处理字符串
1、走查字符串
问题:你想遍历一个字符串,将其中的每个字符都作为一行返回,但 SQL 没有提供循环操作。例如,你想分 4 行显示EMP 表中的 ENAME"KING",每一行只包含其中的一个字符。
解决方案:使用笛卡儿积计算以每行一个字符的方式返回字符串中所有的字符时需要多少行,然后使用 DBMS 内置的字符串解析函数提取感兴趣的字符。(如果使用的是 SQL Server,请用 SUBSTRING 和 DATALENGTH 替换SUBSTR 和 LENGTH。)
sql
select substr(e.ename,iter.pos,1) as C
from (
select ename
from emp
where ename = 'KING'
) e, (
select id as pos
from t10
) iter
where iter.pos <= length(e.ename);
2、在字符串字面量中嵌入引号
问题:你想在字符串字面量中嵌入引号。例如,你希望使用SQL 生成如下结果。
sql
QMARKS
--------------
g'day mate
beavers' teeth
'解决方案:下面的 3 条 SELECT 语句展示了生成引号(位于字符串中的引号和独立的引号)的不同方式。
sql
1 select 'g''day mate' qmarks from t1 union all
2 select 'beavers'' teeth' from t1 union all
3 select '''' from t1处理引号时,把它们想象成像圆括号那样通常将有所帮助。左括号必须有配套的右括号,引号也是如此。别忘了,在任何字符串中,引号的个数都必须是双数。如果想在字符串中嵌入一个引号,则必须使用两个引号。
sql
select 'apples core', 'apple''s core',
case when '' is null then 0 else 1 end
from t1
3、计算字符串中特定字符出现的次数
问题:你想计算特定的字符或子串在给定字符串中出现的次数。请看下面的字符串。
sql
10,CLARK,MANAGER你想确定这个字符串中有多少个逗号。
解决方案:删除字符串中的逗号,再将原来的字符串长度与删除逗号后的字符串长度相减,就可以确定字符串中包含多少个逗号。所有 DBMS 都提供了获取字符串长度的函数以及从字符串中删除字符的函数。在大多数情况下,这两个函数分别是 LENGTH 和 REPLACE(SQL Server 用户需要用内置函数 LEN 替代 LENGTH)。
sql
select (length('10,CLARK,MANAGER')-
length(replace('10,CLARK,MANAGER',',','')))/length(',')
as cnt
from t1;
cnt
-----
2
(1 row)上述解决方案使用了简单的减法运算。第 1 行的 LENGTH调用返回了字符串原来的长度,而第 2 行的第 1 个LENGTH 调用返回了(使用 REPLACE)将逗号删除后的字符串长度。
通过将上述两个长度相减,得到的差值就是字符串包含的逗号个数。最后一个操作是用长度差值除以查找的字符串的长度,仅当要查找的字符串的长度大于 1 时,这个除法运算才是必不可少的。下面的示例会计算 LL 在字符串"HELLO HELLO"中出现的次数,如果不执行除法运算,那么返回的结果将是错误的。
sql
select
(length('HELLO HELLO')-
length(replace('HELLO HELLO','LL','')))/length('LL')
as correct_cnt,
(length('HELLO HELLO')-
length(replace('HELLO HELLO','LL',''))) as incorrect_cnt
from t1;
correct_cnt | incorrect_cnt
-------------+---------------
2 | 4
(1 row)4、将不想要的字符从字符串中删除
问题:你想将特定的字符从数据中删除。一种使用场景是,处理格式糟糕的数值数据(尤其是金额数据)。在金额数据中,逗号被用作了千分位分隔符,其中还包含货币符号。另一种使用场景是,你要将数据库中的数据导出为 CSV文件,但有一个文本字段包含逗号(访问 CSV 文件时,将把逗号视为分隔符)。请看下面的结果集。
sql
ENAMESAL ---------- ---------- SMITH
800 ALLEN
1600 WARD
1250 JONES
2975 MARTIN
1250 BLAKE...5、将数字数据和字符数据分开
问题:你在同一列中同时存储了数字数据和字符数据。如果你使用的是同时存储了数量和度量单位(或货币符号)的遗留数据(例如,在列中存储 100 km、AUD$200 或 40pounds,而不是将数量和单位存储在不同的列中),那么很可能会遇到这种情况。
你想将字符数据和数字数据分开。请看下面的结果集。
sql
create table word_number(
DATA VARCHAR(20)
);
insert into word_number values
('SMITH800'),
('ALLEN1600'),
('WARD1250'),
('JONES2975'),
('MARTIN1250'),
('BLAKE2850'),
('CLARK2450'),
('SCOTT3000'),
('KING5000'),
('TURNER1500'),
('ADAMS1100'),
('JAMES950'),
('FORD3000'),
('MILLER1300');你希望结果是下面这样的。
sql
ENAME SAL
---------- ----------
SMITH 800
ALLEN 1600
WARD 1250
JONES 2975
MARTIN 1250
BLAKE 2850
CLARK 2450
SCOTT 3000
KING 5000
TURNER 1500
ADAMS 1100
JAMES 950
FORD 3000
MILLER 1300解决方案:使用内置函数 TRANSLATE 和 REPLACE 将字符数据和数字数据分开。与本章的其他实例一样,诀窍是使用函数TRANSLATE 将多种字符转换为特定的字符,这样无须搜索多个数字或字符,而只需搜索表示所有数字或字符的字符。
DB2:使用函数 TRANSLATE 和 REPLACE 将数字数据和字符数据分开。
sql
select replace(
translate(data,'0000000000','0123456789'),'0','') ename,
cast(
replace(
translate(lower(data),repeat('z',26),
'abcdefghijklmnopqrstuvwxyz'),'z','') as integer) sal
from (
select ename||cast(sal as char(4)) data
from emp
) xOracle:使用函数 TRANSLATE 和 REPLACE 将数字数据和字符数据分开。
sql
select replace(
translate(data,'0123456789','0000000000'),'0') ename,
to_number(
replace(
translate(lower(data),
'abcdefghijklmnopqrstuvwxyz',
rpad('z',26,'z')),'z')) sal
from (
select ename||sal data
from emp
