拟递归,子节点倒序压栈保证遍历顺序正确
四、源码避坑指南
坑①:层序遍历忘了 levelSize
java
// ❌ 错误写法:无法区分层级
while (!queue.isEmpty()) {
Employee emp = queue.poll();
System.out.println(emp.name); // 全挤在一起,不知道谁在哪层
}
// ✅ 正确写法:每层先记录当前层节点数
int levelSize = queue.size();
for (int i = 0; i < levelSize; i++) {
Employee emp = queue.poll();
// ...
}坑②:非递归后序遍历用单栈硬刚
后序遍历的非递归有单栈法(需要记录上次访问节点),逻辑极其绕。工程中推荐双栈法------思路清晰,面试时不容易翻车。上面代码已用双栈法实现。
坑③:红黑树插入忘了"以祖父为当前节点继续向上"
插入修复不是一步到位的。父红叔红变色后,祖父变成红色必须作为新的当前节点重新检查------因为祖父变红后可能与曾祖父产生连续红冲突。这是一个循环过程,不是 if-else。
五、大厂面试连环炮
面试官:"刚才你提到了树的遍历,你能用非递归实现一棵二叉树的中序遍历吗?"
回答要点 :栈模拟,一路向左走到黑,弹出打印,转向右子树。把上面 2.2 节的 inOrderNR() 写出来即可。关键说出 "时间复杂度 O(n),空间复杂度 O(h),h 为树高,最坏 O(n)"------这句话能让面试官知道你不只是背代码。
面试官:"层序遍历呢?如果要求按层输出呢?"
回答要点 :队列 + levelSize 计数。说清楚 queue.size() 在进入 for 循环前就取好值,因为循环内会动态增删队列。
面试官:"AVL 树和红黑树有什么区别?为什么 HashMap 选红黑树?"
标准答案:
"AVL 树追求严格平衡(高度差 ≤ 1),查询性能略优但插入删除需多次旋转;红黑树用宽松的平衡条件(最长路径 ≤ 2×最短路径),牺牲少量查询性能换取更高的写入吞吐量。HashMap 的插入和删除频率极高,红黑树最多旋转 2~3 次就能恢复平衡,而 AVL 树可能沿路径一路旋转到根。这是一个读写性能的工程权衡------JDK 选择了更适合高频写入的红黑树。"
加分项:提到红黑树的典型应用不止 Java------Linux 的 CFS 调度器、epoll 的事件管理、nginx 的定时器,都用红黑树。这说明你的知识面不局限于 Java。
面试官:"红黑树的五大性质,能说全吗?"
回答要点 :①非红即黑 ②根黑 ③叶黑(NIL) ④不连续红 ⑤黑高一致。重点解释性质 5 为什么是灵魂------它保证了最长路径 ≤ 2×最短路径,从而保证 O(log n)。
面试官(终极追问):"如果我让你设计一个数据结构,读操作占 99%,写操作占 1%,你选 AVL 还是红黑树?"
答案:选 AVL。因为读多写少的场景,AVL 更平衡带来的查询优势能覆盖偶尔写入的旋转开销。但如果读写比变成 50:50,红黑树是更合理的选择。
六、通俗类比小结
走迷宫类比:
- 前/中/后序遍历像一个人走迷宫------选定方向,一条路走到黑,碰壁再回头(DFS / 深度优先)
- 层序遍历像雷达扫描------以起点为圆心,一圈一圈往外扩展,不放过任何一个角落(BFS / 广度优先)
- 红黑树像迷宫里有五条交通规则------不能连续两个红灯(性质 4),每条路红灯数一样(性质 5)------虽然多绕了一点,但保证不会彻底堵死