目录
[1. 预处理](#1. 预处理)
[2. 编译](#2. 编译)
[3. 汇编](#3. 汇编)
[4. 链接](#4. 链接)
变量
变量定义
在C++中,变量是用来存储数据值的一种实体。每个变量都有一个类型,这个类型决定了变量可以存储的数据的种类以及变量在内存中所占的空间大小。
通俗的来讲:我们家中会有收纳柜,收纳柜存储的是我们的物品,物品就相当于数据,收纳柜就相当于变量,不同的柜子有不同的类型,有的装内衣,有的装袜子。
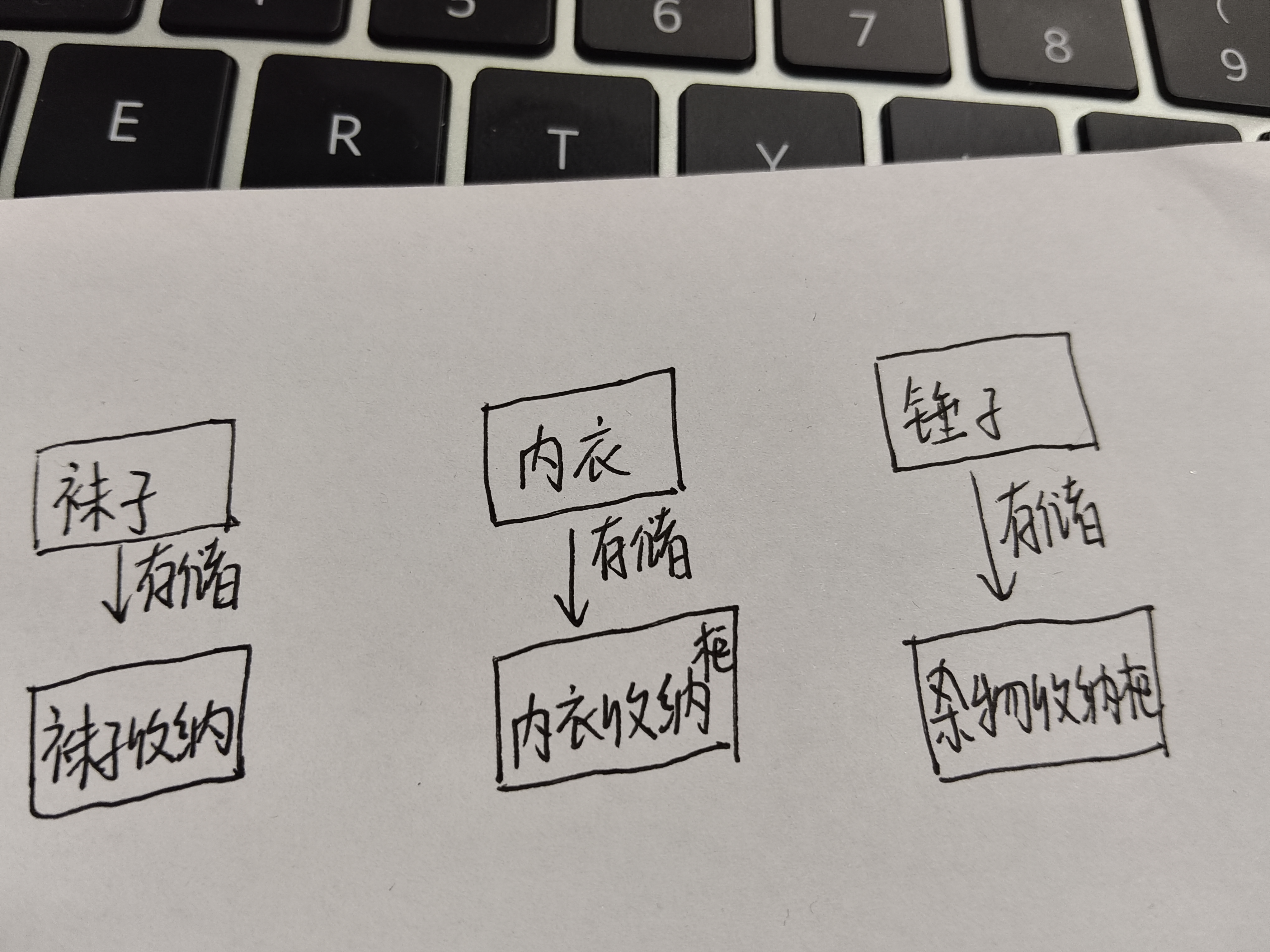
装内衣的柜子一般不会装螺丝刀,一个柜子在定义好用来做什么,它存储的内容就确定了。
小tips:
计算机中数据是按照二进制存储的,一个字节占8bit,bit就是位的意思,比如数字2会转化为二进制00000010,然后将这个00000010放到计算机为我们分配好的存储单元里,这个存储单元本身还有一个地址,假设存储单元的地址为5,转化为二进制就是00000101.
