echo-agent 前身为 2025 年 11 月启动的个人助理项目 fubot,最初面向长期陪伴型个人智能体,围绕认知记忆、上下文延续、用户偏好沉淀、任务闭环与持续自我优化展开。随着真实场景迭代,项目逐步形成多入口接入、统一事件模型、消息总线、Agent Loop、多模型抽象、工具调用、MCP 接入、任务调度、权限审批、运行轨迹、长期记忆和受控自演进等能力。目前已支持微信、QQ、CLI、Gateway、Webhook、Cron 等入口,服务用户超过 20 万、累计下载超过 50 万,是面向长期运行、记忆增强和可持续成长智能体的开源 Agent Runtime。

你可能见过这样的 Agent demo:一个 while True 循环里调用模型,模型要工具就执行工具,把结果塞回去,再继续问模型,直到它输出最终回答。
这个写法很适合解释 ReAct 的基本思想。问题是,一旦进入真实工程,它很快会膨胀:会话要不要加锁?流式消息谁来发?审批命令要不要进模型?工具执行失败怎么追踪?最终回答保存在哪里?
如果这些问题都塞进同一个循环,Agent Loop 很快就不再是"循环",而是一个难以测试、难以观测、难以扩展的大函数。
本篇只讲一个点:Agent Loop 不是模型内部的 while 循环,而是一次入站事件的系统级生命周期控制。
问题入口
很多 Agent 教程会把 Loop 简化成下面这样:
ini
while True:
user_input = read_user_input()
message = call_llm(user_input)
if message.tool_calls:
result = run_tool(message.tool_calls)
continue
return message.content这个模型没有错,但它只覆盖了推理阶段里的一小段:模型、工具、观察、继续推理。
真实系统面对的不是一行用户输入,而是一个事件。事件可能来自 CLI、HTTP Gateway、WebSocket、企业微信、定时任务,也可能来自测试代码中的直接调用。事件进入系统后,还要带上 session、身份、通道、trace、流式输出方式和可能的媒体信息。
会调用工具只说明系统有行动接口;能不能成为 Agent,要看工具调用是否进入受状态、权限和追踪约束的闭环。
所以,生产级 Agent Loop 的最小单位不应该是 user_input -> text,而应该是:
rust
InboundEvent -> Pipeline -> OutboundEvent / response_text为了不停留在抽象层面,下面以 echo-agent 的实现为例。
事件契约
echo-agent 的 Agent Loop 首先守住的是事件契约。通道层负责把外部消息翻译成统一的 InboundEvent,Loop 不直接关心企业微信怎么验签、HTTP 怎么鉴权、CLI 怎么读取标准输入。
这带来一个直接好处:Agent Loop 不绑定具体入口。只要入口能生成 InboundEvent,就可以进入同一条核心运行路径。
输出也不能被假设成"立即返回字符串"。在异步通道里,回答可能通过 MessageBus 发布成 OutboundEvent;在 CLI 或测试场景里,也可以由 process_direct 返回 response_text。这就是 publish_response 这类参数存在的原因。
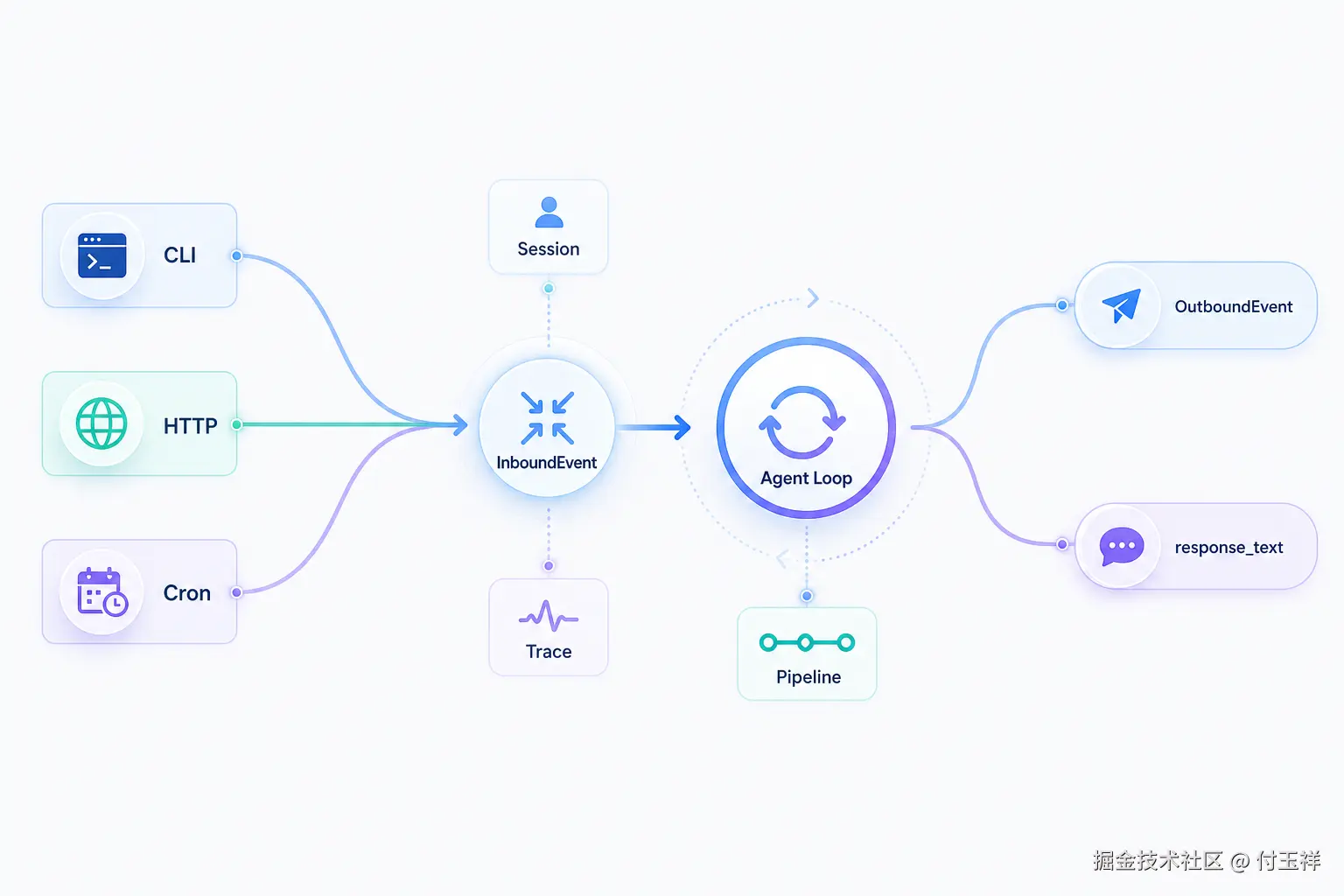
事件契约里还有两个很硬的工程边界。
第一,同一 session 内的事件要串行处理。用户连续发两条消息,如果第一条还在执行工具,第二条已经开始构造上下文,历史记录、工具结果和记忆快照就可能交错写入。不同 session 可以并发,但同一 session 必须保持语义顺序。
