SWIFT 的全称是 Scalable lightWeight Infrastructure for Fine-Tuning(可扩展的轻量级微调基础设施),提供从模型微调到最终部署的一整套工具,让大模型的定制和落地变得简单、高效。
一、Swift 框架简介
MS-SWIFT 是阿里云 ModelScope 社区开源的大模型微调框架,核心特点是:
-
支持 600+ 大语言模型和 300+ 多模态模型
-
内置 LoRA、QLoRA 等参数高效微调方法
-
单卡 24GB 显存即可微调 7B 级别模型
-
覆盖训练→评估→量化→部署全流程
二、环境安装
python
# 创建虚拟环境
conda create -n swift python=3.10
conda activate swift
# 安装 PyTorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 安装 ms-swift
pip install ms-swift -U
# 可选:安装加速依赖
pip install deepspeed flash-attn --no-build-isolation三、数据格式准备
Swift 支持多种数据格式,推荐使用 JSONL 格式的 messages 结构。我这里使用了一个小数据样本。
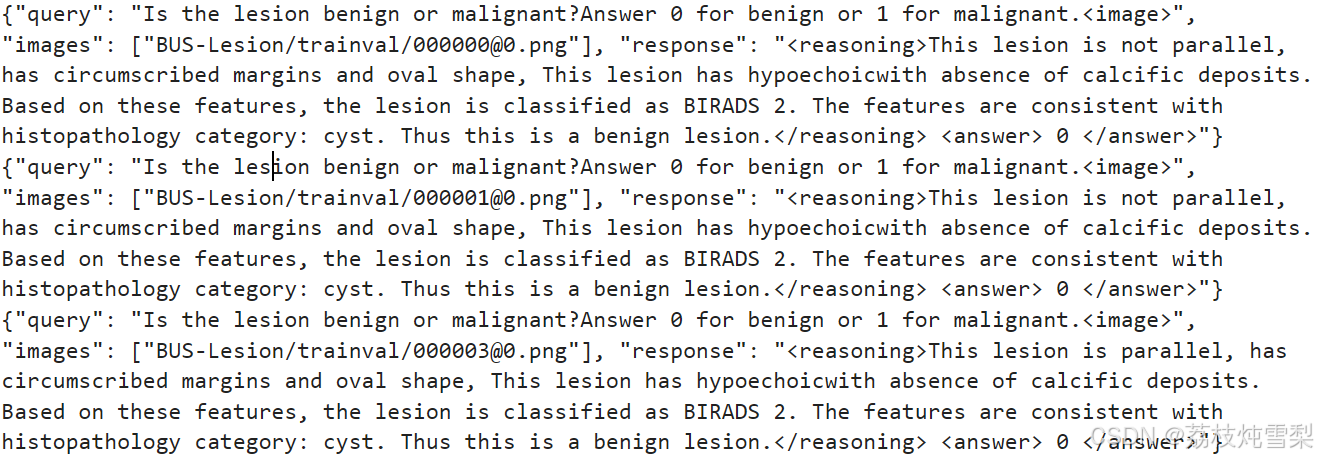
1、JSON与JSONAL区别
| 特性 | JSON | JSONL |
|---|---|---|
| 结构 | 一个完整的对象(通常是数组) | 每行一个独立对象 |
| 文件扩展名 | .json |
.jsonl 或 .jsonlines |
| 读取方式 | 一次性加载整个文件到内存 | 逐行读取,一次处理一条 |
| 内存占用 | 大文件会占用大量内存 | 内存友好,只加载当前行 |
| 编辑便利性 | 需要解析整个结构才能修改 | 可以直接追加或修改某一行 |
| 流式处理 | 不支持 | 支持(边读边处理) |
| 断点续传 | 困难 | 容易(记录已处理行数) |
四、核心训练命令
根据数据集和路径自行修改代码。
python
swift sft \
--model autodl-tmp/modelscope_cache/models/Qwen/Qwen2.5-VL-7B-Instruct\
--adapters autodl-tmp/output/continued_training/v2-20260614-155943/checkpoint-816 \
--dataset /root/autodl-tmp/BUSCoT/DatasetFiles/train_fixed.jsonl\
--quant_bits 4 \
--lora_rank 16 \
--lora_alpha 32 \
--tuner_type lora \
--gradient_checkpointing true \
--per_device_train_batch_size 2 \
--learning_rate 1e-4\