)PostgreSQL:使用函数 TRANSLATE 和 REPLACE 将数字数据和字符数据分开。
sql
select replace(
translate(data,'0123456789','0000000000'),'0','') as ename,
cast(
replace(
translate(lower(data),
'abcdefghijklmnopqrstuvwxyz',
rpad('z',26,'z')),'z','') as integer) as sal
from (
select ename||sal as data
from emp
) x;
ename | sal
--------+------
ALLEN | 1600
WARD | 1250
MARTIN | 1250
BLAKE | 2850
TURNER | 1500
JAMES | 950
YODA | 5000
MILLER | 4000
KING | 4000
CLARK | 4000
(10 rows)SQL Server:使用函数 TRANSLATE 和 REPLACE 将数字数据和字符数据分开。
sql
select replace(
translate(data,'0123456789','0000000000'),'0','') as ename,
cast(
replace(
translate(lower(data),
'abcdefghijklmnopqrstuvwxyz',
replicate('z',26),'z','') as integer) as sal
from (
select concat(ename,sal) as data
from emp
) xMySQL:使用REGEXP_SUBSTR函数
sql
SELECT
REGEXP_SUBSTR(DATA, '^[A-Z]+') AS ENAME,
CAST(REGEXP_SUBSTR(DATA, '[0-9]+$') AS UNSIGNED) AS SAL
FROM word_number;6、判断字符串是否只包含字母和数字
问题:你想从一张表中返回这样的行,即其特定列只包含字母和数字。请看下面的视图 V(SQL Server 用户应该使用运算符 + 而不是 || 来执行拼接操作)。
sql
create view V as
select ename as data
from emp
where deptno=10
union all
select ename||', $'|| cast(sal as char(4)) ||'.00' as data
from emp
where deptno=20
union all
select ename|| cast(deptno as char(4)) as data
from emp
where deptno=30视图 V 代表你的表,它包含的内容如下。
sql
DATA
--------------------
CLARK
KING
MILLER
SMITH, $800.00
JONES, $2975.00
SCOTT, $3000.00
ADAMS, $1100.00
FORD, $3000.00
ALLEN30
WARD30
MARTIN30
BLAKE30
TURNER30
JAMES30然而,你只想从这个视图中返回如下记录。
sql
DATA
-------------
CLARK
KING
MILLER
ALLEN30
WARD30
MARTIN30
BLAKE30
TURNER30
JAMES30简言之,你不想返回除了字母和数字还包含其他字符的行。
解决方案:要解决这个问题,第一感觉是搜索可能出现在字符串中的所有非字母数字字符,但你会发现,采取相反的做法更容易:查找所有的字母数字字符。采取这种方法时,可以将所有的字母数字字符都转换为特定字符,从而将它们视为单个字符进行处理。为什么要这样做呢?这是因为这样可以将字母数字字符作为一个整体进行操作。将所有的字母数字字符都转换为你选择的字符后,将字母数字字符与其他字符隔离就易如反掌了。
DB2使用函数 TRANSLATE 将所有的字母数字字符都转换为特定的字符,然后找出那些除了这个特定字符外还包含其他字符的行。在 DB2 中,必须在视图 V 中调用函数CAST,否则类型转换错误将导致无法创建这个视图。强制转换为 CHAR 时,必须倍加小心,因为其长度是固定的(数据不够的话,将进行填充)。
sql
select data
from V
where translate(lower(data),
repeat('a',36),
'0123456789abcdefghijklmnopqrstuvwxyz') =
repeat('a',length(data))MySQL:在 MySQL 中,创建视图 V 的语法稍有不同。
sql
create view V as
select ename as data
from emp
where deptno=10
union all
select concat(ename,', $',sal,'.00') as data
from emp
where deptno=20
union all
select concat(ename,deptno) as data
from emp
where deptno=30;使用正则表达式轻松地找出包含非字母数字字符的行。
sql
select data
from V
where data regexp '[^0-9a-zA-Z]' = 0;Oracle 和 PostgreSQL:使用函数 TRANSLATE 将所有的字母数字字符都转换为特定的字符,然后找出那些除了这个特定字符外还包含其他字符的行。在 Oracle 和 PostgreSQL 中,可以不在视图V 中调用函数 CAST。强制转换为 CHAR 时,必须倍加小心,因为其长度是固定的(数据不够的话,将进行填充)。
如果你决定执行强制转换,那么请转换为 VARCHAR 或VARCHAR2。
sql
select data
from V
where translate(lower(data),
'0123456789abcdefghijklmnopqrstuvwxyz',
rpad('a',36,'a')) = rpad('a',length(data),'a')
# 正则 postres
SELECT data
FROM V
WHERE data ~ '^[0-9a-zA-Z]+$';SQL Server:与其他数据库使用的方法是一样的,但 SQL Server 中没有 RPAD。
sql
select data
from V
where translate(lower(data),
'0123456789abcdefghijklmnopqrstuvwxyz',
replicate('a',36)) = replicate('a',len(data))7、提取姓名中的首字母
问题:你想将全名转换为首字母缩写。对于下面的姓名:
sql
Stewie Griffin你想返回如下内容。
sql
S.G.解决方案:务必牢记,SQL 不像 C 或 Python 等语言那么灵活,因此在 SQL 中,创建可以处理任何姓名格式的通用解决方案并非易事。下面的解决方案要求全名要么由名和姓组成,要么由名、中间名/中间名缩写和姓组成。
DB2:使用内置函数 REPLACE、TRANSLATE 和 REPEAT 提取首字母。
sql
select replace(
replace(
translate(replace('Stewie Griffin', '.', ''),
repeat('#',26),
'abcdefghijklmnopqrstuvwxyz'),
'#','' ), ' ','.' )
||'.'