第二,每次事件处理都要创建可追踪边界。echo-agent 会为事件生成 trace_id,再用 TraceLogger 记录模型调用、工具调用和错误信息。没有这层追踪,Agent 的最终回答只能靠零散日志猜。
控制循环
"Loop" 这个词容易误导人。很多人听到 Agent Loop,会自然想到模型内部的 ReAct 循环:思考、调用工具、观察结果、继续思考。
但系统层面的 Agent Loop 更像控制循环。它包含四个要素:输入、状态、控制决策和输出。
以"帮我修复测试失败"为例,输入是一次 InboundEvent;状态包括当前会话、仓库上下文、历史工具结果、审批状态和模型路由健康;控制决策包括是否加载历史、是否暴露写文件工具、是否需要审批、是否继续迭代;输出可能是进度消息、工具调用 trace、最终回答、会话保存和后台记忆整理。
这和 ReAct 循环不是一回事:
| 层级 | 关注点 | 典型步骤 |
|---|---|---|
| ReAct 循环 | 模型如何使用工具 | 推理、工具调用、工具结果、继续推理 |
| 系统循环 | 一次事件如何被治理 | 事件进入、会话加载、上下文构建、推理执行、响应保存、输出投递 |
把两者混在一起,会得到一个常见坏味道:所有逻辑都往推理循环里塞。上下文拼接、审批、工具执行、会话保存、后台整理、错误兜底,最后全挤进一个函数。
AgentLoop 的核心不是让模型一直说话,而是把模型放进受状态和策略约束的运行闭环。
三阶段 Pipeline
echo-agent 当前把 Agent Loop 拆成三阶段 Pipeline:
rust
ContextStage -> InferenceStage -> ResponseStage这不是为了让目录看起来更架构化,而是按时间切分一次事件处理。
ContextStage 负责"进入模型前"。它把会话历史、记忆、技能、知识库、媒体、系统提示词和工具定义组装成模型可用输入。
InferenceStage 负责"模型循环中"。它执行模型推理与工具调用循环,包括模型调用、工具执行、观察结果回填,以及触达终止条件。
ResponseStage 负责"模型完成后"。它处理最终回答、会话保存、输出发布状态,以及记忆整理、技能复盘等后台任务。

可以把 _process_event 理解成一个很薄的编排器:
ini
async def _process_event(event, trace_id, publish_response=False):
session = await sessions.get_or_create(event.session_key)
ensure_working_memory(event.session_key)
command_response = await handle_approval_command(event)
if command_response:
save_command_result(session, event, command_response)
return ProcessResult(response_text=command_response)
stream = TokenStreamPublisher(...)
ctx = await context_stage.build(
event=event,
session=session,
trace_id=trace_id,
stream_publisher=stream,
)
inference = await inference_stage.run(ctx)
response = await response_stage.finalize(ctx, inference)
return ProcessResult(