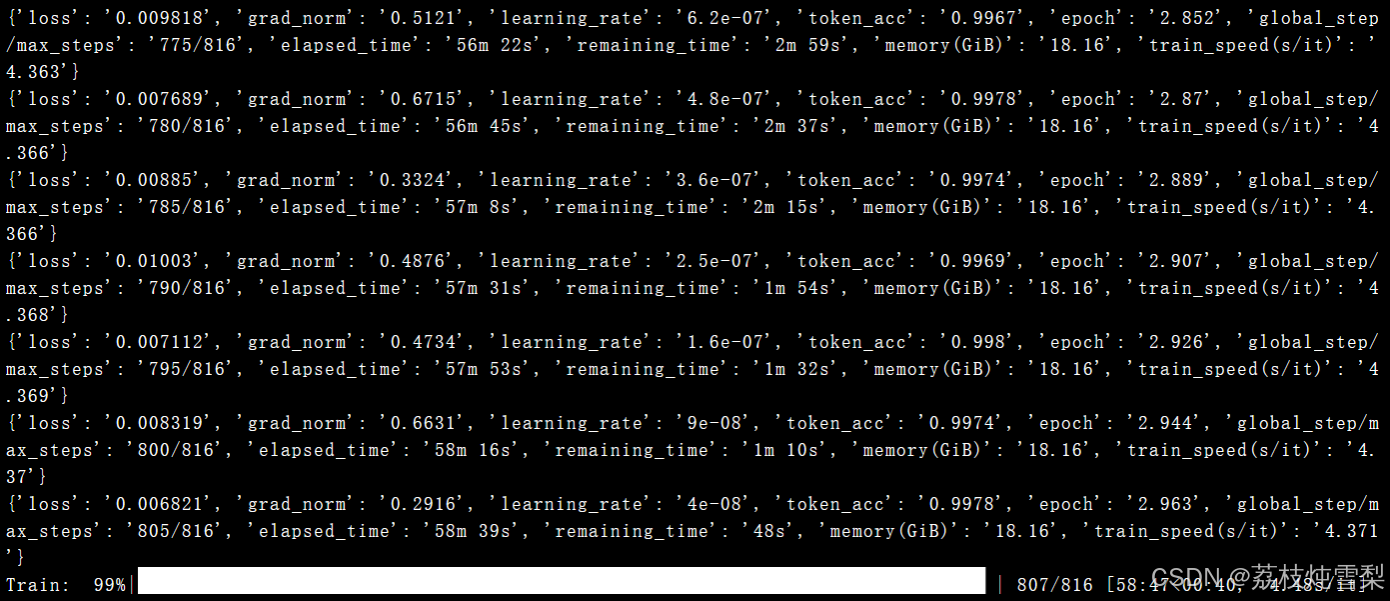
--output_dir /root/autodl-tmp/output/continued_training五、训练过程
六、推理测试
1、生成测试集结果文件
python
swift infer \
--adapters autodl-tmp/output/continued_training/v4-20260614-181229/checkpoint-816 \
--val_dataset /root/autodl-tmp/BUSCoT/DatasetFiles/test.jsonl \
--infer_backend pt \
--max_batch_size 4 \
--max_new_tokens 512 \
--result_path ./test_results.jsonl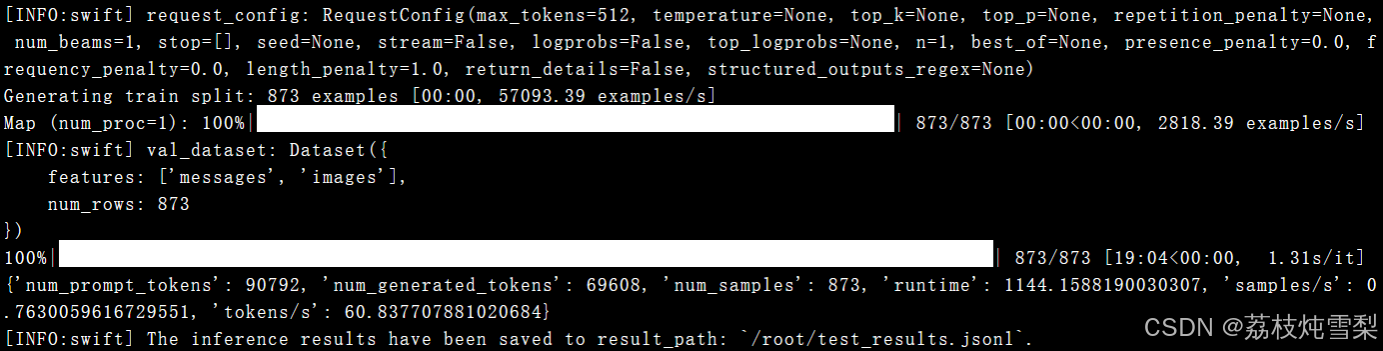
2、评估推理结果准确率
python
import json
import re
def calculate_accuracy(result_file):
correct = 0
total = 0
with open(result_file, 'r') as f:
for line in f:
data = json.loads(line)
# 模型预测的输出
predicted = data.get('response', '')
# 真实标签(需要从测试集中获取,或者结果文件中已包含)
ground_truth = data.get('ground_truth', '')
# 如果结果文件中没有 ground_truth,可以从 predict 结构中提取
# 有些格式下,真实值在 labels 字段中
if not ground_truth:
ground_truth = data.get('labels', '')
# 提取 answer 标签中的数字
pred_match = re.search(r'<answer>\s*(\d+)\s*</answer>', predicted)
true_match = re.search(r'<answer>\s*(\d+)\s*</answer>', ground_truth)
if pred_match and true_match:
if pred_match.group(1) == true_match.group(1):
correct += 1
total += 1
elif pred_match and not true_match:
# 如果真实值没有 answer 标签,尝试直接匹配数字
total += 1
# 这里可以根据实际情况处理
if total > 0:
print(f"准确率: {correct}/{total} = {correct/total*100:.2f}%")
else:
print("没有找到有效的评估样本")
calculate_accuracy('test_results.jsonl')3、评估结果

结果还有待提高,谢谢关注!!!