from t1MySQL:使用内置函数 CONCAT、CONCAT_WS、SUBSTRING 和SUBSTRING_INDEX 提取首字母。
sql
select case
when cnt = 2 then
trim(trailing '.' from
concat_ws('.',
substr(substring_index(name,' ',1),1,1),
substr(name,
length(substring_index(name,' ',1))+2,1),
substr(substring_index(name,' ',-1),1,1),
'.'))
else
trim(trailing '.' from
concat_ws('.',
substr(substring_index(name,' ',1),1,1),
substr(substring_index(name,' ',-1),1,1)
))
end as initials
from (
select name,length(name)-length(replace(name,' ','')) as cnt
from (
select replace('Stewie Griffin','.','') as name from t1
)y
)xOracle 和 PostgreSQL:使用内置函数 REPLACE、TRANSLATE 和 RPAD 提取首字母。
sql
select replace(
replace(
translate(replace('Stewie Griffin', '.', ''),
'abcdefghijklmnopqrstuvwxyz',
rpad('#',26,'#') ), '#','' ),' ','.' ) ||'.'
from t1;SQL Server:
sql
select replace(
replace(
translate(replace('Stewie Griffin', '.', ''),
'abcdefghijklmnopqrstuvwxyz',
replicate('#',26) ), '#','' ),' ','.' ) + '.'
from t18、根据部分字符串排序
问题:你想根据子串对结果集进行排序。请看下面的记录。
sql
create table t_name(
ENAME VARCHAR(20)
);
INSERT INTO t_name VALUES
('SMITH'),
('ALLEN'),
('WARD'),
('JONES'),
('MARTIN'),
('BLAKE'),
('CLARK'),
('SCOTT'),
('KING'),
('TURNER'),
('ADAMS'),
('JAMES'),
('FORD'),
('MILLER');你想根据姓名的最后两个字符对记录进行排序。
sql
ENAME
---------
ALLEN
TURNER
MILLER
JONES
JAMES
MARTIN
BLAKE
ADAMS
KING
WARD
FORD
CLARK
SMITH
SCOTT解决方案:本解决方案的关键是找到并使用 DBMS 内置函数来提取用作排序依据的子串。这通常是使用函数 SUBSTR 实现的。
DB2、Oracle、MySQL 和 PostgreSQL:结合使用内置函数 LENGTH 和 SUBSTR 提取字符串的特定部分,并将其作为排序依据。
sql
select ename
from t_name
order by substr(ename,length(ename)-1,2);SQL Server:使用函数 SUBSTRING 和 LEN 提取字符串的特定部分,并将其作为排序依据。
sql
select ename
from t_name
order by substring(ename,len(ename)-1,2)9、根据字符串中的数字排序
问题:你想根据字符串中的数字对结果集进行排序。请看下面的视图。
sql
create view V as
select e.ename ||' '||
cast(e.empno as char(4))||' '||
d.dname as data
from emp e, dept d
where e.deptno=d.deptno;这个视图返回的数据如下。
sql
DATA
----------------------------
CLARK 7782 ACCOUNTING
KING 7839 ACCOUNTING
MILLER 7934 ACCOUNTING
SMITH 7369 RESEARCH
JONES 7566 RESEARCH
SCOTT 7788 RESEARCH
ADAMS 7876 RESEARCH
FORD 7902 RESEARCH
ALLEN 7499 SALES
WARD 7521 SALES
MARTIN 7654 SALES
BLAKE 7698 SALES
TURNER 7844 SALES
JAMES 7900 SALES你要根据位于员工姓名和所属部门之间的员工编号对结果进行排序。
sql
DATA
---------------------------
SMITH 7369 RESEARCH
ALLEN 7499 SALES
WARD 7521 SALES
JONES 7566 RESEARCH
MARTIN 7654 SALES
BLAKE 7698 SALES
CLARK 7782 ACCOUNTING
SCOTT 7788 RESEARCH
KING 7839 ACCOUNTING
TURNER 7844 SALES
ADAMS 7876 RESEARCH
JAMES 7900 SALES
FORD 7902 RESEARCH
MILLER 7934 ACCOUNTING解决方案:下面的解决方案使用的函数和语法因 DBMS 而异,但所有解决方案采用的方法都相同(使用内置函数 REPLACE和 TRANSLATE)。基本思路是使用函数 REPLACE 和TRANSLATE 将字符串中的非数字字符删除,只留下用作排序依据的数字值。
DB2:使用内置函数 REPLACE 和 TRANSLATE 提取字符串中的数字值,并将其用作排序依据。
sql
select data
from V
order by
cast(
replace(
translate(data,repeat('#',length(data)),
replace(
translate(data,'##########','0123456789'),
'#','')),'#','') as integer)Oracle:使用内置函数 REPLACE 和 TRANSLATE 提取字符串中的数字值,并将其用作排序依据。
sql
select data
from V
order by
to_number(
replace(
translate(data,
replace(
translate(data,'0123456789','##########'),
'#'),rpad('#',20,'#')),'#'))PostgreSQL:使用内置函数 REPLACE 和 TRANSLATE 提取字符串中的数字值,并将其用作排序依据。
