2026 年 6 月的同一周,两个AI大佬几乎说了同一句话。
Boris Cherny,Claude Code 的创始人,在推特上写道:
「Stop prompting. Start looping. The prompt is dead; the loop is the new unit of work.」
(别再提示了。开始循环。Prompt 已死,Loop 才是新的工作单元。)
Peter Steinberger,OpenClaw 的创始人,在同一周的博客中说:
「We spent years perfecting prompts. Now we realize the real engineering is in designing the loop that makes prompts unnecessary.」
(我们花了数年完善 prompt。现在我们意识到,真正的工程在于设计让 prompt 变得不必要的 loop。)
两个不同背景、不同产品的人,得出了相同的结论。这不是巧合,这是范式转移的信号。
一个新的工程学科正在浮现------Loop Engineering。
什么是 Loop Engineering?
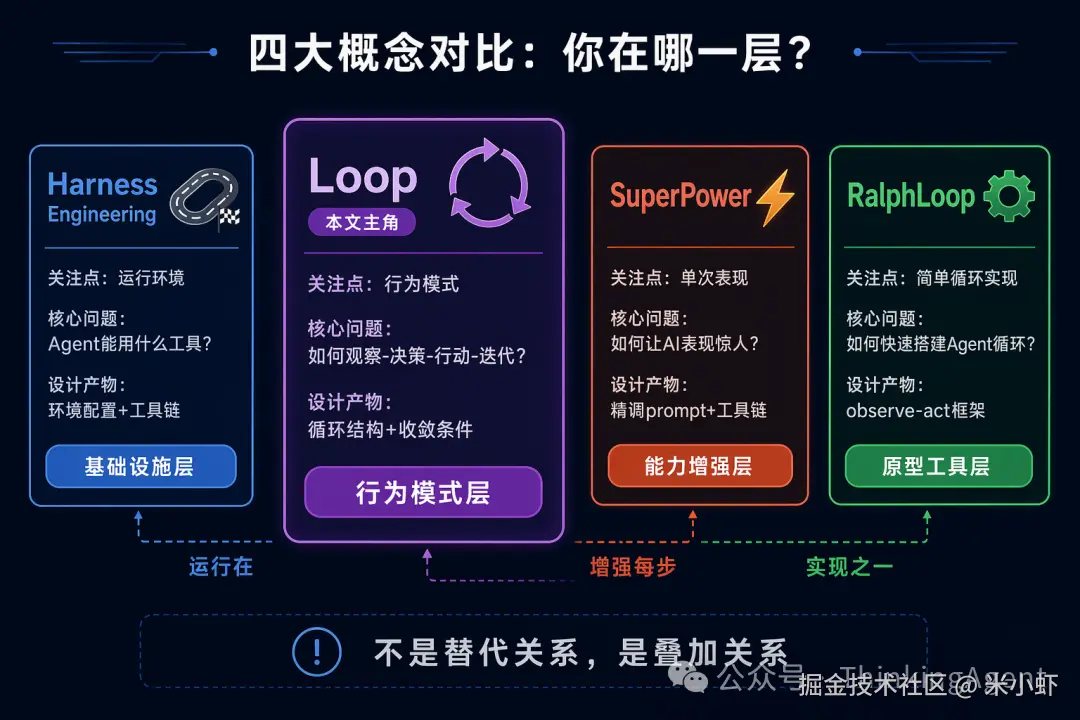
四大概念对比
一句话定义: Loop Engineering 是设计和优化 AI 自主运行循环的工程实践。它关注的不是「如何写好一个 prompt」,而是「如何设计一个让 AI 能持续、自主、可靠地完成任务的循环系统」。
从 Prompt 到 Loop 的演进
| 维度 | Prompt Engineering | Agent Engineering | Loop Engineering |
|---|---|---|---|
| 工作单元 | 单次 prompt-response | 多步任务编排 | 持续运行的循环 |
| 人的角色 | 每次都要写 prompt | 设计 Agent 逻辑 | 设计 Loop 结构 |
| AI 的角色 | 被动回答 | 半自主执行 | 自主循环运行 |
| 可靠性来源 | prompt 质量 | Agent 规划能力 | Loop 的收敛设计 |
| 典型产出 | 一段文本 | 一个完成任务的 Agent | 一个持续运行的系统 |
Loop 的核心结构
一个典型的 Loop 包含 5 个要素:
- Observe(观察): 感知当前环境和状态
- Decide(决策): 基于目标和约束做出判断
- Act(行动): 执行具体操作
- Evaluate(评估): 检查结果是否符合预期
- Iterate(迭代): 根据评估结果调整策略,回到第 1 步
这不是一个简单的 for 循环,而是一个有收敛条件的自适应循环。好的 Loop 会越跑越精准,坏的 Loop 会无限打转。
Loop Engineering vs Harness Engineering:同一枚硬币的两面
上一个话题我们聊了 Harness Engineering。很多人会问:Loop 和 Harness 有什么区别?