response_text=response.response_text,
outbound_sent=response.outbound_sent,
)这段逻辑真正重要的是"没有做什么":它没有直接拼系统提示词,没有直接调用模型,没有直接执行工具,也没有直接保存最终会话。这些事情分别落在三个阶段里。
这样拆的收益很明确:上下文构造可以单测,推理循环可以单测,响应后处理也可以单测。书稿里提到,tests/test_pipeline_stages.py 可以直接测试 PipelineContext 默认值、InferenceResult 默认值、ContextStage.build 输出、任务类型推断和 ResponseStage.finalize 后处理行为。
如果只能通过完整 Agent Loop 间接触发这些逻辑,测试会慢,也会脆。
共享上下文
Pipeline 拆开以后,阶段之间必须共享状态。最粗糙的做法,是每个阶段传一长串参数:事件、会话、消息、工具定义、检索结果、任务类型、流式发布器。
这种写法很快会失控。参数越传越长,阶段依赖越隐蔽,后续重构也越危险。
echo-agent 使用 PipelineContext 作为一次事件处理的上下文载体。它包含四类字段:
| 类型 | 字段示例 | 作用 |
|---|---|---|
| 请求边界 | event、session、trace_id、publish_response |
标识本次处理属于谁、如何追踪、如何输出 |
| 模型输入 | system_prompt、messages、tool_defs |
进入模型调用的核心内容 |
| 推理辅助 | retrieval、task_type、execution_plan |
影响路由、计划和提示词构造 |
| 输出控制 | intro_text、stream_publisher |
控制首次介绍语和流式发布 |
这里要注意,PipelineContext 不是全局状态。它只属于一次事件处理,不跨请求复用。正因为生命周期明确,它才能安全地在三个阶段之间传递。
类似地,InferenceResult 和 _ProcessResult 也要分层。前者面向 Pipeline 内部,关心最终回答、工具调用次数、是否需要技能复盘和记忆复盘;后者面向 Agent Loop 外层,只关心最终文本和是否已经发送。
这类"小而明确"的数据结构,会限制阶段越权。一个阶段不应该随手改动不属于自己的发布状态、推理统计或持久化结果。
运行边界
Pipeline 解决的是主路径拆分,但 Agent Loop 还要守住外围边界。
_on_inbound 是入站事件的最外层边界。它先检查 _running 状态,已经停止的 Agent 不应继续进入模型或工具执行。随后它会处理审批命令快路径,例如 /approvals、/approve、/deny。
审批命令不应该每次都进入完整 Pipeline。它们是控制面命令,不是普通自然语言任务。如果先构造上下文、调用模型、暴露工具定义,再处理审批,延迟和风险都没有必要。
之后,Loop 获取 SessionManager.acquire(event.session_key) 返回的异步锁。同一 session 拿同一把锁,不同 session 使用不同锁。这保护的是对话因果,不只是内存一致性。

流式输出也是边界的一部分。echo-agent 的 _TokenStreamPublisher 不只是把每个 token 原样发出去。它维护完整文本、待发送缓冲和非最终消息状态,并根据 stream_flush_chars、stream_flush_interval_ms、stream_paragraph_mode 控制刷新。
段落模式下,系统优先寻找段落边界,其次寻找句子边界,最后才按时间阈值强制刷新。这样做是为了避免用户在通道里看到大量半句话碎片。