sql
select data
from V
order by
cast(
replace(
translate(data,
replace(
translate(data,'0123456789','##########'),
'#',''),rpad('#',20,'#')),'#','') as integer);MySQL:
sql
SELECT *
FROM V
ORDER BY CAST(
REGEXP_SUBSTR(data, '[0-9]+')
AS UNSIGNED
);10、根据表中的行创建分隔列表
问题:你想以分隔列表(分隔符可能是逗号)而不是常见的垂直列的方式返回表中的行。换言之,你要将下面的结果集:
sql
DEPTNO EMPS
------ ----------
10 CLARK
10 KING
10 MILLER
20 SMITH
20 ADAMS
20 FORD
20 SCOTT
20 JONES
30 ALLEN
30 BLAKE
30 MARTIN
30 JAMES
30 TURNER
30 WARD转换成如下这样。
sql
DEPTNO EMPS
------- ------------------------------------
10 CLARK,KING,MILLER
20 SMITH,JONES,SCOTT,ADAMS,FORD
30 ALLEN,WARD,MARTIN,BLAKE,TURNER,JAMES解决方案:这个问题的解决方案随 DBMS 而异,关键是利用 DBMS提供的内置函数。弄清楚 DBMS 都提供了哪些函数,才能充分利用 DBMS 的功能,设计出创造性的解决方案, 以解决通常使用 SQL 无法解决的问题。
当前,大多数 DBMS 提供了专门为串接字符串而设计的函数,比如 MySQL 的函数 GROUP_CONCAT(最早的函数之一)或 SQL Server 的函数 STRING_ADD(SQLServer 2017 中新增的)。这些函数的语法类似,让你能够轻松地解决上述问题。
DB2:使用 LIST_AGG 创建分隔列表。
sql
select deptno,
list_agg(ename ',') within GROUP(Order by 0) as emps
from emp
group by deptnoMySQL :使用内置函数 GROUP_CONCAT 创建分隔列表。
sql
select deptno,
group_concat(ename order by empno separator ',') as emps
from emp
group by deptno;
Oracle:使用内置函数 SYS_CONNECT_BY_PATH 创建分隔列表。
sql
select deptno,
ltrim(sys_connect_by_path(ename,','),',') emps
from (
select deptno,
ename,
row_number() over
(partition by deptno order by empno) rn,
count(*) over
(partition by deptno) cnt
from emp
)
where level = cnt
start with rn = 1
connect by prior deptno = deptno and prior rn = rn-1PostgreSQL 和 SQL Server:
sql
select deptno,
string_agg(ename order by empno separator, ',') as emps
from emp
group by deptno11、将分隔数据转换为多值IN列表
问题:你想将分隔数据传递给 WHERE 子句中的 IN 列表迭代器。请看下面的字符串。
sql
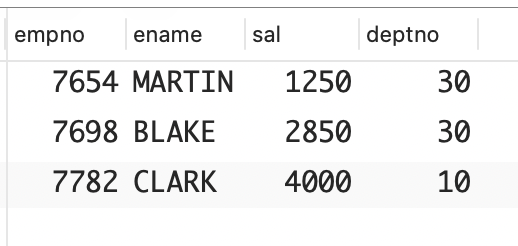
7654,7698,7782,7788你想在 WHERE 子句中使用这个字符串,但下面的 SQL以失败告终,因为 EMPNO 是数值列。
sql
select ename,sal,deptno
from emp
where empno in ( '7654,7698,7782,7788' )这条 SQL 语句之所以执行失败,是因为 EMPNO 为数值列,而 IN 列表包含的是单个字符串值。你希望这个字符串被视为用逗号分隔的数值列表。
解决方案:从表面上看,SQL 好像应该能够将分隔字符串视为值列表,但情况并非如此。遇到位于引号内的逗号时,SQL不可能知道这意味着引号内的内容是一个多值列表。SQL必须将引号内的所有内容视为单个实体------一个字符串值。你必须将前述字符串拆分成多个 EMPNO。本解决方案的关键是拆分字符串,但不是拆分为单个的字符,而是拆分为有效的 EMPNO 值。
DB2:通过遍历传递给 IN 列表的字符串,可以轻松地将其转换 为多行数据。在这里,函数 ROW_NUMBER、LOCATE 和SUBSTR 很有用。
sql
select empno,ename,sal,deptno
from emp
where empno in (
select cast(substr(c,2,locate(',',c,2)-2) as integer) empno
from (
select substr(csv.emps,cast(iter.pos as integer)) as c
from (select ','||'7654,7698,7782,7788'||',' emps
from t1) csv,
(select id as pos
from t100 ) iter
where iter.pos <= length(csv.emps)
) x
where length(c) > 1
and substr(c,1,1) = ','
)MySQL:通过遍历传递给 IN 列表的字符串,可以轻松地将其转换为多行数据。
sql
select empno, ename, sal, deptno
from emp
where empno in
(
select substring_index(
substring_index(list.vals,',',iter.pos),',',-1) empno
from (select id pos from t10) as iter,
(select '7654,7698,7782,7788' as vals
from t1) list
where iter.pos <=
(length(list.vals)-length(replace(list.vals,',','')))+1
);
Oracle:通过遍历传递给 IN 列表的字符串,可以轻松地将其转换为多行数据。在这里,函数 ROWNUM、SUBSTR 和 INSTR很有用。
sql
select empno,ename,sal,deptno
from emp
where empno in (
select to_number(
rtrim(
substr(emps,
instr(emps,',',1,iter.pos)+1,