答案是:它们是同一枚硬币的两面。
Harness 是 Loop 运行的基础设施 ,Loop 是 Harness 上跑的行为模式。
类比理解
想象一辆赛车:
- Harness 是赛道------它定义了边界、工具、状态管理、错误处理
- Loop 是赛车在赛道上的跑法------它定义了策略、节奏、何时加速何时刹车
没有赛道,赛车跑不起来。没有跑法,赛道只是个空壳。
技术对比
| 维度 | Harness Engineering | Loop Engineering |
|---|---|---|
| 关注点 | 运行环境和中间层 | 行为模式和迭代策略 |
| 核心问题 | Agent 能访问什么工具?如何管理状态? | Agent 如何观察-决策-行动-评估-迭代? |
| 设计产物 | 环境配置、工具链、状态管理 | 循环结构、收敛条件、迭代策略 |
| 衡量指标 | Token 效率、轨迹长度、环境利用率 | 收敛速度、任务完成率、自主程度 |
| 典型论文 | Recursive Agent Harnesses (2026-06) | Agentic Loop Patterns (2026-05) |
实战关系
在实践中,两者密不可分:
markdown
Harness(基础设施层)
├── 文件系统工具
├── 代码执行环境
├── 状态管理器
└── 错误处理机制
│
└── Loop(行为模式层)运行在 Harness 之上
├── Observe:读取 Harness 提供的环境状态
├── Decide:基于目标选择下一步行动
├── Act:调用 Harness 提供的工具
├── Evaluate:检查结果质量
└── Iterate:决定是否继续循环关键洞察: Harness 决定了 Loop 的「能力上限」,而 Loop 决定了 Harness 的「价值释放」。一个好的 Harness 配一个差的 Loop,就像一条好赛道配一个不会开车的司机。
Loop Engineering vs SuperPower:从「超能力」到「自驱力」
SuperPower 是 2024-2025 年间流行的一个概念------通过精心设计的 prompt 和工具链,让 AI 展现出「超能力」般的表现。
核心差异
| 维度 | SuperPower | Loop Engineering |
|---|---|---|
| 哲学 | 让 AI 在单次任务中表现惊人 | 让 AI 在持续运行中稳定可靠 |
| 设计目标 | 最大化单次输出质量 | 最大化长期运行的收敛性和自主性 |
| 失败模式 | 单次表现惊艳但不可重复 | 单次表现平淡但持续进步 |
| 人的参与度 | 每次都需要人触发和校准 | 设计一次,长期自主运行 |
| 适用场景 | 创意生成、代码编写、文档撰写 | 持续监控、自动修复、知识积累 |
一个直观的对比
SuperPower 方式: 你每天给 AI 一个精心设计的 prompt,让它帮你做代码审查。每次审查都很出色,但你每天都得写 prompt。
Loop Engineering 方式: 你设计一个 Loop,让 AI 自动监听 Git 提交,每次有新代码就自动审查,发现问题自动创建 issue,审查质量通过反馈机制持续提升。你只需要设计一次 Loop。
互补关系
SuperPower 和 Loop Engineering 不是替代关系,而是互补关系:
- SuperPower 解决「能力」问题: 让 AI 在特定任务上表现出色
- Loop Engineering 解决「持续性」问题: 让 AI 能自主、持续地运行
最好的实践是:用 SuperPower 的方法提升 Loop 中每一步的质量,用 Loop Engineering 的方法让这些步骤自主运行。
Loop Engineering vs RalphLoop:工业级 vs 原型级
RalphLoop 是 2025 年底出现的一个开源项目,它实现了一个简单的 Agent 循环框架。Loop Engineering 作为一个工程学科,与 RalphLoop 这个具体实现有何不同?