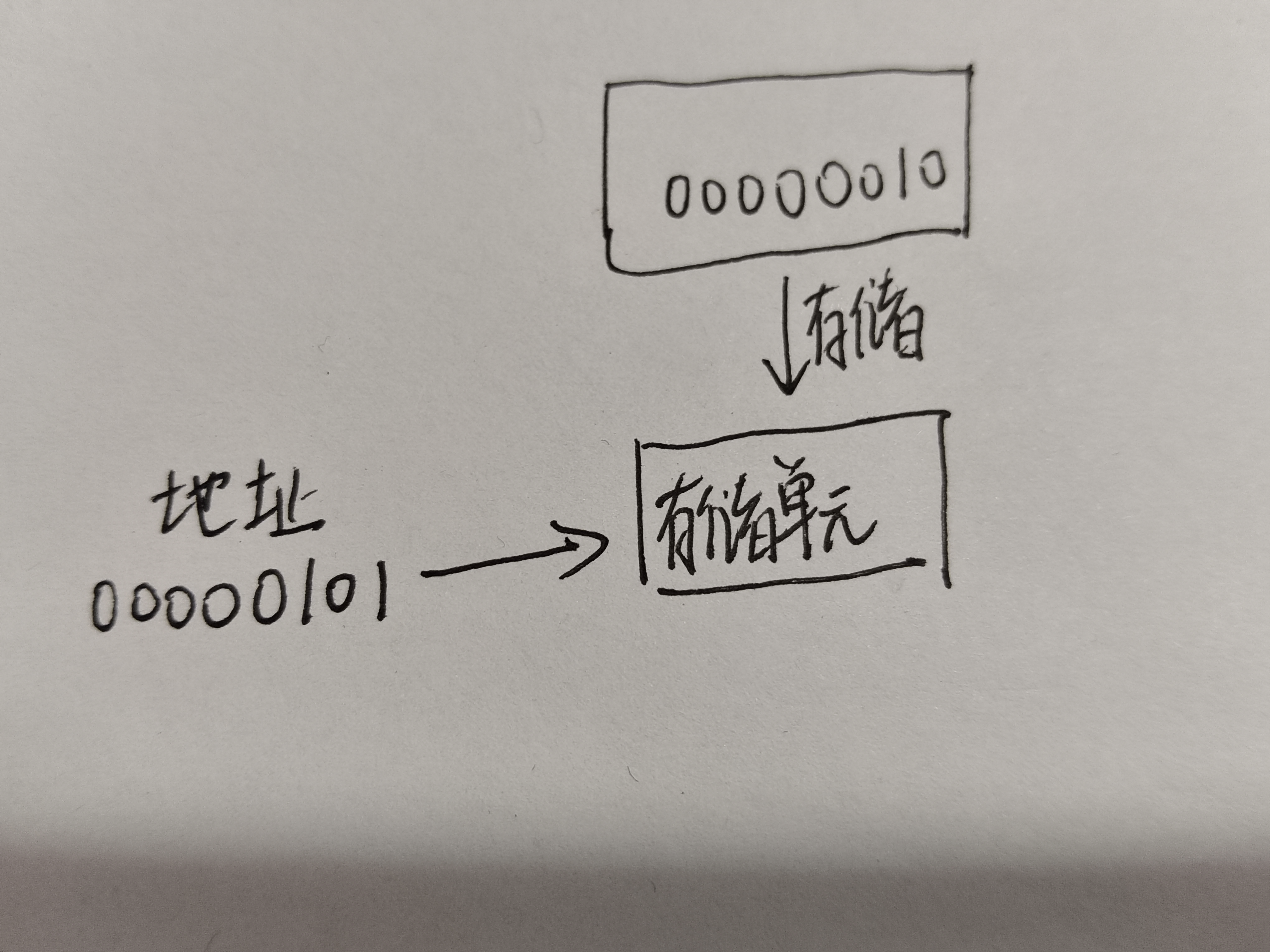
变量的声明和初始化
在C++中,你首先需要声明一个变量,然后(可选地)可以初始化它。声明变量时,你需要指定变量的类型和名称。
cpp
//声明一个整型变量number,未初始化
int number;
//声明并初始化一个整型变量num
int num = 175;
//声明并初始化一个双精度浮点型变量weight
double weight =65.5;
//声明并初始化一个字符型变量gender
char gender ="M';变量的命名规则
在C++中,变量名可以包含字母、数字和下划线(_),但不能以数字开头。此外,C++是区分大小写的,因此Sum和sum被视为两个不同的变量。
变量类型
C++支持多种基本数据类型,包括整型(int、short、long、longlong)、浮点型(float、double、longdouble)、字符型(char)、布尔型(bool)等。此外,C++还支持枚举(enum)、结构体(struct)、联合体(union)和类(class)等复合数据类型。
示例:
cpp
#include <iostream>
int main(){
//初始化变量a和b
int a=5,b=10;
//a+b的值赋值给sum
int sum =a+ b;
//输出求和的结果
std::cout <<"The sum of "<<a<<"and"<<b<<"is"<< sum << std::endl;
return 0;
}在这个示例中,我们声明了三个整型变量a,b和sum,并将a和b的值分别初始化为5和10。然后,我们计算a和b的和,并将结果存储在变量sum中最后我们用std::cout输出计算结果。
输出运算符
在C++中,输出通常是通过标准输出流(std::cout )来完成的。std::cout 是C++标准库中的一个对象,它代表标准输出设备,通常是屏幕。为了使用std::cout来输出数据,你需要包含头文件'<iostream>'。
为什么要用std呢?
std 是c++标准作用域(类似于大区间,在不同区域的同一个位置进行区分,比如北京朝阳区6号楼和海淀区的6号楼)标准输出 ,用其他的cout则前面用其他的作用域,cout虽然包含在#include<iostream>头文件里,但是他是出于这样一个作用域中去定义的。
下面是一个简单的输出例子:
cpp
#include<iostream>//包含标准输入输出流库
int main(){
//输出字符串
std::cout << "Hello, World!" << std::endl;
//输出数字
int number =2;
std::cout <<"The number is: "< number << std::endl;
//输出浮点数
double pi=3.1415;
std::cout <<"The value of pi is approximately:"<< pi<< std:endl;
//输出字符
char ch ='A';
std::cout << "The character is: "<< ch<< std::endl;
//输出布尔值
bool truth = true;
std::cout<<std::boolalpha;//启用布尔值的true/false输出
std::cout << "The truth is:"<< truth << std::endl;
return 0;