instr(emps,',',1,iter.pos+1)
instr(emps,',',1,iter.pos)),',')) emps
from (select ','||'7654,7698,7782,7788'||',' emps from t1) csv,
(select rownum pos from emp) iter
where iter.pos <= ((length(csv.emps)-
length(replace(csv.emps,',')))/length(','))-1
)PostgreSQL:通过遍历传递给 IN 列表的字符串,可以轻松地将其转换为多行数据。函数 SPLIT_PART 能够将字符串轻松地拆分为多个数字。
sql
select ename,sal,deptno
from emp
where empno in (
select cast(empno as integer) as empno
from (
select split_part(list.vals,',',iter.pos) as empno
from (select id as pos from t10) iter,
(select ','||'7654,7698,7782,7788'||',' as vals
from t1) list
where iter.pos <=
length(list.vals)-length(replace(list.vals,',',''))
) z
where length(empno) > 0
)SQL Server:通过遍历传递给 IN 列表的字符串,可以轻松地将其转换为多行数据。在这里,函数 ROW_NUMBER、CHARINDEX和 SUBSTRING 很有用。
sql
select empno,ename,sal,deptno
from emp
where empno in (select substring(c,2,charindex(',',c,2)-2) as empno
from (
select substring(csv.emps,iter.pos,len(csv.emps)) as c
from (select ','+'7654,7698,7782,7788'+',' as emps
from t1) csv,
(select id as pos
from t100) iter
where iter.pos <= len(csv.emps)
) x
where len(c) > 1
and substring(c,1,1) = ','
)12、按字母顺序排列字符串中的字符
问题:你想按字母顺序排列字符串中的字符。请看下面的结果集
sql
ENAME
----------
ADAMS
ALLEN
BLAKE
CLARK
FORD
JAMES
JONES
KING
MARTIN
MILLER
SCOTT
SMITH
TURNER
WARD你要将以上结果集变成如下这样。
sql
OLD_NAME NEW_NAME
---------- --------
ADAMS AADMS
ALLEN AELLN
BLAKE ABEKL
CLARK ACKLR
FORD DFOR
JAMES AEJMS
JONES EJNOS
KING GIKN
MARTIN AIMNRT
MILLER EILLMR
SCOTT COSTT
SMITH HIMST
TURNER ENRRTU
WARD ADRW解决方案:随着标准化程度的提高,不同 DBMS 解决方案的相似程度和可移植性也越来越高,这个问题很好地证明了这一点。
DB2:要按字母顺序排列字符,必须遍历每个字符串,然后对其中的字符进行排序。
sql
select ename,
listagg(c,'') WITHIN GROUP( ORDER BY c)
from (
select a.ename,
substr(a.ename,iter.pos,1
) as c
from emp a,
(select id as pos from t10) iter
where iter.pos <= length(a.ename)
order by 1,2
) x
Group By cMySQL:这里的关键是函数 GROUP_CONCAT,该函数不仅能拼接每个姓名中的字符,还能对它们进行排序。
sql
select ename, group_concat(c order by c separator '')
from (
select ename, substr(a.ename,iter.pos,1) c
from emp a,
( select id pos from t10 ) iter
where iter.pos <= length(a.ename)
) x
group by ename;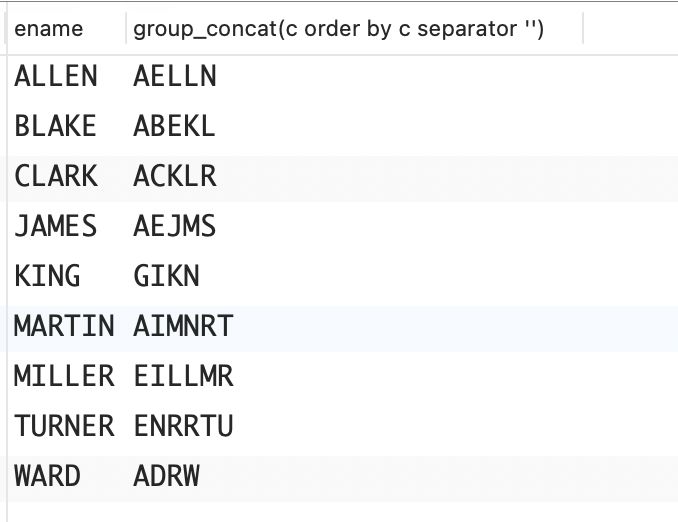
Oracle:函数 SYS_CONNECT_BY_PATH 能以迭代的方式创建列表。
sql
select old_name, new_name
from (
select old_name, replace(sys_connect_by_path(c,' '),' ') new_name
from (
select e.ename old_name,
row_number() over(partition by e.ename
order by substr(e.ename,iter.pos,1)) rn,
substr(e.ename,iter.pos,1) c
from emp e,
( select rownum pos from emp ) iter
where iter.pos <= length(e.ename)
order by 1
) x
start with rn = 1
connect by prior rn = rn-1 and prior old_name = old_name
)
where length(old_name) = length(new_name)PostgreSQL:PostgreSQL 如今提供了 STRING_AGG,可用于对字符串中的字符进行排序。
sql
select ename, string_agg(c , ''
ORDER BY c)
from (
select a.ename,
substr(a.ename,iter.pos,1) as c
from emp a,
(select id as pos from t10) iter
where iter.pos <= length(a.ename)
order by 1,2
) x
Group By cSQL Server:如果你使用的是 SQL Server 2017 或更高的版本,那么可以采用使用 STRING_AGG 的 PostgreSQL 解决方案。否则,必须遍历每个字符串并对其中的字符进行排序。
sql
select ename,
max(case when pos=1 then c else '' end)+
max(case when pos=2 then c else '' end)+
max(case when pos=3 then c else '' end)+