最终保存时,又不能把中间碎片当成历史。ResponseStage 要保存的是完整、干净的 assistant 回答;流式过程只是用户体验层的输出形态。
终止条件
Agent Loop 不只要知道怎么开始,还要知道何时停下。
终止可以来自多种信号:模型给出最终回答,最大迭代次数耗尽,工具熔断触发,审批拒绝或超时,用户取消,任务转入后台。
这些信号不能都当成普通错误。最大迭代表示系统主动防止失控;审批拒绝表示行动边界被阻断;工具失败可能需要模型尝试替代方案;用户取消则应尽量停止副作用并保存现场。
echo-agent 中的 max_iterations、ToolCircuitBreaker、ApprovalGate 和后台任务管理,都在给 Loop 设置停止条件。
会做事很重要,会停下来同样重要。没有终止条件的 Agent,本质上没有行动边界。
错误边界也应该和阶段边界一致。ContextStage 失败,多半是无法构造正确输入;InferenceStage 失败,多半是模型、工具、审批或执行问题;ResponseStage 失败,则可能是保存、输出或后台整理问题。不同失败性质不同,处理策略也不应该混成一个大 except。
生产可用性
判断一个 Agent Loop 是否生产可用,不能只看"能不能循环调用模型"。至少要检查这些工程项:
| 检查项 | 可检验标准 |
|---|---|
| 事件契约 | 多入口统一成 InboundEvent,Loop 不直接绑定通道 API |
| 会话串行 | 同 session 串行处理,不同 session 可并发推进 |
| 阶段拆分 | 上下文、推理、响应后处理有明确输入输出 |
| 工具治理 | 模型可见工具来自注册表和策略过滤 |
| 权限审批 | 写操作、高风险工具有统一审批路径 |
| 可观测性 | 每次事件有 trace_id,模型调用和 tool call 可追踪 |
| 流式输出 | 中间增量和最终会话保存分离 |
| 终止条件 | 最大迭代、熔断、审批拒绝、用户取消可区分 |
| 后台任务 | 记忆整理、技能复盘等任务可追踪、可清理 |
| 回归测试 | 阶段行为、并发锁、错误路径有测试覆盖 |
这张表背后的判断很简单:Agent Loop 不是越厚越强,而是越能稳定协调多个子系统,越不需要亲自知道所有细节。
新增模型 provider 不应改 Loop,新增通道不应改 Loop,新增记忆策略也不应改 Loop。Loop 应该依赖稳定契约,例如 LLMProvider、ToolRegistry、MessageBus、SessionManager 和 Pipeline Stage。
小结
从单体循环到三阶段 Pipeline,本质上不是代码风格变化,而是对复杂性的重新归类。
ReAct 解决模型如何使用工具;Agent Loop 解决一次事件如何在会话、上下文、权限、工具、输出、持久化和后台任务之间被治理。
ContextStage 让模型看到正确的世界,InferenceStage 让模型意图变成受控行动,ResponseStage 让本次行动沉淀为系统状态。AgentLoop 则保持生命周期顺序和关键不变量。
理解这一点后,再看 Agent 工程,会少很多误判。真正难的不是写一个会调工具的 while 循环,而是让这个循环进入一个可测试、可观测、可停止、可演进的系统边界。
(全篇完)
本文为 echo-agent 设计笔记系列第 07 篇。项目源码已开源至 GitHubgithub.com/fuyuxiang/e... Agent 的工程落地感兴趣,欢迎加入技术交流群(QQ群号:47572014)参与日常讨论。下一篇我们将探讨 《ContextStage 设计笔记:让模型看到正确的世界》,敬请期待。