定位差异
| 维度 | RalphLoop | Loop Engineering |
|---|---|---|
| 性质 | 具体的开源框架/工具 | 工程学科/方法论 |
| 类比 | React 之于前端工程 | 前端工程本身 |
| 关注点 | 实现一个可用的 Agent 循环 | 设计最优的循环策略和模式 |
| 成熟度 | 原型级,适合学习和实验 | 工程级,面向生产环境 |
| Loop 模式 | 单一的 observe-act 循环 | 多种 Loop 模式(收敛、探索、修复、学习) |
RalphLoop 的局限
RalphLoop 是一个很好的起点,但它有几个工程级场景下的局限:
- 单一 Loop 模式: 只实现了基础的 observe-act 循环,缺少收敛条件和自适应策略
- 无状态管理: 每次循环都是独立的,缺少跨循环的记忆和上下文
- 无错误恢复: 循环出错时没有回退和重试机制
- 无可观测性: 缺少循环的监控、日志和调试工具
Loop Engineering 补充了什么
Loop Engineering 作为学科,提供了 RalphLoop 缺失的工程实践:
- 多种 Loop 模式: 收敛型 Loop、探索型 Loop、修复型 Loop、学习型 Loop
- 状态管理策略: 短期状态(当前循环)、中期状态(当前任务)、长期状态(跨任务积累)
- 收敛条件设计: 如何定义「足够好」?如何避免无限循环?
- 错误处理模式: 重试、回退、降级、人工干预
- 可观测性框架: 循环次数、收敛曲线、Token 消耗、成功率
与 Goal 的对话:目标是 Loop 的北极星
在 Loop Engineering 的语境下,Goal(目标)是一个核心概念。没有明确目标的 Loop 只是一个死循环。
一段虚拟对话
工程师: 我设计了一个 Loop,让 AI 自动优化代码。但它跑了一晚上,把代码改得面目全非。
Loop Engineering 专家: 你的 Goal 是什么?
工程师: 优化代码质量啊。
专家: 「代码质量」太模糊了。你需要一个可度量的 Goal。比如:「让所有函数的圈复杂度降到 10 以下」或「让测试覆盖率从 60% 提升到 80%」。
工程师: 但 AI 不知道这些指标怎么计算。
专家: 这就是 Loop Engineering 的核心------你不仅要定义 Goal,还要定义 Goal 的评估函数。Loop 的每一步都要检查:「我离 Goal 更近了吗?」
Goal 设计的 4 个原则
- 可度量(Measurable): Goal 必须能被量化。「更好」不是 Goal,「测试覆盖率 > 80%」才是。
- 可验证(Verifiable): 每次循环都能检查是否达到了 Goal。如果验证成本太高,Loop 就跑不起来。
- 有边界(Bounded): Goal 必须有明确的范围。「优化所有代码」不如「优化 src/core/ 目录下的代码」。
- 可分解(Decomposable): 大 Goal 要能拆成小 Goal。「提升系统可靠性」可以拆成「减少 P0 bug 数量」、「提升错误处理覆盖率」等。
Goal 与 Loop 的 3 种关系
| 关系类型 | 描述 | 示例 |
|---|---|---|
| Goal-as-Target(目标靶) | Loop 持续向 Goal 收敛 | 「把 API 响应时间降到 200ms 以下」 |
| Goal-as-Constraint(目标约束) | Loop 在 Goal 约束下优化其他指标 | 「在准确率 > 95% 的前提下,最小化推理成本」 |
| Goal-as-Direction(目标方向) | Loop 朝 Goal 方向前进,但不要求精确到达 | 「持续提升代码可读性」 |
Loop 的 5 种模式
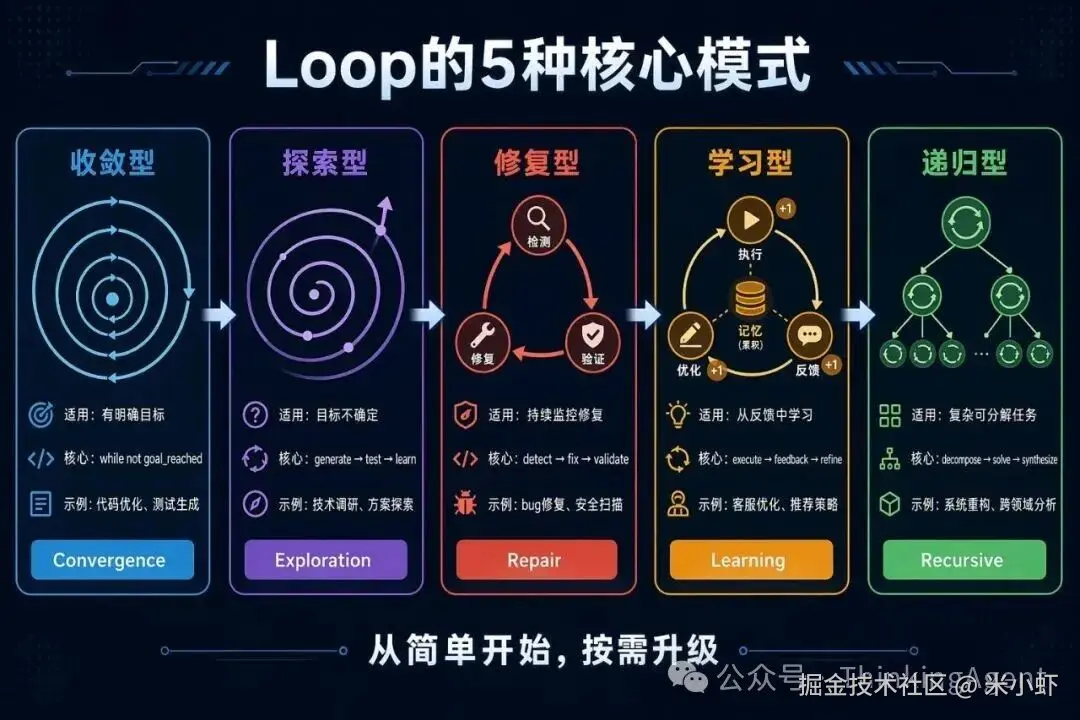