max(case when pos=4 then c else '' end)+
max(case when pos=5 then c else '' end)+
max(case when pos=6 then c else '' end)
from (
select e.ename,
substring(e.ename,iter.pos,1) as c,
row_number() over (
partition by e.ename
order by substring(e.ename,iter.pos,1)) as pos
from emp e,
(select row_number()over(order by ename) as pos
from emp) iter
where iter.pos <= len(e.ename)
) x
group by ename13、识别可视为数字的字符串
问题:你有一个存储字符数据的列,不过其所对应的行既包含数字数据又包含字符数据。请看下面的视图 V。
sql
create view V as
select replace(mixed,' ','') as mixed
from (
select substr(ename,1,2)||
cast(deptno as char(4))||
substr(ename,3,2) as mixed
from emp
where deptno = 10
union all
select cast(empno as char(4)) as mixed
from emp
where deptno = 20
union all
select ename as mixed
from emp
where deptno = 30
) x;
select * from v;
MIXED
--------------
CL10AR
KI10NG
MI10LL
7369
7566
7788
7876
7902
ALLEN
WARD
MARTIN
BLAKE
TURNER
JAMES你想返回只有数字或至少包含一个数字的行。对于同时包含数字和字符的行,你想将字符删除,只返回数字。对于前面的示例数据,你希望结果集如下所示。
sql
MIXED
--------
10
10
10
7369
7566
7788
7876
7902解决方案:在操作字符串和字符方面,函数 REPLACE 和TRANSLATE 很有用。关键是将所有的数字都转换为特定的字符,以便通过这个字符轻松地隔离和识别数字。
DB2:使用函数 TRANSLATE、REPLACE 和 POSSTR 来隔离每行的数字字符。视图 V 中的 CAST 调用必不可少,否则类型转换错误将导致无法创建这个视图。需要使用函数REPLACE 将强制转换为定长 CHAR 生成的多余空白删除。
sql
select mixed old,
cast(
case
when
replace(
translate(mixed,'9999999999','0123456789'),'9','') = ''
then
mixed
else replace(
translate(mixed,
repeat('#',length(mixed)),
replace(
translate(mixed,'9999999999','0123456789'),'9','')),
'#','')
end as integer ) mixed
from V
where posstr(translate(mixed,'9999999999','0123456789'),'9') > 0MySQL:在 MySQL 中,语法稍有不同,需要像下面这样定义视图V。
sql
create view V as
select concat(
substr(ename,1,2),
replace(cast(deptno as char(4)),' ',''),
substr(ename,3,2)
) as mixed
from emp
where deptno = 10
union all
select replace(cast(empno as char(4)), ' ', '')
from emp where deptno = 20
union all
select ename from emp where deptno = 30由于 MySQL 不支持函数 TRANSLATE,因此必须遍历每一行数据并逐字符对其进行评估。
sql
select cast(group_concat(c order by pos separator '') as unsigned)
as MIXED1
from (
select v.mixed, iter.pos, substr(v.mixed,iter.pos,1) as c
from V,
( select id pos from t10 ) iter
where iter.pos <= length(v.mixed)
and ascii(substr(v.mixed,iter.pos,1)) between 48 and 57
) y
group by mixed
order by 1Oracle:使用函数 TRANSLATE、REPLACE 和 INSTR 来隔离每行的数字字符。在视图 V 中,并非必须调用 CAST。使用函数 REPLACE 将强制转换为定长 CHAR 生成的多余空白删除。如果决定保留视图定义中的显式类型转换调用,建议转换为 VARCHAR2。
sql
select to_number (
case
when
replace(translate(mixed,'0123456789','9999999999'),'9')
is not null
then
replace(
translate(mixed,
replace(
translate(mixed,'0123456789','9999999999'),'9'),
rpad('#',length(mixed),'#')),'#')
else
mixed
end
) mixed
from V
where instr(translate(mixed,'0123456789','9999999999'),'9') > 0PostgreSQL:使用函数 TRANSLATE、REPLACE 和 STRPOS 来隔离每行的数字字符。在视图 V 中,并非必须调用 CAST。使用函数 REPLACE 将强制转换为定长 CHAR 生成的多余空白删除。如果决定保留视图定义中的显式类型转换调用,建议转换为 VARCHAR。
sql
select cast(
case
when
replace(translate(mixed,'0123456789','9999999999'),'9','')
is not null
then
replace(
translate(mixed,
replace(
translate(mixed,'0123456789','9999999999'),'9',''),
rpad('#',length(mixed),'#')),'#','')
else
mixed
end as integer ) as mixed