}在这个例子中,<< 是插入运算符,用于将右侧的数据发送到左侧的流对象(在这个例子中是std::cout)。std::endl是一个操纵符,用于在输出后插入换行符,并刷新输出缓冲区,确保立即在屏幕上显示输出。
布尔值(bool) 是真假类型,只存储 true 和false
此外,C++还支持格式化输出,但这通常涉及更复杂的语法,如便用std::iomanip头文件中定义的操纵符(如std:setw和std::setprecision)
使用std::iomanip头文件输出3.14时,setw 输出宽度为 2 则3.14前有个空格 setprecision 输出精度为3时,变成 3.140
数据存储区域和编码原理
变量计算
整型,浮点,双精度等变量都支持计算,比如+、-、*、/、%等
cpp
void calculate(){
//整形变量支持计算,就是我们熟悉的 `+` ,`-`,`*`,`/`,`%`等
int a = 15;
int b = 20;
std::cout << "a + b = " << a+b << std::endl;
std::cout << "a - b = " << a-b << std::endl;
std::cout << "a * b = " << a*b << std::endl;
std::cout << "a / b = " << a/b << std::endl;
std::cout << "a % b = " << a%b << std::endl;
//浮点型变量支持计算
float c = 12.5;
float d = 20.6;
std::cout << "c + d = " << c+d << std::endl;
std::cout << "c - d = " << c-d << std::endl;
std::cout << "c * d = " << c*d << std::endl;
std::cout << "c / d = " << c/d << std::endl;
//浮点型变量支持计算
double e = 10.5;
double f = 20.6;
std::cout << "e + f = " << e+f << std::endl;
std::cout << "e - f = " << e-f << std::endl;
std::cout << "e * f = " << e*f << std::endl;
std::cout << "e / f = " << e/f << std::endl;
}ASCII码表
计算机中字符都是用ASCII码记录的,它为0--127都分配的数字编码,包含英文字母大小写、数字、标点符号以及控制字符(换行、回车等),下面的表是查阅资料找到的
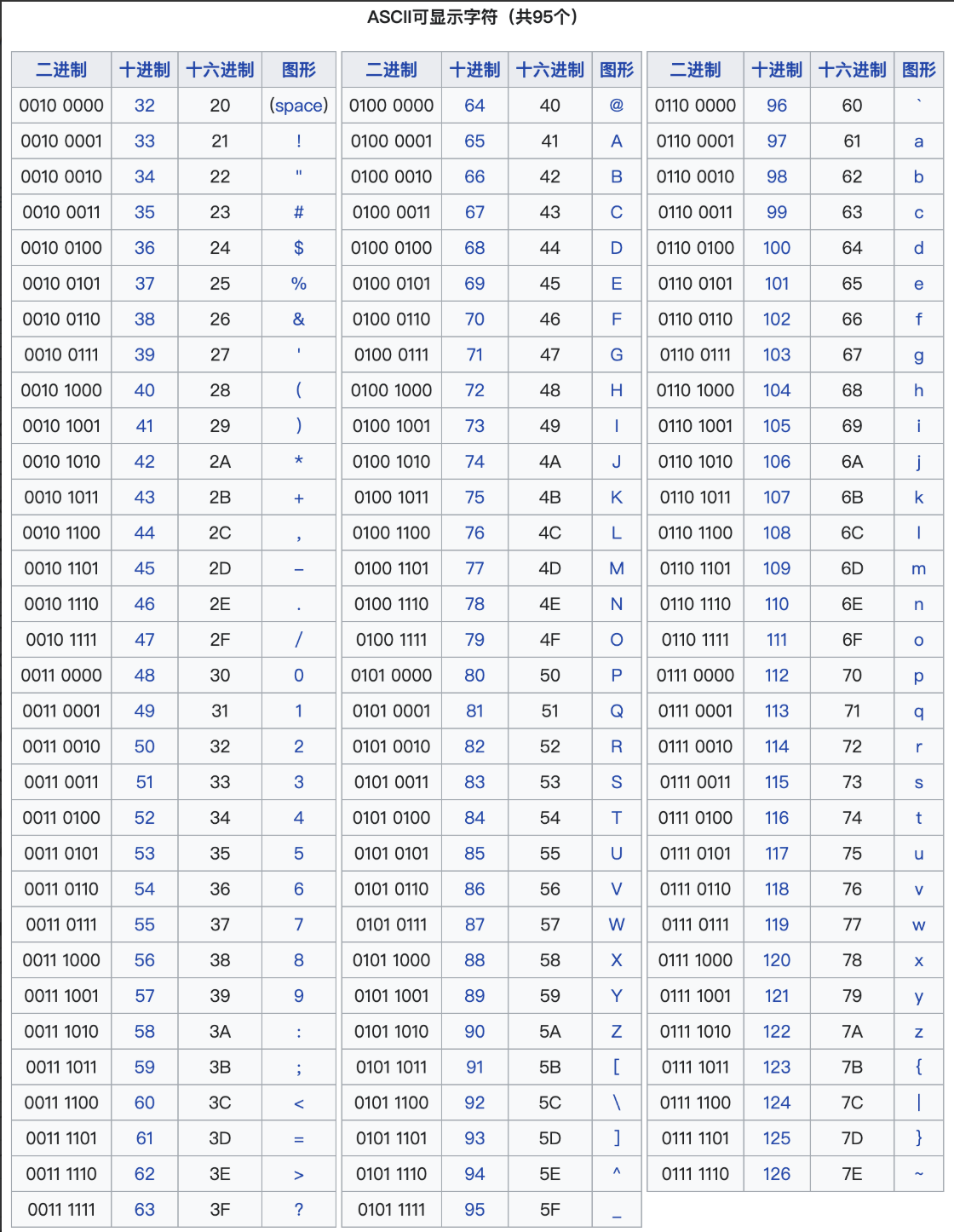
由此,我们字符之间也能进行计算
cpp
//字符变量支持计算,所谓计算就是我们熟悉的 `+` ,`-`,`*`,`/`等
char g = 'a';
char h = 'b';
std::cout << "g + h = " << (int)(g+h) << std::endl;
std::cout << "g - h = " << (int)(g-h) << std::endl;
std::cout << "g * h = " << (int)(g*h) << std::endl;
std::cout << "g / h = " << (int)(g/h) << std::endl;将(g+h)的值转成int类型,后续还会有static_cast<int>(a) 这是将a强制转换成int类型