根据 2026 年的实践总结,Loop Engineering 有 5 种核心模式:
1. 收敛型 Loop(Convergence Loop)
适用场景: 有明确目标和度量标准的任务
python
while not goal_reached(state):
observation = observe(environment)
action = decide(observation, goal)
new_state = act(action)
progress = evaluate(new_state, goal)
if progress < threshold:
break # 收敛停滞,退出
state = new_state典型案例: 自动代码优化、自动测试生成、自动文档补全
2. 探索型 Loop(Exploration Loop)
适用场景: 目标不精确,需要边探索边明确
python
while budget > 0:
candidates = generate_hypotheses(current_knowledge)
best = select_most_promising(candidates)
result = test(best)
update_knowledge(result)
budget -= cost(result)典型案例: 研究调研、方案探索、竞品分析
3. 修复型 Loop(Repair Loop)
适用场景: 持续监控并修复问题
python
while monitoring:
issues = detect_problems(environment)
for issue in prioritize(issues):
fix = generate_fix(issue)
if validate(fix):
apply(fix)
else:
escalate_to_human(issue)
sleep(interval)典型案例: 自动 bug 修复、安全漏洞修复、性能问题修复
4. 学习型 Loop(Learning Loop)
适用场景: 需要从历史中学习并改进
python
for task in task_queue:
strategy = select_strategy(task, past_experience)
result = execute(strategy)
feedback = collect_feedback(result)
update_experience(task, strategy, feedback)
refine_strategies(feedback)典型案例: 客服问答优化、推荐策略调整、写作风格适应
5. 递归型 Loop(Recursive Loop)
适用场景: 复杂任务需要分解为子任务
python
def recursive_loop(task, depth=0):
if is_simple(task):
return solve_directly(task)
if depth > max_depth:
return escalate(task)
subtasks = decompose(task)
results = []
for subtask in subtasks:
result = recursive_loop(subtask, depth + 1)
results.append(result)
return synthesize(task, results)典型案例: 复杂代码重构、多步骤研究、跨领域分析
使用指南:从零开始设计你的第一个 Loop
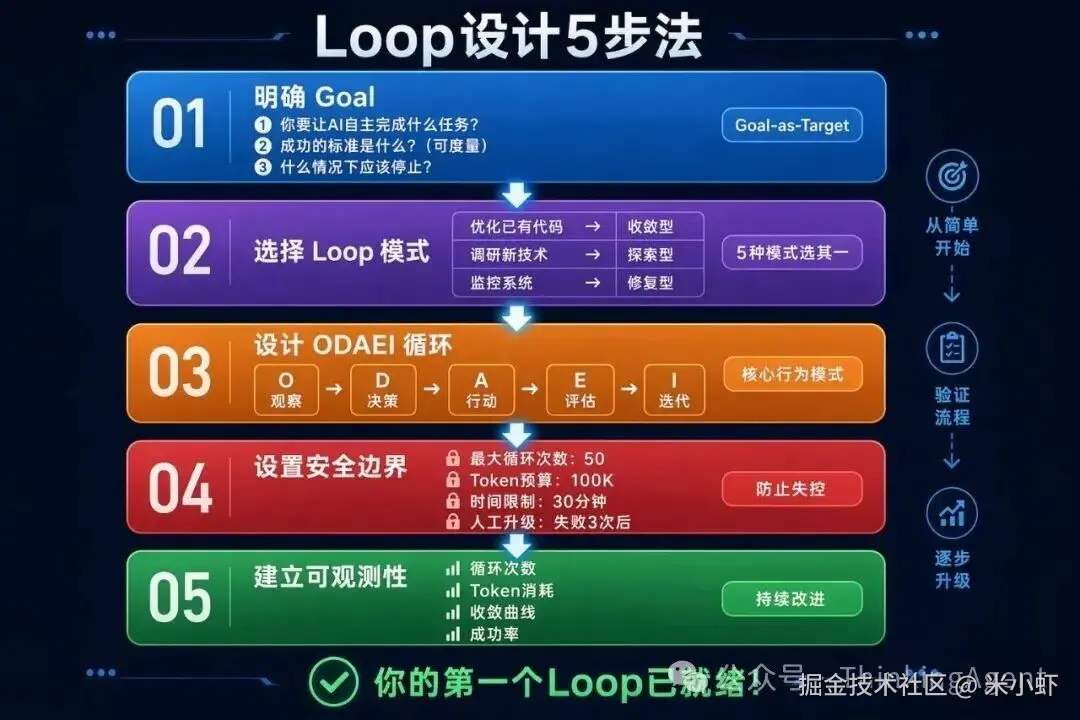
Step 1:明确你的 Goal
在写任何代码之前,先回答 3 个问题:
- 你要让 AI 自主完成什么任务?(不是「帮我做 XX」,而是「自主完成 XX」)