from V
where strpos(translate(mixed,'0123456789','9999999999'),'9') > 0SQL Server:结合使用内置函数 ISNUMERIC 和通配查找,可以轻松地识别包含数字的字符串,但由于 SQL Server 不支持函数TRANSLATE,因此从字符串中提取数字字符的效率不是很高。
14、提取第n个子串
问题:你想从字符串中提取特定的子串。请看下面的视图 V,它是这个问题的数据源。
sql
create view V as
select 'mo,larry,curly' as name
from t1
union all
select 'tina,gina,jaunita,regina,leena' as name
from t1这个视图的输出如下。
sql
select * from v
NAME
-------------------
mo,larry,curly
tina,gina,jaunita,regina,leena你要从每行中提取第二个姓名,因此最终的结果集如下所示。
sql
SUB
-----
larry
gina解决方案:要解决这个问题,关键是将每个姓名作为一行返回,并保留姓名在列表中的位置。具体如何完成这些任务取决于你使用的是哪个 DBMS。
DB2:遍历视图 V 返回的 NAME 后,使用函数 ROW_NUMBER 留下每个字符串中的第二个姓名。
sql
select substr(c,2,locate(',',c,2)-2)
from (
select pos, name, substr(name, pos) c,
row_number() over( partition by name
order by length(substr(name,pos)) desc) rn
from (
select ',' ||csv.name|| ',' as name,
cast(iter.pos as integer) as pos
from V csv,
(select row_number() over() pos from t100 ) iter
where iter.pos <= length(csv.name)+2
) x
where length(substr(name,pos)) > 1
and substr(substr(name,pos),1,1) = ','
) y
where rn = 2MySQL:遍历视图 V 返回的 NAME 后,根据逗号的位置返回每个字符串中的第二个姓名。
sql
select name
from (
select iter.pos,
substring_index(
substring_index(src.name,',',iter.pos),',',-1) name
from V src,
(select id pos from t10) iter,
where iter.pos <=
length(src.name)-length(replace(src.name,',',''))
) x
where pos = 2;Oracle:遍历视图 V 返回的 NAME 后,使用 SUBSTR 和 INSTR检索每个列表中的第二个姓名。
sql
select sub
from (
select iter.pos,
src.name,
substr( src.name,
instr( src.name,',',1,iter.pos )+1,
instr( src.name,',',1,iter.pos+1 ) -
instr( src.name,',',1,iter.pos )-1) sub
from (select ','||name||',' as name from V) src,
(select rownum pos from emp) iter
where iter.pos < length(src.name)-length(replace(src.name,','))
)
where pos = 2PostgreSQL:使用函数 SPLIT_PART 将每个姓名作为一行返回。
sql
select name
from (
select iter.pos, split_part(src.name,',',iter.pos) as name
from (select id as pos from t10) iter,
(select cast(name as text) as name from v) src
where iter.pos <=
length(src.name)-length(replace(src.name,',',''))+1
) x
where pos = 2SQL Server:SQL Server 函数 STRING_SPLIT 可以完成这项任务,但只能接受单个单元格(single cell),因此我们在一个CTE 中使用 STRING_AGG 按 STRING_SPLIT 要求的方式提供数据。
sql
with agg_tab(name)
as
(select STRING_AGG(name,',') from V)
select value from
STRING_SPLIT(
(select name from agg_tab),',')15、拆分IP地址
问题:你想将 IP 地址的不同部分拆分为列。请看下面的 IP 地址。
sql
111.22.3.4你希望查询的结果如下所示。
sql
A B C D
----- ----- ----- ---
111 22 3 4解决方案:具体的解决方案随 DBMS 提供的内置函数而异。不管你使用的是哪种 DBMS,解决方案的关键都在于定位句点及其两边的数字。
DB2:使用递归子句 WITH 模拟迭代 IP 地址的过程,同时使用SUBSTR 来轻松地分析它。在 IP 地址前面添加一个句点,这样每组数字前面就都有了一个句点,因此我们能够以相同的方式处理它们。
sql
with x (pos,ip) as (
values (1,'.92.111.0.222')
union all
select pos+1,ip from x where pos+1 <= 20
)
select max(case when rn=1 then e end) a,
max(case when rn=2 then e end) b,
max(case when rn=3 then e end) c,
max(case when rn=4 then e end) d
from (
select pos,c,d,
case when posstr(d,'.') > 0 then substr(d,1,posstr(d,'.')-1)
else d
end as e,
row_number() over( order by pos desc) rn
from (
select pos, ip,right(ip,pos) as c, substr(right(ip,pos),2) as d
from x
where pos <= length(ip)
and substr(right(ip,pos),1,1) = '.'