各种数据类型都可以转换,double, float,int, char 这种C++给我们提供的基本类型也叫做内置类型。
变量大小
变量是存储在存储单元中,那么计算机为不同的变量分配的大小也不一样, 可以通过sizeof来计算类型的大小
cpp
void sizeofnum(){
std::cout << "Size of char: " << sizeof(char) << " bytes\n";
std::cout << "Size of int: " << sizeof(int) << " bytes\n";
std::cout << "Size of float: " << sizeof(float) << " bytes\n";
std::cout << "Size of double: " << sizeof(double) << " bytes\n";
std::cout << "Size of long long: " << sizeof(long long) << " bytes\n";
}类型转换只能小范围转到大范围,不能大的转成小的,会导致数据丢失,比如:int-->char就会丢失
变量作用域
在C++中,变量作用域(Scope)指的是程序中变量可以被访问的代码区域。作用域决定了变量的生命周期和可见性。下面是几种常见的作用域类型。
全局作用域:
在函数外部声明的变量具有全局作用域。它们可以在程序的任何地方被访问,但通常建议在需要时才使用全局变量,因为它们可能导致代码难以理解和维护。
cpp
#include <iostream>
// 全局变量,为全局作用域
int globalVar = 20;
void funs() {
std::cout << globalVar << std::endl;
}
int main() {
std::cout << globalVar << std::endl;
funs(); // 访问全局变量
return 0;
}局部作用域:
在函数内部、代码块(如if语句、for循环等)内部声明的变量具有局部作用域。局部变量仅在他所初始化或者定义的函数内部是可见的
cpp
#include <iostream>
void func() {
// 局部变量,具有局部作用域
int localVar = 10;
std::cout << "Inside func: localVar = " << localVar << std::endl;
// localVar 在这里之后就不再可见
}
int main() {
// 尝试访问 localVar 会导致编译错误
// std::cout << "localVar = " << localVar << std::endl; // 错误
func(); // 局部变量仅在func函数内部可见
return 0;
}命名空间作用域:
在命名空间中声明的变量(实际上是实体,如变量、函数等)具有命名空间作用域。它们只能在相应的命名空间内被直接访问,但可以通过使用命名空间的名称作为前缀来从外部访问。
cpp
#include <iostream>
// 定义一个命名空间
namespace Myspace {
// 命名空间内的变量,具有命名空间作用域
int namespaceVar = 20;
void printVar() {
std::cout << "Inside Myspace: namespaceVar = " << namespaceVar << std::endl;