- 成功的标准是什么?(可度量的指标)
- 什么情况下应该停止?(收敛条件)
Step 2:选择 Loop 模式
根据任务性质选择:
| 任务类型 | 推荐模式 | 理由 |
|---|---|---|
| 优化已有代码 | 收敛型 | 有明确目标(质量指标) |
| 调研新技术 | 探索型 | 目标不确定 |
| 监控系统健康 | 修复型 | 持续运行 |
| 改进用户体验 | 学习型 | 需要从反馈中学习 |
| 重构大型系统 | 递归型 | 任务可分解 |
Step 3:设计 Observe-Decide-Act-Evaluate-Iterate
以一个「自动代码审查 Loop」为例:
python
# Observe: 检测新的代码变更
new_commits = git.detect_new_commits(branch="main")
for commit in new_commits:
# Decide: 确定审查策略
review_plan = ai.plan_review(
code_diff=commit.diff,
context=commit.related_files,
standards=team.coding_standards
)
# Act: 执行审查
review_result = ai.execute_review(review_plan)
# Evaluate: 检查审查质量
quality_score = evaluate_review(review_result)
if quality_score < 0.7:
# 质量不够,重新审查
review_result = ai.execute_review(review_plan, attempt=2)
# Iterate: 将结果反馈到知识库
knowledge_base.add(commit.id, review_result)
# 创建 issue(如果发现问题)
for issue in review_result.issues:
if issue.severity >= "high":
github.create_issue(issue)Step 4:设置安全边界
任何 Loop 都必须有安全边界,否则可能失控:
- 最大循环次数:
max_iterations = 50 - Token 预算:
max_tokens_per_loop = 100_000 - 时间限制:
max_duration_minutes = 30 - 人工升级:
escalate_after_n_failures = 3 - 变更回滚:
auto_revert_if_tests_fail = True
Step 5:建立可观测性
python
# 每次循环记录
loop_metrics.log({
"iteration": i,
"tokens_used": token_count,
"duration_seconds": elapsed,
"progress_toward_goal": goal_distance,
"actions_taken": action_count,
"errors_encountered": error_count,
"escalated_to_human": escalated
})最佳实践:10 条经验法则
1. 先手动跑通,再自动化
在让 AI 自主运行之前,先手动执行几次,确认流程正确。Loop 放大了错误,也放大了正确。
2. Goal 越具体越好
「提升代码质量」 → 「将圈复杂度 > 15 的函数数量从 23 降到 5」
3. 每次循环只做一个决策
不要在一个循环里让 AI 同时做 10 个决定。拆分循环,每个循环聚焦一个决策。
4. 设置明确的退出条件
每个 Loop 都必须回答:什么情况下我应该停下来?