) x
) yMySQL:函数 SUBSTR_INDEX 让你能够轻松地分析 IP 地址。
sql
select substring_index(substring_index(y.ip,'.',1),'.',-1) a,
substring_index(substring_index(y.ip,'.',2),'.',-1) b,
substring_index(substring_index(y.ip,'.',3),'.',-1) c,
substring_index(substring_index(y.ip,'.',4),'.',-1) d
from (select '92.111.0.2' as ip from t1) y
Oracle:使用内置函数 SUBSTR 和 INSTR 来分析 IP 地址并在其中导航。
sql
select ip,
substr(ip, 1, instr(ip,'.')-1 ) a,
substr(ip, instr(ip,'.')+1,
instr(ip,'.',1,2)-instr(ip,'.')-1 ) b,
substr(ip, instr(ip,'.',1,2)+1,
instr(ip,'.',1,3)-instr(ip,'.',1,2)-1 ) c,
substr(ip, instr(ip,'.',1,3)+1 ) d
from (select '92.111.0.2' as ip from t1)PostgreSQL:使用内置函数 SPLIT_PART 来分析 IP 地址。
sql
select split_part(y.ip,'.',1) as a,
split_part(y.ip,'.',2) as b,
split_part(y.ip,'.',3) as c,
split_part(y.ip,'.',4) as d
from (select cast('92.111.0.2' as text) as ip from t1) as y;
a | b | c | d
----+-----+---+---
92 | 111 | 0 | 2
(1 row)SQL Server:使用递归子句 WITH 模拟迭代 IP 地址的过程,同时使用SUBSTR 来轻松地分析它。在 IP 地址前面添加一个句点,这样每组数字前面就都有了一个句点,因此我们能够以相同的方式处理它们。
sql
with x (pos,ip) as (
select 1 as pos,'.92.111.0.222' as ip from t1
union all
select pos+1,ip from x where pos+1 <= 20
)
select max(case when rn=1 then e end) a,
max(case when rn=2 then e end) b,
max(case when rn=3 then e end) c,
max(case when rn=4 then e end) d
from (
select pos,c,d,
case when charindex('.',d) > 0
then substring(d,1,charindex('.',d)-1)
else d
end as e,
row_number() over(order by pos desc) rn
from (
select pos, ip,right(ip,pos) as c,
substring(right(ip,pos),2,len(ip)) as d
from x
where pos <= len(ip)
and substring(right(ip,pos),1,1) = '.'
) x
) y16、根据发音比较字符串
问题:在匹配单词方面,有两种极端情况,一是匹配拼写正确和拼写错误的单词,二是匹配拼写方式不同(比如英式拼写和美式拼写)的单词。除了这两种极端情况,很多时候还需要匹配由不同字符串表示的单词。所幸 SQL 提供了一种表示单词发音的方式,让你能够查找拼写不同但发音相同的字符串。
例如,你有一个作者姓名清单,其中一些作者是古代的,拼写不像现在这样固定,还有一些存在拼写和输入错误,如下所示。
sql
a_name
----
1 Johnson
2 Jonson
3 Jonsen
4 Jensen
5 Johnsen
6 Shakespeare
7 Shakspear
8 Shaekspir
9 Shakespar在这个清单中,你要找出哪些姓名的发音相同。对于这个问题,解决方案有多种,下面是其中之一(等你阅读完本节后,最后一列的含义将更清晰)。
sql
a_name1 a_name2 soundex_name
---- ---- ----
Jensen Johnson J525
Jensen Jonson J525
Jensen Jonsen J525
Jensen Johnsen J525
Johnsen Johnson J525
Johnsen Jonson J525
Johnsen Jonsen J525
Johnsen Jensen J525
...
Jonson Jensen J525
Jonson Johnsen J525
Shaekspir Shakspear S216
Shakespar Shakespeare S221
Shakespeare Shakespar S221
Shakspear Shaekspir S216解决方案:使用函数 SOUNDEX 将字符串转换为英语发音。使用简单的自连接,可以对同一列中的不同值进行比较。
sql
select an1.a_name as name1, an2.a_name as name2,
SOUNDEX(an1.a_name) as Soundex_Name
from author_names an1
join author_names an2
on (SOUNDEX(an1.a_name)=SOUNDEX(an2.a_name)
and an1.a_name not like an2.a_name)17、查找与模式不匹配的文本
问题:有一个文本字段,其中包含一些结构化的文本值(比如电话号码),而你想找出那些未正确结构化的值。假设有如下数据:
sql
select emp_id, text
from employee_comment
EMP_ID TEXT
---------- ------------------------------------------------------------
7369 126 Varnum, Edmore MI 48829, 989 313-5351
7499 1105 McConnell Court
Cedar Lake MI 48812
Home: 989-387-4321
Cell: (237) 438-3333你要列出其中电话号码格式不正确的行。例如,你要列出下面这一行,因为其电话号码使用了不同的分隔符。
sql
7369 126 Varnum, Edmore MI 48829, 989 313-5351仅当电话号码使用相同的分隔符时,你才认为它们是正确的。
解决方案:这个问题的解决方案由多个部分组成。
- 找出一种方式,指出看起来像电话号码的内容是什么样的。
- 将格式正确的电话号码都删除。
- 看看是否还有看起来像电话号码的内容,如果有,就说明它们的格式不正确。
sql
select emp_id, text
from employee_comment
where regexp_like(text, '[0-9]{3}[-. ][0-9]{3}[-. ][0-9]{4}')
and regexp_like(
regexp_replace(text,
'[0-9]{3}([-. ])[0-9]{3}\1[0-9]{4}','***'),
'[0-9]{3}[-. ][0-9]{3}[-. ][0-9]{4}')
EMP_ID TEXT
---------- ------------------------------------------------------------
7369 126 Varnum, Edmore MI 48829, 989 313-5351
7844 989-387.5359
9999 906-387-1698, 313-535.8886这些行都包含看起来像电话号码但格式不正确的内容。