}
int globalVar = 0;
}
namespace Myspace2 {
int globalVar = 0;
}
int main() {
// 使用命名空间前缀访问变量
std::cout << "Outside Myspace: namespaceVar = " << Myspace::namespaceVar << std::endl;
Myspace::printVar(); // 访问命名空间内的函数
return 0;
}namespace是 c++的关键字 ,c++提供的用来定义空间的专属名词 +想命名的空间 -->namespace Myspace
可以使用空间前缀来访问变量:Myspace(空间)::namespaceVar(变量)或者Myspace::printVar() 访问命名空间的函数
命名空间的作用:防止变量重名的问题,规范化,想用什么加上作用域就可以
如果加上 using namespace std; 可以不用std::,但是如果你用到了using namespace boost 这个库,他也有 cout 就会导致编译错误,他不知道你用的是哪个里面的cout,所以最好写std::cout
类作用域:
在类内部声明的成员变量和成员函数具有类作用域。成员变量和成员函数可以通过类的对象来访问,或者在某些情况下(如静态成员)可以通过类名直接访问。
cpp
#include <iostream>
class MyClass {
public:
// 成员变量,具有类作用域
int classVar;
// 成员函数,也可以访问类作用域内的成员变量
void printVar() {
std::cout << "Inside MyClass: classVar = " << classVar << std::endl;
}
};
int main() {
MyClass obj;
obj.classVar = 20; // 通过对象访问成员变量
obj.printVar(); // 访问成员函数
// 尝试直接访问 classVar 会导致编译错误
// std::cout << "classVar = " << classVar << std::endl; // 是错误的
return 0;
}**小tips:**Myclass-->类名 obj -->对象 obj.+类里面的成员变量和函数 ,类的成员函数叫做方法,类里面的变量叫成员变量,直接访问会报错
块作用域:
这是局部作用域的一个特例,指的是由大括号{}包围的代码块内部声明的变量。这些变量只能在该代码块内被访问。
cpp
#include <iostream>
void func() {
{
// 块内局部变量,具有块作用域
int blockVar = 5;
std::cout << "Inside block: blockVar = " << blockVar << std::endl;
// blockVar 在这个代码块之后就不可见了
}
// 尝试访问 blockVar 会导致编译错误
// std::cout << "blockVar = " << blockVar << std::endl; // 错误
}
int main() {
func(); // 访问块作用域变量仅在func函数内部的代码块内有效
return 0;
}{}括号结束直接被自动回收,块作用域里定义的变量只在块里可见,块外不可见
存储区域
根据存储的数据类型、生命周期和作用域来划分。