- 达到 Goal → 停
- 收敛停滞(连续 N 次无进步)→ 停
- 超出预算 → 停
- 出错次数过多 → 停
5. 用 Harness 提供工具,用 Loop 编排行为
不要在 Loop 里硬编码工具调用。通过 Harness 提供工具,Loop 只负责编排。
6. 状态管理是 Loop 的灵魂
Loop 的每一步都应该知道:
- 我从哪里来?(历史状态)
- 我在哪里?(当前状态)
- 我要去哪里?(Goal 距离)
7. 错误处理要分级
| 错误类型 | 处理方式 |
|---|---|
| 临时性错误(网络超时) | 自动重试(最多 3 次) |
| 逻辑错误(AI 做出了不合理的决策) | 回退到上一个检查点 |
| 系统性错误(Loop 设计有问题) | 停止 Loop,升级到人工 |
8. 不要追求完美,追求收敛
Loop 不需要每次循环都完美。它需要的是整体趋势向好。如果 Loop 在 10 次循环后比 1 次循环后好了 30%,那就是成功的 Loop。
9. 定期回顾 Loop 的设计
每运行 100 次 Loop,回顾一次:
- 平均循环次数是否在减少?(收敛更快了)
- 成功率是否在提升?(质量更好了)
- Token 消耗是否在下降?(效率更高了)
10. 从简单的 Loop 开始
不要一上来就设计递归型 Loop。从最简单的收敛型开始,验证基本流程,然后逐步增加复杂度。
行动建议
如果你是技术负责人,Loop Engineering 给你 3 个具体的行动建议:
1. 识别你团队中的「重复性 AI 工作」
找出团队中「每天都在手动 prompt AI 做同一类任务」的场景。这些就是 Loop Engineering 的最佳起点。
常见候选:
- 每日代码审查
- 每周技术报告撰写
- 持续的安全扫描和修复
- 日常的文档更新
2. 选一个场景,跑通第一个 Loop
不要试图一步到位。选一个简单场景(比如自动代码审查),按上面的 5 步指南设计你的第一个 Loop。
3. 建立 Loop Engineering 的工程规范
- Loop 设计文档模板
- Loop 运行监控仪表盘
- Loop 效果评估标准
- Loop 安全边界规范
结论:Loop 是 AI 工程的下一个基本功
Boris Cherny 和 Peter Steinberger 在同一周说出相同的话,不是因为他们商量好了,而是因为他们都在实践中发现了同一个规律:
当 AI 足够强大时,瓶颈不再是「AI 能做什么」,而是「AI 能自主做多久」。
Prompt Engineering 解决了「AI 能做什么」。Agent Engineering 解决了「AI 能做多复杂的任务」。Harness Engineering 解决了「AI 在什么环境中做」。Loop Engineering 解决了「AI 能自主、持续、可靠地做」。
这不是取代关系,而是叠加关系。每一层都建立在前一层之上。
对于技术负责人和 AI 从业者来说,Loop Engineering 不是「未来要学的东西」,而是「现在就该开始实践的东西」。
从今天开始,别再手动 prompt 了。设计一个 Loop,让 AI 自己跑起来。
原文来源于公众号文章: mp.weixin.qq.com/s/OC0YjjeQn...