代码区:
- 存储程序执行代码(即机器指令)的内存区域。这部分内存是共享的,只读的,且在程序执行期间不会改变。
- 举例说明:当你编译一个C++程序时,所有的函数定义、控制结构等都会被转换成机器指令,并存储在代码区。
全局/静态存储区:
- 存储全局变量和静态变量的内存区域。这些变量在程序的整个运行期间都存在,但它们的可见性和生命周期取决于声明它们的作用域。
- 举例说明:全局变量(在函数外部声明的变量)和静态变量(使用
static关键字声明的变量,无论是在函数内部还是外部)都会存储在这个区域。
栈区:
- 存储局部变量、函数参数、返回地址等的内存区域。栈是一种后进先出(LIFO)的数据结构,用于存储函数调用和自动变量。
- 举例说明:在函数内部声明的变量(不包括静态变量)通常存储在栈上。当函数被调用时,其参数和局部变量会被推入栈中;当函数返回时,这些变量会从栈中弹出,其占用的内存也随之释放。
堆区:
- 由程序员通过动态内存分配函数(如
new和malloc)分配的内存区域。堆区的内存分配和释放是手动的,因此程序员需要负责管理内存,以避免内存泄漏或野指针等问题。 - 举例说明:当你使用
new操作符在C++中动态分配一个对象或数组时,分配的内存就来自堆区。同样,使用delete操作符可以释放堆区中的内存。
常量区:
- 存储常量(如字符串常量、const修饰的全局变量等)的内存区域。这部分内存也是只读的,且通常在程序执行期间不会改变。
- 举例说明:在C++中,使用双引号括起来的字符串字面量通常存储在常量区。此外,使用
const关键字声明的全局变量,如果其值在编译时就已确定,也可能存储在常量区。
cpp
#include <iostream>
#include <cstring> // 用于strlen
// 全局变量,存储在全局/静态存储区
int globalVar = 10;
// 静态变量,也存储在全局/静态存储区,但仅在其声明的文件或函数内部可见
static int staticVar = 20;
void func() {
// 局部变量,存储在栈区
int localVar = 30;
// 静态局部变量,虽然声明在函数内部,但存储在全局/静态存储区,且只在第一次调用时初始化
static int staticLocalVar = 40;
std::cout << "Inside func:" << std::endl;
std::cout << "localVar = " << localVar << std::endl;
std::cout << "staticLocalVar = " << staticLocalVar << std::endl;
// 尝试通过动态内存分配在堆区分配内存
int* heapVar = new int(50);
std::cout << "heapVar = " << *heapVar << std::endl;
// 释放堆区内存(重要:实际使用中不要忘记释放不再使用的堆内存)
delete heapVar;
}
int main() {
// 访问全局变量
std::cout << "Inside main:" << std::endl;
std::cout << "globalVar = " << globalVar << std::endl;
std::cout << "staticVar = " << staticVar << std::endl; // 注意:staticVar在外部不可见(除非在同一个文件中或通过特殊方式)
// 调用函数,展示栈区和堆区的使用
func();
// 字符串常量通常存储在常量区,但直接访问其内存地址并不是标准C++的做法
// 这里我们仅通过指针来展示其存在
const char* strConst = "Hello, World!";
// 注意:不要尝试修改strConst指向的内容,因为它是只读的
std::cout << "strConst = " << strConst << std::endl;
// 尝试获取字符串常量的长度(这不会修改常量区的内容)
std::cout << "Length of strConst = " << strlen(strConst) << std::endl;
return 0;
}小tips:
只要有static关键字,存储在静态区也就是全局区 特性:只在第一次调用时初始化
int* heapVar = new int(50); new int(50);-->开辟了一个空间,空间返回一个地址,地址存储在heapVar,即存的是50这个数据的一个地址。通过new的方式动态开辟了内存,存储在堆区。
程序编译过程
C++程序的编译过程是一个相对复杂但有序的过程,它涉及将高级语言(C++)代码转换为机器可以执行的低级指令。在这个过程中,通常会生成几个中间文件,包括.i(预处理文件)、.s(汇编文件)和.o(目标文件或对象文件)。下面是这个过程的详细解释:
1. 预处理
- 输入 :C++源代码文件(通常以
.cpp或.cxx为后缀)。 - 处理 :预处理器(通常是
cpp)读取源代码文件,并对其进行宏展开、条件编译、文件包含(#include)等处理。 - 输出 :生成预处理后的文件,通常具有
.i后缀(尽管这个步骤可能不是所有编译器都会自动生成.i文件,或者可能需要特定的编译器选项来生成)。
2. 编译
- 输入:预处理后的文件(如果有的话,否则直接是源代码文件)。
- 处理 :编译器(如
g++、clang++等)将预处理后的文件或源代码文件转换为汇编语言代码。这个步骤是编译过程的核心,它执行词法分析、语法分析、语义分析、中间代码生成、代码优化等任务。 - 输出 :生成汇编文件,通常具有
.s或.asm后缀。
3. 汇编
- 输入:汇编文件。
- 处理 :汇编器(如
as、gas等)将汇编语言代码转换为机器语言指令(即目标代码),但这些指令仍然是针对特定架构的,并且尚未被链接成可执行文件。 - 输出 :生成目标文件(或对象文件),通常具有
.o、.obj或.out后缀。
4. 链接
- 输入:一个或多个目标文件,以及可能需要的库文件(如C++标准库)。
- 处理 :链接器(如
ld、lld等)将目标文件和库文件合并成一个可执行文件或库文件。在这个过程中,链接器会解决外部符号引用(即函数和变量的调用),并将它们链接到正确的地址。 - 输出 :生成可执行文件(在Unix-like系统中通常是
.out、.exe或没有特定后缀,在Windows系统中是.exe)。
C++需要编译连接生成指令的语言,是静态语言,解释性语言:python js....不涉及编译过程可以直接运行。
我们需要记住的问题是:
预处理会生成什么文件?编译器处理什么?把什么文件转成了什么类型的文件?
编译:.i文件转为.s文件,.i为预处理文件(把头文件展开拼到一起,内容很长),.s为汇编文件
汇编过程处理.s文件生成.o或.obj目标文件(二进制文件)
链接:多个.obj可以链接生成可执行的exe文件
今天内容就到这,终于开始拾起c++学习了,谢谢大家阅读观看,有问题欢迎在评论区交流!!
